链式存储线性表基本操作及有序单链表合并成有序单列表
链式存储结构的基本操作
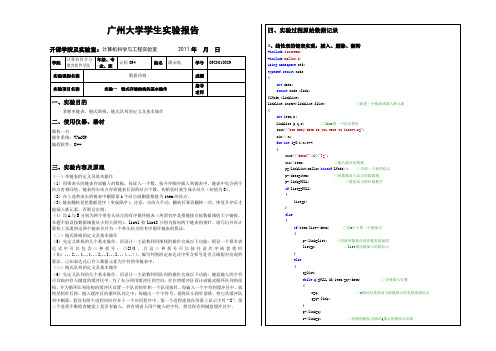
广州大学学生实验报告开课学院及实验室:计算机科学与工程实验室2011年月日学院计算机科学与教育软件学院年级、专业、班计机094 姓名潘永航学号0923010089实验课程名称数据结构成绩实验项目名称实验一链式存储结构的基本操作指导老师一、实验目的掌握单链表,链式堆栈,链式队列的定义及基本操作二、使用仪器、器材微机一台操作系统:WinXP编程软件:C++三、实验内容及原理(一)单链表的定义及基本操作(1)用带表头的链表存放输入的数据,每读入一个数,按升序顺序插入到链表中,链表中允许两个结点有相同值。
链表的头结点存放链表后面的结点个数,初始化时就生成头结点(初值为0)。
(2)在上述带表头的链表中删除第i个结点或删除数值为item的结点。
(3)链表翻转是把数据逆序(变成降序),注意,头结点不动。
翻转后要再翻转一次,恢复升序后才能插入新元素,否则会出错。
(4)设A与B分别为两个带有头结点的有序循环链表(所谓有序是指链接点按数据域值大小链接,本题不妨设按数据域值从小到大排列),list1和list2分别为指向两个链表的指针。
请写出并在计算机上实现将这两个链表合并为一个带头结点的有序循环链表的算法。
(二)链式堆栈的定义及基本操作(5)先定义堆栈的几个基本操作,再设计一主函数利用堆栈的操作完成以下功能:假设一个算术表达式中可以包含三种括号:()[]{},且这三种括号可以按任意次序嵌套使用(如:...[...{...}...[...]...]...(...))。
编写判别给定表达式中所含括号是否正确配对出现的算法,已知表达式已存入数据元素为字符的单链表中。
(三)链式队列的定义及基本操作(6)先定义队列的几个基本操作,再设计一主函数利用队列的操作完成以下功能:键盘输入的字符可以临时存入键盘的缓冲区中。
为了充分利用缓冲区的空间,往往将缓冲区设计成链式循环队列的结构,并为循环队列结构的缓冲区设置一个队首指针和一个队尾指针。
单链表的基本操作
10)调用头插法的函数,分别输入10,20,分别回车:
11)调用尾插法的函数,分别输入30,40
12)查找单链表的第四个元素:
13)主函数中传入参数,删除单链表的第一个结点:
14)主函数传入参数,删除第0个未位置的元素,程序报错:
15)最后,输出单链表中的元素:
return 0;
}
6)编译,连接,运行源代码:
7)输入8,回车,并输入8个数,用空格分隔开,根据输出信息,可以看出,链表已经拆分为两个
五、实验总结
1.单链表采用的是数据+指针的表示形式,指针域总是指向下一个结
点(结构体)的地址,因此,在内存中的地址空间可以是不连续的,操作比顺序存储更加的方便
2.单链表使用时,需要用malloc函数申请地址空间,最后,删除元
素时,使用free函数释放空间。
设计两个有序单链表的合并排序算法

设计两个有序单链表的合并排序算法有序单链表的合并排序,是一种高效的排序算法,可以在较短的时间内对大量数据进行排序。
这种排序算法的核心在于将两个有序的单链表合并成一个有序的单链表,然后再对整个链表进行排序。
合并排序算法的基本原理是分治法。
将需要排序的数组不断地分解成两个子数组,直到每个子数组只包含一个元素为止。
然后再将这些子数组两两合并,直到整个数组被合并成一个有序的数组为止。
这里介绍两个有序单链表的合并排序算法,它们分别是迭代算法和递归算法。
1. 迭代算法迭代算法是一种通用的算法,它的思路是利用循环结构来重复执行一段相同或相似的代码,从而解决一类问题。
对于有序单链表的合并排序,迭代算法的基本思路是将两个有序单链表的元素依次比较,然后将较小的元素加入到新的链表中,直到两个链表中的元素全部被加入到新链表中为止。
以下是迭代算法的具体实现过程:```// 合并两个有序单链表Node* mergeList(Node* head1, Node* head2) { // 新建一个头结点Node* dummy = new Node(-1);// 定义两个指针,分别指向两个链表的头结点 Node* p = head1;Node* q = head2;// 定义一个指针,指向新链表的最后一个节点 Node* curr = dummy;// 循环比较两个链表中的元素while (p != nullptr && q != nullptr) {if (p->val <= q->val) {curr->next = p;p = p->next;} else {curr->next = q;q = q->next;}curr = curr->next;}// 将剩余的元素加入到新链表中curr->next = p != nullptr ? p : q;// 返回新链表的头结点return dummy->next;}// 归并排序Node* mergeSort(Node* head) {if (head == nullptr || head->next == nullptr) {return head;}// 定义两个指针,一个快指针每次走两步,一个慢指针每次走一步 Node* slow = head;Node* fast = head->next;while (fast != nullptr && fast->next != nullptr) {slow = slow->next;fast = fast->next->next;}// 将链表分成两部分Node* head1 = head;Node* head2 = slow->next;slow->next = nullptr;// 分别对两部分链表进行归并排序head1 = mergeSort(head1);head2 = mergeSort(head2);// 合并两个有序单链表return mergeList(head1, head2);}```2. 递归算法递归算法的思想是将一个大问题分解成若干个小问题,然后逐个解决这些小问题,最终得到大问题的解决方案。
[数据结构]线性表合并
![[数据结构]线性表合并](https://img.taocdn.com/s3/m/34cefcfb18e8b8f67c1cfad6195f312b3169eb09.png)
[数据结构]线性表合并⼀、问题描述线性表合并是程序设计语⾔编译中的⼀个最基本的问题,现在有两个线性表LA和LB,其中的元素都是按照⾮递减有序排列的,要将两个LA 和LB归并为⼀个新的线性表LC,使得LC中的元素仍然是⾮递减有序的。
本实验的合并⽅式有两种。
第⼀种是分别取LA和LB的第⼀个元素,即各⾃的最⼩的元素进⾏⽐较,选择较⼩的元素加⼊LC尾部,然后重复以上步骤;当LA表空了或者LB表空了的时候,将另⼀个表剩下的元素按照顺序加⼊LC的尾部,从⽽保证LC中元素有序。
第⼆种⽅式是以LA为母表,将LB中的元素向LA中插⼊,直到LB表空,得到的新的LA表就是最终需要的LC表。
本实验采⽤线性表实现,采⽤了链式表⽰和顺序表⽰两种实现⽅式。
根据各⾃的特点,链式表⽰对应了第⼆种合并⽅式,⽽顺序表⽰对应了第⼀种合并⽅式。
⼆、数据结构——线性表1、链式表⽰:链式表⽰的特点是⽤⼀组任意的存储单元存储线性表的数据元素,每个元素包括两个域——数据域和指针域。
其中数据域是存储数据信息的域,本实验中默认所处理的数据元素都是在整型(int)范围内的数据;指针域中存储⼀个指针,指向当前元素的下⼀个元素的地址。
n个结点按照如上关系连接起来,形成⼀个链表,就是线性表的链式表⽰。
由于链式表⽰对于数据的插⼊、删除操作⽐较⽅便,⽽查找⼀个元素的效率⽐较低下,于是选择⽤第⼆种合并⽅式,即以LA为母表,将LB 中的元素⼀个⼀个插⼊LA中。
⾸先,每个结点的是⼀个node型的变量,包含⼀个int型变量Num和⼀个node*型的指针变量next。
正如上⽂所描述,Num保存该结点的数值,next保存逻辑上下⼀个结点的地址。
然后定义了⼀个名叫MyList的类,其中有private型的变量包含线性表⾃⾝的基本变量,⽐如元素个数、⾸地址等等;还包括public型的线性表的基本操作函数,⽐如初始化(InitList)、清除(ClearList)、打印(PrintList)等等。
线性表的存储结构定义及基本操作(实验报告)

线性表的存储结构定义及基本操作(实验报告)线性表的存储结构定义及基本操作一掌握线性表的逻辑特征掌握线性表顺序存储结构的特点熟练掌握顺序表的基本运算熟练掌握线性表的链式存储结构定义及基本操作理解循环链表和双链表的特点和基本运算加深对顺序存储数据结构的理解和链式存储数据结构的理解逐步培养解决实际问题的编程能力二一基本实验内容顺序表建立顺序表完成顺序表的基本操作初始化插入删除逆转输出销毁置空表求表长查找元素判线性表是否为空1 问题描述利用顺序表设计一组输入数据假定为一组整数能够对顺序表进行如下操作创建一个新的顺序表实现动态空间分配的初始化根据顺序表结点的位置插入一个新结点位置插入也可以根据给定的值进行插入值插入形成有序顺序表根据顺序表结点的位置删除一个结点位置删除也可以根据给定的值删除对应的第一个结点或者删除指定值的所有结点值删除利用最少的空间实现顺序表元素的逆转实现顺序表的各个元素的输出彻底销毁顺序线性表回收所分配的空间对顺序线性表的所有元素删除置为空表返回其数据元素个数按序号查找根据顺序表的特点可以随机存取直接可以定位于第 