最新模式识别实验报告.pdf

模式识别实验报告
模式识别实验报告
————————————————————————————————作者:————————————————————————————————日期:
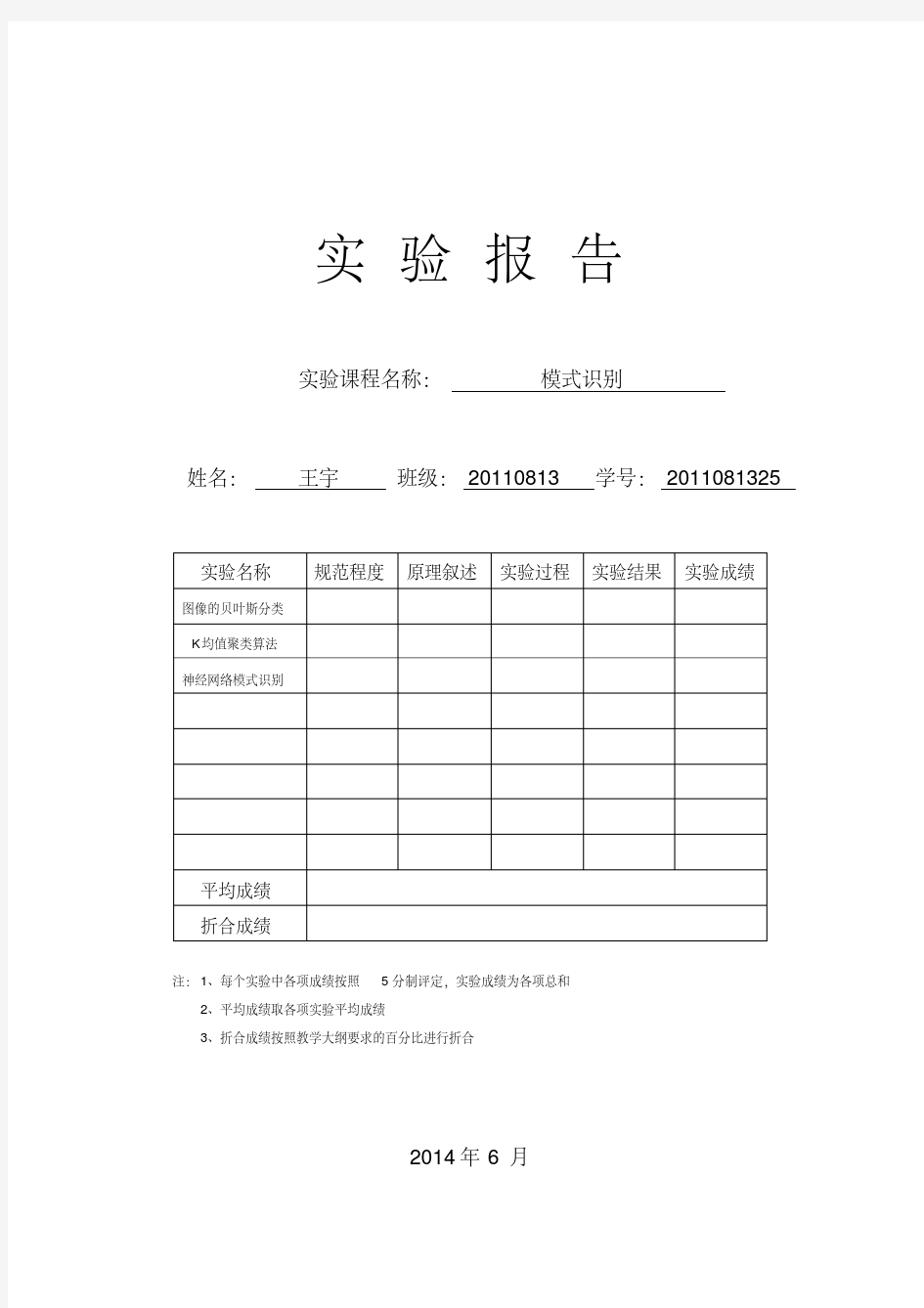
实验报告 实验课程名称:模式识别 姓名:王宇班级: 20110813 学号: 2011081325 实验名称规范程度原理叙述实验过程实验结果实验成绩 图像的贝叶斯分类 K均值聚类算法 神经网络模式识别 平均成绩 折合成绩 注:1、每个实验中各项成绩按照5分制评定,实验成绩为各项总和 2、平均成绩取各项实验平均成绩 3、折合成绩按照教学大纲要求的百分比进行折合 2014年 6月
实验一、 图像的贝叶斯分类 一、实验目的 将模式识别方法与图像处理技术相结合,掌握利用最小错分概率贝叶斯分类器进行图像分类的基本方法,通过实验加深对基本概念的理解。 二、实验仪器设备及软件 HP D538、MATLAB 三、实验原理 概念: 阈值化分割算法是计算机视觉中的常用算法,对灰度图象的阈值分割就是先确定一个处于图像灰度取值范围内的灰度阈值,然后将图像中每个像素的灰度值与这个阈值相比较。并根据比较的结果将对应的像素划分为两类,灰度值大于阈值的像素划分为一类,小于阈值的划分为另一类,等于阈值的可任意划分到两类中的任何一类。 最常用的模型可描述如下:假设图像由具有单峰灰度分布的目标和背景组成,处于目标和背景内部相邻像素间的灰度值是高度相关的,但处于目标和背景交界处两边的像素灰度值有较大差别,此时,图像的灰度直方图基本上可看作是由分别对应于目标和背景的两个单峰直方图混合构成。而且这两个分布应大小接近,且均值足够远,方差足够小,这种情况下直方图呈现较明显的双峰。类似地,如果图像中包含多个单峰灰度目标,则直方图可能呈现较明显的多峰。 上述图像模型只是理想情况,有时图像中目标和背景的灰度值有部分交错。这时如用全局阈值进行分割必然会产生一定的误差。分割误差包括将目标分为背景和将背景分为目标两大类。实际应用中应尽量减小错误分割的概率,常用的一种方法为选取最优阈值。这里所谓的最优阈值,就是指能使误分割概率最小的分割阈值。图像的直方图可以看成是对灰度值概率分布密度函数的一种近似。如一幅图像中只包含目标和背景两类灰度区域,那么直方图所代表的灰度值概率密度函数可以表示为目标和背景两类灰度值概率密度函数的加权和。如果概率密度函数形式已知,就有可能计算出使目标和背景两类误分割概率最小的最优阈值。 假设目标与背景两类像素值均服从正态分布且混有加性高斯噪声,上述分类问题可以使用模式识别中的最小错分概率贝叶斯分类器来解决。以1p 与2p 分别表示目标与背景的灰度分布概率密度函数,1P 与2P 分别表示两类的先验概率,则图像的混合概率密度函数可用下式表示为
模式识别第二次上机实验报告
北京科技大学计算机与通信工程学院 模式分类第二次上机实验报告 姓名:XXXXXX 学号:00000000 班级:电信11 时间:2014-04-16
一、实验目的 1.掌握支持向量机(SVM)的原理、核函数类型选择以及核参数选择原则等; 二、实验内容 2.准备好数据,首先要把数据转换成Libsvm软件包要求的数据格式为: label index1:value1 index2:value2 ... 其中对于分类来说label为类标识,指定数据的种类;对于回归来说label为目标值。(我主要要用到回归) Index是从1开始的自然数,value是每一维的特征值。 该过程可以自己使用excel或者编写程序来完成,也可以使用网络上的FormatDataLibsvm.xls来完成。FormatDataLibsvm.xls使用说明: 先将数据按照下列格式存放(注意label放最后面): value1 value2 label value1 value2 label 然后将以上数据粘贴到FormatDataLibsvm.xls中的最左上角单元格,接着工具->宏执行行FormatDataToLibsvm宏。就可以得到libsvm要求的数据格式。将该数据存放到文本文件中进行下一步的处理。 3.对数据进行归一化。 该过程要用到libsvm软件包中的svm-scale.exe Svm-scale用法: 用法:svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值:lower = -1,upper = 1,没有对y进行缩放)其中,-l:数据下限标记;lower:缩放后数据下限;-u:数据上限标记;upper:缩放后数据上限;-y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值;(回归需要对目标进行缩放,因此该参数可以设定为–y -1 1 )-s save_filename:表示将缩放的规则保存为文件save_filename;-r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放;filename:待缩放的数据文件(要求满足前面所述的格式)。缩放规则文件可以用文本浏览器打开,看到其格式为: y lower upper min max x lower upper index1 min1 max1 index2 min2 max2 其中的lower 与upper 与使用时所设置的lower 与upper 含义相同;index 表示特征序号;min 转换前该特征的最小值;max 转换前该特征的最大值。