计量经济学案例eviews
计量经济学-eviews实验报告

计量经济学作业院系:商学院国贸三班教室:高辉姓名:***学号:************INDEX问题 (2)模型设定 (3)检验异方差 (4)图形检验 (4)Glejser检验 (5)White检验 (6)调整异方差 (6)习题5.8表5.13给出的是1998年我国重要制造业销售收入与销售利润的数据表5.13试完成以下问题:1)求销售利润与销售收入的样本回归函数,并对模型进行经济意义检验和统计检验;2)分别用图形法、Glejser方法、White方法检验模型是否存在异方差;3)如果模型存在异方差,选用适当的方法对异方差性进行修正。
1)假定销售利润与销售收入之间满足线性约束,则理论模型设定为Y i = β1 + β2X I + u i其中,Y i表示销售利润,表示销售收入。
Dependent Variable: YMethod: Least SquaresDate: 12/26/09 Time: 14:45Sample: 1 28Included observations: 28Variable Coefficient Std. Error t-Statistic Prob.C 12.03564 19.51779 0.616650 0.5428X 0.104393 0.008441 12.36670 0.0000R-squared 0.854696 Mean dependent var 213.4650Adjusted R-squared 0.849107 S.D. dependent var 146.4895S.E. of regression 56.90368 Akaike info criterion 10.98935Sum squared resid 84188.74 Schwarz criterion 11.08450Log likelihood -151.8508 Hannan-Quinn criter. 11.01844F-statistic 152.9353 Durbin-Watson stat 1.212795Prob(F-statistic) 0.000000图1估计结果为Yˆi = 12.03564 + 0.104393X i(0.61665)(12.3667)R2 = 0.8547,F = 152.94括号内为t统计量值。
计量经济学EVIEWS模型案例

数据收集
数据来源: 《中国统计年鉴》 其中:
Y ——各项税收收入(亿元)
X2——国内生产总值(亿元) X3——财政支出(亿元) X4——商品零售价格指数(%)
参数估计
假定模型中随机项满足基本假定,可用 假定模型中随机项满足基本假定,可用OLS法估计 法估计 其参数。具体操作: 软件, 其参数。具体操作:用EViews软件,估计结果为: 软件 估 X2t + β2 X3t + β3 X4t + ut
其中: 其中: 各项税收收入(亿元) Y — 各项税收收入(亿元) X2 — 国内生产总值(亿元) 国内生产总值(亿元) X3 — 财政支出(亿元) 财政支出(亿元) 商品零售价格指数( ) X4 — 商品零售价格指数(%)
上机要求: 上机要求:
1、更新数据至2009年,并对模型进行估 计和检验; 2、上网查2010年各解释变量的数据,求 出2010年税收收入的点预测和区间预测, 并与实际值进行比较分析; 3、形成报告于下次上机课上交打印稿。
R 2 = 0.9971
F = 2717.238
df = 21
模型检验: 模型检验: 拟合优度: 较高, 拟合优度:可决系数 R 2 = 0.9974 较高, R 2 = 0.9971 也较高, 修正的可决系数 也较高, 表明模型拟合较好。 表明模型拟合较好。
显著性检验
F检验: 针对 H0 : β2 =,取β4 = 0 检验: 检验 β3 = 查自由度为 k -1=3 和 的临界值 n - k =21
理论分析 影响中国税收收入增长的主要因素可能有: 影响中国税收收入增长的主要因素可能有: (1)从宏观经济看,经济整体增长是税收增长的 )从宏观经济看, 基本源泉。 基本源泉。 2) (2)社会经济的发展和社会保障等都对公共财政 提出要求, 提出要求,公共财政的需求对当年的税收收入可 能会有一定的影响。 能会有一定的影响。 (3)物价水平。中国的税制结构以流转税为主, )物价水平。中国的税制结构以流转税为主, 以现行价格计算的GDP和经营者的收入水平都与 以现行价格计算的 和经营者的收入水平都与 物价水平有关。 物价水平有关。 (4)税收政策因素。 )税收政策因素。
EViews统计分析在计量经济学中的应用综合案例

