stata简单讲义第五讲

Stata软件基本操作和数据分析入门
第五讲多组平均水平的比较
赵耐青
一、复习和补充两组比较的统计检验
1. 配对设计资料(又称为Dependent Samples)
a)对于小样本的情况下,如果配对的差值资料服从正态分布,用配对t检验
(ttest 差值变量=0)
b)大样本的情况下,可以用配对t检验
c)小样本的情况下,并且配对差值呈偏态分布,则用配对符号秩检验(signrank
差值变量=0)
2. 成组设计(Two Independent Samples)
a)如果方差齐性并且大样本情况下,可以用成组t检验(ttest 效应指标变
量,by(分组变量))
b)如果方差齐性并且两组资料分别呈正态分布,可以用成组t检验
c)(Ranksum test)
二、多组比较
1. 完全随机分组设计(要求各组资料之间相互独立)
a)方差齐性并且独立以及每一组资料都服从正态分布(小样本时要求),则采用
完全随机设计的方差分析方法(即:单因素方差分析,One Way ANOV A)进
行分析。
b)方差不齐或小样本情况下资料偏态,则用Kruskal Wallis 检验(H检验)
例5.1 为研究胃癌与胃粘膜细胞中DNA含量(A.U)的关系,某医师测得数据如下,试问四
组人群的胃粘膜细胞中平均DNA含量是否相同?
组别group DNA含量(A.U)
浅表型胃炎 1 9.81 12.73 12.29 12.53 12.95 9.53 12.6 8.9 12.27 14.26 10.68
肠化生 2 14.61 17.54 15.1 17 13.39 15.32 13.74 18.24 13.81 12.63 14.53 16.17早期胃癌 3 23.26 20.8 20.6 23.5 17.85 21.91 22.13 22.04 19.53 18.41 21.48 20.24
晚期胃癌 4 23.73 19.46 22.39 19.53 25.9 20.43 20.71 20.05 23.41 21.34 21.38 25.70由于这四组对象的资料是相互独立的,因此属于完全随机分组类型的。检验问题是考察四组DNA含量的平均水平相同吗。如果每一组资料都正态分布并且方差齐性可以用One
way-ANOV A进行分析,反之用Kruskal Wallis检验。
STA TA数据输入格式
分组正态性检验, =0.05
单因素方差分析的STATA命令:oneway 效应指标变量分组变量,t b 其中t表示计算每一组均数和标准差,b表示采用Bonferroni统计方法进行两
两比较。
本例命令为oneway x group,t b
. oneway x g,t b
| Summary of x
g | Mean Std. Dev. Freq.
------------+------------------------------------
1 | 11.686364 1.6884388 11
2 | 15.17333
3 1.749173 12
3 | 20.979167 1.7668279 12
4 | 22.002
5 2.2429087 12
------------+------------------------------------
Total | 17.583191 4.6080789 47
Analysis of Variance
Source SS df MS F Prob > F
------------------------------------------------------------------------ Between groups 824.942549 3 274.98085 77.87 0.0000
Within groups 151.839445 43 3.53114987
------------------------------------------------------------------------
Total 976.781994 46 21.2343912
Bartlett's test for equal variances: chi2(3) = 1.1354 Prob>chi2 = 0.769 方差齐性的检验为:卡方=1.1354,自由度=3,P值=0.769,因此可以认为方差是齐性的。
H 0:μ
1
=μ
2
=μ
3
=μ
4
四组总体均数相同
H 1:μ
1
,μ
2
,μ
3
,μ
4
不全相同
α=0.05,相应的统计量F=77.87以及相应的自由度为3和43,P值<0.0001,因此4组均数的差别有统计学意义。
Comparison of x by g
(Bonferroni)
Row Mean-|
Col Mean | 1 2 3
---------+---------------------------------
2 | 3.48697(第2组样本均数-第1组样本均数)
| 0.000(H
0:μ
1
=μ
2
检验的P值)
|
3 | 9.2928 5.80583(第3组样本均数-第2组样本均数)
| 0.000 0.000(H
0:μ
3
=μ
2
检验的P值)
|
4 | 10.3161 6.82917 1.02333(第4组样本均数-第3组样本均数)
| 0.000 0.000 1.000(H
0:μ
3
=μ
4
检验的P值)\
上述输出为两两比较的结果,在表格的每个单元中,第一行为两组均数的差值,第二行为两组均数比较检验的P值。
根据上述结果可以知道,第2组、第3组和第4组的AU均数均大于第1组的AU均数,并且差别有统计学意义。说明肠化生患者和胃癌患者的DNA的AU含量平均水平均高于正常人的AU平均水平,并且差别有统计学意义。
第3组和第4组的AU均数也大于第2组的AU平均水平,并且差别有统计学意义。说明胃
癌患者的DNA 的AU 含量平均水平均高于肠化生患者的AU 平均水平,并且差别有统计学意义。
第3组和第4组两组均数的差别没有统计学意义,说明没有足够的证据可以DNA 的AU 含量与癌症的早期与晚期有关系。
假如本例的资料不满足方差分析的要求,则用Kruskal Wallis 检验,数据结构同上。命令为: kwallis 效应指标变量, by(分组变量) 本例的命令为 kwallis x,by(g) H 0:4组的AU 总体分布相同
H 1:4组的AU 总体分布不全相同 α=0.05
结果如下:
说明:4组AU 的总体分布不全相同,然后秩和检验,但α应取小一些(多重比较时,会增大第一类错误的概率)。根据Sidak 检验的建议:1
1(1)k αα'=--,其中k 为要比较的次数,α为多组比较总的检验水平(一般为0.05),α’为两两比较时的检验水平。 如本例:4组两两比较共比246C =次,因此1
61(0.95)0.0085a '=-=, 对于比较第1组和第2组的AU 分布差别的操作命令为: 先计算中位数
sort g 组别变量排序
by g:centile x,centile(50) 计算各组中位数
1234
ranksum x if g==1 | g==2,by(g)
P值< ’,因此第2组AU的平均水平要高于第1组的平均水平(M2>M1),并且差别有统计学意义。
第1组与第3组比较
ranksum x if g==1 | g==3,by(g)
P 值<α’,因此第3组AU 的平均水平要高于第1组的平均水平(M 3>M 1),并且差别有统计学意义,其他比较类似进行。 要注意的问题:
◆ 在方差分析中,要求每一组资料服从正态分布(小样本时),并不是要求各组资料服从一
个正态分布(因为这就意味各组的总体均数相同,失去统计检验的必要性),所以不能把各组的资料合在一起作正态性检验。总的讲,方差分析对正态性具有稳健性,即:偏态分布对方差分析的结果影响不会太大,故正态性检验的α取0.05也就可以了。
◆ 样本量较大时,方差分析对正态性要求大大降低(根据中心极限定理可知:样本均数近
似服从正态分布)。并且由于大多数情况下,样本资料只是近似服从正态分布而不是完全服从正态分布。由于在大样本情况下,用正态性检验就变为很敏感,对于不是完全服从正态分布的资料往往会拒绝正态性检验的H 0:资料服从正态分布。因为正态性检验不能检验资料是否近似服从正态分布,而是检验是否服从正态分布。故在大样本情况下,考察资料的近似正态性,应用频数图进行考察。 ◆ 方差齐性问题对方差分析相对比较敏感,并且并不是随着样本量增大而方差齐性对方差
分析减少影响的。但是当各组样本量接近相同或相同时,方差齐性对方差分析呈现某种稳健性。即:只有当各组样本量相同时,方差齐性对方差分析结果的影响大大降低。这
时随着样本量增大,影响会进一步降低。相反,如果各组样本量相差太大时,方差齐性对方差分析结果的影响很大。这时随着样本量增大,影响会进一步加大。
2. 随机区组设计(处理组之间可能不独立)
a)残差(定义为:..ij ij i j e X X X X =+--,也就是随机区组方差分析中的误差项)
的方差齐性且小样本时正态分布,则用随机区组的方差分析(无重复的两因
素方差分析,Two-way ANOV A)。
b)不满足方差齐性或小样本时资料偏态,则对用秩变换后再用随机区组的方差分析也可以直接用非参数随机区组的秩和检验Fredman test)。 例2下表是某湖水中8个观察地点不同季节取样的氯化物含量测定值,请问在不同季节该湖
水中氯化物的含量有无差别?
