r语言arch模型分析报告_附数据代码
【最新】R语言关联分析模型报告案例附代码数据

【最新】R语⾔关联分析模型报告案例附代码数据【原创】附代码数据有问题到淘宝找“⼤数据部落”就可以了关联分析⽬录⼀、概括 (1)⼆、数据清洗 (1)2.1公⽴学费(NPT4_PUB) (1)2.2毕业率(Graduation.rate) (1)2.3贷款率(GRAD_DEBT_MDN_SUPP) (2)2.4偿还率(RPY_3YR_RT_SUPP) (2)2.5毕业薪⽔(MD_EARN_WNE_P10)。
(3)2.6 私⽴学费(NPT4_PRIV) (3)2.7 ⼊学率(ADM_RATE_ALL) (4)三、Apriori算法 (4)3.1 相关概念 (5)3.2 算法流程 (6)3.3 优缺点 (7)四、模型建⽴及结果 (8)4.1 公⽴模型 (8)4.2 私⽴模型 (11)⼀、概括对7703条样本数据,分别根据公⽴学费和私⽴学费差异,建⽴公⽴模型和私⽴模型,进⾏关联分析。
⼆、数据清洗2.1公⽴学费(NPT4_PUB)此字段,存在4个负值,与实际情况不符,故将此四个值重新定义为NULL。
重新定义后,NULL值的占⽐为75%,占⽐很⼤,不能直接将NULL值删除或者进⾏插补,故将NULL单独作为⼀个取值分组。
对⾮NULL的值按照等⽐原则进⾏分组,分组结果如下:A:[0,5896]B:(5896,7754]C:(7754, 9975]D:(9975, 13819]E:(13819, +]分组后取值分布为:2.2毕业率(Graduation.rate)将PrivacySuppressed值重新定义为NULL,重新定义后,NULL值的占⽐为20%,占⽐较⼤,不适合直接删除或进⾏插补,故将NULL单独作为⼀个取值分组。
对⾮NULL值根据等⽐原则进⾏分组,分组结果如下:A:[0,0.29]B:(0.29,0.47]C:(0.47, 0.61]D:(0.61, 0.75]E:(0.75, +]分组后取值分布为:2.3贷款率(GRAD_DEBT_MDN_SUPP)将PrivacySuppressed值重新定义为NULL,重新定义后,NULL值的占⽐为20%,占⽐较⼤,不适合直接删除或进⾏插补,故将NULL单独作为⼀个取值分组。
【最新】R语言数据分析课件教案讲义(附代码数据)

Suggested steps: Step 1 # Read data into R, attach data, print first 6 lines uwc = read.csv(file.choose()) attach(uwc) head(uwc) Step 2 # Plot marginal distributions par(mfrow=c(1,2)) #1 row by 2 cols graphics window hist(rating,prob=T,col="gray") lines(density(rating)) hist(result,prob=T,col="gray") lines(density(result)) # fit the linear model (linear regression model) fit1 <- lm(result ~ rating) # fit1 is an object generated by the routine “lm” containing a lot # of information about the fitted model. # The rest of the steps are simply accessing information in fit1 # obtain summary and anova of fit # compute fitted values and residuals summary(fit1) anova(fit1) yhat <- fitted.values(fit1) # fitted values res <- residuals(fit1) # residuals # # # # # # # # # # # # # # # various common plots put into a 2X3 matrix of scatter-plots to check the fit and assumptions on noise terms i.e. are they normal and independent of predictor and model? plot 1: scatterplot of data and superimposed fitted model only do this plot when there is only a single predictor plot 2: scatterplot of observed values vs fitted values to see how close the fitted values are to the observed data – do this plot no matter how many predictors plot 3: plot of residuals (random or pattern?) plot 4: Q-Q plot of residuals (are they approx normal?) plot 5: residuals vs predictor (random or pattern?) if there are many predictors we plot residuals against each predictor in turn plot 6: residuals vs fitted (random or pattern?)