计量经济学创新实验设计
我们以方正科技(600601)为例,介绍如何通过Eviews 软件进行系数的回归估计。
打开Eviews6.0,选择File-New-Workfile,frequency选择integer date,时间为1至200,点击确定。
计量经济学创新实验设计
计量经济学创新实验设计
二.资本资产定价模型及其检验方法介绍
各种股票的收益和风险呈现正相关,每种资
产的收益由无风险收益和风险贴水两部分构成。 可表示为:
E Ri Rf i E Rm Rf
(1)
其中: E Ri 为股票的期望收益率; Rf 为无风险收益率、 E Rm 为市场证券组合的
期望收益率; i 是股票 i 收益和市场组合收益间的协方差im 与市场组合收益方差 m 2 的比
值,即 i
im
2 m
,常被称为“
系数”(可以看作某种股票收益变动对市场组合收益变
动的敏感度)。
计量经济学创新实验设计
假设关于任何资产的收益是一个公平博弈,换句 话说就是任何资产已实现的平均收益率等于其预 期的收益率。数学上有如下形式:
Rit E Rit imt eit
(2)
其 中 , mt Rmt E Rmt , E mt 0 , eit 为 随 机 误 差 项 , 且 E eit 0 ,
covemt
, eit
0
,
cov eit ,eit1
0
,
i
cov Rmt
,
Rit
Var
Rmt
。
计量经济学创新实验设计
出现下图后,点击Object-New Object,在Type of object中 选择seriers,,并命名为SY和MY,从而创建两个序列。
【能源消费】EViews计量经济学实验
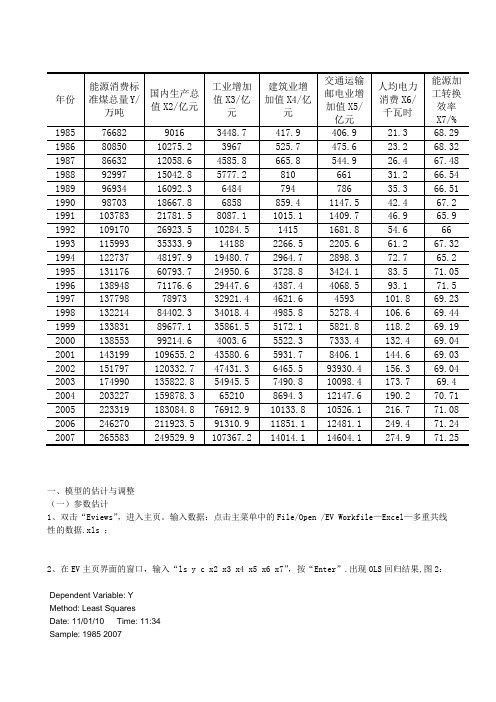
一、模型的估计与调整(一)参数估计1、双击“Eviews”,进入主页。
输入数据:点击主菜单中的File/Open /EV Workfile—Excel—多重共线性的数据.xls ;2、在EV主页界面的窗口,输入“ls y c x2 x3 x4 x5 x6 x7”,按“Enter”.出现OLS回归结果,图2:Dependent Variable: YMethod: Least SquaresDate: 11/01/10 Time: 11:34Sample: 1985 2007Included observations: 23Variable Coefficient Std. Error t-Statistic Prob.C 168326.2 108641.0 1.549381 0.1408 X2 -0.142290 0.763550 -0.186353 0.8545 X3 0.503108 0.248552 2.024157 0.0600 X4 8.294237 10.43112 0.795143 0.4382 X5 -0.203037 0.111019 -1.828841 0.0861 X6 233.9125 388.5188 0.602062 0.5556 X7-1373.3761588.868-0.8643730.4002R-squared0.980436 Mean dependent var 139364.6 Adjusted R-squared 0.973099 S.D. dependent var 51705.05 S.E. of regression 8480.388 Akaike info criterion 21.17469 Sum squared resid 1.15E+09 Schwarz criterion 21.52028 Log likelihood -236.5089 F-statistic 133.6365 Durbin-Watson stat 1.380303 Prob(F-statistic)0.000000由此可见,该模型的可决系数为0.995,修正的可决系数为0.993,模型拟和很好,F 统计量为701.47,模型拟和很好,回归方程整体上显著。
计量经济学案例分析(Eviews操作)

美股行情对A股的影响性分析——标普500与沪深300相关性分析摘要:本文主要通过分析标准普尔500指数与沪深300指数的相关性,以标普500指数为解释变量,以沪深300指数为被解释变量,利用Eviews软件,使用其中的最小二乘法对其进行线性回归分析,最终得出方程。
并对其进行显著性检验(F,t)、异方差检验、自相关性检验来验证方程的可靠性。
然后解释方程的经济意义,并利用软件对未来指数变动进行预测。
最后在未来几天比较预测结果与实际两个指数的变化情况,验证实际应用情况。
关键词:标普500、沪深300、Eviews、显著性检验、异方差检验、自相关性检验。
