轻松看懂机器学习十大常用算法知识分享
如何通俗的解释机器学习的10大算法?
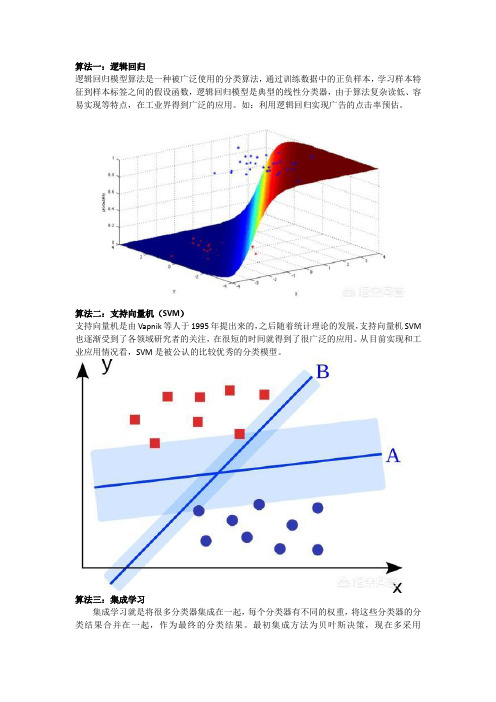
算法一:逻辑回归逻辑回归模型算法是一种被广泛使用的分类算法,通过训练数据中的正负样本,学习样本特征到样本标签之间的假设函数,逻辑回归模型是典型的线性分类器,由于算法复杂读低、容易实现等特点,在工业界得到广泛的应用。
如:利用逻辑回归实现广告的点击率预估。
算法二:支持向量机(SVM)支持向量机是由Vapnik等人于1995年提出来的,之后随着统计理论的发展,支持向量机SVM 也逐渐受到了各领域研究者的关注,在很短的时间就得到了很广泛的应用。
从目前实现和工业应用情况看,SVM是被公认的比较优秀的分类模型。
算法三:集成学习集成学习就是将很多分类器集成在一起,每个分类器有不同的权重,将这些分类器的分类结果合并在一起,作为最终的分类结果。
最初集成方法为贝叶斯决策,现在多采用error-correcting output coding, bagging, and boosting等方法进行集成。
算法四:聚类算法聚类算法是典型的无监督学习,其训练样本中只包含样本的特征,不包含样本的标签信息,在聚类算法中,利用样本的特征,将具有相似属性的样本划分到同一个类别中。
算法五:决策树决策树是人类在思考过程中最常用的逻辑结构,映射到机器学习问题上,在分类问题中,决策树算法通过样本中某一纬属性的值,将样本划分到不同的类别中。
是基于树形结构进行决策的一种分类算法。
算法六:朴素贝叶斯分类器朴素贝叶斯分类是一种十分简单的分类算法,一个含有贝叶斯思想的例子可以这样。
你在路上看到一个黑人且比较高,你十有八九猜他是从非洲来的。
因为在没有其他可用信息的前提下,一般来说大部分非洲人符合这种特征,所以你会选择最大概率是非洲人,这种思想就是贝叶斯思想。
算法七:主成分分析(PCA)主成分分析(PCA)是最常用的线性降维方法,它的目标是通过某种线性投影,将高维的数据映射到低维的空间中表示,并期望在所投影的维度上数据的方差最大,以此使用较少的数据维度,同时保留住较多的原数据点的特性。
轻松看懂机器学习十大常用算法知识分享

轻松看懂机器学习十大常用算法通过本篇文章可以对ML的常用算法有个常识性的认识,没有代码,没有复杂的理论推导,就是图解一下,知道这些算法是什么,它们是怎么应用的,例子主要是分类问题。
每个算法都看了好几个视频,挑出讲的最清晰明了有趣的,便于科普。
以后有时间再对单个算法做深入地解析。
今天的算法如下:1. 决策树2. 随机森林算法3. 逻辑回归4. SVM5. 朴素贝叶斯6. K最近邻算法7. K均值算法8. Adaboost 算法9. 神经网络10. 马尔可夫1. 决策树根据一些feature进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。
这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
Input age. gender, occupattion. ... Does ttie person like computer gamespr&dichon seme In each leaf 一—* +22. 随机森林视频在源数据中随机选取数据,组成几个子集Subwt 3$4jb«et 1Subsgt 2S矩阵是源数据,有1-N条数据,A B C是feature,最后一列C是类别feature A of the 1st sample c J A 1 /HI fc\ -I- I- ■ ■ * V /AN /BN IcN 由S 随机生成M 个子矩阵 Create random subsets这M 个子集得到M 个决策树 目最多,就将此类别作为最后的预测结果C} J 将新数据投入到这M 个树中,得到 M 个分类结果,计数看预测成哪一类的数tree M3. 逻辑回归视频当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
