基于CRF和转换错误驱动学习的浅层句法分析
基于CRF和错误驱动的中心词识别

o n c o n d i t i o n r a n d o m i f e l d s m o d e l( C e d t h e C R F m o d e l i n t a g g i n g f o c u s e s i n t h e q u e s t i o n s i n i t i l a l y .
中图分 类号 : T P 3 1 1 ; T P 3 9 1 文献标 志码 :A 文章 编号 :1 0 0 1 — 3 6 9 5 ( 2 0 1 3 ) 0 8 — 2 3 4 5 - 0 4
d o i : 1 0 . 3 9 6 9 / j . i s s n . 1 0 0 1 — 3 6 9 5 . 2 0 1 3 . 0 8 . 0 2 6
Ke y w o r d s :q u e s t i o n c l a s s i i f c a t i o n ; f o c u s ; c o n d i t i o n r a n d o m i f e l d s m o d e l ( C R F ) ; t r a n s f o ma r t i o n - b a s e d e r r o r — d i r v e n l e a r n i n g
第3 0卷第 8期
2 0 1 3年 8 月
计 算 机 应 用 研 究
Ap p l i c a t i o n Re s e a r c h o f C o mp u t e r s
Vo l | 3 0 No . 8 Au g . 2 0 1 3
基于 C R F和错 误 驱 动 的 中心 词 识别 水
Re c o g n i t i o n o f f o c u s b a s e d o n C RF a n d T B L
【国家自然科学基金】_错误驱动学习_基金支持热词逐年推荐_【万方软件创新助手】_20140802
2014年 序号 1 2 3 4
科研热词 错误驱动 增量学习 svm kkt条件
推荐指数 1 1 1 1
年 序号
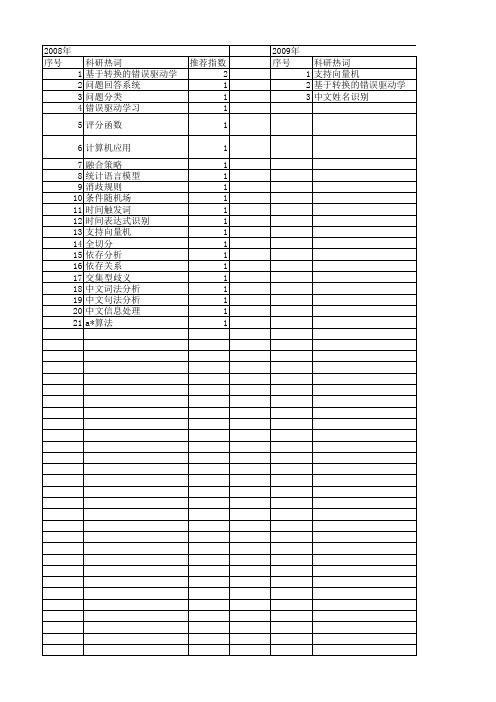
科研热词 1 支持向量机 2 基于转换的错误驱动学习 3 中文姓名识别
推荐指数 1 1 1
2010年 序号 1 2 3 4 5 6 7 8 9
科研热词 推荐指数 错误驱动 2 翻译模板 2 韵律结构预测 1 韵律短语 1 错误驱动的规则学习算法(tbl) 1 语法结构 1 语法树高度 1 等价对 1 nist评测 1
2011年 序号 1 2 3 4 5 6 7 8
2011年 科研热词 推荐指数 转换错误驱动学习 1 转换规则集 1 语调短语预测 1 浅层句法分析 1 模板生成 1 基于转换的错误驱动的学习(tbl) 1 分类与回归树(cart) 1 crf 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26
2013年 科研热词 韵律词 韵律短语 面部动画 隐markov模型 问题分类 错误驱动学习(tbl) 误差滤波器 译文质量 译文调序 词链交叉率 虚拟说话人 神经网络 短语翻译对 监督学习理论 物联网 条件随机场(crf) 有序规则 无线传感器网络 对等模式 头动生成 句法特征 冲突 信道错误 中心词 上下文信息 tbl算法 推荐指数 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2008年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21
科研热词 推荐指数 基于转换的错误驱动学习 2 问题回答系统 1 问题分类 1 错误驱动学习 1 评分函数 1 计算机应用 1 融合策略 1 统计语言模型 1 消歧规则 1 条件随机场 1 时间触发词 1 时间表达式识别 1 支持向量机 1 全切分 1 依存分析 1 依存关系 1 交集型歧义 1 中文词法分析 1 中文句法分析 1 中文信息处理 1 a*算法 1
基于改进线图分析算法的浅层汉语句法分析器的设计与实现

第2 4卷 第 9期
2 0 年 9月 07
计 算 机 应 用 研 究
Ap l a in Re e r h o mp tr p i t s a c fCo u e s c o