i 个结点查找该元素的值对查找结果进行返回按值查找根据给定数据元素的值只能顺序比较查找该元素的位置对查找结果进行返回判断顺序表中是否有元素存在对判断结果进行返回编写主程序实现对各不同的算法调用2 实现要求对顺序表的各项操作一定要编写成为C C 语言函数组合成模块化的形式每个算法的实现要从时间复杂度和空间复杂度上进行评价初始化算法的操作结果构造一个空的顺序线性表对顺序表的空间进行动态管理实现动态分配回收和增加存储空间位置插入算法的初始条件顺序线性表L已存在给定的元素位置为i且1≤i ≤ListLength L 1操作结果在L中第i个位置之前插入新的数据元素eL的长度加1位置删除算法的初始条件顺序线性表L已存在1≤i≤ListLength L 操作结果删除L的第i个数据元素并用e返回其值L的长度减1逆转算法的初始条件顺序线性表L已存在操作结果依次对L的每个数据元素进行交换为了使用最少的额外空间对顺序表的元素进行交换输出算法的初始条件顺序线性表L已存在操作结果依次对L的每个数据元素进行输出销毁算法初始条件顺序线性表L已存在操作结果销毁顺序线性表 L置空表算法初始条件顺序线性表L已存在操作结果将L重置为空表求表长算法初始条件顺序线性表L已存在操作结果返回L中数据元素个数按序号查找算法初始条件顺序线性表 L 已存在元素位置为 i且 1≤i≤ListLength L 操作结果返回 L 中第 i 个数据元素的值按值查找算法初始条件顺序线性表 L 已存在元素值为 e 操作结果返回 L 中数据元素值为 e 的元素位置判表空算法初始条件顺序线性表 L 已存在操作结果若 L 为空表则返回 TRUE否则返回 FALSE分析修改输入数据预期输出并验证输出的结果加深对有关算法的理解二基本实验内容单链表建立单链表完成链表带表头结点的基本操作建立链表插入删除查找输出求前驱求后继两个有序链表的合并操作其他基本操作还有销毁链表将链表置为空表求链表的长度获取某位置结点的内容搜索结点1 问题描述利用线性表的链式存储结构设计一组输入数据假定为一组整数能够对单链表进行如下操作初始化一个带表头结点的空链表创建一个单链表是从无到有地建立起一个链表即一个一个地输入各结点数据并建立起前后相互链接的关系又分为逆位序插在表头输入 n 个元素的值和正位序插在表尾输入 n 个元素的值插入结点可以根据给定位置进行插入位置插入也可以根据结点的值插入到已知的链表中值插入且保持结点的数据按原来的递增次序排列形成有序链表删除结点可以根据给定位置进行删除位置删除也可以把链表中查找结点的值为搜索对象的结点全部删除值删除输出单链表的内容是将链表中各结点的数据依次显示直到链表尾结点编写主程序实现对各不同的算法调用其它的操作算法描述略2 实现要求对链表的各项操作一定要编写成为 C C 语言函数组合成模块化的形式还要针对每个算法的实现从时间复杂度和空间复杂度上进行评价初始化算法的操作结果构造一个空的线性表 L产生头结点并使 L 指向此头结点建立链表算法初始条件空链存在操作结果选择逆位序或正位序的方法建立一个单链表并且返回完成的结果链表位置插入算法初始条件已知单链表 L 存在操作结果在带头结点的单链线性表 L 中第 i 个位置之前插入元素 e链表位置删除算法初始条件已知单链表 L 存在操作结果在带头结点的单链线性表 L 中删除第 i 个元素并由 e 返回其值输出算法初始条件链表 L 已存在操作结果依次输出链表的各个结点的值三扩展实验内容顺序表查前驱元素查后继元素顺序表合并等1 问题描述根据给定元素的值求出前驱元素根据给定元素的值求出后继元素对已建好的两个顺序表进行合并操作若原线性表中元素非递减有序排列要求合并后的结果还是有序有序合并对于原顺序表中元素无序排列的合并只是完成 A A∪B 无序合并要求同样的数据元素只出现一次修改主程序实现对各不同的算法调用2 实现要求查前驱元素算法初始条件顺序线性表 L 已存在操作结果若数据元素存在且不是第一个则返回前驱否则操作失败查后继元素算法初始条件顺序线性表 L 已存在操作结果若数据元素存在且不是最后一个则返回后继否则操作失败无序合并算法的初始条件已知线性表 La 和 Lb操作结果将所有在线性表 Lb 中但不在 La 中的数据元素插入到 La 中有序合并算法的初始条件已知线性表 La 和 Lb 中的数据元素按值非递减排列操作结果归并 La 和 Lb 得到新的线性表 LcLc 的数据元素也按值非递减排列四扩展实验内容链表1 