mfs文件系统架构分析
Ceph、GlusterFS、Lustre、MFS技术比较
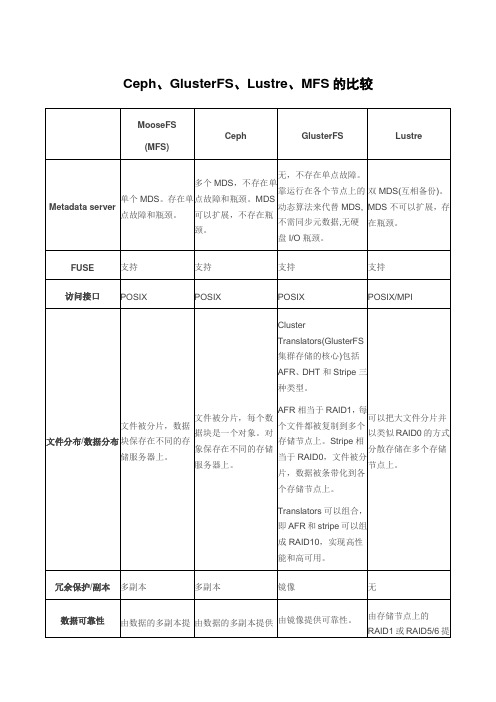
Ceph、GlusterFS、Lustre、MFS的比较引言:开源存储软件Ceph和Gluster能够提供相似的特性并且能够为用户节省不小的开支。
那么谁更快?谁又更易用呢?开源的Ceph及Red Hat旗下的Gluster都是成熟的技术,但兴许不久之后就将经历某种重生了。
随着存储产业开始向扩展性存储及云的方向发展,将不断会有基于这些低价的软件技术的产品推向市场,而对这些自集成解决方案的补充在近一年来不断涌现。
Ceph与Gluster在原理上有着本质上的不同。
Ceph基于一个名为RADOS的对象存储系统,使用一系列API将数据以块(block)、文件(file)和对象(object)的形式展现。
Ceph存储系统的拓扑结构围绕着副本与信息分布,这使得该系统能够有效保障数据的完整性。
而Red Hat将Gluster描述为可扩展的网络存储设备(Scale-out NAS)和对象存储系统。
它使用一个哈希算法来计算数据在存储池中的存放位置,这点跟Ceph很类似。
并且这是保证扩展性的关键。
在Gluster中,所有的存储服务器使用哈希算法完成对特定数据实体的定位。
于是数据可以很容易的复制,并且没有中心元数据单点这样一个容易造成访问瓶颈的部分,这种单点在早期Hadoop上出现,对性能和可靠性造成较大影响。
Ceph与Gluster有着相似的数据分布能力。
Ceph像大多数对象存储软件那样,通过更大的节点集进行数据条带化处理。
这样的好处是能够防止数据访问的瓶颈效应。
因为默认的Ceph块比较小(仅为64KB),所以数据流被切分为许多随机的IO操作。
而磁盘在随机IO的时候一般能够达到最大值(对HDD而言最多达到150次每秒),并且这个数值不会随传输的数据大小改变多少。
所以对于Ceph而言,设置更大的IO 块意味着能够一次聚合传输更多的数据。
Gluster默认的块大小是128KB。
这是Red Hat声称在一项基准测试中Gluster的性能是Ceph的三倍的主要原因。
FastDFS架构分析

FastDFS一个高效的分布式文件系统FastDFS是一款类Google FS的开源分布式文件系统,它用纯C语言实现,支持Linux、FreeBSD、AIX等UNIX系统。
它只能通过专有API对文件进行存取访问,不支持POSIX接口方式,不能mount使用。
准确地讲,Google FS以及FastDFS、mogileFS、HDFS、TFS 等类Google FS都不是系统级的分布式文件系统,而是应用级的分布式文件存储服务。
FastDFS的设计理念FastDFS是为互联网应用量身定做的分布式文件系统,充分考虑了冗余备份、负载均衡、线性扩容等机制,并注重高可用、高性能等指标。
和现有的类Google FS分布式文件系统相比,FastDFS的架构和设计理念有其独到之处,主要体现在轻量级、分组方式和对等结构三个方面。
轻量级FastDFS只有两个角色:Tracker server和Storage server。
Tracker server作为中心结点,其主要作用是负载均衡和调度。
Tracker server在内存中记录分组和Storage server 的状态等信息,不记录文件索引信息,占用的内存量很少。
另外,客户端(应用)和Storage server访问Tracker server时,Tracker server扫描内存中的分组和Storage server信息,然后给出应答。
由此可以看出Tracker server非常轻量化,不会成为系统瓶颈。
FastDFS中的Storage server在其他文件系统中通常称作Trunk server或Data server。
Storage server直接利用OS的文件系统存储文件。
FastDFS不会对文件进行分块存储,客户端上传的文件和Storage server上的文件一一对应。
众所周知,大多数网站都需要存储用户上传的文件,如图片、视频、电子文档等。
出于降低带宽和存储成本的考虑,网站通常都会限制用户上传的文件大小,例如图片文件不能超过5MB、视频文件不能超过100MB等。
百度的分布式文件系统之路

MFS的问题和改进
• 问题 • Master元信息单点 • Master单线程性能瓶颈 • 修复与写入互斥
• 改进 • poll->epoll • 调大hash桶 • fuse调参
CCDB存储体系
Table
File
Object
Permission
Isolation
Priority
Replication
MFS
• 简介 • MFS是MooseFS的简称,是一个分布式网络文件系统, 将数据切片分散到多个存储设备上实现数据容错,可 以像本地文件系统一样进行挂载使用。
• 特点 • 类GFS的开源C实现 • 通用文件系统(POSIX支持) • 高易用性(Mount、Trash、Snapshot……)
MFS的读写流程
CCDB-NFS架构
• Master • 目录树 • 集群管理
• FileServer • 文件元信息 • 文件数据
CCDB-NFS链式复制
• 链式复制 • Primary最后Commit • 读Primary强一致 • 选主简化
CCDB-NFS的多租户支持
• User • Region • ACL • Quota
