hadoop-2.4.0安装配置
Hadoop环境搭建及wordcount实例运行
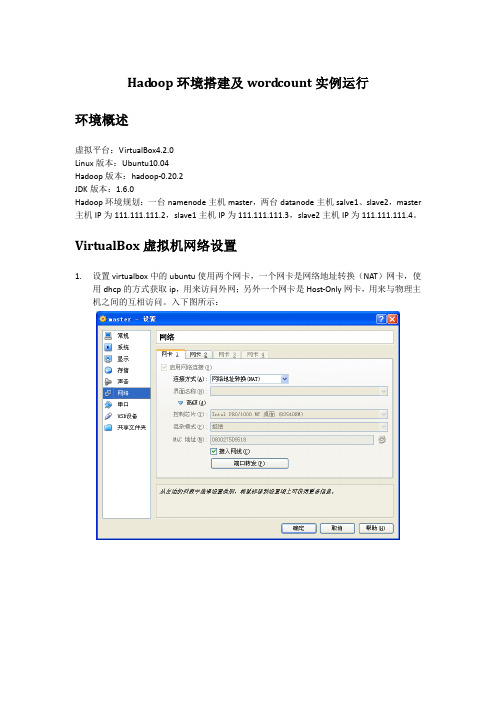
环境概述
虚拟平台:VirtualBox4.2.0
Linux版本:Ubuntu10.04
Hadoop版本:hadoop-0.20.2
JDK版本:1.6.0
Hadoop环境规划:一台namenode主机master,两台datanode主机salve1、slave2,master主机IP为111.111.111.2,slave1主机IP为111.111.111.3,slave2主机IP为111.111.111.4。
ssh_5.3p1-3ubuntu3_all.deb
依次安装即可
dpkg -i openssh-client_5.3p1-3ubuntu3_i386.deb
dpkg -i openssh-server_5.3p1-3ubuntu3_i386.deb
dpkg -i ssh_5.3p1-3ubuntu3_all.deb
14/02/20 15:59:58 INFO mapred.JobClient: Running job: job_201402201551_0003
14/02/20 15:59:59 INFO mapred.JobClient: map 0% reduce 0%
14/02/20 16:00:07 INFO mapred.JobClient: map 100% reduce 0%
111.111.111.2 master
111.111.111.3 slave1
111.111.111.4 slave2
然后按以下步骤配置master到slave1之间的ssh信任关系
用户@主机:/执行目录
操作命令
说明
hadoop@master:/home/hadoop
Hadoop安装部署手册

1.1软件环境1)CentOS6.5x642)Jdk1.7x643)Hadoop2.6.2x644)Hbase-0.98.95)Zookeeper-3.4.61.2集群环境集群中包括 3个节点:1个Master, 2个Slave2安装前的准备2.1下载JDK2.2下载Hadoop2.3下载Zookeeper2.4下载Hbase3开始安装3.1 CentOS安装配置1)安装3台CentOS6.5x64 (使用BasicServer模式,其他使用默认配置,安装过程略)2)Master.Hadoop 配置a)配置网络修改为:保存,退出(esc+:wq+enter ),使配置生效b) 配置主机名修改为:c)配置 hosts修改为:修改为:在最后增加如下内容以上调整,需要重启系统才能生效g) 配置用户新建hadoop用户和组,设置 hadoop用户密码id_rsa.pub ,默认存储在"/home/hadoop/.ssh" 目录下。
a) 把id_rsa.pub 追加到授权的 key 里面去b) 修改.ssh 目录的权限以及 authorized_keys 的权限c) 用root 用户登录服务器修改SSH 配置文件"/etc/ssh/sshd_config"的下列内容3) Slavel.Hadoop 、Slavel.Hadoop 配置及用户密码等等操作3.2无密码登陆配置1)配置Master 无密码登录所有 Slave a)使用 hadoop 用户登陆 Master.Hadoopb)把公钥复制所有的 Slave 机器上。
使用下面的命令格式进行复制公钥2) 配置Slave 无密码登录Mastera) 使用hadoop 用户登陆Slaveb)把公钥复制Master 机器上。
使用下面的命令格式进行复制公钥id_rsa 和相同的方式配置 Slavel 和Slave2的IP 地址,主机名和 hosts 文件,新建hadoop 用户和组c) 在Master机器上将公钥追加到authorized_keys 中3.3安装JDK所有的机器上都要安装 JDK ,先在Master服务器安装,然后其他服务器按照步骤重复进行即可。
在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04

在linux中安装Hadoop教程-伪分布式配置-Hadoop2.6.0-Ubuntu14.04注:该教程转⾃厦门⼤学⼤数据课程学习总结装好了 Ubuntu 系统之后,在安装 Hadoop 前还需要做⼀些必备⼯作。
创建hadoop⽤户如果你安装 Ubuntu 的时候不是⽤的 “hadoop” ⽤户,那么需要增加⼀个名为 hadoop 的⽤户。