问题描述求前驱结点是根据给定结点的值在单链表中搜索其当前结点的后继结点值为给定的值将当前结点返回求后继结点是根据给定结点的值在单链表中搜索其当前结点的值为给定的值将后继结点返回两个有序链表的合并是分别将两个单链表的结点依次插入到第 3 个单链表中继续保持结点有序2 实现要求求前驱算法初始条件线性表 L 已存在操作结果若 cur_e 是 L 的数据元素且不是第一个则用 pre_e 返回它的前驱求后继算法初始条件线性表 L 已存在操作结果若 cur_e 是 L 的数据元素且不是最后一个则用 next_e 返回它的后继两个有序链表的合并算法初始条件线性表单链线性表 La 和 Lb 的元素按值非递减排列操作结果归并 La 和 Lb 得到新的单链表三实验环境和实验步骤实验环境利用CodeBlocks1005集成开发环境进行本实验的操作实验步骤――顺序表的定义与操作1启动CodeBlocks1052按Create a new project 通过file 按CC source选择c然后GO储存文件D\c语言\顺序表c3进行编代码4编好之后搞ctrlshiftF9进行编译然后按ctrlF105如果编译出问题然后进行调试实验步骤――链表的定义与操作1启动CodeBlocks1052按Create a new project 通过file 按CC source选择c然后GO储存文件D\c语言\单链表c3进行编代码4编好之后搞ctrlshiftF9进行编译然后按ctrlF105如果编译出问题然后进行调试四 includeinclude "stdlibh"includedefine LIST_INIT_SIZE 100define ok 1define ERROR 0define OVERFLOW -1define Num 3typedef int DataTypetypedef int Statustypedef structDataType elemint Lengthint ListsizeSeqListSeqList LStatus InitSeqList SeqList LL- elem Da。
线性表的存储结构定义及基本操作

一、实验目的:. 掌握线性表的逻辑特征. 掌握线性表顺序存储结构的特点,熟练掌握顺序表的基本运算. 熟练掌握线性表的链式存储结构定义及基本操作. 理解循环链表和双链表的特点和基本运算. 加深对顺序存储数据结构的理解和链式存储数据结构的理解,逐步培养解决实际问题的编程能力二、实验内容:(一)基本实验内容(顺序表):建立顺序表,完成顺序表的基本操作:初始化、插入、删除、逆转、输出、销毁, 置空表、求表长、查找元素、判线性表是否为空;1.问题描述:利用顺序表,设计一组输入数据(假定为一组整数),能够对顺序表进行如下操作:. 创建一个新的顺序表,实现动态空间分配的初始化;. 根据顺序表结点的位置插入一个新结点(位置插入),也可以根据给定的值进行插入(值插入),形成有序顺序表;. 根据顺序表结点的位置删除一个结点(位置删除),也可以根据给定的值删除对应的第一个结点,或者删除指定值的所有结点(值删除);. 利用最少的空间实现顺序表元素的逆转;. 实现顺序表的各个元素的输出;. 彻底销毁顺序线性表,回收所分配的空间;. 对顺序线性表的所有元素删除,置为空表;. 返回其数据元素个数;. 按序号查找,根据顺序表的特点,可以随机存取,直接可以定位于第i 个结点,查找该元素的值,对查找结果进行返回;. 按值查找,根据给定数据元素的值,只能顺序比较,查找该元素的位置,对查找结果进行返回;. 判断顺序表中是否有元素存在,对判断结果进行返回;. 编写主程序,实现对各不同的算法调用。
2.实现要求:对顺序表的各项操作一定要编写成为C(C++)语言函数,组合成模块化的形式,每个算法的实现要从时间复杂度和空间复杂度上进行评价;. “初始化算法”的操作结果:构造一个空的顺序线性表。
对顺序表的空间进行动态管理,实现动态分配、回收和增加存储空间;. “位置插入算法”的初始条件:顺序线性表L 已存在,给定的元素位置为i,且1≤i≤ListLength(L)+1 ;操作结果:在L 中第i 个位置之前插入新的数据元素e,L 的长度加1;. “位置删除算法”的初始条件:顺序线性表L 已存在,1≤i≤ListLength(L) ;操作结果:删除L 的第i 个数据元素,并用e 返回其值,L 的长度减1 ;. “逆转算法”的初始条件:顺序线性表L 已存在;操作结果:依次对L 的每个数据元素进行交换,为了使用最少的额外空间,对顺序表的元素进行交换;. “输出算法”的初始条件:顺序线性表L 已存在;操作结果:依次对L 的每个数据元素进行输出;. “销毁算法”初始条件:顺序线性表L 