基于影响度的隐私保护关联规则挖掘算法
信息安全工程师考点—隐私保护

信息安全工程师考点—隐私保护,希望对在备考信息安全工程师的考生有所帮助。
考点5、隐私保护【考法分析】本考点主要是隐私保护相关内容的考查。
【要点分析】1.从隐私所有者的角度,隐私可以分为以下三类:①个人隐私;②通信内容隐私;③行为隐私。
2.隐私泄露方式:①互联网服务;②智能终端;③黑客攻击;④管理者监听。
3.从数据挖掘的角度,目前的隐私保护技术主要可以分为三类:①基于数据失真的隐私保护技术;②基于数据加密的隐私保护技术;③基于数据匿名化的隐私保护技术。
4.数据失真技术通过扰动原始数据来实现隐私保护。
基于数据失真的技术通过添加噪音等方法,使敏感数据失真但同时保持某些数据或数据属性不变,仍然可以保持某些统计方面的性质。
①随机化:数据随机化即是对原始数据加入随机噪声,然后发布扰动后数据的方法。
②阻塞与凝聚:随机化技术一个无法避免的缺点是:针对不同的应用都需要设计特定的算法对转换后的数据进行处理,因为所有的应用都需要重建数据的分布。
鉴于随机化技术存在的这个缺陷,研究人员提出了凝聚技术:它将原始数据记录分成组,每一组内存储着由k 条记录产生的统计信息,包捂每个属性的均值、协方差等。
这样,只要是采用凝聚技术处理的数据,都可以用通用的重构算法进行处理。
③差分隐私保护:差分隐私保护可以保证,在数据集中添加或删除一条数据不会影响到查询输出结果,因此即使在最坏情况下,攻击者己知除一条记录之外的所有敏感数据,仍可以保证这一条记录的敏感信息不会被泄露。
5.基于数据加密的隐私保护技术所针对的数据对象往往是分布式的。
在分布式环境下,根据应用的不同,数据会有不同的存储模式,站点也会有不雨的可信度及相应行为。
6.分布式应用普遍采用两种模式存储数据:垂直划分的数据模式和水平划分的数据模式。
垂直划分数据是指分布式环境中每个站点只存储部分属性的数据,所有站点存锚的数据不重复;水平划分数据是将数据记录存储到分布式环境中的多个站点,所有站点存储的数据不重复。
数据挖掘方法及其应用研究

数据挖掘方法及其应用研究数据挖掘是一种从大量数据中自动发掘出有用信息的技术,对于信息化时代的企业而言,数据挖掘技术的应用已经成为了提高业务水平和核心竞争力的必备手段。
本文将从数据挖掘的方法、应用以及研究方面进行探讨。
一、数据挖掘的方法数据挖掘的方法主要是基于数据分析和机器学习的,其中数据分析主要包括关联规则和分类预测等。
首先,关联规则挖掘是指在数据集中发掘出事物之间的关联性,比如“如果顾客购买了巧克力,那么他们很有可能也会购买口香糖”,而分类预测则是对数据进行分类,比如“根据用户的浏览记录,预测他们最可能会购买哪些商品”。
而机器学习是数据挖掘的核心技术,它是一种通过数据自我修正以提高性能的方法。
常见的机器学习方法包括决策树、神经网络以及聚类等。
决策树是一种用于分类和预测的树形结构,它将数据以节点的形式进行分类,直到数据达到叶节点,从而做出相应的决策;神经网络则是通过构建一种类比于人类大脑的模型来识别模式,进行分类或预测;而聚类则是在数据集中查找相似之处并将数据分组的方法。
二、数据挖掘的应用数据挖掘技术在各行各业的应用越来越广泛,比如在金融行业中常用于信用评估、欺诈检测以及风险管理等方面。
在零售业中,数据挖掘技术可以用于用户行为分析及商品推荐,以此提高销售额和用户忠诚度。
而在医疗领域,数据挖掘技术则可以用来提高早期预警、疾病诊断和药物研发等方面的能力。
此外,数据挖掘技术在交通、安全、舆情监测及人工智能等领域也发挥着越来越重要的作用。
三、数据挖掘的研究在数据挖掘的研究方面,目前有诸多的挑战。
首先,各类数据源的结构化程度参差不齐,挖掘数据的质量和有效性面临着较大的挑战。
其次,代表性和可扩展性是数据挖掘领域中的两大难点,它们影响着数据挖掘结果的可靠性和准确性。
另外,数据挖掘算法的集成和融合也是研究方向之一,通过多种算法的组合和协同来解决特定问题,进一步提高数据挖掘的效率和准确性。
最后,隐私保护和信息安全问题也是需要重点关注的研究方向,保障数据隐私的同时,也使得挖掘结果更加可靠。
关联规则简介与Apriori算法课件

评估关联规则的置信度,以确定规则是否具有可信度 。
剪枝
