基因本体数据库与GO富集分析
医学信息学5.DAVID分析差异基因GO和KEGG的富集

对于富集分析而言,一般情况下,大量基因组成的列表有更高的统计意义,对富 集程度高的特殊Terms有更高的敏感度。富集分析产生的p-value在相同或者数量相同的 基因列表中具有可比性。
Linux常用基本命令
Slide 3/ 20
Linux常用ห้องสมุดไป่ตู้本命令
Slide 10/ 20
DAVID对差异基因的GO和KEGG富集分析
⑤、Functional Annotation: [3]、 Functional Annotation Table
该工具实现了基因的功能注释,将输入列表中每个基因在选定数据库中的注释以 表格形式呈现。结果如图。
Options选项展开: 可以对阈值进行设置
此处两个值都设置为1,可以 查看全部数据的富集分析情况, 然后点击Rerun Using Options
点击此处导 出分析数据
Linux常用基本命令
GO KEGG Term
P. Value
Slide 17/ 20
DAVID对差异基因的GO和KEGG富集分析
⑤、Functional Annotation:
该工具是DAVID最核心的分析内容,包含了三个子工具:
[1]、 Functional Annotation Chart
该工具提供gene-term的富集分析。相比于其他富集分析软件而言,DAVID在该 功能上最显著的特点是,注释范围的可扩展性:从最初的GO注释,扩展到现在超过40 中的注释种类,包括GO注释,KEGG注释,蛋白相互作用,蛋白功能区域,疾病相关, 生物代谢通路,序列特点,异构体,基因功能总结,基因在组织里的表达和论文等。用 户可以根据需要选择其中的某些或者所有种类的注释信息。
基因本体论(go)功能注释 gene ontology annotation

基因本体论(go)功能注释 gene ontologyannotation基因本体论(Gene Ontology,简称GO)是一种用来描述基因功能的标准化系统。
GO的功能注释则是使用GO术语为基因或蛋白质序列进行注释,帮助科学家理解生物体内基因的功能和相互关系。
本文将介绍基因本体论(GO)的概念和作用,以及基因本体论功能注释的流程和应用。
一、基因本体论(GO)的概念和作用基因本体论(GO)是一种标准化的词汇系统,用于描述基因和蛋白质的功能、过程和组件。
GO包含三个主要的本体:分子功能(Molecular Function)、生物过程(Biological Process)和细胞组件(Cellular Component)。
每个本体都包含一系列术语和相应的定义,科学家可以根据这些术语和定义来描述基因的功能。
基因本体论的作用是帮助科学家对基因和蛋白质进行分类和理解。
通过将基因和蛋白质注释到GO术语上,科学家可以更准确地了解它们的功能、参与的生物过程以及位于细胞的哪个组件。
这对于研究基因的功能以及疾病的发生和发展有着至关重要的意义。
二、基因本体论功能注释的流程基因本体论功能注释是指将基因或蛋白质序列与基因本体论术语进行关联的过程。
下面是一般的基因本体论功能注释流程:1.数据预处理:获取待注释基因或蛋白质的序列数据,排除冗余数据和噪音数据。
2.基因本体论术语获取:从基因本体论数据库中获取相应的术语,包括分子功能、生物过程和细胞组件。
3.序列比对:将待注释的基因或蛋白质序列与已知序列进行比对,找出相似序列。
4.注释:根据序列比对的结果,将相似序列的注释信息转移到待注释序列上。
5.术语关联:根据注释信息,将待注释基因或蛋白质与相应的基因本体论术语进行关联。
6.结果验证:对注释结果进行验证和统计分析,评估注释的准确性和可靠性。
三、基因本体论功能注释的应用基因本体论功能注释在生命科学研究中有着广泛的应用。
