SPSS多元回归分析实例
多元线性回归实例分析

SPSS--回归-多元线性回归模型案例解析!(一)多元线性回归,主要是研究一个因变量与多个自变量之间的相关关系,跟一元回归原理差不多,区别在于影响因素(自变量)更多些而已,例如:一元线性回归方程为:毫无疑问,多元线性回归方程应该为:组样本,“N截止,代表有P个自变量,如果有x2, xp上图中的x1, 分别代表“自变量”Xp 那么这个多元线性回归,将会组成一个矩阵,如下图所示:那么,多元线性回归方程矩阵形式为:不可解释的误和其中随机误差分为:可解释的误差其中:代表随机误差,差,随机误差必须满足以下四个条件,多元线性方程才有意义(一元线性方程也一样):服成正太分布,即指:随机误差1必须是服成正太分别的随机变量。
02:无偏性假设,即指:期望值为3:同共方差性假设,即指,所有的随机误差变量方差都相等4:独立性假设,即指:所有的随机误差变量都相互独立,可以用协方差解释。
多元线性回归的具体操作过程,下面以教程教程数据今天跟大家一起讨论一下,SPSS---为例,分析汽车特征与汽车销售量之间的关系。
通过分析汽车特征跟汽车销售量的关系,建立拟合多元线性回归模型。
数据如下图所示:————”——“点击分析回归线性进入如下图所示的界面:个自变10车长,车宽,耗油率,车净重等将“作为“销售量”“因变量”拖入因变量框内,将,当然,你也可以选择其它”“逐步”量拖入自变量框内,如上图所示,在“方法旁边,选择默认的方式,在分析结果中,将会得到如下图所示的结果:进入“”的方式,如果你选择(所有的自变量,都会强行进入)统计”这个方法,将会得到如下图所示的结果:(将会根据预先设定的“F逐步如果你选择“关系最为密切,贡””自变量应该是跟“因变量“量的概率值进行筛选,最先进入回归方程的跟因变量关系最为密切,符合判断条件的概献最大的,如下图可以看出,车的价格和车轴时将会被剔除)0.1,当概率值大于等于0.05率值必须小于进行条件筛选,可以自变量”选择变量(E) 框内,我并没有输入数据,如果你需要对某个““内,有一个前提就是:该变量从未在另一个目标列表中”将那个自变量,移入“选择变量框即可,如下图所示:””规则设定相应的“筛选条件“出现!,再点击弹出如下所示的框,如下所示:”统计量“点击两个选项,再勾“”共线性诊断”“估计,在右侧勾选模型拟合度“和在“回归系数”下面勾选3“3”,(设定异常值的依据,只有当残差超过一般默认值为再点击“离群值”选“个案诊断”点击继续。
多因素logistic回归分析spss

多因素logistic回归分析spssLogistic回归分析是一种用来研究影响离散变量的因素的方法,该方法的输出是一个logistic模型,这一模型可以用于预测变量的值,即预测该变量的值有多高的概率会取各种可能的取值。
简言之,logistic回归分析的主要目的是把客观的结果(例如,是否改变某个政策,是否感染某种疾病等)变成可预测的离散变量,以便分析影响客观结果的各种因素。
Spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量(例如,是否改变某个政策,是否感染某种疾病等)的多个因素之间的关联。
该分析需要有一个组合变量作为自变量,以及一个离散变量作为因变量。
例如,如果您要研究性别和年龄两个因素如何影响某种疾病的发生率,那么性别和年龄两个因素就是组合变量,而疾病的发生率则是因变量。
1.建立变量和分类(上述示例中需要建立性别和年龄两个变量,以及分类变量的可能的取值)。
2.执行logistic回归分析。
打开spss,并在“分析”菜单中打开多元分析,然后点击“逻辑回归”,并选择您要研究的变量和分类。
3.生成回归模型和检验其统计学意义。
在spss中,您可以使用类似“回归系数”之类的描述性统计学方法来估算回归模型,并可以使用“p-值”来判断回归模型中各变量的统计学意义。
4.Interpret模型。
根据p值判断各变量的统计学意义,进而分析影响离散变量的多个因素之间的关联。