根据规则的置信度和支持度进行剪枝,去除低置信度 和低支持度的规则。
04 Apriori算法的优化策略
基于散列的技术
散列技术
通过散列函数将数据项映射到固定大小的桶中,具有相同散列值的数据项被分配 到同一个桶中。这种方法可以减少候选项集的数量,提高算法效率。
散列函数选择
选择合适的散列函数可以减少冲突,提高散列技术的效率。需要考虑散列函数的 均匀分布性和稳定性。
基于排序的方法
排序技术
对数据项按照某种顺序进行排序,如 按照支持度降序排序,优先处理支持 度较高的数据项,减少不必要的计算 和比较。
排序算法选择
选择高效的排序算法可以提高算法效 率,如快速排序、归并排序等。
关联规则的分类
关联规则可以根据不同的标准进行分类。
根据不同的标准,关联规则可以分为多种类型。根据规则中涉及的项的数量,可以分为单维关联规则和多维关联规则。根据 规则中项的出现顺序,可以分为无序关联规则和有序关联规则。根据规则的置信度和支持度,可以分为强关联规则和弱关联 规则。
关联规则挖掘的步骤
关联规则挖掘通常包括以下步骤:数据预处理、生成 频繁项集、生成关联规则。
关联规则简介与 Apriori算法课件
目录
• 关联规则简介 • Apriori算法简介 • Apriori算法的实现过程 • Apriori算法的优化策略 • 实例分析 • 总结与展望
01 关联规则简介
关联规则的定义
关联规则是数据挖掘中的一种重要技术,用于发现数据集中 项之间的有趣关系。
关联规则是一种在数据集中发现项之间有趣关系的方法。这 些关系通常以规则的形式表示,其中包含一个或多个项集, 这些项集在数据集中同时出现的频率超过了预先设定的阈值 。
分布式数据库关联规则的安全挖掘算法研究

a d ess e ue ds b td miig ag rtm P d rse a sc r it ue nn lo h P DMA ( r a y P ee ig sr ue Miig Alo tms fra scain r ls i r i P v c rsr n Ditb td i v i nn g r h ) o so it e . i o u
维普资讯
C m ue n te r g a d A p i t n o p trE gn ei n p l ai s计 算 机 工 程 与 应用 n c o
2 0 ,3 6 074 ()
11 8
分布式数据库关联规则 的安全挖 掘算法研 究
Ap l a o s 2 0 4 6) 1 1 1 3 pi t n , 0 7,3( : 8 — 8 . ci
Ab t a t I s r ca t p e e v u e ’ p v c wi o t ico i g n ii u l r n a t n i d s i u e mi i gT i a e sr c : t c u il o r s r e s r s r a y i i t u d s l s i d vd a t s c i s n it b td h n a o r nn .hs p p r
1D p r n f C mp trS in e, ’ n Ja tn nv ri Xia 0 9, hn . e at me to o ue ce c Xia ioo g U iest y, ’n 71 4 C ia 0
2 S e z e a o n o il S c r y Bu e u, h n h n, a g o g 5 8 2 Ch n .h n h n L b r a d S ca e u t r a S e z e Gu n d n 1 0 9, i a i
【国家自然科学基金】_隐私保护数据挖掘_基金支持热词逐年推荐_【万方软件创新助手】_20140802
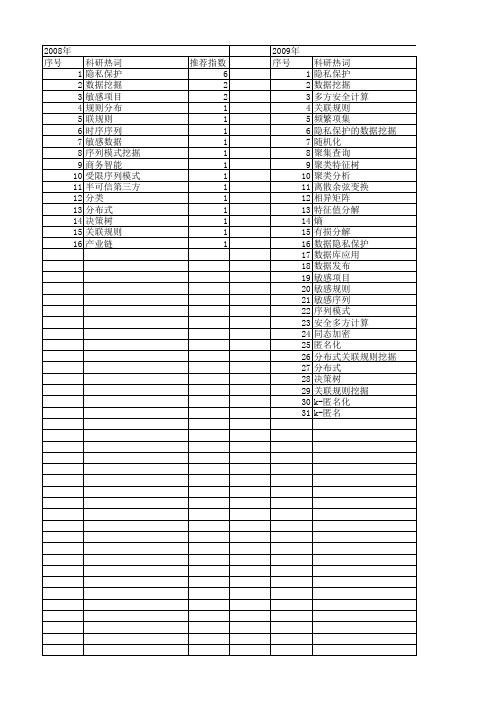
推荐指数 12 6 3 2 2 2 2 2 2 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
Hale Waihona Puke id3 apriori算法
1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40
