Spss大作业
统计应用spss大作业-多因素分析
影响我国居民私家车拥有量的因素分析xxx xxx xxx自我国加入世界贸易组织后,中国汽车市场大举对外开放,带动了国内汽车产业的迅速发展。
国家又出台了一系列鼓励轿车进入家庭的政策,长期以公车消费为主的轿车市场转变为以私人消费为主,私人购车成为当今轿车市场消费的主流。
随着私人轿车消费时代的到来,私人轿车成为拉动私家车拥有量大幅上升的主要因素。
截至2011年11月,我国机动车保有量达2.23亿辆,汽车保有量达1.04亿辆。
大中城市中汽车保有量达到100万辆以上的城市数量达14个。
目前全球汽车保有量约为10亿辆,中国占据了其中的10%。
中国的汽车保有量已经超过日本,成为仅低于美国(2010年2.4亿辆)的世界第二大汽车保有国,业内预计,2020年我国汽车保有量将突破2亿辆。
中国已经成为世界第一大汽车消费市场,汽车销售业成为热门,影响汽车销量的因素越发引起人们的关注。
本文就通过计量模型来分析除了汽车本身的价格外,其他因素如公路里程、全国汽车产量、人均可支配收入、财政收入等多个变量对私家车拥有量的影响。
1 居民私家车拥有量影响因素的选择能够影响居民私家车拥有量的因素非常多,诸如国家财政收入、居民可支配收入、公路里程、全国汽车产量、人均粗钢产量、居民消费水平和原油价格等等。
国家财政收入是政府履行其职能、实施公共政策和提供公共物品与服务需要的基础,是衡量一国政府财力的重要指标,政府在社会经济活动中提供公共物品和服务的范围和数量在很大程度上取决于财政收入的充裕状况,这一指标将影响国内经济的方方面面。
所以,这一指标被选作居民私家车拥有量的影响因素。
居民拥有私家车的前提是汽车消费,而收入是消费的基础,也是影响消费最重要的因素。
本文考虑居民可支配收入对汽车保有量的影响。
公路建设是汽车行驶的基础,所以公路里程对私家车拥有量有很重要的影响,本文将公路里程也作为影响居民汽车保有量的因素。
综上所述,本研究以分析我国居民私家车拥有量的影响因素为目的,选择了1991——2010年的数据为样本,如表1所示。
研究生SPSS作业
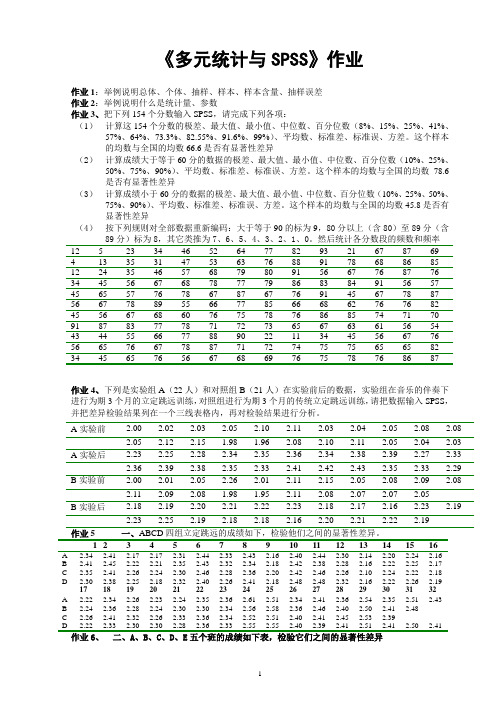
《多元统计与SPSS》作业作业1:举例说明总体、个体、抽样、样本、样本含量、抽样误差作业2:举例说明什么是统计量、参数作业3、把下列154个分数输入SPSS,请完成下列各项:(1)计算这154个分数的极差、最大值、最小值、中位数、百分位数(8%、15%、25%、41%、57%、64%、73.3%、82.55%、91.6%、99%)、平均数、标准差、标准误、方差。
这个样本的均数与全国的均数66.6是否有显著性差异(2)计算成绩大于等于60分的数据的极差、最大值、最小值、中位数、百分位数(10%、25%、50%、75%、90%)、平均数、标准差、标准误、方差。
这个样本的均数与全国的均数78.6是否有显著性差异(3)计算成绩小于60分的数据的极差、最大值、最小值、中位数、百分位数(10%、25%、50%、75%、90%)、平均数、标准差、标准误、方差。
这个样本的均数与全国的均数45.8是否有显著性差异(4)按下列规则对全部数据重新编码:大于等于90的标为9,80分以上(含80)至89分(含89分)标为8,其它类推为7、6、5、4、3、2、1、0。
然后统计各分数段的频数和频率12 5 23 34 46 52 64 77 82 93 21 67 87 694 13 35 31 47 53 63 76 88 91 78 68 86 8512 24 35 46 57 68 79 80 91 56 67 76 87 7634 45 56 67 68 78 77 79 86 83 84 91 56 5745 65 57 76 78 67 87 67 76 91 45 67 78 8756 67 78 89 55 66 77 85 66 68 62 76 76 8245 56 67 68 60 76 75 78 76 86 85 74 71 7091 