R语言数据分析回归研究案例报告 附代码数据

R语言数据分析回归研究案例:移民政策偏好是否有准确的刻板印象?数据重命名,重新编码,重组Group <chr> Count<dbl>Percent<dbl>6 476 56.00 5 179 21.062 60 7.063 54 6.354 46 5.41 1 27 3.18 0 8 0.94对Kirkegaard&Bjerrekær2016的再分析确定用于本研究的32个国家的子集的总体准确性。
#降低样本的#精确度GG_scatter(dk_fiscal, "mean_estimate", "dk_benefits_use",GG_scatter(dk_fiscal_sub, "mean_estimate", "dk_benefits_us e", case_names="Names")GG_scatter(dk_fiscal, "mean_estimate", "dk_fiscal", case_n ames="Names")#compare Muslim bias measures#can we make a bias measure that works without ratio scaleScore stereotype accuracy#add metric to main datad$stereotype_accuracy=indi_accuracy$pearson_rGG_save("figures/aggr_retest_stereotypes.png")GG_save("figures/aggregate_accuracy.png")GG_save("figures/aggregate_accuracy_no_SYR.png")Muslim bias in aggregate dataGG_save("figures/aggregate_muslim_bias.png")Immigrant preferences and stereotypesGG_save("figures/aggregate_muslim_bias_old_data.png") Immigrant preferences and stereotypesGG_save("figures/aggr_fiscal_net_opposition_no_SYR.png")GG_save("figures/aggr_stereotype_net_opposition.png")GG_save("figures/aggr_stereotype_net_opposition_no_SYR.pn g")lhs <chr>op<chr > rhs <chr> est <dbl> se <dbl> z <dbl> pvalue <dbl> net_opposition ~ mean_estimate_fiscal -4.4e-01 0.02303 -19.17 0.0e+00net_opposition~Muslim_frac 4.3e-02 0.05473 0.79 4.3e-01net_opposition~~net_opposition 6.9e-03 0.00175 3.94 8.3e-05dk_fiscal ~~ dk_fiscal 6.2e+03 0.00000 NA NAMuslim_frac~~Muslim_frac1.7e-01 0.0000NANAIndividual level modelsGG_scatter(example_muslim_bias, "Muslim", "resid", case_na mes="name")+#exclude Syria#distributiondescribe(d$Muslim_bias_r)%>%print()GG_save("figures/muslim_bias_dist.png")## `stat_bin()` using `bins = 30`. Pick better value with `GG_scatter(mediation_example, "Muslim", "resid", case_name s="name", repel_names=T)+scale_x_continuous("Muslim % in home country", labels=scal#stereotypes and preferencesmediation_model=plyr::ldply(seq_along_rows(d), function(rGG_denhist(mediation_model, "Muslim_resid_OLS", vline=medi an)## `stat_bin()` using `bins = 30`. Pick better value with `add to main datad$Muslim_preference=mediation_model$Muslim_resid_OLS Predictors of individual primary outcomes#party modelsrms::ols(stereotype_accuracy~party_vote, data=d)GG_group_means(d, "Muslim_bias_r", "party_vote")+ theme(axis.text.x=element_text(angle=-30, hjust=0))GG_group_means(d, "Muslim_preference", "party_vote")+#party agreement cors wtd.cors(d_parties)。
R语言可视化分析案例报告 附代码数据

library(ggplot2)
ggplot(data=mtcars,
aes(x=factor(1),fill=factor(carb)))+
ylab("Percentage of Car Amount by Carb Type")+xlab("")+
## Max. :33.90 Max. :8.000 Max. :472.0 Max. :335.0
## drat wt qsec vs
## Min. :2.760 Min. :1.513 Min. :14.50 Min. :0.0000
## 1st Qu.:3.080 1st Qu.:2.581 1st Qu.:16.89 1st Qu.:0.0000
## Median :3.695 Median :3.325 Median :17.71 Median :0.0000
## Mean :3.597 Mean :3.217 Mean :17.85 Mean :0.4375
## 3rd Qu.:3.920 3rd Qu.:3.610 3rd Qu.:18.90 3rd Qu.:1.0000
ggplot(mtcars,
aes(x=factor(cyl),fill=factor(gear)))+
xlab("cyl amount'")+
ylab("gear amount'")+
geom_bar(color="black")