2014年 科研热词 数据挖掘 隐私保护 差分隐私 频繁模式挖掘 预处理技术 语义距离 聚集查询 统计查询 机器学习 本体 数据发布 数据共享 指数机制 拓展 拉普拉斯机制 属性 安全多方计算 同态加密 可行性分析 分布式数据挖掘 关联规则 top-k模式 olap k-匿名 推荐指数 4 3 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46
科研热词 隐私保护 数据挖掘 聚类 聚类挖掘 数据干扰 数据失真 数据发布 支持向量机 多方安全计算 同态加密 隐私保护数据挖掘 隐私保护数据发布 随机算法 遗传算法 赌轮选择 聚类可用性 聚类分析 系统设计 系统安全 空时k-匿名 社交网络 物联网 海量数据 正交变换 最小选择度优先 旋转扰动 数据隐藏 数据扰动 数据分析 报警关联 序列模式 差分隐私 局部旋转扰动 对数螺线 安全多方计算 多步攻击 多敏感属性 匿名 分布式数据 关联规则 入侵检测 信息服务系统 位置隐私保护 乘法扰动 个性化 l-多样性
基于关联规则的高考数据隐私保护

随着 社会 对高 考制 度改 革 的呼声 越 来越 强烈 ,以教 育部 为 首 的 国家各 级 教育 管 理 施 以期高 考各 项 政策更 加 合理 完 善.为 使 高考 制度 改 革 具有 更 加 科 学实 际 的依据 ,某 些招 生考 试管 理部 门将 实行 网络招 生 以来积 累 的海量 的 、 真 实 的历史 数据 提供 给 高校 或科 研 机构 进行 挖 掘 分析 ,为高考 制 度改革 科 学决 策提 供参 考.为 了保 护高考 数 据 中健 康 状况 、 高考 分数 、 考 生志 愿 、录取 院校 等考 生个 人不 愿公 开 的 隐私数 据 , 招 考管 理部 门在 提供 数 据 前 ,一般 会 隐 匿 考生 姓 名 、考 生 号 、身份 证 号 等 考 生标识 符 信息 .然 而 ,即使 隐藏 了标识 符 信 息 ,也 存 在 着考 生 隐私 泄露 的危 险 , 攻 击 者 通 过其 它 渠 道 获 得相 关 数据 , 将 其 与非 显式标 识 符进 行 比对链 接 , 逆 推信 息所 有者 的主 体信 息 ,获取 主体 对应 的 隐私 信 息, 从 而 造成 不好 的社 会影 响口 ] .目前 , 针 对 忽 视考 生 隐 私 保 护而 引 发 的社 会 问题 的讨 论 已不 在少 数 ,崔 红伟建 议 通过 完善 并运 用档 案法 律法 规来 保 护考 生档 案信 息 中的 隐私权 [ 2 ; 许 莲 丽就 某 省将 高 考“ 加 分 门” 事 件 中涉 案考 生名 单进 行公 开一 事进 行讨 论 , 建 议 隐 匿或删 除 足 以识 别考 生 个人 身 份 的标 识信 息 _ 3 ;张 雪 梅 、丁玉 荣对 某 高 中学 生 魏罡状 告 学校 擅 自录像 、公开 播放 涉 及 其个 人 隐 私 的影 像 一事 进 行 讨论 ,提 出教 育 管理 无权 侵犯 考 生隐 私权 ;赵彬 焰提 出应 尊重 学 生考 试 分数 的隐私 权 l _ 5 ] .如 果在 招生 考 试 管理 部 门提
分布式环境下关联规则的安全挖掘算法
以进行关联规 则的安仓挖掘 。分析表 明,该 算法是正确 町行 的
关健词 :数据挖掘 ;分布式数据库 ;安全;隐私
Pr v c e e v n sr b t d M i i gAl o ih i a y Pr s r i g Dit i u e n n g r t m o s o i to U e f s ca i n Ru s As Uo l
1 . 2可交换 的加密 算法 可 交换 的 加密 算 法 是 用 于许 多隐 私 保 护 协议 的重要
工具。
定义 一个密码算法足可交换 和任意 的 i 的置换 , . K ∈ , [ I ,J
1问题描述
1 . 1相关概念和结论 挖掘 关联规则就是在给定的交易集合 中产生所有满 足最 小支持度 闽值 mnu 和最 小置 信度 m no f i p s i n 的强J则。 c ; ! 关联 I l 规 则的挖掘足一个两步的过程 :() 1找出所有满足 m nu isp的
一种基于SMC和RD的隐私保护挖掘算法
.
