spss中一般线性模型
用spss20进行可重复单因素随机区组、两因素随机区组、两因素裂区试验设计的方差分析

一、可重复单因素随机区组试验设计8个小麦品种的产比试验,采用随机区组设计,3次重复,计产面积25平米,产量结果如下,进行方差分析和多重比较。
表1 小麦品比试验产量结果(公斤)4 3 10.15 3 16.86 3 11.87 3 14.18 3 14.41、打开程序把上述数据输入进去。
2、执行:分析-一般线性模型-单变量。
3、将产量放进因变量,品种和区组放进固定因子。
4、单击模型,选择设定单选框,将品种和区组放进模型中,只分析主效应。
5、在两两比较中进行多重比较,这里只用分析品种。
可以选择多种比较方法。
6、分析结果。
主体间效应的检验因变量: 产量源III 型平方和df 均方 F Sig. 校正模型61.641a 9 6.849 4.174 .009 截距3220.167 1 3220.167 1962.448 .000 区组27.561 2 13.780 8.398 .004 品种34.080 7 4.869 2.967 .040 误差22.972 14 1.641总计3304.780 24校正的总计84.613 23a. R 方 = .729(调整 R 方 = .554)这里只须看区组和品种两行,两者均达到显著水平,说明土壤肥力和品种均影响产量结果。
下面是多重比较,只有方差分析达到显著差异才进行多重比较。
二、两因素可重复随机区组试验设计下面是水稻品种和密度对产量的影响,采用随机区组试验设计,3次重复,品种3个水平,密度3个水平,共27个观测值。
小区计产面积20平米。
表2 水稻品种与密度产比试验1、输入数据,执行:分析-一般线性模型-单变量。
注意区组作为随机因子。
2、选择模型。
注意模型中有三者的主效和品种与密度的交互。
3、分析结果。
注意自由度的分解。
使用一个误差(0.486)计算F值。
主体间效应的检验因变量: 产量源III 型平方和df 均方 F Sig. 截距假设1496.333 1 1496.333 1035.923 .0014、语句。
SPSS如何实现多个指标的多重比较

SPSS如何实现多个指标的多重比较在统计学中,多重比较是一种常用的方法,用于比较多个指标之间的差异。
SPSS是一款功能强大的统计分析软件,提供了多种方法来实现多个指标的多重比较。
下面将介绍两种常用的方法:___校正和Tukey HSD法。
___校正Bonferroni校正是一种常见的多重比较校正方法,它的基本原理是将显著性水平除以比较的指标数目。
SPSS提供了简便的方法来进行Bonferroni校正。
1.打开SPSS软件并加载你的数据集。
2.在菜单栏中选择【分析】>【一般线性模型】>【多重比较】。
3.在弹出窗口中,选择你要进行多重比较的自变量和因变量,然后点击【设置】按钮。
4.在设置窗口中,选择Bonferroni校正方法并输入显著性水平。
5.点击【确定】按钮来完成多重比较的分析。
___ HSD法___ HSD法是一种常用的多重比较方法,它基于___'s方法来调整比较的显著性水平。
SPSS也提供了简单的方法来进行TukeyHSD法的分析。
1.打开SPSS软件并加载你的数据集。
2.在菜单栏中选择【分析】>【一般线性模型】>【多重比较】。
3.在弹出窗口中,选择你要进行多重比较的自变量和因变量,然后点击【设置】按钮。
4.在设置窗口中,选择Tukey HSD法,并选择需要比较的指标。
5.点击【确定】按钮来完成多重比较的分析。
结论通过SPSS软件提供的Bonferroni校正和Tukey HSD法,我们可以方便地实现多个指标的多重比较分析。
在进行多重比较时,我们需要选择适当的校正方法,并设定显著性水平,以确保分析结果的可靠性。
SPSS专题2 回归分析(线性回归、Logistic回归、对数线性模型)

19
Correlation s lif e_ expectanc y _ f emale(y ear) .503** .000 164 1.000 . 192 .676**
cleanwateraccess_rura... life_expectancy_femal... Die before 5 per 1000
Model 1 2
R .930
a
R Square .866 .879
Model 1
df 1 54 55 2 53 55
Regres sion Residual Total Regres sion Residual Total
Mean Square 54229.658 155.861 27534.985 142.946
2
回归分析 • 一旦建立了回归模型 • 可以对各种变量的关系有了进一步的定量理解 • 还可以利用该模型(函数)通过自变量对因变量做 预测。 • 这里所说的预测,是用已知的自变量的值通过模型 对未知的因变量值进行估计;它并不一定涉及时间 先后的概念。
3
例1 有50个从初中升到高中的学生.为了比较初三的成绩是否和高中的成绩 相关,得到了他们在初三和高一的各科平均成绩(数据:highschool.sav)
50名同学初三和高一成绩的散点图
100
90
80
70
60
高 一成 绩
50
40 40
从这张图可以看出什么呢?