Vo . 4 No 9 12 . S p .2 0 et 0 7
基 于改 进 线 图分 析 算 法 的浅层 汉 语 句 法 分 析 器 的设 计 与 实现 术
吴江 宁 ,朱 国华
( 大连 理 工大 学 系统 工程研 究所 ,辽 宁 大连 1 6 2 ) 10 4
摘
要 :针 对传 统 的汉语 句法分析 算法进 行改进 , 用 了 自 向上与 自顶 向下相 结合 的线 图分 析方 法 , 采 底 分析 、 设
A bsr c : Ba e n t r dto a ha tag rtm ,t i p rp o os d a mpr v i e e s ntxpa sn lo tm ,whih ta t s d o heta iin lc r l o i h hspa e r p e n i o ed Ch n s y a ri ga g r h i c
c mb n d b t m D a d t p d w t tge r e n a c h f ce c n ep e iin o e C i e e s n a t n l- o ie o t u n o n sr e isi o d rt e h n e t eef in y a d t rc s f h h n s y tc i a ay o o a n o i h o t c ss t a o o e ftr eman mo u e ,te r o d s g n a in mo ue b s d o h x i m o d ln t th n i.I w sc mp s do e i d ls h ywe ew r e me tt d l a e n t ema mu w r - g h mac ig h o e a g rtm ,p r o p e h tg i gmo u e b s d o t t t a t o ftan n fr lt e ̄ q e c ,a d t e s n a a sn lo h i a t fs e c a gn d l a e n sai i lmeh d o ri i g o eai sc v e u n y n h y t p r ig x mo u eb s d o h mp o e h r a a y i ag rtn .A ma l i h n s op s w s u e o v ia e t e ef in y a d d l a e n te i r v d c at n l s lo i a s h s l sz C ie e c r u a s d t a d t h f c e c n — e l i fa ii t fte i r v d a g r h e s lyo bi h mp o e o i m. l t Ke r s txu r c s ig C i e e s na t n l s ; c a t l o i m; s n a a s r y tx sr c u e y wo d : e ta p o e sn ; h n s y tc i a a y i l c s h r ag r h t y tx p r e ;s na t t r u
使用AI技术进行自然语言处理的常用方法

使用AI技术进行自然语言处理的常用方法自然语言处理(Natural Language Processing, NLP)是人工智能领域中一个重要的子领域,旨在使计算机能够理解、分析和生成人类语言。
随着人们对自然语言处理应用的需求日益增长,AI技术在该领域得到了广泛应用。
本文将介绍一些常用的AI技术和方法,以实现有效的自然语言处理。
一、词法分析词法分析是NLP中最基础的任务之一,它涉及将句子拆分成单词并标记它们的属性。
通常,词法分析会使用标注器(Tagger)来为每个单词确定其类型或形式。
标注器根据任务需求可以是基于规则、统计模型或深度学习模型而设计。
1. 基于规则的标注:这种方法使用预定义的规则来确定每个单词的特征,例如正则表达式或简单规则集。
但是这种方法对于复杂结构或未知文本效果不佳。
2. 基于统计模型的标注:统计模型利用已经标记过的训练数据学习概率模型,并基于学习到的概率来为新句子中每个单词打标签。
常用的统计模型包括隐马尔可夫模型(Hidden Markov Model, HMM)和最大熵模型(Maximum Entropy Model, MEM)等。
3. 基于深度学习的标注:近年来,基于深度学习的NLP方法成为发展的热点。