Recovery
Control
Table Engine
File Engine
KV Engine
Replica Block System
Raid-like Block System
Memory
SSD
Disk
Interface Platform Distributed Engine Block Hardware
AFS压缩支持
• DataNode透明压缩 • Client写入时压缩 • 分级压缩(LZ4/LZO->LZMA)
Linux平台上MFS(MooseFS)的部署v0.5

Linux平台上MFS(MooseFS)的部署目录1 概述 (3)2 实验环境 (3)3 安装和配置MFS Master (4)3.1 安装master (4)3.2 配置master (4)3.3 启动和停止master服务 (5)4 安装和配置ChunkServer (5)4.1 安装ChunkServer (5)4.2 配置ChunkServer (5)4.3 启动和停止ChunkServer服务 (6)5 安装和配置MFS Client (6)5.1 安装FUSE (6)5.2 安装MFS Client (7)5.3 使用MFS (7)5.4 设置副本数量 (7)5.5 设置空间回收时间 (8)6 破坏性测试 (9)6.1 测试数据存储服务器 (9)6.2 测试元数据服务器 (9)1 概述MFS(MooseFS)是一个Linux/Unix平台上开源的分布式文件系统。
它可以把文件复制成多份(如3份)分别放置在多个数据服务器(ChunkServer)上,实现文件的冗余。
而且可以动态的增加ChunkServer,实现动态存储容量扩展,甚至可以支持PB级的存储容量。
2 实验环境●硬件和软件环境:✓PC:Intel(R) Core(TM)2 Quad CPU Q9550@ 2.83GHz, 8G RAM✓OS: CentOS 5.2 (x86_64), Kernel: 2.6.18-92.el5xen✓MFS: MooseFS v1.5.12表2-1 安装MFS所需软件列表3 安装和配置MFS Master3.1 安装master●创建用户# useradd mfs -s /sbin/nologin●安装master# tar xvzf mfs-1.5.12.tar.gz# cd mfs-1.5.12# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs # make# make install3.2 配置master●创建目录# mkdir -p /var/run/mfs# chown mfs:mfs /var/run/mfs●更改配置文件/usr/local/mfs/etc/mfsmaster.cfg:#WORKING_USER = mfs#WORKING_GROUP = mfs#LOCK_FILE = /var/run/mfs/mfsmaster.pid#DATA_PATH = /usr/local/mfs/var/mfs#SYSLOG_IDENT = mfsmaster#BACK_LOGS = 50#REPLICATIONS_DELAY_INIT = 300#REPLICATIONS_DELAY_DISCONNECT = 3600#MATOCS_LISTEN_HOST = *#MATOCS_LISTEN_PORT = 9420#MATOCU_LISTEN_HOST = *#MATOCU_LISTEN_PORT = 9421#CHUNKS_LOOP_TIME = 300#CHUNKS_DEL_LIMIT = 100#CHUNKS_REP_LIMIT = 153.3 启动和停止master服务●启动master服务# /usr/local/mfs/sbin/mfsmaster start●停止master服务# /usr/local/mfs/sbin/mfsmaster -s●查看master日志/var/log/messages# tail -f /var/log/messages4 安装和配置ChunkServer4.1 安装ChunkServer●创建用户# useradd mfs -s /sbin/nologin●安装ChunkServer# tar xvzf mfs-1.5.12.tar.gz# cd mfs-1.5.12# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs # make# make install4.2 配置ChunkServer●创建目录# mkdir -p /var/run/mfs# chown mfs:mfs /var/run/mfs●创建共享存储的挂载点,建议分配整个磁盘分区# mount /dev/xvdb1 /data# chown mfs:mfs /data●更改配置文件/usr/local/mfs/etc/mfschunkserver.cfg:#WORKING_USER = mfs#WORKING_GROUP = mfs#DATA_PATH = /usr/local/mfs/var/mfs#LOCK_FILE = /var/run/mfs/mfschunkserver.pid#SYSLOG_IDENT = mfschunkserver#BACK_LOGS = 50#MASTER_RECONNECTION_DELAY = 30MASTER_HOST = 10.8.2.41MASTER_PORT = 9420#MASTER_TIMEOUT = 60#CSSERV_LISTEN_HOST = *#CSSERV_LISTEN_PORT = 9422#CSSERV_TIMEOUT = 60#CSTOCS_TIMEOUT = 60#HDD_CONF_FILENAME = /usr/local/mfs/etc/mfshdd.cfg●更改配置文件/usr/local/mfs/etc/mfshdd.cfg, 增加文件系统挂载点:/data1/data2注意:配置的挂载点必须让mfs用户有读写权限,如没有,用如下命令赋权限:# chown mfs:mfs /data14.3 启动和停止ChunkServer服务●启动chunkserver服务# /usr/local/mfs/sbin/mfschunkserver start●停止chunkserver服务# /usr/local/mfs/sbin/mfschunkserver -s●查看chunkserver日志/var/log/messages# tail -f /var/log/messages5 安装和配置MFS Client5.1 安装FUSE●增加环境变量并使其生效export PKG_CONFIG_PATH=/usr/local/lib/pkgconfig:$PKG_CONFIG_PATHexport LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/usr/local/lib:.export PATH=$PATH:/usr/local/mfs/bin:.●安装fuse# tar xvzf fuse-2.7.4.tar.gz# cd fuse-2.7.4# ./configure# make# make install5.2 安装MFS Client●创建用户# useradd mfs -s /sbin/nologin●安装MFS Client# tar xvzf mfs-1.5.12.tar.gz# cd mfs-1.5.12# ./configure --prefix=/usr/local/mfs --with-default-user=mfs --with-default-group=mfs --enable-mfsmount# make# make install5.3 使用MFS●如果报错fuse: device not found, 请先fuse mount.# modprobe fuse●挂载MFS文件系统# mkdir /mfsdata# /usr/local/mfs/bin/mfsmount -h 10.8.2.41 -w /mfsdata●使用MFS# dd if=/dev/urandom of=/mfsdata/test.dat bs=1M count=200# md5sum /mfsdata/test.dat522c27c45064c2d0463c168593f5bead /mfsdata/test.dat5.4 设置副本数量●查看目录现在的副本数量:# mfsgetgoal /mfsdata/mfsdata: 1# mfsfileinfo /mfsdata/test.dat/mfsdata/test.dat:chunk 0: 0000000000000013_00000004 / (id:19 ver:4)copy 1: 10.8.2.44:9422chunk 1: 0000000000000014_00000003 / (id:20 ver:3)copy 1: 10.8.2.42:9422chunk 2: 0000000000000015_00000003 / (id:21 ver:3)copy 1: 10.8.2.42:9422chunk 3: 0000000000000016_00000001 / (id:22 ver:1)copy 1: 10.8.2.42:9422●更改目录现在的副本数量:# mfsrsetgoal 3 /mfsdata/mfsdata/:inodes with goal changed: 3 (3)inodes with goal not changed: 0 (0)inodes with permission denied: 0 (0)●查看更改后目录的副本数量:# mfsgetgoal /mfsdata/mfsdata: 3# mfsfileinfo /mfsdata/test.dat/mfsdata/test.dat:chunk 0: 0000000000000013_00000004 / (id:19 ver:4)copy 1: 10.8.2.42:9422copy 2: 10.8.2.43:9422copy 3: 10.8.2.44:9422chunk 1: 0000000000000014_00000003 / (id:20 ver:3)copy 1: 10.8.2.42:9422copy 2: 10.8.2.43:9422copy 3: 10.8.2.44:9422chunk 2: 0000000000000015_00000003 / (id:21 ver:3)copy 1: 10.8.2.42:9422copy 2: 10.8.2.43:9422copy 3: 