50 60 70 80 90 100 110
4
初三成绩
还有定性变量 • 该数据中,除了初三和高一的成绩之外,还有 一个定性变量 • 它是学生在高一时的家庭收入状况;它有三个 水平:低、中、高,分别在数据中用1、2、3 表示。
方差分析
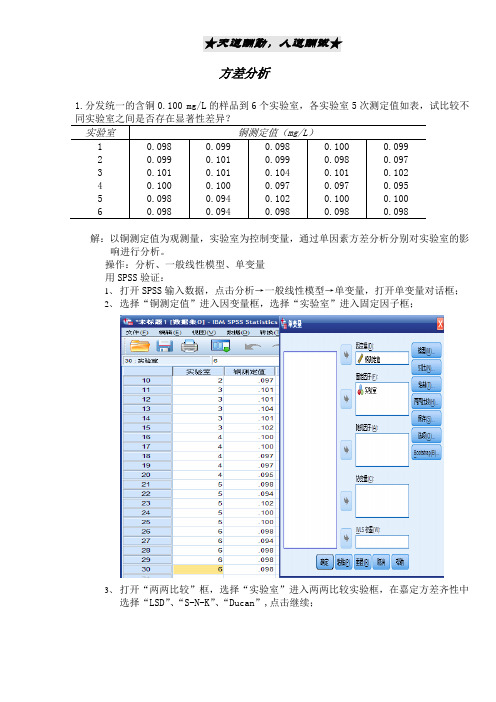
方差分析1.分发统一的含铜0.100 mg/L的样品到6个实验室,各实验室5次测定值如表,试比较不解:以铜测定值为观测量,实验室为控制变量,通过单因素方差分析分别对实验室的影响进行分析。
操作:分析、一般线性模型、单变量用SPSS验证:1、打开SPSS输入数据,点击分析→一般线性模型→单变量,打开单变量对话框;2、选择“铜测定值”进入因变量框,选择“实验室”进入固定因子框;3、打开“两两比较”框,选择“实验室”进入两两比较实验框,在嘉定方差齐性中选择“LSD”、“S-N-K”、“Ducan”,点击继续;4、点击确定,运行结果,如下图。
1-1 主体间因子N实验室1 52 53 54 55 56 5(I-J) 下限上限LSD 12 .00000 .001203 1.000 -.00248.002483 -.00300*.001203 .020 -.00548 -.000524 .00100 .001203 .414 -.00148 .003485 .00000 .001203 1.000 -.00248 .002486 .00160 .001203 .196 -.00088 .0040821 .00000 .001203 1.000 -.00248 .002483 -.00300*.001203 .020 -.00548 -.000524 .00100 .001203 .414 -.00148 .003485 .00000 .001203 1.000 -.00248 .002486 .00160 .001203 .196 -.00088 .0040831 .00300*.001203 .020 .00052 .005482 .00300*.001203 .020 .00052 .005484 .00400*.001203 .003 .00152 .006485 .00300*.001203 .020 .00052 .005486 .00460*.001203 .001 .00212 .0070841 -.00100 .001203 .414 -.00348 .001482 -.00100 .001203 .414 -.00348 .001483 -.00400*.001203 .003 -.00648 -.001525 -.00100 .001203 .414 -.00348 .001486 .00060 .001203 .622 -.00188 .0030851 .00000 .001203 1.000 -.00248 .002482 .00000 .001203 1.000 -.00248 .002483 -.00300*.001203 .020 -.00548 -.000524 .00100 .001203 .414 -.00148 .003486 .00160 .001203 .196 -.00088 .0040861 -.00160 .001203 .196 -.00408 .000882 -.00160 .001203 .196 -.00408 .000883 -.00460*.001203 .001 -.00708 -.002124 -.00060 .001203 .622 -.00308 .001885 -.00160 .001203 .196 -.00408 .00088 基于观测到的均值。
SPSS Modeler 建立线性回归模型

Modeler 建立线性回归模型示例线性回归模型是一种常用的统计学模型。
IBM SPSS Modeler 是一个强大的数据挖掘分析工具,本文将介绍如何用它进行线性回归预测模型的建立和使用。
在本文中,将通过建立一个理赔欺诈检测模型的实例来展示如何利用IBM SPSS Modeler 建立线性回归预测模型以及如何解释及应用该模型。