使用深度学习模型如循环神经网络(Recurrent Neural Network, RNN)或卷积神经网络(Convolutional Neural Network, CNN)可以更准确地为文本打上标签。
二、句法分析句法分析是NLP中一个重要而复杂的任务,旨在确定句子中单词之间的依赖关系。
通常,句法分析可以通过两种方法来完成:基于规则和基于统计。
1. 基于规则的句法分析:这种方法使用人工定义的语法规则来解决句法分析问题。
例如,上下文无关文法(Context-Free Grammar, CFG)是一种流行的形式化语言表示方法,它将句子表示为推导树,并使用产生式规则描述单词之间的关系。
基于条件随机场的中文分词方法

基于条件随机场的中文分词方法
迟呈英;于长远;战学刚
【期刊名称】《情报杂志》
【年(卷),期】2008(027)005
【摘要】提出了一种基于条件随机场(Conditional Random Fields,简称CRF)的中文分词方法.CRF模型利用词的上下文信息,对歧义词和未登陆词进行分词统计处理取得了理想的效果.以SIGHAN2006 Chinese Language Processing Bakeoff 提供的数据作为实验数据.实验数据表明,基于CRF的中文分词方法取得了很好的效果,在Uppen,Msra两种语料的封闭测试中准确率分别达到了95.8%和95.9%.【总页数】3页(P79-81)
【作者】迟呈英;于长远;战学刚
【作者单位】辽宁科技大学,鞍山,114051;辽宁科技大学,鞍山,114051;辽宁科技大学,鞍山,114051
【正文语种】中文
【中图分类】G35
【相关文献】
1.词性标注的方法研究——结合条件随机场和基于转换学习的方法进行词性标注[J], 阴晋岭;王惠临
2.基于条件随机场的中文分词算法改进 [J], 顾佼佼;杨志宏;姜文志;胡文萱
3.基于链式条件随机场的中文分词改进方法 [J], 徐浩煜;任智慧;施俊;周晗
4.基于字位置概率特征的条件随机场中文分词方法 [J], 沈勤中;周国栋;朱巧明;孔
芳;丁金涛
5.基于字向量的条件随机场的中文分词方法 [J], 周寅
因版权原因,仅展示原文概要,查看原文内容请购买。
分布式策略与CRFs相结合识别汉语组块

分布式策略与CRFs相结合识别汉语组块
黄德根;于静
【期刊名称】《中文信息学报》
【年(卷),期】2009(23)1
【摘要】该文提出了一种基于CRFs的分布式策略及错误驱动的方法识别汉语组块.该方法首先将11种类型的汉语组块进行分组,结合CRFs构建不同的组块识别模型来识别组块;之后利用基于CRFs的错误驱动技术自动对分组组块进行二次识别;最后依据各分组F值大小顺序处理类型冲突.实验结果表明,基于CRFs的分布式策略及错误驱动方法识别汉语组块是有效的,系统开放式测试的精确率、召回率、F 值分别达到94.90%、91.00%和92.91%,好于单独的CRFs方法、分布式策略方法及其他组合方法.
【总页数】7页(P16-22)
【作者】黄德根;于静
【作者单位】大连理工大学,计算机科学与工程系,辽宁,大连,116024;大连理工大学,计算机科学与工程系,辽宁,大连,116024
【正文语种】中文
【中图分类】TP391
【相关文献】
1.SVM和基于转换的错误驱动学习相结合的汉语组块识别 [J], 邹宏梅;王挺
2.统计和规则相结合的汉语组块分析 [J], 李素建;刘群;白硕
3.基于CRF与RUTA规则相结合的卒中入院记录医学实体识别及应用 [J], 许源;葛艳秋;王强;熊刚;易应萍
4.基于CRFs的多策略生物医学命名实体识别 [J], 马瑞民;马民艳
5.基于CRF与RUTA规则相结合的卒中入院记录医学实体识别及应用 [J], 许源;葛艳秋;王强;熊刚;易应萍;;;;;;
因版权原因,仅展示原文概要,查看原文内容请购买。
自然语言处理中的句法分析方法及应用
自然语言处理中的句法分析方法及应用自然语言处理(Natural Language Processing,NLP)是人工智能领域的一个重要分支,旨在使计算机能够理解和处理人类语言。
在NLP中,句法分析是一项关键任务,它涉及对句子的结构和语法关系进行分析和解析。
本文将探讨句法分析的方法和应用。
一、句法分析方法句法分析是通过将句子分解为短语和句法结构来理解其语法关系。
目前,有多种句法分析方法被广泛应用于NLP任务中。
1. 基于规则的句法分析方法基于规则的句法分析方法是最早被提出的方法之一。