长 沙 理 工 大 学 学 报 (自 然 科 学 版 )
Vo . . 1 9 NO 3
Se 201 p. 2
J u n l f a gh iest fS in ea dTeh oo y Nau a ce c ) o r a n sa Unv riyo ce c n c n lg ( tr l in e o Ch S
2 1 定 义 项 集 随 机 干 扰 矩 阵 .
情况下 , 算法 的效 率 明显 变 得低 下 . 而在 随 机 干扰 方法方 面 , 现存 的算法 多 是依 次 对单 属 性 干扰 , 破
坏 了属 性 的相关 性 , 而影 响 了挖 掘 的精确 度. 从 作 者 提 出了基 于关 联 规则 的 P AR P MS P i R( r —
…
m
1
m矩 l 列 阵
。 …
o MC a dR 算法 , nS n D) 该算 法 充分 利 用 随机 干 扰
。一
;.阵 素 示 I 元 n表 项 矩 J
方法 的高效 率 和安 全 多 方计 算 方法 的 高精 确 度 ,
相对 于其他 算法 , 其综 合性 能较 强.
Ab ta t n ve o h h rc m ig ft ec re tmi ig ag rt m o h rv c r — sr c :I iw ft es o t o n so h u r n n n l o ih f rt e p ia y p e
s r i g a s ca i n r l e v n s o ito u e,s c s o y t ki g i t c ou hea go ihm fii n y whi g— u h a l a n n o a c ntt l rt e fce c l ne e
【计算机科学】_关联规则挖掘_期刊发文热词逐年推荐_20140723
科研热词 关联规则 数据挖掘 隐私保护 频繁项集 频繁闭项集格 频繁闭项集 随机化回答 量化关联规则 遥感图像 通用数据流挖掘成员 语义信息损失 语义web使用挖掘 自适应遗传算法 网络差错管理 概化 时态约束 日志本体 数据流挖掘 数据安全级 排序 归纳逻辑编程 异构系统 就业竞争力 小生境 多维关联规则 基因表达式编程 图像挖掘 压缩关联矩阵 分类 分布式关联规则挖掘 关联规则发现 免疫算法 仿真 令牌群 令牌 人工免疫 web日志 mpsqar算法 brt算法
2012年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23
科研热词 数据挖掘 关联规则 频繁模式增长算法 遗传算法 网络安全 线性链表 约束关联挖掘 知识发现 模糊关联规则 概率 极大团 时序逻辑 数据仓库 性能优化 并行数据挖掘 安全态势生成 安全态势建模 分布式协调系统 决策树 关键时间段(kti) 关联规则挖掘 olap apriori算法
推荐指数 6 3 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
2013年 序号 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29
科研热词 数据挖掘 关联规则 频繁事务集 预测决策 项集依赖 粒子群优化 神经网络 海量冗余 浮动 模糊贴近 模糊规则 有效时间 最小关联规则 时态 时序挖掘 文本 支持度 小波变换 多变异算子 垂直数据 同态区间 变异算子 单支重构 动态关联规则 加权关联规则 冗余规则 兴趣度约束 元规则 gm(1,1)
推荐指数 6 4 2 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
基于LBS(位置服务)的隐私保护算法研究
基于LBS(位置服务)的隐私保护算法研究黄小英【摘要】随着数据挖掘和数据发布等数据库应用的出现与发展,如何保护隐私数据和防止敏感信息泄露成为当前面临的重大挑战.隐私保护技术需要在保护数据隐私的同时不影响数据应用.根据采用技术的不同,出现了数据失真、数据加密、限制发布等隐私保护技术.【期刊名称】《制造业自动化》【年(卷),期】2011(033)009【总页数】3页(P96-98)【关键词】隐私保护;随机化;安全计算【作者】黄小英【作者单位】广西工商职业技术学院,南宁,530003【正文语种】中文【中图分类】TP312数据挖掘和数据发布是当前数据库应用的两个重要方面。