数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的文件重定向符号“>”将结果另存为指定的文件。该文件中的参数可用于最后面对目标值的反归一化。反归一化的公式为: (Value-lower)*(max-min)/(upper - lower)+lower 其中value为归一化后的值,其他参数与前面介绍的相同。 建议将训练数据集与测试数据集放在同一个文本文件中一起归一化,然后再将归一化结果分成训练集和测试集。 4.训练数据,生成模型。 用法:svmtrain [options] training_set_file [model_file] 其中,options(操作参数):可用的选项即表示的涵义如下所示-s svm类型:设置SVM 类型,默
模式识别论文
模式识别 课题:基于支持向量机人工神经网络的水质预测研究专业:电子信息工程
摘要 针对江水浊度序列宽频、非线性、非平稳的特点,将经验模态分解(EMD)和支持向量机(SVM)回归方法引入浊度预测领域,建立了基于EMD2SVM的浊度预测模型.通过EMD分解,将原始非平稳的浊度序列分解为若干固有模态分量(IMF),根据各IMF序列的特点,选择不同的参数对各IMF序列进行预测,最后合成原始序列的预测值.将该方法应用于实际浊度预测,并与径向基神经网络(RBF)预测及单独支持向量机回归预测结果进行比较,仿真结果表明该方法预测精度有明显提高.水质评价实际上是一个监测数据处理与状态估计、识别的过程,提出一种基于支持向量机的方法应用于水质评价,该方法依据决策二叉树多类分类的思想,构建了基于支持向量机的水环境质量状况识别与评价模型。以长江口的实际水质监测数据为例进行了实验分析,并与单因子方法及单个BP神经网络方法进行了比较分析。实验结果表明,运用该模型对长江口的实际水质监测数据进行的综合水质评价效果较好,且具有较高的实用价值。 关键词:浊度;预测;经验模态分解;支持向量;BP神经网络 一.概述 江水浊度受地表径流、温度以及人类活动等的影响,波动明显,在不同的月份有着很大的变化,表现出非平稳、非线性的特点.对其进行分析和预测,对于河流生态评价、航运安全以及以江河水为原水的饮用
水生产具有重要的指导意义.国内外在浊度序列分析方面的研究文献较少,通常都是综合考虑各种水质参数而对浊度进行预测,采用较多的是人工神经网络等非线性模型方法[1,2].这种模型结构复杂,要求原始数据丰富,在实际操作中实现较为困难.此外,对于江水浊度这一具有宽带频谱的小样本混沌时间序列,采用单一的预测方法,将会把原始浊度序列中的各种不同特征信息同质化,势必影响其预测精度.采用经验模态分解(Empirical Mode Decomposition,EMD)将浊度序列分解后分别预测,再进行合成将可能提高其预测精度.不同于小波变换,在对信号进行经验模态分解时不需要先验基底,每一个固有模态函数(In2trinsic Mode Function,IMF)包含的频率成分不仅与采样频率有关,并且还随着信号本身的变化而变化,具有自适应性,能够把局部时间内含有的多个模态的非线性、非平稳信号分解成若干个彼此间影响甚微的基本模态分量,这些分量具有不同的尺度,从而简化系统间特征信息的干涉或耦合[3].支持向量机(Support Vector Ma2chines,SVM)是建立在统计学习理论上的一种机器学习方法,是目前针对小样本统计估计和预测学习的较好方法[4],对统计学习理论的发展起到巨大推动作用并得到广泛应用[5~8].SVM有良好的泛化能力,并解决了模型选择与欠学习、过学习问题及非线性问题,避免了局部最优解,克服了“维数灾难”,且人为设定参数少,便于使用,已成功应用于许多分类、识别和回归问题[5,6,8].根据江水浊度序列的特点,结合EMD和SVM两种方法的不同功能,本文提出了基于EMD2SVM模型的预测方法,用于江水浊度的
西交大模式识别实验报告
模式识别实验报告 姓名: 班级: 学号: 提交日期:
实验一 线性分类器的设计 一、 实验目的: 掌握模式识别的基本概念,理解线性分类器的算法原理。 二、 实验要求 (1)学习和掌握线性分类器的算法原理; (2)在MATLAB 环境下编程实现三种线性分类器并能对提供的数据进行分类; (3) 对实现的线性分类器性能进行简单的评估(例如算法使用条件,算法效率及复杂度等)。 三、 算法原理介绍 (1)判别函数:是指由x 的各个分量的线性组合而成的函数: 00g(x)w ::t x w w w =+权向量阈值权 若样本有c 类,则存在c 个判别函数,对具有0g(x)w t x w =+形式的判别函数的一个两类线性分类器来说,要求实现以下判定规则: 1 2(x)0,y (x)0,y i i g g ωω>∈?? <∈? 方程g(x)=0定义了一个判定面,它把两个类的点分开来,这个平面被称为超平面,如下图所示。