已存在;操作结果:销毁顺序线性表L;. “置空表算法”初始条件:顺序线性表L 已存在;操作结果:将L 重置为空表;. “求表长算法”初始条件:顺序线性表L 已存在;操作结果:返回L 中数据元素个数;. “按序号查找算法”初始条件:顺序线性表L 已存在,元素位置为i,且1≤i≤ListLength(L)操作结果:返回L 中第i 个数据元素的值. “按值查找算法”初始条件:顺序线性表L 已存在,元素值为e;操作结果:返回L 中数据元素值为e 的元素位置;. “判表空算法”初始条件:顺序线性表L 已存在;操作结果:若L 为空表,则返回TRUE,否则返回FALSE;分析: 修改输入数据,预期输出并验证输出的结果,加深对有关算法的理解。
单链表数据结构

插入
if (p != NULL && j == i-1) { // 找到第i个结点
s = (LinkList) malloc ( sizeof (LNode)); // 生成新结点
s->data = e;
// 数据域赋值
s->next = p->next; //新结点指针指向后一结点
p->next = s; return OK;
6、销毁
4.6 销毁操作
while(L) { p = L->next; free(L); L=p;
// p指向第一结点(头节点为“哑结点”) // 释放首结点 // L指向p
}
// 销毁完成后,L为空(NULL)
算法的时间复杂度为:O(ListLength(L))
判空 求表长
4.7 其它操作
if(L->next==NULL) return TRUE; // 空
5、清空
4.5 清空操作
while (L->next) { p = L->next; L->next = p->next; free(p);
// p指向当前结点 // 头结点指向当前结点的后结点 // 释放当前结点内存
}
// 清空完成后,仍保留头结点L
算法的时间复杂度为:O(ListLength(L))
点。
5.1.2 逆序建立单链表
①建立一个带头结点的空单链表;
②输入数据元素ai,建立新结点p, 并把p插入在头结点之后成为第一个 结点。
③重复执行②步,直到完成单链表的 建立。
a1
a2 a1
创建出来的链表 点顺序与插入操作
顺序相反。
链表的反转与合并掌握链表反转和合并操作的实现

链表的反转与合并掌握链表反转和合并操作的实现链表是一种常见的数据结构,它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。
链表的反转和合并是链表操作中常见且重要的操作,在很多编程问题中都有应用。
本文将介绍链表的反转和合并操作的实现方法。
一、链表的反转链表的反转是指将链表中节点的顺序反向排列。
例如,对于链表1→2→3→4→5,反转后的链表为5→4→3→2→1。
实现链表的反转有两种常见的方法:迭代法和递归法。
1. 迭代法迭代法的实现思路是,从链表头节点开始,依次遍历每个节点,将该节点的指针指向前一个节点。
具体步骤如下:1)定义三个指针:当前节点指针cur、前一个节点指针prev、下一个节点指针next。
2)遍历链表,将当前节点的指针指向前一个节点,然后更新prev、cur和next指针的位置。
3)重复上述步骤,直到遍历到链表末尾。
以下是迭代法的实现代码示例(使用Python语言):```pythondef reverse_list(head):prev = Nonecur = headwhile cur:next = cur.nextcur.next = prevprev = curcur = nextreturn prev```2. 递归法递归法的实现思路是,从链表的尾节点开始,依次反转每个节点。
具体步骤如下:1)递归地反转除最后一个节点外的链表。
2)将当前节点的指针指向前一个节点。
3)返回反转后的链表的头节点。
以下是递归法的实现代码示例(使用Python语言):```pythondef reverse_list(head):if not head or not head.next:return headnew_head = reverse_list(head.next)head.next.next = headhead.next = Nonereturn new_head```二、链表的合并链表的合并是指将两个有序链表按照一定的规则合并成一个有序链表。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
}
if (p==NULL)
return(0);
else
return(n);
}
