数据结构第七章参考答案
数据结构章节练习题-答案第7章图

7.1 选择题1. 对于一个具有n个顶点和e条边的有向图,在用邻接表表示图时,拓扑排序算法时间复杂度为()A) O(n)B)O(n+e)C) O(n*n)D)O(n*n*n)【答案】B2. 设无向图的顶点个数为n,则该图最多有()条边。
A) n-1B)n(n-1)/2C)n(n+1)/2【答案】B3. 连通分量指的是()A) 无向图中的极小连通子图B) 无向图中的极大连通子图C) 有向图中的极小连通子图D) 有向图中的极大连通子图【答案】B4. n 个结点的完全有向图含有边的数目()A) n*n B) n(n+1) C) n/2【答案】D5. 关键路径是()A) AOE网中从源点到汇点的最长路径B) AOE网中从源点到汇点的最短路径C) AOV网中从源点到汇点的最长路径D) n2D) n* (n-1)D) AOV网中从源点到汇点的最短路径【答案】 A 6.有向图中一个顶点的度是该顶点的()A)入度B)出度C)入度与出度之和D)(入度+出度)12【答案】C7.有e 条边的无向图,若用邻接表存储,表中有()边结点。
A) e B) 2eC) e-1D) 2(e-1)【答案】B8.实现图的广度优先搜索算法需使用的辅助数据结构为()A)栈B)队列C)二叉树D)树【答案】B9.实现图的非递归深度优先搜索算法需使用的辅助数据结构为()A)栈B)队列C)二叉树D)树【答案】 A 10.存储无向图的邻接矩阵一定是一个()A)上三角矩阵B)稀疏矩阵C)对称矩阵D)对角矩阵【答案】C11.在一个有向图中所有顶点的入度之和等于出度之和的()倍A) B) 1C) 2D) 4答案】B12.在图采用邻接表存储时,求最小生成树的Prim 算法的时间复杂度为(A) O(n)B) O(n+e)C 0(n2)D) 0(n3))【答案】B13 .下列关于AOE网的叙述中,不正确的是()A) 关键活动不按期完成就会影响整个工程的完成时间B) 任何一个关键活动提前完成,那么整个工程将会提前完成C) 所有的关键活动提前完成,那么整个工程将会提前完成D) 某些关键活动提前完成,那么整个工程将会提前完成【答案】B14. 具有10 个顶点的无向图至少有多少条边才能保证连通()A ) 9B) 10C) 11D) 12【答案】A15. 在含n 个顶点和e 条边的无向图的邻接矩阵中,零元素的个数为()A)e B)2eC)n2-e D)n2-2e【答案】D7.2 填空题1 .无向图中所有顶点的度数之和等于所有边数的________________ 倍。
数据结构第七章习题答案

第七章图
1.下面是一个图的邻接表结构,画出此图,并根据此存储结构和深度优先搜索算法写出从C开始的深度优先搜索序列。
1
2
3
4
5
【解答】
A B F
C D E
C开始的深度优先搜索序列:CDEABF(唯一的结果)
2.假定要在某县所辖六个镇(含县城)之间修公路,若镇I和镇J 之间有可能通过道路连接,则Wij表示这条路的长度。
要求每个镇都通公路且所修公路总里程最短,那么应选择哪些线路来修。
(1).画出该图。
(2).用C语言描述该图的数组表示法存储结构,并注明你所使用变量
的实际含义。
(3).图示你所定义的数据结构。
(4).标识出你选择的线路。
【解答】 (1)
(2)
#define MAX 6 typedef struct {
char vexs[MAX]; // 顶点信息 int arcs[MAX][MAX]; // 边的信息
int vexnum, arcnum; // 顶点数,边数 } MGraph; (3)略
(4){(1,3), (3,4), (2,4), (4,5), (5,6)}
3.图G 如下所示。
(1).给出该图的所有强连通分量。
(2).在图中删除弧<2,1>,然后写出从顶点1开始的拓扑有序序列。
5
4
6
1
3
2
4
15 10
2
15
20
30
4
10
10
【解答】
(1) 共4个强连通分量:
(2) 1,3,2,6,5,4。
数据结构 第7章习题答案