它通过定义一系列语法规则来分析句子的结构。
这些规则可以是基于上下文无关文法(Context-Free Grammar,CFG)的产生式规则,也可以是基于依存关系的转换规则。
然而,由于需要手动编写规则,这种方法在处理复杂的语言现象和大规模语料库时效果不佳。
2. 基于统计的句法分析方法基于统计的句法分析方法通过使用统计模型来学习句子的语法结构。
其中,最常用的模型是基于马尔可夫随机场(Markov Random Fields,MRF)的条件随机场(Conditional Random Fields,CRF)。
这种方法通过训练大量标注好的语料库来学习语法模型,然后使用该模型对新句子进行分析。
相比于基于规则的方法,基于统计的方法能够自动学习语言规律,并且在大规模语料库上表现出更好的性能。
3. 基于深度学习的句法分析方法近年来,随着深度学习的兴起,基于深度学习的句法分析方法也得到了广泛应用。
这种方法使用神经网络模型来学习句子的语法结构。
其中,最常用的模型是基于循环神经网络(Recurrent Neural Network,RNN)和长短期记忆网络(LongShort-Term Memory,LSTM)的模型。
这些模型能够自动学习句子的上下文信息,并在句法分析任务中取得了很好的效果。
二、句法分析的应用句法分析在NLP任务中有着广泛的应用。
基于CRF算法的汉语比较句识别和关系抽取
M i i g Ch n s o a a i e s n e c s a d r l to s b s d o l o ih n n i e e c mp r tv e t n e n e a i n a e n CRF a g rt m
H A G G oh i A inf g LU Q a — e g U N a—u,Y O Ta— n , I uns n a h
在 前人研 究的基础和 C R序 列规 则为特 征 , S 同时利 用 C F算 法抽取 实体 对 象 , R
并增加 以 实体 对 象的信 息作为特 征 , 著提 高 了比较 句识 别的 准确 率、 回率和 F 度 量 , 高分 别达 到9 .5 、 显 召 一 最 6 5%
a l o x n n e p cal o p n o n n .I i o e e e r h t d n i h n s o a aie s n e c sa d e t c be f rt tmi ig. s e i l fro i i n mi ig t Sa n v l s a c oi e t y C i e e c mp r t e t n e n xr t e y r f v a
黄 高 辉 , 天 防 , 全 升 姚 刘
( 海交通 大 学 计 算机 科 学与工程 系, 海 204 ) 上 上 020 摘 要 :比较 句是 表 明事物之 间 关 系的 常见表 达方 式 , 于文 本挖掘 , 别是 情感 分析 , 有 重要 的价 值。 目前 对 特 具
汉语 比较 句的研 究还是 一个新 颖的课 题 , 包括 汉 语 比 较 句 的 识 别 和 比 较 关 系 的 抽 取 。 对 于 汉 语 比较 句 的 识 别 ,
第2 7卷 第 6期
基于法院判决文书的法律知识图谱构建和补全
24
郑 州 大 学 学 报 (理 学 版)
第 53 卷
因此本文在以上问题的基础上,以“ 伪卡盗刷判决书” 为研究对象,目标是为每一份判决书文本构建出 的知识图谱进行自动补全。 主要的贡献有:
1) 整合了基于 StanfordNLP ( 斯坦福自然语言处理包) 的伪卡盗刷知识图谱构建流程,实验结果验证了 该流程的可行性与有效性,为下一步的补全工作提供了数据基础;
Step4 定义概念之间的关系。 概念的分类层次结构体现了分类概念间的一种继承关系。 但是在领域本 体中,概念和概念之间除了通过继承关系来交互,还根据需要定义其他关系。 如在本文中,警察和刑警之间 应该是相容关系。
根据上述本体的构建原则,本文 构 建 了 伪 卡 盗 刷 本 体 中 的 核 心 概 念 ( 部 分 ) ———人 物:开 户 人、盗 刷 人、 银行客服、警察等;报警:电话挂失、电话冻结、银行报警、电话报警等;刷卡:ATM 取现、柜台取现、POS 机刷 卡、网上支出等。 2. 2 伪卡盗刷判决书的语义角色标注和三元组的建立