(2)广义线性判别函数 线性判别函数g(x)又可写成以下形式: 01 (x)w d i i i g w x ==+∑ 其中系数wi 是权向量w 的分量。通过加入另外的项(w 的各对分量之间的乘积),得到二次判别函数: 因为 ,不失一般性,可以假设 。这样,二次判别函数拥有更多 的系数来产生复杂的分隔面。此时g(x)=0定义的分隔面是一个二阶曲面。 若继续加入更高次的项,就可以得到多项式判别函数,这可看作对某一判别函数g(x)做级数展开,然后取其截尾逼近,此时广义线性判别函数可写成: 或: 这里y 通常被成为“增广特征向量”(augmented feature vector),类似的,a 被称为
模式识别方法简述
XXX大学 课程设计报告书 课题名称模式识别 姓名 学号 院、系、部 专业 指导教师 xxxx年 xx 月 xx日
模式识别方法简述 摘要:模式识别(Pattern Recognition)是指对表征事物或现象的各种形式的( 数值的、文字的和逻辑关系的) 信息进行处理和分析, 以对事物或现象进行描述、辨认、分类和解释的过程, 是信息科学和人工智能的重要组成部分。模式识别研究主要集中在两方面, 一是研究生物体( 包括人) 是如何感知对象的,属于认识科学的范畴, 二是在给定的任务下, 如何用计算机实现模式识别的理论和方法。前者是生理学家、心理学家、生物学家和神经生理学家的研究内容, 后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力, 已经取得了系统的研究成果。 关键词:模式识别; 模式识别方法; 统计模式识别; 模板匹配; 神经网络模式识别 模式识别(Pattern Recognition)是人类的一项基本智能,在日常生活中,人们经常在进行“模式识别”。随着2 0 世纪4 0 年代计算机的出现以及5 0 年代人工智能的兴起,人们当然也希望能用计算机来代替或扩展人类的部分脑力劳动。(计算机)模式识别在2 0 世纪6 0 年代初迅速发展并成为一门新学科。 模式识别研究主要集中在两方面, 一是研究生物体( 包括人) 是如何感知对象的,属于认识科学的范畴, 二是在给定的任务下, 如何用计算机实现模式识别的理论和方法。前者是生理学家、心理学家、生物学家和神经生理学家的研究内容, 后者通过数学家、信息学专家和计算机科学工作者近几十年来的努力, 已经取得了系统的研究成果。模式识别与统计学、心理学、语言学、计算机科学、生物学、控制论等都有关系。它与人工智能、图像处理的研究有交叉关系。例如自适应或自组织的模式识别系统包含了人工智能的学习机制;人工智能研究的景物理解、自然语言理解也包含模式识别问题。又如模式识别中的预处理和特征抽取环节应用图像处理的技术;图像处理中的图像分析也应用模式识别的技术。 模式识别是一种借助计算机对信息进行处理、判别的分类过程。判决分类在
《模式识别》实验报告
《模式识别》实验报告 一、数据生成与绘图实验 1.高斯发生器。用均值为m,协方差矩阵为S 的高斯分布生成N个l 维向量。 设置均值 T m=-1,0 ?? ??,协方差为[1,1/2;1/2,1]; 代码: m=[-1;0]; S=[1,1/2;1/2,1]; mvnrnd(m,S,8) 结果显示: ans = -0.4623 3.3678 0.8339 3.3153 -3.2588 -2.2985 -0.1378 3.0594 -0.6812 0.7876 -2.3077 -0.7085 -1.4336 0.4022 -0.6574 -0.0062 2.高斯函数计算。编写一个计算已知向量x的高斯分布(m, s)值的Matlab函数。 均值与协方差与第一题相同,因此代码如下: x=[1;1]; z=1/((2*pi)^0.5*det(S)^0.5)*exp(-0.5*(x-m)'*inv(S)*(x-m)) 显示结果: z = 0.0623 3.由高斯分布类生成数据集。编写一个Matlab 函数,生成N 个l维向量数据集,它们是基于c个本体的高斯分布(mi , si ),对应先验概率Pi ,i= 1,……,c。 M文件如下: function [X,Y] = generate_gauss_classes(m,S,P,N) [r,c]=size(m); X=[]; Y=[]; for j=1:c t=mvnrnd(m(:,j),S(:,:,j),fix(P(j)*N)); X=[X t]; Y=[Y ones(1,fix(P(j)*N))*j]; end end
调用指令如下: m1=[1;1]; m2=[12;8]; m3=[16;1]; S1=[4,0;0,4]; S2=[4,0;0,4]; S3=[4,0;0,4]; m=[m1,m2,m3]; S(:,:,1)=S1; S(:,:,2)=S2; S(:,:,3)=S3; P=[1/3,1/3,1/3]; N=10; [X,Y] = generate_gauss_classes(m,S,P,N) 二、贝叶斯决策上机实验 1.(a)由均值向量m1=[1;1],m2=[7;7],m3=[15;1],方差矩阵S 的正态分布形成三个等(先验)概率的类,再基于这三个类,生成并绘制一个N=1000 的二维向量的数据集。 (b)当类的先验概率定义为向量P =[0.6,0.3,0.1],重复(a)。 (c)仔细分析每个类向量形成的聚类的形状、向量数量的特点及分布参数的影响。 M文件代码如下: function plotData(P) m1=[1;1]; S1=[12,0;0,1]; m2=[7;7]; S2=[8,3;3,2]; m3=[15;1]; S3=[2,0;0,2]; N=1000; r1=mvnrnd(m1,S1,fix(P(1)*N)); r2=mvnrnd(m2,S2,fix(P(2)*N)); r3=mvnrnd(m3,S3,fix(P(3)*N)); figure(1); plot(r1(:,1),r1(:,2),'r.'); hold on; plot(r2(:,1),r2(:,2),'g.'); hold on; plot(r3(:,1),r3(:,2),'b.'); end (a)调用指令: P=[1/3,1/3,1/3];