一方面,数据挖掘与知识发现在各个领域都扮演着非常重要的角色。
数据挖掘的目的在于从大量的数据中抽取出潜在的、有价值的知识(模型或规则)。
传统的数据挖掘技术在发现知识的同时,也给数据的隐私带来了威胁。
另一方面,数据发布是将数据库中的数据直接地展现给用户。
而在各种数据发布应用中,如果数据发布者不采取适当的数据保护措施,将可能造成敏感数据的泄漏,从而给数据所有者带来危害。
所以,如何在各种数据库应用中保护数据的隐私,成为近年来学术界的研究热点。
没有任何一种隐私保护技术适用于所有应用。
隐私保护技术分为三类:1)基于数据失真(Distorting)的技术:使敏感数据失真但同时保持某些数据或数据属性不变的方法。
例如,采用添加噪声(Adding Noise)、交换(Swapping)等技术对原始数据进行扰动处理,但要求保证处理后的数据仍然可以保持某些统计方面的性质,以便进行数据挖掘等操作。
2)基于数据加密的技术:采用加密技术在数据挖掘过程中隐藏敏感数据的方法。
多用于分布式应用环境中,如安全多方计算(Secure Multiparty Computation,以下简称SMC)。
3)基于限制发布的技术:根据具体情况有条件地发布数据。
如:不发布数据的某些域值,数据泛化(Generalization)等。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于影响度的隐私保护关联规则挖掘算法 徐龙琴1,刘双印1,2 (1. 广东海洋大学信息学院,广东 湛江 524025;2. 中国农业大学信息与电气工程学院,北京 100083) 摘 要:将T检验思想引入隐私保护数据挖掘算法,提出基于影响度的隐私保护关联规则挖掘算法。将影响度作为关联规则生成准则,以减少冗余规则和不相关规则,提高挖掘效率;通过调整事务间敏感关联规则的项目,实现敏感规则隐藏。实验结果表明,该算法能使规则损失率和增加率降低到6%以下。 关键词关键词::隐私保护;关联规则;影响度;数据挖掘;敏感规则
Privacy Preserving Association Rule Mining Algorithm Based on Influence Measure
XU Long-qin1, LIU Shuang-yin1,2 (1. College of Information, Guangdong Ocean University, Zhanjiang 524025, China; 2. College of Information and Electrical Engineering, China Agricultural University, Beijing 100083, China)
【Abstract】This paper introduces the idea of T-testing into privacy preserving data mining algorithms, proposes privacy preserving association rule mining algorithm based on influence measure. Considering influence measure as association rules generated as a criterion is to reduce the redundant rules and irrelevant rules so as to improve the efficiency of mining. Sensitive rules can be hided by adjusting the transaction association rules between the sensitive rule hiding sensitive items to achieve. Experimental results shows that, the algorithm makes the rules for side effects such as loss rate and the rate of decrease to as low as 6%. 【Key words】privacy preserving; association rule; influence measure; data mining; sensitive rule