4. Draw a scatter plot showing the relationship betweenwtandmpg.
R语言假设检验数据分析案例分析报告 附代码数据

R语言假设检验数据分析案例分析报告总体均值的90%置信区间是(65,77)。
人口分布近似正常,人口标准差未知。
这个置信区间基于25个观测值的简单随机样本。
计算样本均值,误差范围和样本标准偏差。
n <-25#we know that the margin of error is (b-a)/2 where the confidence interval is (a,b)ME <-((77-65)/2)ME## [1] 6#we know that sample mean is calculated as (a+b)/2 for confidence interval (a,b)xbar <-((77+65)/2)xbar## [1] 71df <-25-1t.value <-qt(.95, df)t.value## [1] 1.710882sd <-(ME/t.value)*5sd## [1] 17.53481SAT scores.SAT分数。
常春藤大学学生的SAT分数分布在一个标准差为250分。
两位统计学生Raina和Luke想估计一下平均SAT成绩作为班级项目的一部分。
他们希望他们的误差不超过25分。
(a) Raina wants to use a 90% confidence interval. How large a sample should she collect? #we will use formual n = (Z(.05)*(standard deviation)/ME)^2z.star <-1.65ME <-25SD <-250sample.size <-(((z.star*SD)/(ME))^2)sample.size## [1] 272.25(b) 卢克想要使用99%的置信区间。
在不计算实际样本量的情况下,确定他的样本是否应该大于或小于Raina's,并解释您的推理。
【原创】R语言线性回归案例数据分析可视化报告(附代码数据)

R语言线性回归案例数据分析可视化报告在本实验中,我们将查看来自所有30个职业棒球大联盟球队的数据,并检查一个赛季的得分与其他球员统计数据之间的线性关系。
我们的目标是通过图表和数字总结这些关系,以便找出哪个变量(如果有的话)可以帮助我们最好地预测一个赛季中球队的得分情况。
数据用变量at_bats绘制这种关系作为预测。
关系看起来是线性的吗?如果你知道一个团队的at_bats,你会习惯使用线性模型来预测运行次数吗?散点图.如果关系看起来是线性的,我们可以用相关系数来量化关系的强度。
.残差平方和回想一下我们描述单个变量分布的方式。
回想一下,我们讨论了中心,传播和形状等特征。
能够描述两个数值变量(例如上面的runand at_bats)的关系也是有用的。
从前面的练习中查看你的情节,描述这两个变量之间的关系。
确保讨论关系的形式,方向和强度以及任何不寻常的观察。
正如我们用均值和标准差来总结单个变量一样,我们可以通过找出最符合其关联的线来总结这两个变量之间的关系。
使用下面的交互功能来选择您认为通过点云的最佳工作的线路。
# Click two points to make a line.After running this command, you’ll be prompted to click two points on the plot to define a line. Once you’ve done that, the line you specified will be shown in black and the residuals in blue. Note that there are 30 residuals, one for each of the 30 observations. Recall that the residuals are the difference between the observed values and the values predicted by the line:e i=y i−y^i ei=yi−y^iThe most common way to do linear regression is to select the line that minimizes the sum of squared residuals. To visualize the squared residuals, you can rerun the plot command and add the argument showSquares = TRUE.## Click two points to make a line.Note that the output from the plot_ss function provides you with the slope and intercept of your line as well as the sum of squares.Run the function several times. What was the smallest sum of squares that you got? How does it compare to your neighbors?Answer: The smallest sum of squares is 123721.9. It explains the dispersion from mean. The linear modelIt is rather cumbersome to try to get the correct least squares line, i.e. the line that minimizes the sum of squared residuals, through trial and error. Instead we can use the lm function in R to fit the linear model (a.k.a. regression line).The first argument in the function lm is a formula that takes the form y ~ x. Here it can be read that we want to make a linear model of runs as a function of at_bats. The second argument specifies that R should look in the mlb11 data frame to find the runs and at_bats variables.The output of lm is an object that contains all of the information we need about the linear model that was just fit. We can access this information using the summary function.Let’s consider this output piece by piece. First, the formula used to describe the model is shown at the top. After the formula you find the five-number summary of the residuals. The “Coefficients” table shown next is key; its