摘要: 由于法律领域知识图谱专业性强、结构复杂,而现有的关系抽取方法因各个领域的需求和术语不同,无法适 用于法律领域知识图谱的构建和补全。 首先,提出了基于 StanfordNLP 关系 抽 取 机 制 的 法 律 知 识 图 谱 构 建 方 法;然 后,构建基于设置谓语导向词的深度学习模型对法律知识图谱进行补全;最后,选用典型案例( 伪卡盗刷判决书) 作 为文本对象验证模型的可行性。 与其他知识图谱补全模型相比,本模型的准确率达到 95% 以上。 基于谓语导向词 的 深 度 学 习 模 型 综 合 了 自 动 构 建 和 人 工 参 与 ,提 高 了 关 系 抽 取 的 准 确 率 和 补 全 的 效 率 ,能 最 大 程 度 挖 掘 判 决 书 文 本中的深层隐式关系,更好地发挥判决书文本的应用技术。 关键词: 关系抽取; 领域术语; 知识图谱构建; 深度学习 中图分类号: TP391 文献标志码: A 文章编号: 1671-6841( 2021) 03-0023-07 DOI: 10. 13705 / j. issn. 1671-6841. 2020304
基于CRF的中文组块分析
组块分析又称为部分句法分析 , 是与完全句法分析相对 的.完全句法分析是充分分析整个句子的 语法 特 点 , 大限度 地揭 示 句子 所反 映 的主题 内容 .而组 块 分 析仅 限于 把 句子 解 析 成 较小 的单 元 ,为 最
进 一步 揭示 这些单 元 问 的句法 关 系提供 依 据 , 而降低 分析 难度 . 从
X h n —i U Qa , I e U Z o gy,H i L U L i n
( oe eo o p t c ne n eh o g , in U i rt, h n cu 30 2 C i ) C lg C m u r i c dTcnl y J i nv sy C a gh n10 1 , hn l f eSe a o l ei a
近年 来 , 器学 习方 法在 数 据标 注 问题 中得 到 广 泛应 用 ,比较通 用 的方 法有 支 持 向量机 ( V 、 机 S M) 隐马 尔可 夫模 型 ( MM) 最 大熵 模 型 ( x u nrp ) H 、 Ma i m e t y 、最 大熵 马尔 可 夫模 型 ( MM) m o ME 以及 条 件 随
维普资讯
第4 5卷
第 3期
吉 林 大 学 学 报 (理 学 版 )
J U N L O II N V R I Y ( CE C DT O 0 R A FJLN U I E ST S IN E E IIN)
Vo . 5 No 3 14 . Ma 2 0 y 07
mo l y de ,b wh c Chie e e t h n ng r n fr d n o a e i t e ih n s tx c u ki ta so me i t lb l ng h wo ds r wi t er h k a s n t hi h c un t g a d e tbl h n d lfr tg e o pu c o d n o C n iin lr n m edsS st r d c h h n a f sa i i g a mo e o a g d c r s a c r i g t o d t a a do f l O a o p e itt e c u k t g o s o i
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2 0 [共 享 任务 中组块 的定义 , 合 中文 的特 点 对组块 进 行定 义 。中文 组块 的定 义 : 0 06 ] 结 组块 是 句子 中相 邻 的 词语 组成 的 序列 , 各个 组块 之 间不重 叠 、 不递 归 、 不嵌 套 , 个 组块具 有 一个核 心词 语 。组块 介 于词语 和句 每 子之 间 , 并且 具有 一定 的 句法功 能 , 各个 组块 之 间的关 系是 平行 的 。本文 定 义 了 6种组块 类 型 ( 型 , 占汉语 短语 总数 的 9 以上 。对 于 每个 组块 , 0, 9 6 都标 注一个 组 块标记 。本 文组 块 的边 界 标 注采 用 I 2 注 方 法L , 体 的标 注 规则 如 下 : — 表 示 当前 词是 组 块 x开 始 的词 ; I OB 标 7具 ] ①B X, ② — X, 示 当前 词是 组块 X 中 间或者 结尾 的词 ; 表 ③o, 表示 当前词 是 一个 不属 于任 何组 块 的词 。 1 2 组块 的 获取 .