⾸先按 ctrl+alt+t 打开终端窗⼝,输⼊如下命令创建新⽤户 : sudo useradd -m hadoop -s /bin/bash这条命令创建了可以登陆的 hadoop ⽤户,并使⽤ /bin/bash 作为 shell。
sudo命令 本⽂中会⼤量使⽤到sudo命令。
sudo是ubuntu中⼀种权限管理机制,管理员可以授权给⼀些普通⽤户去执⾏⼀些需要root权限执⾏的操作。
当使⽤sudo命令时,就需要输⼊您当前⽤户的密码.密码 在Linux的终端中输⼊密码,终端是不会显⽰任何你当前输⼊的密码,也不会提⽰你已经输⼊了多少字符密码。
⽽在windows系统中,输⼊密码⼀般都会以“*”表⽰你输⼊的密码字符 接着使⽤如下命令设置密码,可简单设置为 hadoop,按提⽰输⼊两次密码: sudo passwd hadoop可为 hadoop ⽤户增加管理员权限,⽅便部署,避免⼀些对新⼿来说⽐较棘⼿的权限问题: sudo adduser hadoop sudo最后注销当前⽤户(点击屏幕右上⾓的齿轮,选择注销),返回登陆界⾯。
在登陆界⾯中选择刚创建的 hadoop ⽤户进⾏登陆。
更新apt⽤ hadoop ⽤户登录后,我们先更新⼀下 apt,后续我们使⽤ apt 安装软件,如果没更新可能有⼀些软件安装不了。
按 ctrl+alt+t 打开终端窗⼝,执⾏如下命令: sudo apt-get update后续需要更改⼀些配置⽂件,我⽐较喜欢⽤的是 vim(vi增强版,基本⽤法相同) sudo apt-get install vim安装SSH、配置SSH⽆密码登陆集群、单节点模式都需要⽤到 SSH 登陆(类似于远程登陆,你可以登录某台 Linux 主机,并且在上⾯运⾏命令),Ubuntu 默认已安装了SSH client,此外还需要安装 SSH server: sudo apt-get install openssh-server安装后,配置SSH⽆密码登陆利⽤ ssh-keygen ⽣成密钥,并将密钥加⼊到授权中: exit # 退出刚才的 ssh localhost cd ~/.ssh/ # 若没有该⽬录,请先执⾏⼀次ssh localhost ssh-keygen -t rsa # 会有提⽰,都按回车就可以 cat ./id_rsa.pub >> ./authorized_keys # 加⼊授权此时再⽤ssh localhost命令,⽆需输⼊密码就可以直接登陆了。
Hadoop 搭建

(与程序设计有关)
课程名称:云计算技术提高
实验题目:Hadoop搭建
Xx xx:0000000000
x x:xx
x x:
xxxx
2021年5月21日
实验目的及要求:
开源分布式计算架构Hadoop的搭建
软硬件环境:
Vmware一台计算机
算法或原理分析(实验内容):
Hadoop是Apache基金会旗下一个开源的分布式存储和分析计算平台,使用Java语言开发,具有很好的跨平台性,可以运行在商用(廉价)硬件上,用户无需了解分布式底层细节,就可以开发分布式程序,充分使用集群的高速计算和存储。
三.Hadoop的安装
1.安装并配置环境变量
进入官网进行下载hadoop-2.7.5, 将压缩包在/usr目录下解压利用tar -zxvf Hadoop-2.7.5.tar.gz命令。同样进入 vi /etc/profile 文件,设置相应的HADOOP_HOME、PATH在hadoop相应的绝对路径。
4.建立ssh无密码访问
二.JDK安装
1.下载JDK
利用yum list java-1.8*查看镜像列表;并利用yum install java-1.8.0-openjdk* -y安装
2.配置环境变量
利用vi /etc/profile文件配置环境,设置相应的JAVA_HOME、JRE_HOME、PATH、CLASSPATH的绝对路径。退出后,使用source /etc/profile使环境变量生效。利用java -version可以测试安装是否成功。
3.关闭防火墙并设置时间同步
通过命令firewall-cmd–state查看防火墙运行状态;利用systemctl stop firewalld.service关闭防火墙;最后使用systemctl disable firewalld.service禁止自启。利用yum install ntp下载相关组件,利用date命令测试
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册