第7章 《图》习题参考答案一、单选题(每题1分,共16分)( C )1. 在一个图中,所有顶点的度数之和等于图的边数的 倍。
A .1/2 B. 1 C. 2 D. 4 (B )2. 在一个有向图中,所有顶点的入度之和等于所有顶点的出度之和的 倍。
A .1/2 B. 1 C. 2 D. 4 ( B )3. 有8个结点的无向图最多有 条边。
A .14 B. 28 C. 56 D. 112 ( C )4. 有8个结点的无向连通图最少有 条边。
A .5 B. 6 C. 7 D. 8 ( C )5. 有8个结点的有向完全图有 条边。
A .14 B. 28 C. 56 D. 112 (B )6. 用邻接表表示图进行广度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列 C. 树 D. 图 ( A )7. 用邻接表表示图进行深度优先遍历时,通常是采用 来实现算法的。
A .栈 B. 队列 C. 树 D. 图 ()8. 已知图的邻接矩阵,根据算法思想,则从顶点0出发按深度优先遍历的结点序列是( D )9. 已知图的邻接矩阵同上题8,根据算法,则从顶点0出发,按深度优先遍历的结点序列是A . 0 2 4 3 1 5 6 B. 0 1 3 5 6 4 2C. 0 4 2 3 1 6 5D. 0 1 2 34 6 5 ( D )10. 已知图的邻接表如下所示,根据算法,则从顶点0出发按深度优先遍历的结点序列是( A )11. 已知图的邻接表如下所示,根据算法,则从顶点0出发按广度优先遍历的结点序列是A .0 2 4 3 1 5 6B. 0 1 3 6 5 4 2C. 0 1 3 4 2 5 6D. 0 3 6 1 5 4 2⎥⎥⎥⎥⎥⎥⎥⎥⎥⎦⎤⎢⎢⎢⎢⎢⎢⎢⎢⎢⎣⎡0100011101100001011010110011001000110010011011110A .0 1 3 2 B. 0 2 3 1 C. 0 3 2 1 D. 0 1 2 3(A)12. 深度优先遍历类似于二叉树的A.先序遍历 B. 中序遍历 C. 后序遍历 D. 层次遍历(D)13. 广度优先遍历类似于二叉树的A.先序遍历 B. 中序遍历 C. 后序遍历 D. 层次遍历(A)14. 任何一个无向连通图的最小生成树A.只有一棵 B. 一棵或多棵 C. 一定有多棵 D. 可能不存在(注,生成树不唯一,但最小生成树唯一,即边权之和或树权最小的情况唯一)二、填空题(每空1分,共20分)1. 图有邻接矩阵、邻接表等存储结构,遍历图有深度优先遍历、广度优先遍历等方法。
《数据结构(C语言版 第2版)》(严蔚敏 著)第七章练习题答案

《数据结构(C语言版第2版)》(严蔚敏著)第七章练习题答案第7章查找1.选择题(1)对n个元素的表做顺序查找时,若查找每个元素的概率相同,则平均查找长度为()。
A.(n-1)/2B.n/2C.(n+1)/2D.n答案:C解释:总查找次数N=1+2+3+…+n=n(n+1)/2,则平均查找长度为N/n=(n+1)/2。
(2)适用于折半查找的表的存储方式及元素排列要求为()。
A.链接方式存储,元素无序B.链接方式存储,元素有序C.顺序方式存储,元素无序D.顺序方式存储,元素有序答案:D解释:折半查找要求线性表必须采用顺序存储结构,而且表中元素按关键字有序排列。
(3)如果要求一个线性表既能较快的查找,又能适应动态变化的要求,最好采用()查找法。
A.顺序查找B.折半查找C.分块查找D.哈希查找答案:C解释:分块查找的优点是:在表中插入和删除数据元素时,只要找到该元素对应的块,就可以在该块内进行插入和删除运算。
由于块内是无序的,故插入和删除比较容易,无需进行大量移动。
如果线性表既要快速查找又经常动态变化,则可采用分块查找。
(4)折半查找有序表(4,6,10,12,20,30,50,70,88,100)。
若查找表中元素58,则它将依次与表中()比较大小,查找结果是失败。
A.20,70,30,50B.30,88,70,50C.20,50D.30,88,50答案:A解释:表中共10个元素,第一次取⎣(1+10)/2⎦=5,与第五个元素20比较,58大于20,再取⎣(6+10)/2⎦=8,与第八个元素70比较,依次类推再与30、50比较,最终查找失败。