int ListInsert(LinkList *&L,int i,ElemType e)
{
int j=0;
LinkList *p=L,*s;
while (j<i-1 && p!=NULL)
{
j++;
p=p->next;
if(p1->value < p2->value)
{
ph = p1;
p = p1;
p1 = p1->next;
}
else
{
ph = p2;
p = p2;
p2 = p2->next;
}
while(p1 && p2)
{
if(p1->value < p2->value)
{
p->next = p1;
p = p1;
}
if (p==NULL)//未找到第i-1个结点
return 0;
else//找到第i-1个结点*p
{
s=(LinkList *)malloc(sizeof(LinkList));//创建新结点*s
s->data=e;
s->next=p->next;//将*s插入到*p之后
p->next=s;
return 1;
typedef char ElemType;
typedef struct LNode//定义单链表结点类型
{
ElemType data;
struct LNode *next;
} LinkList;
void InitList(LinkList *&L)
{
L=(LinkList *)malloc(sizeof(LinkList));//创建头结点
L->next=NULL;
}
void DestroyList(LinkList *&L)
{
LinkList *p=L,*q=p->next;
while (q!=NULL)
{
free(p);
p=q;
q=p->next;
}
free(p);
}
int ListEmpty(LinkList *L)
{
return(L->next==NULL);
}
int ListLength(LinkList *L)
{
LinkList *p=L;int i=0;
while (p->next!=NULL)
{
i++;
p=p->next;
}
return(i);
}
void DispList(LinkList *L)
{
LinkList *p=L->next;
while (p!=NULL)
p1 = p1->next;
}elBiblioteka e{p->next = p2;
p = p2;
p2 = p2->next;
}
}
if(!p1) p->next = p2;
if(!p2) p->next = p1;
return ph;
}
//文件名:algo2-2.cpp
#include <stdio.h>
#include <malloc.h>
if (p==NULL)
return 0;
else
{
e=p->data;
return 1;
}
}
int LocateElem(LinkList *L,ElemType e)
{
LinkList *p=L->next;
int n=1;
while (p!=NULL && p->data!=e)
{
p=p->next;
//合并两个有序单链表,并返回合并后新链表的头指针
LNode MergeLink(LNode p1,LNode p2)
{
if(!p1) return p1; //如果链表为空,则直接返回另一个链表
if(!p2) return p2; //如果链表为空,则直接返回另一个链表
LNode ph, p; //ph合并后新链表的头指针
{
q=p->next;//q指向要删除的结点
if (q==NULL) return 0;
e=q->data;
p->next=q->next;//从单链表中删除*q结点
free(q);//释放*q结点
return 1;
}
}
{
printf("%c",p->data);
p=p->next;
}
printf("\n");
}
int GetElem(LinkList *L,int i,ElemType &e)
{
int j=0;
LinkList *p=L;
while (j<i && p!=NULL)
{
j++;
p=p->next;
}
}
}
int ListDelete(LinkList *&L,int i,ElemType &e)
{
int j=0;
LinkList *p=L,*q;
while (j<i-1 && p!=NULL)
{
j++;
p=p->next;
}
if (p==NULL)//未找到第i-1个结点
return 0;
else//找到第i-1个结点*p