四、总结Logistic回归分析是一种用来研究影响离散变量的因素的方法,spss可以提供多因素logistic回归分析,这种分析可用于识别影响离散变量的多个因素之间的关联,spss中步骤:建立变量和分类,执行logistic回归分析,生成回归模型和检验其统计学意义,Interpret模型。
SPSS多元线性回归分析教程

线性回归分析的SPSS操作本节内容主要介绍如何确定并建立线性回归方程。
包括只有一个自变量的一元线性回归和和含有多个自变量的多元线性回归。
为了确保所建立的回归方程符合线性标准,在进行回归分析之前,我们往往需要对因变量与自变量进行线性检验。
也就是类似于相关分析一章中讲过的借助于散点图对变量间的关系进行粗略的线性检验,这里不再重复。
另外,通过散点图还可以发现数据中的奇异值,对散点图中表示的可能的奇异值需要认真检查这一数据的合理性。
一、一元线性回归分析1.数据以本章第三节例3的数据为例,简单介绍利用SPSS如何进行一元线性回归分析。
数据编辑窗口显示数据输入格式如下图7-8(文件7-6-1.sav):图7-8:回归分析数据输入2.用SPSS进行回归分析,实例操作如下:2.1.回归方程的建立与检验(1)操作①单击主菜单Analyze / Regression / Linear…,进入设置对话框如图7-9所示。
从左边变量表列中把因变量y选入到因变量(Dependent)框中,把自变量x选入到自变量(Independent)框中。
在方法即Method一项上请注意保持系统默认的选项Enter,选择该项表示要求系统在建立回归方程时把所选中的全部自变量都保留在方程中。
所以该方法可命名为强制进入法(在多元回归分析中再具体介绍这一选项的应用)。
具体如下图所示:图7-9 线性回归分析主对话框②请单击Statistics…按钮,可以选择需要输出的一些统计量。
如Regression Coefficients(回归系数)中的Estimates,可以输出回归系数及相关统计量,包括回归系数B、标准误、标准化回归系数BETA、T值及显著性水平等。
Model fit项可输出相关系数R,测定系数R2,调整系数、估计标准误及方差分析表。
上述两项为默认选项,请注意保持选中。
设置如图7-10所示。
设置完成后点击Continue返回主对话框。
图7-10:线性回归分析的Statistics选项图7-11:线性回归分析的Options选项回归方程建立后,除了需要对方程的显著性进行检验外,还需要检验所建立的方程是否违反回归分析的假定,为此需进行多项残差分析。
spss回归分析

第八章回归分析回归分析是处理两个及两个以上变量间线性依存关系的统计方法。
在医学领域中,此类问题很普遍,如人头发中某种金属元素的含量与血液中该元素的含量有关系,人的体表面积与身高、体重有关系;等等。
回归分析就是用于说明这种依存变化的数学关系。
第一节Linear过程8.1.1 主要功能调用此过程可完成二元或多元的线性回归分析。
在多元线性回归分析中,用户还可根据需要,选用不同筛选自变量的方法(如:逐步法、向前法、向后法,等)。
8.1.2 实例操作[例8.1]某医师测得10名3岁儿童的身高(cm)、体重(kg)和体表面积(cm2)资料如下。
试用多元回归方法确定以身高、体重为自变量,体表面积为应变量的回归方程。
8.1.2.1 数据准备激活数据管理窗口,定义变量名:体表面积为Y,保留3位小数;身高、体重分别为X1、X2,1位小数。
输入原始数据,结果如图8.1所示。
图8.1 原始数据的输入8.1.2.2 统计分析激活Statistics菜单选Regression中的Linear...项,弹出Linear Regression对话框(如图8.2示)。
从对话框左侧的变量列表中选y,点击 钮使之进入Dependent框,选x1、x2,点击 钮使之进入Indepentdent(s)框;在Method处下拉菜单,共有5个选项:Enter(全部入选法)、Stepwise(逐步法)、Remove(强制剔除法)、Backward(向后法)、Forward(向前法)。