模式识别人工智能论文
浅谈人工智能与模式识别的应用 一、引言 随着计算机应用范围不断的拓宽,我们对于计算机具有更加有效的感知“能力”,诸如对声音、文字、图像、温度以及震动等外界信息,这样就可以依靠计算机来对人类的生存环境进行数字化改造。但是从一般的意义上来讲,当前的计算机都无法直接感知这些信息,而只能通过人在键盘、鼠标等外设上的操作才能感知外部信息。虽然摄像仪、图文扫描仪和话筒等相关设备已经部分的解决了非电信号的转换问题,但是仍然存在着识别技术不高,不能确保计算机真正的感知所采录的究竟是什么信息。这直接使得计算机对外部世界的感知能力低下,成为计算机应用发展的瓶颈。这时,能够提高计算机外部感知能力的学科——模式识别应运而生,并得到了快速的发展,同时也成为了未来电子信息产业发展的必然趋势。 人工智能中所提到的模式识别是指采用计算机来代替人类或者是帮助人类来感知外部信息,可以说是一种对人类感知能力的一种仿真模拟。近年来电子产品中也加入了诸多此类的功能:如手机中的指纹识别解锁功能;眼球识别解锁技术;手势拍照功能亦或是机场先进的人耳识别技术等等。这些功能看起来纷繁复杂,但如果需要一个概括的话,可以说这都是模式识别技术给现代生活带来的福分。它探讨的是计算机模式识别系统的建立,通过计算机系统来模拟人类感官对外界信息的识别和感知,从而将非电信号转化为计算机可以识别的电信号。
二、人工智能和模式识别 (一)人工智能。人工智能(Artificial Intelligence),是相对与人的自然智能而言的,它是指采用人工的方法及技术,对人工智能进行模仿、延伸及扩展,进而实现“机器思维”式的人工智能。简而言之,人工智能是一门研究具有智能行为的计算模型,其最终的目的在于建立一个具有感知、推理、学习和联想,甚至是决策能力的计算机系统,快速的解决一些需要专业人才能解决的问题。从本质上来讲,人工智能是一种对人类思维及信息处理过程的模拟和仿真。 (二)模式识别。模式识别,即通过计算机采用数学的知识和方法来研究模式的自动处理及判读,实现人工智能。在这里,我们将周围的环境及客体统统都称之为“模式”,即计算机需要对其周围所有的相关信息进行识别和感知,进而进行信息的处理。在人工智能开发,即智能机器开发过程中的一个关键环节,就是采用计算机来实现模式(包括文字、声音、人物和物体等)的自动识别,其在实现智能的过程中也给人类对自身智能的认识提供了一个途径。在模式识别的过程中,信息处理实际上是机器对周围环境及客体的识别过程,是对人参与智能识别的一个仿真。相对于人而言,光学信息及声学信息是两个重要的信息识别来源和方式,它同时也是人工智能机器在模式识别过程中的两个重要途径。在市场上具有代表性的产品有:光学字符识别系统以及语音识别系统等。 在这里的模式识别,我们可以将之理解成为:根据识别对象具有特征的观察值来将其进行分类的一个过程。采用计算机来进行模式识别,是在上世纪60年代初发展起来的一门新兴学科,但同样也是未来一段实践中发展的必然方向。在生活节奏相当之快的今天人们希望电子产品可以为我们的生活提供更多的便利条件。因此在未来相当一段时间内模式识别技术依然是发展的必然趋势。
模式识别及其在图像处理中的应用
武汉理工大学 模式识别及其在图像处理中的应用 学院(系):自动化学院 课程名称:模式识别原理 专业班级:控制科学与工程1603班 任课教师:张素文 学生姓名:王红刚 2017年1月3日
模式识别及其在图像处理中的应用 摘要:随着计算机和人工智能技术的发展,模式识别在图像处理中的应用日益广泛。综述了模式识别在图像处理中特征提取、主要的识别方法(统计决策法、句法识别、模糊识别、神经网络)及其存在的问题, 并且对近年来模式识别的新进展———支持向量机与仿生模式识别做了分析和总结, 最后讨论了模式识别亟待解决的问题并对其发展进行了展望。 关键词:模式识别;图像处理;特征提取;识别方法 Pattern Recognition and Its Application in Image Processing Abstract:With the development of computer and artificial intelli-gence , pattern recognition is w idely used in the image processing in-creasingly .T he feature extraction and the main methods of pattern recognition in the image processing , w hich include statistical deci-sion, structural method , fuzzy method , artificial neural netw ork aresummarized.T he support vector and bionic pattern recognition w hich are the new developments of the pattern recognition are also analyzed .At last, the problems to be solved and development trends are discussed. Key words:pattern recognition ;image processing ;feature extrac-tion;recognition methods