一、研究背景1.全球化大环境在经济全球化不断深入发展的今天,全球资本市场,尤其是中美两个超级大国之间的资本流通,早已彼此嵌入,密不可分。
全世界早有不少学者对中美资本流通做了深入研究。
但美国股市发展早于中国十几年,其内部的资金也远远超过中国股市,美国股市的资本流动势必会对中国股市产生一定影响,这种影响不仅体现在情绪面,更反映在指数变动方向上。
2.对外开放资本市场的QFII政策Qualified Foreign Institutional Investor,作为一种过渡性制度安排,QFII制度是在资本项目尚未完全开放的国家和地区,实现有序、稳妥开放证券市场的特殊通道。
外资对中国股市的影响早已不可忽视,而美国市场的变动也一定程度会影响在中国股市外资的操作行为。
所以研究两个指数的变动是很有意义的。
二、数据1.数据选择沪深两个市场各自均有独立的综合指数和成份指数,这些指数不能用来反映沪深两市的整体情况,而沪深300指数则同时考虑了两市的交易情况,是中国A股市场的“晴雨表”。
标准普尔500指数英文简写为S&P 500 Index,是记录美国500家上市公司的一个股票指数。
与道琼斯指数等其他指数相比,标准普尔500指数包含的公司更多,因此风险更为分散,能够反映更广泛的市场变化。
用Eviews分析计量经济学问题

计量经济学案例分析一、问题背景高新区自开始设立至今短短十多年的时间,以其惊人的经济发展速度为世人所关注。
随着我国经济发展模式的逐步转变,高新区已经成为我国依靠科技进步和技术创新推动经济社会发展、走中国特色自主创新道路的一面旗帜。
“十二五”时期,面对新的机遇和挑战,国家高新区应注重提升五种能力,努力成为加快转变经济发展方式的排头兵。
为了探索高新经济发展的内在规律性,本文采用截面数据对高新区的投入产出进行分析,力求能够增进对高新区经济发展的了解,对高新区的进一步发展有所帮助。
二、模型设定本文研究的是高新区投入对产出的影响,所以本模型的被解释变量Y 即为高新区的产出。
就目前对高新区数据的统计来看,反映高新区产出的主要有“工业总产值”、“工业增加值”、“技工贸总收入”、“利润”和“上缴税额”几个总量指标。
按照生产函数理论,产出利用增加值,所以模型中我们将使用“工业增加值”指标数据来估计各高新区的总产出。
从高新区的投入来看,对产出有重要影响的因素主要包括以下几个方面:资本K ,劳动力L ,技术投入T ,此外,体制改革,管理模式创新也可以看作是投入的要素,但因其不可量化,因此归入模型的扰动项中。
这样,按照科布道格拉斯形式的生产函数,我们设定函数形式为:u T L AK Y γβα= 两边取自然对数得:u T L K A Y ln ln ln ln ln ln ++++=γβα其中,资本数据K 我们利用的是当年的年末净资产来进行估计,即当年年末资产减去当年年末负债后得到的数据;用当年年末从业人员来估计劳动力L ;用当年技术研发投入来估计技术投入T 。
数据选用的是截面数据。
从《国家高新技术产业开发区十年发展报告(1991-2000年)》得到1999年全国53个高新区各项指标统计数据:三、模型估计用Eviews 软件进行回归分析,得到如下结果:Dependent Variable: Y Method: Least SquaresDate: 13/12/11 Time: 19:31 Sample: 1 53C 0.664556 0.644854 1.030553 0.3078 LNK 0.478131 0.171585 2.786560 0.0076 LNL 0.367855 0.174496 2.108104 0.0402 R-squared0.740558 Mean dependent var6.280427Adjusted R-squared 0.724674 S.D. dependent var 0.440805 S.E. of regression 0.231297 Akaike info criterion -0.017755Sum squared resid 2.621421 Schwarz criterion 0.130946 Log likelihood4.470508 F-statistic 46.62236从表可以看出,回归方程为:TL K Y ln 140542.0ln 367855.0ln 478131.0664556.0ln +++=T= (1.030553) (2.786560) (2.109104) (1.520604)740558.02=R 724674.02=R(1) 经济意义检验从回归结果可以看出,模型估计的γβα,,的参数值都为正、且小于1,与生产函数理论中γβα,,各数值的意义相符。
计量经济学---EViews的基本操作案例
说明总离差平方和的99.88%被样本回归直线解释,仅有0.12%未被解释,因此,样
本回归直线对样本点的拟合优度很高。也即用人均年收入解释消费性支出变化效 果很好。
回归系数显著性检验(t检验)
提出原假设H0:β 1=0 备择假设H1:β 1≠0
取显著性水平α =0.05,在自由度为v=17-2=15下,查t分布表,得:t
R² =0.998726
F=12952.03 n=17 DW=1.025082
(7)回归预测
点估计。假定预测出2002年、2003年的平均每人年收入分别为
X2002=6932.91元,X2003=7334.37元。预测Ŷ2002,Ŷ2003的值。
将X2002=6932.91,X2003=7334.37代入估计的回归方程的点估计值 Ŷ2002=132.0125+0.768761*6932.91=5461.76(元)
(3)画散点图
确定了模型后,需要在直观上初步探明变量之间的相互关系,
为此,以人均年收入为横轴,以人均年消费支出为纵轴,描 出样本变量观测值的散点分布图。如下图所示:
根据上图散点分布情况可以看出,在1985~2001年期间,我国城镇
居民人均年消费和可支配收入之间存在较为明显的线性关系。
(4)显示估计结果Fra bibliotekTHANKS
利用Eviews的最小二乘法程序,输出的结果如下: Dependent Variable(从属变量):Y Method:Least Squares(最小二乘法) Sample:1985 2001 Included observations:17
(5)模型检验
可决系数检验:R² =1-ESS/TSS=0.9988
Xi——表示城镇居民人均年收入水平 ui——表示随机误差项 现给定样本观测值(Xi,Yi),i=1,2,…,17,n=17为样本容量。则建立样 本回归模型:Yi=β0+β1Xi+ei 其中,β0,β1分别为β0、β1的估计值,ei为残差项。样本回归方程: Ŷi=β0+β1Xi 其中,Ŷi表示样本观测值Yi的估计值。
基于EVIEWS软件的计量经济学建模检验案例解读
基于EVIEWS软件的计量经济学建模检验案例解读计量经济学是经济学领域的一个重要分支,它运用数理统计方法对经济学模型进行定量分析和预测。
而EVIEWS软件则是计量经济学常用的数据分析与建模工具。
本文将通过一个实例案例,解读基于EVIEWS软件的计量经济学建模检验的方法和过程。
首先,我们需要了解案例的背景和研究问题。
假设我们想研究某国家的经济增长与就业率之间的关系。
我们提出了一个假设:经济增长对就业率有积极的影响。
第一步是数据收集和准备。
我们需要收集与经济增长和就业率相关的数据。
以中国为例,我们可以从国家统计局等官方机构获取国内生产总值(GDP)和就业率的数据。
这些数据应该是时间序列数据,通常包括一定的时间跨度和频率(例如月度或年度数据)。
第二步是数据预处理。
我们需要对收集到的数据进行清洗和处理,以确保数据的质量。
具体来说,我们需要检查数据是否存在缺失值、异常值等,确保数据的连续性和一致性。
第三步是建立计量经济学模型。
在本案例中,我们使用一个简单的线性回归模型来研究经济增长对就业率的影响。
假设就业率(Y)是经济增长(X)的线性函数,即Y = β0 +β1X + ε,其中β0和β1是回归系数,ε是误差项。
第四步是模型检验。
在EVIEWS软件中,我们可以利用OLS(Ordinary Least Squares)方法进行模型的估计和检验。
OLS方法是最小二乘法的一种形式,用于估计回归系数的值。
此外,我们还可以通过检验模型的显著性和拟合优度来评估模型的质量。
具体来说,我们可以通过检验回归系数的t值和p值来判断是否存在统计显著性。
如果t值的绝对值较大且p值小于设定的显著性水平(通常是0.05),则可以认为回归系数是显著的,即具有统计意义。
此外,我们还可以计算回归方程的R-squared值来评估模型的拟合优度,R-squared值越接近1,说明模型的解释能力越强。
最后,我们需要进行模型诊断。
模型诊断用于检验回归模型的假设是否成立,以及模型是否满足统计方法的要求。
计量经济学操作实验及案例分析
计量经济学课程实验实验一 EViews软件的基本操作【实验目的】了解EViews软件的基本操作对象,掌握软件的基本操作。
【实验内容】一、EViews软件的安装;二、数据的输入、编辑与序列生成;三、图形分析与描述统计分析;四、数据文件的存贮、调用与转换。
实验内容中后三步以表1-1所列出的税收收入和国内生产总值的统计资料为例进行操作。