10.8.2.44:9422chunk 3: 0000000000000016_00000001 / (id:22 ver:1)copy 1: 10.8.2.42:9422copy 2: 10.8.2.43:9422copy 3: 10.8.2.44:94225.5 设置空间回收时间●查看目录当前回收时间:# mfsgettrashtime /mfsdata/mfsdata: 86400●设置目录当前回收时间为600秒:# mfsrsettrashtime 600 /mfsdata/mfsdata:inodes with trashtime changed: 3 (3)inodes with trashtime not changed: 0 (0)inodes with permission denied: 0 (0)●查看更改后空间回收时间:# mfsgettrashtime /mfsdata/mfsdata: 6006 破坏性测试6.1 测试数据存储服务器现在用4个服务器组成了MFS的存储平台,其中一个是master,其余三个服务器是chunkserver.先停止一个chunkserver服务,然后在某个MFS客户端往挂接点的目录(/mfsdata)里复制数据或者创建目录/文件、或者读取文件、或者删除文件,观察操作是否能正常进行。
分布式文件系统MFS(moosefs)实现存储共享
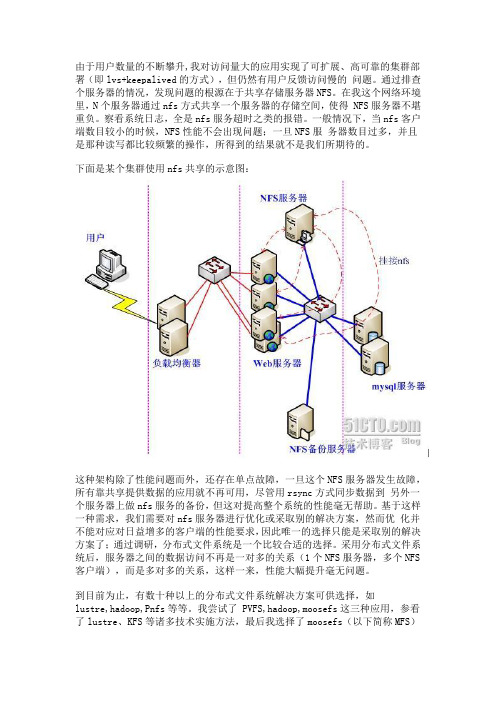
由于用户数量的不断攀升,我对访问量大的应用实现了可扩展、高可靠的集群部署(即lvs+keepalived的方式),但仍然有用户反馈访问慢的问题。
通过排查个服务器的情况,发现问题的根源在于共享存储服务器NFS。
在我这个网络环境里,N个服务器通过nfs方式共享一个服务器的存储空间,使得 NFS服务器不堪重负。
察看系统日志,全是nfs服务超时之类的报错。
一般情况下,当nfs客户端数目较小的时候,NFS性能不会出现问题;一旦NFS服务器数目过多,并且是那种读写都比较频繁的操作,所得到的结果就不是我们所期待的。
下面是某个集群使用nfs共享的示意图:这种架构除了性能问题而外,还存在单点故障,一旦这个NFS服务器发生故障,所有靠共享提供数据的应用就不再可用,尽管用rsync方式同步数据到另外一个服务器上做nfs服务的备份,但这对提高整个系统的性能毫无帮助。
基于这样一种需求,我们需要对nfs服务器进行优化或采取别的解决方案,然而优化并不能对应对日益增多的客户端的性能要求,因此唯一的选择只能是采取别的解决方案了;通过调研,分布式文件系统是一个比较合适的选择。
采用分布式文件系统后,服务器之间的数据访问不再是一对多的关系(1个NFS服务器,多个NFS 客户端),而是多对多的关系,这样一来,性能大幅提升毫无问题。
到目前为止,有数十种以上的分布式文件系统解决方案可供选择,如lustre,hadoop,Pnfs等等。
我尝试了 PVFS,hadoop,moosefs这三种应用,参看了lustre、KFS等诸多技术实施方法,最后我选择了moosefs(以下简称MFS)这种分布式文件系统来作为我的共享存储服务器。
为什么要选它呢?我来说说我的一些看法:1、实施起来简单。
MFS的安装、部署、配置相对于其他几种工具来说,要简单和容易得多。
看看lustre 700多页的pdf文档,让人头昏吧。
2、不停服务扩容。
MFS框架做好后,随时增加服务器扩充容量;扩充和减少容量皆不会影响现有的服务。
mfs文件系统使用手册
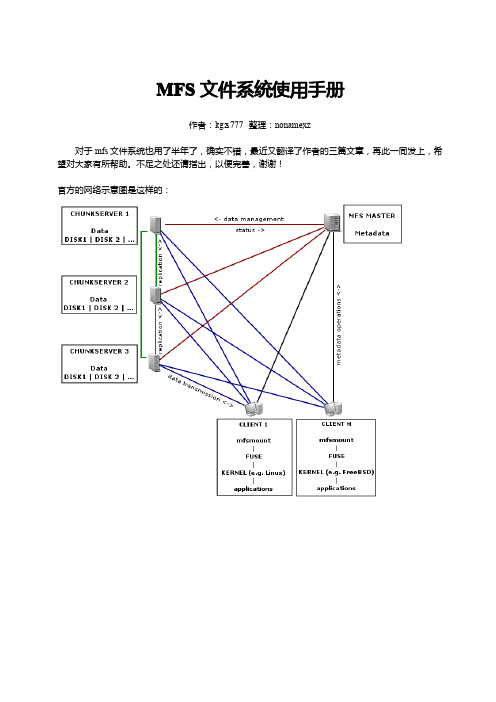
MFS文件系统使用手册作者:ltgz s777整理:nonamexz对于mfs文件系统也用了半年了,确实不错,最近又翻译了作者的三篇文章,再此一同发上,希望对大家有所帮助。
不足之处还请指出,以便完善,谢谢!官方的网络示意图是这样的:MFS 文件系统结构:具体的实例安装和配置元数据服务(master server )安装元数据服务角色角色作用管理服务器managing server (master)负责各个数据存储服务器的管理,文件读写调度,文件空间回收以及恢复.多节点拷贝元数据日志服务器Metalogger server (Metalogger )负责备份master 服务器的变化日志文件,文件类型为changelog_ml.*.mfs ,以便于在master server 出问题的时候接替其进行工作数据存储服务器data servers (chunkservers)负责连接管理服务器,听从管理服务器调度,提供存储空间,并为客户提供数据传输.客户机挂载使用client computers 通过fuse 内核接口挂接远程管理服务器上所管理的数据存储服务器,.看起来共享的文件系统和本地unix 文件系统使用一样的效果.mfsmaster.cfg的配置配置文件位于安装目录/usr/local/mfs/etc,需要的配置文件有两个:mfsmaster.cfg和mfsexports.cfg,mfsmaster.cfg是主配置文件,mfsexports.cfg是被挂接目录及权限设置。
需要注意的是,凡是用#注释掉的变量均使用其默认值。
以上是对master server的mfsmaster.cfg配置文件的解释,对于这个文件不需要做任何修改就可以工作。