Hadoop2.2.0+Hbase0.98.1+Sqoop1.4.4+Hive0.13完全安装手册前言: (3)一. Hadoop安装(伪分布式) (4)1. 操作系统 (4)2. 安装JDK (4)1> 下载并解压JDK (4)2> 配置环境变量 (4)3> 检测JDK环境 (5)3. 安装SSH (5)1> 检验ssh是否已经安装 (5)2> 安装ssh (5)3> 配置ssh免密码登录 (5)4. 安装Hadoop (6)1> 下载并解压 (6)2> 配置环境变量 (6)3> 配置Hadoop (6)4> 启动并验证 (8)前言:网络上充斥着大量Hadoop1的教程,版本老旧,Hadoop2的中文资料相对较少,本教程的宗旨在于从Hadoop2出发,结合作者在实际工作中的经验,提供一套最新版本的Hadoop2相关教程。
为什么是Hadoop2.2.0,而不是Hadoop2.4.0本文写作时,Hadoop的最新版本已经是2.4.0,但是最新版本的Hbase0.98.1仅支持到Hadoop2.2.0,且Hadoop2.2.0已经相对稳定,所以我们依然采用2.2.0版本。
一. Hadoop安装(伪分布式)1. 操作系统Hadoop一定要运行在Linux系统环境下,网上有windows下模拟linux环境部署的教程,放弃这个吧,莫名其妙的问题多如牛毛。
2. 安装JDK1> 下载并解压JDK我的目录为:/home/apple/jdk1.82> 配置环境变量打开/etc/profile,添加以下内容:export JAVA_HOME=/home/apple/jdk1.8export PATH=$PATH:$JAVA_HOME/binexport CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jar执行source /etc/profile ,使更改后的profile生效。
Hadoop集群配置心得(低配置集群+自动同步配置)

Hadoop集群配置⼼得(低配置集群+⾃动同步配置)本⽂为本⼈原创,⾸发到炼数成⾦。
情况是这样的,我没有⼀个⾮常强劲的电脑来搞出⼀个性能⾮常NB的服务器集群,相信很多⼈也跟我差不多,所以现在把我的低配置集群经验拿出来写⼀下好了。
我的配备:1)五六年前的赛扬单核处理器2G内存笔记本 2)公司给配的ThinkpadT420,i5双核处理器4G内存(可⽤内存只有3.4G,是因为装的是32位系统的缘故吧。
)就算是⽤公司配置的电脑,做出来三台1G内存的虚拟机也显然是不现实的。
企业笔记本运⾏的软件多啊,什么都不做空余内存也才不到3G。
所以呢,我的想法就是:⽤我⾃⼰的笔记本(简称PC1)做Master节点,⽤来跑Jobtracker,Namenode 和SecondaryNamenode;⽤公司的笔记本跑两个虚拟机(简称VM1和VM2),⽤来做Slave节点,跑Tasktracker和Datanode。
这么做的话,就需要让PC1,VM1和VM2处于同⼀个⽹段⾥,保证他们之间可以互相连通。
⽹络环境:我的两台电脑都是通过⼀个⽆线路由上⽹。
构建跟外部的电脑同⼀⽹段的虚拟机配置过程:准备⼯作:构建⼀个集群,⾸先前提条件是每台服务器都要有⼀个固定的IP地址,然后才可能进⾏后续的操作。
所以呢,先把我的两台笔记本电脑全部设置成固定IP(注意,如果像我⼀样使⽤⽆线路由上⽹,那就要把⽆线⽹卡的IP设置成固定IP)。
⽤来做Master节点的PC1:192.168.33.150,⽤来跑虚拟机的宿主笔记本:192.168.33.157。
⽬标:VM1和VM2的IP地址分别设置成192.168.33.151和152。
步骤:1)新建VM1虚拟机。
2)打开VM1的⽹卡设置界⾯,连接⽅式选Bridge。
(桥接)关于桥接的具体信息,可以百度⼀下。
我们需要知道的,就是⽤桥接的⽅式,可以让虚拟机通过本机的⽹关来上⽹,所以就可以跟本机处于同⼀个⽹段,互相之间可以进⾏通信。
Linux系统下Hadoop运行环境搭建