本例选用Enter法。
点击OK钮即完成分析。
图8.2 线性回归分析对话框用户还可点击Statistics...钮选择是否作变量的描述性统计、回归方程应变量的可信区间估计等分析;点击Plots...钮选择是否作变量分布图(本例要求对标准化Y预测值作变量分布图);点击Save...钮选择对回归分析的有关结果是否作保存(本例要求对根据所确定的回归方程求得的未校正Y预测值和标准化Y预测值作保存);点击Options...钮选择变量入选与剔除的α、β值和缺失值的处理方法。
SPSS多元线性回归分析实例操作步骤之欧阳美创编
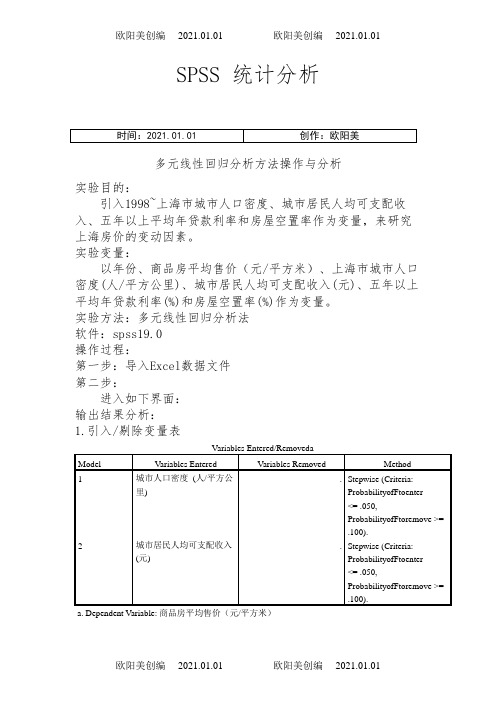
SPSS 统计分析多元线性回归分析方法操作与分析实验目的:引入1998~上海市城市人口密度、城市居民人均可支配收入、五年以上平均年贷款利率和房屋空置率作为变量,来研究上海房价的变动因素。
实验变量:以年份、商品房平均售价(元/平方米)、上海市城市人口密度(人/平方公里)、城市居民人均可支配收入(元)、五年以上平均年贷款利率(%)和房屋空置率(%)作为变量。
实验方法:多元线性回归分析法软件:spss19.0操作过程:第一步:导入Excel数据文件第二步:进入如下界面:输出结果分析:1.引入/剔除变量表Variables Entered/RemovedaModel Variables Entered Variables Removed Method1城市人口密度 (人/平方公里).Stepwise (Criteria: ProbabilityofFtoenter<= .050, ProbabilityofFtoremove >= .100).2城市居民人均可支配收入(元).Stepwise (Criteria: ProbabilityofFtoenter<= .050, ProbabilityofFtoremove >= .100).a. Dependent Variable: 商品房平均售价(元/平方米)该表显示模型最先引入变量城市人口密度 (人/平方公里),第二个引入模型的是变量城市居民人均可支配收入(元),没有变量被剔除。
1.模型汇总Model SummarycModel R R Square Adjusted R Square Std. Error of theEstimate DurbinWatson1 1.000a 1.000 1.00035.1872 1.000b 1.000 1.00028.351 2.845a. Predictors: (Constant), 城市人口密度 (人/平方公里)b. Predictors: (Constant), 城市人口密度 (人/平方公里), 城市居民人均可支配收入(元)c. Dependent Variable: 商品房平均售价(元/平方米)该表显示模型的拟合情况。
回归分析的spss实现

常见的非线性模型有: 1、二次曲线(Quadratic),方程为 y 0 1x 2 x2 ,变量变换后的方程为 y 0 1x 2 x1 ( x1 x2 ) y 0 1x 2、复合曲线(Compound),方程为 ,变量变换后的方程为 ln( y) ln(0 ) ln(1 ) x 3、增长曲线(Growth),方程为 ,变量变换后的方程为 ln( y) 0 1 x
2
曲线估计
• 曲线估计概述
变量间的相关关系中,并不总是表现出线性 关系,非线性关系也是极为常见的。变量之间的 非线性关系可以划分为本质线性关系和本质非线 性关系。本质线性关系是指变量关系形式上虽然 呈非线性关系,但可通过变量变换为线性关系, 并最终可通过线性回归分析建立线性模型。本质 非线性关系是指变量关系不仅形式上呈非线性关 系,而且也无法变换为线性关系。本节的曲线估 计是解决本质线性关系问题的。
求这段曲线的纵坐标y关于横坐标x的二次多项式回归方程.
3
非线性回归
3.混凝土的抗压强度随养护时间的延长而增加,现将一批 混凝土作成12个试块,记录了养护日期x(日)及抗压强度y (kg/cm2)的数据:
养护时间 x 抗压强度 y
2 35
3 42
4 47
5 53Βιβλιοθήκη 7 599 6512 68
14 73
17 76
ye
0 1x
4、对数曲线(Logarithmic),方程为 y 0 1 ln( x) ,变量变换后的线性方程 为 y 0 1x1 y 0 1x 2 x2 3 x3 5、三次曲线(Cubic),方程为 ,变量变换后的方程为 y 0 1x 2 x1 3 x2 0 1 / x 6、S曲线(S),方程为 y e ,变量变 换后的方程为 ln( y) 0 1x1 y 0e1x 7、指数曲线(Exponential),方程为 ,变量变换后的线性方程为 ln( y) ln(0 ) 1x
SPSS多元回归分析实例教程
1)准备分析数据在SPSS数据编辑窗口中,创建“年份”、“蛾量”、“卵量”、“降水量”、“雨日”和“幼虫密度”变量,并输入数据。
再创建蛾量、卵量、降水量、雨日和幼虫密度的分级变量“x1”、“x2”、“x3”、“x4”和“y”,它们对应的分级数值可以在SPSS数据编辑窗口中通过计算产生。
编辑后的数据显示如图2-1。
图2-1或者打开已存在的数据文件“DATA6-5.SAV”。
2)启动线性回归过程单击SPSS主菜单的“Analyze”下的“Regression”中“Linear”项,将打开如图2-2所示的线性回归过程窗口。
图2-2 线性回归对话窗口3) 设置分析变量设置因变量:用鼠标选中左边变量列表中的“幼虫密度[y]”变量,然后点击“Dependent”栏左边的向右拉按钮,该变量就移到“Dependent”因变量显示栏里。
设置自变量:将左边变量列表中的“蛾量[x1]”、“卵量[x2]”、“降水量[x3]”、“雨日[x4]”变量,选移到“Independent(S)”自变量显示栏里。
设置控制变量: 本例子中不使用控制变量,所以不选择任何变量。
选择标签变量: 选择“年份”为标签变量。
选择加权变量: 本例子没有加权变量,因此不作任何设置。
4)回归方式本例子中的4个预报因子变量是经过相关系数法选取出来的,在回归分析时不做筛选。
因此在“Method”框中选中“Enter”选项,建立全回归模型。
5)设置输出统计量单击“Statistics”按钮,将打开如图2-3所示的对话框。
该对话框用于设置相关参数。
其中各项的意义分别为:图2-3 “Statistics”对话框①“Regression Coefficients”回归系数选项:“Estimates”输出回归系数和相关统计量。
“Confidence interval”回归系数的95%置信区间。
“Covariance matrix”回归系数的方差-协方差矩阵。
本例子选择“Estimates”输出回归系数和相关统计量。
spss用多元线性回归分析GDP的结论
spss用多元线性回归分析GDP的结论通过建立多元线性回归模型对国内生产总值的影响因素作实证分析,以其拟合出较为优良的GDP模型:
根据奥肯定律我们认为,就业人数和GDP应当是相互促进的的增长的,但在文中模型它的增长反而会使GDP下降。
这主要是因为20世纪90年代以来,我国的经济迅速增长,但大多是靠投资和进出口带动,并没有真正的带动就业同步增长。
产业结构和人才结构不匹配,资本和技术密集程度提高,而且,人口的增长也抵消了很多就业岗位的增加,这就使得劳动力人数和GDP之间呈现出了负向的变化。
当然,GDP只是反应经济增长的一个指标,不能单纯的注重它在数量方面的增长,更要注重一个合理且优良的结构,比如这几年十分受到关注的绿色GDP 等。
要全面协调的经济发展才是不断提升综合国力和提高人民生活水平的正确方法。
SPSS多元线性回归结果分析
SPSS多元线性回归结果分析输出下⾯三张表第⼀张R⽅是拟合优度对总回归⽅程进⾏F检验。
显著性是sig。
结果的统计学意义,是结果真实程度(能够代表总体)的⼀种估计⽅法。
专业上,p 值为结果可信程度的⼀个递减指标,p 值越⼤,我们越不能认为样本中变量的关联是总体中各变量关联的可靠指标。
p 值是将观察结果认为有效即具有总体代表性的犯错概率。
如 p=0.05 提⽰样本中变量关联有 5% 的可能是由于偶然性造成的。
即假设总体中任意变量间均⽆关联,我们重复类似实验,会发现约 20 个实验中有⼀个实验,我们所研究的变量关联将等于或强于我们的实验结果。
(这并不是说如变量间存在关联,我们可得到 5% 或 95% 次数的相同结果,当总体中的变量存在关联,重复研究和发现关联的可能性与设计的统计学效⼒有关。
)在许多研究领域,0.05 的 p 值通常被认为是可接受错误的边界⽔平。
F检验:对于多元线性回归模型,在对每个回归系数进⾏显著性检验之前,应该对回归模型的整体做显著性检验。
这就是F检验。
当检验被解释变量y t与⼀组解释变量x1, x2 , ... , x k -1是否存在回归关系时,给出的零假设与备择假设分别是H0:b1 = b2 = ... = b k-1 = 0 ,H1:b i, i = 1, ..., k -1不全为零。
⾸先要构造F统计量。
由(3.36)式知总平⽅和(SST)可分解为回归平⽅和(SSR)与残差平⽅和(SSE)两部分。
与这种分解相对应,相应⾃由度也可以被分解为两部分。
SST具有T - 1个⾃由度。
这是因为在T个变差 ( y t -), t = 1, ..., T,中存在⼀个约束条件,即 = 0。
由于回归函数中含有k个参数,⽽这k个参数受⼀个约束条件制约,所以SSR具有k -1个⾃由度。
因为SSE中含有T个残差,= y t -, t = 1, 2, ..., T,这些残差值被k个参数所约束,所以SSE具有T - k个⾃由度。
SPSS实验回归分析
回归分析一.实验描述:中国民航客运量的回归模型。
为了研究我国民航客运量的变化趋势及其成因,我们以民航客运量作为因变量Y,以国民收入(X1)、消费额(X2)、铁路客运量(X3)、民航航线里程(X4)、来华旅游入境人数(X5)、为主要影响因素。
数据如下表。
试建立Y与X1--X5之间的多元线性回归模型。
二.实验过程描述及实验结果(1)该表格中输出了5个自变量和1个因变量的一般统计结果,包括各自变量与因变量的平均值,标准差和个案数16。
该表格中列出了各个变量之间的相关性,从该表格可以看出因变量Y和自变量X1之间的相关系数为0.989,相关性最大,。
因变量Y与自变量X3之间相关系数为0.227,相关性最小。
(3)该表格输出的是被引入或从回归方程中被剔出的各变量。
说明进行线性回归分析时所采用的方法是全部引入法Enter。
因变量为Y。
(4)该表格输出的是常用统计量。
从该表看出相关性系数R为0.999,判定系数R2为0.998,调整的判定系数为0.997,回归估计的标准误差为49.49240。
该表格输出的是方差分析表。
从这部分结果看出:统计量F为1.128E3;相伴概率值小于0.01,拒绝原假设说明多个自变量与因变量Y之间存在线性回归关系。
Sum of Squares一栏中分别代表回归平方和(1.382E7),残差平方和(24494.981)以及总平方和(1.384E7),df为自由度。
判定系数R2=0.99855。
该表格为回归系数分析。
其中Unstandardized Coefficients为非标准化系数,Standardized Coefficients为标准化系数,t为回归系数检验统计量,sig为相伴概率值。
由表知t检验的相伴概率值均小于0.01,拒绝原假设,说明个变量与因变量之间均有显著线性相关关系。
从表格中可以看出该多元线性回归方程为:y=450.909+0.354 X1-0.561 X2-0.007 X3+21.578 X4+0.435 X5该表格为残差统计结果表。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS多元回归分析实例
多元回归分析是一种多变量统计分析方法,它用于探讨自变量与因变量之间的关系。
在实际应用中,可以通过SPSS软件进行多元回归分析。
以下是一个关于房屋价格的多元回归分析实例。
假设我们想要解释一些城市房屋价格与房屋的面积、年龄和地理位置之间的关系。
首先,我们需要收集相关数据,包括房屋价格作为因变量,房屋的面积、年龄和地理位置作为自变量。
我们可以通过SPSS软件建立一个数据文件,将这些数据输入到相应的变量中。
然后,我们需要进行数据预处理,包括缺失值处理和异常值处理。
在SPSS中,可以使用"Transform"菜单中的"Recode"功能来处理缺失值和异常值。
接下来,我们可以建立一个多元回归模型,通过分析自变量与因变量之间的关系。
在SPSS中,可以使用"Analyze"菜单中的"Regression"功能来进行多元回归分析。
在多元回归分析的对话框中,我们需要选择因变量和自变量,然后点击"OK"按钮运行分析。
在本例中,我们可以选择价格作为因变量,面积、年龄和地理位置作为自变量。
SPSS将输出分析结果,包括回归系数、标准误差、显著性水平等信息。
我们可以根据这些结果来解释自变量与因变量之间的关系。
例如,回归系数表示自变量对因变量的影响程度。
正的回归系数表示自变量与因变量呈正相关关系,负的回归系数表示自变量与因变量呈负相关关系。
标准误差用于评估回归模型的准确性。
较小的标准误差表示模型的预
测能力较强,较大的标准误差表示模型的预测能力较弱。
显著性水平用于判断自变量与因变量之间的关系是否显著。
通常情况下,显著性水平小于0.05时,表示自变量与因变量之间的关系是显著的。
最后,我们可以通过图表来展示多元回归分析的结果。
在SPSS中,
可以使用"Graphs"菜单中的"Chart Builder"功能来绘制相关的图表,如
散点图、线性回归图等。
总而言之,通过SPSS软件进行多元回归分析可以帮助我们解释自变
量与因变量之间的关系。
在实际应用中,多元回归分析可以用于预测房屋
价格、销售量等目标变量。
同时,我们还可以根据分析结果来优化自变量
的选择,提高模型的准确性。