mfsexports.cfg的配置该文件每一个条目分为三部分:第一部分:客户端的ip地址第二部分:被挂接的目录第三部分:客户端拥有的权限地址可以指定的几种表现形式:*所有的ip地址n.n.n.n单个ip地址n.n.n.n/b IP网络地址/位数掩码n.n.n.n/m.m.m.m IP网络地址/子网掩码f.f.f.f-t.t.t.t IP段目录部分需要注意两点:/标识MooseFS根;.表示MFSMETA文件系统权限部分:ro只读模式共享rw读写的方式共享alldirs许挂载任何指定的子目录maproot映射为root,还是指定的用户password指定客户端密码启动master servermaster server可以单独启动(所谓单独启动就是在没有数据存储服务器(chunkserver)的时候也可以启动,但是不能存储,chunkserver启动后会自动的加入)。
分布式文件系统MFS、Ceph、GlusterFS、Lustre的比较
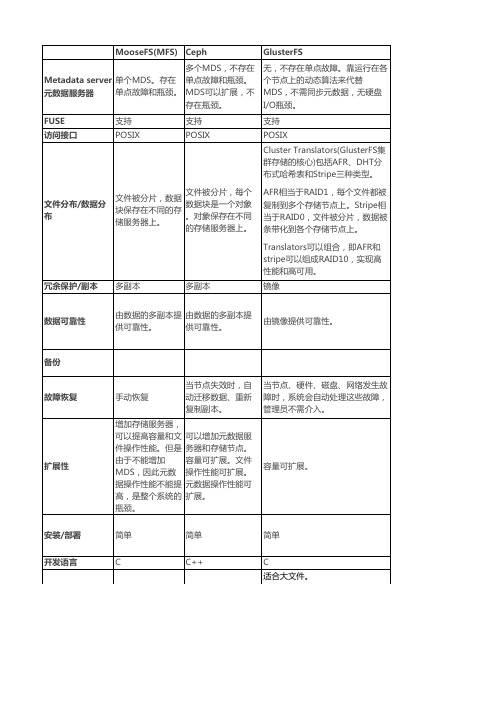
文件被分片,每个 文件被分片,数据 数据块是一个对象 块保存在不同的存 。对象保存在不同 储服务器上。 的存储服务器上。
AFR相当于RAID1,每个文件都被 复制到多个存储节点上。Stripe相 当于RAID0,文件被分片,数据被 条带化到各个存储节点上。 Translators可以组合,即AFR和 stripe可以组成RAID10,实现高 性能和高可用。
可增加存储节点,提 高容量可文件操作性 能,但是由于不能增 加MDS,因此元数 据操作性能不能提 高,是整个系统的瓶 颈。 复杂。而且Lustre严 重依赖内核,需要重 新编译内核。 C
大文件读写
大文件读写
重型 HPC领域。
很成熟、很庞大。
故障恢复
手动恢复 增加存储服务器, 可以提高容量和文 件操作性能。但是 由于不能增加 MDS,因此元数 据操作性能不能提 高,是整个系统的 瓶颈。 简单 C
扩展性
容量可扩展。
安装/部署 开发语言
简单 C++
简单 C 适合大文件。
适合场景
大量小文件读写
小文件
适合场景
大量小文件读写
小文件
对于小文件,无元数据服务设计解 决了元数据的问题。但GlusterFS 并没有在I/O方面作优化,在存储 服务器底层文件系统上仍然是大量 小文件,本地文件系统元数据访问 是瓶颈,数据分布和并行性也无法 充分发挥作用。因此,GlusterFS 的小文件性能还存在很大优化空间 。 中型 较多用户使用 无元数据服务器,堆栈式架构(基 本功能模块可以进行堆栈式组合, 实现强大功能)。具有线性横向扩 展能力。 由于没有元数据服务器,因此增加 了客户端的负载,占用相当的CPU 和内存。 但遍历文件目录时,则实现较为复 杂和低效,需要搜索所有的存储节 点。因此不建议使用较深的路径。
mfs 预研遇到问题及解决办法

metalogger 进程: /usr/sbin/mfsmetalogger start
客户端挂载mfsmount: /usr/bin/mfsmount /mnt/mfs -H mfsmaster
运行CGI 监控服务/usr/sbin/mfscgiserv,这样就可以用浏览器查看整个MooseFS 的运行情况:
为了安全停止MooseFS 集群,建议执行如下的步骤:
停止chunk server 进程: /usr/sbin/mfschunkserver -s
停止 metalogger 进程: /usr/sbin/mfsmetalogger -s
在所有客户端用Unmount 命令先卸载文件系统(本例将是: umount /mnt/mfs)
解决办法:
#export PKG_CONFIG_PATH=$PKG_CONFIG_PATH:/usr/local/lib/pkgconfig
5、问题:卸载已挂载的文件系统
umount: /mnt/mfs: device is busy.
(In some cases useful info about processes that use
解决办法:
That folder was owned by 'nobody' instead of my user.
That's why you couldn't do anything with it.
I have changed the ownership of it, so you should be good to go
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Moose File System2012.11.13 jluzcMooseFS is a fault tolerant, network distributed file system. It spreads data over several physical servers which are visible to the user as one resource. For standard file operations MooseFS acts as other Unix-alike file systems:∙ A hierarchical structure (directory tree)∙Stores POSIX file attributes (permissions, last access and modification times)∙Supports special files (block