Linux系统下Hadoop运⾏环境搭建1.安装ssh免密登录命令:ssh-keygenoverwrite(覆盖写⼊)输⼊y⼀路回车将⽣成的密钥发送到本机地址ssh-copy-id localhost(若报错命令⽆法找到则需要安装openssh-clients)yum –y install openssh-clients测试免密设置是否成功ssh localhost2.卸载已有java确定JDK版本rpm –qa | grep jdkrpm –qa | grep gcj切换到root⽤户,根据结果卸载javayum -y remove java-1.8.0-openjdk-headless.x86_64 yum -y remove java-1.7.0-openjdk-headless.x86_64卸载后输⼊java –version查看3.安装java切换回hadoop⽤户,命令:su hadoop查看下当前⽬标⽂件,命令:ls新建⼀个app⽂件夹,命令:mkdir app将桌⾯的hadoop⽂件夹中的java及hadoop安装包移动到app⽂件夹中命令:mv /home/hadoop/Desktop/hadoop/jdk-8u141-linux-x64.gz /home/hadoop/app mv /home/hadoop/Desktop/hadoop/hadoop-2.7.0.tar.gz /home/hadoop/app解压java程序包,命令:tar –zxvf jdk-7u79-linux-x64.tar.gz创建软连接ln –s jdk1.8.0_141 jdk配置jdk环境变量切换到root⽤户再输⼊vi /etc/profile输⼊export JAVA_HOME=/home/hadoop/app/jdk1.8.0_141export JAVA_JRE=JAVA_HOME/jreexport CLASSPATH=.:$JAVA_HOME/lib:$JAVA_JRE/libexport PATH=$PATH:$JAVA_HOME/bin保存退出,并使/etc/profile⽂件⽣效source /etc/profile能查询jdk版本号,说明jdk安装成功java -version4.安装hadoop切换回hadoop⽤户,解压缩hadoop-2.6.0.tar.gz安装包创建软连接,命令:ln -s hadoop-2.7.0 hadoop验证单机模式的Hadoop是否安装成功,命令:hadoop/bin/hadoop version此时可以查看到Hadoop安装版本为Hadoop2.7.0,说明单机版安装成功。
Win10系统安装Hadoop与Hbase
目录1. 前言 (2)2. 准备工作 (2)2.1. 下载Hadoop (2)2.2. 下载hadoop-common (3)2.3. 下载Hbase (3)2.4. 下载JDK (4)3. 环境配置 (4)3.1. 将下载好的3个压缩包分别解压缩 (4)3.2. 覆盖文件 (6)3.3. 安装JDK (7)3.3.1. 配置JAVA环境变量 (8)3.3.2. 测试JDK安装是否成功 (11)4. 配置Hadoop (11)4.1. hadoop-env.cmd (12)4.2. core-site.xml (13)4.3. hdfs-site.xml (14)4.4. 创建mapred-site.xml (15)4.5. yarn-site.xml (18)5. 启动Hadoop (20)5.1. 以管理员身份运行CMD命令提示符 (20)5.2. 切换到hadoop目录 (21)5.3. 运行hadoop-env.cmd脚本 (21)5.4. 格式化HDFS文件系统 (21)5.5. 启动HDFS (22)5.6. 遇到异常 (23)5.6.1. 解决方案 (23)5.7. 停止Hadoop (25)6. 配置Hbase (26)6.1. 编辑hbase-site.xml (26)6.2. 编辑hbase-env.cmd (27)7. 启动Hbase (28)8. Hbase Shell (31)8.1. 用shell连接HBase (31)8.2. 使用shell (31)8.2.1. 创建表 (31)8.2.2. Scan表 (32)8.2.3. Get一行 (33)8.2.4. 删除表 (33)8.2.5. 关闭shell (34)8.2.6. 停止Hbase (34)9. Java API Hbase (35)1.前言工作需要,现在开始做大数据开发了,通过下面的配置步骤,你可以在win10系统中,部署出一套hadoop+hbase,便于单机测试调试开发。
sparkonyarn安装配置手册