first column displays the linear model’s y-intercept and the coefficient of at_bats. With this table, we can write down the least squares regression line for the linear model:y^=−2789.2429+0.6305∗atbats y^=−2789.2429+0.6305∗atbatsOne last piece of information we will discuss from the summary output is the MultipleR-squared, or more simply, R2R2. The R2R2value represents the proportion of variability in the response variable that is explained by the explanatory variable. For this model, 37.3% of the variability in runs is explained by at-bats.output, write the equation of the regression line. What does the slope tell us in thecontext of the relationship between success of a team and its home runs?Answer: homeruns has positive relationship with runs, which means 1 homeruns increase 1.835 times runs.Prediction and prediction errors Let’s create a scatterplot with the least squares line laid on top.The function abline plots a line based on its slope and intercept. Here, we used a shortcut by providing the model m1, which contains both parameter estimates. This line can be used to predict y y at any value of x x. When predictions are made for values of x x that are beyond the range of the observed data, it is referred to as extrapolation and is not usually recommended. However, predictions made within the range of the data are more reliable. They’re also used to compute the residuals.many runs would he or she predict for a team with 5,578 at-bats? Is this an overestimate or an underestimate, and by how much? In other words, what is the residual for thisprediction?Model diagnosticsTo assess whether the linear model is reliable, we need to check for (1) linearity, (2) nearly normal residuals, and (3) constant variability.Linearity: You already checked if the relationship between runs and at-bats is linear using a scatterplot. We should also verify this condition with a plot of the residuals vs. at-bats. Recall that any code following a # is intended to be a comment that helps understand the code but is ignored by R.6.Is there any apparent pattern in the residuals plot? What does this indicate about the linearity of the relationship between runs and at-bats?Answer: the residuals has normal linearity of the relationship between runs ans at-bats, which mean is 0.Nearly normal residuals: To check this condition, we can look at a histogramor a normal probability plot of the residuals.7.Based on the histogram and the normal probability plot, does the nearly normal residuals condition appear to be met?Answer: Yes.It’s nearly normal.Constant variability:1. Choose another traditional variable from mlb11 that you think might be a goodpredictor of runs. Produce a scatterplot of the two variables and fit a linear model. Ata glance, does there seem to be a linear relationship?Answer: Yes, the scatterplot shows they have a linear relationship..1.How does this relationship compare to the relationship between runs and at_bats?Use the R22 values from the two model summaries to compare. Does your variable seem to predict runs better than at_bats? How can you tell?1. Now that you can summarize the linear relationship between two variables, investigatethe relationships between runs and each of the other five traditional variables. Which variable best predicts runs? Support your conclusion using the graphical andnumerical methods we’ve