(5)对22个记录的有序表作折半查找,当查找失败时,至少需要比较()次关键字。
A.3B.4C.5D.6答案:B解释:22个记录的有序表,其折半查找的判定树深度为⎣log222⎦+1=5,且该判定树不是满二叉树,即查找失败时至多比较5次,至少比较4次。
(6)折半搜索与二叉排序树的时间性能()。
数据结构课后习题答案第七章
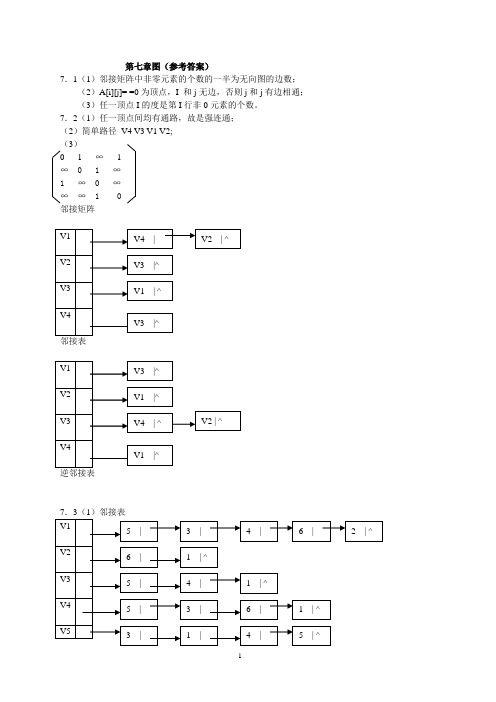
第七章图(参考答案)7.1(1)邻接矩阵中非零元素的个数的一半为无向图的边数;(2)A[i][j]= =0为顶点,I 和j无边,否则j和j有边相通;(3)任一顶点I的度是第I行非0元素的个数。
7.2(1)任一顶点间均有通路,故是强连通;(2)简单路径V4 V3 V1 V2;(3)0 1 ∞ 1∞ 0 1 ∞1 ∞ 0 ∞∞∞ 1 0邻接矩阵邻接表(2)从顶点4开始的DFS序列:V5,V3,V4,V6,V2,V1(3)从顶点4开始的BFS序列:V4,V5,V3,V6,V1,V27.4(1)①adjlisttp g; vtxptr i,j; //全程变量② void dfs(vtxptr x)//从顶点x开始深度优先遍历图g。
在遍历中若发现顶点j,则说明顶点i和j间有路径。
{ visited[x]=1; //置访问标记if (y= =j){ found=1;exit(0);}//有通路,退出else { p=g[x].firstarc;//找x的第一邻接点while (p!=null){ k=p->adjvex;if (!visited[k])dfs(k);p=p->nextarc;//下一邻接点}}③ void connect_DFS (adjlisttp g)//基于图的深度优先遍历策略,本算法判断一邻接表为存储结构的图g种,是否存在顶点i //到顶点j的路径。
设 1<=i ,j<=n,i<>j.{ visited[1..n]=0;found=0;scanf (&i,&j);dfs (i);if (found) printf (” 顶点”,i,”和顶点”,j,”有路径”);else printf (” 顶点”,i,”和顶点”,j,”无路径”);}// void connect_DFS(2)宽度优先遍历全程变量,调用函数与(1)相同,下面仅写宽度优先遍历部分。
数据结构第七章考试题库[含答案]
![数据结构第七章考试题库[含答案]](https://img.taocdn.com/s3/m/fe02a251e87101f69e319598.png)
第七章图一、选择题1.图中有关路径的定义是()。
【北方交通大学 2001 一、24 (2分)】A.由顶点和相邻顶点序偶构成的边所形成的序列 B.由不同顶点所形成的序列C.由不同边所形成的序列 D.上述定义都不是2.设无向图的顶点个数为n,则该图最多有()条边。
A.n-1 B.n(n-1)/2 C. n(n+1)/2 D.0 E.n2【清华大学 1998 一、5 (2分)】【西安电子科技大 1998 一、6 (2分)】【北京航空航天大学 1999 一、7 (2分)】3.一个n个顶点的连通无向图,其边的个数至少为()。
【浙江大学 1999 四、4 (4分)】A.n-1 B.n C.n+1 D.nlogn;4.要连通具有n个顶点的有向图,至少需要()条边。
【北京航空航天大学 2000 一、6(2分)】A.n-l B.n C.n+l D.2n5.n个结点的完全有向图含有边的数目()。
【中山大学 1998 二、9 (2分)】A.n*n B.n(n+1) C.n/2 D.n*(n-l)6.一个有n个结点的图,最少有()个连通分量,最多有()个连通分量。
A.0 B.1 C.n-1 D.n【北京邮电大学 2000 二、5 (20/8分)】7.在一个无向图中,所有顶点的度数之和等于所有边数()倍,在一个有向图中,所有顶点的入度之和等于所有顶点出度之和的()倍。