以下是一些常见的应用领域:1.基因功能研究:通过注释基因的功能,科学家可以更好地理解基因在细胞中的作用,从而揭示生物体内复杂的生物过程。
实验6 基因芯片数据处理分析与GO分析

实验目的:
1. 学会使用 TM4 软件集对芯片数据进行处理和分析,学会使用 Cluster 进行聚类分析 3. 学会 GO 语义及其相关注释的浏览与搜索,学会使用 DAVID 进行基因集功能富集分析
实验内容:
一、基因芯片数据处理和分析
基因芯片或称微阵列(microarray)能够平行、高通量地检测成千上万基因转录本的表 达水平, 应用芯片技术可以比较正常和异常细胞中的表达, 帮助识别疾病相关基因和药物作 用靶标,分析复杂疾病的致病机制,也可以揭示基因间的表达调控关系。基因芯片数据处理 包括芯片杂交实验芯片数据采集(扫描)数据基本处理提交数据库生物信息学分析 等步骤,涉及很多不同的实验类型。这里介绍 TIGR 中心开发的 TM4 软件包,应用 MeV、 Cluster 和 TreeView 等软件对相关基因表达谱进行聚类分析和差异表达基因的筛选。
Figure 6.11 ( 2 ) 数 据 导 入 : 点 击 “Browse” 按 钮 , 打 开 软 件 自 带 的 表 达 量 数 据 文 件 :
TDMS_format_sample.txt , 样 本 数 据 便 自 动 加 载 到 “Expression File Loader” 窗 口 下 方 的 “Expression Table”栏(Figure 6.12) 。实验数据类型有两个选项:双色芯片(Two-color Array) 和单色芯片(Single-color Array) ,本例选择双色芯片。单击“Load”按钮将数据导入。
Figure 6.12 (3)显示基因表达情况:通过 Multiple Array Viewer 窗口看热图(Heat map) ,了解每 个基因在不同样本中的相对表达量(Figure 6.13) 。
kegg与go通路数据库介绍功能富集软件介绍

42
GO组成
GO提供了一系列的语义(terms)用来描述基因、基因 产物的特性。分三类:
1. 细胞组分(Cellular Component):用于描述亚细胞 结构、位置和大分子复 合物,如细胞核、端粒等; 2. 分子功能(Molecular Function):用于描述基因、 基因产物个体的功能,如酶活性,分子结合等;
41
GO 简介
GO (gene ontology)是基因本体联合会(Gene Ontology Consortium)所建立的数据库,旨在建立一个适用于各种 物种的,对在不同数据库中的基因和蛋白质产物进行限定 和一致性描述的,并能随着研究不断深入而更新的语义词 汇标准。 该数据库最初是由1998年对三个模式生物数据库的整合开 始:the FlyBase (果蝇数据库),the Saccharomyces Genome Database(酵母基因组数据库SGD) 和 the Mouse Genome Informatics(小鼠基因组数据库MGI)。随后,GO 不断发展扩大,现在已是包含多种动物、植物、微生物的 数据库。
2
下载数据
预处理的数据: E-GEOD 18842.processed.1.zip 原始数据: E-GEOD-18842.raw.1.zip E-GEOD-18842.raw.2.zip E-GEOD-18842.raw.3.zip 样本信息: E-GEOD-18842.sdrf.txt 平台信息: A-AFFY-44.adf.txt
3
芯片数据预处理步骤
1. 背景校正(Background Correction); 2. 标准化(Normalization); 3. 合并(Summary).