一.ssh无密码登陆1.安装sshyum install openssh-server2.产生keyssh-keygen -t rsa -P ""Enter file in which to save the key (/root/.ssh/id_rsa):(按回车)3.使用keycat /root/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys二.安装配置JDK1.解压tar -zxvf jdk-7u71-linux-x64.tar.gz2.打开全局变量配置文件vim /etc/profile3.在该文件末尾增加如下语句4.使配置生效source /etc/profile5.确认JDK安装成功三.安装配置hadoop1.解压tar -zxvf hadoop-2.2.0.tar.gz2.配置hadoop-env.shcd /opt/hadoop-2.2.0/etc/hadoopvim hadoop-env.sh增加如下配置:3.在/etc/profile里增加如下配置:尤其最后两行,否则会导致启动错误。
4.配置core-site.xmlcd /opt/hadoop-2.2.0/etc/hadoopvim core-site.xml增加如下配置还需增加如下配置,否则找不到库<property><name>hadoop.native.lib</name><value>true</value></property>5.配置hdfs-site.xmlcd /opt/hadoop-2.2.0/etc/hadoopvim hdfs-site.xml增加如下配置6.配置mapred-site.xmlcd /opt/hadoop-2.2.0/etc/hadoopcp mapred-site.xml.template mapred-site.xmlvim mapred-site.xml增加如下配置7.使配置生效source hadoop-env.sh8.启动hadoop总是报如下错误WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable原因是apache官网提供的二进制包,里面的native库,是32位的,而服务器是64位的。
hadoop2.2安装
Hadoop2.2.0安装配置手册!完全分布式Hadoop集群搭建过程历时一周多,终于搭建好最新版本Hadoop2.2集群,期间遇到各种问题,作为菜鸟真心被各种折磨,不过当wordcount给出结果的那一刻,兴奋的不得了~~(文当中若有错误之处或疑问欢迎指正,互相学习)另外:欢迎配置过程中遇到问题的朋友留言,相互讨论,并且能够把解决方法共享给大家。
下面评论中有几个朋友遇到的问题和解决方法,欢迎参考!第一部分Hadoop 2.2 下载Hadoop我们从Apache官方网站直接下载最新版本Hadoop2.2。
官方目前是提供了linux32位系统可执行文件,所以如果需要在64位系统上部署则需要单独下载src 源码自行编译(10楼评论中提供了一个解决方法链接)。
下载地址:/hadoop/common/hadoop-2.2.0/如下图所示,下载红色标记部分即可。
如果要自行编译则下载src.tar.gz.第二部分集群环境搭建1、这里我们搭建一个由三台机器组成的集群:192.168.0.1 hduser/passwd cloud001 nn/snn/rm CentOS6 64bit192.168.0.2 hduser/passwd cloud002 dn/nm Ubuntu13.04 32bit192.168.0.3 hduser/passwd cloud003 dn/nm Ubuntu13.0432bit1.1 上面各列分别为IP、user/passwd、hostname、在cluster中充当的角色(namenode, secondary namenode, datanode , resourcemanager, nodemanager)1.2 Hostname可以在/etc/hostname中修改(ubuntu是在这个路径下,RedHat稍有不同)1.3 这里我们为每台机器新建了一个账户hduser.这里需要给每个账户分配sudo的权限。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一.安装JDK(安装包: jdk-7u51-linux-i586)
1.转到下载路径,对下载后的文件解压缩,比如我的下载路径为/usr/lib/jvm
cd /usr/lib/jvm
sudo tar zxvf jdk-7u51-linux-i586
2.将解压出的文件拷贝到/usr/lib/jvm中,比如我解压出的文件夹为jdk1.7.0_51
