序列相关的检验和修正
序列相关的检验及修正
例题:中国居民总量消费函数 数据:
1、 建立回归模型,模型的OLS 估计 t t t X Y μββ++=10
(1)录入数据
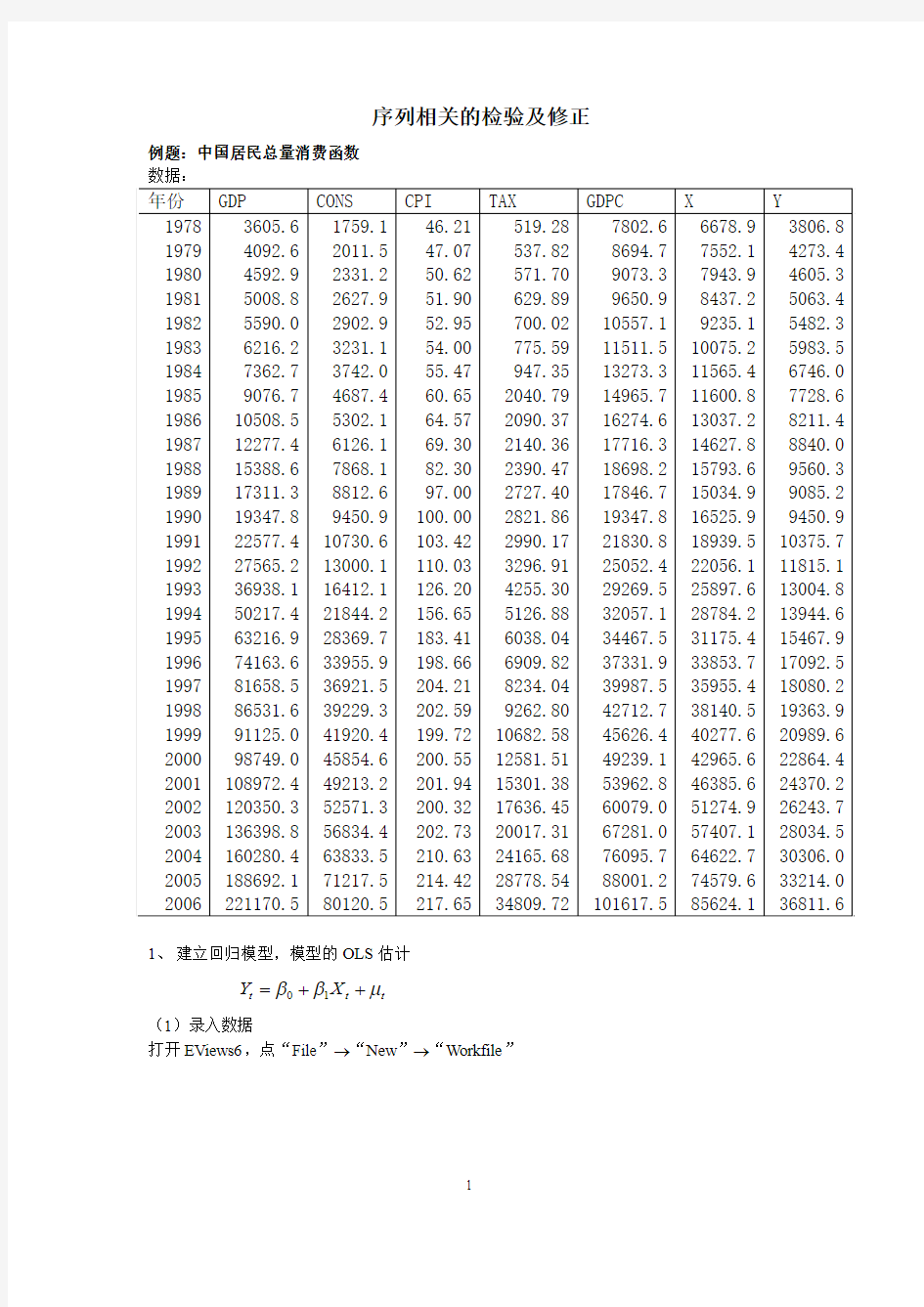
打开EViews6,点“File ”→“New ”→“Workfile ”
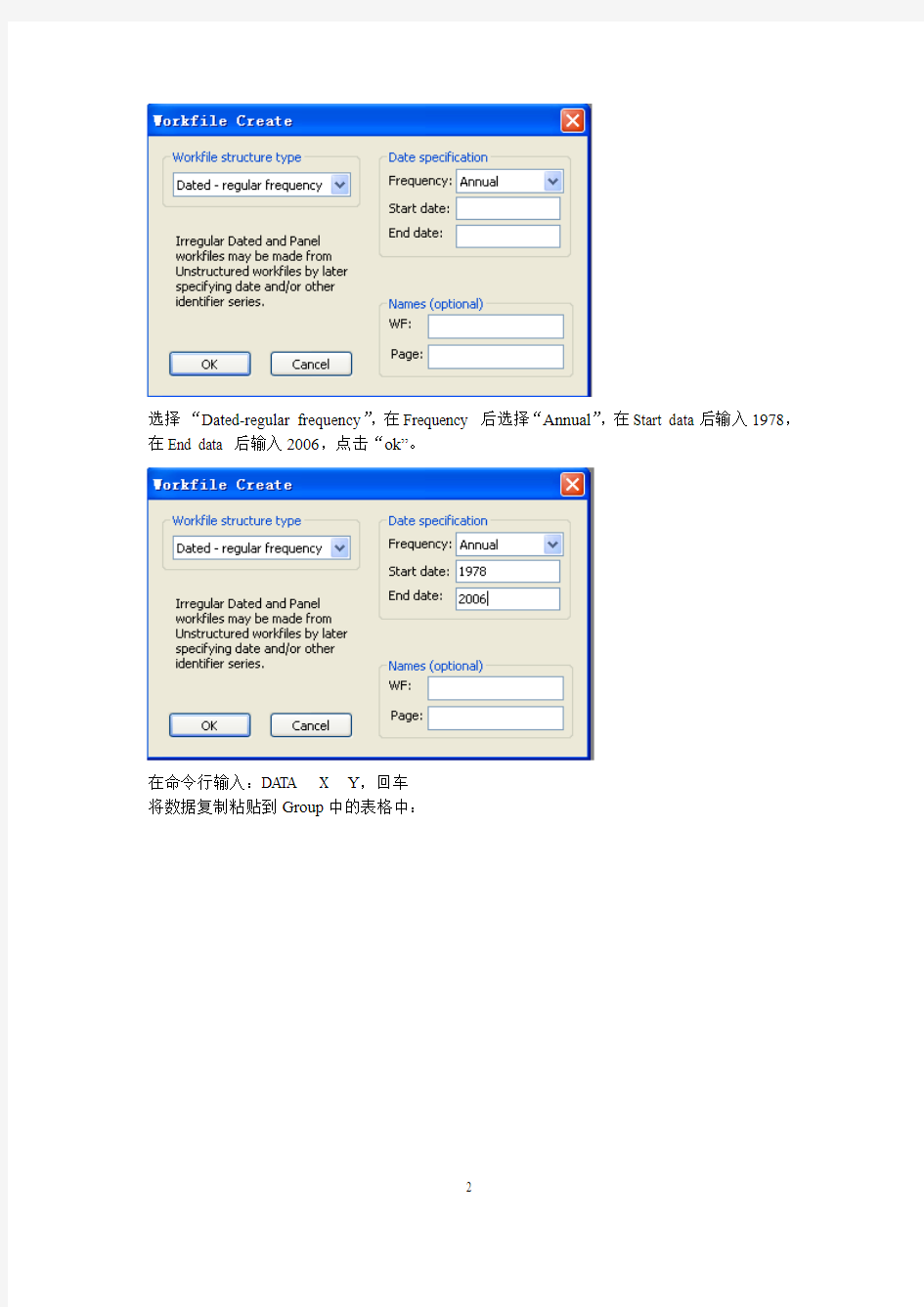
选择“Dated-regular frequency”,在Frequency 后选择“Annual”,在Start data后输入1978,在End data 后输入2006,点击“ok”。
在命令行输入:DATA X Y,回车
将数据复制粘贴到Group中的表格中:
(2)估计回归方程
在命令行输入命令:LS Y C X,回车
或者在主菜单中点“Quick” “Estimate Equation”,在Specification中输入Y C X,点“确定”。得到如下输出:
写出估计结果:
X Y 4375.028.2091?+=
(6.243) (47.059) 2
R =0.9880 =2
R
0.9875 F=2214.537 D.W.=0.277
2、 序列相关的检验 (1) 图示检验法 作残差序列的时序图:
保存残差虚列: GENR E=RESID 作图: PLOT E
从图上可以看出,模型的最小二乘残差开始连续几期小于0,接着连续几期都大于0,这种模式的残差意味着模型可能存在正的序列相关性。
做t
e ~和1~-t e 的关系图: SCAT E(-1) E
从上面的散点图可以看出,t e ~和1~-t e 之间可以拟合一个线性模型: t
e ~=t t e ερ+-1~ 且回归直线的斜率为正(ρ>0),表明模型存在正的序列相关性。
(2)DW 检验
由OLS 估计的结果可知:D.W.=0.277。查DW 分布的临界值表,k=2,n=29时,L d =1.34,
U d =1.48,显然0<0.277 (3)回归检验法 拟合模型:t e ~=t t e ερ+-1~,并运用OLS 估计模型:LS E E(-1) 得到如下结果: 写出回归结果: 1 ~949.0?~-=t t e e (8.148) 回归系数的t 统计量为8.148,伴随概率P=0.0000<α=0.05,表明原模型存在一阶序列相关。 拟合模型:t e ~=t t t e e ερρ++--2211~~,并运用OLS 估计模型:LS E E(-1) E(-2) 得到如下结果: 写出回归结果: 2 1~864.0~659.1?~---=t t t e e e (10.895) (-5.567) 回归系数 和的t 统计量分别为10.895、-5.567,相应的伴随概率P=0.0000<α=0.05, 表明原模型存在二阶序列相关。 拟合模型:t e ~=112233t t t t e e e ρρρε---+++ , 并运用OLS 估计模型:LS E E(-1) E(-2) E(-3),回车,得到如下结果: 写出回归结果: 123? 1.4950.4740.286t t t t e e e e ---=-- (7.280) (-1.277) (-1.182) 回归系数的t 统计量为7.280,相应的伴随概率P1=0.0000<α=0.05,表明 显著不 为零,但 和 的t 统计量分别为-1.277、-1.182,相应的伴随概率P2=0.2144,P3=0.2491, 均大于α=0.05,表明原模型不存在三阶序列相关。 综上,原模型有二阶序列相关。 (4)LM 检验 首先采用OLS 估计模型,在弹出的Equation 窗口,点View →Residual Tests →Serial correlation LM Test…,弹出下面的对话框: 点“OK ”。得到下面的输出: 从上面的输出可知:LM=23.65686,Prob.Chi-Square(2)=0.0000,小于α=0.05,且辅助回归中RESID(-1)和RESID(-2)的系数均显著不为0(对应t统计量的P值均小于0.05),说明模型具有2节序列相关。 在Equation窗口,点View→Residual Tests→Serial corre lation LM Test…,在弹出的对话框里将滞后阶数改为3: 点“OK”。得到下面的输出: 这时,LM=23.96054,Prob.Chi-Square(2)=0.0000,小于 =0.05,但辅助回归中RESID(-2)和RESID(-3)的系数不显著(对应t统计量的P值均大于0.05),说明模型仅存在2阶序列相关,不具有3阶的序列相关。 3、序列相关的修正 (1)广义差分法 已知模型具有2阶序列相关,在命令行输入命令: LS Y C X AR(1) AR(2) 回车 得到下面的输出: 写出修正后的模型: (0.049) (4.309) (6.526) (-1.681) (2)序列相关稳健估计法 在主菜单中点“Quick” “Estimate Equation”,在Specification中输入Y C X,然后点击“Options”,在弹出的对话框里选择“Heteroskedasticity consistent coefficient”—— “Newey—West”,点“确定”。 得到如下输出: 写出估计结果: =2091.282+0.4375X (4.238) (22.294) =0.988 =0.988 F=2214.54 D.W=0.277 实验五自相关性 【实验目的】 掌握自相关性的检验与处理方法。 【实验内容】 利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。 【实验步骤】 一、回归模型的筛选 ⒈相关图分析 SCAT X Y 相关图表明,GDP指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而加以比较分析。 ⒉估计模型,利用LS命令分别建立以下模型 ⑴线性模型:LS Y C X t (-6.706) (13.862) = 2 R=0.9100 F=192.145 S.E=5030.809 ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX t (-31.604) (64.189) = 2 R=0.9954 F=4120.223 S.E=0.1221 ⑶对数模型:LS Y C LNX =t (-6.501) (7.200) 2R =0.7318 F =51.8455 S.E =8685.043 ⑷指数模型:LS LNY C X =t (23.716) (14.939) 2R =0.9215 F =223.166 S.E =0.5049 ⑸二次多项式模型:GENR X2=X^2 LS Y C X X2 =t (3.747) (-8.235) (25.886) 2R =0.9976 F =3814.274 S.E =835.979 ⒊选择模型 比较以上模型,可见各模型回归系数的符号及数值较为合理。各解释变量及常数项都通过了t 检验,模型都较为显著。除了对数模型的拟合优度较低外,其余模型都具有高拟合优度,因此可以首先剔除对数模型。 比较各模型的残差分布表。线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,指数模型则大体相反,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这两种函数形式设置是不当的。而且,这两个模型的拟合优度也较双对数模型和二次多项式模型低,所以又可舍弃线性模型和指数模型。双对数模型和二次多项式模型都具有很高的拟合优度,因而初步选定回归模型为这两个模型。 二、自相关性检验 ⒈DW 检验; ⑴双对数模型 因为n =21,k =1,取显著性水平α=0.05时,查表得L d =1.22, U d =1.42,而0<0.7062=DW 案例三 ARIMA 模型的建立 一、实验目的 了解ARIMA 模型的特点和建模过程,了解AR ,MA 和ARIMA 模型三者之间的区别与联系,掌握如何利用自相关系数和偏自相关系数对ARIMA 模型进行识别,利用最小二乘法等方法对ARIMA 模型进行估计,利用信息准则对估计的ARIMA 模型进行诊断,以及如何利用ARIMA 模型进行预测。掌握在实证研究如何运用Eviews 软件进行ARIMA 模型的识别、诊断、估计和预测。 二、基本概念 所谓ARIMA 模型,是指将非平稳时间序列转化为平稳时间序列,然后将平稳的时间序列建立ARMA 模型。ARIMA 模型根据原序列是否平稳以及回归中所含部分的不同,包括移动平均过程(MA )、自回归过程(AR )、自回归移动平均过程(ARMA )以及ARIMA 过程。 在ARIMA 模型的识别过程中,我们主要用到两个工具:自相关函数ACF ,偏自相关函数PACF 以及它们各自的相关图。对于一个序列{}t X 而言,它的第j 阶自相关系数j ρ为它的j 阶自协方差除以方差,即j ρ=j 0γγ ,它是关于滞后期j 的函数,因此我们也称之为自相关函数,通常记ACF(j )。偏自相关函数PACF(j )度量了消除中间滞后项影响后两滞后变量之间的相关关系。 三、实验内容及要求 1、实验内容: (1)根据时序图的形状,采用相应的方法把非平稳序列平稳化; (2)对经过平稳化后的1950年到2007年中国进出口贸易总额数据运用经典B-J 方法论建立合适的ARIMA (,,p d q )模型,并能够利用此模型进行进出口贸易总额的预测。 2、实验要求: (1)深刻理解非平稳时间序列的概念和ARIMA 模型的建模思想; (2)如何通过观察自相关,偏自相关系数及其图形,利用最小二乘法,以及信息准则建立合适的ARIMA 模型;如何利用ARIMA 模型进行预测; (3)熟练掌握相关Eviews 操作,读懂模型参数估计结果。 四、实验指导 1、模型识别 (1)数据录入 打开Eviews 软件,选择“File”菜单中的“New --Workfile”选项,在“Workfile structure type ”栏选择“Dated –regular frequency ”,在“Date specification ”栏中分别选择“Annual ”(年数据) ,分别在起始年输入1950,终止年输入2007,点击ok ,见图3-1,这样就建立了一个工作文件。点击File/Import ,找到相应的Excel 数据集,导入即可。 实验二序列相关性 【实验目的】 掌握序列相关性问题出现的来源、后果、检验及修正的原理,以及相关的Eviews操作方法。 【实验内容】 经济理论指出,商品进口主要由进口国的经济发展水平,以及商品进口价格指数与国内价格指数对比因素决定的。由于无法取得价格指数数据,我们主要研究中国商品进口与国内生产总值的关系。 以1978-2001年中国商品进口额与国内生产总值数据为例,练习检查和克服模型的序列相关性的操作方法。 【实验步骤】 一、建立线性回归模型 利用表中数据建立M 关于GDP 的散点图(SCAT GDP M )。 可以看到M 与GDP 呈现接近线性的正相关关系。 建立一个线性回归模型(LS M C GDP )。 即得到的回归式为: GDP M 0204.09058.152+= (3.32) (20.1) 9461.02=R D.W.=0.63 F=405 二、 进行序列相关性检验 1、 观察残差图 做出残差项与时间以及与滞后一期的残差项的折线图,可以看出随机项存在正序列相关性。 2、 用D.W.检验判断 由回归结果输出D.W.=0.628。若给定05.0=α,已知n=24,k=2,查D.W.检验上下界表可得,45.1,27.1==U L d d 。由于D.W.=0.628<1.27=L d ,故存在正自相关。 3、 用LM 检验判断 在估计窗口中选择Serial Correlation LM Test,设定滞后期Lag=1,得到LM 检验结果。 由于P值为0.0027,可以拒绝原假设,表明存在自相关。 4、用回归检验法判断 对初始估计结果得到的残差序列定义为E1,首先做一阶自回归(LS E1 E1(-1))。 经济计量分析实验报告 一、实验项目 自相关性的检验及修正 二、实验日期 2015.12.13 三、实验目的 对于国内旅游总花费的有关影响因素建立多元线性回归模型,对变量进行多重共线性的检验及修正后,对随机误差项进行异方差的检验和补救及自相关性的检验和修正。 四、实验内容 建立模型,对模型进行参数估计,对样本回归函数进行统计检验,以判定估计的可靠程度,包括拟合优度检验、方程总体线性的显著性检验、变量的显著性检验,以及参数的置信区间估计。 检验变量是否具有多重共线性并修正。 检验是否存在异方差并补救。 检验是否存在相关性并修正。 五、实验步骤 1、建立模型。 以国内旅游总花费Y 作为被解释变量,以年底总人口表示人口增长水平,以旅行社数量表示旅行社的发展情况,以城市公共交通运营数表示城市公共交通运行状况,以城乡居民储蓄存款年末增加值表示城乡居民储蓄存款增长水平。 2、模型设定为: t t t t t μβββββ+X +X +X +X +=Y 443322110t 其中:t Y — 国内旅游总花费(亿元) t 1X — 年底总人口(万人) t 2X — 旅行社数量(个) t 3X — 城市公共交通运营数(辆) t 4X — 城乡居民储蓄存款年末增加值(亿元) 3、对模型进行多重共线性检验。 4、检验异方差是否存在并补救。 5、检验自相关性是否存在并修正。 六、实验结果 消除多重共线性及排除异方差性之后的回归模型为:2382963.08388.301?X Y +-= 检验 I 、图示法 1、1-t e ,t e 散点图 -1,500 -1,000 -500 500 1,000 1,500 -2,000 -1,00001,0002,000 ET(-1) E T 大部分落在第Ⅰ,Ⅲ象限,表明随机误差项存在正自相关。 2、t e 折线图 -1,500 -1,000 -500 500 1,000 1,500 86 88 90 92 94 96 98 00 02 04 06 08 10 RESID Ⅱ、解析法 1、D-W 检验 第十三章 时间序列回归 本章讨论含有ARMA 项的单方程回归方法,这种方法对于分析时间序列数据(检验序列相关性,估计ARMA 模型,使用分布多重滞后,非平稳时间序列的单位根检验)是很重要的。 §13.1序列相关理论 时间序列回归中的一个普遍现象是:残差和它自己的滞后值有关。这种相关性违背了回归理论的标准假设:干扰项互不相关。与序列相关相联系的主要问题有: 一、一阶自回归模型 最简单且最常用的序列相关模型是一阶自回归AR(1)模型 定义如下:t t t u x y +'=β t t t u u ερ+=-1 参数ρ是一阶序列相关系数,实际上,AR(1)模型是将以前观测值的残差包含到现观测值的回归模型中。 二、高阶自回归模型: 更为一般,带有p 阶自回归的回归,AR(p)误差由下式给出: t t t u x y +'=β t p t p t t t u u u u ερρρ++++=--- 2211 AR(p)的自回归将渐渐衰减至零,同时高于p 阶的偏自相关也是零。 §13.2 检验序列相关 在使用估计方程进行统计推断(如假设检验和预测)之前,一般应检验残差(序列相关的证据),Eviews 提供了几种方法来检验当前序列相关。 1.Dubin-Waston 统计量 D-W 统计量用于检验一阶序列相关。 2.相关图和Q-统计量 计算相关图和Q-统计量的细节见第七章 3.序列相关LM 检验 检验的原假设是:至给定阶数,残差不具有序列相关。 §13.3 估计含AR 项的模型 随机误差项存在序列相关说明模型定义存在严重问题。特别的,应注意使用OLS 得出的过分限制的定义。有时,在回归方程中添加不应被排除的变量会消除序列相关。 1.一阶序列相关 在EViews 中估计一AR(1)模型,选择Quick/Estimate Equation 打开一个方程,用列表法输入方程后,最后将AR(1)项加到列表中。例如:估计一个带有AR(1)误差的简单消费函数 t t t u GDP c c CS ++=21 t t t u u ερ+=-1 应定义方程为: cs c gdp ar(1) 2.高阶序列相关 估计高阶AR 模型稍稍复杂些,为估计AR(k ),应输入模型的定义和所包括的各阶AR 值。如果想估计一个有1-5阶自回归的模型 t t t u GDP c c CS ++=21 t t t t u u u ερρ+++=--5511 应输入: cs c gdp ar(1) ar(2) ar(3) ar(4) ar(5) 3.存在序列相关的非线性模型 EViews 可以估计带有AR 误差项的非线性回归模型。例如: 估计如下的带有附加AR(2)误差的非线性方程 t c t t u GDP c CS ++=21 关于x y的散点图 由散点图可以判断出才可能存在异方差。运用怀特检验判断是否有异方差 White Heteroskedasticity Test: F-statistic 5.71174 5 Probability 0.00831 1 Obs*R-squared 8.98267 0 Probability 0.01120 6 由此可见,1%的显著水平上存在异方差。运用加权最小二乘法消除异方差: Dependent Variable: Y Method: Least Squares Date: 10/29/14 Time: 14:46 Sample: 1 31 Included observations: 31 Weighting series: 1/ABS(RESID) Variable Coeffici ent Std. Error t-Statistic Prob. C -2171.3 76 418.8113 -5.184616 0.0000 X 0.97610 4 0.022593 43.20372 0.0000 Weighted Statistics R-squared 0.99927 0 Mean dependent var 16676.9 9 Adjusted R-squared 0.99924 5 S.D. dependent var 18232.7 8 S.E. of regression 501.062 0 Akaike info criterion 15.3336 8 Sum squared resid 728082 9. Schwarz criterion 15.4261 9 Log likelihood -235.67 20 F-statistic 1866.56 1 Durbin-Watson stat 1.37353 7 Prob(F-statistic) 0.00000 0 Unweighted Statistics R-squared 0.92681 6 Mean dependent var 17975.6 8 Adjusted R-squared 0.92429 2 S.D. dependent var 5667.54 2 S.E. of regression 1559.42 4 Sum squared resid 705223 38 Durbin-Watson stat 1.57587 5 由上表,f检验的伴随概率为0.000000,说明在1%的显著水平上,拒绝原假设,t检验的伴随概率为0.0000,说明在1%的显著水平上,拒绝原假设y x 之间存在显著的线性关系,该模型很好的反映了实际情况,所以消除了异方差。 实验五 自相关性【实验目的】 掌握自相关性的检验与处理方法。 【实验内容】利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。表5-1 我国城乡居民储蓄存款与GDP 统计资料(1978年=100)年份 存款余额Y GDP 指数X 年份存款余额Y GDP 指数X 1978 210.60100.019895146.90271.31979 281.00107.619907034.20281.71980 399.50116.019919107.00307.61981 523.70122.1199211545.40351.41982 675.40133.1199314762.39398.81983 892.50147.6199421518.80449.31984 1214.70170.0199529662.25496.51985 1622.60192.9199638520.84544.11986 2237.60210.0199746279.80592.01987 3073.30234.0199853407.47638.219883801.50260.7【实验步骤】一、回归模型的筛选 ⒈相关图分析SCAT X Y 相关图表明,GDP 指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而 加以比较分析。⒉估计模型,利用LS 命令分别建立以下模型⑴线性模型: LS Y C X x y 5075.9284.14984?+-= (-6.706) (13.862)=t =0.9100 F =192.145 S.E =5030.8092R ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX 、管路敷设技术护层防腐跨接地线弯曲半径标高等,要求技术交底。管线敷设技术中包含线槽、管架等多项方式,为解决高中语文电气课件中管壁薄、接口不严等问题,合理利用管线敷设技术。线缆敷设原则:在分线盒处,当不同电压回路交叉时,应采用金属隔板进行隔开处理;同一线槽内,强电回路须同时切断习题电源,线缆敷设完毕,要进行检查和检测处理。、电气课件中调试写复杂设备与装置高中资料试卷调试方案,编写重要设备高中资料试卷试验方案以及系统启动方案;对整套启动过程中高中资料试卷电气设备进行调试工作并且进行过关运行高中资料试卷技术指导。对于调试过程中高中资料试卷技术问题,作为调试人员,需要在事前掌握图纸资料、设备制造厂家出具高中资料试卷试验报告与相关技术资料,并且了解现场设备高中资料试卷布置情况与有关高中资料试卷电气系统接线等情况,然后根据规范与规程规、电气设备调试高中资料试卷技术工况进行自动处理,尤其要避免错误高中资料试卷保护装置动作,并且拒绝动作,来避免不必要高中资料试卷突然停机。因此,电力高中资料试卷保护装置调试技术,要求电力保护装置做到准确灵活。对于差动保护装置高中资料试卷调试技术是指发电机一变压器组在发生内部故障时,需要进行外部电源高中资料试卷切除从而采用高中资料试卷主要保护装置。 实验2 自相关的检验与修正 一、实验目的: 掌握自相关模型的检验方法与处理方法.。 二、实验容及要求: 表1列出了1985-2007年中国农村居民人均纯收入与人均消费性支出的统计数据。 (1)利用OLS法建立中国农村居民人均消费性支出与人均纯收入的线性模型。 (2)检验模型是否存在自相关。 (3)如果存在自相关,试采用适当的方法加以消除。 表1 1985-2007年中国农村居民人均纯收入与人均消费性支出(单位:元) 实验如下: 首先对数据进行调整,将全年人均纯收入和全年人均消费性支出相应调整为全年实际人均纯收入和全年实际人均消费性支出。 图1 1、用OLS估计法估计参数 图2 图3 图4 从图4中可以看出,中国农村居民人均消费性支出与人均纯收入存在着显著的正相关关系。 估计回归方程: 从图3中可以得出,估计回归方程为: Y=56.21878+0.698928X t=(3.864210)(31.99973) R2=0.979904 F=1023.983 D.W.=0.409903 (1)图示法 图5 从图5中,可以看出残差的变化有系统模式,连续为正或连续为负,表示残差项存在一阶正自相关。 (2)DW检验 从图3中可以得到D.W.=0.409903,在显著水平去5%,n=23,k=2,d L=1.26, d U=1.44。此时0 序列相关的检验及修正 例题:中国居民总量消费函数 数据: 年份 GDP CONS CPI TAX GDPC X Y 1978 3605.6 1759.1 46.21 519.28 7802.6 6678.9 3806.8 1979 4092.6 2011.5 47.07 537.82 8694.7 7552.1 4273.4 1980 4592.9 2331.2 50.62 571.70 9073.3 7943.9 4605.3 1981 5008.8 2627.9 51.90 629.89 9650.9 8437.2 5063.4 1982 5590.0 2902.9 52.95 700.02 10557.1 9235.1 5482.3 1983 6216.2 3231.1 54.00 775.59 11511.5 10075.2 5983.5 1984 7362.7 3742.0 55.47 947.35 13273.3 11565.4 6746.0 1985 9076.7 4687.4 60.65 2040.79 14965.7 11600.8 7728.6 1986 10508.5 5302.1 64.57 2090.37 16274.6 13037.2 8211.4 1987 12277.4 6126.1 69.30 2140.36 17716.3 14627.8 8840.0 1988 15388.6 7868.1 82.30 2390.47 18698.2 15793.6 9560.3 1989 17311.3 8812.6 97.00 2727.40 17846.7 15034.9 9085.2 1990 19347.8 9450.9 100.00 2821.86 19347.8 16525.9 9450.9 1991 22577.4 10730.6 103.42 2990.17 21830.8 18939.5 10375.7 1992 27565.2 13000.1 110.03 3296.91 25052.4 22056.1 11815.1 1993 36938.1 16412.1 126.20 4255.30 29269.5 25897.6 13004.8 1994 50217.4 21844.2 156.65 5126.88 32057.1 28784.2 13944.6 1995 63216.9 28369.7 183.41 6038.04 34467.5 31175.4 15467.9 1996 74163.6 33955.9 198.66 6909.82 37331.9 33853.7 17092.5 1997 81658.5 36921.5 204.21 8234.04 39987.5 35955.4 18080.2 1998 86531.6 39229.3 202.59 9262.80 42712.7 38140.5 19363.9 1999 91125.0 41920.4 199.72 10682.58 45626.4 40277.6 20989.6 2000 98749.0 45854.6 200.55 12581.51 49239.1 42965.6 22864.4 2001 108972.4 49213.2 201.94 15301.38 53962.8 46385.6 24370.2 2002 120350.3 52571.3 200.32 17636.45 60079.0 51274.9 26243.7 2003 136398.8 56834.4 202.73 20017.31 67281.0 57407.1 28034.5 2004 160280.4 63833.5 210.63 24165.68 76095.7 64622.7 30306.0 2005 188692.1 71217.5 214.42 28778.54 88001.2 74579.6 33214.0 2006 221170.5 80120.5 217.65 34809.72 101617.5 85624.1 36811.6 1、 建立回归模型,模型的OLS 估计 t t t X Y μββ++=10 (1)录入数据 打开EViews6,点“File ” “New ”“Workfile ” 1.序列相关性概述 或 对于模型 00 (,)()t t s t t s Cov E s μμμμ--=≠≠在其他假设仍成立的条件下,随机误差项序列相关意味着 ρ:自协方差系数(Coefficient of Autocovariance )或一阶自相关系数(First-order Coefficient of Autocorrelation ) 若E(μt μt -1)≠0 t =1,2,…,T 称为一阶序列相关,或自相关(Autocorrelation )自相关往往可写成如下形式: μt =ρμt -1+εt -1<ρ<1εt 是满足以下标准的OLS 假定的随机误差项: 2 000(),(),(,)t t t t s E Var Cov s εεσεε-===≠ 2.实际经济问题中的序列相关性 经济变量固有的惯性 大多数经济时间数据都有一个明显的特点:惯性,表现在时间序列不同时间的前后关联上。 模型设定的偏误所谓模型设定偏误(Specification error )是指所设定的模型“不正确”。主要表现在模型中丢掉了重要的解释变量或模型函数形式有偏误。数据的“编造” 在实际经济问题中,有些数据是通过已知数据生成的。因此,新生成的数据与原数据间就有了内在的联系,表现出序列相关性。 +++ 3.序列相关性的后果参数估计量非有效因为,在有效性证明中利用了即同方差性和互相独立性条件。而且,在大样本情况下,参数估计量也不具有渐近有效性。2()μμσ'=E X I +如果出现了序列相关性,估计的出现偏误(偏大 或偏小),t 检验失去意义。 ?βj S 变量的显著性检验中,构造了t 统计量 ??/ββ=j j t S +变量的显著性检验失去意义 序列相关性检验(一)一元线性回归结果: Dependent Variable: Y Method: Least Squares Date: 06/01/12 Time: 14:16 Sample: 1981 2007 Included observations: 27 C 4276.362 1079.786 3.960380 0.0005 X 0.871668 0.029448 29.60012 0.0000 R-squared 0.972258 Mean dependent var 24869.44 Adjusted R-squared 0.971149 S.D. dependent var 25261.92 S.E. of regression 4290.920 Akaike info criterion 19.63758 Sum squared resid 4.60E+08 Schwarz criterion 19.73356 Log likelihood -263.1073 F-statistic 876.1668 Durbin-Watson stat 0.174669 Prob(F-statistic) 0.000000 (二)拉格朗日乘数检验: 含二阶残差项的回归结果: Breusch-Godfrey Serial Correlation LM Test: F-statistic 120.8648 Probability 0.000000 Obs*R-squared 24.65421 Probability 0.000004 Test Equation: Dependent Variable: RESID Method: Least Squares Variable Coefficient Std. Error t-Statistic Prob. C 361.5102 372.6461 0.970117 0.3421 X -0.025697 0.013222 -1.943398 0.0643 RESID(-1) 1.477525 0.193620 7.631049 0.0000 RESID(-2) -0.485298 0.229297 -2.116459 0.0453 R-squared 0.913119 Mean dependent var -2.29E-12 Adjusted R-squared 0.901787 S.D. dependent var 4207.593 S.E. of regression 1318.618 Akaike info criterion 17.34251 Sum squared resid 39991346 Schwarz criterion 17.53449 Log likelihood -230.1239 F-statistic 80.57655 Durbin-Watson stat 1.772240 Prob(F-statistic) 0.000000 时间序列分析法原理及步骤 ----目标变量随决策变量随时间序列变化系统 一、认识时间序列变动特征 认识时间序列所具有的变动特征, 以便在系统预测时选择采用不同的方法 1》随机性:均匀分布、无规则分布,可能符合某统计分布(用因变量的散点图和直方图及其包含的正态分布检验随机性, 大多服从正态分布 2》平稳性:样本序列的自相关函数在某一固定水平线附近摆动, 即方差和数学期望稳定为常数 识别序列特征可利用函数 ACF :其中是的 k 阶自 协方差,且 平稳过程的自相关系数和偏自相关系数都会以某种方式衰减趋于 0, 前者测度当前序列与先前序列之间简单和常规的相关程度, 后者是在控制其它先前序列的影响后,测度当前序列与某一先前序列之间的相关程度。实际上, 预测模型大都难以满足这些条件, 现实的经济、金融、商业等序列都是非稳定的,但通过数据处理可以变换为平稳的。 二、选择模型形式和参数检验 1》自回归 AR(p模型 模型意义仅通过时间序列变量的自身历史观测值来反映有关因素对预测目标的影响和作用,不受模型变量互相独立的假设条件约束,所构成的模型可以消除普通回归预测方法中由于自变量选择、多重共线性的比你更造成的困难用 PACF 函数判别 (从 p 阶开始的所有偏自相关系数均为 0 2》移动平均 MA(q模型 识别条件 平稳时间序列的偏相关系数和自相关系数均不截尾,但较快收敛到 0, 则该时间序列可能是 ARMA(p,q模型。实际问题中,多数要用此模型。因此建模解模的主要工作时求解 p,q 和φ、θ的值,检验和的值。 模型阶数 实际应用中 p,q 一般不超过 2. 3》自回归综合移动平均 ARIMA(p,d,q模型 模型含义 模型形式类似 ARMA(p,q模型, 但数据必须经过特殊处理。特别当线性时间序列非平稳时,不能直接利用 ARMA(p,q模型,但可以利用有限阶差分使非平稳时间序列平稳化,实际应用中 d (差分次数一般不超过 2. 模型识别 平稳时间序列的偏相关系数和自相关系数均不截尾,且缓慢衰减收敛,则该时间序列可能是 ARIMA(p,d,q模型。若时间序列存在周期性波动, 则可按时间周期进 专业班级 08级信息工程组别 成员 1、引言 人在发浊音时,气流通过声门使声带产生张弛振荡式振动,产生一股准周期脉冲气流,这一气流激励声道就产生浊音,又称有声语音,它携带着语音中的大部分能量。这种声带振动的频率称为基频,相应的周期就称为基音周期( Pitch) ,它由声带逐渐开启到面积最大(约占基音周期的50% ) 、逐渐关闭到完全闭合(约占基音周期的35% ) 、完全闭合(约占基音周期的15% )三部分组成。 当今主流的基音周期检测技术主要有时域的自相关法、频域的倒谱法、时频结合的小波变换分析方法以及在其基础上的衍生算法。本文所采用的方法是自相关法 2.设计思路 (1)自相关函数 对于离散的语音信号x(n),它的自相关函数定义为: R(k)=Σx(n)x(n-k), 如果信号x(n))具有周期性,那么它的自相关函数也具有周期性,而且周期与信号x(n)的周期性相同。自相关函数提供了一种获取周期信号周期的方法。在周期信号周期的整数倍上,它的自相关函数可以达到最大值,因此可以不考虑起始时间,而从自相关函数的第一个最大值的位置估计出信号的基音周期,这使自相关函数成为信号基音周期估计的一种工具。 (2)短时自相关函数 语音信号是非平稳的信号,所以对信号的处理都使用短时自相关函数。短时自相关函数是在信号的第N个样本点附近用短时窗截取一段信号,做自相关计算所得的结果 Rm(k)=Σx(n)x(n-k) 式中,n表示窗函数是从第n点开始加入。 3、程序代码 function pitch x=wavread('E:\luyin\wkxp.wav');%读取声音文件 figure(1); stem(x,'.'); %显示声音信号的波形 n=160; %取20ms的声音片段,即160个样点 for m=1:length(x)/n; %对每一帧求短时自相关函数 for k=1:n; Rm(k)=0; for i=(k+1):n; Rm(k)=Rm(k)+x(i+(m-1)*n)*x(i-k+(m-1)*n); end end p=Rm(10:n); %防止误判,去掉前边10个数值较大的点 [Rmax,N(m)]=max(p); %读取第一个自相关函数的最大点end %补回前边去掉的10个点 N=N+10; 计量经济学 自相关性检验实验报告 实验内容:自相关性检验 工业增加值主要由全社会固定资产投资决定。为了考察全社会固 定资产投资对工业增加值的影响,可使用如下模型:Y i = 1 β β+ i X; 其中,X表示全社会固定资产投资,Y表示工业增加值。下表列出了中国1998-2000的全社会固定资产投资X与工业增加值Y的统计数据。 一、估计回归方程 OLS法的估计结果如下: Y=668.0114+1.181861X (2.24039)(61.0963) R2=0.994936,R2=0.994669,SE=951.3388,D.W.=1.282353。 二、进行序列相关性检验 (1)图示检验法 通过残差与残差滞后一期的散点图可以判断,随机干扰项存在正序列相关性。 (2)回归检验法 一阶回归检验 e=0.356978e1-t+εt t 二阶回归检验 e=0.572433e1-t-0.607831e2-t+εt t 可见:该模型存在二阶序列相关。 (3)杜宾-瓦森(D.W)检验法 由OLS法的估计结果知:D.W.=1.282353。本例中,在5%的显 =1.22,著性水平下,解释变量个数为2,样本容量为21,查表得d l d u=1.42,而D.W.=1.282353,位于下限与上限之间,不能确定相关性。(4)拉格朗日乘数(LM)检验法 F-statistic 6.662380 Probability 0.007304 Test Equation: Dependent Variable: RESID Method: Least Squares Date: 12/26/09 Time: 22:55 X 0.005520 0.015408 0.358245 0.7246 RESID(-1) 0.578069 0.195306 2.959807 0.0088 Adjusted R-squared 0.340473 S.D. dependent var 927.2503 S.E. of regression 753.0318 Akaike info criterion 16.25574 Sum squared resid 9639967. Schwarz criterion 16.45469 Log likelihood -166.6852 F-statistic 4.441587 由上表可知:含二阶滞后残差项的辅助回归为: e=-35.61516+0.05520X+0.578069e1-t-0.617998e2-t t (-0.1507) (0.3582) (2.9598) (-3.0757) 序列相关性的检验与修正 案例:书本P115进口与国内生产总值的关系。 一检验 准备工作:建立工作文件,导入数据。采用OLS方法建立进口方程。在命令框输入: equation Eq01.ls m c gdp 建立残差序列 在命令框输入: series e=resid 建立残差序列的滞后一期序列 在命令框输入: series e_lag1=resid(-1) 方法1:利用两个残差序列画图、观察。 方法2:查看回归方程的DW值=0.628,存在序列相关。方法3:LM检验 在命令框输入: equation Eq02.ls e c gdp e(-1) e(-2) 在命令框输入:Scalar lm1= @obs(e(-2))*eq02.@r2 可得LM1=15.006 在命令框输入:scalar chi1=@qchisq(0.95,2) 可得chi1=5.99 可以判定模型存在2阶序列相关。 简便方法:在方程eq01窗口中点击View/Residual Test/Series Correlation LM Test,并选择滞后期为2,则会得到如下图所示的信息。 注:LM计算结果与上面有差异,因为这里的辅助回归所采用的resid(-1)、resid(-2)的缺失值用0补齐。 检验是否存在更高阶的序列相关。继续在命令框输入: equation Eq03.ls e c gdp e(-1) e(-2) e(-3) 在命令框输入:Scalar lm2= @obs(e(-3))*eq03.@r2 可得LM2=14.58 在命令框输入:scalar chi2=@qchisq(0.95,3) 可得chi2=7.185 仍然存在序列相关性,但由于e(-3)的参数不显著,可认为不存在3阶序列相关。在方程eq01窗口中点击View/Residual Test/Series Correlation LM Test,并选择滞后期为3,则会得到如下图所示的信息。 显然,LM检验的结果拒绝原假设(无序列相关),表明存在序列相关性。 二序列相关性的修正与补救 广义差分法就是广义最小二乘法(GLS),但损失了部分样本观测值,损失的数量依赖于序列相关性的阶数(如一阶序列相关,至少损失1个样本值)。 在实际操作中,往往基于广义差分法完成估计。根据随机扰动项相关系数估计方法的不同,可以分为C-O迭代法和Durbin两步法。 (1)Durbin两步法 第一步,估计随机扰动项的相关系数 根据前面检验可知存在二阶序列相关,因此设定方程为 实验五 自相关性 【实验目的】 掌握自相关性的检验与处理方法。 【实验内容】 利用表5-1资料,试建立我国城乡居民储蓄存款模型,并检验模型的自相关性。 【实验步骤】 一、回归模型的筛选 ⒈相关图分析 SCAT X Y 相关图表明,GDP 指数与居民储蓄存款二者的曲线相关关系较为明显。现将函数初步设定为线性、双对数、对数、指数、二次多项式等不同形式,进而加以比较分析。 ⒉估计模型,利用LS 命令分别建立以下模型 ⑴线性模型: LS Y C X x y 5075.9284.14984?+-= =t (-6.706) (13.862) 2 R =0.9100 F =192.145 S.E =5030.809 ⑵双对数模型:GENR LNY=LOG(Y) GENR LNX=LOG(X) LS LNY C LNX x y ln 9588.20753.8?ln +-= =t (-31.604) (64.189) 2 R =0.9954 F =4120.223 S.E =0.1221 ⑶对数模型:LS Y C LNX x y ln 82.236058.118140?+-= =t (-6.501) (7.200) 2 R =0.7318 F =51.8455 S.E =8685.043 ⑷指数模型:LS LNY C X x y 010005.03185.5?ln += =t (23.716) (14.939) 2 R =0.9215 F =223.166 S.E =0.5049 ⑸二次多项式模型:GENR X2=X^2 LS Y C X X2 21966.05485.4456.2944?x x y +-= =t (3.747) (-8.235) (25.886) 2 R =0.9976 F =3814.274 S.E =835.979 ⒊选择模型 比较以上模型,可见各模型回归系数的符号及数值较为合理。各解释变量及常数项都通过了t 检验,模型都较为显著。除了对数模型的拟合优度较低外,其余模型都具有高拟合优度,因此可以首先剔除对数模型。 比较各模型的残差分布表。线性模型的残差在较长时期内呈连续递减趋势而后又转为连续递增趋势,指数模型则大体相反,残差先呈连续递增趋势而后又转为连续递减趋势,因此,可以初步判断这两种函数形式设置是不当的。而且,这两个模型的拟合优度也较双对数模型和二次多项式模型低,所以又可舍弃线性模型和指数模型。双对数模型和二次多项式模型都具有很高的拟合优度,因而初步选定回归模型为这两个模型。 二、自相关性检验 ⒈DW 检验; ⑴双对数模型 因为n =21,k =1,取显著性水平α=0.05时,查表得L d =1.22,U d =1.42,而0<0.7062=DW 《时间序列分析方法》 学院:理学院 专业:经济数学 姓名:郑维竟 学号:201046800316 D W -检验法在自相关性检验中的应用 摘要:在一阶自回归模型的计算结果中,往往会产生残差,这时我们就需要对残差值进行检验,当然对残差检验的方法很多,每种检验方法都有自己的优点和局限,本文介绍一种相对来说比较易懂,易操作,效果好的检验方法,即杜宾-瓦特森检验法。 关键词:D W -检验 自相关 应用 1.自相关性产生的原因 自相关又称序列相关,是指总体回归模型的随机误差项之间存在相关关系。即不同观测点上的误差项彼此相关。 自相关产生的原因有很多,一般认为主要有一下几种,经济变量惯性的作用引起随机误差项自相关,经济行为的滞后性引起随机误差项自相关,一些随机偶然因素的干扰引起随机误差项自相关,模型设定误差引起随机误差项自相关,观测数据处理引起随机误差项序列相关。 一般经验告诉我们,对于采用时间序列数据作样本的计量经济学问题,由于在不同样本点上解释变量以外的其他因素在时间上的连续性,带来它们对被解释变量的影响的连续性,所以往往存在序列相关性。 2.-D W 检验的推导 -D W 检验是J.Durbin(杜宾)和G .S.Watson(瓦特森)于1951年提出的一种适用于小样本的检验方法。-D W 检验只能用于检验随机误差项具有一阶自回归形式的自相关问题。这种检验方法是建立经济计量模型中最常用的方法,一般的计算机软件都可以计算出-D W 检验值。它仅限于一阶自回归形式,即1t t t u u ρε-=+这种检验方法如下: 提出原假设0:0H ρ=,u 不是一阶自相关;备择假设1:0H ρ≠,u 具有一阶自相关。 为检验原假设,构造D W -统计量,记作DW 或d () 2 12 21 n t t t n t t e e d e -==-= ∑∑ (2.1) 这个统计量的分子是残差的一阶差分平方和,分母是残差平方和。下面,我们证明d 介于0到4之间。当2d =时,0ρ=,说明t u 无自相关。 对统计量d 展开 () 2 12 21 n t t t n t t e e d e -==-= ∑∑eviews自相关性检验
试验一异方差的检验与修正-时间序列分析
Eviews序列相关性实验报告
计量经济学--自相关性的检验及修正
第十三章 时间序列回归
自相关性检验
【免费下载】eviews自相关性检验
自相关地检验与修正
序列相关的检验和修正
序列相关性检验(上)
时间序列相关性检验-自相关
时间序列分析法原理及步骤
自相关 基音检测
计量经济学自相关性检验实验报告
序列相关性的检验与修正(精)
eviews自相关性检验
自相关检验方法