gene ontology enrichment analysis

gene ontology enrichment analysis基因本体富集分析(gene ontology enrichment analysis)是一种用来分析不同基因集间的差异性的方法,可以帮助研究人员识别出与某些生物学过程相关的基因及其功能。
本文将分步骤阐述常见的基因本体富集分析流程。
第一步:选取适当的基因集和背景集在进行基因本体富集分析前,需要确定一个需要研究的基因集,通常该集合由已有的基因测序数据得出。
接着,我们需要选择一个与研究对象相关的背景基因集,通常情况下,背景基因集就是研究对象中未包含的整体基因。
第二步:统计基因本体类别首先,我们需要对已确定的基因集进行注释,将其与已知的基因本体(GO term)进行匹配。
GO term是由一些标准化语言描述的基因功能和生物过程,包含三个主要分类:分子功能、细胞组成和生物过程。
从生物学的角度看,GO term能够帮助我们更好的了解基因之间的相互关系和作用,同时还能够对相关生物学过程进行分类和统计。
统计每个基因本体分类中包含的基因数,并对其进行比较。
如果一个基因本体类别中包含的基因数量显著多于在整个背景基因集中出现该类别的概率,则表明该类别在基因集中富集(enrichment)了。
第三步:确定显著性水平在第二步中,我们可以得到一堆基因本体富集的结果,但是,是否这些结果是有意义的需要通过设定显著性水平来判断。
显著性水平可以表示为P值、FDR或Benjamini/Hochberg等纠正方法。
依据统计方法的不同,显著性水平的数值也不同,最常用的是P值。
P值越小,差异性越显著。
第四步:结果展示和分析在最后一步中,我们需要对富集分析的结果进行展示和分析。
通常情况下,一个基因在多个基因本体类别间都可以分类,为了避免过度解释结果,我们通常会选择多重比较校正或者Bonferroni校正技术来控制假阳性率。
根据结果,我们可以进一步探索基因在不同基因本体分类中所具有的功能以及对不同生物过程的影响。
go analysis of up-regulated genes in ko

go analysis of up-regulated genes in ko
在基因表达分析中,对上调基因进行GO(基因本体论)分析是一种常见的手段。
上调基因是指在特定条件下,其表达水平相对于对照或基准条件有所增加的基因。
在GO分析中,首先需要准备目的基因文件,这个文件包含差异表达信息,如果使用工具自带的背景基因文件,那么目的基因文件的基因ID类型需要与背景基因文件一致。
然后,选择“使用文件”按钮上传目的基因和背景基因文件,如果是自己准备的背景基因文件则无此限制,只需目的基因id与背景基因id一致即可。
接下来,选择是否包含log2FC列,这是表示差异倍数取对数后的值。
物种选择也很重要,根据分析需求选择正确的物种。
最后,点击提交按钮,等待分析完成。
此外,GO富集分析的结果通常包括气泡图、条形图、富集圈图等,这些结果可以帮助理解上调基因在生物学过程中的角色。
对于KEGG 富集分析,其结果还可以在KEGG通路图上体现,比如红色表示上调,
绿色表示下调。
总之,通过GO和KEGG富集分析,可以对上调基因进行深入的功能和通路分析,从而更好地理解基因表达变化的生物学意义。
基因通路富集分析方法大总结
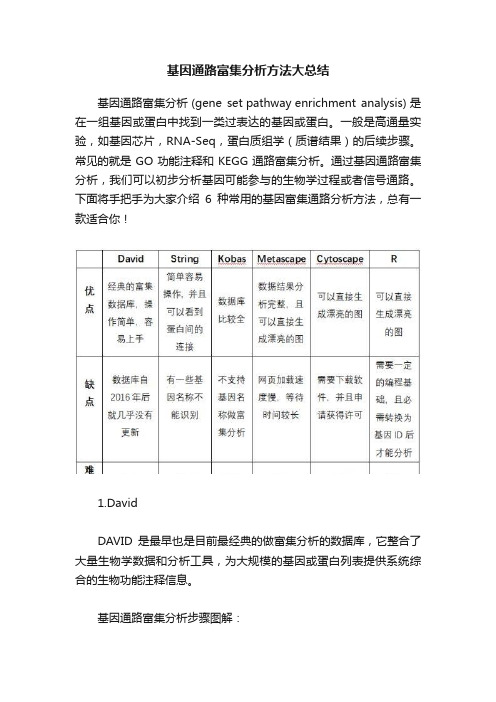
基因通路富集分析方法大总结基因通路富集分析 (gene set pathway enrichment analysis) 是在一组基因或蛋白中找到一类过表达的基因或蛋白。
一般是高通量实验,如基因芯片,RNA-Seq,蛋白质组学(质谱结果)的后续步骤。
常见的就是GO功能注释和KEGG通路富集分析。
通过基因通路富集分析,我们可以初步分析基因可能参与的生物学过程或者信号通路。
下面将手把手为大家介绍6种常用的基因富集通路分析方法,总有一款适合你!1.DavidDAVID是最早也是目前最经典的做富集分析的数据库,它整合了大量生物学数据和分析工具,为大规模的基因或蛋白列表提供系统综合的生物功能注释信息。