【哈尔滨工业大学 2001 二、3 (2分)】A.1/2 B.2 C.1 D.48.用有向无环图描述表达式(A+B)*((A+B)/A),至少需要顶点的数目为( )。
【中山大学1999一、14】A.5 B.6 C.8 D.99.用DFS遍历一个无环有向图,并在DFS算法退栈返回时打印相应的顶点,则输出的顶点序列是( )。
A.逆拓扑有序 B.拓扑有序 C.无序的【中科院软件所1998】10.下面结构中最适于表示稀疏无向图的是(),适于表示稀疏有向图的是()。
A.邻接矩阵 B.逆邻接表 C.邻接多重表 D.十字链表 E.邻接表【北京工业大学 2001 一、3 (2分)】11.下列哪一种图的邻接矩阵是对称矩阵?()【北方交通大学 2001 一、11 (2分)】A.有向图 B.无向图 C.AOV网 D.AOE网12.从邻接阵矩可以看出,该图共有(①)个顶点;如果是有向图该图共有(②)条弧;如果是无向图,则共有(③)条边。
数据结构第七章参考答案

习题71.填空题(1)由10000个结点构成的二叉排序树,在等概率查找的条件下,查找成功时的平均查找长度的最大值可能达到(___________)。
答案:5000.5(2)长度为11的有序序列:1,12,13,24,35,36,47,58,59,69,71进行等概率查找,如果采用顺序查找,则平均查找长度为(___________),如果采用二分查找,则平均查找长度为(___________),如果采用哈希查找,哈希表长为15,哈希函数为H(key)=key%13,采用线性探测解决地址冲突,即d i=(H(key)+i)%15,则平均查找长度为(保留1位小数)(___________)。
答案:6,3,1.6(3)在折半查找中,查找终止的条件为(___________)。
答案:找到匹配元素或者low>high?(4)某索引顺序表共有元素275个,平均分成5块。
若先对索引表采用顺序查找,再对块元素进行顺序查找,则等概率情况下,分块查找成功的平均查找长度是(___________)。
答案:31(5)高度为8的平衡二叉树的结点数至少是(___________)。
答案: 54 计算公式:F(n)=F(n-1)+F(n-2)+1(6)对于这个序列{25,43,62,31,48,56},采用的散列函数为H(k)=k%7,则元素48的同义词是(___________)。
答案:62(7)在各种查找方法中,平均查找长度与结点个数无关的查找方法是(___________)。
答案:散列查找(8)一个按元素值排好的顺序表(长度大于2),分别用顺序查找和折半查找与给定值相等的元素,平均比较次数分别是s和b,在查找成功的情况下,s和b的关系是(___________);在查找不成功的情况下,s和b的关系是(___________)。
答案:(1)(2s-1)b=2s([log2(2s-1)]+1)-2[log2(2s-1)]+1+1(2)分两种情况考虑,见解答。
数据结构第七章的习题答案

数据结构第七章的习题答案数据结构第七章的习题答案数据结构是计算机科学中非常重要的一门学科,它研究如何组织和管理数据以便高效地访问和操作。
第七章是数据结构课程中的一个关键章节,它涵盖了树和二叉树这两个重要的数据结构。
本文将为读者提供第七章习题的详细解答,帮助读者更好地理解和掌握这些概念。
1. 问题:给定一个二叉树,如何判断它是否是二叉搜索树?解答:要判断一个二叉树是否是二叉搜索树,我们可以使用中序遍历的方法。
中序遍历会按照从小到大的顺序访问二叉树中的节点。
所以,如果一个二叉树是二叉搜索树,那么它的中序遍历结果应该是一个有序的序列。
具体实现时,我们可以使用递归或者迭代的方式进行中序遍历,并将遍历的结果保存在一个数组中。
然后,我们检查这个数组是否是有序的即可判断二叉树是否是二叉搜索树。
2. 问题:给定一个二叉树,如何找到它的最大深度?解答:要找到一个二叉树的最大深度,我们可以使用递归的方式。
对于每个节点,它的最大深度等于其左子树和右子树中的最大深度加1。
递归的终止条件是节点为空,此时深度为0。