and character devices, pipes and sockets)∙Symbolic links (file names pointing to target files, not necessarily on MooseFS) and hard links (different names of files which refer to the same data on MooseFS)∙Access to the file system can be limited based on IP address and/or passwordDistinctive features of MooseFS are:∙High reliability (several copies of the data can be stored across separate computers)∙Capacity is dynamically expandable by attaching newcomputers/disks∙Deleted files are retained for a configurable period of time (a file system level "trash bin")∙Coherent snapshots of files, even while the file is being written/accessedARCHITECTUREMooseFS consists of four components:∙Managing server (master server) – a single machine managing the whole filesystem, storing metadata for every file (information on size, attributes and file location(s), including all informationabout non-regular files, i.e. directories, sockets, pipes anddevices).∙Data servers (chunk servers) - any number of commodity servers storing files data and synchronizing it among themselves (if acertain file is supposed to exist in more than one copy).∙Metadata backup server(s) (metalogger server) - any number of servers, all of which store metadata changelogs and periodically downloading main metadata file; so as to promote these servers to the the role of the Managing server when primary master stopsworking.∙Client computers that access (mount) the files in MooseFS - any number of machines using mfsmount process to communicate with the managing server (to receive and modify file metadata) and withchunkservers (to exchange actual file data).mfsmount is based on the FUSE mechanism (Filesystem in USErspace), so MooseFS is available on every Operating System with a working FUSE implementation (Linux, FreeBSD, MacOS X, etc.)Metadata is stored in the memory of the managing server and simultaneously saved to disk (as a periodically updated binary file and immediately updated incremental logs). The main binary file as well as the logs are synchronized to the metaloggers (if present).File data is divided into fragments (chunks) with a maximum of 64MiB each. Each chunk is itself a file on selected disks on data servers (chunkservers).High reliability is achieved by configuring as many different data servers as appropriate