基因通路富集分析步骤图解:第一步:打开网址,点击Functional Annotation。
第二步:输入基因集,选择输入类型第三步:选择物种,查看结果(包括GO和KEGG通路结果)2.StringString数据库是瑞士苏黎世大学构建的一个搜寻蛋白质之间相互作用的数据库。
既包括蛋白质之间的直接物理相互作用,也包括蛋白质之间的间接功能相关性。
它除了包含有实验数据、从PubMed摘要中挖掘的结果和综合其他数据库数据外,还有利用生物信息学的方法预测的结果。
基因通路富集分析步骤图解:第一步:打开网站,输入基因列表和选择物种;第二步:选择数据库内对应基因名称;第三步:结果下载-包括Go和KEGG通路。
(如有需要还可以下载蛋白连接的结果)4.KobasKobas是北京大学开发的用于注释和鉴定富集途径和疾病的数据库基因通路富集分析步骤图解:第一步:打开网站,选择Gene-list Enrichment第二步:选择输入类型,物种,输入基因列表,选择数据库,后可分析下载数据。
5.MetascapeMetascape是近年来新兴的富集分析数据,数据不仅更新快,其覆盖面也相当广泛。
从数据库种类来说,Metascape整合了GO、KEGG、UniProt和DrugBank等多个权威的数据资源,使其不仅能完成通路富集和生物过程注释,还能做基因相关的蛋白质网络分析和涉及到的药物分析,致力于为科研工作者提供每个基因全面而详细的信息。
利用 agriGO 网络服务进行 GO 富集分析

利用agriGO网络服务进行GO富集分析苏震,徐文英,杜舟,周鑫1.分析目的随着生命科学的发展,越来越多的基因功能被实验验证或者预测推导,但如何规范地注释这些基因是一个难题。
基因本体论(Gene Ontology,GO)是一个在生物信息学领域中广泛使用的本体,应用于基因的功能注释和富集化分析。
GO是一个国际标准化的基因功能分类体系,提供了一套动态更新的标准词汇表,由Gene Ontology组织(/)开发并且维护。
并且,GO是对基因属性特征的客观描述,独立于任何物种或者细胞类型。
因此,我们利用GO,可以对不同物种、不同细胞类型下的基因功能进行规范的描述,避免了沟通上的不便,也可以将隐藏在文献中的基因功能信息更加有效地提取出来。
在动植物功能基因组的研究中,高通量技术的使用产生了海量的组学数据,比如在不同发育期、不同逆境处理下的转录组数据集可以多至上千个表达谱,如何分析和解释这些数据成为摆在生物学家面前的一个难题,而使用GO对基因功能注释进行富集分析,是一套较好的解决方案。
agriGO(GO Analysis Toolkit and Database for Agricultural Community)是一个专注农业物种(以植物物种为主)的GO功能注释与分析的网络数据库与在线分析平台。
agriGO采用的是一套具有完整结构的控制词汇集,使得对该系统可以更好地用于统计和运算,为生物信息学、生物统计学的研究带来了很大的便利。
2.分析工具Gene Ontology富集分析工具agriGO,网址:/agriGO//agriGOv2/参考文献:Zhou Du, Xin Zhou, Yi Ling, Zhenhai Zhang, and Zhen Su. (2010) agriGO: a GO analysis toolkit for the agricultural community. Nucleic Acids Research 38: W64-W70.Tian Tian, Yue Liu, Hengyu Yan, Qi You, Xin Yi, Zhou Du, Wenying Xu, Zhen Su; (2017) agriGO v2.0: a GO analysis toolkit for the agricultural community, 2017 update. Nucleic Acids Research. doi: 10.1093/nar/gkx3823.操作步骤采用agriGO平台提供的实例,练习agriGO中主要的分析工具(见/agriGO/analysis.php):Singular Enrichment Analysis (SEA) 、Parametric Analysis of Gene Set Enrichment (PAGE) 和Cross comparison of SEA (SEACOMPARE)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