DOI: 10.3969/j.issn.1000-3428.2011.11.020
计 算 机 工 程 Computer Engineering 第37卷 第11期
Vol.37 No.11 2011年6月
June 2011
·软件技术与数据库软件技术与数据库·· 文章编号文章编号::1000—3428(2011)11—0059—03 文献标识码文献标识码::A 中图分类号中图分类号::TP182
1 概述 随着网络技术、计算机存储技术的快速发展,浩瀚的数据收集存储变得更加便捷,出现了数据爆炸而知识匮乏的被动局面。关联规则数据挖掘可以从海量数据中抽取、分析并挖掘出隐藏的、用户感兴趣的规则、规律和模式,能有效解决上述困境,并在辅助决策预测、异常模式检测、欺诈行为发现、科学探索及医学研究等诸领域发挥积极作用,但同时也给隐私数据和信息安全带来严重的威胁。 例如,通过挖掘医院患者病历数据可发现不同疾病间潜藏的关联,制定更有针对性的治疗方案,但也造成患者隐私不同程度的泄露,使患者经常遭受婴儿用品厂商、婚姻中介商、医药保健公司等外界的“骚扰”。此外超市消费记录、网站购物偏好、个人或公司的信贷记录等信息中的关联关系也容易使个人或公司的隐私遭到侵害。 为此,隐私保护关联规则数据挖掘成为当前研究的热点,有关专家学者相继提出了许多解决的方法和对策[1-6],但这些方法都以Apriori算法和支持度-置信度框架生成关联规则,没考虑规则项目间相关度,产生了许多冗余、不相关的规则,不仅影响挖掘效率,还严重影响非敏感规则的支持度。 针对上述不足,本文提出一种新的隐私保护关联规则挖掘算法,可减少冗余规则的产生,提高挖掘效率和敏感规则隐私保护的综合性能。
2 研究研究背景背景 针对关联规则数据挖掘引起隐私泄漏问题,文献[1]提出了敏感规则、数据清理等概念,在尽可能不影响其他规则重
要性前提下,降低给定规则重要性,实现关联规则挖掘隐私保护。文献[2]使用“未知”值替换敏感数据,方法实现简单,但仅适用于少量项目值的挖掘。文献[3]使用删除项目方法,将含有许多后件的某项或多项删除,虽易实现,但当有许多规则存在时,作为后件的项目也常在其他规则中作为前件,如将该项目删除,易造成其他有效规则被误删除。文献[4]提出了SWA算法,通过删除包含敏感规则集部分项集方法,降低敏感规则支持度以隐藏敏感规则,该算法效率较高,适宜处理大规模的数据库。文献[5]将数据干扰和查询限制相结合,提出数据随机处理的隐私保护策略,有效实现了隐私保护的关联规则挖掘。文献[6]通过增减事务方法,降低敏感规则的支持度,实现敏感规则隐藏,但删除强相关事务,存在原数据库基本特征被修改,非敏感项目丢失等问题。文献[7]采用添加和删除项目相结合的方法,实现敏感知识隐藏,并通过选择最佳移动项候选事务减少非敏感事务的丢失率。 以上算法都是以传统的数据挖掘Apriori算法和支持度-置信度框架为基础,生成关联规则,所挖掘到的强关联规则中并不都是用户感兴趣的敏感规则,造成规则中存在大量冗
基金项目基金项目::国家星火计划基金资助项目(2007EA780068);广东省 自然科学基金资助项目(7010116);广东省科技计划基金资助项目(2010B020315025);湛江市科技计划基金资助项目(2010C3113011) 作者简介作者简介::徐龙琴(1977-),女,讲师、硕士、CCF会员,主研方向:数据库安全,智能信息系统,人工智能;刘双印,副教授、 博士研究生、CCF会员 收稿日期收稿日期::2011-01-29 E-mail:xlqlw@126.com 60 计 算 机 工 程 2011年6月5日 余不相关的规则,影响用户对规则的选择和挖掘效率,表1所示的实例说明了利用该框架生成规则时存在的不足。因篇幅所限,本文只列举部分数据和讨论若干长度为2的项目集,并假定支持度minSupp=0.25,置信度minConf=0.45。 