discussed (for the sake of conciseness, only include output for the best variable, not all five).Answer: The new_obs is the best predicts runs since it has smallest Std. Error, which the points are on or very close to the line.1.Now examine the three newer variables. These are the statistics used by the author of Moneyball to predict a teams success. In general, are they more or less effective at predicting runs that the old variables? Explain using appropriate graphical andnumerical evidence. Of all ten variables we’ve analyzed, which seems to be the best predictor of runs? Using the limited (or not so limited) information you know about these baseball statistics, does your result make sense?Answer: ‘new_slug’ as 87.85% ,‘new_onbase’ as 77.85% ,and ‘new_obs’ as 68.84% are predicte better on ‘runs’ than old variables.1. Check the model diagnostics for the regression model with the variable you decidedwas the best predictor for runs.This is a product of OpenIntro that is released under a Creative Commons Attribution-ShareAlike 3.0 Unported. This lab was adapted for OpenIntro by Andrew Bray and Mine Çetinkaya-Rundel from a lab written by the faculty and TAs of UCLA Statistics.。
R语言实验报告范文

R语言实验报告范文实验报告:基于R语言的数据分析摘要:本实验基于R语言进行数据分析,主要从数据类型、数据预处理、数据可视化以及数据分析四个方面进行了详细的探索和实践。
实验结果表明,R语言作为一种强大的数据分析工具,在数据处理和可视化方面具有较高的效率和灵活性。
一、引言数据分析在现代科学研究和商业决策中扮演着重要角色。
随着大数据时代的到来,数据分析的方法和工具也得到了极大发展。
R语言作为一种开源的数据分析工具,被广泛应用于数据科学领域。
本实验旨在通过使用R语言进行数据分析,展示R语言在数据处理和可视化方面的应用能力。
二、材料与方法1.数据集:本实验使用了一个包含学生身高、体重、年龄和成绩的数据集。
2.R语言版本:R语言版本为3.6.1三、结果与讨论1.数据类型处理在数据分析中,需要对数据进行适当的处理和转换。
R语言提供了丰富的数据类型和操作函数。
在本实验中,我们使用了R语言中的函数将数据从字符型转换为数值型,并进行了缺失值处理。
同时,我们还进行了数据类型的检查和转换。
2.数据预处理数据预处理是数据分析中的重要一步。
在本实验中,我们使用R语言中的函数处理了异常值、重复值和离群值。
通过计算均值、中位数和四分位数,我们对数据进行了描述性统计,并进行了异常值和离群值的检测和处理。
3.数据可视化数据可视化是数据分析的重要手段之一、R语言提供了丰富的绘图函数和包,可以用于生成各种类型的图表。
在本实验中,我们使用了ggplot2包绘制了散点图、直方图和箱线图等图表。
这些图表直观地展示了数据的分布情况和特点。
4.数据分析数据分析是数据分析的核心环节。
在本实验中,我们使用R语言中的函数进行了相关性分析和回归分析。
通过计算相关系数和回归系数,我们探索了数据之间的关系,并对学生成绩进行了预测。
四、结论本实验通过使用R语言进行数据分析,展示了R语言在数据处理和可视化方面的强大能力。
通过将数据从字符型转换为数值型、处理异常值和离群值,我们获取了可靠的数据集。
【原创】R语言数据可视化分析报告(附代码数据)
Vis 3这个图形是用另一个数据集菱形建立的,也是内置在ggplot2包中的数据集。
library(ggthemes)
ggplot(diamonds)+geom_density(aes(price,fill=cut,color=cut),alpha=0.4,size=0.5)+labs(title='Diamond Price Density',x='Diamond Price (USD)',y='Density')+theme_economist()
library(ggplot2)
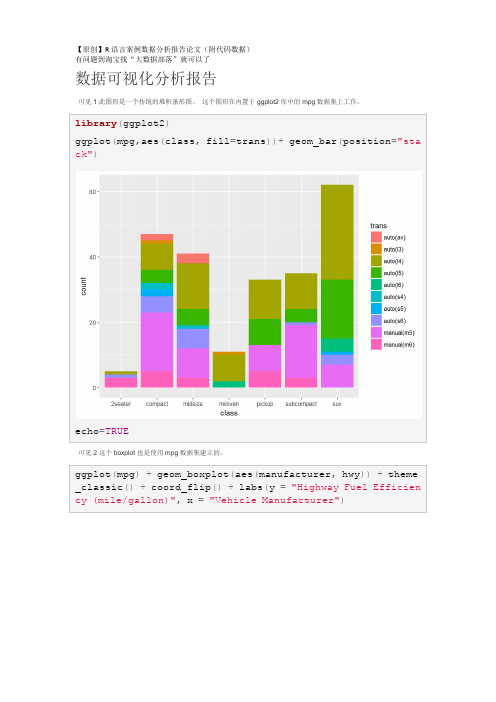
ggplot(mpg,aes(class,fill=trans))+geom_bar(position="stack")
echo=TRUE
可见2这个boxplot也是使用mpg数据集建立的。
ggplot(mpg)+geom_boxplot(aes(manufacturer,hwy))+theme_classic()+coord_flip()+labs(y="Highway Fuel Efficiency (mile/gallon)",x="Vehicle Manufacturer")
echo=TRUE
另外,我正在使用ggplot2软件包来将线性模型拟合到框架内的所有数据上。
ggplot(iris,aes(Sepal.Length,Petal.Length))+geom_point()+geom_smooth(method=lm)+theme_minimal()+theme(panel.grid.major=element_line(size=1),panel.grid.minor=element_line(size=0.7))+labs(title='relationship between Petal and Sepal Length',x='Iris Sepal Length',y='Iris Petal Length')
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
# R代码复制到相应后面(能附上运行得到的图不)# 数据读取和处理(为减少误差,估计时根据每个交易日的收盘价对日收益率进行自然对数处理,即收益率r=log(/)。
##读取数据golddata=read.csv("数据.csv")head(golddata)## 日期收盘价## 1 2008/1/2 5385.103## 2 2008/1/3 5422.034## 3 2008/1/4 5483.650## 4 2008/1/7 5556.593## 5 2008/1/8 5528.054## 6 2008/1/9 5613.758golddata=golddata[ ,2]head(golddata)## [1] 5385.103 5422.034 5483.650 5556.593 5528.054 5613.758Valuedata<-golddata ##Value dataValuedata=ts(Valuedata,start =c(2008,2),frequency=365)n<-length(Valuedata)### 为减少误差,在估计时,根据每个交易日的收盘价对日收益率进行自然对数处理,即将收益率根据以下公式进行计算:# 绘制收益率波动图Valuedata1 <-log(lag(Valuedata)) -log(Valuedata)# 即得到收盘价对数的一阶差分。