注释系统中每一个结点都是基因或蛋白的一种描述,结点之间保持严格的关 系,即“is a”或“part of”。
(细胞质)
(细胞器)
(线粒体)
(细胞器膜)
is a· is a → is a
(线粒体)
(胞内细胞器)
part of·part of → part of
(线粒体)
(细胞质)
(细胞器)
part of·is a → part of 与is a·part of → part of
谢 谢
基因功能富集分析
P值的生物学意义决定于所提交的基因列表,例如, 如果列表中均为上调基因而某功能条目显著,则认为 此实验因素作用可能使这个功能激活;相反如果为下 调基因并且条目显著,则认为实验因素作用可能使这 个功能抑制。
基因功能富集分析
控制FDR(False Discovery Rate)值:在进行差异基因挑选时,整个 差异基因筛选过程需要做成千上万次假设检验,导致假阳性率的累积增 大。对于这种多重假设检验带来的放大的假阳性率,需要进行纠正。 FDR用比较温和的方法对p值进行了校正,在假阳性和假阴性间达到平衡, 将假/真阳性比例控制到一定范围之内。
提供目前可获得的基因或基因产物的功能。
涵盖了基因的细胞组分(cellular component)、分子功能 (molecular function)、生物学过程(biological process)。
GO注释是对某个特定基因功能的描述,每一条 GO注释,由一个基因和相应的GO term组成。
基因本体的基本单位是term,每个term都对应 一个属性。
从整体上来看GO注释系统是一个“有向无环 图”。
GO term之间关系表述
is a 子节点所描述的功能、细胞组分或生物过程从始至终都是 属于父节点的 part of 只有其中一部分属于父节点的 has part 与part of互补 从父节点的角度出发 regulates negatively regulates 负向调节 positively regulates 正向调节 箭头代表关系的方向 虚线表示推断的关系 实线表示注释的关 系
基因本体数据库
产生的背景与意义
随着后基因组时代研究的不断深入,基因组学的研究任务已由最 开始的基因组序列识别,渐渐转移到在整体分子水平对功能进行 研究。一个重要标志是功能基因组学的不断发展。
功能基因组学的主要任务之一是进行基因组功能注释(genome annotation),对进一步识别基因,研究基因的表达调控机制, 研究基因在生物体代谢途径中的地位,分析基因、基因产物之间 的相互作用关系,预测和发现蛋白质功能,揭示生命的起源和进 化等具有重 terms 之间的关系 /amigo www.ebi.ac.bk/QuickGO
基因功能富集分析
基因本体富集分析:一组基因直接注释的结果是得到大量的功能 结点。这些功能具有概念上的交叠现象,导致分析结果冗余,不 利于进一步的精细分析;鉴定功能一致的基因群体,使上千个分 子减少为较小数量的生物学功能,更容易理解一组分子改变的意 义。 富集分析方法通常是分析一组基因在某个功能结点上是否过出现。 这个原理可以由单个基因的注释分析发展到大基因集合的成组分 析。
GO的目的
解决生物学定义混乱的现象,使各 种数据库中基因产物功能描述相一 致
允许在各种水平查询基因产物的特 性
使得在不同生物数据库中的查询具 有极高的一致性
旨在建立一套适用于各种物种的, 对基因和蛋白质功能进行限定和描 述的,并能随着研究不断深入而更 新的语义词汇标准。
定义
基因本体数据库是GO组织(Gene Ontology Consortium) 在2000年构建的一个结构化的标准生物学模型,目的是建立基 因及其产物知识的标准词汇体系。