表1 网上交易网上交易事务数据库事务数据库 事务号 项目集(Items) t1 A, B, C, D, J, Q t2 B, H, K, M, D, U … … t10 A, B, H, J, K, U 由表1计算可知:A⇒J和C⇒B的支持度和置信度都分别为0.4和1,大于设定的阈值,按以往惯例则认为都是有效的关联规则。但发现不管C是否出现,B总出现,显然C⇒B不是有效的关联规则。另外,U⇒M的支持度和置信度分别为0.3和0.6,大于设定的阈值,通常认为也应该为有效的规则,但计算得到P(U∪M)=P(U)P(M),从数理统计角度讲它们是不相关的。此外对表1采用数据变换法、数据阻塞法降低支持度,实现规则隐藏,但对非敏感规则支持度影响很大,存在规则丢失和虚假规则增生等缺陷。 为减少对非敏感规则的影响,提高挖掘效率,本文提出了一种基于影响度的隐私保护关联规则挖掘方法,把影响度作为关联规则生成的衡量准则,可大大减少不相关规则和冗余规则,加快挖掘速度;同时引入最佳候选移动项,在保证非敏感项影响最小前提下更新事务集,降低敏感规则的支持度和置信度,实现敏感规则隐藏。 3 基于影响度的隐私保护关联规则挖掘算法 鉴于传统挖掘算法存在挖掘效率低等不足,本文将数理统计中检验样本差异显著性的重要统计工具T检验的思想引入到隐私保护关联规则挖掘中,采用T检验来分析规则X⇒Y的Confidence(X⇒Y)与期望置信度P(Y)之间的差异,作为关联规则生成衡量准则。即根据关联规则影响度大小,在生成关联规则的过程中将差异不显著的规则直接过滤掉,可有效减少冗余的和不相关的规则的产生,提高关联规则的挖掘 效率。 3.1 相关概念 3.1.1 关联规则挖掘 假定项目集为I={i1, i2,…, im},事务数据库DB={t1, t2,…, tn},其中,ti为一个事务,∀ti⊆I,即每个事务ti所包含的项集都是I的子集。关联规则形式化表示为X⇒Y,其中,X⊆I,Y⊆I且X∩Y=∅[8]。关联规则的强度可用支持度Support和置信度Confidence度量。计算表达式如下: Support(X⇒Y)=|X∪Y|/|DB|≥minSupp (1) Confidence(X⇒Y)=|X∪Y|/|X|≥minConf (2) 其中,minConf为最小置信度;minSupp为最小支持度。为了隐藏挖掘出的敏感规则,由以上表达式可知,通过减少项目X和Y同时出现的频率,降低支持度Support和置信度Confidence,即可达到敏感规则隐藏的目的。 3.1.2 关联规则影响度 关联规则的影响度用来表征规则的前项和后项的相关程度,influence(X⇒Y)计算表达式定义如下: 定义1 ()()()()(1())ConfidenceXYPYinfluenceXYPYPYn⇒−⇒=− (3) 若influence (X⇒Y)>tα(n),即P(Y|X)与P(Y)之间的差异较大,则表明Y的出现受X的影响较大,规则X⇒Y是敏感的和需要保护的。tα(n)为样本容量为n的T分布显著水平为α
的下临界值,称为最小影响度。根据概率统计的需要及n值较大,tα(n)常用正态分布下显著水平为α=0.05下的临界值u
α
替代,即tα(n)≈u0.05=1.96。
基于T检验影响度的生成关联衡量准则将关联规则分为
4类: (1)不相关规则 如Confidence(X⇒Y)= P(Y),即P(X∪Y)= P(X)P(Y),则项集X和项集Y构成的X⇒Y为不相关规则,包含不相关规则的事务,称为不相关事务。 (2)冗余规则 若(Support(X⇒Y)≥minSupp)∧(P(Y)≥Confidence(X⇒Y)≥minConf)成立,则称X⇒Y为冗余规则,该冗余规则在挖掘的过程予以删除,以提高效率。 (3)弱关联规则:若(Support(X⇒Y)≥minSupp)∧(Confidence (X⇒Y)≥minConf)∧(0成立,则称X⇒Y为弱关联规则,包含弱关联规则X⇒Y的事务,称为弱相关事务。 (4)强关联规则 若(Support(X⇒Y)≥minSupp)∧(P(Y)≥Confidence(X⇒Y)≥minConf)∧(influence(X⇒Y)>t0.05(n)≈u0.05= 1.96)成立,则称