所以此时需要这样的形状的模型会比较好那么怎么得到这样的模型呢?这个模型需要满足两个条件大于等于0,小于等于1大于等于0的模型可以选择绝对值,平方值,这里用指数函数,一定大于0小于等于1用除法,分子是自己,分母是自身加上1,那一定是小于1的了通过源数据计算可以得到相应的系数了最后得到logistic的图形4. SVMsupport vector mach ine要将两类分开,想要得到一个超平面,最优的超平面是到两类的margin达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1 ,所以绿色的超平面比较好The best chok;e wiN be Efie r------------------------------- i将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类Vrr G class 1V T £ clciss 2小化分母,于是变成了一个优化问题The total margin is computed by举个栗子,三个点,找到最优的超平面,定义了 weight vector =(2, 3)- (1,1)点到面的距离根据图中的公式计算所以得到total margin 的表达式如下,目标是最大化这个 margin ,就需要最 Mnm<zing thus termwil maim 英1 the耗冲蛊bib 期net parallel PERPENDICUL?得到weight vector 为(a, 2a),将两个点代入方程,代入(2 , 3)另其值=1,代入(1, 1)另其值=-1,求解出a和截矩w0的值,进而得到超平面的表达式ExampleI 叩峠|H iiill忆川a求出来后,代入(a, 2a)得到的就是support vector a和w0 代入超平面的方程就是support vector machi ne原始问题是:给你一句话,它属于哪一类5.朴素贝叶斯视频举个在NLP 的应用给一段文字,返回情感分类,这段文字的态度是 positive ,还是negativeY ( I levs this navies it 1 s. but wi th B«tirical humor« Th* diais >freat and th-e AdvAhture fleedeB are 亠 It Md-nAqes CQ be whtMlcAl and wtil 1.日 laughing •£ the CMvtntiona of th* ftiry genre. I wouldrecomend it to just atout ■nyo“B ・ I*v« ・M 小 it eeveral t LJitefi a.nd I !m hu&pp 予to d« it again whvnvvflr I h«vt a friand who hasn 11 seen it yet , )=c 亠为了解决这个问题,可以只看其中的一些单词X 1>0¥4 林耳祁0耳畫*義專0鼻注 輛蜩中出 xxxxxxK utlrlioailxxxitxxxxxx MjCXXXJtMXXXX f ・t XXXXXMXHIO C X M X X M X XX X XMXXXXM fun MXXK KxrxxKxxxxxxxlALuicftl xxxx rQumtic XJCJCX 丄augiliiEkgXXXXX KM XJCXXJCXX KXXXXXX XXXXXXXXJCxx^x^xxxjcxxxxx r«eom*nd KX >:XXXXXKXKXXXXXJC3EXXXXXXJQ( XXX3EXXXKX XJCSQ^vral XXJUU