浅 层句 法分 析 (h l w p rig , 叫部 分句法 分 析 ( at l as g 或 者组块 分 析 (h n as g 。 s al as ) 也 o n p ri ri ) ap n c u kp ri ) n 浅 层句 法分 析将 句法 分析 分成 : 块 的识 别 和分 析 ; 组 组块 间 的相互 依存关 系分 析 。 目前 浅 层句法 分析 的方 法 主 要 有 : 于统 计 的方 法 、 基 基于 规 则 的方 法 以及 统 计 和规 则 相 结 合 的 方 法 。在 英 文方 面 , d E 利用 Ku ol i S VM 取 得 了很好 的 组块识 别 效果 ; 中文 的组块 识 别方面 , 广路 等 [利用 统计 的方 法 进行 组块 的识 别 , 在 孙 2 ] 黄 德根 等[ 利用 C F识别 汉语 组块 。本文将 利 用 C 3 ] R RF和 转换 错误 驱动 学 习相 结合 的方 法进 行 浅层 句法
分 析 。C RF模 型 克服 了传 统 机器 学 习方 法 中存 在 的标注 偏 置 问题 L , 基 于转 换 的错误 驱 动学 习则 可 以 4而 ]
进 一步提 高 组块 的识 别率 。
组 块 的定 义与 获 取
1 1 组 块 的定义 . 组 块 的 定 义 对 组 块 分 析 的结 果 有 很 大 影 响 。本 文 根 据 Ab e [ 对 英 语 组 块 的 定 义 以及 C NL 一 n y5 ] o L
第2 9卷
第 3期
广 西师 范大 学学 报 : 自然 科学 版
Ju n l f a g i oma Unvri : trl c n eE io o ra n x r l ies y Naua i c dt n o Gu N t Se i
Vo . 9 No 3 12 .
Se .2 pt 011
目前 中文还 没 有统 一 的组 块语 料库 , 本文 将从 宾 州大 学 中文 树库 5 0版 本 中抽 取 组块 建 立 汉语 组块 .
库 。该 树库 共 有 1 8 87 2个 句子 , 5 72 2个单 词 ,2 8 个 汉 字 , 为 8 0个 数据文 件 存储 。宾 州大学 约 0 2 8 49 3 分 9 中文 树库 中 原有 2 3种 短语 类 型 , 根据 上 文组 块定 义从 中抽 取 了 6种常用 类型 的组块 , 如表 2所 示 。
摘
要 : 文 提 出一 种 C F和 基 于 转 换 错误 驱 动 相 结 合 的 中 文 浅 层 句 法 分 析 方 法 。 方 法 应 用 于 宾 州 大 学 中 本 R 该
文树库 , 取得不错 的组块识别效 果。 C 在 RF识 别的基础上 , 对初始识别 结果中的组块标注信息进行统计分析 ,
收 稿 日期 :0 10 —5 2 1-52 基 金项 目 : 家 自然 科 学 基 金 资 助 项 目 ( 0 7 1 3 60 3 1 ) 国 家 哲 学 社 科 基 金 资 助 项 目( O Y 2 ) 江 苏 省 自然 国 6 7 3 7 ,1 7 1 9 ; 1C Y0 1 ; 科 学 基 金 资 助 项 目 ( K2 1 5 7 ; 苏 省 教 育 厅 自然 科学 基 金 资 助 项 目(O J 5 O 0 ) 江 苏 省高 校 社 科 基 B 004)江 1 K B 2 09 ; 金 资 助项 目( 6J 7 0 7 0 SB 1 0 )
2 1 年 9月 01
基 于 C F和 转 换 错 误 驱 动 学 习的 浅 层 句 法分 析 R
张 芬 , 。 曲维 光 h , 红艳 h , 俊 生h 。 赵 。周
(. 1 南京师范大学 计算机科学与技术学院 , 江苏 南京 2 0 4 }. 1 0 6 2 江苏省信息安全保密技术研究中心, 苏 南京 2 1 9 ; 江 0 1 7 3 .南京师范大学 语言信息科技研究 中心 , 江苏 南京 2 1 9 ) 0 1 7
获得 候 选 转 换 规 则 集 合 ; 根 据 定 义 的 规 则 评 价 函 数 对 候 选 集 进 行 筛选 , 到 最 终 的 转 换 规 则 集 合 ; 后 应 用 再 得 最 转 换 规 则 集 对 C F标 注 的 结 果 进 行 校 正 。 实 验结 果表 明 , 单 独 使 用 C R 与 RF结 果 相 比 , 块 识 别 的 精 确 率 、 组 召 回率 以 及 F值 均 得 到 了 提 高 。 关 键 词 : 层 句 法 分 析 ;RF; 换 错 误 驱 动学 习 ; 换 规 则 集 浅 C 转 转 中 图分 类号 : P 9 . T 311 文献 标 识 码 : A 文章 编号 :0 160 (0 10 —1 70 10 —6 0 2 1 ) 304 —4