87 83 77 78 71 72 73 65 67 63 61 56 5443 44 55 66 77 88 90 22 11 34 45 56 67 7656 65 76 67 78 87 71 72 74 75 75 65 65 8234 45 65 76 56 67 68 69 76 75 78 76 86 87作业4、下列是实验组A(22人)和对照组B(21人)在实验前后的数据,实验组在音乐的伴奏下进行为期3个月的立定跳远训练,对照组进行为期3个月的传统立定跳远训练,请把数据输入SPSS,并把差异检验结果列在一个三线表格内,再对检验结果进行分析。
SPSS作业(1-5章)3.27

第一章 SPSS概述1. SPSS有哪些主要窗口?它们的作用和特点各是什么?2. SPSS有哪三种主要使用方式?各自的特点是什么?3. .sav,.spo,.sps分别是哪类文件的扩展名?4.在SPSS的输出窗口中应如何操作才能将不同的分析结果保存到不同的文件中?5.SPSS的数据加工和管理功能主要集中在哪些菜单中?统计绘图和分析功能主要集中在哪些菜单中?6.利用SPSS进行数据分析的一般基本步骤是什么?第二章SPSS数据文件的建立和管理1. SPSS中有哪两种基本数据组成方式?各自的特点和应用场合是什么?2. 在定义SPSS数据结构时,默认的变量名和变量类型是什么?如果希望增强SPSS统计分析结果的易读性,还需要对数据结构的哪些方面进行必要说明?3你认为SPSS数据窗口与Excel工作表在基本操作方式和数据组织方式方面有什么异同?4.先自己建立两个数据文件:“学生成绩一.sav”和“学生成绩二.sav”,分别存放关于学生学号、性别、和若干门课程成绩的数据,然后将这两个数据文件横向合并,形成一个完整的数据文件。
6根据P18案例2-2建立数据文件,要求完整的数据结构。
7针对当前社会或社会关心的热点问题,以小组形式设计一份调查问卷并进行调查。
试在SPSS中录入所获得的调查数据形成一份SPSS数据文件。
其中,变量的类型应包括字符型和数字型,变量的计量尺度应包括定距型、定类型和定序型。
如果调查资料中存在缺失数据,应在SPSS数据文件的建立过程中进行必要的定义说明。
第三章SPSS数据的预处理1.利用数据筛选功能,将住房状况调查.sav生成两个文件,其中第一个文件存储户口为“外地户口”且家庭收入在10000-15000之间的数据;第二个文件存储按简单随机抽样抽取的70%的样本数据2.利用住房状况调查.sav 将其按家庭收入(升序)、现住面积(升序)、计划面积(降序)进行多重排序。
3.利用学生成绩表.sav 对每个学生计算得优课程数和得良课程数,并按得优课程数进行降序排列。
SPSS操作实验作业1(附答案)

SPSS操作实验 (作业1)作为华夏儿女都曾为有着五千年的文化历史而骄傲过,作为时代青年都曾为中国所饱受的欺压而愤慨过,因为我们多是炎黄子孙。
然而,当代大学生对华夏文明究竟知道多少呢某研究机构对大学电气、管理、电信、外语、人文几个学院的同学进行了调查,各个学院发放问卷数参照各个学院的人数比例,总共发放问卷250余份,回收有效问卷228份。
调查问卷设置了调查大学生对传统文化了解程度的题目,如“佛教的来源是什么”、“儒家的思想核心是什么”、“《清明上河图》的作者是谁”等。
调查问卷给出了每位调查者对传统文化了解程度的总得分,同时也列出了被调查者的性别、专业、年级等数据信息。
请利用这些资料,分析以下问题。
问题一:分析大学生对中国传统文化的了解程度得分,并按了解程度对得分进行合理的分类。
问题二:研究获得文化来源对大学生了解传统文化的程度是否存在影响。
要求:直接导出查看器文件为.doc后打印(导出后不得修改)对分析结果进行说明,另附(手写、打印均可)。
于作业布置后,1周内上交本次作业计入期末成绩答案问题一操作过程1.打开数据文件作业。
同时单击数据浏览窗口的【变量视图】按钮,检查各个变量的数据结构定义是否合理,是否需要修改调整。
2.选择菜单栏中的【分析】→【描述统计】→【频率】命令,弹出【频率】对话框。
在此对话框左侧的候选变量列表框中选择“X9”变量,将其添加至【变量】列表框中,表示它是进行频数分析的变量。
3.单击【统计量】按钮,在弹出的对话框的【割点相等组】文本框中键入数字“5”,输出第20%、40%、60%和80%百分位数,即将数据按照题目要求分为等间隔的五类。
接着,勾选【标准差】、【均值】等选项,表示输出了解程度得分的描述性统计量。
再单击【继续】按钮,返回【频率】对话框。
4.单击【图表】按钮,勾选【直方图】和【显示正态曲线】复选框,即直方图中附带正态曲线。
再单击【继续】按钮,返回【频率】对话框。
最后,单击【确定】按钮,操作完成。
spss数分大作业北交大

第二题:利用居民储蓄调查数据,从中随机选取75%的样本,进行分析,实现以下目标:1、分析不同户口储户的储蓄目的(一),只输出图形并进行分析即可,不需要输出频数表格;2、分析城镇和农村储户对“未来收入状况的变化趋势”是否持相同的态度;3 、分析储户一次存款金额的分布,并检验储户的一次存款金额的均值为4500元, 是否可信?基本思路由于本题只需要“从中随机选取75%的样本,进行分析”,所以需要用到数据选取一项。
数据选取的方式很多,依本题思路看,属于随机抽样即近似抽样和精确抽样。
操作步骤数据--选择个案--随机个案样本,点开下面的样本--大约个案填写75%结果结果的解释和结论其中会多出生成一个名为filter_$的新变量,取值为1或0。
1表示本个案被选中,0表示未被选中。
该变量是SPSS产生的中间变量,如果删除它则自动取消样本抽样。
1、分析不同户口储户的储蓄目的(一),只输出图形并进行分析即可,不需要输出频数表格;基本思路首先进行多选项分析,对多选项变量集进行频数分析;对不同职业储户储蓄目的进行分析,采用多选项交叉分组下的频数分析操作步骤分析---描述统计---交叉表---行选择目的一,列选择户口,勾选显示条形图和取消表格。
结果结果分析:从条形图来看,城市户口的人比农村户口的人购买能力强,二者在正常生活零用方面花费最大。
其次,城市人口的花销重心还在买高档消费商品和结婚用品上,说明城镇户口的生活水平高。
2.分析城镇和农村储户对“未来收入状况的变化趋势”是否持相同的态度基本思路:该问题列联表的行变量为户口,列变量为未来收入状况,在列联表中输出各种百分比、期望频数、剩余、标准化剩余,显示各交叉分组下频数分布柱形图,并利用卡方检验方法,对城镇和农村储户对该问题的态度是否一致进行分析。
操作步骤:分析→描述统计→交叉表,显示复式条形图前打勾,行选择户口,列选择未来收入情况,统计量选择卡方,点击单元格,在观察值、期望值、行、列、总计、四舍五入单元格计数前打勾,最后确认果:结结果解释和结论:),对应的自由度为3(df=3),显著性水平值为0.021<0.05,故可认为实际次数与理论次数有差异。
SPSS作业【完整版】

《SPSS数据分析》实验教学调查报告南广学院学生人际交往能力调查报告团队成员:蒋中青李云聪殷娜郑春春组序: 7专业:舆情与媒介调查年级: 2007指导教师:谢蓓教师职称:讲师目录一.测量主题-----------------P3 二.主题的来源---------------P3 三.主题的确定---------------P3 四.文献综述-----------------P3 五.相关名词的定义-----------P7 六.维度图-------------------P8 七.维度名词的解释-----------P8 八.研究假设-----------------P8 九.研究方案-----------------P9 十.研究构架---------------- P9 十一. 数据处理----------------P10 十二.结论--------------------P11 十三.附件问卷----------------P12南广学院学生人际交往能力的调查一、测量主题南广学院学生人际交往能力调查分析二、主题的来源我们知道轰动全国的云南大学2.23 凶杀案,主犯马加爵,由于与同学产生了一些小矛盾,而走上杀人的道路。
这件事不得不引起我们的思考。
为此,我们在生活﹑学习﹑工作中,要正视和解决不愿交往﹑不懂交往﹑不善交往的问题,塑造自身形象,以积极的态度和行为对待人际交往,建立和谐的人际关系。
大学学什么?除了知识外,最关键、最基本的是人的能力,大学生应该培养各种能力如:人际交往能力、创新思维能力、掌握信息能力、学习能力和自立能力等等。
其中人际交往能力的培养尤为重要, 伟大的革命导师马克思曾经说过:人是各种社会关系的总和,每个人都不是孤立存在的,他必定存在于各种社会关系之中,如何理顺好这些关系、如何提高生活质量就涉及到了社交能力的问题。
大学生进入学校的那一刻就已决定了其交往需要,良好的人际交往能力以及良好的人际关系是生存和发展的必要条件。
spss作业.doc

第六章SPSS参数检验——均值比较1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
操作:分析→比较均值→单样本T均值为73.7273,Q值为0.668大于0.05,均值预75没有显著性差异,接受原假设。
即该经理的宣称是可信的。
2、经济学家认为决策者是对事实做出反应,不是对提出事实的方式做出反应。
然而心理学家则倾向于认为提出事实的方式是有关系的。
为验证哪种观点更站得住脚,调查者分别以下面两种不同的方式随机访问了足球球迷。
l 方式一:假设你已经买了100元一张的足球票,当你来到足球场门口时,发现票丢了且再也找不到了。
球场还有票出售。
你会再掏出100元买一张球票吗?(1.买0.不买)。
随机访问了200人,其中:92人回答买;l 方式二:你想看足球赛,100元一张票。
当你来到足球场买票时,发现丢了100元钱。
你口袋中还有钱,此时你还会付100元买一张球票吗?(1.买0.不买)。
随机访问了183人,其中:161人回答买;请恰当建立SPSS数据文件,并利用本章所学习的参数检验方法,说明你更倾向于那种观点,为什么?操作:输入数据→分析→比较均值→独立样本T检验3、一种植物只开兰花和白花。
按照某权威建立的遗传模型,该植物杂交的后代有75%的几率开兰花,25%的几率开白花。
现从杂交种子中随机挑选200颗,种植后发现142株开了兰花,请利用SPSS进行分析,说明这与遗传模型是否一致?操作:输入数据→分析→比较均值→独立T检验(输入值为0.75)即:0.215大于0.05,预遗传模型没有差异性4、给幼鼠喂以不同的饲料,用以下两种方法设计实验:方式1:同一鼠喂不同的饲料所测得的体内钙留存量数据如下:鼠号饲料1 饲料2 133.136.7233.13 4 5 6 7 8 926.8 36.3 39.5 30.925.733.4 34.5 28.628.8 35.1 35.2 43.8 36.5 37.9 28.7配对样本T检验l 方式2:甲组有12只喂饲料1,乙组有9只喂饲料2所测得的钙留存量数据如下甲组饲料129.7 26.7 28.9 31.1 31.1 26.8 26.3 39.5 30.9 33.4 33.1 28.6乙组饲料228.7 28.3 29.3 32.2 31.1 30.0 36.2 36.8 30.0请选用恰当方法对上述两种方式所获得的数据进行分析,研究不同饲料是否使幼鼠体内钙的留存量有显著不同。
SPSS期末大作业-完整版

第1题:基本统计分析1分析:本题要求随机选取80%的样本,因而需要选用随机抽样的方法,在此选择随机抽样中的近似抽样方法进行抽样。
其基本操作步骤如下:数据→选择个案→随机个案样本→大约(A)80 所有个案的%。
1、基本思路:(1)由于存款金额为定距型变量,直接采用频数分析不利于对其分布形态的把握,因而采用数据分组,先对数据进行分组再编制频数分布表。
此处分为少于500元,500~2000元,2000~3500元,3500~5000元,5000元以上五组。
分组后进行频数分析并绘制带正态曲线的直方图。
(2)进行数据拆分,并分别计算不同年龄段储户的一次存取款金额的四分位数,并通过四分位数比较其分布上的差异。
操作步骤:(1)数据分组:【转换→重新编码为不同变量】,然后选择存取款金额到【数字变量→输出变量(V)】框中。
在【名称(N)】中输入“存取款金额1”,单击【更改(H)】按钮;单击【旧值和新值】按钮进行分组区间定义。
存取款金额1频率百分比有效百分比累积百分比有效1.00 82 34.6 34.6 34.62.00 76 32.1 32.1 66.73.00 104.2 4.2 70.94.00 22 9.3 9.3 80.25.00 47 19.8 19.8 100.0 合计237 100.0 100.0(2)【分析→描述统计→频率】;选择“存款金额分组”变量到【变量(V)】框中;单击【图标(C)】按钮,选择【直方图】和【在直方图上显示正态曲线】;选中【显示频率表格】,确定。
(3)【数据→拆分文件】,选择“年龄”变量到【分组方式】框中,选中【比较组】和【按分组变量排序文件】,确定;【分析→描述统计→频率】,选择“存款金额”到【变量】框中,单击【统计量】按钮,选择【四分位数】→继续→确定。
统计量存(取)款金额20岁以下N有效1缺失0 百分位数25 50.00 50 50.00 7550.00 20~35岁N有效 131 缺失0 百分位数25 500.00 50 1000.00 755000.0035~50岁N有效 73 缺失0 百分位数25 500.00 50 1000.00 75 4500.0050岁以上N有效32缺失0 百分位数25 525.00 50 1000.00 752000.00结果及结果描述:频数分布表表明,有一半以上的人的一次存取款金额少于2000元,且有34.6%的人的存取款金额少于500元,19.8%的人的存取款金额多于5000元,下图为相应的带正态曲线的直方图。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
大作业
汽车市场研究
问题描述
以往在我国各地汽车需求量的研究中,主要是根据国家政策、国民经济发展情况、各地区公路状况等,总和不同时期汽车保有量,对汽车市场进行定性分析和决策,这样往往带有主观因素,下面为一组可能影响汽车保有量的数据,部分数据如图,用合理的方法对数据进行研究。
图
一层次聚类
、求解思路
用层次聚类的方法,分析与预测各个地区的汽车市场发展情况。
首先对原始数据进行标准化变换处理,经过运算使得每列数据的平均值为0,方差为1,这样原始数据中5列具有不同比较标准的数据就能放在一起比较;然后用标准化后的30个不同地区数据求出欧式距离;最后采用Wald离差平方和法。
、问题求解与分析
通过SPSS软件求解的结果与分析:
结果分析:图为层次分析的凝聚状态表,第一列为聚类步骤,表示共进行了29个步骤的分析;第二列和第三列表示某部聚类分析中,哪两个样本或聚类成了一类;第四列表示两个样本或类间距,从图看出,距离小的样本之间先聚类;第五列和第六列表示某步聚类分析中,参与聚类的是样本还是类,0表示样本;第七列表示本步聚类分析结果在下面聚类的第几步中用到。
图
结果分析:图将30个样本分为三类,第一类包括1、2、6、9、10、11,第二类包括3、4、7、12、15、16、18、19、22、26,第三类包括5、8、13、14、17、20、21、23、24、25、27、28、29、30 。
Case
3 Cluster
s
1:北京1
2:天津1 3:河北2 4:山西2
5:内蒙
古
3 6:辽宁1 7:吉林2
8:黑龙
江
3
9:上海1 10:江
1苏
11:浙
1江
12:安
2徽
13:福
3建
14:江
3西
15:山
2东
16:河
2南
17:湖
3北
18:湖
2南
19:广
2东
20:广
3西
21:海
3南
22:四
2川
23:贵
3州
24:云
3南
25:西
3藏
26:陕
2西
27:甘
3肃
28:青
3海
29:宁
3夏
30:新
3
疆
图
结果分析:图是层次聚类分析的树形图,由于部分样本或小类之间的距离较小,因此光从该图很难清晰看出哪几个样本先聚类,这时应借助于图进行判别。
