同济医学院SPSSSPSSLogistic回归
Spss软件之logistic回归分析

…
n
0
1
Xn01
X n02
…
1
0
X n11
X n12
…
2
0
Xn21
X n22
…
Xk X 10k X 11 k X 12k
X iMk
X n0k X n1 k X n2k
M
0
XnM1
XnM2
…
X nMk
Conditional logistic regression
用Pi表示第i层在一组危险因素作用下发病的概率, 条 件 logistic 模型可表示为
n
L
1
i1 1
M
k exp
j (X itj X i0 j )
t 1
j1
可以看出,条件logistic 回归分析只估计了表示危 险因素作用的βj值,表示匹配组效应的常数项βi0 则被自动地消去了。
Conditional logistic regression
对上述条件似然函数L取自然对数后,用非线性 迭代法求出参数的估计值bi及其标准误Sbi。回归 系数的假设检验及分析方法与非条件logistic回归 完全相同。
c1 1, c0 0,
Xj
1, 暴露
0,非暴露
ORj exp( j )
Logistic regression analysis
0,
ORj
1
无作用
ORj exp( j ), j >0, ORj 1 危险因子
0, ORj 1 保护因子
二、模型的参数估计
在logistic回归模型中,回归系数的估计通常用最大 似然法(MLE)。其基本思想是先建立一个样本 的似然函数,求似然函数达到最大值时参数的取 值,即为参数的极大似然估计值。
医院资料如何应用SPSS软件包进行Logistic回归分析

3.2
表2
8179例步敷民族患者年龄分布
合计
1762 3669 1994 754 8179
8179倒少数民族患者中,年龄多集中在20~40岁。造 影响少数民族身体健康的主要疾病是消化系统疾病.
成丁少数民族最佳劳动力的损失。
3 3
等兽维吾尔族咕萨克族回族鬣古接其他
,, <20 20~ 40— 60~ 94 232 11l 65 1499 3197 1712 593 7001 114 125 89 56 384 41 92 73 33 239 14 23 9 7 53
示无,4表示很多)
目标变量xx,=x03一X13(数学表达式)
定义条件:if z=1.
目标变量xx3=X13一x03(数学表达式) 定义条件:if
z=0。
喜吃卤食和盐渍食物(X∞与x12)0,1.2,3,4表示程 度(0表示不吃.4表示很喜欢吃) 精神状况(x03与X13)0表示差,1表示好 由于SPSS 10.0的版本未提供条件Logistic回归模型的 分析过程。需对数据进行处理,然后利用SPSS 10.0的非条 件1.ogkstic回归的分析过程来进行1:1条件Logistic回归。 根据1:1条件Logistic回归模型:
生=!:翌§
Q:§!!
£:垒21
1
g:蛆!
Q:!坐
2:!蛰垦:Q2
Q:Z!Q
结果解释类似二分类Logistic回归。以癌变(ID=3)为
类Logistic回归分析。 表4性别和新旧两种疗法治疗慢性支气是的疗效
性别
基准.分别用两个回归方程进行D水平1与Ⅲ水平3和 m水平2与m水平3的比较。回归系数经假设检验均有
3主要结果解释
SPSS软件在医学科研中的应用-Logistic回归分析

SPSS软件在医学科研中的应用计算机实习(SPSS10.0)何平平北大医学部流行病与卫生统计学系实习六Logistic回归分析(一)Logistic回归分析的任务影响因素分析在流行病学研究中,logistic回归常用于疾病的危险因素分析,logistic回归分析可以提供一个重要的指标:OR。
(二)Logistic回归分析的基本原理1.变量特点因变量:二分类变量,若令因变量为y,则常用y=1表示“发病”,y=0表示“不发病”(在病例对照研究中,分别表示病例组和对照组)。
自变量:可以为分类变量,也可以为连续变量。