to realize the "goal" value (number of copies to keep) set for the given file.HOW THE SYSTEM WORKSAll file operations on a client computer that has mounted MooseFS are exactly the same as they would be with other file systems. The operating system kernel transfers all file operations to the FUSE module, which communicates with the mfsmount process. The mfsmount process communicates through the network subsequently with the managing server and data servers (chunk servers). This entire process is fully transparent to the user.mfsmount communicates with the managing server every time an operation on file metadata is required:∙creating files∙deleting files∙reading directories∙reading and changing attributes∙changing file sizes∙at the start of reading or writing data∙on any access to special files on MFSMETAmfsmount uses a direct connection to the data server (chunk server) that stores the relevant chunk of a file. When writing a file, after finishing the write process the managing server receives information from mfsmount to update a file's length and the last modification time.Furthermore, data servers (chunk servers) communicate with each other to replicate data in order to achieve the appropriate number of copies of a file on different machines.FAULT TOLERANCEAdministrative commands allow the system administrator to specify the "goal", or number of copies that should be maintained, on a per-directory or per-file level. Setting the goal to more than one and having more than one data server will provide fault tolerance. When the file data is stored in many copies (on more than one data server), the system is resistant to failures or temporary network outages of a single data server.This of course does not refer to files with the "goal" set to 1, in which case the file will only exist on a single data server irrespective of how many data servers are deployed in the system.Exceptionally important files may have their goal set to a number higher than two, which will allow these files to be resistant to a breakdown of more than one server at once.In general the setting for the number of copies available should be one more than the anticipated number of inaccessible or out-of-order servers.In the case where a single data server experiences a failure or disconnection from the network, the