回归分析(Regression Analysis)是一种统计学上对数据进行分析的方法,主要是希望探讨数据之间是否有一种特定关系。
线性回归分析是最常见的一种回归分析,它用线性函数来对因变量及自变量进行建模(自变量和因变量都必须是连续型变量),这种方式产生的模型称为线性模型。
线性回归模型由于其运算速度快、直观性强以及参数易于确定等特点,在实践中应用最为广泛,也是建立预测模型的重要手段之一。
IBM SPSS Modeler 是一组数据挖掘工具,通过这些工具可以采用商业技术快速建立预测性模型,并将其应用于商业活动,从而改进决策过程。
在后面的文章中,将通过一个理赔欺诈检测的实际商业应用来介绍如何用IBM SPSS Modeler 建立、分析及应用线性回归分析模型。
用线性回归建立理赔欺诈检测模型在本例中,用于建立模型的数据存放在InsClaim.dat 中,该文件是一个CSV 格式的数据文件,存储了某医院以往医疗保险理赔的历史记录。
该文件共有293 条记录,每条记录有 4 个字段,分别是ASG(疾病严重程度)、AGE(年龄)、LOS(住院天数)和CLAIM(索赔数额)。
图1 显示了该数据的部分内容。
图 1. 历史理赔数据文件任务与计划基于已有的数据,我们的任务主要有如下内容:∙建立理赔金额预测模型,该模型将基于病人的疾病严重程度、住院天数及年龄预测其索赔金额。
∙假设模型匹配良好,分析那些与预测误差较大的病人资料。
∙通过模型来进行索赔欺诈预测。
根据经验及对数据进行的初步分析(这个数据初步分析可以通过IBM SPSS Modeler 的功能实现,此处不是重点,故不做深入介绍),可以猜测理赔金额与疾病严重程度、住院天数以及年龄存在线性相关关系,因此我们将首先选用线性回归模型进行建模,因此可以得到下面这样一个初步计划:∙应用线性回归分析来建立模型。
第八章 一般线性模型――General Linear Model菜单详解

第八章一般线性模型――General Linear Model菜单详解请注意,本章的标题用了一些修辞手法,一般线性模型可不是用一章就可以说清楚的,因为它包括的内容实在太多了。
那么,究竟我们用到的哪些分析会包含在其中呢?简而言之:凡是和方差分析粘边的都可以用他来做。
比如成组设计的方差分析(即单因素方差分析)、配伍设计的方差分析(即两因素方差分析)、交叉设计的方差分析、析因设计的方差分析、重复测量的方差分析、协方差分析等等。
因此,能真正掌握GLM菜单的用法,会使大家的统计分析能力有极大地提高。
实际上一般线性模型包括的统计模型还不止这些,我这里举出来的只是从用SPSS作统计分析的角度而言的一些。
好了,既然一般线性模型的能力如此强大,那么下属的四个子菜单各自的功能是什么呢?请看:∙Univariate子菜单:四个菜单中的大哥大,绝大部分的方法分析都在这里面进行。
∙Multivariate子菜单:当结果变量(应变量)不止一个时,当然要用他来分析啦!∙Repeted Measures子菜单:顾名思义,重复测量的数据就要用他来分析,这一点我可能要强调一下,用前两个菜单似乎都可以分析出来结果,但在许多情况下该结果是不正确的,应该用重复测量的分析方法才对(不能再讲了,再讲下去就会扯到多水平模型去了)。
∙Variance Components子菜单:用于作方差成份模型的,这个模型实在太深,不是一时半会说的请的,所以我在这里就干脆不讲了。
出于模型复杂性、篇幅、应用范围及乱七八糟一系列的理由,当然主要是我懒得一一解释,我决定本章采用举例讲解的方式,及讲解一些常见的分析实例,通过这种方法来熟悉那些最为常用的分析方法。
对统计分析的数据格式不太熟悉的朋友,请一定先去看看统计软件第一课:论统计软件中的数据录入格式,会大有帮助的。
§8.1两因素方差分析下面的这个例子来自《卫生统计学》第四版,书还没有出来,大家先尝尝鲜。
spss中一般线性模型解析

Simple:对预测变量或因素变量的每一水平都与参照水平进行比 较。选择Last或First作为参照水平;
Difference:对预测变量或因素每一水平的效应,除第一水平以 外,都与其前面各水平的平均效应进行比较。与Helmert对照方 法相反;