模式识别实验报告
实验一Bayes 分类器设计 本实验旨在让同学对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识,理解二类分类器的设计原理。 1实验原理 最小风险贝叶斯决策可按下列步骤进行: (1)在已知)(i P ω,)(i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑== c j i i i i i P X P P X P X P 1 ) ()() ()()(ωωωωω j=1,…,x (2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑== c j j j i i X P a X a R 1 )(),()(ωω λ,i=1,2,…,a (3)对(2)中得到的a 个条件风险值)(X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的决策k a ,即 则k a 就是最小风险贝叶斯决策。 2实验内容 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=0.9; 异常状态:P (2ω)=0.1。
现有一系列待观察的细胞,其观察值为x : -3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 已知类条件概率密度曲线如下图: )|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,0.25)(2,4)试对观察的结果进 行分类。 3 实验要求 1) 用matlab 完成分类器的设计,要求程序相应语句有说明文字。 2) 根据例子画出后验概率的分布曲线以及分类的结果示意图。 3) 如果是最小风险贝叶斯决策,决策表如下:
模式识别实验报告(一二)
信息与通信工程学院 模式识别实验报告 班级: 姓名: 学号: 日期:2011年12月
实验一、Bayes 分类器设计 一、实验目的: 1.对模式识别有一个初步的理解 2.能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识 3.理解二类分类器的设计原理 二、实验条件: matlab 软件 三、实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1)在已知 ) (i P ω, ) (i X P ω,i=1,…,c 及给出待识别的X 的情况下,根据贝叶斯公式计 算出后验概率: ∑== c j i i i i i P X P P X P X P 1 ) ()() ()()(ωωωωω j=1,…,x 2)利用计算出的后验概率及决策表,按下面的公式计算出采取i a ,i=1,…,a 的条件风险 ∑== c j j j i i X P a X a R 1 )(),()(ωω λ,i=1,2,…,a 3)对(2)中得到的a 个条件风险值) (X a R i ,i=1,…,a 进行比较,找出使其条件风险最小的 决策k a ,即()() 1,min k i i a R a x R a x == 则 k a 就是最小风险贝叶斯决策。 四、实验内容 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为 正常状态:P (1ω)=; 异常状态:P (2ω)=。 现有一系列待观察的细胞,其观察值为x : 已知先验概率是的曲线如下图:
)|(1ωx p )|(2ωx p 类条件概率分布正态分布分别为(-2,)(2,4)试对观察的结果 进行分类。 五、实验步骤: 1.用matlab 完成分类器的设计,说明文字程序相应语句,子程序有调用过程。 2.根据例子画出后验概率的分布曲线以及分类的结果示意图。 3.最小风险贝叶斯决策,决策表如下: 结果,并比较两个结果。 六、实验代码 1.最小错误率贝叶斯决策 x=[ ] pw1=; pw2=; e1=-2; a1=; e2=2;a2=2; m=numel(x); %得到待测细胞个数 pw1_x=zeros(1,m); %存放对w1的后验概率矩阵 pw2_x=zeros(1,m); %存放对w2的后验概率矩阵
模式识别实验报告_2
模式识别理论与方法 课程作业实验报告 实验名称:Generating Pattern Classes 实验编号:Proj01-01 规定提交日期:2012年3月16日 实际提交日期:2012年3月13日 摘要: 在熟悉Matlab中相关产生随机数和随机向量的函数基础上,重点就多元(维)高斯分布情况进行了本次实验研究:以mvnrnd()函数为核心,由浅入深、由简到难地逐步实现了获得N 个d维c类模式集,并将任意指定的两个维数、按类分不同颜色进行二维投影绘图展示。 技术论述:
1,用矩阵表征各均值、协方差2,多维正态分布函数: 实验结果讨论:
从实验的过程和结果来看,进一步熟悉了多维高斯分布函数的性质和使用,基本达到了预期目的。 实验结果: 图形部分: 图1集合中的任意指定两个维度投影散点图形
图2集合中的任意指定两个维度投影散点图形,每类一种颜色 数据部分: Fa= 9.6483 5.5074 2.4839 5.72087.2769 4.8807 9.1065 4.1758 1.5420 6.1500 6.2567 4.1387 10.0206 3.5897 2.6956 6.1500 6.9009 4.0248 10.1862 5.2959 3.1518 5.22877.1401 3.1974 10.4976 4.9501 1.4253 5.58257.4102 4.9474 11.3841 4.5128 2.0714 5.90068.2228 4.4821 9.6409 5.43540.9810 6.2676 6.9863 4.2530 8.8512 5.2401 2.7416 6.5095 6.1853 4.8751 9.8849 5.8766 3.3881 5.7879 6.7070 6.6132 10.6845 4.8772 3.4440 6.0758 6.6633 3.5381 8.7478 3.3923 2.4628 6.1352 6.9258 3.3907
模式识别及其在图像处理中的应用
模式识别及其在图像处理中的应用 摘要:随着计算机和人工智能技术的发展,模式识别在图像处理中的应用日益广泛。综述了模式识别在图像处理中特征提取、主要的识别方法(统计决策法、句法识别、模糊识别、神经网络)及其存在的问题,并且对近年来模式识别的新进展——支持向量机与仿生模式识别做了分析和总结,最后讨论了模式识别亟待解决的问题并对其发展进行了展望。 关键词:模式识别;图像处理;特征提取;识别方法
模式识别诞生于20世纪20年代,随着计算机的出现和人工智能的发展,模式识别在60年代初迅速发展成一门学科。它所研究的理论和方法在很多学科和领域中得到广泛的重视,推动了人工智能系统的发展,扩大了计算机应用的可能性。图像处理就是模式识别方法的一个重要领域,目前广泛应用的文字识别( MNO)就是模式识别在图像处理中的一个典型应用。 1.模式识别的基本框架 模式识别在不同的文献中给出的定义不同。一般认为,模式是通过对具体的事物进行观测所得到的具有时间与空间分布的信息,模式所属的类别或同一类中模式的总体称为模式类,其中个别具体的模式往往称为样本。模式识别就是研究通过计算机自动地(或者人为进行少量干预)将待识别的模式分配到各个模式类中的技术。模式识别的基本框架如图1所示。 根据有无标准样本,模式识别可分为监督识别方法和非监督识别方法。监督识别方法是在已知训练样本所属类别的条件下设计分类器,通过该分类器对待识样本进行识别的方法。如图1,标准样本集中的样本经过预处理、选择与提取特征后设计分类器,分类器的性能与样本集的大小、分布等有关。待检样本经过预处理、选择与提取特征后进入分类器,得到分类结果或识别结果。非监督模式识别方法是在没有样本所属类别信息的情况下直接根据某种规则进行分类决策。应用于图像处理中的模式识别方法大多为有监督模式识别法,例如人脸检测、车牌识别等。无监督的模式识别方法主要用于图像分割、图像压缩、遥感图像的识别等。
北科大模式识别基础实验报告
学院:自动化学院班级: 姓名: 学号: 2014年11月
实验一 Bayes 分类器的设计 一、 实验目的: 1. 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识; 2. 理解二类分类器的设计原理。 二、 实验条件: 1. PC 微机一台和MATLAB 软件。 三、 实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1. 在已知)(i P ω,)|(i X P ω,c i ,,1 =及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑== c j j j i i i P X P P X P X P 1 ) ()|() ()|()|(ωωωωω c j ,,1 = 2. 利用计算出的后验概率及决策表,按下式计算出采取i α决策的条件风险: ∑==c j j j i i X P X R 1 ) |(),()|(ωωαλα a i ,,1 = 3. 对2中得到的a 个条件风险值)|(X R i α(a i ,,1 =)进行比较,找出使条件风险最小的决策k α,即: ) |(m i n )|(,,1X R X R k c i k αα ==, 则k α就是最小风险贝叶斯决策。 四、 实验内容: 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为: 正常状态:)(1ωP =0.9; 异常状态:)(2ωP =0.1。 现有一系列待观察的细胞,其观察值为x : -3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531