2.Logistic模型Log P1 P = ®+®1x1+ ®2x2+ ...... + ®mxmP=P(y=1|x),为发病概率;1-P=P(y=0|x),为不发病概率。
®0为常数项,®1 ,®2 ….. ®m分别为m个自变量的回归系数。
模型估计方法:最大似然法(Maximum Likelihood Method)。
构造似然函数(L ikelihood function )L= P(y=1|x) P(y=0|x),通过迭代法估计一组参数(®0,®1 ,®2 ….. ®m)使L达到最大。
3.自变量的相对重要性分析衡量变量相对重要性的指标(1)Wald值:(®i /SE(®i ))2,近似⎪2分布,用于检验自变量的显著性。
(2)对自变量作显著性检验的概率P值。
当Wald值越大,P值越小时,自变量的影响就越大。
4.自变量的筛选与多元线性回归分析类似,有Forward法(实际上是逐步向前法)、Backward法(默认方法为Enter,即所有自变量一次全部进入方程)。
5.模型拟合的优良性指标(1)拟合分类表(Classification Table)根据Logistic回归型,对样本重新判别分类,符合率越高,模型拟合越好。
SPSS做Logistic回归步骤
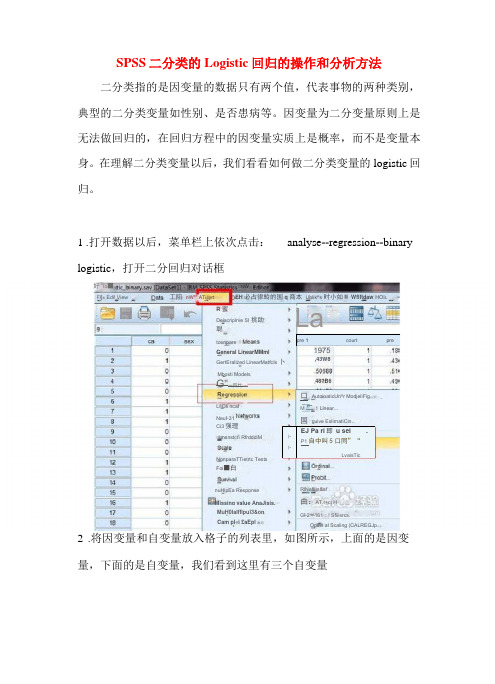
SPSS 二分类的Logistic 回归的操作和分析方法二分类指的是因变量的数据只有两个值,代表事物的两种类别, 典型的二分类变量如性别、是否患病等。
因变量为二分变量原则上是 无法做回归的,在回归方程中的因变量实质上是概率,而不是变量本 身。
在理解二分类变量以后,我们看看如何做二分类变量的logistic 回归。
1 .打开数据以后,菜单栏上依次点击: analyse --regression --binary logistic ,打开二分回归对话框2 .将因变量和自变量放入格子的列表里,如图所示,上面的是因变 量,下面的是自变量,我们看到这里有三个自变量pre 1courtpre卜 卜EJ Pa ri 即 u sei.P1自中叫5口同”“LvaisTic好 Io ■网 □N W□imsnstcri RfrdddiMNonparaTTietrtc Tests Foi ■白MuH0lalfflpul3&on Deiscriplrve SI 挑助聪LfiOli ncaf - Neuf-31 nuHlpEa ResponseMissing value AnaJisis. EH 必占律蛉的国q 商本 Ublik^s 时小如M Wflftdaw HOI LFl[« Edi! View工陷 nW"" ATiilyrtCam pl«i £aEpl 骷与Opsin al Scaling (CALREGJp..R 蜜GertEralized LinearMatfcIs 卜 Mbosti ModelsRlNafllin&af .曲:AT.r+ci HC] 2^^161;! Sfiiisrcs.tosnpareGeneral LinearMMml 48?B6Ci3强理 G"一四忙—一 3 La,43W8口 AutoioaticUn^r ModjeliFig..M 二1 Linear...国 guive EslirnatiCin...C>ep«n (lferit3 .设置回归方法,这里选择最简单的方法:enter ,它指的是将所有的 变量一次纳入到方程。
SPSS for logistic回归模型

Chi-square 1.624 1.624 1.624
df 3 3 3
Si g. .654 .654 .654
结果分析
模型的总的检 验情况
❖ 变量筛选方法用的是强行引入法或全回归法。此表 中显示共进行了1次,选入了3个变量。
简单分析实例
结果分析
Model Summary
模型摘要表
Step 1
-2 Log Cox & Snell
哑变量设置