files stored within it that had at least two copies, will remain accessible from another data server. The data that is now 'under its goal' will be replicated on another accessible data server to again provide the required number of copies.It should be noted that if the number of available servers is lower than the "goal" set for a given file, the required number of copies cannot be preserved. Similarly if there are the same number of servers as the currently set goal and if a data server has reached 100% of its capacity, it will be unable to begin to hold a copy of a file that is now below its goal threshold due to another data server going offline. In these cases a new data server should be connected to the system as soon as possible in order to maintain the desired number of copies of the file.A new data server can be connected to the system at any time. The new capacity will immediately become available for use to store new files or to hold replicated copies of files from other data servers.Administrative utilities exist to query the status of the files within the file system to determine if any of the files are currently below their goal (set number of copies). This utility can also be used to alter the goal setting as required.The data fragments stored in the chunks are versioned, so re-connecting a data server with older copy of data (such as if it had been offline for a period of time), will not cause the files to become incoherent. The data server will synchronize itself to hold the current versions of the chunks, where the obsolete chunks will be removed and the free space will be reallocated to hold the new chunks.Failures of a client machine (that runs the mfsmount process) will haveno influence on the coherence of the file system or on the other client's operations. In the worst case scenario the data that has not yet been sent from the failed client computer may be lost.PLATFORMSMooseFS is available on every Operating System with a working FUSE implementation:∙Linux (Linux 2.6.14 and up have FUSE support included in the official kernel)∙FreeBSD∙OpenSolaris∙MacOS XThe master server, metalogger server and chunkservers can also be run on Solaris or Windows with Cygwin. Unfortunately without FUSE it won't be possible to mount the filesystem within these operating systems.。