-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 )|(1ωx P )|(2ωx P 类条件概率分布正态分布分别为(-2,0.25)(2,4)。决策表为011=λ(11 λ表示 ) ,(j i ωαλ的简写),12λ=6, 21λ=1,22λ=0。 试对观察的结果进行分类。 五、 实验程序及结果: 试验程序和曲线如下,分类结果在运行后的主程序中: 实验程序: x= [-3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531 -2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 ] pw1=0.9 ;pw2=0.1 e1=-2; a1=0.5 e2=2;a2=2 m=numel(x) %得到待测细胞个数 pw1_x=zeros(1,m) %存放对w1的后验概率矩阵 pw2_x=zeros(1,m) %存放对w2的后验概率矩阵 results=zeros(1,m) %存放比较结果矩阵 for i = 1:m %计算在w1下的后验概率 pw1_x(i)=(pw1*normpdf(x(i),e1,a1))/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2)) %计算在w2下的后验概率 pw2_x(i)=(pw2*normpdf(x(i),e2,a2))/(pw1*normpdf(x(i),e1,a1)+pw2*normpdf(x(i),e2,a2)) end for i = 1:m if pw1_x(i)>pw2_x(i) %比较两类后验概率 result(i)=0 %正常细胞 else result(i)=1 %异常细胞 end end a=[-5:0.05:5] %取样本点以画图 n=numel(a) pw1_plot=zeros(1,n) pw2_plot=zeros(1,n) for j=1:n
基于支持向量机的模式识别
基于支持向量机的模式识别 摘要 随着人工智能和机器学习学科的不断发展,传统的机器学习方法已经不能适应学科的快速发展。而支持向量机(Support Vector Machine,SVM)则是根据统计学习理论提出的一种新型且有效的机器学习方法,它以结构风险最小化和VC 维理论为基础,适当的选择函数子集和决策函数,使学习机器的实际风险最小化,通过对有限的训练样本进行最小误差分类。支持向量机能够较好的解决小样本、非线性、过学习和局部最小等实际问题,同时具有较强的推广能力。支持向量机的样本训练问题实质是求解一个大的凸二次规划问题,从而所得到的解也是全局最优的,通常也是唯一的解。 本文以支持向量机理论为基础,对其在模式识别领域的应用进行系统的研究。首先运用传统的增式支持向量机对历史数据分类,该分类结果表明对于较复杂的数据辨识时效果不佳。然后运用改进后的增式支持向量机对历史数据进行分类,再利用支持向量机具有的分类优势对数据进行模式识别。 本文对传统增式支持向量机算法和改进增式支持向量机算法进行了仿真对比,仿真结果体现了改进增式支持向量机算法的优越性,改进增式支持向量机算法减少了训练样本集的样本数量,优化了时间复杂度和空间复杂度,提高了分类效率。该方法应用于模式识别领域中能明显提高系统的准确率。 关键词:支持向量机;模式识别;多类分类;增式算法
Pattern Recognition Based on Support Vector Machine Abstract With the discipline of artificial intelligence and machine learning continues to evolve, traditional machine learning methods can not adapt to the rapid development of disciplines. The support vector machine (Support Vector Machine, SVM) is based on statistical learning theory a new and effective machine learning method, which to base on the structural risk minimization and the VC dimension theory, a function subset of appropriate choice and decision-making function of appropriate choice, the learning machine to minimize the actual risk, through the limited training samples for minimum error classification. SVM can solve the small sample, nonlinear, over learning and local minimum practical issues, but also it has a strong outreach capacity. Sample training problems