单位:亿元资料来源:《中国统计年鉴1999》【实验步骤】一、安装EViews软件㈠EViews对系统环境的要求⒈一台386、486奔腾或其他芯片的计算机,运行Windows3.1、Windows9X、Windows2000、WindowsNT或WindowsXP操作系统;⒉至少4MB内存;⒊VGA、Super VGA显示器;⒋鼠标、轨迹球或写字板;⒌至少10MB以上的硬盘空间。
㈡安装步骤⒈点击“网上邻居”,进入服务器;⒉在服务器上查找“计量经济软件”文件夹,双击其中的setup.exe,会出现如图1-1所示的安装界面,直接点击next按钮即可继续安装;⒊指定安装EViews软件的目录(默认为C:\EViews3,如图1-2所示),点击OK按钮后,一直点击next按钮即可;⒋安装完毕之后,将EViews的启动设置成桌面快捷方式。
图1-1 安装界面1图1-2 安装界面2二、数据的输入、编辑与序列生成 ㈠创建工作文件 ⒈菜单方式启动EViews 软件之后,进入EViews 主窗口(如图1-3所示)。
图1-3 EViews 主窗口在主菜单上依次点击File/New/Workfile ,即选择新建对象的类型为工作文件,将弹出一个对话框(如图1-4所示),由用户选择数据的时间频率(frequency )、起始期和终止期。
图1-4 工作文件对话框其中, Annual ——年度 Monthly ——月度Semi-annual ——半年 Weekly ——周 Quarterly ——季度 Daily ——日 Undated or irregular ——非时序数据工作区域状态栏选择时间频率为Annual(年度),再分别点击起始期栏(Start date)和终止期栏(End date),输入相应的日前1985和1998。
计量经济学EIVEWS实验步骤和案例
一元线性回归检验个人的收入与消费是密不可分的,为了考察城镇居民可支配收入和其人均消费支出的关系,利用计量经济学的方法进行回归。
1990-2011年城镇居民可支配收录和人均消费支出数据如表1.1所示表1.1 城镇居民可支配收录和人均消费支出图2-1数据来源:《中国民政统计年鉴2012》作城镇居民可支配收录(X)和人均消费支出(Y)的散点图图2. 2从散点图可以看出居民家庭平均每人每年消费支出(Y)和城市居民人均年可支配收入(X)大体呈现为线性关系,所以建立的计量经济模型为如下线性模型:12i i i Y X u ββ=++三、估计参数假定所建模型及随机扰动项i u 满足古典假定,可以用OLS 法估计其参数。
运用计算机软件EViews 作计量经济分析十分方便。
利用EViews 作简单线性回归分析的步骤如下:1、建立工作文件首先,双击EViews 图标,进入EViews 主页。
在菜单一次点击File\New\Workfile图2-3选择数据类型和起止日期。
时间序列提供起止日期(年、季度、月度、周、日),非时间序列提供最大观察个数。
本例中在Start Data 里输入1990,在End data 里输入2011,见图2-3。
单击OK 后屏幕出现Workfile 工作框,如图2-4所示。
图2-4二、输入和编辑数据建立或调入工作文件以后,可以输入和编辑数据。
在主菜单上单击Quick→Empty Group(见图2-5)图2-5再用方向键将光标移到每一列的顶部之后,输入各个变量名,回车后输入数据(见图2-7)。
另外数据还可以从Excel中直接复制到空组。
然后为每个时间序列取序列名。
单击数据表中的SER01,在数据组对话框中的命令窗口输入该序列名称,如本例中输入X,回车后Yes。
采用同样的步骤修改序列名Y(见图2-8)。
数据输入操作完成。
图2-8数据输入完毕,单击工作文件窗口工具条的Save或单击菜单兰的File→Save将数据存入磁盘。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
案例分析
1.问题的提出和模型的设定
根据我国1978—1997年的财政收入Y 和国民生产总值X 的数据资料,分析财政收入和国民生产总值的关系建立财政收入和国民生产总值的回归模型。
假定财政收入和国民收入总值之间满足线性约束,则理论模型设定为
i i i u X Y ++=21ββ
其中i Y 表示财政收入,i X 表示国民生产总值。
表1
我国1978—1997年财政收入和国民生产总值
2.参数估计
进入EViews 软件包,确定时间范围;编辑输入数据;选择估计方程菜单,估计样本回归函数如下
表 2
obs
X Y 1978
3624.100 1132.260 1979
4038.200 1146.380 1980