sudo cp –r jdk1.7.0_51 /usr/lib/jvm
3.修改环境变量
gedit ~/.bashrc
在最下面添加下面几行
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_51
保存退出,输入:
source ~/.bashrc
4. 配置profile文件
sudo gedit /etc/profile
在文件末尾加入以下内容,保存
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_51
export JRE_HOME=$JAVA_HOME/jre
export CLASSPATH=$JRE_HOME/lib:$JAVA_HOME/lib:.
export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH
关闭后执行以下指令使环境变量生效
source /etc/profile
二.创建hadoop用户组
1.创建hadoop用户组
sudo addgroup hadoop
3 .为hadoop用户添加权限
sudo gedit /etc/sudoers
给hadoop用户赋予和root同样的权限
用hadoop用户登陆ubuntu系统
三.安装SSH
sudo apt-get install openssh-server
sudo /etc/init.d/ssh start
查看服务是否正确启动:ps –e | grep ssh
设置免密码登陆,生成私钥和公钥
ssh-keygen –t rsa –P “”
此时会在/home/hadoop/.ssh下生成两个文件:id_rsa和id_rsa.pub,前者为私钥,
后者为公钥。
下面我们将公钥追加到authorized_keys中,它用户保存所有允许以当前用户身份登录
到ssh客户端用户的公钥内容。
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
登录ssh
ssh localhost
退出
exit
四.安装hadoop(hadoop-2.4.0.tar.gz)
1.转到下载路径,对下载后的文件解压缩,比如我的下载路径为/usr/hadoop
cd /usr/hadoop
sudo tar zxvf hadoop-2.4.0.tar.gz
将解压出的文件拷贝到/usr/lib/jvm中,比如我解压出的文件夹为jdk1.7.0_51
sudo cp –r jdk1.7.0_51 /usr/lib/jvm
2.配置hadoop
1)配置.bashrc文件
sudo gedit ~/.bashrc
文件末尾加如下内容,保存,关闭
执行如下命令:
source ~/.bashrc
2)配置profile文件
sudo gedit /etc/profile
在文件末尾加入以下内容,保存
export HADOOP_PREFIX=/usr/hadoop/hadoop-2.4.0
关闭后执行以下指令使环境变量生效
source /etc/profile
3.以下配置文件在/usr/hadoop/hadoop-2.4.0/etc/hadoop中
1) 配置hadoop-env.sh
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_51
export HADOOP_COMMON_LIB_NATIVE_DIR=${HADOOP_PREFIX/lib}
export HADOOP_OPTS=”-Djava.library.path=$HADOOP_PREFIX/lib”
2)配置core-site.xml
3) 配置hdfs-site.xml
4) 配置mapred-site.xml(如果没有mapred-site.xml,复制mapred-site.xml.template
为mapred-site.xml)
5) 配置 yarn-site.xml
4. 格式化hdfs,初次运行hadoop必须要有该操作
cd /usr/hadoop/hadoop-2.4.0
bin/hadoop namenode –format
5.打开hadoop
sbin/start-all.sh
等待启动完毕。。。输入指令jps,出现以下五个进程说明hadoop配置完毕
SecondaryNameNode,DataNode,ResourceManager,NodeManager,NodeManager,Na
menode