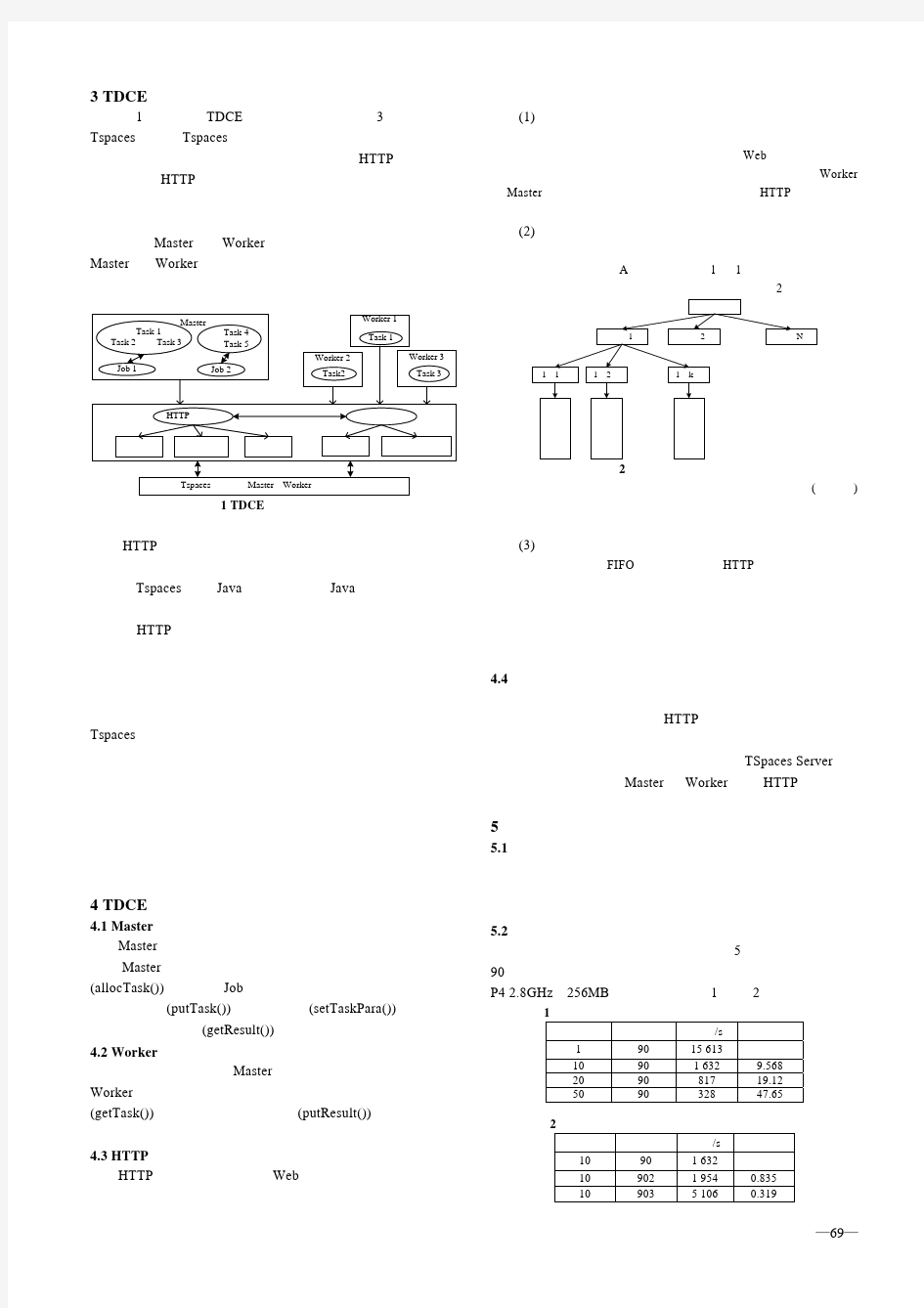
TDCE基于Tspaces的分布并行计算系统

并行计算综述
并行计算综述 姓名:尹航学号:S131020012 专业:计算机科学与技术摘要:本文对并行计算的基本概念和基本理论进行了分析和研究。主要内容有:并行计算提出的背景,目前国内外的研究现状,并行计算概念和并行计算机类型,并行计算的性能评价,并行计算模型,并行编程环境与并行编程语言。 关键词:并行计算;性能评价;并行计算模型;并行编程 1. 前言 网络并行计算是近几年国际上并行计算新出现的一个重要研究方向,也是热门课题。网络并行计算就是利用互联网上的计算机资源实现其它问题的计算,这种并行计算环境的显著优点是投资少、见效快、灵活性强等。由于科学计算的要求,越来越多的用户希望能具有并行计算的环境,但除了少数计算机大户(石油、天气预报等)外,很多用户由于工业资金的不足而不能使用并行计算机。一旦实现并行计算,就可以通过网络实现超级计算。这样,就不必要购买昂贵的并行计算机。 目前,国内一般的应用单位都具有局域网或广域网的结点,基本上具备网络计算的硬件环境。其次,网络并行计算的系统软件PVM是当前国际上公认的一种消息传递标准软件系统。有了该软件系统,可以在不具备并行机的情况下进行并行计算。该软件是美国国家基金资助的开放软件,没有版权问题。可以从国际互联网上获得其源代码及其相应的辅助工具程序。这无疑给人们对计算大问题带来了良好的机遇。这种计算环境特别适合我国国情。 近几年国内一些高校和科研院所投入了一些力量来进行并行计算软件的应用理论和方法的研究,并取得了可喜的成绩。到目前为止,网络并行计算已经在勘探地球物理、机械制造、计算数学、石油资源、数字模拟等许多应用领域开展研究。这将在计算机的应用的各应用领域科学开创一个崭新的环境。 2. 并行计算简介[1] 2.1并行计算与科学计算 并行计算(Parallel Computing),简单地讲,就是在并行计算机上所作的计算,它和常说的高性能计算(High Performance Computing)、超级计算(Super Computing)是同义词,因为任何高性能计算和超级计算都离不开并行技术。
LSF高性能分布运算解决方案
LSF高性能分布运算解决方案 一、系统组成 速度系统主要由IBM X3850 X5集群计算机、IBM X3650 M3 虚拟化服务器、Dell R5100图形工作站、存储系统组成。 IBM X3850 X5集群计算机:每个节点 4 颗CPU,每个 CPU 8核,主频 2.26GHz,节点内存 128GB。 IBM X3650 M3虚拟化服务器:每个节点 2 个 CPU,每个 CPU4核,主频 2.66GHz,节点内存 48GB。 Dell R5100图形工作站:每个节点包括 1个NVIDIA Quadro 6000 显示卡,主机CPU 主频为3.06 GHz,内存为 8GB,硬盘为 4*146GB。 存储系统:IBM DS5020 可用容量约为 12TB,由集群计算机、虚拟化服务器和图形工作站共享。 IBM X3850 X5计算集群运行用户的程序。 LSF高性能分布运算解决方案系统示意图 二、主要软件
1.操作系统:IBM X3850 X5集群计算机安装 64 位Windows2008 系统,IBM X3650 M3 安装Vmware ESX4.1系统,图形工作站安装64 位Windows2008 系统。 2.作业调度系统:Platform 公司的LSF。 3.应用软件:如表 1 所示。 名称厂家 LightTools ORA ZEMAX-EE Focus Software PADS ES Suite Ap SW Mentor Graphics Expedition PCB Pinnacle Mentor Graphics DxDesigner ExpPCB Bnd SW Mentor Graphics I/O Designer Ap SW Mentor Graphics Multi-FPGA Optimization Op S Mentor Graphics HyperLynx SI PI Bnd SW Mentor Graphics Questa Core VLOG Ap SW Mentor Graphics Precision RTL Plus Ap SW Mentor Graphics SystemVision 150 Ap SW Mentor Graphics FlowTHERM Parallel Ap SW Mentor Graphics Labview NI Code Composer Studio TI Quartus II Altera ISE Xilinx Vxworks Wind River Intel C++ Studio XE Intel MatLab及相关工具箱Mathworks Maple MapleSoft Oracle Oracle NX Mach 3 Product Design Siemens PLM Software ADAMS MSC
大数据与并行计算
西安科技大学 计算机科学与技术学院 实习报告 课程:大数据和并行计算 班级:网络工程 姓名: 学号:
前言 大数据技术(big data),或称巨量资料,指的是所涉及的资料量规模巨大到无法通过目前主流软件工具,在合理时间内达到撷取、管理、处理、并整理成为帮助企业经营决策更积极目的的资讯。在维克托·迈尔-舍恩伯格及肯尼斯·库克耶编写的《大数据时代》中大数据指不用随机分析法(抽样调查)这样的捷径,而采用所有数据进行分析处理。大数据的4V特点:Volume(大量)、Velocity(高速)、Variety(多样)、Value(价值)。 特点具体有: 大数据分析相比于传统的数据仓库应用,具有数据量大、查询分析复杂等特点。《计算机学报》刊登的“架构大数据:挑战、现状与展望”一文列举了大数据分析平台需要具备的几个重要特性,对当前的主流实现平台——并行数据库、MapReduce及基于两者的混合架构进行了分析归纳,指出了各自的优势及不足,同时也对各个方向的研究现状及作者在大数据分析方面的努力进行了介绍,对未来研究做了展望。 大数据的4个“V”,或者说特点有四个层面:第一,数据体量巨大。从TB级别,跃升到PB级别;第二,数据类型繁多。前文提到的网络日志、视频、图片、地理位置信息等等。第三,处理速度快,1秒定律,可从各种类型的数据中快速获得高价值的信息,这一点也是和传统的数据挖掘技术有着本质的不同。第四,只要合理利用数据并对其进行正确、准确的分析,将会带来很高的价值回报。业界将其归纳为4个“V”——Volume(数据体量大)、Variety(数据类型繁多)、Velocity(处理速度快)、Value(价值密度低)。 从某种程度上说,大数据是数据分析的前沿技术。简言之,从各种各样类型的数据中,快速获得有价值信息的能力,就是大数据技术。明白这一点至关重要,也正是这一点促使该技术具备走向众多企业的潜力。 1.大数据概念及分析 毫无疑问,世界上所有关注开发技术的人都意识到“大数据”对企业商务所蕴含的潜在价值,其目的都在于解决在企业发展过程中各种业务数据增长所带来的痛苦。 现实是,许多问题阻碍了大数据技术的发展和实际应用。 因为一种成功的技术,需要一些衡量的标准。现在我们可以通过几个基本要素来衡量一下大数据技术,这就是——流处理、并行性、摘要索引和可视化。 大数据技术涵盖哪些内容? 1.1流处理 伴随着业务发展的步调,以及业务流程的复杂化,我们的注意力越来越集中在“数据流”而非“数据集”上面。 决策者感兴趣的是紧扣其组织机构的命脉,并获取实时的结果。他们需要的是能够处理随时发生的数据流的架构,当前的数据库技术并不适合数据流处理。 1.2并行化 大数据的定义有许多种,以下这种相对有用。“小数据”的情形类似于桌面环境,磁盘存储能力在1GB到10GB之间,“中数据”的数据量在100GB到1TB之间,“大数据”分布式的存储在多台机器上,包含1TB到多个PB的数据。 如果你在分布式数据环境中工作,并且想在很短的时间内处理数据,这就需要分布式处理。 1.3摘要索引 摘要索引是一个对数据创建预计算摘要,以加速查询运行的过程。摘要索引的问题是,你必须为要执行的查询做好计划,因此它有所限制。 数据增长飞速,对摘要索引的要求远不会停止,不论是长期考虑还是短期,供应商必须对摘要索引的制定有一个确定的策略。 1.4数据可视化 可视化工具有两大类。
并行计算-练习题
2014年《并行计算系统》复习题 (15分)给出五种并行计算机体系结构的名称,并分别画出其典型结构。 ①并行向量处理机(PVP) ②对称多机系统(SMP) ③大规模并行处理机(MPP) ④分布式共享存储器多机系统(DSM) ⑤工作站机群(COW) (10分)给出五种典型的访存模型,并分别简要描述其特点。 ①均匀访存模型(UMA): 物理存储器被所有处理机均匀共享 所有处理机访存时间相同 适于通用的或分时的应用程序类型 ②非均匀访存模型(NUMA): 是所有处理机的本地存储器的集合 访问本地LM的访存时间较短 访问远程LM的访存时间较长 ③Cache一致性非均匀访存模型(CC-NUMA): DSM结构 ④全局Cache访存模型(COMA): 是NUMA的一种特例,是采用各处理机的Cache组成的全局地址空间 远程Cache的访问是由Cache目录支持的 ⑤非远程访存模型(NORMA): 在分布式存储器多机系统中,如果所有存储器都是专用的,而且只能被本地存储机访问,则这种访问模型称为NORAM 绝大多数的NUMA支持NORAM 在DSM中,NORAM的特性被隐匿的 3. (15分)对于如下的静态互连网络,给出其网络直径、节点的度数、对剖宽度,说明该网络是否是一个对称网络。 网络直径:8 节点的度数:2 对剖宽度:2 该网络是一个对称网络 4. (15分)设一个计算任务,在一个处理机上执行需10个小时完成,其中可并行化的部分为9个小时,不可并行化的部分为1个小时。问: (1)该程序的串行比例因子是多少,并行比例因子是多少? 串行比例因子:1/10
并行比例因子:9/10 如果有10个处理机并行执行该程序,可达到的加速比是多少? 10/(9/10 + 1) = 5.263 (3)如果有20个处理机并行执行该程序,可达到的加速比是多少? 10/(9/20 + 1)= 6.897 (15分)什么是并行计算系统的可扩放性?可放性包括哪些方面?可扩放性研究的目的是什么? 一个计算机系统(硬件、软件、算法、程序等)被称为可扩放的,是指其性能随处理机数目的增加而按比例提高。例如,工作负载能力和加速比都可随处理机的数目的增加而增加。可扩放性包括: 1.机器规模的可扩放性 系统性能是如何随着处理机数目的增加而改善的 2.问题规模的可扩放性 系统的性能是如何随着数据规模和负载规模的增加而改善 3.技术的可扩放性 系统的性能上如何随着技术的改变而改善 可扩放性研究的目的: 确定解决某类问题时何种并行算法与何种并行体系结构的组合,可以有效的利用大量的处理器; 对于运用于某种并行机上的某种算法,根据在小规模处理机的运行性能预测移植到大规模处理机上的运行性能; 对固定问题规模,确定最优处理机数和可获得的最大的加速比 (15分)给出五个基本的并行计算模型,并说明其各自的优缺点。 ①PRAM:SIMD-SM 优点: 适于表示和分析并行计算的复杂性; 隐匿了并行计算机的大部底层细节(如通信、同步),从而易于使用。 缺点: 不适于MIMD计算机,存在存储器竞争和通信延迟问题。 ②APRAM:MIMD-SM 优点: 保存了PRAM的简单性; 可编程性和可调试性(correctness)好; 易于进行程序复杂性分析。 缺点: 不适于具有分布式存储器的MIMD计算机。 ③BSP:MIMD-DM 优点: 把计算和通信分割开来; 使用hashing自动进行存储器和通信管理; 提供了一个编程环境。 缺点: 显式的同步机制限制并行计算机数据的增加; 在一个Superstep中最多只能传递h各报文。
