动力学方程拟合模型(DOC)

动力学方程拟合模型
动力学方程拟合模型主要分为幂函数型模型和双曲线型模型。
在幂函数型动力学方程中,温度和浓度被认为是独立地影响反应速率的,可以表示为:
在双曲线型动力方程中强调模型方程中的吸附常数不能靠单独测定吸附性质来确定,而必须和反应速率常数一起由反应动力学实验确定。这说明模型方程中的吸附平衡常数并不是真正的吸附平衡常数,模型假设的反应机理和实际反应机理也会有相当的距离。双曲线型动力学方程的一般表达形式为
上述两类动力学模型都具有很强的拟合实验数据的能力,都既可用于均相反应体系,也可用于非均相反应体系。对气固相催化反应过程,幂函数型动力学方程可由捷姆金的非均匀表面吸附理论导出,但更常见的是将它作为一种纯经验的关联方式去拟合反应动力学的实验数据。虽然,在这种情况中幂函数型动力学方程不能提供关于反应机理的任何信息,但因为这种方程形式简单、参数数目少,通常也能足够精确地拟合实验数据,所以在非均相反应过程开发和工业反应器设计中还是得到了广泛的应用。
1.幂函数拟合
刘晓青[1]等人研究了HNO3介质中TiAP萃取Th(Ⅳ)的动力学模式和萃取动力学反应速率方程。
对于本萃取体系,由反应速率方程的一般形式可知:
可用孤立变量法求得各反应物的分反应级数a、b与c,从而确立萃取动力学方程。
第一步:分级数的求算
1.求a
固定反应物中TiAP和HNO3的浓度,
当TiAP的浓度远远大于体系中Th的初始浓
度时,可以认为体系中TiAP浓度在整个萃
取过程中没有变化而为一定値,则速率方程
可以简化为
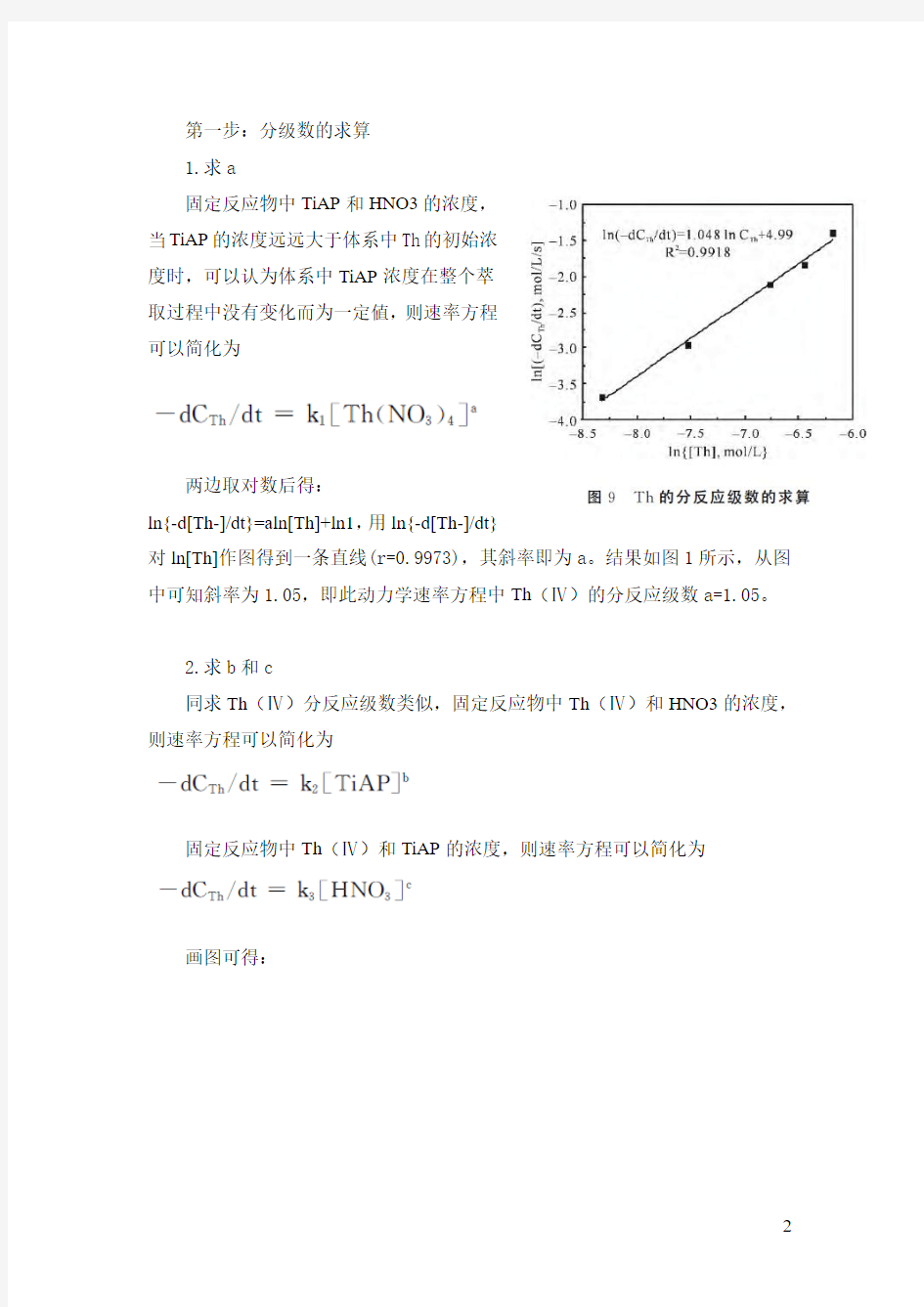
两边取对数后得:
ln{-d[Th-]/dt}=aln[Th]+ln1,用ln{-d[Th-]/dt}
对ln[Th]作图得到一条直线(r=0.9973),其斜率即为a。结果如图1所示,从图中可知斜率为1.05,即此动力学速率方程中Th(Ⅳ)的分反应级数a=1.05。
2.求b和c
同求Th(Ⅳ)分反应级数类似,固定反应物中Th(Ⅳ)和HNO3的浓度,则速率方程可以简化为
固定反应物中Th(Ⅳ)和TiAP的浓度,则速率方程可以简化为
画图可得:
TiAP的分反应级数为1.77,HNO3的分反应级数为0.38。
第二步:写出反应反应速率方程
则293K时,该反应的平均速率常数k为1.6*10-2(mol/L)-2.2·s-1。
2.双曲线拟合
双曲线型反应动力学方程是由Hinshelwood在研究气固相催化反应动力学时,根据Langmuir的均匀表面吸附理论导出的,其后Hougen和Watson用此模型成功地处理了许多气固相催化反应,使它成为一种广泛应用的方法。因此,双曲线型动力学方程又被称为Langmuir-Hin-shelwood方程或Hougen-Watson方程。
王志良[2]等人用半连续式无梯度反应器在130~210 ℃范围内研究了苯与乙烯在FX-02沸石催化剂上烷基化反应的本征动力学。应用改进的Gauss-Newton 法对常微分形式的动力学模型进行了参数估值,得到了双曲函数形式的本征动力学方程。体系的反应情况如下:
乙烯( E)、苯( B)、乙苯( EB)、二乙苯( DEB)
根据Langmuir-Hinshelwood 机理, 对上述两个反应用如下的动力学模型来表示:
序贯试验设计选用最小体积判别式( MVD ):
对ks1、ks- 1、ks2、ks- 2、KE、KB、KEB、KDEB八个参数采用改进的Gauss-Newton 法,直接对常微分形式的动力学模型进行参数估值,目标函数由最小二乘估值准则确定:
经过动力学的预试验和序贯试验后,下图给出了参数估值的相对置信区间大小与试验次数的关系。可以看出,当进行5次序贯试验后,Δ-1/2的值迅速下降, 表
明试验点的安排较合理,在有效的试验次数内使参数的估值达到了相当高的置信度。
参数估计是在序贯试验下进行的,对参数的联合置信区间检验结果证明,参数具有很高的精度。模型检验其方差分析结果表明,计算值与试验数据的相符性良好, 残差分析进一步证明模型无缺陷。
3.其他算法在动力学方程中的应用
在查找文献的时候,找到多篇与动力学有关的文献采用了不同的算法对动力学参数进行拟合估算。
3.1遗传算法
遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。黄晓峰[3]等用改进的实数编码遗传算法进行了估计反应动力学参数的研究,提出了一种优化分布线性交叉操作策略,使子代个体在搜索空间内达到均匀分布,从而提高了搜索的效率。
作者用这种改进的实数编码遗传算法进行了正丁烷选择氧化反应动力学参数的估计。正丁烷在VPO催化剂上选择氧化制顺酐,是催化晶格氧参与催化循环、按照氧化还原( RE-DOX) 机理进行的重要烃类选择氧化反应,其简化后的基元反应序列为:
R 和X 分别代表还原态和氧化态催化剂,B 为正丁烷,MA 为顺酐。
主要操作策略和控制参数为:适应度线性调整、带最优个体保存的期望值选
择, 优化分布的线性交叉操作和连续变异操作。种群数目N =50 , 交叉概率Pc =0.8 , 变异概率Pm =0.05 , 交叉系数α=2.0 。
优化问题描述为估计反应速率常数K 1 、K 2 或活化能E 1 、E 2 与指前因子k01 、k 02 , 以使反应速率的估计值rBE 与测量值rBM 的偏差平方和RSS 极小化:
最后结果如下,表现出较高的精度。
3.2蒙特卡罗法
詹晓力[4]等利用蒙特卡罗方法模拟计算了化学反应动力学参数,由基元反应确定蒙特卡罗模拟的具体做法,将蒙特卡罗方法的模拟结果与动力学实验结果进行比较,根据比较结果自动调整和优化动力学参数,从而无需事先确定动力学方程,即可有效地估算各种化学反应的动力学参数。用该方法模拟Mo-Bi 系丙烯氨氧化催化剂上的氨分解基元反应。无丙烯存在下的氨分解基元反应如下:
下图给出了用蒙特卡罗方法对该问题进行模拟的结果,m 为催化剂质量,nA0为初始氨物质的量,c R为转化率,r 为速率。从图中可见,按估算的动力学参数所计算的转化率-时间和反应速率-时间曲线与实验数据吻合得较好。
总结
化学反应的机理通常是十分复杂的。一些看起来相当简单的反应的机理至今也没有完全搞清。因此,不论是双曲线型模型还是幂函数型模型,都只是可以用来拟合反应动力学实验数据的一种函数形式。由于这两种方程在数学上的适应性极强,对同一组实验数据可同时用这两种方程拟合的例子也是屡见不鲜的。从这个意义上讲,目前工程上应用的绝大多数动力学模型都不是机理模型,在原实验范围之外作大幅度的外推都是有风险的。
参考文献
[1]刘晓青等.HNO3介质中TiAP萃取Th(Ⅳ)的动力学研究[J].四川大学学报,2014,51(6):1249-1254.
[2]王志良等.FX-02沸石催化剂上苯与乙烯烷基化的反应动力学[J].石油炼制与化工,1999,30(2):52-55.
[3]黄晓峰,潘立登,陈标华,等.用改进的实数编码遗传算法估计反应动力学参数[J].高校化学工程学报,1999,13( 1) : 50-55.
[4]詹晓力,罗正鸿,陈丰秋,等.基于Monte Carlo 模拟的化学反应动力学参数估算[J].高
等学校化学学报,2003,24( 8) : 1511-1514.
结构方程模型及其应用
結 構方程程模型型及其應 新增資 應用 資料
目錄 內容 頁數 引言 2 I. 第9.1版的改動 3 - 4 II. 章節內的新增資料 第一章 5 第三章 6 – 8 第十二章 9 – 10 第十四章 11 – 17 III. 附录內的新增資料 19 1
引言 自2005,為方便普通話及廣東話的學生,修習香港中文大學我所任教的結構方程課程,我製做了一個含有2種方言的網上課程,其後我亦將整個課程放在個人網頁(https://www.360docs.net/doc/ab6602894.html,)免費讓公眾使用。 網上課程更精簡地解釋重點,尤其是對本書最艱深的部份(第三、四章),幫助最大。學員先看綱上課程,再參考書本內容,必感事半功倍。 主要参考文獻: du Toit, S., du Toit, M., Mels, G., & Cheng, Y. (n.d.). LISREL for Windows: SIMPLIS syntax files. Lincolnwood, IL: Scientific Software International, Inc. (available https://www.360docs.net/doc/ab6602894.html,/lisrel/techdocs/SIMPLISSyntax.pdf) J?reskog, K.G. & S?rbom, D. (1999). LISREL 8: User’s Reference Guide. Lincolnwood, IL: Scientific Software International, Inc. J?reskog, K.G. & S?rbom, D. (1999). Structural Equation Modeling with the SIMPLIS Command Language. Lincolnwood, IL: Scientific Software International, Inc. Scientific Software International (SSI) (2012). LISREL 9.1 Release Notes. Lincolnwood, IL: The Author. (available from https://www.360docs.net/doc/ab6602894.html,/lisrel/LISREL_9.1_Release_Notes.pdf) 2
结构方程sem模型案例分析
结构方程SEM模型案例分析 什么是SEM模型? 结构方程模型(Structural equation modeling, SEM)是一种融合了因素分析和路径分析的多元统计技术。它的强势在于对多变量间交互关系的定量研究。在近三十年内,SEM大量的应用于社会科学及行为科学的领域里,并在近几年开始逐渐应用于市场研究中. 顾客满意度就是顾客认为产品或服务是否达到或超过他的预期的一种感受。结构方程模型(SEM)就是对顾客满意度的研究采用的模型方法之一。其目的在于探索事物间的因果关系,并将这种关系用因果模型、路径图等形式加以表述。如下图: 图: SEM模型的基本框架 在模型中包括两类变量:一类为观测变量,是可以通过访谈或其他方式调查得到的,用长方形表示;一类为结构变量,是无法直接观察的变量,又称为潜变量,用椭圆形表示。 各变量之间均存在一定的关系,这种关系是可以计算的。计算出来的值就叫参数,参数值的大小,意味着该指标对满意度的影响的大小,都是直接决定顾客购买与否的重要因素。如果能科学地测算出参数值,就可以找出影响顾客满意度的关键绩效因素,引导企业进行完善或者改进,达到快速提升顾客满意度的目的。 SEM的主要优势 第一,它可以立体、多层次的展现驱动力分析。这种多层次的因果关系更加符合真实的人类思维形式,而这是传统回归分析无法做到的。SEM根据不同属性的抽象程度将属性分成多层进行分析。 第二,SEM分析可以将无法直接测量的属性纳入分析,比方说消费者忠诚度。这样就可以将数据分析的范围加大,尤其适合一些比较抽象的归纳性的属性。 第三,SEM分析可以将各属性之间的因果关系量化,使它们能在同一个层面进行对比,同时也可以使用同一个模型对各细分市场或各竞争对手进行比较。
第二章:动力学系统的微分方程模型
第二章:动力学系统的微分方程模型 利用计算机进行仿真时,一般情况下要给出系统的数学模型,因此有必要掌握一定的建立数学模型的方法。在动力学系统中,大多数情况下可以使用微分方程来表示系统的动态特性,也可以通过微分方程可以将原来的系统简化为状态方程或者差分方程模型等。在这一章中,重点介绍建系统动态问题的微分方程的基本理论和方法。 在实际工程中,一般把系统分为两种类型,一是连续系统;其数学模型一般是高阶微分方程;另一种是离散系统,它的数学模型是差分方程。 §2.1 动力学系统统基本元件 任何机械系统都是由机械元件组成的,在机械系统中有3种类型的基本机械元件:惯性元件、弹性元件和阻尼元件。 1 惯性元件:惯性元件是指具有质量或转动惯量的元件,惯量可以定义为使加速度(或角加速度)产生单位变化所需要的力(或力矩)。 惯量(质量)= ) 加速度(力(2 /) s m N 惯量(转动惯量)= ) 角加速度(力矩(2/) s rad m N ? 2 弹性元件:它在外力或外力偶作用下可以产生变形的元件,这种元件可以通过外力做功来储存能量。按变形性质可以分为线性元件和非线性元件,通常等效成一弹簧来表示。 对于线性弹簧元件,弹簧中所受到的力与位移成正比,比例常数为弹簧刚度k 。 x k F ?= 这里k 称为弹簧刚度,x ?是弹簧相对于原长的变形量,弹性力的方向总是指向弹簧的原长位移,出了弹簧和受力之间是线性关系以外,还有所谓硬弹簧和软弹簧,它们的受力和弹簧变形之间的关系是一非线性关系。 3 阻尼元件:这种元件是以吸收能量以其它形式消耗能量,而不储存能量,可以形象的表示为一个活塞在一个充满流体介质的油缸中运动。阻尼力通常表示为: α x c R = 阻尼力的方向总是速度方向相反。当1=α,为线性阻尼模型。否则为非线性阻 尼模型。应注意当α等于偶数情况时,要将阻尼力表示为: ||1--=αx x c R 这里的“-”表示与速度方向相反
吸附动力学和热力学各模型公式及特点
吸附动力学和热力学各模型公式及特点 -CAL-FENGHAI.-(YICAI)-Company One1
分配系数 吸附量 Langmiur KL 是个常数与吸附剂结合位点的亲和力有关,该模型只对均匀表面有效 Freundlich Ce 反应达到平衡时溶液中残留溶质的浓度 KF 和n 是Freundlich 常数,其中KF 与吸附剂的吸附亲和力大小有关,n 指示吸附过程的支持力。1/n 越小吸附性能越好一般认为其在~时,吸附比较容易;大于2时,难以吸附。 应用最普遍,但是它适用于高度不均匀表面,而且仅对限制浓度范围(低浓度)的吸附数据有效 一级动力学1(1)k t t e q q e -=- 线性 二级动力学 22 21e t e k q t q k q t =+ 线性 初始吸附速度
Elovich 动力学模型 Webber-Morris动力学模型 Boyd kinetic plot 令F=Q t/Q e, K B t=(1-F) 准一级模型基于假定吸附受扩散步骤控制; 准二级动力学模型假设吸附速率由吸附剂表面未被占有的吸附空位数目的平方值决定,吸附过程受化学吸附机理的控制,这种化学吸附涉及到吸附剂与吸附质之间的电子共用或电子转移; Webber-Morris动力学模型 粒子内扩散模型中,qt与t1/2进行线性拟合,如果直线通过原点,说明颗粒内扩散是控制吸附过程的限速步骤;如果不通过原点,吸附过程受其它吸附阶段的共同控制;该模型能够描述大多数吸附过程,但是,由于吸附初期和末期物质传递的差异,试验结果往往不能完全符合拟合直线通过原点的理想情况。粒子内扩散模型最适合描述物质在颗粒内部扩散过程的动力学,而对于颗粒表面、液体膜内扩散的过程往往不适合 Elovich 方程为一经验式,描述的是包括一系列反应机制的过程,如溶质在溶液体相或界面处的扩散、表面的活化与去活化作用等,它非常适用于反应过程中活化能变化较大的过程,如土壤和沉积物界面上的过程。此外,Elovich 方程还能够揭示其他动力学方程所忽视的数据的不规则性。 Elovich和双常数模型适合于复非均相的扩散过程。 Langmuir模型假定吸附剂表面均匀,吸附质之间没有相互作用,吸附是单层吸附,即吸附只发生在吸附剂的外表面。Qm 为饱和吸附量,表示单位吸附剂表面,全部铺满单分子层吸附剂时的吸附量;该模型的假设对实验条件的变化比较敏感,一旦条件发生变化,模型参数则要作相应的改变,因此该模型只
结构方程模型的应用及分析策略
结构方程模型的应用及分析策略 侯杰泰成子娟 (香港中文大学教育学院东北师范大学教育学院,130024) 摘要:差不多所有心理、教育、社会等概念,均难以直接准确测量,结构方程(SEM,Structural Equation Modelling)提供一个处理测量误差的方法,采用多个指标去反映潜在变量,也令估计整个模型因子间关系,较传统回归方法更为准确合理。本文主要用一系列有关学习动机的虚拟例子,指出每个问题的主要分析策略,以展示SEM在教育及心理学可以应用的研究范畴。文内探讨的方法包括:验证性因素、高阶因子、路径及因果分析、多时段(multiwave)设计、单形模型(Simple Model)、及多组比较等。 关键词结构方程验证性因素分析路径及因果分析高阶因子多组比较 结构方程(SEM,Structural Equation Modelling)、协方差结构模型(Covariance Structure Modelling、LISREL)等类似名词已渐流行,并成为一种十分重要的数据分析技巧;在大学高等学位研究课程,它是多变量分析(multivariate analysis)的重要课题;比较重要的社会、教育、心理期刊,也早已特开专栏介绍(如:候,1994;Connell & Tanaka,1987;Joreskog & Sorbom,1982);可见SEM在统计学中所建立的声望及崇高地位是无容置疑的。本文主要用一系列有关学习动机的虚拟例子,来指出每个问题的主要分析策略,以展示结构方程模型在教育及心理学可以应用的研究范畴。 一、结构方程:优点及拟合概念 1.数学模式 很多社会、心理等变项,均不能准确地及直接地量度,这包括智力、社会阶层、学习动机等,我们只好退而求其次,用一些外项指标(observable indicators),去反映这些潜伏变项。例如:我们以学生父母教育程度、父母职业及其收入(共六个变项),作为学生家庭社经地位(潜伏变项)的指标,我们又以学生中、英、数三科成绩(外显变项),作为学业成就(潜伏变项)的指标。 简单来说SEM可分测量(measurement)及潜伏变项(latent variable)两部分。测量部分就是求出六个社经指标与社经地位(或三科成绩与学业成就)(即外显指标与潜伏变项之间)的关系:而潜伏变项部分则指社经地位与学业成就(即潜伏变项与潜伏变项间)的关系。 指标(外显变项)含有随机(或系统)性的量度上误差,但潜伏变项则不含这些部份。SEM可用以下矩阵方程表示(Bollen,1989;Joreskog & Sorbom,1993): η=βη+Γξ+ζ
结构方程模型案例
结构方程模型(Structural Equation Modeling,SEM) 20世纪——主流统计方法技术:因素分析回归分析 20世纪70年代:结构方程模型时代正式来临 结构方程模型是一门基于统计分析技术的研究方法学,它主要用于解决社会科学研究中的多变量问题,用来处理复杂的多变量研究数据的探究与分析。在社会科学及经济、市场、管理等研究领域,有时需处理多个原因、多个结果的关系,或者会碰到不可直接观测的变量(即潜变量),这些都是传统的统计方法不能很好解决的问题。SEM能够对抽象的概念进行估计与检定,而且能够同时进行潜在变量的估计与复杂自变量/因变量预测模型的参数估计。 结构方程模型是一种非常通用的、主要的线形统计建模技术,广泛应用于心理学、经济学、社会学、行为科学等领域的研究。实际上,它是计量经济学、计量社会学与计量心理学等领域的统计分析方法的综合。多元回归、因子分析和通径分析等方法都只是结构方程模型中的一种特例。 结构方程模型是利用联立方程组求解,它没有很严格的假定限制条件,同时允许自变量和因变量存在测量误差。在许多科学领域的研究中,有些变量并不能直接测量。实际上,这些变量基本上是人们为了理解和研究某类目的而建立的假设概念,对于它们并不存在直接测量的操作方法。人们可以找到一些可观察的变量作为这些潜在变量的“标识”,然而这些潜在变量的观察标识总是包含了大量的测量误差。在统计分析中,即使是对那些可以测量的变量,也总是不断受到测量误差问题的侵扰。自变量测量误差的发生会导致常规回归模型参数估计产生偏差。虽然传统的因子分析允许对潜在变量设立多元标识,也可处理测量误差,但是,它不能分析因子之间的关系。只有结构方程模型即能够使研究人员在分析中处理测量误差,又可分析潜在变量之间的结构关系。 简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。通过结构方程多组分析,我们可以了解不同组别内各变量的关系是否保持不变,各因子的均值是否有显著差异。” 目前,已经有多种软件可以处理SEM,包括:LISREL,AMOS, EQS, Mplus. 结构方程模型包括测量方程(LV和MV之间关系的方程,外部关系)和结构方程(LV之间关系的方程,内部关系),以ACSI模型为例,具体形式如下:
双曲线模型
双曲线型反应动力学方程是由Hinshelwood在研究气固相催化反应动力学时,根据Langmuir的均匀表面吸附理论导出的,其后Hougen和Watson用此模型成功地处理了许多气固相催化反应,使它成为一种广泛应用的方法。因此,双曲线型动力学方程又被称为Langmuir-Hin-shelwood方程或Hougen-Watson方程。 双曲线型反应动力学模型的基本假定是: ①催化剂的所有活性中心的动力学性质和热力学性质都是均一的, 吸附分子间除了对活性中心的竞争外,不存在其他相互作用。 ②吸附、反应、脱附三步骤中有一步骤是速率控制步骤,其余步骤被 认为处于平衡状态。’ ③方程中的所有参数都根据反应的实验数据确定,不独立进行吸附 常数的测定。 ④对表面反应的详细机理不作任何假设。 他们强调模型方程中的吸附常数不能靠单独测定吸附性质来确定,而必须和反应速率常数一起由反应动力学实验确定。这说明模型方程中的吸附平衡常数并不是真正的吸附平衡常数,模型假设的反应机理和实际反应机理也会有相当的距离。 双曲线型动力学方程的一般形式为: 在幂函数型动力学方程中,温度和浓度被认为是独立地影响反应速率的,所以上式可改写为: 上述两类动力学模型都具有很强的拟合实验数据的能力,都既可用于均相反应体系,也可用于非均相反应体系。对气固相催化反应过程,幂函数型动力学方程可由捷姆金的非均匀表面吸附理论导出,但更常见的是将它作为一种纯经验的关联方式去拟合反应动力学的实验数据。虽然,在这种情况中幂函数型动力学方程不能提供关于反应机理的任何信息,但因为这种方程形式简单、参数数目少,通常也能足够精确地拟合实验数据,所以在非均相反应过程开发和工业反应器设计中还是得到了广泛的应用。
《结构方程模型及其应用》
《结构方程模型及其应用》 内容简介 侯杰泰,香港中文大学教育心理系教授、系主任。主要研究方向为学习动机,应用统计和香港语文政策。曾多次在北京、上海、南京、长春、广州等地举办的地区或全国性结构方程分析研习班上讲学。 在社会、心理、教育、经济、管理、市场等研究的数据分析中,当今称得上前沿的几个统计方法中,应用最广、研究最多的恐怕非结构方程分析莫属。它包含了方差分析、回归分析、路径分析和因子分析,弥补了传统回归分析和因子分析的不足,可以分析多因多果的联系、潜变量的关系,还可以处理多水平数据和纵向数据,是非常重要的多元数据分析工具。 本书是国内第一本系统介绍结构方程模型和LISREL的著作。阐述了结构方程分析(包括验证性因子分析)的基本概念、统计原理、在社会科学研究中的应用、常用模型及其LISREL程序、输出结果的解释和模型评价。《结构方程模型及其应用》还讨论了一些与结构方程模型有关的专题,是一本由初级至中上程度的结构方程分析著作,可作为有关专业高年级本科生和研究生的教科书及应用工作者的参考书。 目录 序 第一部分结构方程模型入门 第一章引言
一、描述数据 二、具体例子展示准确与简洁的考虑 三、探索性与验证性因子分析比较 第二章结构方程模型简介 一、结构方程模型的重要性 二、结构方程模型的结构 三、结构方程模型的优点 四、结构方程模型包含的统计方法 五、路径图的图标规则 六、结构方程分析软件包 七、LISIREL操作入门 第二部分结构方程模型应用 第三章应用示范I:验证性因子分析和全模型 一、验证性因子分析 二、多质多法模型 三、全模型 四、高阶因子分析 第四章应用示范II:单纯形和多组模型 一、单纯形模型 二、多组验证性因子分析 三、多组分析:均值结构模型 四、回归模型
origin拟合准一级准二级动力学方程详解
建立用户自定义函数的步骤: 1.选择Tools: Fitting Function Organizer (快捷键F9) ,打开Fitting function 单击New Category 按钮,创建一个函数类,可以根据自己需要重命名,比如yxz.然后单击New Function,在这个类下面创建一个新的函数,然后命名,比如thepseudosecondorderkinetic 1:
2. 对该函数进行简短的描述,Brief Description栏输入:To used for the pseudo second order kinetic fitting,定义函数所需参数,ParameterNames:a,k;输入函数方程。Function 栏输入需编写的方程:y=((a^2)*k*x)/(1+a*k*x)这个方程的逻辑关系一定要对!
3.然后进行点击Function 右侧的按钮
4.编译正确是前提是:方程正确,方程中的相关参数在方程之前进行了创建,参数声明和方程建立完成之后,单击进入编译界面,单击Compile
5.当出现上图红框中文字是,证明公式定义成功,否则失败!须重新定义。 6.在file中单击save,然后单击return to dialog,再单击OK。 7.至此,用户自定义函数的建立已经完成。 二、自定义拟合函数的使用: 1先建立原文件图用点格式绘图
2.完成后点击工具栏里的Analysis----Fitting---- 3. 选择刚建立的yxz下的thepseudosecondorderkinetic 1公式。
动力学方程拟合模型DOC
动力学方程拟合模型 动力学方程拟合模型主要分为幂函数型模型和双曲线型模型。 在幂函数型动力学方程中,温度和浓度被认为是独立地影响反应速率的,可以表示为: 在双曲线型动力方程中强调模型方程中的吸附常数不能靠单独测定吸附性质来确定,而必须和反应速率常数一起由反应动力学实验确定。这说明模型方程中的吸附平衡常数并不是真正的吸附平衡常数,模型假设的反应机理和实际反应机理也会有相当的距离。双曲线型动力学方程的一般表达形式为 上述两类动力学模型都具有很强的拟合实验数据的能力,都既可用于均相反应体系,也可用于非均相反应体系。对气固相催化反应过程,幂函数型动力学方程可由捷姆金的非均匀表面吸附理论导出,但更常见的是将它作为一种纯经验的关联方式去拟合反应动力学的实验数据。虽然,在这种情况中幂函数型动力学方程不能提供关于反应机理的任何信息,但因为这种方程形式简单、参数数目少,通常也能足够精确地拟合实验数据,所以在非均相反应过程开发和工业反应器设计中还是得到了广泛的应用。 1.幂函数拟合 刘晓青[1]等人研究了HNO3介质中TiAP萃取Th(Ⅳ)的动力学模式和萃取动力学反应速率方程。 对于本萃取体系,由反应速率方程的一般形式可知: 可用孤立变量法求得各反应物的分反应级数a、b与c,从而确立萃取动力学方程。
第一步:分级数的求算 1.求a 固定反应物中TiAP和HNO3的浓度, 当TiAP的浓度远远大于体系中Th的初始浓 度时,可以认为体系中TiAP浓度在整个萃 取过程中没有变化而为一定値,则速率方程 可以简化为 两边取对数后得: ln{-d[Th-]/dt}=aln[Th]+ln1,用ln{-d[Th-]/dt} 对ln[Th]作图得到一条直线(r=0.9973),其斜率即为a。结果如图1所示,从图中可知斜率为1.05,即此动力学速率方程中Th(Ⅳ)的分反应级数a=1.05。 2.求b和c 同求Th(Ⅳ)分反应级数类似,固定反应物中Th(Ⅳ)和HNO3的浓度,则速率方程可以简化为 固定反应物中Th(Ⅳ)和TiAP的浓度,则速率方程可以简化为 画图可得:
结构方程模型案例汇总-共18页
结构方程模型( Structural Equation ,SEM) Modeling 20 世纪——主流统计方法技术:因素分析回归分析 20 世纪70 年代:结构方程模型时代正式来临结构方程模型是一门基于统计分析技术的研究方法学,它主要用于解决社会科学研究中的多变量问题,用来处理复杂的多变量研究数据的探究与分析。在社会科学及经济、市场、管理等研究领域,有时需处理多个原因、多个结果的关系,或者会碰到不可直接观测的变量(即潜变量),这些都是传统的统计方法不能很好解决的问题。SEM能够对抽象的概念进行估计与检定,而且能够同时进行潜在变量的估计与复杂自变量/ 因变量预测模型的参数估计。 结构方程模型是一种非常通用的、主要的线形统计建模技术,广泛应用于心理学、经济学、社会学、行为科学等领域的研究。实际上,它是计量经济学、计量社会学与计量心理学等领域的统计分析方法的综合。多元回归、因子分析和通径分析等方法都只是结构方程模型中的一种特例。 结构方程模型是利用联立方程组求解,它没有很严格的假定限制条件,同时允许自变量和因变量存在测量误差。在许多科学领域的研究中,有些变量并不能直接测量。实际上,这些变量基本上是人们为了理解和研究某类目的而建立的假设概念,对于它们并不存在直接测量的操作方法。人们可以找到一些可观察的变量作为这些潜在变量的“标识”,然而这些潜在变量的观察标识总是包含了大量的测量误差。在统计分析中,即使是对那些可以测量的变量,也总是不断受到测量误差问题的侵扰。自变量测量误差的发生会导致常规回归模型参数估计产生偏差。虽然传统的因子分析允许对潜在变量设立多元标识,也可处理测量误差,但是,它不能分析因子之间的关系。只有结构方程模型即能够使研究人员在分析中处理测量误差,又可分析潜在变量之间的结构关系。 简单而言,与传统的回归分析不同,结构方程分析能同时处理多个因变量,并可比较及评价不同的理论模型。与传统的探索性因子分析不同,在结构方程模型中,我们可以提出一个特定的因子结构,并检验它是否吻合数据。通过结构方程多组分析,我们可以了解不同组别内各变量的关系是否保持不变,各因子的均值是否有显著差异。” 目前,已经有多种软件可以处理SEM,包括:LISREL,AMOS, EQS, Mplus. 结构方程模型包括测量方程(LV和MV之间关系的方程,外部关系)和结构方程
动力学方程
1问题一:什么是非等温试验? 通常有等温法(也称静态法)和非等温法(也称动态法), 等温法是较早研究化学动力学时普遍采用的方法,该法的缺点在于比较费时,并且研究物质分解时,往往在升到一定的试验温度之前物质己发生初步分解,使得结果不很可靠。在非等温法中,试样温度随时间按线性变化,它在不同温度下的质量由热天平连续记录下来。非等温法是从反应开始到结束的整个温度范围内研究反应动力学,测得的一条热重曲线与不同温度下测得的多条等温失重曲线提供的数据等同,相比于等温法,非等温法只需一个微量的试验样品,消除了样品间的误差以及等温法将样品升至一定温度过程中出现的误差,并节省了试验时间。在目前的热重分析中常采用非等温法来进行动力学的研究。 问题二:文献中常用热解动力学表达式 d (a)/dt=kf(a) ——(1) a为t时刻的分解率(材料的失重百分率)又称转化率。a=(m0-m)/(m0-m∞) k=A exp(-E/RT)——(2)β=dT/dt ——(3) 采用coats-Readferm积分法推到 Ln[g(a)/T2]=ln(AR/βE)-E/RT f(a)=(1-a)2 f(a)为分饵的固体反应物与反应速率的函数关系。设Y= Ln[g(a)/T2] X=1/T 做X,Y直线曲线,求出斜率即可得到活化能E,同时得到结局求出指前因子A。 确定g(a)的值就能得到活化能E,常用g(a)的形式很多,有的是模型,有的是反应级数,总之尝试多种方法,找到最合适的,得到更精确的线性关系。 问题三: 1单条升温速率曲线的Coats-Redfern法,跟上述方程表达式一样,可得, ln[-ln( 1 -a)/T 2] = ln[AR/βE( 1-2RT/ E) ]-E/RT( n = 1) ,(4) ln[-( 1 -a)1 -n/T2( 1 -n ) ] = ln [AR/βE (1-2RT/ E) ]-E/RT( n≠1) . (5) 因为,一般活化能 E 的数值远大于温度T,所以(1?2RT/E)≈1,则式(4)和式(5)右端第1项几乎是常数。因此,可分别取n等于0.5, 0.6, 0.7, 0.8, 1.0, 1.2和1.5,结合热重实验的数据得到式(4)和式(5)的左端数值,并对1/T作图,得到这些直线的线性相关系数和标准误差数据,通过对比确定出线性较好的直线,由其斜率得到活化能E。 2,多条升温速率曲线的Flynn-Wall-Ozawa 法 Flynn-Wall-Ozawa(FWO)法通过多条升温速率曲线确定动力学参数,是等转化率法、积分法的一种。 根据式(1)(2)(3)进行移项积分得到, Logβ=log[AE/RG(a)]-2.315-0.4567E/RT 由不同升温速率βi的TG 实验数据,在同一反应深度a下,找到相应的温度Ti,则lgβi 与Ti可以拟合得到一条直线,由其斜率可以得到活化能E,并且可以得到活化能随反应深度a的变化关系。(例如excel蒙古栎的四种升温速率)
origin拟合准一年级准二年级动力学方程详解
o r i g i n拟合准一年级准二年级动力学方程详解内部编号:(YUUT-TBBY-MMUT-URRUY-UOOY-DBUYI-0128)
建立用户自定义函数的步骤:1.选择 Tools: Fitting Function Organizer (快捷键F9) ,打开 Fitting function organizer. 单击 New Category 按钮,创建一个函数类,可以根据自 己需要重命名,比如 yxz.然后单击 New Function,在这个类下面创建一个新的 函数,然后命名,比如 thepseudosecondorderkinetic 1: 2. 对该函数进行简短的描述,Brief Description栏输入:To used for the pseudo second order kinetic fitting,定义函数所需参数,ParameterNames: a,k;输入函数方程。Function 栏输入需编写的方程:y=((a^2)*k*x)/(1+a*k*x) 这个方程的逻辑关系一定要对! 3.然后进行点击Function 右侧的按钮 4.编译正确是前提是:方程正确,方程中的相关参数在方程之前进行了创建,参 数声明和方程建立完成之后,单击进入编译界面,单击Compile 5.当出现上图红框中文字是,证明公式定义成功,否则失败!须重新定义。 6.在file中单击 save,然后单击return to dialog,再单击OK。 7.至此,用户自定义函数的建立已经完成。 二、自定义拟合函数的使用: 1先建立原文件图用点格式绘图 2. 完成后点击工具栏里的Analysis----Fitting---- 3. 选择刚建立的yxz 下的thepseudosecondorderkinetic 1 公式。 4. 点击 Parameters
最新★结构方程模型要点资料
★结构方程模型要点 一、结构方程模型的模型构成 1、变量 观测变量:能够观测到的变量(路径图中以长方形表示) 潜在变量:难以直接观测到的抽象概念,由观测变量推估出来的变量(路径图中以椭圆形表示) 内生变量:模型总会受到任何一个其他变量影响的变量(因变量;路径图会受 外生变量:模型中不受任何其他变量影响但影响其他变量的变量(自变量;路 中介变量:当内生变量同时做因变量和自变量时,表示该变量不仅被其他变量影响,还可能对其他变量产生影响。 内生潜在变量:潜变量作为内生变量 内生观测变量:内生潜在变量的观测变量 外生潜在变量:潜变量作为外生变量 外生观测变量:外生潜在变量的观测变量 中介潜变量:潜变量作为中介变量 中介观测变量:中介潜在变量的观测变量 2、参数(“未知”和“估计”) 潜在变量自身:总体的平均数或方差 变量之间关系:因素载荷,路径系数,协方差 参数类型:自由参数、固定参数 自由参数:参数大小必须通过统计程序加以估计 固定参数:模型拟合过程中无须估计 (1)为潜在变量设定的测量尺度 ①将潜在变量下的各观测变量的残差项方差设置为1 ②将潜在变量下的各观测变量的因子负荷固定为1 (2)为提高模型识别度人为设定 限定参数:多样本间比较(半自由参数) 3、路径图 (1)含义:路径分析的最有用的一个工具,用图形形式表示变量之间的各种线性关系,包括直接的和间接的关系。 (2)常用记号: ①矩形框表示观测变量 ②圆或椭圆表示潜在变量 ③小的圆或椭圆,或无任何框,表示方程或测量的误差 单向箭头指向指标或观测变量,表示测量误差 单向箭头指向因子或潜在变量,表示内生变量未能被外生潜在变量解释的部分,是方程的误差 ④单向箭头连接的两个变量表示假定有因果关系,箭头由原因(外生)变量指向结果(内生)变量
使用AMOS解释结构方程模型
AMOS输出解读 惠顿研究 惠顿数据文件在各种结构方程模型中被当作经典案例,包括AMOS 和LISREL。本文以惠顿的社会疏离感追踪研究为例详细解释AMOS的输出结果。AMOS同样能处理与时间有关的自相关回归。 惠顿研究涉及三个潜变量,每个潜变量由两个观测变量确定。67疏离感由67无力感(在1967年无力感量表上的得分)和67无价值感(在1967年无价值感量表上的得分)确定。71疏离感的处理方式相同,使用1971年对应的两个量表的得分。第三个潜变量,SES(社会经济地位)是由教育(上学年数)和SEI(邓肯的社会经济指数)确定。 解读步骤 1.导入数据。 AMOS在文件ex06-a.amw中提供惠顿数据文件。使用File/Open,选择这个文件。在图形模式中,文件显示如下。虽然这里是预定义模式,图形模式允许你给变量添加椭圆,方形,箭头等元素建立新模型
2.模型识别。 潜变量的方差和与它关联的回归系数取决于变量的测量单位,但刚开始谁知道呢。比如说要估计误差的回归系数同时也估计误差的方差,就好像说“我买了10块钱的黄瓜,然后你就推测有几根黄瓜,每根黄瓜多少钱”,这是不可能实现的,因为没有足够的信息。如何告诉你“我买了10块钱的黄瓜,有5根”,你便可以推出每根黄瓜2块钱。对潜变量,必须给它们指定一个数值,要么是与潜变量有关的回归系数,要么是它的方差。对误差项的处理也是一样。一旦做完这些处理,其它系数在模型中就可以被估计。在这里我们把与误差项关联的路径设为1,再从潜变量指向观测变量的路径中选一条把它设为1。这样就给每个潜变量设置了测量尺度,如果没有这个测量尺度,模型是不确定的。有了这些约束,模型就可以识别了。 注释:设置的数值可以是1,也可以是其它数,这些数对回归系数没有影响,但对误差有影响,在标准化的情况下,误差项的路径系数平方等于它的测量方差。 3.解释模型。 模型设置完毕后,在图形模式中点击工具栏中计算估计按钮 运行分析。点击浏览文本按钮。输出如下。蓝色字体用于注解,不是AMOS输出的一部分。 Title Example6,Model A:Exploratory analysis Stability of alienation, mediated by ses.Correlations,standard deviations and means from Wheaton et al.(1977). 以上是标题,全是英文,自己翻译去吧,没有什么价值,一堆垃圾。 Notes for Group(Group number1) The model is recursive. Sample size=932
吸附动力学和热力学各模型公式及特点
分配系数 吸附量 Langmiur KL 是个常数与吸附剂结合位点的亲和力有关,该模型只对均匀表面有效 Freundlich Ce 反应达到平衡时溶液中残留溶质的浓度 KF 和n 是Freundlich 常数,其中KF 与吸附剂的吸附亲和力大小有关,n 指示吸附过程的支持力。1/n 越小吸附性能越好一般认为其在0.1~0.5时,吸附比较容易;大于2时,难以吸附。 应用最普遍,但是它适用于高度不均匀表面,而且仅对限制浓度范围(低浓度)的吸附数据有效 一级动力学1(1)k t t e q q e -=- 线性
二级动力学 2 221e t e k q t q k q t =+ 线性 初始吸附速度 Elovich 动力学模型 Webber-Morris 动力学模型 Boyd kinetic plot 令F=Q t /Q e, K B t=-0.498-ln(1-F) 准一级模型基于假定吸附受扩散步骤控制; 准二级动力学模型假设吸附速率由吸附剂表面未被占有的吸附空位数目的平方值决定,吸附过程受化学吸附机理的控制,这种化学吸附涉及到吸附剂与吸附质之间的电子共用或电子转移; Webber-Morris 动力学模型 粒子内扩散模型中,qt 与t1/2进行线性拟合,如果直线通过原点,说明颗粒内扩散是控制吸附过程的限速步骤;如果不通过原点,吸附过程受其它吸附阶段的共同控制;该模型能够描述大多数吸附过程,但是,由于吸附初期和末期物质传递的差异,试验结果往往不能完全符合拟合直线通过原点的理想情况。粒子内扩散模型最适合描述物质在颗粒内部扩散过程的动力学,而对于颗粒表面、液体膜内扩散的过程往往不适合
AMOS结构方程模型修正经典案例
AMOS结构方程模型修正经典案例 第一节模型设定结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解 释四个步骤。下面以一个研究实例作为说明,使用 Amos7 软件1进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据2进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承 ASCI 模型核心概念的基础上,对模型作了一些改进,在模型中 增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。 模型中共包含七个因素 (潜变量 ):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素 是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍, 2000)。 表 7-1设计的结构路径图和基本路径假设 设计的结构路径图基本路径假设 超市形象 顾客抱怨质量期望 感知价值 顾客满意 质量感知 顾客忠诚超市形象对质量期望有路径影响 质量期望对质量感知有路径影响 质量感知对感知价格有路径影响 质量期望对感知价格有路径影响 感知价格对顾客满意有路径影响 顾客满意对顾客忠诚有路径影响 超市形象对顾客满意有路径影响 超市形象对顾客忠诚有路径影响 2.1 、顾客满意模型中各因素的具体范畴 1本案例是在Amos7 中完成的。 2见 spss数据文件“处理后的数据 .sav”。
结构方程模型估计案例
结构方程模型估计案例 Prepared on 22 November 2020
应用案例1 第一节模型设定 结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在着名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。 模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。 表7-1 设计的结构路径图和基本路径假设 、顾客满意模型中各因素的具体范畴 参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。 表7-2 模型变量对应表 1关于该案例的操作也可结合书上第七章的相关内容来看。 2本案例是在Amos7中完成的。 3见spss数据文件“处理后的数据.sav”。
1什么是结构方程模型
1什么是结构方程模型? 结构方程模型是应用线性方程表示观测变量与潜变量之间,以及潜在变量之间关系的一种多元统计方法,其实质是一种广义的一般线性模型。 ?結構方程模式(Structural Equation Models,簡稱SEM),早期稱為線性結構方程模式(Linear Structural Relationships,簡稱LISREL)或稱為共變數結構分析(Covariance Structure Analysis)。 ?主要目的在於考驗潛在變項(Latent variables)與外顯變項(Manifest variable, 又稱觀察變項)之關係,此種關係猶如古典測驗理論中真分數(true score)與實得分數(observed score)之關係。它結合了因素分析(factor analysis)與路徑分析(path analysis),包涵測量與結構模式。 ? 1.1介绍潜在变量与观察变量的概念 ?(1)很多社会、心理研究中所涉及到的变量,都不能准确、直接地测量,这种变量称为潜变量,如工作自主权、工作满意度等。 ?(2)这时,只能退而求其次,用一些外显指标,去间接测量这些潜变量。如用工作方式选择、工作目标调整作为工作自主权(潜变量)的指标,以目前工作满意度、工作兴趣、工作乐趣、工作厌恶程度(外显指标)作为工作满意度的指标。 ?(3)传统的统计分析方法不能妥善处理这些潜变量,而结构方程模型则能同时处理潜变量及其指标。 (4)书上第7页 观测变量:能够观测到的变量(路径图中以长方形表示) 潜在变量:难以直接观测到的抽象概念,由测量变量推估出来的变量(路 径图中以椭圆形表示) 内生变量:模型总会受到任何一个其他变量影响的变量(因变量;路径图 会受到任何一个其他变量以单箭头指涉的变量 外生变量:模型中不受任何其他变量影响但影响其他变量的变量(自变量; 路径图中会指向任何一个其他变量,但不受任何变量以单箭头指涉的变量) 中介变量:当内生变量同时做因变量和自变量时,表示该变量不仅被其他 变量影响,还可能对其他变量产生影响。 内生潜在变量:潜变量作为内生变量 外生观测变量:外生潜在变量的观测变量 外生潜在变量:潜变量作为外生变量 外生观测变量:外生潜在变量的观测变量 中介潜变量:潜变量作为中介变量 中介观测变量:中介潜在变量的观测变量 1.2介绍测量模型与结构模型的概念(书上第9页)
结构方程Amos操作Word案例
超市形象质量期望 质量感知感知价值顾客满意 顾客抱怨 顾客忠诚 应用案例1 第一节模型设定 结构方程模型分析过程可以分为模型构建、模型运算、模型修正以及模型解释四个步骤。下面以一个研究实例作为说明,使用Amos7软件2进行计算,阐述在实际应用中结构方程模型的构建、运算、修正与模型解释过程。 一、模型构建的思路 本案例在著名的美国顾客满意度指数模型(ASCI)的基础上,提出了一个新的模型,并以此构建潜变量并建立模型结构。根据构建的理论模型,通过设计问卷对某超市顾客购物服务满意度调查得到实际数据,然后利用对缺失值进行处理后的数据3进行分析,并对文中提出的模型进行拟合、修正和解释。 二、潜变量和可测变量的设定 本文在继承ASCI模型核心概念的基础上,对模型作了一些改进,在模型中增加超市形象。它包括顾客对超市总体形象及与其他超市相比的知名度。它与顾客期望,感知价格和顾客满意有关,设计的模型见表7-1。 模型中共包含七个因素(潜变量):超市形象、质量期望、质量感知、感知价值、顾客满意、顾客抱怨、顾客忠诚,其中前四个要素是前提变量,后三个因素是结果变量,前提变量综合决定并影响着结果变量(Eugene W. Anderson & Claes Fornell,2000;殷荣伍,2000)。 表7-1 设计的结构路径图和基本路径假设 设计的结构路径图基本路径假设 超市形象对质量期望有路径影响 质量期望对质量感知有路径影响 质量感知对感知价格有路径影响 质量期望对感知价格有路径影响 感知价格对顾客满意有路径影响 顾客满意对顾客忠诚有路径影响 超市形象对顾客满意有路径影响 超市形象对顾客忠诚有路径影响 2.1、顾客满意模型中各因素的具体范畴 参考前面模型的总体构建情况、国外研究理论和其他行业实证结论,以及小范围甄别调查的结果,模型中各要素需要观测的具体范畴,见表7-2。 1关于该案例的操作也可结合书上第七章的相关内容来看。 2本案例是在Amos7中完成的。 3见spss数据文件“处理后的数据.sav”。