语法分析器(含完整源码)教学文稿
语法分析器

实验一:编写C语言的词法分析器输入文件名:*.c 输出文件名:*.tok【实验内容】实现C语言的词法分析程序。
从输入的C语言源程序中,识别出各个具有独立意义的单词,以二元组(单词的类别,单词的值)的形式输出。
保留字、运算符和分隔符以一字一类的方式编码,所有的标识符作为一类,所有的常量作为一类。
【实验目的】明确词法分析的任务,了解词法分析器的设计与实现。
【实验要求】(1)程序(2)实验报告:C语言的词法正规表达式,状态转换图。
【实验说明】上机两次4小时,第7周检查。
【输入样例】main(){int a,b;a = 10;b = a + 20;}【输出样例】(id,main)((,_)(),_)({,_}(int,_)(id,a)(,,_)(id,b)(;,_)(id,a)(=,_)(const,10)(;,_)(id,b)(=,_)(id,a)(+,_)(const,20)(;,_)(),_)[/watermark]#include <stdio.h>#include <stdlib.h>#include <string.h>#include <ctype.h>#define LEN sizeof(struct Node)#define NULL 0struct Node{char data;struct Node *next; /* 定义动态链表数据结构 */};void output(struct Node*);/*扫描输出函数*/void scaner(); /*词法分析*/void getbc();void getch();void concat();int letter(char ch);int degit(char ch);int reserve();void retract();void back(char *a,char *b);struct Node *head,*p;char ch; /*全局变量*/char *key[]={"float","int","char","if","else","for","while"}; /*关键字表*/ char token[20]; /*字符数组,存放构成单词的符号串*/int main(void){head=(struct Node *)malloc(LEN); /*分配头节点存储空间*/if(!head){printf("error");exit(1);}head->next=NULL;head->data=' ';p=head;printf("When input a \'$\' at the beigining of an line,this programe will be over.\n"); printf("And the programe will output the codes you inputed just now.\n");printf("Please input your codes:\n");while(1){int i=0;char temp[256];/*每行长度不超过256个字符*/gets(temp); /*输入源程序,以行为单位*/if(temp[0]=='$') break;/*当输入的第一个字符为$时表示输入源代码结束*/p->next=(struct Node *)malloc(LEN);if(!(head->next)){printf("error");exit(1);}p=p->next;while(temp[i]!='\0' && i<256) /*将输入的代码以行为单位存入缓冲区*/{p->data=temp[i];p->next=(struct Node *)malloc(LEN);if(!(p->next)){printf("error");exit(1);}p=p->next;i++;}p->data='\n';p->next=NULL; /*尾结点*/}output(head); /*扫描缓冲区,输出结果*/p=head->next;while(p->next!=NULL)scaner(); /*词法分析*/system("pause");return 0;}void output(struct Node *head) /*扫描缓冲区函数*/{if(!head) {printf("error");exit(1);}p=head->next;while(p->next!=NULL){printf("%c",p->data);p=p->next;}printf("\n");}void getbc() /*若ch中是空白字符,则不停调用getch()直到读入的不是空白字符为止*/ {while (ch==' ')getch();}void getch() /*从缓冲区读入一字符*/{ch=p->data;p=p->next;}void concat() /*将ch中的字符连接到token的后面*/{unsigned int i;i=strlen(token);token[i]=ch;token[i+1]='\0';}int letter(char ch) /*判断ch中的是否是字母*/{return isalpha((int)ch);}int digit(char ch) /*判断ch中的是否是数字*/{return isdigit((int)ch);}int reserve() /*判断token中的字符串是否是关键字或是标识符*/{int k;for(k=0;k<6;k++){if(strcmp(key[k],token)==0)return (k+1);}return 0;}void retract() /*指针回退一个字符*/{struct Node *Q;Q=head->next;while(Q->next!=p)Q=Q->next;p=Q;}void back(char *a,char *b) /*返回函数,输出序列*/ {printf("(%s,%s)\n",a,b);}void scaner() /*词法分析函数*/{int c;token[0]=NULL; /*将token清空*/getch();getbc(); /*读入一个单词*/if(letter(ch)) /*处理字符的情况*/{while(letter(ch)||digit(ch)){concat();getch();}retract();c=reserve();if(c!=0)back(token,"_");elseback("id",token);}else if(digit(ch)) /*处理数字的情况*/{while(digit(ch)){concat();getch();}retract();printf("(num,%d)\n",atoi(token));}elseswitch(ch) /*处理特殊符号的情况*/{case'+': back("+","_");break;case'-': back("-","_");break;case'*': back("*","_");break;case'/': back("/","_");break;case'<': getch();if(ch=='=')back("<=","_");retract();back("<","_");break;case'>': getch();if(ch=='=') back(">=","_"); retract();back(">","_");break;case';': back(";","_");break;case'{': back("{","_");break;case'}': back("}","_");break;case'(': back("(","_");break;case')': back(")","_");break;case'=': back("=","_");break;case',': back(",","_");break;case'\n': break;default: printf("error");break;}}照着课件上敲的p.s. 老师的【输出样例】最后一个错了 :)这个是上传的 txt 格式文件 [点击查看][/watermark]另外一个此法分析器#include "stdafx.h"#include <stdio.h>#include <stdlib.h>#include <string.h>#include <ctype.h>#include <malloc.h>#include <ctype.h>#include <conio.h>#define NULL 0FILE *fp;char ch;char *key视频教程'>word[8]={"do","begin","else","end","if","then","var","while"}; char *operatornum[4]={"+","-","*","/"};char *comparison[6]={"<","<=","=",">",">=","<>"};char *interpunction[6]={",",";",":=",".","(",")"};//////////////////////////////////////////////////////////////////////////////////////////bool search(char searchstr[],int wordtype){int i;switch (wordtype){case 1:for(i=0;i<=7;i++){if(strcmp(keyword[i],searchstr)==0)return(true);}case 2:{for(i=0;i<=3;i++){if(strcmp(operatornum[i],searchstr)==0)return(true);}break;}case 3: for(i=0;i<=5;i++){if(strcmp(comparison[i],searchstr)==0)return(true);}case 4: for(i=0;i<=5;i++){if(strcmp(interpunction[i],searchstr)==0)return(true);}}return(false);}///////////////////////////////////////////////////////////////////////////////////////////char letterprocess (char ch)//字母处理函数{int i=-1;char letter[20];while (isalnum(ch)!=0){letter[++i]=ch;ch=fgetc(fp);};letter[i+1]='\0';if (search(letter,1)){printf("<%s,->\n",letter);//strcat(letter,"\n");//fputs('<' letter '>\n',outp);}else{printf("<indentifier,%s>\n",letter);//strcat(letter,"\n");//fputs(letter,outp);}return(ch);}///////////////////////////////////////////////////////////////////////////////////////////char numberprocess(char ch)//数字处理程序{int i=-1;char num[20];while (isdigit(ch)!=0){num[++i]=ch;ch=fgetc(fp);}if(isalpha(ch)!=0){while(isspace(ch)==0){num[++i]=ch;ch=fgetc(fp);}num[i+1]='\0';printf("错误!非法标识符:%s\n",num);goto u;}num[i+1]='\0';printf("<num,%s>\n",num);//strcat(num,"\n");//fputs(num,outp);u: return(ch);}//////////////////////////////////////////////////////////////////////////////////////////////char otherprocess(char ch){int i=-1;char other[20];if (isspace(ch)!=0){ch=fgetc(fp);goto u;}while ((isspace(ch)==0)&&(isalnum(ch)==0)){other[++i]=ch;ch=fgetc(fp);}other[i+1]='\0';if (search(other,2))printf("<relop,%s>\n",other);elseif (search(other,3))printf("<%s,->\n",other);elseif (search(other,4))printf("<%s,->\n",other);elseprintf("错误!非法字符:%s\n",other);u: return (ch);}/////////////////////////////////////////////////////////////////////////////////////////////void main (){char str,c;printf("**********************************词法分析器************************************\n");//outp=fopen("二元式表.txt","w");if ((fp=fopen("源程序.txt","r"))==NULL)printf("源程序无法打开!\n");else{str =fgetc(fp);while (str!=EOF){if (isalpha(str)!=0)str=letterprocess(str);else{if (isdigit(str)!=0)str=numberprocess(str);elsestr=otherprocess(str);}};printf("词法分析结束,谢谢使用!\n");printf("点任意键退出!\n");}c=getch();}本文章来自 21视频教程网词法分析器_C语言程序设计教程原文链接:/html/61641.shtml。
编译原理语法分析报告+代码

编译原理语法分析报告+代码1000字一、语法分析语法分析是编译器的重要部分,它的作用是对源程序进行分析和判断,判断源程序是否符合语法规则,把源程序划分为一个个语法单元,并建立语法树,这里介绍一种常见的语法分析方法——LR(1)分析。
1.LR(1)分析LR(1)分析是一种自底向上的语法分析方法,它是以LR语法分析机为基础的。
LR(1)分析是在扫描整个输入的基础上作出决策的,名字中的1表示当扫描到一个符号时,它会读下一个符号来做决策并且仅仅读一个符号。
2.LR(1)分析器构建构建LR(1)分析器首先需要构建LR(1)自动机,然后对其进行分析,得到一个分析表。
分析表有两个函数:action和goto。
分析表的行是状态,列是终结符或非终结符,如果分析表的项中既包含action又包含goto,那么这个表就是一个LR(1)分析表。
3.核心算法核心算法就是通过分析表进行分析,具体步骤如下:(1)创建一个栈,将一个状态push入栈。
(2)循环扫描输入,每扫描一个符号就执行一个操作,直到栈为空。
(3)在栈的顶部状态上查找action表。
如果输入符号是一个终结符,那么应该执行的动作是shift。
如果输入符号是一个结束符号,那么说明输入已经结束,执行acc(accept)操作。
(4)如果找到了一个shift,就将其作为下一个状态push入栈,并将上次扫描到的符号作为标记push入栈。
(5)否则,在栈的顶部状态上查找goto表。
在状态表中查找新状态,并将其push入栈。
常见的错误处理:(1)在action表中找不到适当的输入:语法错误,报错。
(2)在goto表中找不到适当的输入:一个状态不能在当前符号的词法单元下产生任何变化。
4.算法实现这里提供一个简单的C++代码实现。
1)自动机的结构体声明:struct Automaton {int status; // 状态编号char symbol; // 符号int go_to; // 跳转状态int move_type; // 移动类型Automaton() : status(-1), symbol(0), go_to(-1),move_type(-1) {}};2)分析表结构体声明:struct AnalyzeTable {static const int ROWS = 100; // 分析表行数static const int COLS = 100; // 分析表列数Automaton analyze_table[ROWS][COLS]; // 分析表};3)LR(1)分析器的实现:class LR1Parser {public:LR1Parser(const std::string& grammar_file); // 构造函数~LR1Parser();void parse(const std::string& input_file); // 解析函数private:std::map<char, std::vector<std::string>> productions_; // 产生式std::map<char, std::set<char>> first_; // First集合std::map<char, std::set<char>> follow_; // Follow集合AnalyzeTable analyze_table_; // 分析表};4)分析表构建函数实现:void LR1Parser::build_analyze_table() {// 对于每个项A -> α.Bβ, a,把它添加到一个集合中。
编译原理LL(1)语法分析器java版完整源代码

编译原理LL(1)语法分析器java版完整源代码public class Accept2 {public static StringBuffer stack=new StringBuffer("#E");public static StringBuffer stack2=new StringBuffer("i+i*#");public static void main(String arts[]){//stack2.deleteCharAt(0);System.out.print(accept(stack,stack2));}public static boolean accept(StringBuffer stack,StringBuffer stack2){//判断识别与否boolean result=true;outer:while (true) {System.out.format("%-9s",stack+"");System.out.format("%9s",stack2+"\n");char c1 = stack.charAt(stack.length() - 1);char c2 = stack2.charAt(0);if(c1=='#'&&c2=='#')return true;switch (c1) {case'E':if(!E(c2)) {result=false;break outer;}break;case'P': //P代表E’if(!P(c2)) {result=false;break outer;}break;case'T':if(!T(c2)) {result=false;break outer;}break;case'Q': //Q代表T’if(!Q(c2)) {result=false;break outer;}break;case'F':if(!F(c2)) {result=false;break outer;}break;default: {//终结符的时候if(c2==c1){//System.out.println();}else{return false;}}}if(result=false)break outer;}return result;}public static boolean E(char c) {//语法分析⼦程序 E boolean result=true;if(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("PT");}else if(c=='('){stack.deleteCharAt(stack.length()-1);stack.append("PT");else{System.err.println("E 推导时错误!不能匹配!"); result=false;}return result;}public static boolean P(char c){//语法分析⼦程序 P boolean result=true;if(c=='+') {stack.deleteCharAt(stack.length()-1);stack.append("PT+");}else if(c==')') {//stack.append("");System.out.println("P->/");}else if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");System.out.println("P->/");else{System.err.println("P 推导时错误!不能匹配!");result=false;}return result;}public static boolean T(char c) {//语法分析⼦程序 Tboolean result=true;if(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("QF");}else if(c=='(') {stack.deleteCharAt(stack.length()-1);stack.append("QF");}else{result=false;System.err.println("T 推导时错误!不能匹配!");}return result;public static boolean Q(char c){//语法分析⼦程序 Q boolean result=true; if(c=='+') {stack.deleteCharAt(stack.length()-1);//stack.append("");System.out.println("Q->/");}stack.deleteCharAt(stack.length()-1);stack.append("QF*");}else if(c==')') {stack.deleteCharAt(stack.length()-1);//stack.append("");System.out.println("Q->/");}else if(c=='#') {stack.deleteCharAt(stack.length()-1);//stack.append("");System.out.println("Q->/");}else{result=false;System.err.println("Q 推导时错误!不能匹配!"); }return result;}public static boolean F(char c) {//语法分析⼦程序 F boolean result=true;if(c=='i') {stack.deleteCharAt(stack.length()-1);stack.append("i");}else if(c=='(') {stack.deleteCharAt(stack.length()-1);stack.append(")E(");}else{result=false;System.err.println("F 推导时错误!不能匹配!"); }return result;/* public static StringBuffer changeOrder(String s){//左右交换顺序StringBuffer sb=new StringBuffer();for(int i=0;isb.append(s.charAt(s.length()-1-i));}return sb;}*/}#E i+i*i+i##PT i+i*i+i##PQF i+i*i+i##PQi i+i*i+i##PQ +i*i+i#Q->/#P +i*i+i##PT+ +i*i+i##PT i*i+i##PQF i*i+i##PQi i*i+i##PQ *i+i##PQF* *i+i##PQF i+i##PQi i+i##PQ +i#Q->/#P +i##PT+ +i##PT i##PQF i##PQi i##PQ #Q->/#P #P->/True#E i+i*##PT i+i*##PQF i+i*##PQi i+i*##PQ +i*#Q->/#P +i*##PT+ +i*##PT i*##PQF i*##PQi i*##PQ *##PQF* *##PQF #falseF 推导时错误!不能匹配!。
编译原理_语法分析器

编译原理实验报告语法分析器一.实验目的及内容实验目的:编制一个语法分析程序,实现对词法分析程序所提供的单词序列进行语法检查和结构分析。
实验内容:在上机(一)词法分析的基础上,采用递归子程序法或其他适合的语法分析方法,实现其语法分析程序。
要求编译后能检查出语法错误。
已知待分析的C语言子集的语法,用EBNF表示如下:<程序>→main()<语句块><语句块> →‘{’<语句串>‘}’<语句串> → <语句> {; <语句> };<语句> → <赋值语句> |<条件语句>|<循环语句><赋值语句>→ID=<表达式><条件语句>→if‘(‘条件’)’<语句块><循环语句>→while’(‘<条件>’)‘<语句块><条件> → <表达式><关系运算符> <表达式><表达式> →<项>{+<项>|-<项>}<项> → <因子> {* <因子> |/ <因子>}<因子> →ID|NUM| ‘(’<表达式>‘)’<关系运算符> →<|<=|>|>=|==|!=二、实验原理及基本技术路线图(方框原理图或程序流程图)三、所用仪器、材料(设备名称、型号、规格等或使用软件)1台PC以及VISUAL C++6.0软件四、实验方法、步骤(或:程序代码或操作过程)#include <iostream>#include <string>using namespace std;char prog[80],token[8];char ch;int syn,p,m,n,sum,k=0;char *key[6]={"main","int","char","if","else","while"};void scaner();void lrparser();void yucu();void statement();void expression();void term();void factor();void main(){p=0;cout<<"语法分析"<<endl;cout<<"请输入字符串,以“@”结尾:"<<endl;do {ch = getchar(); prog[p++]=ch;}while(ch!='@');p=0;scaner();lrparser();}void scaner(){sum=m=0;for(n=0;n<8;n++) token[n]=NULL;ch=prog[p++];while(ch==' ') ch=prog[p++];if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')){while((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||(ch>='0'&&ch<='9')) {token[m++]=ch; ch=prog[p++];}token[m++]='\0';p--;syn=10;for(n=0;n<6;n++)if(strcmp(token,key[n])==0){syn=n+1; break;}}else if(ch>='0'&&ch<='9'){while(ch>='0'&&ch<='9'){sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=20;}elseswitch(ch){case '<': m=0;token[m++]=ch;ch=prog[p++];if(ch=='<') {syn=33; token[m++]=ch;}else if(ch=='=') {syn=35; token[m++]=ch;}break;case '>': m=0;token[m++]=ch;ch=prog[p++];if(ch=='=') {syn=34; token[m++]=ch;}else {syn=32; p--;}break;case '=':token[m++]=ch;ch=prog[p++];if(ch=='='){ syn=36;token[m++]=ch;}else{ syn=21;p--;}break;case ':': m=0;token[m++]=ch;ch=prog[p++];if(ch=='=') {syn=18; token[m++]=ch;}else {syn=17; p--;}break;case '+': syn=22; token[0]=ch; break;case '-': syn=23; token[0]=ch; break;case '*': syn=24; token[0]=ch; break;case '/': syn=25; token[0]=ch; break;case ';': syn=31; token[0]=ch; break;case '(': syn=26; token[0]=ch; break;case ')': syn=27; token[0]=ch; break;case '@': syn=0; token[0]=ch; break;default : syn=-1;}}void lrparser(){if(syn==1){scaner();yucu();if(syn=6){scaner();if(syn==0 && (k==0))cout<<"\nsuccess\n"<<endl;}else{if(k!=1)cout<<"\nwhile error\n"<<endl;k=1;}}else{cout<<"\nmain error\n"<<endl;k=1;}return;}void yucu(){statement();while(syn==31){scaner();statement();}return;}void statement(){if(syn==10){scaner();if(syn==18){scaner();expression();}else{cout<<"\nscentence error\n"<<endl;k=1;}}return;}void expression(){term();while(syn==22||syn==23){scaner();term();}return;}void term(){factor();while(syn==24||syn==25){scaner();factor();}return;}void factor(){if(syn==10||syn==20)scaner();else if(syn==26){scaner();expression();if(syn==27)scaner();else{cout<<"( error"<<endl;k=1;}}else{cout<<"expression error"<<endl;k=1;}return;}五、实验过程原始记录( 测试数据、图表、计算等)六、实验结果、分析和结论(误差分析与数据处理、成果总结等。
编译原理语法分析器(完美运行版)

学院(系)名称:计算机工程系实验环境:Windows XP实验分析:(1)定义部分:定义常量、变量、数据结构。
(2)初始化:设立LL(1)分析表、初始化变量空间(包括堆栈、结构体、数组、临时变量等);(3)控制部分:从键盘输入一个表达式符号串;(4)利用LL(1)分析算法进行表达式处理:根据LL(1)分析表对表达式符号串进行堆栈(或其他)操作,输出分实验程序:#include<iostream>#include<stack>using namespace std;stack<char> symbol;stack<int> state;char sen[50];char sym[12][6]={//符号表{'s','e','e','s','e','e'},{'e','s','e','e','e','a'},{'r','r','s','r','r','r'},{'r','r','r','r','r','r'},{'s','e','e','s','e','e'},{'r','r','r','r','r','r'},{'s','e','e','s','e','e'},{'s','e','e','s','e','e'},{'e','s','e','e','s','e'},{'r','r','s','r','r','r'},{'r','r','r','r','r','r'},{'r','r','r','r','r','r'}};char snum[12][6]={//数字表{5,1,1,4,2,1},{3,6,5,3,2,0},{2,2,7,2,2,2},{4,4,4,4,4,4},{5,1,1,4,2,1},{6,6,6,6,6,6},{5,1,1,4,2,1},{5,1,1,4,2,1},{3,6,5,3,11,4},{1,1,7,1,1,1},{3,3,3,3,3,3},{5,5,5,5,5,5}};int go2[12][3]={//goto表{1,2,3},{0,0,0},{0,0,0},{0,0,0},{8,2,3},{0,0,0},{0,9,3},{0,0,10},{0,0,0},{0,0,0},{0,0,0},{0,0,0}};void action(int i,char *&a,char &how,int &num,char &A,int &b)//action函数[i,a] {int j;switch(*a){case 'i':j=0;break;case '+':j=1;break;case '*':j=2;break;case '(':j=3;break;case ')':j=4;break;case '#':j=5;break;default:j=-1;break;}if(j!=-1){how=sym[i][j];num=snum[i][j];if(how=='r'){switch(num){case 1:A='E',b=3;cout<<"按E->E+T规约"<<endl; break;case 2:A='E',b=1;cout<<"按E->T规约"<<endl; break;case 3:A='T',b=3;cout<<"按T->T*F规约"<<endl; break;case 4:A='T',b=1;cout<<"按T->F规约"<<endl; break;case 5:A='F',b=3;cout<<"按F->(E)规约"<<endl; break;case 6:A='F',b=1;cout<<"按F->id规约"<<endl; break;default:break;}}}}int go(int t,char A)//goto[t,A] {switch(A){case 'E':return go2[t][0];break;case 'T':return go2[t][1];break;case 'F':return go2[t][2];break;}}void error(int i,int j,char *&a)//error处理函数{cout<<"error"<<endl;switch(j){case 1://期望输入id或左括号,但是碰到+,*,或$,就假设已经输入id了,转到状态5 state.push(5);symbol.push('i');//必须有这个,如果假设输入id的话,符号栈里必须有....cout<<"缺少运算对象id"<<endl;break;case 2://从输入中删除右括号a++;cout<<"不配对的右括号"<<endl;break;case 3://期望碰到+,但是输入id或左括号,假设已经输入算符+,转到状态6state.push(6);symbol.push('+');cout<<"缺少运算符"<<endl;break;case 4://缺少右括号,假设已经输入右括号,转到状态11state.push(11);symbol.push(')');cout<<"缺少右括号"<<endl;break;case 5:a++;cout<<"*号无效,应该输入+号!"<<endl;case 6:a++;}}int main(){int s;char *a;char how;int num;int b;char A;while(1){cin>>sen;a=sen;state.push(0);//先输入0状态while(*a!='\0'){b=0;num=0;how='\0';A='\0';s=state.top();action(s,a,how,num,A,b);if(how=='s')//移进{cout<<"移进"<<endl;symbol.push(*a);state.push(num);// if(*a=='i')// a++;//在这里忽略i后面的da++;}else if(how=='r')//规约{for(int i=0;i<b;i++){if(!state.empty())state.pop();if(!symbol.empty())symbol.pop();}int t=state.top();symbol.push(A);state.push(go(t,A));}else if(how=='a')//接受break;else{error(s,num,a);//错误处理}}cout<<"成功接受"<<endl;}return 0;}测试用例:i*(i+i)+i#测试结果:心得体会:通过这次实验,我对编译原理这门专业必修课有了进一步的深层次了解,把理论知识应用于实验中,实验过程中对于程序的逻辑理解欠缺了考虑,在多次的调试和改进中最终完善了程序,而在调试过程中学习的知识得到了完善和补充,对语法分析器的理解更进一步。
编译原理语法分析报告+代码

语法分析一、实验目的编制一个递归下降分析程序,实现对词法分析程序所提供的单词序列的语法检查和结构分析。
二、实验要求利用C语言编制递归下降分析程序,并对简单语言进行语法分析。
2.1 待分析的简单语言的语法用扩充的BNF表示如下:⑴<程序>::=begin<语句串>end⑵<语句串>::=<语句>{;<语句>}⑶<语句>::=<赋值语句>⑷<赋值语句>::=ID:=<表达式>⑸<表达式>::=<项>{+<项> | -<项>}⑹<项>::=<因子>{*<因子> | /<因子>⑺<因子>::=ID | NUM | (<表达式>)2.2 实验要求说明输入单词串,以“#”结束,如果是文法正确的句子,则输出成功信息,打印“success”,否则输出“error”。
例如:输入begin a:=9; x:=2*3; b:=a+x end #输出success!输入x:=a+b*c end #输出error2.3 语法分析程序的酸法思想(1)主程序示意图如图2-1所示。
图2-1 语法分析主程序示意图(2)递归下降分析程序示意图如图2-2所示。
(3)语句串分析过程示意图如图2-3所示。
图2-3 语句串分析示意图图2-2 递归下降分析程序示意图(4)statement语句分析程序流程如图2-4、2-5、2-6、2-7所示。
图2-4 statement语句分析函数示意图图2-5 expression表达式分析函数示意图图2-7 factor分析过程示意图三、语法分析程序的C语言程序源代码:#include "stdio.h"#include "string.h"char prog[100],token[8],ch;char *rwtab[6]={"begin","if","then","while","do","end"};int syn,p,m,n,sum;int kk;factor();expression();yucu();term();statement();lrparser();scaner();main(){p=kk=0;printf("\nplease input a string (end with '#'): \n");do{ scanf("%c",&ch);prog[p++]=ch;}while(ch!='#');p=0;scaner();lrparser();getch();}lrparser(){if(syn==1){scaner(); /*读下一个单词符号*/yucu(); /*调用yucu()函数;*/if (syn==6){ scaner();if ((syn==0)&&(kk==0))printf("success!\n");}else { if(kk!=1) printf("the string haven't got a 'end'!\n");kk=1;}}else { printf("haven't got a 'begin'!\n");kk=1;}return;}yucu(){statement(); /*调用函数statement();*/while(syn==26){scaner(); /*读下一个单词符号*/if(syn!=6)statement(); /*调用函数statement();*/}return;}statement(){ if(syn==10){scaner(); /*读下一个单词符号*/if(syn==18){ scaner(); /*读下一个单词符号*/ expression(); /*调用函数statement();*/ }else { printf("the sing ':=' is wrong!\n");kk=1;}}else { printf("wrong sentence!\n");kk=1;}return;}expression(){ term();while((syn==13)||(syn==14)){ scaner(); /*读下一个单词符号*/ term(); /*调用函数term();*/}return;}term(){ factor();while((syn==15)||(syn==16)){ scaner(); /*读下一个单词符号*/ factor(); /*调用函数factor(); */ }return;}factor(){ if((syn==10)||(syn==11)) scaner();else if(syn==27){ scaner(); /*读下一个单词符号*/expression(); /*调用函数statement();*/ if(syn==28)scaner(); /*读下一个单词符号*/else { printf("the error on '('\n");kk=1;}}else { printf("the expression error!\n");kk=1;}return;}scaner(){ sum=0;for(m=0;m<8;m++)token[m++]=NULL;m=0;ch=prog[p++];while(ch==' ')ch=prog[p++];if(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))){ while(((ch<='z')&&(ch>='a'))||((ch<='Z')&&(ch>='A'))||((ch>='0')&&(ch<='9'))) {token[m++]=ch;ch=prog[p++];}p--;syn=10;token[m++]='\0';for(n=0;n<6;n++)if(strcmp(token,rwtab[n])==0){ syn=n+1;break;}}else if((ch>='0')&&(ch<='9')){ while((ch>='0')&&(ch<='9')){ sum=sum*10+ch-'0';ch=prog[p++];}p--;syn=11;}else switch(ch){ case '<':m=0;ch=prog[p++];if(ch=='>'){ syn=21;}else if(ch=='='){ syn=22;}else{ syn=20;p--;}break;case '>':m=0;ch=prog[p++];if(ch=='='){ syn=24;}else{ syn=23;p--;}break;case ':':m=0;ch=prog[p++];if(ch=='='){ syn=18;}else{ syn=17;p--;}break;case '+': syn=13; break;case '-': syn=14; break;case '*': syn=15;break;case '/': syn=16;break;case '(': syn=27;break;case ')': syn=28;break;case '=': syn=25;break;case ';': syn=26;break;case '#': syn=0;break;default: syn=-1;break;}}四、结果分析:输入begin a:=9; x:=2*3; b:=a+x end # 后输出success!如图4-1所示:图4-1输入x:=a+b*c end # 后输出error 如图4-2所示:图4-2五、总结:通过本次试验,了解了语法分析的运行过程,主程序大致流程为:“置初值”→调用scaner 函数读下一个单词符号→调用IrParse→结束。
编译原理(第三版)语法分析器
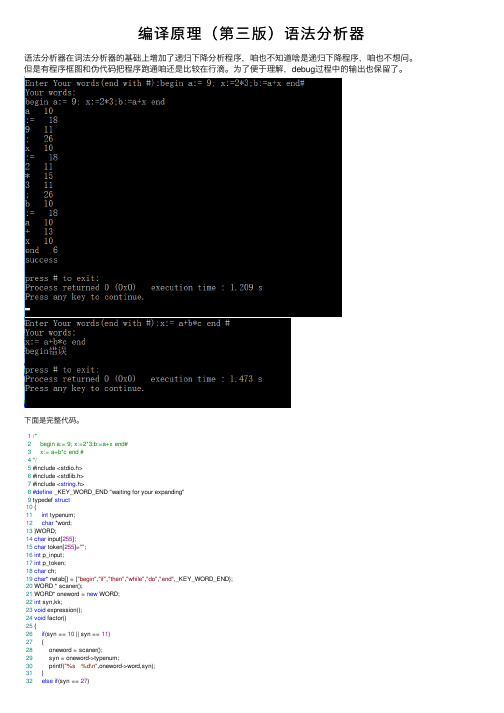
编译原理(第三版)语法分析器语法分析器在词法分析器的基础上增加了递归下降分析程序,咱也不知道啥是递归下降程序,咱也不想问。
但是有程序框图和伪代码把程序跑通咱还是⽐较在⾏滴。
为了便于理解,debug过程中的输出也保留了。
下⾯是完整代码。
1/*2 begin a:= 9; x:=2*3;b:=a+x end#3 x:= a+b*c end #4*/5 #include <stdio.h>6 #include <stdlib.h>7 #include <string.h>8#define _KEY_WORD_END "waiting for your expanding"9 typedef struct10 {11int typenum;12char *word;13 }WORD;14char input[255];15char token[255]="";16int p_input;17int p_token;18char ch;19char* rwtab[] = {"begin","if","then","while","do","end",_KEY_WORD_END};20 WORD * scaner();21 WORD* oneword = new WORD;22int syn,kk;23void expression();24void factor()25 {26if(syn == 10 || syn == 11)27 {28 oneword = scaner();29 syn = oneword->typenum;30 printf("%s %d\n",oneword->word,syn);31 }32else if(syn == 27)33 {34 oneword = scaner();35 syn = oneword->typenum;36 printf("%s %d\n",oneword->word,syn);37 expression();38if(syn == 28)39 {40 oneword = scaner();41 syn = oneword->typenum;42 printf("%s %d\n",oneword->word,syn);43 }44else{45 printf("右括号错误\n");46 kk = 1;47 }48 }49else50 {51 printf("表达式错误\n");52 kk = 1;53 }54return;55 }56void term()57 {58 factor();59while(syn == 15 || syn == 16)60 {61 oneword = scaner();62 syn = oneword->typenum;63 printf("%s %d\n",oneword->word,syn);64 factor();65 }66return;67 }68void expression()69 {70 term();71while(syn == 13 || syn == 14)72 {73 oneword = scaner();74 syn = oneword->typenum;75 printf("%s %d\n",oneword->word,syn);76 term();77 }78return;79 }80void statement()81 {82if(syn == 10)83 {84 oneword = scaner();85 syn = oneword->typenum;86 printf("%s %d\n",oneword->word,syn); 87if(syn == 18)88 {89 oneword = scaner();90 syn = oneword->typenum;91 printf("%s %d\n",oneword->word,syn);92 expression();93 }94else{95 printf("赋值号错误\n");96 kk = 1;97 }98 }99else{100 printf("语句错误\n");101 kk = 1;102 }103return;104 }105void yucu()106 {107 statement();108while(syn == 26)109 {110 oneword = scaner();111 syn = oneword->typenum;112 printf("%s %d\n",oneword->word,syn); 113 statement();114 }115return;116 }117void Irparser()118 {119if(syn == 1)120 {121 oneword = scaner();122 syn = oneword->typenum;123 printf("%s %d\n",oneword->word,syn);124 yucu();125126if(syn==6)127 {128 oneword = scaner();129 syn = oneword->typenum;130if(syn == 0 && (kk == 0))131 printf("success\n");132 }133else{134if(kk != 1)135 {136 printf("缺少end错误\n");137 kk = 1;138 }139 }140 }141else{142 printf("begin错误\n");143 kk = 1;144 }145return;146 }147int main()148 {149int over = 1;150151 printf("Enter Your words(end with #):");152 scanf("%[^#]s",input);153 p_input = 0;154 printf("Your words:\n%s\n",input);155156//获取下⼀个单词符号157 oneword = scaner();158 syn = oneword->typenum;159 Irparser();160161 printf("\npress # to exit:");162 scanf("%[^#]s",input);163return0;164 }165char m_getch()166 {167 ch = input[p_input];168 p_input = p_input+1;169return(ch);170 }171void getbc()172 {173while(ch == ''||ch == 10)174 {175 ch = input[p_input];176 p_input++;177 }178 }179void concat()180 {181 token[p_token] = ch;182 p_token++;183 token[p_token] = '\0';184 }185int letter()186 {187if((ch >= 'a'&& ch <= 'z')|| (ch >='A'&&ch <= 'Z')) 188return1;189else190return0;191 }192int digit()193 {194if(ch >= '0'&&ch <='9')return1;195else return0;196 }197int reserve()198 {199int i = 0;200while(strcmp(rwtab[i],_KEY_WORD_END))201 {202if(!strcmp(rwtab[i],token))203return i+1;204 i++;205 }206return10;207 }208void retract()209 {210 p_input--;211 }212213char* dtb()214 {215return NULL;216 }217218 WORD* scaner()219 {220221 WORD* myword = new WORD; 222 myword->typenum = 10;223 myword->word = "";224 p_token = 0;225 m_getch();226 getbc();227if(letter())228 {229while(letter()||digit())230 {231 concat();232 m_getch();233 }234 retract();235 myword->typenum = reserve(); 236 myword->word = token;237return(myword);238 }239else if(digit())240 {241while(digit())242 {243 concat();244 m_getch();245 }246 retract();247 myword->typenum = 11;248 myword->word = token;249return(myword);250 }251else switch(ch)252 {253case'=':m_getch();254if(ch == '=')255 {256 myword->typenum = 25; 257 myword->word = "=="; 258return(myword);259 }260 retract();261 myword->typenum = 21; 262 myword->word = "=";263return(myword);264break;265case'+':266 myword->typenum = 13; 267 myword->word = "+";268return(myword);269break;270case'-':271 myword->typenum = 14; 272 myword->word = "-";273return(myword);274break;275case'*':276 myword->typenum = 15; 277 myword->word = "*";278return(myword);279break;280case'/':281 myword->typenum = 16; 282 myword->word = "/";283return(myword);284break;289break;290case')':291 myword->typenum = 28; 292 myword->word = ")";293return(myword);294break;295case'[':296 myword->typenum = 28; 297 myword->word = "[";298return(myword);299break;300case']':301 myword->typenum = 29; 302 myword->word = "]";303return(myword);304break;305case'{':306 myword->typenum = 30; 307 myword->word = "{";308return(myword);309break;310case'}':311 myword->typenum = 31; 312 myword->word = "}";313return(myword);314break;315case',':316 myword->typenum = 32; 317 myword->word = ",";318return(myword);319break;320case':':m_getch();321if(ch == '=')322 {323 myword->typenum = 18; 324 myword->word = ":="; 325return(myword);326 }327 retract();328 myword->typenum = 17; 329 myword->word = ":";330return(myword);331break;332case';':333 myword->typenum = 26; 334 myword->word = ";";335return(myword);336break;337case'>':m_getch();338if(ch == '=')339 {340 myword->typenum = 24; 341 myword->word = ">="; 342return(myword);343 }344 retract();345 myword->typenum = 23; 346 myword->word = ">";347return(myword);348break;349case'<':m_getch();350if(ch == '=')351 {352 myword->typenum = 22; 353 myword->word = "<="; 354return(myword);355 }356else if(ch == '>')357 {358 myword->typenum = 21; 359 myword->word = "<>"; 360return(myword);361 }362 retract();363 myword->typenum = 20; 364 myword->word = "<";365return(myword);366break;367case'!':m_getch();368if(ch == '=')373 }374 retract();375 myword->typenum = -1; 376 myword->word = "ERROR"; 377return(myword);378break;379case'#':380 myword->typenum = 0;381 myword->word = "#";382return(myword);383break;384case'\0':385 myword->typenum = 0;386 myword->word = "OVER"; 387return(myword);388break;389default: myword->typenum = -1; 390 myword->word = "ERROR"; 391return(myword);392 }393 }。
语法分析器

实验二:语法分析器
课程ห้องสมุดไป่ตู้称:编译原理
学院:计算机科学与工程
班级:
姓名:
学号:
教师:李拥军
2015年01月06日
一、
设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析的理解掌握以及高级语言语法结构的定义,掌握语法分析的常用方法
二、
(1)操作系统:Windows 7
(2)编程环境:Visual Studio 2010
要实现上术的语法分析需要增加一些常量:
typedef enum {StmtK,ExpK} NodeKind;
typedef enum {IfK,RepeatK,AssignK,ReadK,WriteK,WhileK} StmtKind;
typedef enum {OpK,ConstK,IdK,StrK,BoolK} ExpKind;
S.code=Label S.begin||Seq.code||Label Seq.next||E.code
S->if E then S1 end
E.true=newlabel;
E.fasle=S.next
S1.next=S.next
S.code=E.code || gen(E.true) || S1.code
match(ID);
while(token==COMMA)
{
match(COMMA);
st_insert(tokenString,type,lineno,location++);
match(ID);
}
match(SEMI);//';' is expected
}
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
语法分析器(含完整源码)语法分析实验报告一、实验目的:1. 了解单词(内部编码)符号串中的短语句型结构形成规律。
2. 理解和掌握语法分析过程中语法分析思想(LL,LR)的智能算法化方法。
二、实验内容:构造自己设计的小语言的语法分析器:1. 小语言的语法描述(语法规则)的设计即文法的设计;2. 把文法形式符号中所隐含的信息内容挖掘出来并用LL或LR 的资料形式(分析表)表示出来;3. 语法分析的数据输入形式和输出形式的确定;4. 语法分析程序各个模块的设计与调试。
主要设备和材料:电脑、winxp操作系统、VC语言系统三、实验分工:081四、实验步骤:1、语法规则①<程序>::= {<变量定义语句>|<赋值语句>|<条件语句> |<循环语句> }②<变量定义语句>::=var 变量{,变量};③<赋值语句>::=变量:= <表达式>;④<表达式>::=标识符{运算符标识符};⑤<标识符>::=变量|常量⑥<运算符>::=+ | - | * | / | >= | <=⑦<条件语句>::=<if语句>[<else语句>]⑧<if语句>::= if(表达式) then[begin] {赋值语句|条件语句| 循环语句}[end]⑨<else语句>::= [begin] {赋值语句|条件语句| 循环语句} [end]⑩<循环语句>::=while(表达式) [begin] {赋值语句| 条件语句| 循环语句} [end]<输出语句>::=prn 表达式--注1:若if语句、else语句、循环语句中出现begin,后面的end必须出现,即begin与end同对出现--注2:if、while后的"(",")"表示终结符,而不是定义成分优先的说明符号2、分析表:( ) : = 变量常量,;运算符变量定义->②->②->②->②赋值语句->③->③->③->③ ->③条件语句->⑦->⑦->⑦->⑦->⑦->⑦->⑦循环语句->⑩->⑩->⑩->⑩->⑩->⑩->⑩输出语句->->->分析表(续):while var begin end if then prn 变量定义->②赋值语句条件语句->⑦->⑦->⑦->⑦循环语句->⑩->⑩->⑩输出语句-> 3、调试和测试五、源代码(见附录):六、实验总结:本实验在词法分析的基础上,对提取出的标识符进行语法判断。
对已有的语法规则运用LL(1)文法判别并进行构造分析表时,遇到的最大困难是:当发生规约冲突时,该如何处理。
如对于产生式s-->aAb,当对a进行规约时,满足语法规则的β(用户输入串中当前要进行规约的标识符)只有有限种,而不满足的却有无限种情况。
当发生规约冲突时,如何在这无限种情况中,确定冲突的具体信息,以便用户查找。
在反复的尝试和验证中,我们发现发生冲突的用户输入串满足一定的规律,且按这种规律可以把这无限种情况化归为有限类,于是我们找出其中规律并进行划分,然后再对这些有限类冲突进行处理。
七、实验心得:通过这次实验有以下几点收获:1. LR(1)的构造使得对理论的知识理解的更加透彻。
其中LR(1)分析表构造了很多遍,一直无法得到正确结果,这是恒心的考验。
2.在写程序中用类数组来存放单词属性使得对单词各项值的调用更加方便,特别是对出错信息的检测有很大的作用。
3.本实验是在词法基础上的更进一步,在词法程序上添加语法程序,更加理解二者之间的关系。
词法分析为语法分析提供了词法单元,方便分析,使程序模块化,易于读懂。
附录:#include <iostream>#include <fstream>#include <string>#include <math.h>#include <ctype.h>#include <cstdlib>using namespace std;#define Max 655 //最大代码长度#define WordMaxNum 256 //变量最大个数#define DigitNum 256 //常量最大个数#define MaxKeyWord 32 //关键字数量#define MaxOptANum 8 //运算符最大个数#define MaxOptBNum 4 //运算符最大个数#define MaxEndNum 11 //界符最大个数typedef struct DisplayTable{int Index; //标识符所在表的下标int type; //标识符的类型int line; //标识符所在表的行数char symbol[20]; //标识符所在表的名称}Table;int TableNum = 0; //display表的表项总数char Word[WordMaxNum][20]; //标识符表char Digit[WordMaxNum][20]; //数字表int WordNum = 0; //变量表的下标int DigNum = 0; //常量表的下标bool errorFlag = 0; //错误标志int TableIndex = -1; //display 表的下标索引int beginCount = 0;//遇到begin加1,遇到end减1int ifCount = 0; //遇到if加1Table *table = new Table[Max];//关键字const char* const KeyWord[MaxKeyWord] = {"and","array", "begin","case","char","constant","do","else","end","false", "for","if","input","integer","not","of","or","output", "packed","procedure","program","read","real","repeat","set", "then", "to", "type", "until", "var","while", "with","prn"};// 单目运算const char OptA[] = {'+','-','*','/','=','#','<','>'};//双目运算符const char *OptB[] = {"<=",">=",":=","<>"};// 界符const char End[] = {'(', ')' , ',' , ';' , '.' , '[' , ']' , ':' , '{' , '}' , '"'};void error(char str[20],int nLine, int errorType){errorFlag = 1;cout <<" \nError : ";switch(errorType){case 1:cout << "第" << nLine-1 <<"行" << str << " 变量的长度超过限制!\n";break;case 2:cout << "第" << nLine-1 <<"行" << str << " 小数点错误!\n";break;case 3:cout << "第" << nLine-1 <<"行" << str << " 常量的长度超过限制!\n";break;}//switch}//errorvoid Scanner(char ch[],int chLen,int nLine){int chIndex = 0;while(chIndex < chLen) //对输入的字符扫描{/****************处理空格和tab***************************/ //忽略空格和tabwhile(ch[chIndex] == ' ' || ch[chIndex] == 9 ){ chIndex ++; }/*************************处理换行符*********************/ //遇到换行符,行数加1while(ch[chIndex] == 10){ nLine++;chIndex ++;}/***************************标识符**********************/ if( isalpha(ch[chIndex])) //以字母、下划线开头{char str[256];int strLen = 0;//是字母、下划线while(isalpha(ch[chIndex]) || ch[chIndex] == '_' ){str[strLen ++] = ch[chIndex];chIndex ++;while(isdigit(ch[chIndex]))//不是第一位,可以为数字{str[strLen ++] = ch[chIndex];chIndex ++;}}str[strLen] = 0; //字符串结束符if(strlen(str) > 20) //标识符超过规定长度,报错处理{error(str,nLine,1);}else{int i;for(i = 0;i < MaxKeyWord; i++) //与关键字匹配//是关键字,写入table表中if(strcmp(str, KeyWord[i]) == 0){strcpy(table[TableNum].symbol,str);table[TableNum].type = 1; //关键字table[TableNum].line = nLine;table[TableNum].Index = i;TableNum ++;break;}if(i >= MaxKeyWord) //不是关键字{table[TableNum].Index = WordNum;strcpy(Word[WordNum++],str);table[TableNum].type = 2; //变量标识符strcpy(table[TableNum].symbol,str);table[TableNum].line = nLine;TableNum ++;}}}/**************************常数**************************/ else if(isdigit(ch[chIndex])) //遇到数字{int flag = 0;char str[256];int strLen = 0;//数字和小数点while(isdigit(ch[chIndex]) || ch[chIndex] == '.') {//flag表记小数点的个数,0时为整数,1时为小数,2时出错if(ch[chIndex] == '.')flag ++;str[strLen ++] = ch[chIndex];chIndex ++;}str[strLen] = 0;if(strlen(str) > 20) //常量标识符超过规定长度20,报错处理{error(str,nLine,3);}if(flag == 0){table[TableNum].type = 3; //整数}if(flag == 1){table[TableNum].type = 4; //小数}if(flag > 1){error(str,nLine,2);}table[TableNum].Index = DigNum;strcpy(Digit[DigNum ++],str);strcpy(table[TableNum].symbol,str);table[TableNum].line = nLine;TableNum ++;}/*************************运算符************************/ else{//用来区分是不是无法识别的标识符,0为运算符,1为界符int errorFlag;char str[3];str[0] = ch[chIndex];str[1] = ch[chIndex + 1];str[2] = '\0';int i;for( i = 0;i < MaxOptBNum;i++)//MaxOptBNum)if(strcmp(str,OptB[i]) == 0){errorFlag = 0;table[TableNum].type = 6;strcpy(table[TableNum].symbol,str);table[TableNum].line = nLine;table[TableNum].Index = i;TableNum ++;chIndex = chIndex + 2;break;}if(i >= MaxOptBNum){for( int k = 0;k < MaxOptANum; k++)if(OptA[k] == ch[chIndex]){errorFlag = 0;table[TableNum].type = 5;table[TableNum].symbol[0] =ch[chIndex];table[TableNum].symbol[1] = 0;table[TableNum].line = nLine;table[TableNum].Index = k;TableNum ++;chIndex ++;break;}/*************************界符************************/for(int j = 0;j < MaxEndNum;j ++)if(End[j] ==ch[chIndex]){errorFlag = 1;table[TableNum].line = nLine;table[TableNum].symbol[0] = ch[chIndex];table[TableNum].symbol[1] = 0;table[TableNum].Index = j;table[TableNum].type = 7;TableNum ++;chIndex ++;}/********************其他无法识别字符*****************/ //开头的不是字母、数字、运算符、界符if(errorFlag != 0 && errorFlag != 1){char str[256];int strLen = -1;str[strLen ++] = ch[chIndex];chIndex ++;while(*ch != ' ' || *ch != 9 || ch[chIndex] != 10){str[strLen ++] = ch[chIndex];chIndex ++;}str[strLen] = 0;table[TableNum].type = 8;strcpy(table[TableNum].symbol,str);table[TableNum].line = nLine;table[TableNum].Index = -2;TableNum ++;}}}}}/**************把十进制小数转为16进制******************/ void Trans(double x,int p) //把十进制小数转为16进制{int i=0; //控制保留的有效位数while(i<p){if(x==0) //如果小数部分是0break; //则退出循环else{int k=int(x*16); //取整数部分x=x*16-int(k); //得到小数部分if(k<=9)cout<<k;elsecout<<char(k+55);};i++;};};/***********************语法错误*************************/ void Gerror(int errorType,int nIndex){errorFlag = 1;switch(errorType){case 1:cout << "第" << table[nIndex].line <<"行:" <<table[nIndex].symbol <<" 应该为赋值号:= \n";break;case 2:cout << "第" << table[nIndex].line <<"行:" << table[nIndex].symbol <<" 应为变量 \n";break;case 3:cout << "第" << table[nIndex].line <<"行:" << table[nIndex].symbol <<" 应为逗号 \n";break;case 4:cout << "第" << table[nIndex].line <<"行:" << table[nIndex].symbol <<" 应为分号 \n";break;case 5:cout << "第" << table[nIndex].line <<"行:" << table[nIndex].symbol <<" 应为运算符 \n";break;case 6:cout << "第" << table[nIndex].line <<"行:" << table[nIndex].symbol <<" 应为变量或常量 \n";break;case 7:cout << "第" <<table[TableIndex].line <<"行 "<< table[nIndex].symbol << "与"<<table[TableIndex + 1].symbol<<"之间缺少运算符 \n";break;case 8:cout << "第" << table[nIndex].line <<"行:" <<table[nIndex + 1 ].symbol <<" 应为'(' \n";break;case 9:cout << "第" <<table[TableIndex].line <<"行 "<< table[TableIndex].symbol << "与"<<table[nIndex + 1].symbol <<"之间缺少'(' \n";break;case 10:cout << "第" << table[TableIndex - 1].line<< " 行: 缺少'then'" << endl;break;case 11:cout << "第" << table[TableIndex].line << " 行:"<<table[nIndex].symbol << "应为then \n";break;case 12:cout << "第" << table[TableIndex].line << " 行: end 后不能接 " <<table[TableIndex].symbol <<endl;break;case 13:cout << "第" << table[nIndex].line <<"行:"<< table[nIndex - 1].symbol <<"与 "<<table[TableIndex].symbol <<"之间缺少变量 \n";break;case 14:cout << "第" <<table[nIndex ].line <<"行 "<< table[nIndex ].symbol << "后缺少';' \n";break;case 15:cout << "第" << table[TableIndex].line << " 行:"<<table[nIndex].symbol << "应为')' \n";break;case 16:cout << "第" << table[TableIndex].line<< " 行,begin 后不能接 "<<table[TableIndex].symbol << endl;break;}}/************************表达式判断********************/ bool express(){while(1 ){if(table[TableIndex].type==2||table[TableIndex].type == 3 ){if(table[TableIndex].type==3&&table[TableIndex+ 1].type == 2 && table[TableIndex].line == table[TableIndex + 1].line){Gerror(7,TableIndex); //出错信息:该处缺少运算符//TableIndex = TableIndex + 2;TableIndex ++;}if(table[TableIndex].line != table[TableIndex + 1].line){// Gerror(14,TableIndex); //出错信息:该语句缺少分号return 1;}TableIndex ++;}else{if(table[TableIndex].type == 5||table[TableIndex].type == 6) {Gerror(13,TableIndex);TableIndex ++;}else{Gerror(6,TableIndex); //出错信息:该处应为变量或常量}TableIndex ++;}if(table[TableIndex].type ==5|| table[TableIndex].type ==6 )TableIndex ++;else if(table[TableIndex].type == 7)return 1;else if(TableIndex >= TableNum) //|| ){Gerror(14,TableIndex); //出错信息:该语句缺少分号return 1;}else{Gerror(5,TableIndex); //出错信息:此处应为运算符TableIndex ++;}}}/*******************赋值语句判断*************************/ bool Assign() //赋值语句的判断{TableIndex ++;if(strcmp( ":=" , table[TableIndex].symbol) == 0){TableIndex ++;}else{Gerror(1,TableIndex); //出错信息:赋值号应该为":="TableIndex ++;}if(express()) //":="后可以为变量或常量{if(strcmp(";",table[TableIndex].symbol) == 0){return 1;}else{if(TableIndex >= TableNum){Gerror(14,TableIndex); //出错信息:该语句缺少分号return 1;}else if(table[TableIndex].line != table[TableIndex +1].line){Gerror(14,TableIndex); //出错信息:该语句缺少分号return 1;//TableIndex ++;}}}else{Gerror(6,TableIndex); //出错信息:":="后应为变量或常量TableIndex ++;}return 0;}/**********************语句判断*************************/ bool judge() //条件、循环、初始化语句的判断{/**************************begin********************** /if(strcmp("begin",table[TableIndex].symbol)==0) //匹配begin{beginCount ++;if(table[TableIndex + 1].type == 7){TableIndex ++;cout << "第" << table[TableIndex].line<< " 行,begin 后不能接 "<<table[TableIndex].symbol << endl;return 1;}}/**************************end***********************/if(strcmp("end",table[TableIndex].symbol) == 0) //匹配end {beginCount --;if(TableIndex < TableNum)if(table[TableIndex+1].type==7||table[TableIndex+ 1].type == 8){TableIndex ++;Gerror(12,TableIndex);return 1;}}/**************************else**********************/if(strcmp("else",table[TableIndex].symbol) == 0) //匹配else{ifCount --;return 1;}if(strcmp("prn",table[TableIndex].symbol) == 0) //匹配prn{TableIndex ++;if(table[TableIndex].type == 2 ||table[TableIndex].type == 3) // prn 后为变量或常量{TableIndex ++;//语句结束,“;”0) {return 1;}else{Gerror(4,TableIndex);//出错信息:此处应为";"}} //ifelse{Gerror(2,TableIndex);//出错信息:此处应为变量TableIndex ++;}}//if_prn/**********************var变量定义**********************/if(strcmp("var",table[TableIndex].symbol) == 0)// var a,b,c; {TableIndex ++;if(table[TableIndex].type != 2){Gerror(13,TableIndex);else Gerror(2,TableIndex);//出错信息:此处应为变量}TableIndex ++;if(strcmp(",",table[TableIndex].symbol) !=0){Gerror(3,TableIndex); //出错信息:此处应为","TableIndex ++;}while(1){while(strcmp(",",table[TableIndex].symbol)==0){TableIndex = TableIndex + 1;if(table[TableIndex].type !=2){Gerror(2,TableIndex);//出错信息:此处应为变量TableIndex ++;}TableIndex ++;}if(strcmp(";",table[TableIndex].symbol)==0){return 1;}else{Gerror(4,TableIndex);//出错信息:此处应为分号";"return 0;}}}/*****************if语句判断************************///if语句else if(strcmp("if",table[TableIndex].symbol) == 0){ifCount ++; //if个数加1if(table[TableIndex +1].type == 2 || table[TableIndex + 1].type == 3){Gerror(9,TableIndex); //出错信息:此处缺少')'TableIndex ++;}else if(strcmp("(",table[TableIndex + 1].symbol) != 0) {Gerror(8,TableIndex);//出错信息:此处应为分号"("}TableIndex = TableIndex + 2;if(express()){if(strcmp(")",table[TableIndex].symbol) == 0) //'('匹配{TableIndex ++;if(strcmp("begin",table[TableIndex ].symbol) == 0) {beginCount ++;if(table[TableIndex + 1].type == 7){Gerror(16,TableIndex);TableIndex ++;return 1;}Gerror(10,TableIndex);//出错信息:此处缺少"then"return 0;}if(strcmp("then",table[TableIndex].symbol) != 0){Gerror(11,TableIndex);//出错信息:此处应为"then"return 0;}//if_thenelse{return 1;}}//if_)else{Gerror(15,TableIndex);return 0;}} //if_express}//if_if//return 1;}int main(){ifstream in;ofstream out;char in_file_name[26],out_file_name[26];char ch[Max];cin.getline(ch,Max,'#');int nLine = 1;/**********************调用词法分析**********************/ Scanner(ch, strlen(ch),nLine);//for(int i = 0; i < TableNum;i ++)// cout << table[i].type<< " "<<table[i].symbol<< " "<<table[i].Index<<""<<table[i].line<< endl;/**********************调用语法分析**********************/ cout << endl << "语法分析结果:\n "<< endl;while(TableIndex <= TableNum){TableIndex ++;if(table[TableIndex].type == 1)judge();else if(table[TableIndex].type == 2)Assign(); //赋值语句}if(ifCount < 0){errorFlag = 1;cout << "程序缺少if \n";}if(beginCount <0){errorFlag = 1;cout << "程序缺少begin \n";}if(beginCount >0){errorFlag = 1;cout << "程序缺少end \n";}if(errorFlag == 0){cout << "语法分析成功!"; }return 0;}。