例2 Hosmer 和Lemeshow于1989年研究了低出生体重 婴儿的影响因素,结果变量为是否娩出低出生体重 儿(变量名为LOW,1表示低出生体重儿,0表示非 低出生体重儿),考虑的自变量有产妇妊娠前体重、 产妇年龄、种族、是否吸烟、早产次数、是否患高 血压等。(数据文件见:logistic_step.sav。)
哑变量设置
❖ 哑变量设置应该注意的问题
参照水平最好要有实际意义,不推荐使用其他作为参照; 参照水平组要有一定的频数作保证,应不少于30或50例; 对有序自变量的分析:
从专业出发确定; 分别以哑变量和连续性变量的方式引入模型进行比较 后确定。
逐步回归
❖ 6 种筛选自变量的方法
Forward:Conditional (最可靠) Forward:LR Forward:Wald (应当慎用) Backward: Conditional (最可靠) Backward:LR Backward:Wald(应当慎用)
未患 病
患病
Overall Percentage
a. The cut value is .500
是否 患冠心 病
未患 病
患病
5
3
2
4
同济医学院SPSSSPSSLogistic回归PPT课件

料或分类资料
21
SPSS哑变量设置
Indicator Simple
参照分类为0,其余为1, 即各分类与参照分类比较
Difference 除第一类分类外,各分类与
Repeated
其之前平均分类效应比较
22
2020/1/10
23
SPSS哑变量设置
Helmert
与Difference相反,各水平与其之后水平的平 均效应比较
Deviation:
除参照分类外,各水平与分类的总效应比较
Polynomial
正交多项式设置
自动设置哑变量是有缺点的
等级变量不合适
24
哑变量设置应注意的问题
参照水平最好要有实际意义,不推荐使 用其他作为参照;
14
例1
研究急性心肌梗塞(AMI)患病与饮酒 的关系, 采用横断面调查。
饮酒 不饮酒 合计
(X=1) (X=0)
患病(y=1) 55
74
129
未患病(y=0) 104663 212555 317218
合计
104718 212629 317347
15
SPSS基本操作
16
SPSS基本操作
17
SPSS基本操作
所以 -< ln(Odds) <+
对ln(Odds)引入类似多重线性回归 的表达式
ln(Odds)
ln( P 1 P
)
0
1x1
m xm
10
Logistic回归模型
记:log it(P) ln( P ) 1 P
利用SPSS进行logistic回归分析(二元、多项)

线性回归是很重要的一种回归方法,但是线性回归只适用于因变量为连续型变量的情况,那如果因变量为分类变量呢?比方说我们想预测某个病人会不会痊愈,顾客会不会购买产品,等等,这时候我们就要用到logistic回归分析了。
Logistic回归主要分为三类,一种是因变量为二分类得logistic回归,这种回归叫做二项logistic回归,一种是因变量为无序多分类得logistic回归,比如倾向于选择哪种产品,这种回归叫做多项logistic回归。
还有一种是因变量为有序多分类的logistic回归,比如病重的程度是高,中,低呀等等,这种回归也叫累积logistic回归,或者序次logistic回归。
二值logistic回归:选择分析——回归——二元logistic,打开主面板,因变量勾选你的二分类变量,这个没有什么疑问,然后看下边写着一个协变量。
有没有很奇怪什么叫做协变量?在二元logistic回归里边可以认为协变量类似于自变量,或者就是自变量。
把你的自变量选到协变量的框框里边。
细心的朋友会发现,在指向协变量的那个箭头下边,还有一个小小的按钮,标着a*b,这个按钮的作用是用来选择交互项的。
我们知道,有时候两个变量合在一起会产生新的效应,比如年龄和结婚次数综合在一起,会对健康程度有一个新的影响,这时候,我们就认为两者有交互效应。
那么我们为了模型的准确,就把这个交互效应也选到模型里去。
我们在右边的那个框框里选择变量a,按住ctrl,在选择变量b,那么我们就同时选住这两个变量了,然后点那个a*b的按钮,这样,一个新的名字很长的变量就出现在协变量的框框里了,就是我们的交互作用的变量。