表2 某湖水中不同季节的氯化物含量测定值(mg/L ) location no
春 夏 秋 冬 1 21.28 18.33 17.27 14.91 2 22.78 19.81 16.55 14.85 3 20.90 18.93 16.36 16.30 4 19.90 21.23 17.86 15.73 5 21.49 19.09 15.11 17.05 6 22.38 17.92 16.57 14.34 7 21.67 19.39 17.19 16.31 8
22.06
19.65
16.58
14.33
显然同一地点不同季节的氯化物含量有一定的相关性,故不能采用完全随机设计的方差分析方法对4个季节的氯化物含量进行统计分析。可以把同一地点的4个季节氯化物含量视为一个区组,因此可以用随机区组的方差分析进行统计分析。
设第8个地点在冬季的氯化物总体均数为μ0,同样在冬季,第i个地点的氯化物总体均数与第8个地点在冬季的氯化物总体均数相差βi,i=1,2,3,4,5,6,7。因此在冬季的这8个地点在冬季的氯化物总体均数可以表示为
地点编号 1 2 3 4 5 6 7 8 冬季氯化物均数μ
+β1μ0+β2μ0+β3μ0+β4μ0+β5μ0+β6μ0+β7μ0
假定在同一地区,春季的氯化物总体均数与冬季的氯化物总体均数相差α1,因此春节和冬季的氯化物总体均数可以表示为
地点编号 1 2 3 4 5 6 7 8 冬季氯化物均数μ0+β1μ0+β2μ0+β3μ0+β4μ0+β5μ0+β6μ0+β7μ0春季氯化物均数μ0+α1+β1μ0+α1+β2μ0+α1+β3μ0+α1+β4μ0+α1+β5μ0+α1+β6μ0+α1+β7μ0如果α1=0说明在同一地点,冬季和春季的氯化物总体均数相同;α1>0说明春季的氯化物含量平均高于冬季氯化物含量,反之α<0,说明春季氯化物含量均数低于冬季氯化物含量。同理假定在同一地区,夏季和秋季的氯化物总体均数与冬季的氯化物总体均数分别相差α2和α3,则四个季节的氯化物总体均数可以表示为
地点编号 1 2 3 4 5 6 7 8 冬季氯化物均数μ0+β1μ0+β2μ0+β3μ0+β4μ0+β5μ0+β6μ0+β7μ0春季氯化物均数μ0+α1+β1μ0+α1+β2μ0+α1+β3μ0+α1+β4μ0+α1+β5μ0+α1+β6μ0+α1+β7μ0夏季氯化物均数μ0+α2+β1μ0+α2+β2μ0+α2+β3μ0+α2+β4μ0+α2+β5μ0+α2+β6μ0+α2+β7μ0春季氯化物均数μ0+α3+β1μ0+α3+β2μ0+α3+β3μ0+α3+β4μ0+α3+β5μ0+α3+β6μ0+α3+β7μ0根据上述总体均数表示,可以知道:在四个季节中的氯化物总体均数(同一地点)无变化就是H0:α1=α2=α3=0(在随机区组方差分析中称为无处理效应,但不能称4组的总体均数相同,因为在同一季节中不同地点的总体均数可能不同)。
H1:α1,α2,α3不全为0
Stata 数据输入格式
其中id
Stata操作命令:
anova x t id
. anova x t id
Number of obs = 32 R-squared = 0.8923 Root MSE = 1.01769 Adj R-squared = 0.8410
Source | Partial SS df MS F Prob > F -----------+---------------------------------------------------- Model | 180.214326 10 18.0214326 17.40 0.0000 |
t | 177.344737 3 59.1149122 57.08 0.0000 id | 2.86958916 7 .409941308 0.40 0.8942 |
Residual | 21.749618 21 1.0356961
-----------+---------------------------------------------------- Total | 201.963944 31 6.51496593
处理效应H0:α1=α2=α3=0的检验对应的统计量
18.021
57.08
1.036
M S
F
M S
===
处理
误差
相应的P值<0.0001(计算机输出值是0.0000),所以拒绝无效假设,可以认为4个季节的氯化物总体均数不全相同。
不同季节中的两两比较用LSD方法检验如下:
在输入anova x t id命令后,再输入regress命令便得到下列结果
其中1 6.081α=
,对应的假设检验H 0:α1=0的统计量t=11.95,P 值<0.001,95%可信区间
为(5.022,7.139),因此可以认为春季的氯化物平均高于冬季,差别有统计学意义。 2 3.816α=
,对应的假设检验H 0:α2=0的统计量t=7.50,P 值<0.001,95%可信区间为
(2.758,4.874),因此可以认为夏季的氯化物平均高于冬季,差别有统计学意义。
3 1.208α=
,对应的假设检验H 0:α3=0的统计量t=2.37,P 值=0.027,95%可信区间为
(0.1494,2.266),因此可以认为秋季的氯化物平均高于冬季,差别有统计学意义。
对于春季氯化物平均数(μ0+α1+βi )与夏季的氯化物平均数(μ0+α2+βi )比较对应为α1>α2、α1=α2和α1<α2的问题。因此需要检验H 0:α1=α2 vs H 1:α1≠α2 ,相应的STATA 命令(anova x t id 命令和regress 命令后)为test b[t[1]]=_b[t[2]],得到下列结果
相应的统计量F=26.28,P 值<0.0001,差别有统计学意义。由于α1的估计值>α2的估计值,所以可以认为春季氯化物平均高于夏季的氯化物含量。
同理检验H 0:α1=α3 vs H 1:α1≠α3,只需输入命令test b[t[1]]=_b[t[3]] 检验H 0:α2=α3 vs H 1:α2≠α3,只需输入命令test b[t[2]]=_b[t[3]] 此处不在详细叙述了。
由于随机区组方差分析要求残差(..ij ij i j e X X X X =+--)服从正态分布,再输入
regress 以后,只要输入predict 残差变量名,residual ,就可以得到残差计算值。 本例用e 表示残差变量名,因此输入predict e,residual
就可以得到残差计算值e,然后对残差进行正态性检验(sktest 残差变量名)
本例输入命令为: sktest e
虑正态性问题)
如果资料呈偏态分布,可以对资料进行秩变换(Rank Transform)后,然后把变换后的秩视为原始数据进行随机区组的方差分析。
秩变换的STATA命令为egen 秩变量名=rank(观察变量名),by(区组变量)
为了说明上述操作分析的过程,故借用本例资料进行秩变换操作说明如下(本例资料正态分布,无需用秩变换,只是说明操作而言).
设用r表示秩变量名,则本例操作为
egen r=rank(x) ,by(id) 产生秩r
解释如同上述,不再重复。
stata常见问题及解决办法个人总结笔记
1. 如何输出STATA的图,和保存? 先输入数据 (1)Twoway connected 变量1 变量2 //划出折线图 (2)twoway scatter 变量1 变量2 //划出散点图 2. 怎样在stata8中做HAUSMAN检验? 四步曲,重点在于解释结果 (1)xtreg y x , fe (2)est store fe (3)xtreg y x, re (4)hausman fe 如果拒绝,说明corr(x,ui)=0的假设是有问题的,需要重新设定RE model 后再进行检验,如果模型的设定没有问题,但检验还是拒绝原假设(p值接近0),那么就只能采用FE model 了,因为此时的RE 估计量是有偏的。 (definitely right. 当你使用stata的时候,最重要的命令不是这些是help and find it然后就能找到你的答案了) hausman检验是用来检验用fe还是re的,其原假设是re优于fe,从你的结果来看(Prob>chi2 =0.0000),应该拒绝原假设,所以应该用fe 3.stata里平方的命令怎么写? gen age=age^2 4. stata里边怎么取对数啊? gen lnx=log(x) 5.如何用STATA求自然对数?如说:ln(X^2)=-4.8536,如何求X啊? . dis sqrt(exp(-4.8536))或者dis exp(-4.8536/2) 6.关于hausman检验,结果是CHI2(2)=2355.81,prob>chi2=0.000,可以使用随机效应模型嘛? prob>chi2=0.000,is like p-value. we should reject the null, so fixed effect is preferred.Randome effect is not suggested. CHI2(2)=2355.81,就意味着拒绝原假设,从而选取固定效应模型。 7.我在做gdp一阶差分单位根检验的时候,输入的命令是ipshin dgdp,lags(1)得
Stata 自学笔记
Stata笔记 1.clear 2.input 3.save https://www.360docs.net/doc/73424273.html,e 5.sysuse 6.d/des/desc/describe 7.sum & return list & ereturn list 8.reg 9.clear results 10.matrix 11.type 12.insheet 13.rename 14.infile 15.browse 16.xmluse https://www.360docs.net/doc/73424273.html,press 18.xpose 19.tsset 20.outfile 21.outsheet 22.xmlsave 23.变量 Stata笔记 1.clear 清除内存数据。数据都是存入内存来计算的,所以在输入大量数据之前,要先清除内存中的数据来释放空间。删除的不光包括数据,还有变量,以及Data Editor 中的数据。(就是删除所有数据,什么都不留) 不影响已经存在硬盘上的数据。(只删除内存中的所有数据)
具体使用方法在下文中有具体例子。 手动输入数据。 可以分五次输入,也可以直接复制到Command 。 input x y x 50 30 20 20 30 50 20 52 60 end 保存数据。 此项如果保存在C 盘可能因为权限不够而报错。换到其他盘符即可。 save data_name[,replace] save 名称[,如果之前已经有这个名称,则替换(覆盖)。] 使用、导入(.dta )数据。 use data_name[,clear] use “file_path”[,clear] use url[,clear] use 名称[,清除。] 2.input 3.save https://www.360docs.net/doc/73424273.html,e
Stata12软件的基本设定(设置)
Stata12 软件的基本设定 如果你已经安装了stata12,请直接跳到(6)。 ( 1)将StataSE12.1绿色版.7z解压到D盘根目录,即D:\stata12(注意:是D:\stata12,而 非D:\stata12 \stata12,另外, stata12 是小写)。 (下载地址: https://www.360docs.net/doc/73424273.html,/share/link?shareid=2683949182&uk=3523563089) (2)打开stata12:双击图1中带有蓝色阴影的图标即可。1 图 1stata12 放置界面 (3)关于更新 A 、首次打开 stata12,会弹出对话框,询问你是否需要更新。如果不需要更新,请按下 图进行设定: 图 2首次打开stata12 时的更新设定B(、为了节省时间,这一步可以跳过,对于一般用户而言,更新与否不会影响你的使 用效果)如需把stata12 更新到最新版本,请在command窗口中输入updateal l命令。更新过程大概需要几分钟到几十分钟不等。特别注意的是,更新完毕后,你一定要输入如下 命令,才算是真正完成了stata 的更新: updateswap。这个命令的作用是用新下载的文件覆盖 旧文件。忘记这一步,往往会导致你的stata 丢失变量或出现一些奇怪的现象。 1 你也可以右击这个图标,然后选择“附加到开始菜单”。这样 stata12 的 logo 就会出现在开始 菜单中,每次启动 stata12 就只需从“开始”菜单中单击这个 logo 即可。
(4)关于profile.do文件。每次启动stata12 时,它会自动执行D:\stata12 文件夹下的 profile.do文件,该文件中包含了一系列命令,用于设定stata所占用的内存,各种 文件路径的位置等信息。如果你是按照上述要求放置stata12 文件的,那么启动 stata12 后,屏幕上应该显示如下信息(否则你要检查文件名的拼写是否正确):running stata12 profi le .do... ( 5)如果你的计算机分区中没有 D 盘,你也可以把stata12 放置于其他盘符下,但需要做一些微小的调整。这里以 F 盘为例,也可以是C, H, K 等其他盘 ①.将 stata12 解压后放置于 F 盘下,即F:\stata12 。注意: stata 是小写。 ②.修改 profile.do 文件,具体方法为 : Step1: 输入 doedit F:\stata12 \prof il e. do命令,打开 profile.do 文件; Step2:将第六行 中的 localD"D" 命令修改为 l ocal D"F"; Step3:保存 profile.do文件,退出stata12,然后重启即可。 ③.若上述设定无误,则在重新打开stata12 后,屏幕第一行会显示如下信息: running stata12profi le .d o... 同时,输入sysdir命令,屏幕上会呈现如下信息( 此时你才能正确使用外部命令): .sy sdir STATA: F stata12 UPDATES: F stata12 \ado\updat BASE: F stata12 \ado\bas SIT E: F stata12 \ado\s it PLUS: F stata12 \ado\p PERSONAL: F stata12 \ado\personal PartII :课件的使用方法 Q1. 如何打开课堂上使用的do 文档? A:请将PX_aufe.rar压缩包解压到D:\stata12\ado\personal 文件夹中,即 D:\stata12\ado\personal\PX_aufe 。若希望练习第一讲中的相关操作,可依次执行如下命令:Step1:在STATA命令窗口中输入cdD:\stata12\ado\personal\PX_aufe命令,定义当前工作 路径(会显示在 STATA 屏幕左下角); Step2:输入doedit xB01_Panel_Data命令,即可打开第一讲的讲义 xB01_Panel_Data.do 文件。当然,我们也可以通过点击菜单的方式完成 上述操作,步骤如下: Step1:在 STATA 主菜单中点击 “ Newdo-fileEditor ”图标; Step2:在第一步中弹出的“ Do-fileEditor”窗口中点击“O pen”图标,然后到D:\stata12\ado\personal\PX_aufe文件夹下,双击“ xB01_Panel_Data”文件即可打开之。 B:在练习之前,请先执行如下命令,以便进入第一讲所在目录,本讲中使用的所有数 据文件和相关文档都存放于该目录下。请选中下图中第 34-37 行的命令,点击菜单条中第二行中 带有蓝色阴影的按钮( ExecuteSelection(do) ,快捷键为 Ctrl+D )。
让你快速上手的stata讲义
Stata简明讲义 王非 中国经济研究中心 ebwf@https://www.360docs.net/doc/73424273.html,
〇、写在前面的话 关于学习Stata的意义,大家只需知道:目前,Stata是计量经济学、特别是微观计量经济学的主流软件。因此,Stata很重要、很有用,而大家也会在使用Stata 的过程中慢慢体会到它的特点。 本讲义取名为“Stata简明讲义”,意在突出“简”和“明”两个字。虽然讲义长达五十多页,但相比Stata的完全手册来说,还不及九牛之一毛,故为“简”。实际上,完全手册中的很多内容都鲜有人(特别是计量经济学者)问津,而本讲义列出的内容则是大家经常用到的操作;所以,“简”也有“简”的好处。即便如此,掌握这份讲义也并非易事。所谓“明”,是明晰的意思。本讲义本着“手把手教”的精神,力求把每项操作都说得具体明晰,以方便初学者(特别是没有程序操作经历的初学者)尽快上手。至于本讲义在“简明”上做得怎么样,还需要各位读者来评判。 中心的一位学长邹传伟,曾经写过一份“Stata介绍”,在网上可以下载。那份讲义比较全面,但不够具体明晰。本讲义参照那份讲义,在框架上查漏补缺,并进一步地明晰化。本讲义第二部分的“do文件”和第七部分的“残差分析”的相关内容均来自于中心的沈艳老师的相关讲义,而沈老师对于本讲义的成形给予了细致的指导。本讲义附带了一些数据文件,其中“WAGE1.dta”和“WAGEPRC.dta”均来自Wooldridge的中级计量教材的数据集,而其他数据则为作者自己的杜撰。尽管从别人那里拿来了许多好东西,但本讲义的任何错误仍源于作者自己的疏忽。 本讲义是这样安排的:第一部分讲Stata的界面,第二部分讲do文件,第三部分讲怎样把数据导入Stata,第四部分专门讲help和search命令以及帮助文件的阅读方法,第五部分讲数据的描述及管理,第六部分讲如何画图,第七部分讲初步的回归分析。
Stata学习笔记
以下命令均采用小写字母 Chapter 1 stata入门 打开数据 use "D:\Stata9\", clear 用use命令打开数据 sysuse auto,clear auto 为系统数据sysuse为打开系统数据的命令 获取帮助 Help summarize summarize为需要获取帮助对象可以改为其他的需要帮助的对象Findit summarize,net 寻找网络帮助summarize为需要获取帮助对象 Search summarize ,net 寻找网络帮助summarize为需要获取帮助对象 显示结果 Display 5+9 描述统计(summarize 可简写成sum) Use atuo,clear Summarize price 描述price的观察值个数、平均值、标准差、最小值、最大值 Sum weight summarize可简写成sum Sum weight price 同时完成上面两步 绘图 Scatter price weight scatter 为绘制散点图命令 Line price weight ,sort line 为绘制折线图命令,sort为排序,绘制折线图前需要先排序 生成新的数据(generate 可简写成gen) Clear Set obs 1000 设置观测值的组数 Gen x=_n _n 为观察值得序号 Gen y=x+100 控制结果输出显示 List n 设置屏幕滚动 Set more off 先设置此项则显示时,屏幕不停止 Set more on 先设置此项则显示时,会使显示停止 清除内存中原有内容 clear 设置文件存取路径(cd) Cd d:\stata d:\stata为路径
stata简单讲义第六讲
线性相关和回归 赵耐青 在实际研究中,经常要考察两个指标之间的关系,即:相关性。现以体重与身高的关系为例,分析两个变量之间的相关性。要求身高和体重呈双正态分布,既:在身高和体重平均数的附近的频数较多,远离身高和体重平均数的频数较少。 样本相关系数计算公式(称为Pearson 相关系数): ) () () )((2 2 YY XX XY L L L Y Y X X Y Y X X r = ----= ∑ ∑ ∑ (1) 1. 考察随机模拟相关的情况。 显示两个变量相关的散点图程序simur.ado (本教材配套程序,使用见前言)。命令为simur 样本量 总体相关系数 如显示样本量为100,ρ=0的散点图 本例命令为simur 100 0
如显示样本量为200,ρ=0.8的散点图本例命令为simur 200 0.8 如显示样本量为200,ρ=0.99的散点图本例命令为simur 200 0.99
如显示样本量为200,ρ=-0.99的散点图 本例命令为simur 200 -0.99 例1. 测得某地15名正常成年男子的身高x(cm)、体重y(kg)如试计算x和y之间的相关系数r并检验H0:ρ=0 vs H1: ρ≠0。 α=0.05
数据格式为 176.0 69.0 175.0 74.0 172.0 68.0 170.0 64.0 173.0 68.5 168.0 56.0 172.0 54.0 170.0 62.0 172.0 63.0 173.0 67.0 168.0 60.0 171.0 68.0 172.0 76.0 173.0 65.0 Stata命令pwcorr 变量1 变量2 …变量m,sig 本例命令pwcorr x y,sig pwcorr x y,sig Pearson相关系数=0.5994,P值=0.0182<0.05,因此可以认为身高与体重呈正线性相关。
STATA实用教程
文档收集于互联网,已重新整理排版.word版本可编辑,有帮助欢迎下载支持. 第一章接触STATA 小而功能强大;数据存储在内存中,运算速度快;语法简单,结果易读;可编程?cd [direction] /*调整默认目录,当路径中存在空格时要加引号*/ ?set memory [number]/*内存设定,默认单位为KB,可自定MB*/ ?exit /*退出*/ 第二章STATA命令 [prefix:]command[varlist] [=exp.] [if exp.] [using filename] [in range] [weigh:] [, options] 命令前缀命令变量串表达式条件式使用文件个案范围权重选项?var | var#-var## | var* /*表示单变量、多变量、以var开头的变量*/ ?in # | in -# | in #/## /*表示第#个、倒数第#个、从第#到第##个变量*/ ?help commandname/*帮助*/ 第三章使用STATA数据文件 一、读取数据 ?use filename [, clear] /*读取全部数据,选项clear表示清空内存*/ ?use var1 var#using filename /*将数据部分变量读进内存*/ ?use in #/## using filename /*将数据部分个案读进内存*/ ?use if var==# using filename /*将数据特定个案读进内存*/ ?use filename if var==# /*同上*/ 二、数据的标签与注释 ?label data “text”/*标签用于对数据整体的说明,这是贴标签的命令*/ 1文档来源为:从网络收集整理.word版本可编辑.
Stata笔记-北京科技大学
改颜色edit-preference-general prefernce-classic 下面命令框-右键-font-改字号 命令cd d:\ 改到d盘(change directory) dir查询d盘有什么 sysuse auto 系统自带汽车数据,数据变量(字段)显示在右上角 br(owse) 浏览数据(字符型红色,数值型黑色,蓝色-右键-value labels-hide all labels标签隐藏) h(elp) li(st) 告诉你命令怎么用,下面有例子 左边双击执行,单击复制到命令框 order price mpg(单击右边的变量) order make-foreign 改变变量顺序,从make到foreign g(enerate) new=rep78-trunk 输出新变量(rep78,trunk是字段,可单击选择,"."表示缺省,加减乘除+-*/) list if new==14 (==为等于,=为赋值,可以点击more) li(st) if new2>=14 & new2<24 (按q可以退出,即quit) replace new3=rep78 (输错了替换) drop new new2 new3删除变量 list if new>10000 list make if new<10000|new>2000 (竖线表示或者,回车上面那个) !=表示不等于 左边命令,右键save save data 文件名为data sysuse auto preserve reserve save auto2 保存时不需加后缀,删除时带后缀.dta sort price从小到大 gsort price 都可以,比较随意 gsort -trunk price (默认加号,为排序) order make new (将new排到第二位) aorder (alphabetic 按字母顺序排序) disp(lay) sin(1) 作为计算器使用 ln以e为底 ----------------3.13--------- 锐思数据库选择数据 -----非金融行业负债表---- 左边-财务报表-非金融行业 合并标识-1合并报表 调整标识-1 报表类型-q4、信息来源-q4 公司类别-20-定期报告 信息来源:q4 a股股票代码
stata 中文教程
Stata介绍 作为流行的计量经济学软件,Stata的功能十分地全面和强大。可以毫不夸张地说,凡是成熟的计量经济学方法,在Stata中都可以找到相应的命令,而这些命令都有许多选项以适应不同的环境或满足不同的需要。即使是最详细的Stata手册,也难免有遗珠之憾,更何况本文仅是一个粗浅的介绍。掌握Stata最好的办法是在实践中学习:Stata 本身提供了非常强大的帮助系统,并且关于Stata的书籍和网络资源都不少。 本文拟根据如下顺序介绍Stata: 1.界面; 2.文件和数据; 3.语法和命令; 4.数据管理; 5.描述统计; 6.画图; 7.回归和回归分析; 8.常用命令。 第3和第4部分是最体现Stata灵活性的地方,也是应用Stata的基础。第5和第6部分介绍如何用Stata完成基本的统计功能。Stata的功能很多,比如回归,曲线拟合,生存分析,主成分分析,因子分析,聚类分析,时间序列分析等等。但回归无疑是其中最重要的功能。第7部分介绍如何用Stata作线性回归和Logistic回归。本文第2和第3部分包含了作者的观点,难免有偏颇之处。其余部分主要来自文献的归纳和总结。限于水平有限,错误在所难免,敬请原谅。
1.界面 图1 Stata界面 Stata有4个窗口: 1. Stata Command(右下)用于向Stata输入命令; 2. Stata Results(右上)用于显示运行结果; 3. Review(左上)记录使用过的命令; 4. Variables(左下)显示当前memory中的所有变量。 窗口上方是工具栏,其上的按钮依次为(从左到右)Open, Save, Print Graph/Print Log, Log Start/Stop/Suspend, Bring Log to Front, Bring Graph to Front, Do-file Editor, Data Editor, Data Browser, Clear –more- condition, Break。其中常用的有Open, Save, Do-file Editor, Data Editor和Data Browser(图1中已用圆圈标出)。它们的使用办法将在下文介绍。 工具栏上方是菜单栏。其中最常用的是Help菜单。 界面左下角显示了Stata的默认路径。Stata使用的数据文件一般存放在该路径下。
stata学习笔记
经济数据的特点与类型。 1、横截面数据:多个经济个体的变量在同一时间点上的取值,如2012年中国各省的GDP 2、时间数列数据:指的是某个经济个体的变量在不同时点上的取值,如1978-2012年山东 省每年的GDP 3、面板数据:多个经济个体的变量在不同时点上的取值,如1978-2012年中国各省的GDP 小样本OLS(最小二乘法):单一方程线性回归最常见方法 条件:解释变量与扰动项正交、扰动项无自相关、同方差。 拟合优度:衡量线性回归模型对样本数据的拟合程度(R2),越高说明模型拟合程度越好。单系数T检验:对回归方程扰动项的具体概率进行假设 显著性水平进行检验 F检验:整个回归方程是否显著 STATA操作简介: 如果数据中包含1949-10-01或1949/10/01的时间变量,导入stata后可能会被视为字符串,因此对于日度数据,可以使用命令gen newvar=date(varname,YMD),将其转换为整数日期变量,其中YMD说明原始数据的格式为年月日,如果原始数据的格式为月日年则使用MDY;对于月度数据则gen newvar=monthly(varname,YM)。 .describe:数据的概貌.drop keep:删除和保留 .su:统计特征Pwcorr:变量之间相关系数 Star(.05):5%显著性水平gen:产生 g intc=log(tc):取自然对数. reg:OLS回归 .Vce:协方差矩阵reg。。。,noc表示在进行回归时不要常数项 大样本OLS:只要求解释变量与同期的扰动项正交即可Robust:稳健标准误,如果存在异方差,则应使用稳健标准误
复旦大学stata精华学习笔记
Stata: 输出regression table到word和excel 1. 安装estout。最简单的方式是在stata的指令输入: ssc install estout, replace EST安装的指导网址是:https://www.360docs.net/doc/73424273.html,/bocode/e/estout/installation.html 2.跑你的regression 3.写下这行指令esttab using test.rtf,然后就会出现个漂亮的表格给你(WORD 文档)。只要再小幅修改,就可以直接用了。这个档案会存在my document\stata 下。如果你用打开的是一个stata do file,结果会保存到do文件所在文件夹中。如果要得到excel文件,就把后缀改为.xls或者.csv就可以了 4.跑多个其实也不难,只要每跑完一个regression,你把它取个名字存起来:est store m1。m1是你要改的,第一个model所以我叫m1,第二个的话指令就变成est store m2,依次类推。 5.运行指令:esttab m1 m2 ... using test.rtf就行了。 异方差的检验: Breusch-Pagan test in STATA: 其基本命令是:estat hettest var1 var2 var3 其中,var1 var2 var3 分别为你认为导致异方差性的几个自变量。是你自己设定的一个 滞后项数量。 同样,如果输出的P-Value 显著小于0.05,则拒绝原假设,即不存在异方差性。 White检验: 其基本命令是在完成基本的OLS 回归之后,输入 imtest, white 如果输出的P-Value 显著小于0.05,则拒绝原假设,即不存在异方差性 处理异方差性问题的方法: 方法一:WLS WLS是GLS(一般最小二乘法)的一种,也可以说在异方差情形下的GLS就是WLS。在WLS下,我们设定扰动项的条件方差是某个解释变量子集的函数。之所以被称为加权最小二乘法,是因为这个估计最小化的是残差的加权平方和,而上述函数的倒数恰为其权重。 在stata中实现WLS的方法如下: reg (被解释变量)(解释变量1)(解释变量2)…… [aweight=变量名]
stata笔记要点
1.一般检验 假设系数为 0,t 比较大则拒绝假设,认为系数不为 0. 假设系数为 0,P 比较小则拒绝假设,认为系数不为 0. 假设方程不显著,F 比较大则拒绝假设,认为方程显著。 2.小样本运用 OLS 进行估计的前提条件为: (1)线性假定。即解释变量与被解释变量之间为线性关系。这一前提可以通过将非线性转换为线性方程来解决。 (2)严格外生性。即随机扰动项独立于所有解释变量:与解释变量之间所有时候都是正交关系,随机扰动项期望为 0。(工具变量法解决) (3)不存在严格的多重共线性。一般在现实数据中不会出现,但是设置过多的虚拟变量时,可能会出现这种现象。Stata 可以自动剔除。 (4)扰动项为球型扰动项,即随即扰动项同方差,无自相关性。 3.大样本估计时,一般要求数据在 30 个以上就可以称为大样本了。大样本的前提是 (1)线性假定 (2)渐进独立的平稳过程 (3)前定解释变量,即解释变量与同期的扰动项正交。 (4)E(XiXit)为非退化矩阵。 (5)gt 为鞅差分序列,且其协方差矩阵为非退化矩阵。 与小样本相比,其不需要严格的外生性和正太随机扰动项的要求。 4.命令 稳健标准差回归:reg y x1 x2 x3, robust 回归系数与 OLS 一样,但标准差存在差异。如果认为存在异方差,则使用稳健标准差。使用稳健标准差可以对大样本进行检验。 只要样本容量足够大,在模型出现异方差的情况下,使用稳健标准差时参数估计、假 设检验等均可正常进行,即可以很大程度上消除异方差带来的副作用 对单个系数进行检验:test lnq=1 线性检验:testnl_b[lnpl]=_b[lnq]^2 5.如果回归模型为非线性,不方便使用 OLS,则可以采取最大似然估计法(MLE),或者非线 性最小二乘法(NLS) 6.违背经典假设,即存在异方差的情况。截面数据通常会出现异方差。 因此检验异方差可以: (1)看残差图,但只是直观,可能并不准确。 rvfplot(residual-versus-fitted plot)与拟合值的散点图 rvpplot varname(residual-versus-predictor plot)与解释变量的散点图 扰动项的方差随观测值而变动,表示可能存在异方差。 (2)怀特检验: estat imtest,white(post-estimation information matrix test) P比较小,则拒绝同方差假设,表示存在异方差,不能用OLS。反之则证明为同方差。 (3)BP 检验 estat hettest,iid (默认设置为使用拟合值 y^) estat hettest, rhs iid (使用方程右边的解释变量,而不是 y^)
STATA实用教程
S T A T A实用教程-CAL-FENGHAI.-(YICAI)-Company One1
第一章接触STATA 小而功能强大;数据存储在内存中,运算速度快;语法简单,结果易读;可编程cd [direction] /*调整默认目录,当路径中存在空格时要加引号*/ set memory [number] /*内存设定,默认单位为KB,可自定MB*/ exit /*退出*/ 第二章 STATA命令 [prefix:]command[varlist] [=exp.] [if exp.] [using filename] [in range] [weigh:] [, options]命令前缀命令变量串表达式条件式使用文件个案范围权重选项var | var#-var## | var* /*表示单变量、多变量、以var开头的变量*/ in # | in -# | in #/## /*表示第#个、倒数第#个、从第#到第##个变量*/ help commandname/*帮助*/ 第三章使用STATA数据文件 一、读取数据 use filename [, clear] /*读取全部数据,选项clear表示清空内存*/ use var1 var# using filename /*将数据部分变量读进内存*/ use in #/## using filename /*将数据部分个案读进内存*/ use if var==# using filename /*将数据特定个案读进内存*/ use filename if var==# /*同上*/ 二、数据的标签与注释 label data “text” /*标签用于对数据整体的说明,这是贴标签的命令*/ notes:“text” /*注释用于记录操作过程,这是写注释的命令*/
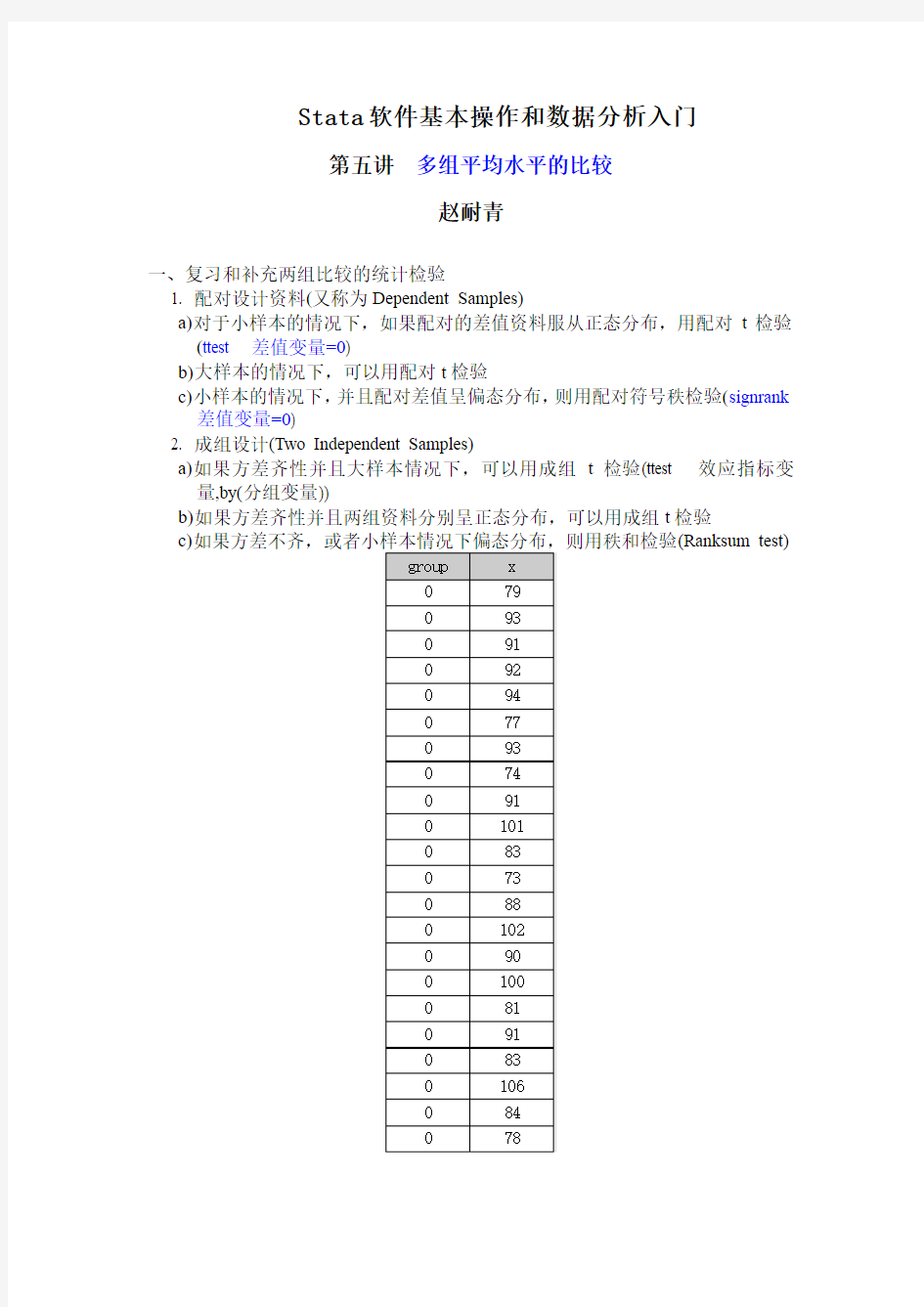
stata简单讲义第五讲
Stata软件基本操作和数据分析入门 第五讲多组平均水平的比较 赵耐青 一、复习和补充两组比较的统计检验 1. 配对设计资料(又称为Dependent Samples) a)对于小样本的情况下,如果配对的差值资料服从正态分布,用配对t检验 (ttest 差值变量=0) b)大样本的情况下,可以用配对t检验 c)小样本的情况下,并且配对差值呈偏态分布,则用配对符号秩检验(signrank 差值变量=0) 2. 成组设计(Two Independent Samples) a)如果方差齐性并且大样本情况下,可以用成组t检验(ttest 效应指标变 量,by(分组变量)) b)如果方差齐性并且两组资料分别呈正态分布,可以用成组t检验 c)(Ranksum test)
二、多组比较 1. 完全随机分组设计(要求各组资料之间相互独立) a)方差齐性并且独立以及每一组资料都服从正态分布(小样本时要求),则采用 完全随机设计的方差分析方法(即:单因素方差分析,One Way ANOV A)进 行分析。 b)方差不齐或小样本情况下资料偏态,则用Kruskal Wallis 检验(H检验) 例5.1 为研究胃癌与胃粘膜细胞中DNA含量(A.U)的关系,某医师测得数据如下,试问四 组人群的胃粘膜细胞中平均DNA含量是否相同? 组别group DNA含量(A.U) 浅表型胃炎 1 9.81 12.73 12.29 12.53 12.95 9.53 12.6 8.9 12.27 14.26 10.68 肠化生 2 14.61 17.54 15.1 17 13.39 15.32 13.74 18.24 13.81 12.63 14.53 16.17早期胃癌 3 23.26 20.8 20.6 23.5 17.85 21.91 22.13 22.04 19.53 18.41 21.48 20.24
Stata学习笔记和国贸理论总结
Stata学习笔记 一、认识数据 (一)向stata中导入txt、csv格式的数据 1.这两种数据可以用文本文档打开,新建记事本,然后将相应文档拖入记事本即可打开数据,复制 2.按下stata中的edit按钮,右键选择paste special 3.*.xls/*.xlsx数据仅能用Excel打开,不可用记事本打开,打开后会出现乱码,也不要保存,否则就恢复不了。逗号分隔的数据常为csv数据。 (二)网页数据 网页上的表格只要能选中的,都能复制到excel中;网页数据的下载可以通过百度“国家数据”进行搜索、下载 二、Do-file 和 log文件 打开stata后,第一步就要do-file,记录步骤和历史记录,方便日后查看。Stata处理中保留的三种文件:原始数据 (*.dta),记录处理步骤 (*.do),以及处理的历史记录 (*.smcl)。 三、导入Stata Stata不识别带有中文的变量,如果导入的数据第一行有中文就没法导入。但是对于列来说不会出现这个问题,不分析即可(Stata不分析字符串,红色文本显示;被分析的数据,黑色显示);第一行是英文变量名,选择“Treat first row as variable names” 在导入新数据的时候,需要清空原有数据,clear命令。 导入空格分隔数据:复制——Stata中选择edit按钮或输入相应命令——右键选择paste special——并选择,确定;导入Excel中数据,复制粘贴即可;逗号分隔数据,选择paste special后点击comma,然后确定。 Stata数据格式为 *.dta,导入后统一使用此格式。 四、基本操作(几个命令) (一)use auto,clear 。在清空原有数据的同时,导入新的auto数据。 (二)browse 。浏览数据。
V131-STATA全套数据资料+讲义-Chen_QJ_修改说明1
《资本-劳动替代弹性与地区经济增长》 修改说明 对审稿意见1的答复 非常感谢贵刊审稿人在百忙之中审阅拙作,并提出了一些宝贵的修改意见。参考这些意见,我们对文章初稿进行了如下几个方面的修改: (1)对文中部分公式的推导过程进行了更为细致的说明,统一放置于附录1。 (2)对文中所使用的估计方法——可行性一般化非线性最小二乘法(FGNLS)的具体实现过程,尤其是相关参数初始值的设定方法进行了更为细致的说明,请见正文和附录2。 (3)其它一些细节上的调整和完善。包括:对部分表述不妥之处的修改;增加了6条参考文献;对实证结果进行了更为细致的讨论,突出了本文结论所隐含的政策含义等。 下面,我们针对审稿人提出的问题给出详细答复。 审稿意见:本文估算了我国不同省份的资本-劳动替代弹性,并进一步考察了资本-劳动替代弹性对经济增长的影响。论文考察的问题具有较为重要的理论和现实意义,但文章仍存在较多的问题,建议作者进一步修正和完善。 下面我们具体指出本文存在的问题,如有不妥之处也请谅解。 1.本文第三部分替代弹性与经济增长率关系的理论分析中存在的问题较多,这里得不到作者想要的结论,本部分存在的问题如下: (1)在新古典增长框架下,经济增长率是外生给定的,经济增长率取决于人口增长率与技术进步率。在本的框架下,均衡状态人均产出的增长率等于零,而与资本-劳动替代弹性无关,因此得不到本文的结论。 (2)文中方程(1)后资本边际生产率括号外的指数有误,请仔细核实; (3)文中方程(3)前的推导有误,得不到文中方程(3)的结论; (4)同样的,也得不到文中方程(4)的结论。 答复:本文以新古典生产函数为基础来推导经济增长率和替代弹性的关系,分析中采用索洛基本方程,但并没有分析经济处于稳态时替代弹性对经济增长率的影响。此外,Klump and de La Grandville(2000)的理论分析研究表明,当经济处于稳态时,具有较高替代弹性的经济体的人均产出水平的增长率将更高,所以,即使在新古典框架下,替代弹性将影响稳态时的经济增长率。在替代弹性大于1的条件下,资本-劳动比趋于无穷大时,资本的边际产量大于0,因此,即使没有技术进步也能实现经济增长,即内生经济增长。 我们仔细检查了理论分析部分推导过程,发现资本边际生产率括号外的指数应为 1 1 σ- ,我
江西财经大学营销调研stata软件笔记
.sysuse auto,clear 从内存中调一笔数据 .help sysuse 帮助菜单 help+其他单词都弹出帮助菜单 .sysuse dir 出来的结果↓ .auto.dta census.dta fscstage1.dta network1.dta strepto.dta voter.dta autornd.dta cholesterol.dta gnp96.dta network1a.dta telomerase.dta xrcise4deprsn.dta bcg.dta citytemp.dta haloperidol.dta nlsw88.dta tsline1.dta xtline1.dta bplong.dta citytemp4.dta lifeexp.dta nlswide1.dta tsline2.dta bpwide.dta educ99gdp.dta lubin97.dta pop2000.dta uslifeexp.dta cancer.dta fleiss.dta magnes.dta sp500.dta uslifeexp2.dta .sysuse sp500,clear 查询sp500的相关数据 .clear 清除数据 .edit 建立空白数据表格 .rename var1 code 把var1(原始表格列命名)重命名为code .label variable val2 “年龄” .label variable val2 “age” .help rename 重命名的帮助菜单 webuse renamexmpl 从网上下载一些数据 des (describe the data)表格中的数据分析 renpfix income inc 批量更改数据 .insheet using "D:\data0507.txt",clear 通过命令导入文件 .sysuse auto,clear sumarize price.detail .stata的命令结构如下 [bysort:] command [][][][][] .help tab(tabulate) sysuse census, clear describe contains data from D:\ado\base/c/census.dta obs: (观测值) 50 1980 Census data by state vars:(变量名) 13 6 Apr 2009 15:43 size: 3,100 (99.9% of memory free) --------------------------------------------------------------------- --------------------------------------------------------------- storage display value variable name type format label variable label --------------------------------------------------------------------- ---------------------------------------------------------------
Stata时间序列笔记
文档结尾是FAQ和var建模的15点注意事项 【梳理概念】 向量自回归(VAR, Vector Auto regression)常用于预测相互联系的时间序列系统以及分析随机扰动对变量系统的动态影响。 V AR模型: V AR方法通过把系统中每一个内生变量,作为系统中所有内生变量的滞后值的函数来构造模型,从而回避了结构化模型的要求。 V AR模型对于相互联系的时间序列变量系统是有效的预测模型,同时,向量自回归模型也被频繁地用于分析不同类型的随机误差项对系统变量的动态影响。如果变量之间不仅存在滞后影响,而不存在同期影响关系,则适合建立V AR模型,因为V AR模型实际上是把当期关系隐含到了随机扰动项之中。 协整: Engle和Granger(1987a)指出两个或多个非平稳时间序列的线性组合可能是平稳的。假如这样一种平稳的或的线性组合存在,这些非平稳(有单位根)时间序列之间被认为是具有协整关系的。这种平稳的线性组合被称为协整方程且可被解释为变量之间的长期均衡关系。 * 第六讲时间序列分析 *---- 目录----- * *-- 简介 * 6.1 时间序列数据的处理 *-- 平稳时间序列模型 * 6.2 ARIMA 模型 * 6.3 V AR 模型 *-- 非平稳时间序列模型——近些年得到重视,发展很快 * 6.4 非平稳时间序列简介 * 6.5 单位根检验——检验非平稳 * 6.6 协整分析——非平稳序列的分析 *-- 自回归条件异方差模型 * 6.7 GARCH 模型——金融序列不同时点上序列的差异
反映动态关系的时间数据顺序不可颠倒 cd d:\stata10\ado\personal\Net_Course\B6_TimeS *======================= * 时间序列数据的处理help time *======================= * 声明时间序列:tsset 命令 use gnp96.dta, clear list in 1/20 gen Lgnp = L.gnp(此时没办法生成之后一阶的变量,因为没有设定时间变量) tsset date(设定date为时间变量,timeseries) list in 1/20 gen Lgnp = L.gnp96 滞后一期,所以会产生1个缺失值 ●检查是否有断点——肉眼看不方便,用命令检查 use gnp96.dta, clear tsset date tsreport, report drop in 10/10 ——去掉断点成连续的,才能继续进行 list in 1/12 tsreport, report tsreport, report list/*列出存在断点的样本信息*/ ●填充缺漏值——接着上一步,看看stata如何填充缺漏值。一般用前面的数据的平均值或 预测等 Tsfill(以缺漏值的形式)
stata 学习笔记(持续更新中) (2011-04-14 212642)
一、异方差怀特检验 在stata中没有这个命令。联网的情况下,使用“ssc install whitetst”即可下载安装。以下命令也可以用来找命令,例如找bpagan 命令 indit bpagan 或 search bpagan, all 二、scalar 标量 scalar a=2 //赋予标量a的值为2 dis a+2 //a+2=2+2=4 scalar b=a+3 //b=a+3=2+3=5 di b //结果窗口显示出:5 scalar s=”hello”//标量也可以为字符型 di s //结果窗口显示出: hello 三、异方差的纠正——WLS(weighted least square estimator) (1)基本思路: reg y x1 x2 x3 [aw=x1](将x1作为异方差的来源,对方程进行修正) 上式相当于: reg y/(x1^0.5) 1/(x1^0.5) x1/(x1^0.5) x2/(x1^0.5) x3/(x1^0.5),noconstant (2)纠正异方差的常用套路(构造h值) reg y x1 x2 x3 predict u,resid gen usq=u^2 gen logusq=log(usq) reg logusq x1 x2 x3 predict g gen h=exp(g) reg y x1 x2 x3 [aw=1/h] 异方差hausman检验: reg y x1 x2 x3 est store A(将上述回归结果储存到A中) reg y x1 x2 x3 [aw=1/h] est store B hausman A B 当因变量为对数形式时(log(y))如何预测y reg logy x1 x2 x3 predict k gen m=exp(k) reg y m,noconstant m的系数为i y的预测值=i×exp(k) 四、stata 生成虚拟变量 生成虚拟变量