4517.800 1159.930 1981
4860.300 1175.790 1982
5301.800 1212.330 1983
5957.400 1366.950 1984
7206.700 1624.860 1985
8989.100 2004.820 1986
10201.40 2122.010 1987
11954.50 2199.350 1988
14922.30 2357.240 1989
16917.80 2664.900 1990
18598.40 2937.100 1991
21662.50 3149.480 1992
26651.90 3483.370 1993
34560.50 4348.950 1994
46670.00 5218.100 1995
57494.90 6242.200 1996
66850.50 7407.990 1997 73452.50 8651.140
估计结果为
Y=858.3108 + 0.100031X
(12.78768) (46.04788)
R^2=0.991583 S.E.=208.508 F=2120.408
括号内为t统计量值。
3.检验模型的异方差
(一)图形法
1、EViews软件操作。
由路径:Quick/Qstimate Equation,进入Equation Specification窗口,键入“y c x”,确认并“ok”,得样本回归估计结果,见表2。
(1)生成残差平方序列。
在得到表2估计结果后,立即用生成命令建立序列
2
i
e
,记为
e2。
生成过程如下,先按路径:Procs/Generate Series,进入Generate Series by Equation 对话框,即
然后,在Generate Series by Equation对话框中(如图1),键入“e2=(resid)^2”,则
生成序列
2
i
e。
(2)绘制
2
t
e
对t
X
的散点图。
选择变量名X与e2(注意选择变量的顺序,先选的变量
将在图形中表示横轴,后选的变量表示纵轴),进入数据列表,再按路径view/graph/scatter,可得散点图,见图2
2、判断。
由图2可以看出,残差平方
2
i
e
对解释变量X的散点图主要分布在图形中的下
三角部分,大致看出残差平方
2
i
e
随i
X的变动呈增大的趋势,因此,模型很可能存在异方差。
但是否确实存在异方差还应通过更进一步的检验。
(二)Goldfeld-Quanadt检验
1、EViews软件操作。
(1)对变量取值排序(按递增或递减)。
在Procs菜单里选Sort Series命令,出现排序对话框,如果以递增型排序,选Ascenging,如果以递减型排序,则应选Descending,键入X,点ok。
本例选递增型排序,这时变量Y与X将以X按递增型排序。
(2)构造子样本区间,建立回归模型。
在本例中,样本容量n=20,删除中间4个的观测值,余下部分平分得两个样本区间:1978-1985和1990-1997,它们的样本个数均是8个。
在Sample菜单里,将区间定义为1978-1985,然后用OLS方法求得如下结果
表3
在Sample菜单里,将区间定义为1990-1997,再用OLS方法求得如下结果
表4
(3)求F统计量值。
基于表3和表4中残差平方和的数据,即Sum squared resid的值。
由表3计算得到的残差平方和为35130.06,由表4计算得到的残差平方和为508664,根据Goldfeld-Quanadt检验,F统计量为14.4795。
(4)判断。
因为F=14.4795>临界值,所以拒绝原假设,表明模型确实存在异方差。
四、异方差性的修正
(一)加权最小二乘法(WLS)
在运用WLS法估计过程中,我们分别选用了权数w1,w2,w3。
权数的生成过程如下,由图1,在对话框中的Enter Quation处,按如下格式分别键入:w1=1/x;w2=1/x^2;w3=1/sqr(x),经估计检验发现用权数w3的效果最好。
下面仅给出用权数w3的结果。
表 5
估计结果如下:
Y=790.2419 + 0.1031 X
(17.4237)(33.0780)
R^2=0.9838 D.W.=0.7723 S.E.=167.4993 F=1094.154 括号内为t统计量值。
可以看出运用加权小二乘法消除了异方差性后,参数的t检验均显著,可决系数大幅提高,F检验也显著,并说明国民生产总值每增加1亿元,平均说来财政收入将增加0.1031亿元,而不是引子中得出的增加0.100031亿元。
虽然这个模型可能还存在某些其他需要进一步解决的问题,但这一估计结果或许比引子中的结论更为接近真实情况。