二分搜索算法(折半查找)原理以及递归(recuition),迭代(iteration)的两种实现源代码
二分搜索算法(折半查找)原理以及递归(recuition),迭代(iteration)的两种实现源代码
折半查找法也称为二分查找法,它充分利用了元素间的次序关系,采用分治策略,可在最坏的情况下用O(log n)完成搜索任务。
【基本思想】
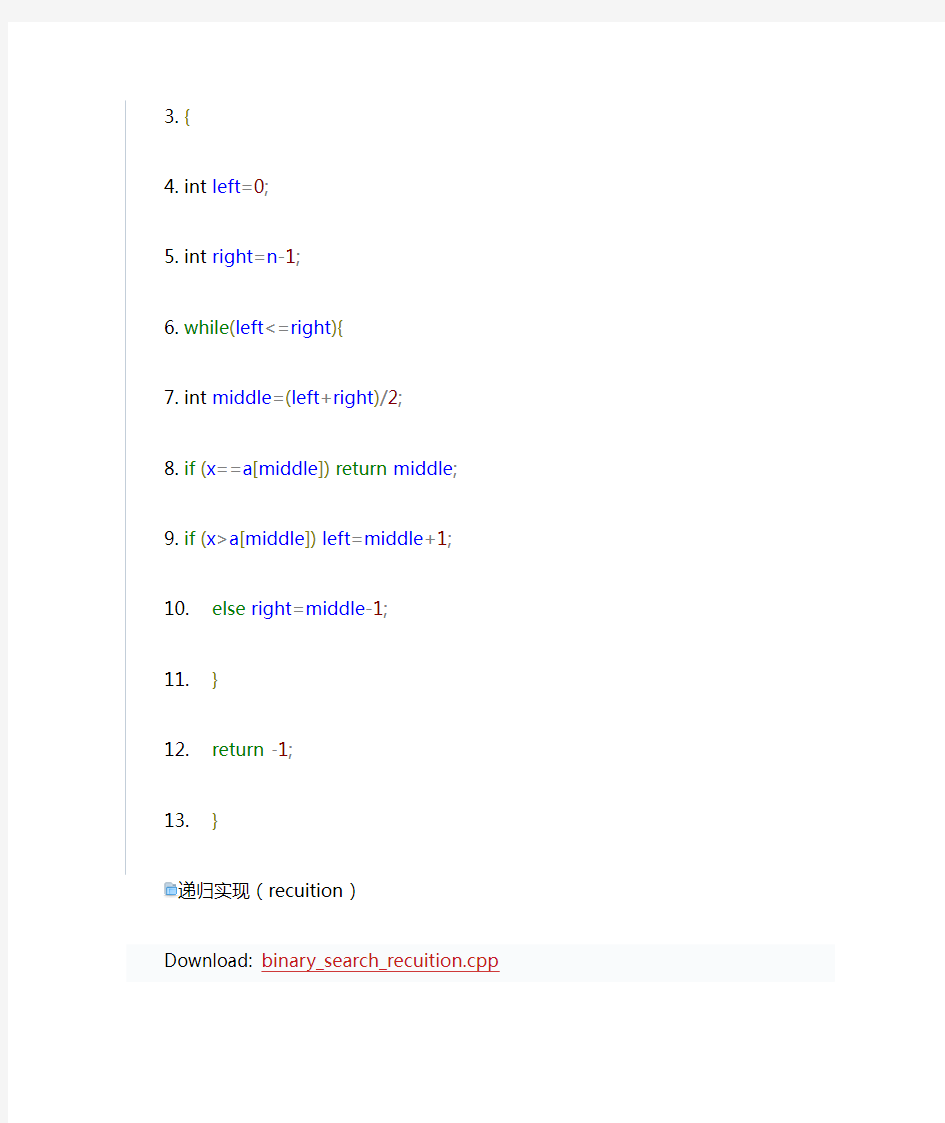
将n个元素分成个数大致相同的两半,取a[n/2]与欲查找的x作比较,如果x=a[n/2]则找到x,算法终止。如果x
二分搜索法的应用极其广泛,而且它的思想易于理解。第一个二分搜索算法早在1946 年就出现了,但是第一个完全正确的二分搜索算法直到1962年才出现。Bentley在他的著作《Writing Correct Programs》中写道,90%的计算机专家不能在2小时内写出完全正确的二分搜索算法。问题的关键在于准确地制定各次查找范围的边界以及终止条件的确定,正确地归纳奇偶数的各种情况,其实整理后可以发现它的具体算法是很直观的。
C++描述
递归实现(recuition)
迭代实现(iteration)
顺序查找法适用于存储结构为顺序或链接存储的线行表
一判断题 1.顺序查找法适用于存储结构为顺序或链接存储的线行表。 2.一个广义表可以为其他广义表所共享。 3.快速排序是选择排序的算法。 4.完全二叉树的某结点若无左子树,则它必是叶子结点。 5.最小代价生成树是唯一的。 6.哈希表的结点中只包含数据元素自身的信息,不包含任何指针。 7.存放在磁盘,磁带上的文件,即可意识顺序文件,也可以是索引文件。8.折半查找法的查找速度一定比顺序查找法快。 二选择题 1.将两个各有n个元素的有序表归并成一个有序表,其最少的比较次数是()。 A. n B. 2n-1 C. 2n D. n-1 2.在文件"局部有序"或文件长度较小的情况下,最佳内部排序的方法是()。 A. 直接插入排序 B.气泡排序 C. 简单选择排序 D. 快速排序 3.高度为K的二叉树最的结点数为()。 A. 2 4.一个栈的输入序列是12345,则占的不可能的输出序列是() A.54321 B. 45321 C.43512 D.12345 5.ISAM文件和V ASM文件属于() A索引非顺序文件 B. 索引顺序文件 C. 顺序文件 D. 散列文件 6. 任何一棵二叉树的叶子结点在先序,中序和后序遍历序列中的相对次序() A. 不发生变化 B. 发生变化 C. 不能确定 D. 以上都不对 7.已知某二叉树的后序遍历序列是dabec, 中序遍历序列是debac , 它的前序遍历是()。 A. acbed B. decab C. deabc D.cedba 三.填空题 1.将下图二叉树按中序线索化,结点的右指针指向(),Y的左指针指向() B D C X E Y 2.一棵树T中,包括一个度为1的结点,两个度为2的结点,三个度为3的结点,四各度为4的结点和若干叶子结点,则T的叶结点数为()
汉语词典快速查询算法研究概要