JLXKXX XJtJLXXXX xxxxx liappyxxx XJC xxxx againXXXXXKXXXMXXXXXXXXXXXKXXXYXXXX XXXXXKXKXXXX XXXXX )=c © 这段文字,将仅由一些单词和它们的计数代表Y (great 右— 2 love -—* 2 recommend 1 laugh 1 happy 1 • • ■ •…通过bayes rules变成一个比较简单容易求得的问题•Assigning each word: P(word | c)•Assigning each sentence. P(s|c)=[I P(word|c)C\a^ pm1_love this fun film(JJ0.01忆岬th-i0 101.050010.1C.OS fun0.1film P 估 |pos)=0.0000005问题变成,这一类中这句话出现的概率是多少,当然,别忘了公式里的另外两个概率栗子:单词love在positive的情况下出现的概率是0.1,在negative 的情况下出现的概率是0.001Model negI o DOW 0 01P(s|posJ > P(s|neR)6. K最近邻视频k n earest n eighbours给一个新的数据时,离它最近的k个点中,哪个类别多,这个数据就属于哪一love this fun film栗子:要区分猫和狗,通过claws和sou nd两个feature来判断的话,圆形和三角形是已知分类的了,那么这个star代表的是哪一类呢Who Is this??SOUNDk = 3时,这三条线链接的点就是最近的三个点,那么圆形多一些,所以这个star就是属于猫SOUND7. K均值视频想要将一组数据,分为三类,粉色数值大,黄色数值小最开心先初始化,这里面选了最简单的3 , 2, 1作为各类的初始值剩下的数据里,每个都与三个初始值计算距离,然后归类到离它最近的初始值所在类别分好类后,计算每一类的平均值,作为新一轮的中心点(about) 9几轮之后,分组不再变化了,就可以停止了8. Adaboost视频adaboost 是bosti ng 的方法之一bosting就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。
总结机器学习小白必学的10种算法

总结机器学习小白必学的10种算法
在机器学习中,有一种叫做「没有免费的午餐」的定理。
简而言之,它指出没有任何一种算法对所有问题都有效,在监督学习(即预测建模)中尤其如此。
例如,你不能说神经网络总是比决策树好,反之亦然。
有很多因素在起作用,例如数据集的大小和结构。
因此,你应该针对具体问题尝试多种不同算法,并留出一个数据「测试集」来评估性能、选出优胜者。
当然,你尝试的算法必须适合你的问题,也就是选择正确的机器学习任务。
打个比方,如果你需要打扫房子,你可能会用吸尘器、扫帚或拖把,但是你不会拿出铲子开始挖土。
大原则
不过也有一个普遍原则,即所有监督机器学习算法预测建模的基础。
机器学习算法被描述为学习一个目标函数f,该函数将输入变量X 最好地映射到输出变量Y:Y = f(X)
这是一个普遍的学习任务,我们可以根据输入变量X 的新样本对Y 进行预测。
我们不知道函数 f 的样子或形式。
如果我们知道的话,我们将会直接使用它,不需要用机器学习算法从数据中学习。
最常见的机器学习算法是学习映射Y = f(X) 来预测新X 的Y。
这叫做预测建模或预测分析,我们的目标是尽可能作出最准确的预测。
对于想了解机器学习基础知识的新手,本文将概述数据科学家使用的top 10 机器学习算法。
1. 线性回归
线性回归可能是统计学和机器学习中最知名和最易理解的算法之一。
预测建模主要关注最小化模型误差或者尽可能作出最准确的预测,以可解释性为代价。
我们将借用、重用包括统计学在内的很多不同领域的算法,并将其用于这些目的。
机器学习初学者必须知道的十大算法_光环大数据培训

机器学习初学者必须知道的十大算法_光环大数据培训ML算法是可以从数据中学习并从中改进的算法,无需人工干预。
学习任务可能包括将输入映射到输出,在未标记的数据中学习隐藏的结构,或者“基于实例的学习”,其中通过将新实例与来自存储在存储器中的训练数据的实例进行比较来为新实例生成类标签。
1.ML算法的类型有三种ML算法:1.监督学习:监督学习可以理解为:使用标记的训练数据来学习从输入变量(X)到输出变量(Y)的映射函数。
Y=f(X)监督学习问题可以有两种类型:分类:预测输出变量处于类别形式的给定样本的结果。
例如男性和女性,病态和健康等标签。
回归:预测给定样本的输出变量的实值结果。
例子包括表示降雨量和人的身高的实值标签。
在这篇博客中介绍的前5个算法——线性回归,Logistic回归,CART,朴素贝叶斯,KNN都是监督学习。
人工智能领域的大牛吴恩达曾在他的公开课中提到,目前机器学习带来的经济价值全部来自监督学习。
2.无监督学习:无监督学习问题只有输入变量(X),但没有相应的输出变量。
它使用无标签的训练数据来模拟数据的基本结构。
无监督学习问题可以有两种类型:1.关联:发现数据集合中的相关数据共现的概率。
它广泛用于市场篮子分析。
例如:如果顾客购买面包,他有80%的可能购买鸡蛋。
2.群集:对样本进行分组,使得同一个群集内的对象彼此之间的关系比另一个群集中的对象更为相似。
3.维度降低:维度降低意味着减少数据集的变量数量,同时确保重要的信息仍然传达。
可以使用特征提取方法和特征选择方法来完成维度降低。
特征选择选择原始变量的一个子集。
特征提取执行从高维空间到低维空间的数据转换。
例如:PCA算法是一种特征提取方法。
Apriori,K-means,PCA是无监督学习的例子。
3.强化学习:强化学习是一种机器学习算法,它允许代理根据当前状态决定最佳的下一个动作。
强化算法通常通过反复试验来学习最佳行为。
它们通常用于机器人的训练,机器人可以通过在碰到障碍物后接收负面反馈来学习避免碰撞。
机器学习10大经典算法详解

机器学习10⼤经典算法详解本⽂为⼤家分享了机器学习10⼤经典算法,供⼤家参考,具体内容如下1、C4.5C4.5算法是机器学习算法中的⼀种分类决策树算法,其核⼼算法是ID3算法. C4.5算法继承了ID3算法的优点,并在以下⼏⽅⾯对ID3算法进⾏了改进:1)⽤信息增益率来选择属性,克服了⽤信息增益选择属性时偏向选择取值多的属性的不⾜;2)在树构造过程中进⾏剪枝;3)能够完成对连续属性的离散化处理;4)能够对不完整数据进⾏处理。
C4.5算法有如下优点:产⽣的分类规则易于理解,准确率较⾼。
其缺点是:在构造树的过程中,需要对数据集进⾏多次的顺序扫描和排序,因⽽导致算法的低效。
2、The k-means algorithm即K-Means算法k-means algorithm算法是⼀个聚类算法,把n的对象根据他们的属性分为k个分割,k < n。
它与处理混合正态分布的最⼤期望算法很相似,因为他们都试图找到数据中⾃然聚类的中⼼。
它假设对象属性来⾃于空间向量,并且⽬标是使各个群组内部的均⽅误差总和最⼩。
3、Support vector machines⽀持向量机⽀持向量机(Support Vector Machine),简称SV机(论⽂中⼀般简称SVM)。
它是⼀种监督式学习的⽅法,它⼴泛的应⽤于统计分类以及回归分析中。
⽀持向量机将向量映射到⼀个更⾼维的空间⾥,在这个空间⾥建⽴有⼀个最⼤间隔超平⾯。
在分开数据的超平⾯的两边建有两个互相平⾏的超平⾯。
分隔超平⾯使两个平⾏超平⾯的距离最⼤化。
假定平⾏超平⾯间的距离或差距越⼤,分类器的总误差越⼩。
⼀个极好的指南是C.J.C Burges的《模式识别⽀持向量机指南》。
van der Walt和Barnard 将⽀持向量机和其他分类器进⾏了⽐较。