注: 只有Deviation和Simple 需要选择参考水平,Last(系统 默认)和First。
08:44
8
A、选择效应类型
Interactin:交互效应 Main effects:主效应 All2-way: 所有2维交互效应 All3-way:所有3维交互效应
All4-Way:所有4维交互效应
All5-Way:所有5维交互效应
08:44
9
B、选择模型中的主效应 (Model)
模型中包括所有3维效应,
定义效应类型为All3-way,
单击变量Llight、 Device、 Target。 单击箭头按钮, Model框中出现3维交互效应项:Ligh*Device*Target。
08:44 12
Ⅲ、选择平方和分解的方法
Sum of squares:
TYPEⅠ(嵌套设计)、 TYPEⅡ(平衡设计、仅主 效应)、 TYPE Ⅲ(系统默认、最常 用) TYPEIV(不完整数据)。
08:44
11
C. 建立模型中的交互项
模型中包括三个变量的所有2维交互效应项,
定义效应类型为All2-way, 单击light、Device、Target三个变量名, 单击箭头按钮。 Model中出现三个 2维交互效应项: Light*Device、 Light*Target、 Device*Target。
运用SPSS软件对生物统计分析
(运用SPSS软件对生物统计分析)班级学号姓名成绩SPSS方差分析在生物统计的应用摘要:方差分析是生物统计中常采用的一种方法。
如何使用统计分析软件进行方差分析来实现对研究结果的快速和科学的处理,获得正确的结论,是生物学研究中重要的一环。
本文通过实例介绍了如何使用SPSS数据分析工具进行方差分析的方法;实现了数据分析和处理的快捷、准确和直观;与Excel相比,SPSS的统计分析功能更为强大,既有利于提高数据处理效率,又降低了实验成本。
关键词:SPSS 方差分析单因变量多因素方差分析引言:生物学研究离不开统计分析,比较单一或多因素影响下各组别数据之间的差异是生物统计中常用的方法。
如何选择适当的分析软件使差异分析更加快速、便捷,对于研究者来说尤为重要。
常用的分析软件,如:SAS、BMDP、Excel和SPSS等都包含差异分析功能,一般来说所分析数据的种类、软件的功能和使用的便捷性决定了最适合软件的选择。
上述软件中SAS是功能最为强大的统计软件,是熟悉统计学并擅长编程的专业人士的首选。
而SPSS则是非统计学专业人士的首选,其分析结果清晰、直观、易于掌握。
SPSS统计分析软件是20世纪60年代末由美国斯坦福大学的三位研究生共同研制开发的,它借助于数据管理窗口和主窗口的File、Data、Transform等菜单完成,本文通过几个实例介绍了SPSS的数据管理方法以及如何利用SPSS数据分析工具进行方差分析。
l SPSS方差分析的特点方差分析又称变异分析或F检验,用于两个及两个以上样本均数差别的显著性检验。
由于受到各种因素的影响,研究所得的数据呈现波动状,造成波动的原因可分成两类,一类是不可控的随机因素,另一类是研究中施加的对结果形成影响的可控因素。
通过方差分析可评估不同来源的变异对总变异的贡献大小,从而客观地判断可控因素对研究结果影响力的大小旧。
从方差人手的研究方法有助于找到事物的内在规律性。
SPSS适用于社会学、医学、经济学和统计学等多个学科的量化研究。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
20:42
29
主要结果---描述性统计量
Between-Subjects Factors Group 1 2 3 4 Value Label 对 照 组 低 剂 量 组 中 剂 量 组 高 剂 量 组 N 15 15 15 15
Descriptive Statistics Dependent Variable: 耐 缺 氧 时 间 ( min) Group 对 照 组 低 剂 量 组 中 剂 量 组 高 剂 量 组 Total Mean 21.5467 22.8767 28.0553 31.8333 26.0780 Std. Deviation 3.42821 3.55555 4.38119 4.53727 5.69819 N 15 15 15 15 60