of Support Vector Machines to solve really a large convex quadratic programming problems, and to the global optimal solution is also obtained, usually the only solution. This paper based on support vector machine theory, its application in the field of pattern recognition system. First, by using the traditional incremental support vector machine classification of historical data, the classification results show that the data for the identification of more complex when the results are poor. And then improved by the use of incremental Support Vector Machines to classify the historical data, and then use the classification of Support Vector Machine has advantages for data pattern recognition. This type of traditional incremental Support Vector Machine and improved incremental Support Vector Machine algorithm was simulated comparison, simulation results demonstrate the improved incremental Support Vector Machine algorithm by superiority, improved incremental Support Vector Machine algorithm reduces the set of training samples number of samples,and to optimize the time complexity and space complexity, improving the classification efficiency. The method is applied to pattern recognition can significantly improve the accuracy of the system. Key words: Support Vector Machine; Pattern Recognition; Multi-class Classification; Incremental Algorithm
模式识别基础实验报告
2015年12月
实验一 Bayes 分类器的设计 一、 实验目的: 1. 对模式识别有一个初步的理解,能够根据自己的设计对贝叶斯决策理论算法有一个深刻地认识; 2. 理解二类分类器的设计原理。 二、 实验条件: 1. PC 微机一台和MATLAB 软件。 三、 实验原理: 最小风险贝叶斯决策可按下列步骤进行: 1. 在已知)(i P ω,)|(i X P ω,c i ,,1 =及给出待识别的X 的情况下,根据贝叶斯公式计算出后验概率: ∑==c j j j i i i P X P P X P X P 1)()|() ()|()|(ωωωωω c j ,,1 = 2. 利用计算出的后验概率及决策表,按下式计算出采取i α决策的条件风险: ∑==c j j j i i X P X R 1) |(),()|(ωωαλα a i ,,1 = 3. 对2中得到的a 个条件风险值)|(X R i α(a i ,,1 =)进行比较,找出使条件风险最小的决策k α,即: )|(m i n )|(,,1X R X R k c i k αα ==, 则k α就是最小风险贝叶斯决策。 四、 实验内容: 假定某个局部区域细胞识别中正常(1ω)和非正常(2ω)两类先验概率分别为: 正常状态:)(1ωP =0.9; 异常状态:)(2ωP =0.1。 现有一系列待观察的细胞,其观察值为x : -3.9847 -3.5549 -1.2401 -0.9780 -0.7932 -2.8531
-2.7605 -3.7287 -3.5414 -2.2692 -3.4549 -3.0752 -3.9934 2.8792 -0.9780 0.7932 1.1882 3.0682 -1.5799 -1.4885 -0.7431 -0.4221 -1.1186 4.2532 )|(1ωx P )|(2ωx P 类条件概率分布正态分布分别为(-2,0.25)(2,4)。决策表为011=λ(11λ表示),(j i ωαλ的简写),12λ=6, 21λ=1,22λ=0。 试对观察的结果进行分类。 五、 实验程序及结果: 试验程序和曲线如下,分类结果在运行后的主程序中: