Python与机器学习-- 身高与体重数据分析(分类器)I
如何使用Python进行体育数据分析?

如何使用Python进行体育数据分析?在当今数字化的时代,数据已经成为各个领域决策的重要依据,体育领域也不例外。
通过对体育数据的分析,我们可以更好地了解运动员的表现、球队的战术、比赛的趋势等,从而为训练、比赛和管理提供有力的支持。
Python 作为一种功能强大且易于学习的编程语言,为体育数据分析提供了便捷的工具和方法。
接下来,让我们一起探索如何使用 Python 进行体育数据分析。
首先,我们需要获取体育数据。
数据的来源多种多样,比如体育赛事的官方网站、专业的数据提供商、社交媒体等。
获取到的数据可能是结构化的(如 CSV、Excel 表格),也可能是非结构化的(如网页文本、JSON 格式)。
对于结构化数据,我们可以使用 Python 的`pandas`库来读取和处理。
`pandas`提供了丰富的函数和方法,能够轻松地读取 CSV、Excel 等文件,并进行数据清洗、筛选、合并等操作。
例如,假设我们有一份包含运动员比赛数据的 CSV 文件,其中包括运动员的姓名、比赛场次、得分、篮板、助攻等信息。
我们可以使用以下代码读取数据:```pythonimport pandas as pddata = pdread_csv('athletes_datacsv')```读取数据后,可能会存在一些缺失值、异常值或重复的数据。
我们需要对数据进行清洗和预处理,以确保数据的质量。
可以使用`pandas`的`dropna()`方法删除包含缺失值的行或列,使用`describe()`方法查看数据的统计摘要,以便发现异常值。
在进行数据分析之前,我们还需要明确分析的目标。
是要比较不同运动员的表现?还是要分析球队在不同赛季的战绩变化?或者是研究比赛中的战术模式?根据不同的目标,选择合适的分析方法和指标。
如果要比较不同运动员的表现,我们可以计算一些常见的统计指标,如场均得分、场均篮板、投篮命中率等。
以下是计算场均得分的示例代码:```pythondata'场均得分' = data'得分' / data'比赛场次'```对于球队战绩的分析,可以绘制折线图来展示球队在不同赛季的胜负情况。
体重与身高的关系分析
进一步,我们可以检验样本是否在标准 体重范围内。设置信度为95%
标准体重模型用红线标注
1)ß的检验
H0 : ß=0.9 , H1 : ß≠0.9 ,若
b sb
0
t / 2
我们将拒绝H0。
t=
b sb
0
0.009 = =0.013477 4.84676/7.25760
0.025
t0.05/( ≈Z =1.96 2 75-2)
体体较之原模型剔除影响点后的模型有更高的决定系数拟合度更好06490510残差散点图
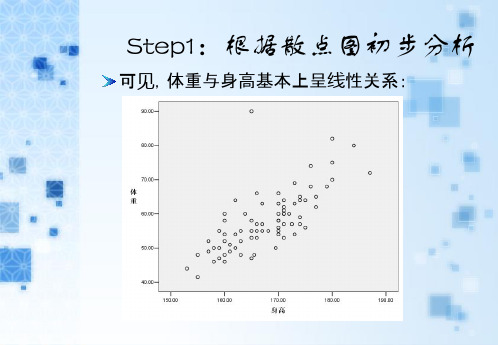
Step1:根据散点图初步分析
可见,体重与身高基本上呈线性关系:
Step2:相关系数分析
Correlations
身高 身高 Pearson Correlation Sig. (2-tailed) N 体重 Pearson Correlation Sig. (2-tailed) N 1 体重 .714* * .000 76 .714* * .000 76 76 76 1
Collinearity Statistics Toleranc e 1.000 VIF 1.000
(Constant) 身高
a. Depe nde nt Va ria ble: 体重
(男)体重=身高×0.609-41.306
标准体重有各种计算方法,但一般以 (身高cm-100)×0.9=标准体重 的公式来计算。 与我们的模型: 体重=身高×0.909-94.773 相比,差异不大
身高
.
a. Depe nden t Va riab le: 体重
ANOVAb
Model 1 Regression Residual Total Sum of Squares 3056.149 2932.150 5988.299 Mean df Square 1 3056.149 74 75 39.624 F 77.129 Sig. .000a
Python数据分析与机器学习入门

Python数据分析与机器学习入门一、引言数据分析与机器学习在当前的信息时代中越来越受到人们的关注。
作为一种高效、快速、准确的数据处理和分析工具,Python被越来越多的数据分析师和机器学习工程师所使用。
本文将对Python数据分析和机器学习做一个入门介绍。
二、Python数据分析1. 数据分析的基本概念数据分析是指对收集来的数据进行有效的处理和分析,以提取有用信息和知识的过程。
数据分析一般包括数据预处理、数据分析、数据可视化等环节。
2. Python数据分析的优势(1)Python是一种开源的脚本语言,语法简单易懂,易学易用;(2)Python有庞大的数据分析生态系统,如NumPy、Pandas等库,可以方便地对数据进行处理和分析;(3)Python有强大的图形库,如pyplot、matplotlib等,可以帮助用户进行数据可视化。
3. Python数据分析库(1)NumPy:Python科学计算的基础包,提供了高性能的数组和矩阵运算功能。
(2)Pandas:Python数据分析的核心库,提供了数据结构和数据分析工具,可以处理结构化数据、缺失数据等数据分析中的问题。
(3)Matplotlib:Python的2D绘图库,支持各种图表,如直方图、折线图、散点图等,方便进行数据可视化。
(4)Seaborn:Python的高级数据可视化库,基于Matplotlib,对数据进行统计可视化,简单易用。
三、Python机器学习1. 机器学习的基本概念机器学习是一种人工智能的应用,是指通过对大量数据进行学习和训练,让机器具有自我学习、自我优化、自我适应的能力,以达到提高机器性能和性能预测的目的。
2. Python机器学习的优势(1)Python机器学习工具库丰富,如Scikit-learn、TensorFlow等,支持多种算法和模型;(2)Python机器学习库易学易用、灵活性强,可以根据需要自己定义算法和模型。
Python机器学习经典案例

Python机器学习经典案例Python机器学习经典案例随着大数据时代的到来,机器学习逐渐成为了热门的话题。
在机器学习领域,Python是一种十分受欢迎的编程语言之一,得益于其开源性、灵活性等特点,Python在机器学习领域被广泛应用。
本文将介绍几个Python机器学习经典案例,以此为大家提供参考和学习。
案例1:KNN分类器在Iris数据集上的应用工欲善其事,必先利其器。
在开始介绍Python机器学习案例前,我们需要先了解一下几个Python机器学习工具:- Numpy:用于处理大型数组和矩阵、支持数学运算、逻辑运算等。
- Pandas:用于数据操作和数据分析,可以读取各种格式的数据文件。
- Matplotlib:用于制作图表,展示数据结果。
- Scikit-learn(sklearn):Python机器学习库之一,包含机器学习中的各种算法和工具函数。
接下来我们以Iris数据集为例,介绍如何使用Python机器学习库中的KNN分类器进行数据分类。
Iris数据集是一个经典的数据集,它包含了三种鸢尾花(Iris Setosa、Iris Versicolour、Iris Virginica)的花萼和花瓣长度和宽度共四个属性,共计150条数据。
我们需要利用这些数据,训练出一个KNN分类器,用于预测新鲜的未知鸢尾花属于哪一类。
以下是我们的代码实现:```pythonimport numpy as npimport pandas as pdfrom sklearn.model_selection import train_test_splitfrom sklearn.neighbors import KNeighborsClassifierfrom sklearn import datasets#加载鸢尾花数据集iris = datasets.load_iris()#将数据集和标签拆分开来x = iris.data[:, :4]y = iris.target#数据分割x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)#训练分类器kNN = KNeighborsClassifier(n_neighbors=3)kNN.fit(x_train, y_train)#预测并计算准确率y_pred = kNN.predict(x_test)acc = np.mean(y_pred == y_test) * 100print("Accuracy:{:.2f}%".format(acc))```通过运行以上代码我们可以得到一个精度为96.67%的结果,说明这个测试集的预测结果非常准确。
Bayes分类器原理分析以及实现

Bayes分类器原理分析以及实现编程环境:python 3.7jupyter notebook⽂章说明:这⾥只是贝叶斯分类器的原理进⾏分析以及实现,重点关注其中的数学原理和逻辑步骤,在测试等阶段直接调⽤了python机器学习的库。
基本步骤:输⼊类数,特征数,待分样本数输⼊训练样本数和训练样本集计算先验概率计算各类条件概率密度计算各类的后验概率若按最⼩错误率原则分类,则根据后验概率判定若按最⼩风险原则分类,则计算各样本属于各类时的风险并判定# 导⼊基本库import pandas as pdimport numpy as npimport mathimport matplotlib.pyplot as plt%matplotlib inline%config InlineBackend.figure_format = 'png'数据预处理colume_names = ['','gender','height','weight','size']df= pd.read_excel('data/gender.xlsx',index_col=0,names=colume_names)df.head(5)gender height weight size1⼥163.062.036.02⼥158.042.036.03男168.067.042.04男180.067.041.05男180.075.046.0df.shape(571, 4)这⾥可以看到数据有4个维度,分别为性别、⾝⾼、体重、鞋码,共有571条记录。
下⾯做⼀些简单的处理:# 性别数据转换df.replace('男',1,inplace=True)df.replace('⼥',2,inplace=True)df.head(5)gender height weight size12163.062.036.022158.042.036.031168.067.042.041180.067.041.0gender height weight size 51180.075.046.0# 男⽣⼥⽣数据分开male_df = df.loc[df['gender']==1]female_df = df.loc[df['gender']==2]female_df.head(5)gender height weight size 12163.062.036.022158.042.036.092160.045.036.0102163.048.037.0112161.045.036.01、单个特征——⾝⾼为了更加深⼊得理解贝叶斯分类器原理,我们从简单的⼀维特征开始。
Python 数据分析与机器学习

Python 数据分析与机器学习Python 是一种高级编程语言,它的易于使用和灵活性使它成为许多数据分析和机器学习的首选语言。
Python 有着丰富的库和工具,可以加速数据的处理和分析,此外,它也可以很容易地将分析结果可视化展示出来。
Python 可以处理几乎所有的数据类型和文件格式,可以在 Web、移动应用、桌面应用、服务器等各种平台上使用。
本文将介绍 Python 数据分析和机器学习的基础知识,重点在于讲解一些可以实际解决问题的案例。
数据分析入门Python 的数据分析库主要有 pandas、numpy、matplotlib 等。
pandas 提供了灵活的数据结构,可以支持数据的筛选、整合和计算。
numpy 提供了高效的数值计算库,包括向量、矩阵等的计算。
matplotlib 则可以将数据可视化,让数据更加生动、直观。
下面我们将简单介绍数据读取、清理、筛选和计算。
首先我们需要指定数据的文件路径,这里以csv格式文件为例:```pythonimport pandas as pddf = pd.read_csv('data.csv')```读取数据后,我们可以通过 DataFrame 提供的方法进行数据清理和筛选。
举个例子,我们要筛选某个城市的所有房子价格,可以使用以下代码:```pythondf_city = df[df['city'] == 'Beijing']df_price = df_city['price']```这里,我们首先通过 DataFrame 索引筛选出某个城市的所有房子数据,然后从中取出价格一列。
接下来我们计算一下该城市房屋的平均价格:```pythonaverage_price = df_price.mean()print(average_price)```这里的 mean 方法是 pandas 库中提供的计算平均值的方法。
用身高与体重数据进行性别分类的实验报告

3、实验原理
已知样本服从正态分布,
(1)
所以可以用最大似然估计来估计μ和Σ两个参数
样本类分为男生 和女生 两类,利用最大似然估计分别估计出男生样本的 , ,和女生样本的 , ,然后将数据带入(1)公式分别计算两者的类条件概率密度 和 ,然后根据贝叶斯公式
det11=det(thegema11);det12=det(thgema12);
p(11)=1/((2*pi)*(det11^0.5))*exp(-1/2*((a-u11)'/thegema11)*(a-u11));
p(12)=1/((2*pi)*(det12^0.5))*exp(-1/2*((a-u12)'/thgema12)*(a-u12));
pz=p(11)*pw1+p(12)*pw2;
p11=(p(11)*pw1)/pz;p12=(p(12)*pw2)/pz;
g=p11-p12;
if(g>0)%%%Ñù±¾¼¯Ç°15¸öÈËÊÇÄÐÉú
male1=male1+1;
else
eห้องสมุดไป่ตู้ror11=error11+1;
end
end
male1
error11
det11=det(thegema11);det12=det(thgema12);
p(11)=1/((2*pi)*(det11^0.5))*exp(-1/2*((a-u11)'/thegema11)*(a-u11));
p(12)=1/((2*pi)*(det12^0.5))*exp(-1/2*((a-u12)'/thgema12)*(a-u12));
用Python实现数据分析和机器学习

用Python实现数据分析和机器学习在本文中,我们将探讨Python在数据分析和机器学习方面的应用,并介绍如何在Python中使用这些库。
我们将学习如何处理数据和应用机器学习算法来解决一些实际问题。
一、Python在数据分析方面的应用Python可用于数据的获取、处理、转换、统计和可视化等方面的应用,例如获取网络数据、处理CSV、Excel和数据库等格式的数据文件。
1. 获取数据当我们从互联网上获取数据时,可以使用Python的requests和BeautifulSoup来爬取网页内容。
requests 库用于HTTP协议的网络数据获取,而 BeautifulSoup 库则用于HTML和XML文件内容的解析。
requests 和 BeautifulSoup的优秀组合可以帮助我们获取互联网上的数据并将其转换为Python中的数据对象。
2. 数据处理在Python中, Pandas 库是一个非常强大的数据处理库。
Pandas 可以将Excel、CSV和数据库等各种数据格式转换为Python的数据帧(DataFrames),从而方便地进行数据处理和操作。
Pandas的数据帧具有类似于Excel中的工作表的结构。
数据帧有多种功能,例如数据筛选,数据排序以及数据汇总等等。
3. 数据可视化Matplotlib 是Python的一个重要的数据可视化工具。
这个库可以用来生成各种图表和图形,例如散点图、折线图、柱状图等等。
Matplotlib 对于数据分析师或机器学习人员来说非常有用,因为它可以让你更直观的了解所获得的数据。
二、Python在机器学习方面的应用Python在机器学习方面的应用同样是非常广泛的,特别是Scikit-learn 和TensorFlow。
Scikit-learn是一个开源的机器学习库,提供了包括分类、回归、聚类、降维等多种算法。
TensorFlow是Google开发的深度学习库,是目前最受欢迎的深度学习框架之一。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
逻辑回归:三、数据可视化:分类
Car 情报局
xcord11 = []; xcord12 = []; ycord1 = []; xcord21 = []; xcord22 = []; ycord2 = []; n = len(Y)
for i in range(n): if int(Y.values[i]) == 1: xcord11.append(X.values[i,0]); xcord12.append(X.values[i,1]); ycord1.append(Y.values[i]); else: xcord21.append(X.values[i,0]); xcord22.append(X.values[i,1]); ycord2.append(Y.values[i]);
逻辑回归:三、数据可视化:观察
import matplotlib.pyplot as plt X = df[['Height', 'Weight']] Y = df[['Gender']]
Car 情报局
plt.figure() plt.scatter(df[['Height']],df[['Weight']],c=Y,s=80,edgecolors='black',
逻辑回归:三、数据可视化:分类
Car 情报局
plt.figure()
plt.scatter(xcord11, xcord12, c='red', s=80, edgecolors='black', linewidths=1, marker='s')
plt.scatter(xcord21, xcord22, c='green', s=80, edgecolors='black', linewidths=1) plt.title(u'性别判定(实际值)') plt.xlabel(u'身高') plt.ylabel(u'体重')
Car 情报局
二、有监督学习
Car 情报局
回归(Regression) y 是连续值(实数或 连续整数),f (x) 的输出也是连续值。这
种类型的问题就是回归问题。对于所有已知
或未知的 (x, y),使得 f (x,θ ) 和 y 尽可能
地一致。损失函数通常定义为平方误差。
分类(Classification) y 是离散的类别标
Car 情报局
✓ Y.values.ravel():将y的值转化为1维的向量 ✓ output.reshape(len(output),1):reshape()是数组对象中的方法,用于改变数组的
形状。
逻辑回归:四、预测结果的可视化
Car 情报局
plt.scatter(df[[‘Height’]], df[[‘Weight’]], c=output, s=80, edgecolors=‘black’, linewidths=1, cmap=plt.cm.Paired) ✓ plt.cm中cm全称表示colormap,颜色映射地图 ✓ paired表示两个相近色彩输出
身高与体重数据分析(分类器)
知识回顾:可视化
常用图形展示
柱状图 直方图 箱形图 散点图 气泡图 饼图 折线图 热力图
Car 情报局
主要教学内容
分类
有监督学习 分类 逻辑回归 朴素贝叶斯
项目:使用身高、体重数据进行性别分类
数据读取 数据预处理 数据分类(逻辑回归、朴素贝叶斯) 数据可视化
step_size = 0.2 x_values, y_values = np.meshgrid(np.arange(x_min,x_max,step_size),
np.arange(y_min,y_max,step_size))
逻辑回归:四、可视化进阶
Car 情报局
mesh_output = classifier.predict(np.c_[x_values.ravel(),y_values.ravel()]) mesh_output = mesh_output.reshape(x_values.shape) #np.c_是按列连接两个矩阵,就是把两矩阵左右相加,要求行数相等 plt.pcolormesh(x_values,y_values,mesh_output,cmap=plt.cm.gray)
Car 情报局
上机时间:20min
Car 情报局
• 模型应用 • 数据可视化 • 实验报告5-6题 • 思考:不同方法的区别与
优劣分析
课堂小结
重点: • 机器学习、有监督学习、分类 • 逻辑回归 • 朴素贝叶斯 难点: • 逻辑回归的理解与参数选择、数
据可视化 思考: • 模型评估:模型的优劣分析 作业:实验报告
朴素贝叶斯:建立模型
from sklearn.naive_bayes 立模型
classifier = MultinomialNB()
# 拟合
classifier.fit(X, Y.values.ravel())
# 给出待预测的一个特征
output = classifier.predict(X) output = output.reshape(len(output),1)
Car 情报局
项目应用:身高与体重(性别分类)
Car 情报局
项目应用:逻辑回归
Car 情报局
逻辑回归
原理:找到一条线,但不是去拟合每个数据点,而是把不同类别的样本区分开来 优点:速度快、简单、可解释性好(直接看到各个特征的权重)、易扩展(能容 易地更新模型吸收新的数据)、如果想要一个概率框架,动态调整分类阀值。 缺点:特征处理复杂、需要归一化和较多的特征工程。 应用:两分类问题,常用于数据挖掘,疾病自动诊断,经济预测等领域
Car 情报局
Car 情报局
THANK YOU!
plt.show()
上机时间:15min
• 数据可视化 • 数据可视化进阶 • 实验报告2-3题
Car 情报局
逻辑回归:三、模型训练
from sklearn import linear_model # 建立回归模型 classifier = linear_model.LogisticRegression(solver='liblinear', C=1) # 拟合 classifier.fit(X, Y.values.ravel()) # 给出待预测的一个特征 output = classifier.predict(X) output = output.reshape(len(output),1)
Car 情报局
一、机器学习的方法
测试数据集 x_test
Car 情报局
x_train 训练数据集
y_train
机器学习 fit( ) 算法
模型
predict( ) 输出结果 y_pred
评估
y_test
报告
二、有监督学习
在监督学习中,每一个例子都是一对由一个输入对 象(通常是一个向量)和一个期望的输出值(也被 称为监督信号)。
朴素贝叶斯:
Car 情报局
当A特征发生 时,特征B某个 值出现的概率
已经B特征值的前提下,某个A特征值 出现的概率
P(A|B)P(B)
P(B|A)
=特征A中某个 P (A) 特征值所占的
比例
特征B中某个特 征值所占的比例
贝叶斯分类法是基于贝叶斯定理的统计学分类方法。它通过预测一个给定的元组属于一个特定类的概率,来进行分 类。朴素贝叶斯分类法假定一个属性值在给定类的影响独立于其他属性的 —— 类条件独立性。 •优点:所需估计的参数少,对于缺失数据不敏感。 •缺点:假设属性之间相互独立,这往往并不成立。(喜欢吃番茄、鸡蛋,却不喜欢吃番茄炒蛋)、需要知道先验概 率、分类决策错误率高。 •应用:新闻分类、病人分类等等
逻辑回归:四、可视化进阶
Car 情报局
x_min, x_max = df[['Height']].values.min() - 1.0, df[['Height']].values.max() + 1.0
y_min, y_max = df[['Weight']].values.min() - 1.0, df[['Weight']].values.max() + 1.0
上机时间:20min
Car 情报局
• 数据分析与预测 • 数据可视化 • 可视化进阶 • 实验报告4题
朴素贝叶斯:
在统计资料的基础上,依据某些特征,计算各个类别的概率,从而实现分类。
Car 情报局
某个医院早上收了六个门诊病人 现在又来了第七个病人,是一个打喷嚏的建筑工人。请问他患上 感冒的概率有多大?
记(符号),就是分类问题。损失函数有一 般用 0-1 损失函数或负对数似然函数等。 在分类问题中,通过学习得到的决策函数 f (x,θ ) 也叫分类器。
三、分类(Classification)
✓ Logistic Regression: 逻辑回归 ✓ Bayes: 朴素贝叶斯 ✓ Decision Tree: 决策树 ✓ SVM: 支持向量机 ✓ KNN:K近邻 ✓ 神经网络 ✓ 深度学习
solver:优化算法选择,可选:newton-cg,lbfgs,liblinear,sag,saga。默认为liblinear,决定了对逻辑回归损 失函数的优化方法: ✓ liblinear:使用了开源的liblinear库实现,内部使用了坐标轴下降法来迭代优化损失函数。 ✓ lbfgs:拟牛顿法的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。 ✓ newton-cg:也是牛顿法家族的一种,利用损失函数二阶导数矩阵即海森矩阵来迭代优化损失函数。 ✓ sag:即随机平均梯度下降,是梯度下降法的变种,和普通梯度下降法的区别是每次迭代仅仅用一部分的样本