通过R软件,画出日对数收益率线形图(图1)plot.ts(Valuedata1)# 收益率的基本统计表# 通过计算收益率序列的均值,标准差,中位数最大值最小值等基本统计数据,得出下表summary(Valuedata1)## Min. 1st Qu. Median Mean 3rd Qu. Max.## -0.0915400 -0.0082590 0.0004899 -0.0002073 0.0090100 0.0893100library(asbio)#Functions for skewness and kurtosis.## Loading required package: tcltk#data description functiondatadesc =function(X) {result =list(0);#result list to returnmean =mean(X);#meanvar =var(X)#variance,pearsonskew =3*(mean(X)-median(X))/sd(X)#Pearson coefficient of skew nesskurt =kurt(X) #kurtosis,quantile1 =quantile(X,probs =0.25) # first quartile,med =median(X)# median,quantile3 =quantile(X,probs =0.25)# third quartile,max =max(X)# minimum andmin =min(X)# maximum.result =list(mean = mean,variance = var,skewness = pearsonskew,kurtosis = kurt,"first quartile" =quantile1,median = med,"third quartile" =quantile3,"maximum" =max,minimum = min)return(result)}datadesc(Valuedata1) ## $mean## [1] -0.0002073343 #### $variance## [1] 0.0003538641 #### $skewness## [1] -0.1111916#### $kurtosis## [1] 3.309377#### $`first quartile` ## 25%## -0.008258792#### $median## [1] 0.0004898845 #### $`third quartile` ## 25%## -0.008258792#### $maximum## [1] 0.08931021#### $minimum## [1] -0.09154204 ##直方图hist(Valuedata1)# 通过R软件得到指数日收益率直方图# 日收益率偏度为3.309377,其分布是右偏的,其峰度为 3.309377,远高于正态分布的峰度值3。
可知,收益率不服从正态分布,即利用所用基于正态分布统计方法对收益率序的检验均失效# 收益率序列的平稳性检验(ADF检验)library(tseries)# 平稳性检验最常用的方法为单位根方法,运用R软件,对日收益率进行单位根检验,检验结果如下print(adf.test(diff(Valuedata1),alternative ="stationary" , k=0))## Warning in adf.test(diff(Valuedata1), alternative = "stationary", k = 0):## p-value smaller than printed p-value#### Augmented Dickey-Fuller Test#### data: diff(Valuedata1)## Dickey-Fuller = -76.851, Lag order = 0, p-value = 0.01## alternative hypothesis: stationary# 从单位根检验结果可看出:单位根检验的p-value小于相应临界值0.05,从而拒绝原假设,表明收益率不存在单位根,是平稳序列,即服从I(0)过程# 通过R软件画出日收益率的自相关图和收益率的偏自相关图acf(Valuedata1)pacf(Valuedata1)#从自相关图和偏自相关图的结果来看,对数收益率的自相关函数值和偏自相关函数值很快落入置信区间,因此对数收益率稳定。
# ARCH效应检验# 1.滞后阶数的选折及均值方程的确定library(FinTS)## Loading required package: zoo#### Attaching package: 'zoo'## The following objects are masked from 'package:base':#### as.Date, as.Date.numeric# getSymbols("XPT/USD",src="oanda")# Valuedata1ones<-rep(1,length(Valuedata1))ols<-lm(Valuedata1~ones);ols#### Call:## lm(formula = Valuedata1 ~ ones)#### Coefficients:## (Intercept) ones## -0.0002073 NAresiduals<-ols$residualsArchTest(residuals,lags=1)#### ARCH LM-test; Null hypothesis: no ARCH effects#### data: residuals## Chi-squared = 66.824, df = 1, p-value = 3.331e-16ArchTest(residuals,lags=5)#### ARCH LM-test; Null hypothesis: no ARCH effects#### data: residuals## Chi-squared = 191.09, df = 5, p-value < 2.2e-16ArchTest(residuals,lags=12)#### ARCH LM-test; Null hypothesis: no ARCH effects#### data: residuals## Chi-squared = 242.63, df = 12, p-value < 2.2e-16# 根据Chi-squared最小原则可以看出滞后1期为最优,故选择滞后阶数为1,则公式可以写成# 2.残差序列自相关检验(日收益率的残差和残差平方自相关图)# 图6:日收益率差平方自相关图acf(residuals)acf(residuals^2)# 从序列残差图中可以看出,相关系数基本落入蓝色虚线(95%置信区间)内,# 即表明:日收益率残差不存在显著的自相关。
而从残差平方图中可看出,相关系数都没落入蓝色虚线(95%置信区间)内,即表明:日收益率的残差平方有显著的自相关,显示出ARCH效应# 3.对残差平方做线性图plot(residuals^2)plot.ts(residuals^2)# 从残差平方线性图可以看出,回归方程的残差。