具体实现时,我们可以定义一个递归函数,该函数接收一个节点作为参数,并返回以该节点为根节点的子树的最大深度。
在递归函数中,我们先判断节点是否为空,如果为空则返回0;否则,我们分别计算左子树和右子树的最大深度,然后取两者中的较大值加1作为当前节点的最大深度。
3. 问题:给定一个二叉树,如何判断它是否是平衡二叉树?解答:要判断一个二叉树是否是平衡二叉树,我们可以使用递归的方式。
对于每个节点,我们分别计算其左子树和右子树的高度差,如果高度差大于1,则该二叉树不是平衡二叉树。
具体实现时,我们可以定义一个递归函数,该函数接收一个节点作为参数,并返回以该节点为根节点的子树的高度。
在递归函数中,我们先判断节点是否为空,如果为空则返回0;否则,我们分别计算左子树和右子树的高度,然后取两者中的较大值加1作为当前节点的高度。
最后,我们判断左子树和右子树的高度差是否大于1,如果大于1,则该二叉树不是平衡二叉树。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
习题7
1.填空题
(1)由10000个结点构成的二叉排序树,在等概率查找的条件下,查找成功时的平均查找长度的最大值可能达到(___________)。
答案:5000.5
(2)长度为11的有序序列:1,12,13,24,35,36,47,58,59,69,71进行等概率查找,如果采用顺序查找,则平均查找长度为(___________),如果采用二分查找,则平均查找长度为(___________),如果采用哈希查找,哈希表长为15,哈希函数为H(key)=key%13,采用线性探测解决地址冲突,即d i=(H(key)+i)%15,则平均查找长度为(保留1位小数)(___________)。
答案:6,3,1.6
(3)在折半查找中,查找终止的条件为(___________)。
答案:找到匹配元素或者low>high?
(4)某索引顺序表共有元素275个,平均分成5块。
若先对索引表采用顺序查找,再对块元素进行顺序查找,则等概率情况下,分块查找成功的平均查找长度是(___________)。
答案:31
(5)高度为8的平衡二叉树的结点数至少是(___________)。
答案: 54 计算公式:F(n)=F(n-1)+F(n-2)+1
(6)对于这个序列{25,43,62,31,48,56},采用的散列函数为H(k)=k%7,则元素48的同义词是(___________)。
答案:62
(7)在各种查找方法中,平均查找长度与结点个数无关的查找方法是(___________)。
答案:散列查找
(8)一个按元素值排好的顺序表(长度大于2),分别用顺序查找和折半查找与给定值相等的元素,平均比较次数分别是s和b,在查找成功的情况下,s和b的关系是(___________);在查找不成功的情况下,s和b的关系是(___________)。
答案:(1)(2s-1)b=2s([log2(2s-1)]+1)-2[log2(2s-1)]+1+1
(2)分两种情况考虑,见解答。
解: (1)设所有元素的个数为n,显然有s=n*(n+1)/(2n),则
n=2s-1
设折半查找树高度为k,则前k-1层是满二叉树,最后一层的节点数为
n-(2k-1 -1)
因此,总比较次数
nb=20*1+21*2+22*3+…+2k-2*(k-1)+(n-(2k-1 -1))*k,
而
20*1+21*2+22*3+…+2k-2*(k-1)=2k-1*k-2k+1
因此
nb=2k-1*k-2k+1+(n-(2k-1-1))*k=(n+1)k-2k+1
又k=[log2n]+1,n=2s-1,所以有
(2s-1)b=2s([log2(2s-1)]+1)-2[log2(2s-1)]+1+1
(2)查找不成功,对于顺序查找有:s=n。
对于折半查找,找不到的情况有n+1种,查找
到每个叶子节点或度为1的节点后就不再查找,设折半查找树高度为k,则第k-1层的节点数x=2k-2,第k层的节点数y=n-(2k-1 -1)
(a)当第k层的节点数y小于等于第k-1层的节点数x时,