* * * * * * * * * * * * * * * * * * * H I E R A R C H I C A L C L U S T E R
A N A L Y S I S * * * * * * * * * * * * * * * * * * *
Dendrogram using Ward Method
Rescaled Distance Cluster Combine
C A S E 0 5
10 15 20
25
Label Num +---------+---------+---------+--
-------+---------+
安徽12 ─┐
河南16 ─┼─┐
广东19 ─┤│
四川22 ─┘├─────┐
吉林7 ─┐││
陕
西26 ─┼─┘├─────────────┐
湖
南18 ─┘│
│
河
北 3 ─┐│
│
山
西 4 ─┼───────┘
│
山
东15 ─┘
├─────────────────────────┐
贵
州23 ─┐
│
│
青
海28 ─┼─────────┐
│
│
西
藏25 ─┘│
│
│
黑龙
江8 ─┬─┐├───────────┘
│
宁
夏29 ─┘│││
内蒙
古 5 ─┐├───────┘
│
新
疆30 ─┤│
│
湖
北17 ─┤│
│
江
西14 ─┼─┘
广
西20 ─┤│
云
南24 ─┤│
甘
肃27 ─┤│
福
建13 ─┤│
海
南21 ─┘
天
津 2 ─┐
│
浙
江11 ─┼───┐
│
上
海9 ─┘├───────────────────────────────────────────┘
北京 1 ─┐│
江苏10 ─┼───┘
辽宁 6 ─┘
图
总分析:第一类反应的是我国经济发展较发达地区与相对欠发达地区。
1、2、9代表为北京、天津、上海三个直辖市,在全国具有举足轻重的地位,它们的汽车市场发展仍将处于全国领先水平;6、10、11代表辽宁、江苏、浙江,由于地理、人口、气候及交通等原因,汽车市场的发展将作为今后发展的重要因素,带动这些地区经济的腾飞。
第二类中10个元素,分别代表陕西、山东、陕西等,这些地区从经济发展看处于中等水平,将是今后汽车发展的大市场。
第三类为内蒙古、宁夏、新疆等,这些地区相对来说经济发展较慢,汽车发展空间不大。
二多元线性回归分析
求解思路
用多远线性回归的方法,分析国内生产总值、地区人口总数、地区公路长度、全社会货运量对汽车保有量是否有影响。
首先自变量强制进入,不用管个因素质量如何,对回归方程是否有影响;然后选择输出默认输出项,输出回归系数的标准误差、标准回归系数等;最后选择Model fit和Descriptives,输出判定系数、自变量与因变量的均值、标准差等。
问题求解与分析
通过SPSS软件求解的结果与分析:
图
结果分析:图为四个自变量和一个因变量的平均值、方差和个案数为30。
Variables Entered/Removed b
Model Variables
Entered
Variables
Removed Method
1全社会货运量
(万吨), 地
区公路长度
(km), 国内
生产总值(亿
元), 地区人
口总数(万人)
a
.Enter
a. All requested variables
entered.
图
结果分析:图2. 2中第二列为被引入的变量,第三列为从回归方程中被剔除的各个变量,第四列为进入方式。
图
结果分析:图输出常用统计量关系数R为,调整的判定系数为,回归估计的标准误差S=。
图
结果分析:图为方差分析表,统计量F=;相伴概率p=0,说明多个变量与因变量之间存在线性回归关系。
图
结果分析:图为回归系数分析,Unstandardized Coefficients为非标准化系数,Standardized Coefficients为标准化系数,t为回归系数检验统计量,Sig为相伴概率,从图看出各个自变量与因变量的线性回归分析关系不显著。
总分析:四个因变量对因变量的影响作用不显著。