基于FPGA的并行计算技术
基于FPGA的并行计算技术 更新于2012-03-13 17:15:57 文章出处:互联网 1 微处理器与FPGA 微处理器普遍采用冯·诺依曼结构,即存储程序型计算机结构,主要包括存储器和运算器2个子系统。其从存储器读取数据和指令到运算器,运算结果储存到存储器,然后进行下一次读取-运算-储存的操作过程。通过开发专门的数据和指令组合,即控制程序,微处理器就可以完成各种计算任务。冯·诺依曼型计算机成功地把信息处理系统分成了硬件设备和软件程序两部分,使得众多信息处理问题都可以在通用的硬件平台上处理,只需要开发具体的应用软件,从而极大地降低了开发信息处理系统的复杂性。然而,冯·诺依曼型计算机也有不足之处,由于数据和指令必须在存储器和运算器之间传输才能完成运算,使得计算速度受到存储器和运算器之间信息传输速度的限制,形成所谓的冯·诺依曼瓶颈[1];同时,由于运算任务被分解成一系列依次执行的读取-运算-储存过程,所以运算过程在本质上是串行的,使并行计算模式在冯·诺依曼型计算机上的应用受到限制。 受到半导体物理过程的限制,微处理器运算速度的提高已经趋于缓慢,基于多核处理器或者集群计算机的并行计算技术已经逐渐成为提高计算机运算性能的主要手段。并行计算设备中包含多个微处理器,可以同时对多组数据进行处理,从而提高系统的数据处理能力。基于集群计算机的超级计算机已经成为解决大型科学和工程问题的有利工具。然而,由于并行计算设备中的微处理器同样受冯·诺依曼瓶颈的制约,所以在处理一些数据密集型,如图像分析等问题时,计算速度和性价比不理想。 现场可编程门阵列(FPGA)是一种新型的数字电路。传统的数字电路芯片都具有固定的电路和功能,而FPGA可以直接下载用户现场设计的数字电路。FPGA技术颠覆了数字电路传统的设计-流片-封装的工艺过程,直接在成品PFGA芯片上开发新的数字电路,极大地扩大了专用数字电路的用户范围和应用领域。自从20世纪80年代出现以来,FPGA技术迅速发展,FPGA芯片的晶体管数量从最初的数万个迅速发展到现在的数十亿个晶体管[2],FPGA 的应用范围也从简单的逻辑控制电路发展成为重要的高性能计算平台。 FPGA芯片中的每个逻辑门在每个时钟周期都同时进行着某种逻辑运算,因此FPGA本质上是一个超大规模的并行计算设备,非常适合用于开发并行计算应用。目前,FPGA已被成功地应用到分子动力学、基因组测序、神经网路、人工大脑、图像处理、机器博弈等领域,取得了数十到数千倍的速度提高和优异的性价比[3-18]。
LBGK模型的分布式并行计算
万方数据
2LBGKD2Q9模型的并行计算 2.1数据分布 将流场划分成N。xN,的网格。设有P=只×Pv个进程参与并行计算,进程号P。=H以(0≤i<只,0≤J<尸v)。将数据按照重叠一条边的分块分布到各进程中。其中,进程P。存储并处理的数据网格点集,如图l所示。 图1进程珊存储并处理的区域(斜线处为重叠部分) 2.2交替方向的Jacobi迭代通信 Jacobi迭代是一类典型的通信迭代操作。文献[4】主要讨论了一个方向的Jacobi迭代。根据数据分布及计算要求,需要采用2个方向交替的Jacobi迭代通信操作。本文认为,“即发即收”的通信策略能有效避免完全的“先发后收”可能造成的通信数据“堆积”过多,从而避免数据的丢失。进程Pli的通信操作如下(见图2): (1)Ifi≠只一1then发送数据到进程P¨,; (2)Ifi≠0then从进程Pf_J,接收数据; (3)If,≠只-1then发送数据到进程Pml; (4)IfJ≠0then从进程P—l接收数据。 各进程并行执行上述操作。 图2交普方向的Jacobi迭代 2.3通信时间理论 由一般的通信模型可知,若发送、接收信息长度为n字节的数据所需时间为:丁(n)=口+n∥,其中,常数口为通信启动时间;∥为常系数,则上述一次交替方向的Jacobi迭代通信操作的时间约为 20e+2fl'N、.P,=1 P。=1 其他 其中,∥7=∥sizeof(double)。 一般情况下,当等3鲁,即等=鲁时,通信的数据量(字节数)是最少的,为4口+4∥,./丝堡。可见,通信的信息 V只×0 总量和通信时间随进程总数只×尸v的增加而减少。 由于c语言中数组是按“行”存放的(Fortran是按“列”存放的),当存放、发送列数据时,需要一定的辅助操作,这就增加了并行计算的计算时间,因此在只:Pv无法恰好等于Nx:N。时,需要综合考虑流场形状及大小、数据在内存中的按“行”(或按“列”)的存放方式,以确定数据的最佳分布方案。 3数值实验 数值实验是在“自强3000”计算机上进行的ou自强3000”计算机拥有174个计算结点,每个计算结点上有2个3.06CPU,2GB内存。本文的实验使用了其中的32个计算结点共64个CPU。程序采用MPI及C语言编写,程序执行时,每个计算结点中启动2个进程。数值实验针对不同规模的网格划分、不同进程数以及不同的数据分布方案进行了大量实验,测得如下结果:不同的流场规模对应着各自的最佳网格划分方式;计算次数越多,加速比越大,越能体现并行计算的优越性。 由表1数据可以得知,对于规模为Nx×N、,=400x400,数据划分成6×6块时的加速比最高,而对于MXNy=600x200,数据划分为12×3块则更具优越性。合适的划分方式可以使总体通信量减至最少,从而提高加速比和并行效率。另外,计算规模越大,加速比越大。 表1并行计算D2Q9模型的加速比(进程数为36) 在固定计算规模,增加处理器的情况下,并行系统的加速比会上升,并行效率会下降;在固定处理器数目,增加计算规模的情况下,并行系统的加速比和效率都会随之增加。 从表2可见,流场规模越大,并行计算的优越性越显著。因为此时计算规模(粒度)较大,相对于通信量占有一定的优势。由图3可见,加速比随进程数呈线性增长,这表明LBGKD2Q9模型的并行计算具有良好的可扩展性。 表2漉场规模固定时并行计算D2Q9模型的加速比 0816243240485664 numofprocess 图3藐场规模固定时D2Q9模型并行计算的加速比 4结束语 本文讨论了LBGKD2Q9模型的分布式并行计算,通过大量的数值实验重点研究了数据分布方案如何与问题规模匹配,以获得更高的并行效率的问题。展示了LBGK模型方法良好的并行性和可扩展性。得到了二维LBGK模型并行计算数据分布的一般原则、交替方向Jacobi迭代的通信策略。这些结论对进一步开展三维LBGK模型的并行计算及其他类似问题的并行计算有一定的指导意义。(下转第104页) 一101—万方数据
并行计算环境搭建
并行计算环境搭建 一.搭建并调试并行计算环境MPI的详细过程。 1.首先,我们选择在Windows XP平台下安装MPICH。第一步确保Windows平台下安装上了.net框架。 2.在并行环境的每台机子上创建相同的用户名和密码,并使该平台下的各台主机在相同的工作组中。 3.登陆到新创建的帐号下,安装MPICH软件,在选择安装路径时,每台机子的安装路径要确保一致。安装过程中,需要输入一致的passphrase,也即本机的用户名。 4.安装好软件后,要对并行环境进行配置(分为两步): 第一步:注册。在每台机器上运行wmpiregister,按照提示输入帐号和密码,即 本机的登录用户名和密码。 第二步:配置主机。在并行环境下,我们只有一台主机,其他机子作为端结点。 运行主机上的wmpiconfig,在界面左侧栏目中选择TNP工作组,点击“select”按 钮,此时主机会在网络中搜索配置好并行环境的其他机子。配置好并行环境的其他 机子会出现绿色状态,点击“apply”按钮,最后点击“OK”按钮。 5.在并行环境下运行的必须是.exe文件,所以我们必须要对并行程序进行编译并生成.exe文件。为此我们选择Visual C++6.0编译器对我们的C语言程序进行编译, 在编译过程中,主要要配置编译器环境: (1)在编译器环境下选择“工程”,在“link”选项卡的“object/library modules” 中输入mpi.lib,然后点击“OK”按钮。 (2)选择“选项”,点击“路径”选项卡,在“show directories for”下选择“Include files”,在“Directories”中输入MPICH软件中“Include”文件夹的路径; 在“show directories for”下选择“Library files”,在“Directories”中输入 MPICH软件中Library文件夹的路径,点击“OK”。 (3)对并行程序进行编译、链接,并生成.exe文件。 6.将生成的.exe文件拷贝到并行环境下的各台机子上,并确保每台机子的存放路径要相同。 7.在主机上运行“wmpiexec”,在Application中选择生成的.exe文件;输入要执行此程序的进程数,选中“more options”选项卡,在“host”栏中输入主机和各个端结 点的计算机名,点击“execute”执行程序。 二.搭建并调试并行计算环境MPI的详细过程。 1.以管理员身份登录每台计算机,在所有连接的计算机上建立一个同样的工作组,命名为Mshome,并在该工作组下建立相同的帐户,名为GM,密码为GM。 2.安装文件Microsoft NET Framwork1.1,将.NET框架安装到每台计算机上,再安装MPI到每台主机。在安装MPI的过程中,必须输入相同的passphrase,在此输 入之前已建好的帐户名GM。 3.安装好MPI后,再对每台计算机进行注册和配置,其中注册必须每台计算机都要进行,配置只在主控计算机进行: (1)注册:将先前在每台计算机上申请的帐号和密码注册到MPI中去,这样
大规模并行计算
计算机学院 课程设计 课程名称高性能计算设计 题目名称大规模并行计算 专业__ 软件工程 _ __ _ 年级班别 2012级 学号 学生姓名 指导教师 联系方式 2015年12月18日
结构化数据访问注释对于大规模并 行计算 马可aldinucci1索尼亚营,2,基尔帕特里克3,和马西莫torquati2p.kilpatrick@https://www.360docs.net/doc/8b9539220.html, 1计算机科学系,大学都灵,意大利 aldinuc@di.unito.it 2比萨大学计算机科学系,意大利 {营,torquati}@di.unipi。它 3女王大学计算机科学系,贝尔法斯特 p.kilpatrick@https://www.360docs.net/doc/8b9539220.html, 摘要。我们描述了一种方法,旨在解决的问题控制联合开发(流)和一个数据并行骨架吨并行编程环境,基于注释重构。注解驱动一个并行计算的高效实现。重构是用来改造相关联的骨架树到一个更高效,功能上相当于骨架树。在大多数情况下成本模型是用来驱动的重构过程。我们展示了如何示例用例应用程序/内核可以被优化,讨论初步的实验评估结果归属理论。 克-词:算法的骨架,并行设计模式,重构,数据并行性,成本模型。 1我新台币 结构化并行程序设计方法已抽象出概念控制和数据并行通过骨骼上的[ 10 ],这是众所周知的PA T控制[ 8 ]燕鸥。控制并行的设想,设计和实施作为一个图的节点(骨架),每个节点代表一个函数。一股流独立的任务流经图:当每个节点的输入是有效的,它可以计算产生的输出被发送到它的连接节点。在另一方面,数据并行的kelet的描述一个计算模式定义如何在并行数据中访问数据,并将其应用于数据的功能分区以获得最终结果。传统上,控制之间的正交性并行和数据并行解决了采用双层模型控制流驱动的方法进行数据的并行能力增强,可能与并行数据结构暴露出集体行动[ 13 ]反之亦然。然而,控制并行和数据并行的方法。 这项工作已经由欧盟框架7批 ist-2011-288570”释义:自适应异构多核系统的并行模式” 我caragiannis 冯湛华。(E DS。):E尿PAR 2012个车间,LNCS 7640,pp. 381–390,2013。他是cspringe r-ve rlag用IDE L B E RG 2013382米aldinucci等人。 往往缺乏有效的应用程序,在这两个问题的能力被利用,因为本质上不同的手段,通过并行表示,有时,优化。一种高效的任务分配控制驱动的环境,可我nvalidated由糟糕的数据访问策略,反之亦然[ 14 ]。 在本文中,我们勾勒出一个新的方法来面对的控制与基于数据并行二分法的思想,即:数据与控制并行关注需要独立表达因为他们描述正交方面的并行性,和II)的数据访问和控制的并行模式的需要becoordin ED为了有效地支持并行应用的实现。虽然利用并行模式是不是一个新的方法[ 11 ]和协调工作在过去的语言方面作出了努力[ 17,12 ]或框架,本文提出的想法是,这样的协调可以通过对控制定义的图形表示关于数据访问的骨架。此外,我们将展示如何这样的注释可以用来驱动优化的实施图的执行。 2他骨骼框架 考虑骨骼系统包括控制(即流)和数据并行骨架,造型更一般的并行开发模式。我们的骨架是由下面的语法定义的 这些骷髅代表著名的并行开发模式[ 4 ]:序列把现有的序列码,管/农场流并行骨架处理流项
联想网御的多核并行计算网络安全平台
龙源期刊网 https://www.360docs.net/doc/8b9539220.html, 联想网御的多核并行计算网络安全平台 作者:李江力王智民 来源:《中国计算机报》2008年第44期 随着网络带宽的不断发展,网络如何安全、高效地运行逐渐成为人们关注的焦点。上期文章《多核技术开创万兆时代》指出,经过多年不断的努力探索,在历经了高主频CPU、FPGA、ASIC、NP后,我们迎来了多核时代。是不是有了多核,就能够满足当前人们对网络安全处理能力的需求呢?答案也许并非那么简单。 本文将从多核处理器带来的机遇与挑战、多核编程的困境、联想网御的解决方案三个方面来详细阐述多核并行计算相关的技术问题。 多核处理器带来机遇与挑战 通常我们所说的多核处理器是指CMP(ChipMulti-processors)的芯片结构。CMP是由美国斯坦福大学提出的,其思想是将大规模并行处理器中的SMP(Symmetric Multi-processors,对称多处理器)集成到同一芯片内,各个处理器并行执行,在同一个时刻同时有多条指令在执行。 多核处理器的出现使得人们从以前的单纯靠提高CPU主频的“死胡同”走了出来,同时又使得软件开发人员能够采用高级语言进行编程,看似是一个比较完美的技术方案,但同时我们也应该看到多核处理器也给业界带来了一系列的挑战。 同构与异构 CMP的构成分成同构和异构两类,同构是指内部核的结构是相同的,而异构是指内部的核结构是不同的。核内是同构还是异构,对不同的应用,带来的性能影响是不同的。 核间通信 多核处理器各个核之间通信是必然的事情,高效的核间通信机制将是多核处理器性能的重要保障。目前主流的芯片内部高效通信机制有两种,一种是基于总线共享的Cache结构,一种是基于片上的互连结构。采用第一种还是第二种,也是设计多核处理器的时候必须考虑的问题。 并行编程
并行计算在信息安全中的应用介绍
并行计算在信息安全中的应用介绍 目前,并行计算的应用已经是十分广泛,涉及数学,物理,生物,化学,环境科学等各个学科。高性能并行计算及其应用的重要内容涉及一些经典问题的并行算法研究,如网络与排序算法、图论算法、互联网络及其路由算法、VLS布局算法等,也涉及遗传算法、基因测序、量子计算、素性检验等等。并行计算在计算机、物理和数学等方面的研究也推动了信息安全学科的发展。并行计算在信息安全方面的应用主要在于密码学方面。而随着量子物理学的发展,又产生了一个全新的事物:量子计算机。 在数学家香农(Claude E.Shanon)创立的信息论中,用严格的数学方法证明了这么一个结论:一切密码算法,除了一次一密以外,在理论上都是可以破解的。这些密码算法,包括现在的和过去的,已知的和未知的,不管它多么复杂、多么先进,只要有足够强大的计算机,有足够多的密文,一定可以破译。通过设计有效算法利用并行计算来破译密码,是密码学研究的一个方面,通过这种研究可以进一步推动密码学的发展。那么有没有一个超越数学的方法来研究密码呢? 物理学从经典物理学发展到相对论,又发展到量子物理学,每一步都使我们对世界有更深刻的理解,并带来新的技术进步。在信息安全方面,量子物理学以意想不到的方式带来了全新的思路和技术。 量子物理技术在密码学上的应用分为两类:一是利用量子计算机对传统密码体制的分析;二是利用单光子的测不准原理实现通讯过程中的信息保密,即量子密码学。 量子计算机是一种传统意义上的极大规模并行计算系统,利用量子计算机可以在几秒钟内分解RSA 129的公钥,而传统计算机需要数月时间。与经典计算机相比,量子计算机最重要的优越性体现在量子并行计算上。因为量子并行处理,一些利用经典计算机只存在指数时间算法的问题,利用量子计算机却存在多项式时间算法。这方面最著名的一个例子当推Shor在1994年给出的关于大数因子分解的量子多项式算法。 大数的因子分解是数学中的一个传统难题,现在人们普遍相信,对于经典计算机,大数因子分解不存在有效的多项式时间算法。这一结果在密码学中有重要应用,著名的RSA算法的安全性就基于大数因子分解。但Shor却证明,利用量子计算机,可以在多项式时间内将大数分解,这一结果向RSA公钥系统的安全性提出了严重挑战。 不过,量子计算机的实验方案还很初步。现在的实验只制备出单个的量子逻辑门,远未达到实现计算所需要的逻辑门网络。但是,总体来讲,实现量子计算,已经不存在原则性的困难。按照现在的发展速度,可以比较肯定地预计,在不远的将来,量子计算机一定会成为现实,虽然这中间还会有一段艰难而曲折的道路。 量子计算机有如此强大的计算功能,可以想象在不久的将来,各种密码算法都能够被轻易的破解出来。 而量子计算机对传统密码技术带来严重挑战的同时,也带来了全新的量子密码技术。
分布并行计算技术
Hadoop部署 所需要的软件 使用VMwareWorkstationPro搭建虚拟机,安装操作系统 Ubuntu14.04。 JDK1.8 Hadoop2.6.0 1.在Ubuntu中安装JDK 将JDK解压缩到 /home/kluas/java 在~/.bash_profile中配置环境变量,并通过source~/.bash_profile生效。 #java export JAVA_HOME=/home/kluas/java/jdk export JRE_HOME=/home/kluas/java/jdk/jre export PATH=$JAVA_HOME/bin;$JRE_HOME/bin:$PATH export CLASSPATH=$JAVA_HOME/lib:$JRE_HOME/lib:$CLASSPATH 检验JDK是否安装成功 java –version 2.配置ssh信任关系,实现无密码登录 生成机器A的公私密钥对:ssh-keygen -t rsa,之后一路回车。在~/.ssh 目录下生成公钥id_rsa.pub,私钥id_ras。 拷贝机器A的id_rsa.pub到机器B的认证文件中: cat id_rsa.pub >> ~/.ssh/authorized_keys 这时候机器A到机器B的信任关系就建立好了,此时在机器A可以不需要密码直接ssh登录机器B了 3.安装Hadoop2.6.0 解压hadoop软件包,编辑/etc/profile文件,并追加 export HADOOP_HOME=/usr/kluas/Hadoop export PATH=HADOOP_HOME/bin:$PATH 运行 source /etc/profile命令 修改配置文件hadoop目录etc/Hadoop/Hadoop-env.sh追加: export JAVA_HOME=/home/kluas/java/jdk 修改配置文件hadoop目录下etc/Hadoop/core-site.xml追加:
并行计算大纲
附件二: 成都信息工程学院 硕士研究生课程教学大纲 课程名称(中):并行计算 课程名称(英):Parallel Computing 课程编号: 开课单位:软件工程系 预修课程:C语言,Linux操作系统 适用专业:计算机,电子类,大气类1年级研究生 课程性质:学位课 学时:32学时 学分:2学分 考核方式:考试 一、教学目的与要求(说明本课程同专业培养目标、研究方向、培养要求的关 系,及与前后相关课程的联系) 通过本课程的学习,使学生可以对并行程序设计有一个具体的基本的概念,对MPI有比较全面的了解,掌握MPI的基本功能,并且可以编写基本的MPI程序,可以用MPI来解决实际的比较基本的并行计算问题。具体如下: 从内容上,使学生了解并行计算的基本发展过程及现在的发展水平,掌握并行系统的组织结构,并行机群系统的构建方法。掌握MPI并行编程知识,了解并行技术的遗传算法迭代算法中的应用,了解并行监控系统的构成。 从能力方面,要求学生掌握并行机群系统的实际配置方法,能用MPI编制一般难度的并行算法程序并在机群系统上实现。 从教学方法上,采用启发、引导的教学方法,结合多媒体教学方式,提高学生学习兴趣。 二、课程内容简介 本课程以并行计算为主题,对并行计算技术的发展,应用以及并行计算机模型进行概述,与此同时系统介绍了MPI并行编程环境的使用与搭建,旨在帮助学生完成简单的并行程序设计,掌握并行计算平台的搭建,为深入学习并行计算技术打下坚实的基础。
三、主要章节和学时分(含相应章节内容的教学方式,如理论教学、实验教学、 上机、自学、综述文献等) 主要章节章节主要内容简述教学方式学时备注 第1章并行计算的发展及应用1.并行计算技术的发展过 程 2.并行系统在现代技术中 的应用 理论教学2学时 第2章并行计算机系统与结构1、典型并行计算机系统简 介 2、当代并行计算机体系结 构 理论教学2学时 第3章 PC机群系统的搭建1、机群系统概述 2、机群系统的搭建方法 3、机群系统的性能测试方 法 理论教学4学时 第4章机群系统的MPI编程1、MPI语言概述 2、MPI的六个基本函数 3、MPI的消息 4、点对点通讯 5、群集通讯 6、MPI的扩展 理论教学8学时 第5章实践环节上机完成并行机群系统的 配置。 实现简单并行计算程序的 编写。上机16学 时 (此页可附页) 四、采用教材(正式出版教材要求注明教材名称、作者姓名、出版社、出版时间;自编教材要求注明是否成册、编写者姓名、编写者职称、字数等) 《并行计算应用及实战》机械工业出版社王鹏主编 2008
高性能并行计算系统检查点技术与应用
高性能并行计算系统检查点技术与应用 孙国忠 李艳红 樊建平 (中国科学院计算技术研究所 中国科学院研究生院 北京 100080) (sgz@https://www.360docs.net/doc/8b9539220.html,,lyh@https://www.360docs.net/doc/8b9539220.html,,fan@https://www.360docs.net/doc/8b9539220.html,) 摘 要 随着高性能并行计算系统规模越来越大,软件和硬件发生故障的概率随之增大,系统的容错性和可靠性已经成为应用可扩展性的主要限制因素。并行检查点技术可以使系统从故障中恢复并减少计算损失,是高性能计算系统重要的容错手段。本文将介绍检查点技术的背景和定义,研究并行检查点协议的分类,检查点存储技术,以及利用这些协议和技术实现的MPI并行检查点系统,最后给出对各个关键技术的详细评价及结论。 关键词 高性能计算;消息传递系统;并行检查点;回滚恢复 中图法分类号 TP31 A Survey of Checkpointing Technology and It’s Application for High Performance Parallel Systems Sun Guo-Zhong Li Yan-Hong Fan Jian-Ping (Institute of Computing Technology,Chinese Academy of Sciences/Graduate School of the Chinese Academy of Sciences, Beijing 100080) (sgz@https://www.360docs.net/doc/8b9539220.html, lyh@https://www.360docs.net/doc/8b9539220.html, fan@ict.ac.cn) Abstract With the scale of high performance parallel computing systems becoming larger,the fault probability of software and hardware in these systems is increased.As a result, issues of fault tolerance and reliability are becoming limiting factors on application scalability.Parallel checkpointing can help fault system recover from fault and reduce the computing losing,and is an important method for tolerating fault of high performance computing system.This paper will discuss the background and definitions of checkpointing,classify of parallel checkpointing protocols, checkpoint storage technology, and several MPI systems adopting these parallel checkpointing protocols.At last we give appraisement of these key technologies and list our conclusions. Key words High Performance Computing; Message Passing System; Parallel Checkpointing ; Rollback Recovery 1 引 言 高性能并行计算领域的容错技术由于以下几种情况而越发受到重视。1)在一台高性能计算机系统中,总的处理器数快速增长。如BlueGene/L 总的处理器有130,000个,有证据表明这样的一台机器几个小时就要有一个处理器失效。虽然处理器总数的提高带来了性能提高,但是也提高了故障点的数目。2)大多数并行计算机系统正在从采用昂贵的硬件系统向低成本、由处理器和光纤网络定制组装的cluster转变,以及采用Internet范围内网格技术来执行程序导致硬件发生故障的概率较高。3)很多科学计算任务被设计成一次运行几天或者几个月,例如ASCI的stockpile certification 程序以及BlueGene当中的ab initio 蛋白质折叠程序将运行几个月。由于应用的运行时间比硬件的平均故障间隔时间(MTBF)长,科学计算程序必须 本课题得到国家高科技发展计划(863)基金支持(2003AA1Z2070)和中国科学院知识创新工程支持(20036040) 具有对硬件故障的容错技术。采用检查点技术恢复应用运行是一种有效的容错方法。 检查点技术除了实现系统容错,还能协助实现灵活的作业调度。例如,拥有高性能计算系统的气象局要在每天的固定时段加载资源独占作业进行气象预报或者运行紧急作业,需要暂停原来运行的其它作业。因此必须记录原来作业的检查点并在完成紧急作业后恢复运行。 可见,采用检查点技术可以实现系统容错,实现灵活的作业调度以及提高资源利用率。本文将通过对各种并行检查点技术的分析比较,呈现出高性能并行计算系统检查点机制的发展状况,存在的问题和研究前景。 2背景和定义 检查点技术在各个领域都进行了广泛研究,如硬件级指令重试、分布式共享内存系统、系统调试、实时系统等。本文侧重于高性能并行计算系统,主要包括MPP、Cluster。这些系统的进程之间通过消息传递实现通信,本文中也称为消息传
并行计算综述
什么是并行计算 并行计算(parallel computing)是指,在并行机上,将一个应用分解成多个子任务,分配给不同的处理器,各个处理器之间相互协同,并行地执行子任务,从而达到加速求解速度,或者增大求解应用问题规模的目的。 由此,为了成功开展并行计算,必须具备三个基本条件: (1) 并行机。并行机至少包含两台或两台以上处理机,这些处理机通过互连网络相互连接,相互通信。 (2) 应用问题必须具有并行度。也就是说,应用可以分解为多个子任务,这些子任务可以并行地执行。将一个应用分解为多个子任务的过程,称为并行算法的设计。 (3) 并行编程。在并行机提供的并行编程环境上,具体实现并行算法,编制并行程序,并运行该程序,从而达到并行求解应用问题的目的。 并行计算的主要研究目标和内容 对于具体的应用问题,采用并行计算技术的主要目的在于两个方面: (1) 加速求解问题的速度。 (2) 提高求解问题的规模。 组成并行机的三个要素为: ?结点(node)。每个结点由多个处理器构成,可以直接输入输出(I/O)。?互联网络(interconnect network)。所有结点通过互联网络相互连接相互通
信。 ?内存(memory)。内存由多个存储模块组成,这些模块可以与结点对称地分布在互联网络的两侧,或者位于各个结点的内部。 并行编程模型 1.共享内存模型 a)在共享编程模型中,任务间共享统一的可以异步读写的地址空间。 b)共享内存的访问控制机制可能使用锁或信号量。 c)这个模型的优点是对于程序员来说数据没有身份的区分,不需要特别清楚任务间的单数据通信。程序开发也相应的得以简化。 d)在性能上有个很突出的缺点是很难理解和管理数据的本地性问题。 2.线程模型 在并行编程的线程模型中,单个处理器可以有多个并行的执行路径。 3.消息传递模型 消息传递模型有以下三个特征: 1)计算时任务集可以用他们自己的内存。多任务可以在相同的物理处理器上,同时可以访问任意数量的处理器。 2)任务之间通过接收和发送消息来进行数据通信。 3)数据传输通常需要每个处理器协调操作来完成。例如,发送操作有一个接受操作来配合。 4.数据并行模型 数据并行模型有以下特性: 并行工作主要是操纵数据集。数据集一般都是像数组一样典型的通用的数据结构。 任务集都使用相同的数据结构,但是,每个任务都有自己的数据。 每个任务的工作都是相同的,例如,给每个数组元素加4。 在共享内存体系结构上,所有的任务都是在全局存储空间中访问数据。在分布式存储体系结构上数据都是从任务的本地存储空间中分离出来的。
并行计算(陈国良版)课后答案
第三章互连网络 对于一颗K级二叉树(根为0级,叶为k-1级),共有N=2^k-1个节点,当推广至m-元树时(即每个非叶节点有m个子节点)时,试写出总节点数N的表达式。 答: 推广至M元树时,k级M元树总结点数N的表达式为: N=1+m^1+m^2+...+m^(k-1)=(1-m^k)*1/(1-m); 二元胖树如图所示,此时所有非根节点均有2个父节点。如果将图中的每个椭圆均视为单个节点,并且成对节点间的多条边视为一条边,则他实际上就是一个二叉树。试问:如果不管椭圆,只把小方块视为节点,则他从叶到根形成什么样的多级互联网络 答:8输入的完全混洗三级互联网络。 四元胖树如图所示,试问:每个内节点有几个子节点和几个父节点你知道那个机器使用了此种形式的胖树 答:每个内节点有4个子节点,2个父节点。CM-5使用了此类胖树结构。 试构造一个N=64的立方环网络,并将其直径和节点度与N=64的超立方比较之,你的结论是什么 答:A N=64的立方环网络,为4立方环(将4维超立方每个顶点以4面体替代得到),直径d=9,节点度n=4 B N=64的超立方网络,为六维超立方(将一个立方体分为8个小立方,以每个小立方作为简单立方体的节点,互联成6维超立方),直径d=6,节点度n=6 一个N=2^k个节点的 de Bruijin 。 。。。试问:该网络的直径和对剖宽度是多少 答:N=2^k个节点的 de Bruijin网络直径d=k 对剖宽带w=2^(k-1)
一个N=2^n个节点的洗牌交换网络如图所示。试问:此网络节点度==网络直径==网络对剖宽度== 答:N=2^n个节点的洗牌交换网络,网络节点度为=2 ,网络直径=n-1 ,网络对剖宽度=4 一个N=(k+1)2^k个节点的蝶形网络如图所示。试问:此网络节点度=网络直径=网络对剖宽度= 答:N=(k+1)2^k个节点的蝶形网络,网络节点度=4 ,网络直径=2*k ,网络对剖宽度=2^k 对于如下列举的网络技术,用体系结构描述,速率范围,电缆长度等填充下表中的各项。(提示:根据讨论的时间年限,每项可能是一个范围) 答: 如图所示,信包的片0,1,2,3要分别去向目的地A,B,C,D。此时片0占据信道CB,片1占据信道DC,片2占据信道AD,片3占据信道BA。试问: 1)这将会发生什么现象 2)如果采用X-Y选路策略,可避免上述现象吗为什么 答: 1)通路中形成环,发生死锁