则第k-1层有y结点度为1,其余x-y个结点度为0。
则查找次数为:(n+1)b=2yk+2(x-y)(k-1)+y(k-1)=2x(k-1)+yk
(n+1)b=2k-1 *(k-1)+(n-(2k-1 -1))*k
(b)当第k层的节点数y大于第k-1层的节点数x时,
则第k-1层不存在度为0的结点,有2x-y个结点度为1,其余y-x个结点度为2
则查找次数为:(n+1)b=2yk+(2x-y)(k-1)=2x(k-1)+y(k+1)
(n+1)b=2k-1 *(k-1)+(n-(2k-1 -1))*(k+1)
将k=[log2n]+1,n=s分别代入(a)(b)两个等式即得。
2.选择题
(1)从一个具有n个结点的单链表中查找其值等于x的结点时,在查找成功的情况下,需平均比较()个结点。
A. n
B. n/2
C. (n-1)/2
D. (n+1)/2
(2)对一个长度为50的有序表进行折半查找,最多比较()次就能查找出结果。
A. 6
B. 7
C. 8
D. 9
(3)对有18个元素的有序表做折半查找,则查找A[3](下标从1开始)的比较序列的下标依次为()。
A. 1-2-3
B. 9-5-2-3
C. 9-5-3
D. 9-4-2-3
(4)在平衡二叉树中插入一个结点后造成了不平衡,设最低的不平衡点为A,并已知A的左孩子的平衡因子为-1,右孩子的平衡因子为0,则做()型调整以使其平衡。
A. LL
B. LR
C. RL
D. RR
(5)理论上,散列表的平均比较次数为()次。
A. 1
B. 2
C. 4
D. n
(6)二叉排序树中,最小值结点的()。
A. 左指针一定为空
B. 右指针一定为空
C. 左、右指针均为空
D. 左、右指针均不为空
(7)散列技术中的冲突指的是()。
A.两个元素具有相同的序号
B. 两个元素的键值不同,而其他属性相同
C. 数据元素过多
D. 不同键值的元素对应于相同的存储地址
(8)散列表表长m=14,散列函数H(k)=k%11。
表中已有15,38,61,84四个元素,如果用线性探测法处理冲突,则元素49的存储地址是()。
A. 8
B. 3
C. 5
D. 9
(9)采用线性探测法处理冲突所构成的闭散列表上进行查找,可能要探测多个位置,在查找成功的情况下,所探测的这些位置的键值()。
A. 一定都是同词义词
B. 一定都不是同义词
C. 不一定都是同义词
D. 都相同
(10)静态查找与动态查找的根本区别在于()。
A. 它们的逻辑结构不一样
B. 施加在其上的操作不同
C. 所包含的数据元素的类型不一样
D. 存储实现不一样
3.设一个散列表包含hashSize=13个表项,其下标从0到12,采用线性探查法解决冲突,请按以下要求,将关键码{10,100,32,45,58,126,3,29,200,400,0}散列到表中。
(1)散列函数采用除留余数法,用%hashSize(取余运算)将各关键码映像到表中,请指出每一个产生冲突的关键码可能产生多少次冲突。
答案:如下表,
产生冲突的关键码有:29-1次,45-1次,58-2次,126-2次,400-2次
(2)散列函数采用先将关键码各位数字折叠相加,再用%hashSize将相加的结果映像到表中的办法,请指出每一个产生冲突的关键码可能产生多少次冲突。
答案:如下表,
产生冲突的关键码有:100-1次,200-2次,400-2次,0-7次,126-1次
4.试编写一个函数,完成拉链法解决冲突的散列表上删除一个指定结点的算法。
5.设散列表的长度为13,散列函数为H(k)=k%13,给定的关键字序列为:19,14,23,01,68,20,84,27,55,11,10,79。
试画出分别用拉链法和线性探测查找解决冲突时所构造的散列表,并求出在等概率情况下,这两种方法的查找成功和查找不成功的平均查找长度。
答案:拉链法:
平均查找次数:成功时是21/12=1.75次,不成功时是(4+2+2+2+1+2+1)/13=12/13=0.92次(在这里查找比较是指元素值的比较。
如果指针为空,则不进行查找比较,此时不算查找)。
6次。