4、The Apriori algorithmApriori算法是⼀种最有影响的挖掘布尔关联规则频繁项集的算法。
其核⼼是基于两阶段频集思想的递推算法。
机器学习的基础算法和数学知识

机器学习的基础算法和数学知识人工智能、机器学习是如今最为热门的话题之一。
如果你想要开始探索这个领域,那么了解机器学习中的基本算法和数学知识就至关重要。
一、线性回归线性回归是机器学习中用于预测连续输出的最基本算法。
它的目标是寻找一个最佳的拟合函数,使得预测值与实际值之间的误差最小化。
这个“最佳的拟合函数”是由一条直线或超平面表示的,称为“回归线”或“回归平面”。
常见的线性回归算法包括最小二乘法、梯度下降法等。
在数学上,线性回归的目标函数是R2损失函数,它表示预测值与实际值之间的残差平方和。
然后,我们求解这个目标函数的最小值,并使用得到的权重值和偏差值计算预测值。
二、逻辑回归逻辑回归用于分类问题,它的目标是预测一个样本属于哪个分类。
逻辑回归的输出是0和1之间的概率,它比较适用于二分类问题。
与线性回归相似,逻辑回归也是通过目标函数来确定模型的参数。
逻辑回归的目标函数是交叉熵损失函数,这个函数让预测值与实际值之间的误差最小。
逻辑回归还包括一个“sigmoid”函数,用于将连续数值映射到0到1的概率范围内。
三、支持向量机支持向量机是一种被广泛使用的分类算法。
与逻辑回归相比,它更具有优越的泛化能力和解决高维数据问题的能力。
支持向量机在解决二分类问题时,我们需要在支持向量之间找到一个超平面来进行分类。
支持向量是距离超平面最近的样本点, 它们是确定分类超平面的决策点。
支持向量机的目标是在正确分类的情况下,最大化两侧之间的间隔。
支持向量机的核函数往往是高斯核函数,它用于将低维数据转换到高维空间,以解决线性不可分问题。
四、决策树决策树是一种用于分类和回归问题的树形结构。
它常常被用来预测离散和连续性数值的问题。
决策树的优势在于易于理解和解释。
我们可以基于决策树的规则来解释模型的决策过程。
决策树算法有许多不同的实现方式,包括ID3、C4.5和CART。
五、数学知识机器学习需要掌握大量的数学知识,包括线性代数、概率统计、微积分等。
机器学习必知的10大算法

机器学习必知的10大算法机器学习算法可以分为三大类:监督学习、无监督学习和强化学习。
以下介绍 10 个关于监督学习和无监督学习的算法。
•监督学习可用于一个特定的数据集(训练集)具有某一属性(标签),但是其他数据没有标签或者需要预测标签的情况。
•无监督学习可用于给定的没有标签的数据集(数据不是预分配好的),目的就是要找出数据间的潜在关系。
•强化学习位于这两者之间,每次预测都有一定形式的反馈,但是没有精确的标签或者错误信息。
监督学习1. 决策树(Decision Trees)决策树是一个决策支持工具,它使用树形图或者决策模型以及可能性序列,包括偶然事件的结果、资源成本和效用。
下图是其基本原理:从业务决策的角度来看,决策树是人们必须了解的最少的是/否问题,这样才能评估大多数时候做出正确决策的概率。
作为一种方法,它允许你以结构化和系统化的方式来解决问题,从而得出合乎逻辑的结论。
2. 朴素贝叶斯分类 (Naive Bayesian classification)朴素贝叶斯分类器是一类简单的概率分类器,它基于贝叶斯定理和特征间的强大的(朴素的)独立假设。
图中是贝叶斯公式,其中P(A|B)是后验概率,P(B|A)是似然,P(A)是类先验概率,P(B)是预测先验概率。
一些应用例子:判断垃圾邮件对新闻的类别进行分类,比如科技、政治、运动判断文本表达的感情是积极的还是消极的人脸识别3. 最小二乘法(Ordinary Least Squares Regression)如果你懂统计学的话,你可能以前听说过线性回归。
最小二乘法是一种计算线性回归的方法。
你可以将线性回归看做通过一组点来拟合一条直线。
实现这个有很多种方法,“最小二乘法”就像这样:你可以画一条直线,然后对于每一个数据点,计算每个点到直线的垂直距离,然后把它们加起来,那么最后得到的拟合直线就是距离和尽可能小的直线。
线性指的是你用来拟合数据的模型,而最小二乘法指的是你最小化的误差度量。
机器学习常用算法解析

机器学习常用算法解析机器学习是计算机科学与人工智能的一个分支,其目的是让机器通过数据和算法的学习,实现特定任务。
在机器学习领域中,算法是非常重要的组成部分,各种算法模型不仅有着不同的特点,而且适用于不同的场景。
本文将介绍机器学习中常用的算法,包括线性回归、决策树、支持向量机、朴素贝叶斯、神经网络等。
一、线性回归算法线性回归算法是机器学习中最常用的算法之一,其用于预测因变量与一个或多个自变量之间的关系。
例如,在预测一个房子的售价中,我们可以将房屋面积作为自变量,而售价作为因变量。
根据已有数据进行模型训练,我们可以得到一个线性方程,即y = mx + b,其中y为因变量,x为自变量,m和b分别为斜率和截距。
通过这个方程,我们可以根据房屋面积预测出售价。
二、决策树算法决策树算法是一种基于树结构的分类与回归方法,其将数据集分成多个小组,并且根据特定规则进行分组。
每个节点代表一个属性,每个分支代表一个判断条件,通过比较分支上不同属性的取值,进行不同类别的分类。
决策树算法的优势在于模型可解释性高、易于理解和实现。
常用的决策树算法有ID3、C4.5和CART等。
三、支持向量机算法支持向量机算法是一种用于二分类和多分类的有监督学习方法。
其基本思想是寻找一个最优的超平面,将数据集分成不同的类别。
其中,超平面可以是一个线性的判定面,或者是一个非线性的判定面。
支持向量机算法在实际应用中广泛,其在文本分类、图像分类、手写数字识别等领域有着广泛应用。
四、朴素贝叶斯算法朴素贝叶斯算法是统计学习中的一种算法,其基于贝叶斯定理,假设各个特征之间是独立的。
在分类问题中,朴素贝叶斯算法可以计算出一个样本属于各个类别的概率,并将概率最大的类别作为分类结果。
在文本分类、垃圾邮件过滤、情感分析等领域有着广泛应用。
五、神经网络算法神经网络算法是机器学习中的一种模拟人类神经元之间相互连接和相互作用的算法模型。
它模拟生物神经元之间的相互作用,通过多层神经元的迭代训练,学习到输入与输出之间的关系。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
轻松看懂机器学习十大常用算法
通过本篇文章可以对ML的常用算法有个常识性的认识,没有代码,没有复杂的理论推导,就是图解一下,知道这些算法是什么,它们是怎么应用的,例子主要是分类问题。
每个算法都看了好几个视频,挑出讲的最清晰明了有趣的,便于科普。
以后有时间再对单个算法做深入地解析。
今天的算法如下:
1.决策树
2.随机森林算法
3.逻辑回归
4.SVM
5.朴素贝叶斯
6.K最近邻算法
7.K均值算法
8.Adaboost 算法
9.神经网络
10.马尔可夫
1. 决策树
根据一些 feature 进行分类,每个节点提一个问题,通过判断,将数据分为两类,再继续提问。
这些问题是根据已有数据学习出来的,再投入新数据的时候,就可以根据这棵树上的问题,将数据划分到合适的叶子上。
2. 随机森林
视频
在源数据中随机选取数据,组成几个子集
S 矩阵是源数据,有 1-N 条数据,A B C 是feature,最后一列C是类别
由 S 随机生成 M 个子矩阵
这 M 个子集得到 M 个决策树
将新数据投入到这 M 个树中,得到 M 个分类结果,计数看预测成哪一类的数目最多,就将此类别作为最后的预测结果
3. 逻辑回归
视频
当预测目标是概率这样的,值域需要满足大于等于0,小于等于1的,这个时候单纯的线性模型是做不到的,因为在定义域不在某个范围之内时,值域也超出了规定区间。
所以此时需要这样的形状的模型会比较好
那么怎么得到这样的模型呢?
这个模型需要满足两个条件大于等于0,小于等于1
大于等于0 的模型可以选择绝对值,平方值,这里用指数函数,一定大于0 小于等于1 用除法,分子是自己,分母是自身加上1,那一定是小于1的了
再做一下变形,就得到了 logistic regression 模型
通过源数据计算可以得到相应的系数了
最后得到 logistic 的图形
4. SVM
support vector machine
要将两类分开,想要得到一个超平面,最优的超平面是到两类的 margin 达到最大,margin就是超平面与离它最近一点的距离,如下图,Z2>Z1,所以绿色的超平面比较好
将这个超平面表示成一个线性方程,在线上方的一类,都大于等于1,另一类小于等于-1
点到面的距离根据图中的公式计算
所以得到 total margin 的表达式如下,目标是最大化这个 margin,就需要最小化分母,于是变成了一个优化问题
举个栗子,三个点,找到最优的超平面,定义了 weight vector=(2,3)-(1,1)
得到 weight vector 为(a,2a),将两个点代入方程,代入(2,3)另其值=1,代入(1,1)另其值=-1,求解出 a 和截矩 w0 的值,进而得到超平面的表达式。
a 求出来后,代入(a,2a)得到的就是 support vector
a 和 w0 代入超平面的方程就是 support vector machine
5. 朴素贝叶斯
视频
举个在 NLP 的应用
给一段文字,返回情感分类,这段文字的态度是positive,还是negative
为了解决这个问题,可以只看其中的一些单词
这段文字,将仅由一些单词和它们的计数代表
原始问题是:给你一句话,它属于哪一类
通过 bayes rules 变成一个比较简单容易求得的问题
问题变成,这一类中这句话出现的概率是多少,当然,别忘了公式里的另外两个概率
栗子:单词 love 在 positive 的情况下出现的概率是 0.1,在 negative 的情况下出现的概率是 0.001
6. K最近邻
视频
k nearest neighbours
给一个新的数据时,离它最近的 k 个点中,哪个类别多,这个数据就属于哪一类
栗子:要区分猫和狗,通过 claws 和 sound 两个feature来判断的话,圆形和三角形是已知分类的了,那么这个 star 代表的是哪一类呢
k=3时,这三条线链接的点就是最近的三个点,那么圆形多一些,所以这个star就是属于猫
7. K均值
视频
想要将一组数据,分为三类,粉色数值大,黄色数值小
最开心先初始化,这里面选了最简单的 3,2,1 作为各类的初始值
剩下的数据里,每个都与三个初始值计算距离,然后归类到离它最近的初始值所在类别
分好类后,计算每一类的平均值,作为新一轮的中心点
几轮之后,分组不再变化了,就可以停止了
8. Adaboost
视频
adaboost 是 bosting 的方法之一
bosting就是把若干个分类效果并不好的分类器综合起来考虑,会得到一个效果比较好的分类器。
下图,左右两个决策树,单个看是效果不怎么好的,但是把同样的数据投入进去,把两个结果加起来考虑,就会增加可信度
adaboost 的栗子,手写识别中,在画板上可以抓取到很多 features,例如始点的方向,始点和终点的距离等等
training 的时候,会得到每个 feature 的 weight,例如 2 和 3 的开头部分很像,这个 feature 对分类起到的作用很小,它的权重也就会较小
而这个 alpha 角就具有很强的识别性,这个 feature 的权重就会较大,最后的预测结果是综合考虑这些 feature 的结果
9. 神经网络
视频
Neural Networks 适合一个input可能落入至少两个类别里
NN 由若干层神经元,和它们之间的联系组成
第一层是 input 层,最后一层是 output 层
在 hidden 层和 output 层都有自己的 classifier
input 输入到网络中,被激活,计算的分数被传递到下一层,激活后面的神经层,最后output 层的节点上的分数代表属于各类的分数,下图例子得到分类结果为 class 1
同样的 input 被传输到不同的节点上,之所以会得到不同的结果是因为各自节点有不同的weights 和 bias
这也就是 forward propagation
10. 马尔可夫
视频
Markov Chains 由 state 和 transitions 组成
栗子,根据这一句话‘the quick brown fox jumps over the lazy dog’,要得到 markov chain
步骤,先给每一个单词设定成一个状态,然后计算状态间转换的概率
这是一句话计算出来的概率,当你用大量文本去做统计的时候,会得到更大的状态转移矩阵,例如 the 后面可以连接的单词,及相应的概率
生活中,键盘输入法的备选结果也是一样的原理,模型会更高级。