然后在下边有一个方法的下拉菜单。
默认的是进入,就是强迫所有选择的变量都进入到模型里边。
除去进入法以外,还有三种向前法,三种向后法。
一般默认进入就可以了,如果做出来的模型有变量的p值不合格,就用其他方法在做。
再下边的选择变量则是用来选择你的个案的。
SPSS专题2回归分析线性回归Logistic回归对数线性模型

(Constant)
410.150
18.817
21.797
.000
l i fe_expectancy_ femal e(year)
-4.896
.284
-.885
-17.252
.000
cl eanwateraccess_ rural (%)
-.237
a. Dependent Vari abl e: Di e before 5 per 1000
Kendall Spearman
Corre la ti ons
Kendal l's tau_b cl eanwateraccess_ rural (%)
cl eanwateracc
ess_rural (%)
Correl ati on Coeffi ci ent
1 . 00 0
Si g. (2-tai l ed)
Corre la ti ons
cl eanwateraccess_ rural (%)
Pearson Correl ati on Si g. (2-tai l ed)
cl eanwateracc e ss_ ru ra l(% )
l i fe_expectancy_ femal e(year)
N
Die before 5 per 1000
5
还有定性变量
下面是对三种收入对高一成绩和高一与初三成绩差的盒 形图
高一成绩与初三成绩之差 高一成绩
110
100
90
80
70
60
50
39 25
40
30
N=
11
27
12
1
2
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基础知识 P与Odds一一对应P Odds
1 Odds
对于两个Odds的比较,一般用它们的
Ratio,并称为Odds Ratio(OR),其定
义如下:
OR
Odds1
Odds2
其样础知识
P1 P2 Odds1 Odds2 OR 1
P1 P2 Odds1 Odds2 OR 1
参数估计的相关矩阵,均<0.80, 提示各协变量间相互独立
校正混杂作用
实例2:上例没有考虑吸烟情况,故将吸 烟作为分层加入,资料如下:
吸烟
不吸烟
饮酒% 不饮酒% 饮酒% 不饮酒%
患病 33(0.03) 21(0.03) 22(0.015) 53(0.015)
未患病 22331
14210 82332 198345
考虑多因素的影响,对于应变量(反应变量)为 计量资料,一般可以考虑应用多重线性回归模 型进行多因素分析。
数据分析的背景
单因素的分类资料统计分析,一般采用 Pearson 2进行统计检验,用Odds Ratio及其95%可信区间评价关联程度。
考虑多因素的影响,对于反应变量为分 类变量时,用线性回归模型P=a+bx就 不合适了,应选用Logistic回归模型进 行统计分析。
例如:研究患某疾病与饮酒的关联性
饮酒 不饮酒 合计
(X=1) (X=0)
患病(y=1)
a
b
n1
未患病(y=0) c
d
n2
合计
m1 m2 N
患病率 P1=a/m1 P2=b/m2
基础知识
Odds(优势) Odds P 1 P
Odds P (P 1) 1 1 1
1 P 1 P
1 P
P越大,则Odds越大;P越小,则Odds越小 并且 0<Odds<+
Difference 除第一类分类外,各分类与
Repeated
其之前平均分类效应比较
SPSS哑变量设置
Helmert
与Difference相反,各水平与其之后水平的平 均效应比较
Deviation:
除参照分类外,各水平与分类的总效应比较
Polynomial
正交多项式设置
自动设置哑变量是有缺点的