GLM可完成多自变量、多水平、多因变量、重复测 量方差分析以及协方差分析等。
20:42 3
Univariate(单因变量方差分析)基本过程
20:42
4
1 主对话框
Dependent Variable:因变量
Fixed Facter: 固定因子,所有可能的水 平都出现在样本中,如分组等 Random Facter: 随机因子,所有可能 的取值并不都在样本中出现,如观察个 体 Covariates:协变量,协方差分析时用
模型中包括所有3维效应,
定义效应类型为All3-way,
单击变量Llight、 Device、 Target。 单击箭头按钮, Model框中出现3维交互效应项:Ligh*Device*Target。
20:42 12
Ⅲ、选择平方和分解的方法
Sum of squares:
TYPEⅠ(嵌套设计)、 TYPEⅡ(平衡设计、仅主 效应)、 TYPE Ⅲ(系统默认、最常 用) TYPEIV(不完整数据)。
Simple:对预测变量或因素变量的每一水平都与参照水平进行比 较。选择Last或First作为参照水平;
Difference:对预测变量或因素每一水平的效应,除第一水平以 外,都与其前面各水平的平均效应进行比较。与Helmert对照方 法相反;
注: 只有Deviation和Simple 需要选择参考水平,Last(系统 默认)和First。
Sigificance level :指定Confidence intervals的显著性水平
20:42 21
Descriptive statistics:描述统计量,均值、标准差,样本量 Estimates Of effect size:效应量估计。 Observed power:检验假设的功效。 Parameter estimates:各因素变量的模型参数估计、标准误、t 检 验的t值、P值和95%的置信区间。Contrast coefficient matrix: 变换系数矩阵或L矩阵。 Homogeneity tests:方差齐性检验。 Spread Vs level plot:绘制观测量均值-标准差图、观测量均值-方 差图。 Residuals plot:绘制残差图。 Lack of fit:检查因素和因变量间的关系是否被充分描述。
20:42
11
C. 建立模型中的交互项
模型中包括三个变量的所有2维交互效应项,
定义效应类型为All2-way, 单击light、Device、Target三个变量名, 单击箭头按钮。 Model中出现三个 2维交互效应项: Light*Device、 Light*Target、 Device*Target。
一般线性模型(一)
20:42
1
一般线性模型
一般线性模型单变量分析的基本过程 完全随机设计资料的方差分析 随机区组(单位组)设计资料的方差分析
20:42
2
一、一般线性模型单变量分析的基本过程
General Linear Model(GLM,一般线性模型)
包括:
Univariate(单因变量多因素方差分析), Multivariate(多因变量方差分析), Repeated Measures(重复测量方差分析), Variance(方差分量分析)
20:42 15
2.3 Plots按钮
Factor:主对话框中所选因素 变量名; Horizontal:横坐标框 Separate Lines:确定分线变量 Separate Plots:确定分图变量
20:42
16
2.4 Post Hoc按钮
均数多重比较(事后检验)
20:42
17
2.5 Save按钮(选择保存运算值)
20:42
Unstandarized:非标准化残差 Weighted: 加权非标准化残差 Standardized:标准化残差 Studentized:学生化残差 Deleted:剔除残差
19
2.5 Save按钮(选择保存运算值)
Diagnostics(诊断值栏)
Cook’s distance:Cook距离; Leverage values:非中心化 Leverage值;
20:42
24
建立数据文件:耐缺氧时间.sav.
定义变量
20:42
25
建立数据文件:耐缺氧时间.sav.
定义变量
输入数据
20:42
26
建立数据文件:耐缺氧时 间.sav.
定义变量
输入数据
开始分析:analyze →General Linear Model →Univariate
20:42
8
A、选择效应类型
Interactin:交互效应 Main effects:主效应 All2-way: 所有2维交互效应 All3-way:所有3维交互效应
All4-Way:所有4维交互效应
All5-Way:所有5维交互效应
20:42
9
B、选择模型中的主效应 (Model)
Full Factorial,全模型,系统 默认。包括所有因素的主效应 和所有的交互效应。例如有三 个因素变量,全模型包括三个 因素的主效应、两两的交互效 应和三个因素的高级交互效应。 Custom,自定义模型。选择此 项激活下面各操作框
20:42
7
Ⅱ、建立自定义模型
Factors&Covariates 框中 自动列出可以作为因素的 变量名,其后面的括号中 标有字母“F”(固定因 子)、“R”(随机因子) 或者“C”(协变量)。
20:42
23
表1 各组小白鼠耐缺氧时间/min
对照组 21.31 23.48 23.14 20.34 27.48 26.98 19.54 19.56 18.03 17.39 24.03 24.37 22.82 16.01 18.72 低剂量组 20.16 26.13 24.49 25.24 21.32 20.23 19.46 22.47 25.63 29.38 28.81 20.16 18.74 22.51 18.42 中剂量组 35.07 24.33 28.11 33.97 24.74 21.86 29.79 28.65 22.68 25.13 23.01 34.44 28.32 31.69 29.04 高剂量组 30.23 38.47 36.84 35.10 38.61 28.01 27.13 23.37 28.79 28.44 33.24 34.22 31.68 35.08 28.29
20:42
28
建立数据文件:耐缺氧时间.sav.
定义变量 输入数据
开始分析:analyze →General Linear Model →Univariate
Y→Dependent Variable Group→Fixed Factors
Post Hoc :
Options:Group → Display Means for Descriptive Statistics, Homogeneity tests
Y→Dependent Variable
Group→Fixed Factors
20:42
27
建立数据文件:耐缺氧时间.sav.
定义变量 输入数据 开始分析:analyze →General Linear Model →Univariate
Y→Dependent Variable Group→Fixed Factors Post Hoc : Group → Post Hoc Tests for LSD,SNK, Bonferroni
Save to new file
将参数协方差矩阵保存到一个 新文件中
20:42
20
2.6 Option按钮(选择输出项)
Display Means for:显示分组因素
Display:指定输出的统计量
Descriptive statistics:描述统计量,均值、 标准差,样本量 Estimates Of effect size:效应量估计。 Observed power:检验假设的功效。 Parameter estimates:各因素变量的模型 参数估计、标准误、t 检验的t值、P值和 95%的置信区间。
20:42
13
2.2 Contrasts按钮
Factors框中显示出所有在 主对话框中选中的因素, 其后的括号中是当前的对 比方法了; Change Contrast栏中改变 对照方法。