等级变量不合适
哑变量设置应注意的问题
参照水平最好要有实际意义,不推荐使 用其他作为参照;
参照水平组要有一定的频数作保证,应 不少于30或50例;
对有序自变量的分析:
从专业出发确定; 分别以哑变量和连续性变量的方式引入模型
进行比较后确定。
SPSS基本操作
SPSS基本操作
迭代过程
模型拟合优度指标, P值越大越好
如果对二项分类变量按+1与-1编码,那么结 果容易造成错误的解释。
分类变量必须转化。如地区对血压的影响。 等级资料,当等级之间量度不一时必须转化,
如正常,超重和肥胖 连续资料不宜直接进入方程时,转化为等级资
料或分类资料
SPSS哑变量设置
Indicator Simple
参照分类为0,其余为1, 即各分类与参照分类比较
SPSS应用
Logistic回归
华中科技大学公共卫生学院
流第行10病章学与非卫参生数统检计验学系
蒋红卫 jhwccc@
内容
基本概念 基本步骤 基本操作 基本结果解释
数据分析的背景
计量资料单因素统计分析 对于两组计量资料的比较,一般采用t检验或 秩和检验。 对于两个变量的相关分析采用Pearson相关 分析或Spearman相关分析
合计 22364
14231 82354 198398
SPSS基本操作
同例1
逐步回归分析
在多因素统计分析中,多个自变量之间存 在相关性,往往相互影响,研究者希望寻 找主要影响应变量Y的因素。
理论上,只要把各种因素组合都试一遍, 寻找变量个数最多,每个变量均有统计学 意义,并且模型拟合程度最好的模型,这 种模型称为最佳预测模型,这种方法称为 寻找最优子集,当变量较多时很难实现。
故比较两个率<==> 比较OR =1? OR>1 ? OR<1?
(二分类)Logistic回归模型
因为0<Odds<+ 所以 - < ln(Odds) <+
对ln(Odds)引入类似多重线性回归 的表达式
ln(Odds)
ln( P 1 P
)
0
1x1
m xm
Logistic回归模型
记:log it(P) ln( P ) 1 P
mxm
ln(Oddsx11) 0 1(x1 1) mxm
ln(OR) ln(Oddsx11) ln(Oddsx1 ) 1
OR e 反对数变换得到
1
回归系数的意义
多因素Logistic回归分析时,对回归系数的解释 都是指在其它所有自变量固定的情况下的优势比。
存在因素间交互作用时, Logistic回归系数的解 释变得更为复杂,应特别小心。
适用条件
反应变量为二分类变量或某事件的发生 率;
自变量与logit(P)之间为线性关系; 残差合计为0,且服从二项分布; 各观测间相互独立。 logistic回归模型应该使用最大似然法来
解决方程的估计和检验问题,不应当使 用以前的最小二乘法进行参数估计。
例1
研究急性心肌梗塞(AMI)患病与饮酒的 关系, 采用横断面调查。
Logistic回归模型
按研究设计分类 非配对设计:非条件Logistic回归模型 配对病例对照:条件Logistic回归模型
按反应变量分类 二分类Logistic回归模型(常用) 多分类无序Logistic回归模型 多分类有序Logistic回归模型
基础知识
通过下例引入和复习相关概念
饮酒 不饮酒 合计
(X=1) (X=0)
患病(y=1) 55
74
129
未患病(y=0) 104663 212555 317218
合计
104718 212629 317347
SPSS基本操作
SPSS基本操作
SPSS基本操作
SPSS基本操作
SPSS基本操作
哑变量设置
哑变量设置
为了便于解释,对二项分类变量一般按0、1编 码,一般以0表示阴性或较轻情况,而1表示阳 性或较严重情况。
故可以写为
log it(P) 0 1x1 mxm
也可以写为
P exp(0 1x1 m xm ) 1 exp(0 1x1 m xm )
回归系数的意义
以x1的回归系数1为例
固定其它自变量,比较x1与x1 +1的ln(Odds)变化。
对对于于xx11,+1,ln(Oddsx1 ) 0 1x1