汉语词典快速查询算法研究 李江波周强陈祖舜 (清华大学智能技术与系统国家重点实验室北京100084) E-mail: jiangbo@https://www.360docs.net/doc/c02940412.html, 摘要:汉语词典查询是中文信息处理系统的重要基础部分,对系统效率有重要的影响。本文对汉语词典查询算法研究作了简要回顾,设计实现了基于双数组TRIE机制的汉语词典查询算法,并提出了基于双编码机制的词典查询算法。最后对两种词典查询机制进行了实验分析。 关键词:汉语词典查询;双数组TRIE;双编码;中文信息处理。 一、引言 在汉语信息处理系统中,汉语词典查询是一个重要的基础环节,在整个处理过程中都需要频繁地访问词典以获得汉语词语知识,因而汉语词典的快速查询是整个处理系统效率的关键所在。针对词典查询方法,前人作了大量工作,并形成了许多汉语词典组织结构和相应的查询算法。 早期的词典组织构造主要是基于传统Hash方法,文献[1]中采用的方法就是一个典型应用,这种方法的关键技术是Hash函数的设计,采用合理的方式来调节数据块的分配,控制分布的均匀性,减少冲突,提高空间利用率,由于涉及到磁盘读取,这种方法在速度上存在较大局限。 文献[2]指出了三种典型的词典查询方法:整词二分法、TRIE索引树法、逐字二分法。以下分别对这三种方法作简要介绍:(1)基于整词二分的词典机制:整词二分方法的词典结构分为词典正文、词索引表、首字散列表等三级。通过首字散列表的哈希定位和词索引表,很容易确定指定词在词典正文中的可能位置范围,进而在词典正文中通过整词二分进行定位。这种算法的数据结构简单、占用空间小,构建及维护也简单易行,但由于采用全词匹配的查询过程,效率较为低下。(2)基于TRIE索引树的词典机制:TRIE索引树是一种以树的多重链表形式表示的键树,基于TRIE索引树的词典机制由首字散列表和TRIE索引树结点两部分组成。TRIE索引树的优点是分词应用中,在对被切分语句的一次扫描过程中,不需预知待查询词的长度,沿着树链逐字匹配即可;缺点是它的构造和维护比较复杂,而且都是单词树枝,浪费了一定的空间。(3)基于逐字二分法的查询机制:基于逐字二分法的查询机制是对前两种词典机制的改进方案,一方面,从组织结构上,逐字二分与整词二分的词典结构完全一样;另一方面,逐字二分吸收了TRIE索引树的查询优势,即采用的是“逐字匹配”,而不是整词二分的“全词匹配”,这就一定程度地提高了匹配的效率。但由于采用的仍是整词二分的词典结构,使效率的提高受到很大的局限。 文献[3]中提出了基于双字哈希机制的词典查询方法,该方法主要结合了词典中的多字词条(3字词以上)数量少,使用频度低的特点,对基于TRIE索引树的词典机制做出了改进,把TRIE索引树的深度限制为2。其三层结构分别是首字哈希索引,次字哈希索引,剩余字串组。这种查询机制相当于使2字词以下的短词用TRIE索引树机制实现,3字词以上的长词的剩余部分用线性表组织,从而避免了深度搜索,一定程度上提高了查询性能。 此外,文献[4]中提出了一种基于PA TRICIA tree的汉语词典查询机制,这种方法首先使用词条的内码来作为一个关键词位串,然后通过位串比较构造出PATRICIA tree树,树的每个内部节点包括三个数据项:比较位、左指针、右指针,树的叶子节点代表一个词条。查询时根据内部节点选择后继路径,直到叶子节点,该方法的优点是引入了位比较,但是因为树的构造过程是基于内码而非字的,所以不可避免地导致树的深度大大增加,从而造成了效率
随机直接搜索优化算法NLJ辨识算法
随机直接搜索优化算法NLJ 辨识算法 NLJ 优化算法是随机直接搜索优化算法的一种,它是由随机数直接搜索算法算法发展而来,可以有效地解决各种复杂的问题。因其结构简单以及收敛迅速使其在随机搜索算法中始终占有一席之地。这种算法的核心思想是利用收缩变量来缩小搜索域,找到次优解,然后再基于次优解重复上述过程直到最终获得最优解。 假设待辨识的系统模型为: 1110 1 ()(0,1,...,)n n n H s i n a s a s a s a -= =++ ++ (3.1) 其中,01,,...,n a a a 表示待辨识模型的系数值。 该算法主要有以下步骤: Step 1、初始化参数。根据辨识数据,通过手工调整模型参数大致拟合出一个初始模型,确定模型初始参数(0)k i a ,其次,确定参数搜索范围c 。()k i a j 表示参数i a 在第k 次迭代的搜索结果,0,1,...,k p =,j 表示迭代组数,0,1,...,j m =。参数的搜索范围可由设定参数初始值的倍数决定,具体规则如下: 0l i i r ca = ,当 时,1k k k i i i r ca v -=?。 (3.2) 其中,根据经验知识,c 取值为2。 Step 2、计算性能指标。选择如式(3.3)所示的输出误差指标,作为辨识性能指标式,将待辨识的参数带入系统模型,求解估计值()y t 。 0[()()]N t J y t y t ==-∑ (3.3) 其中,()y t 为t 时刻的实际数据。 Step 3、计算参数估计值。在第k 代计算参数估计参数k l a ,其中rand 是在 [0.5,0.5]-之间分布的随机数,k i a 由下式给出: 1()()k k k l i i a j a j rand r -=+? (3.4) 在第k 次迭代计算后,计算m 组性能指标,选择使得性能指标最小的参数值作为下一次迭代的初始值: 11min[(())](0)|k i k k i i J a j a a --= (3.5) Step 4、修改搜索范围。在第k 次搜索前需要根据下式(3.6)对搜索范围进行修正防止局限的搜索范围导致搜索陷入局部极值。 (3.6) 在此处引入变化率η,首先,计算判断每组参数幅值的变化率,并选择变化 3k >1k k k i i i r cr v -=
基于散列表的单片机快速查找算法
1.(1912)《基于散列表的单片机快速查找算法》 源程序代码如下: . /*在IC卡计时收费系统的查找算法中用到了如下数据结构*/ struct f /*刷卡记录的数据结构*/ { unsigned char MemBNum; /*下1条记录的存储块号*/ unsigned char CardID[4]; /*4个字节的IC卡号*/ unsigned char CardType; /*1个字节的卡类型*/ unsigned char FirstTime[2]; /*首次刷卡时间*/ }; /*为了访问的方便,定义如下联合*/ union h { unsigned char Data[8]; /*8个字节的数组*/ struct f Record; /*记录占8个字节*/ }; /*DataRec为联合类型变量*/ union h idata DataRec; /*为了实现存储空间的管理,定义如下全局变量*/ unsigned char MemManage[28]; /*用于存储空间管理的28个内存单元*/ unsigned char NowPoint=0; /*用于存储空间管理的数组指针*/ /*在散列表查找算法中用到了下列函数*/ /*下4个函数为采用I2C总线访问24LC16的函数,由于篇幅原因在本文中未提供原码,读者可参考其它文献*/ /*下4个函数中参数addr为访问24LC16时用到的11位存储地址,返回值指示读写访问是否成功*/ unsigned char wrbyte(unsigned int addr,unsigned char odata); /*向24LC16中写一个字节,该字节在odata中。*/ unsigned char rdbyte(unsigned int addr,unsigned char odata); /*从24LC16中读一个字节,读到字节在odata中。*/ unsigned char wr8byte(unsigned int addr,unsigned char *mtd); /*向24LC16中写8个字节,mtd为写缓冲区首址。*/ unsigned char rd8byte(unsigned int addr,unsigned char *mrd); /*从24LC16中读8个字节,mrd为读缓冲区首址。*/ unsigned char hash(unsigned char *ID); /*链地址法的散列表查找算法程序*/ unsigned char hash_search(union h NowRec); /*哈希(hash)函数*/ unsigned char compare(unsigned char *ID1,unsigned char *ID2); /*关键字比较函数*/ unsigned char req_mem(void); /*存储块分配函数*/ void free_mem(unsigned char MemBNum); /*释放存储块函数*/ unsigned char account(union h OutRec,union h InRec); /*计时消费结帐处理函数,可根据实际情况实现*/ /*功能:采用链地址法的散列表查找算法,包含记录的添加与删除 入口参数(NowRec):待查找的记录 返回值:为0表示无相同关键字记录,将输入记录添加到表尾,为1表示查找成功,结帐并删除该记录*/ unsigned char hash_search(union h NowRec) { unsigned char i,result; /*result为返回的查找结果,result=0查找失败,result=1查找成功*/ unsigned char NowMemBNum; /*当前访问记录的存储块号*/ unsigned char NextMemBNum; /*下1条记录的存储块号*/ unsigned int LastRecAddr; /*链表中上1条已访问记录的首地址或链表首地址*/ unsigned int NowRecAddr; /*链表中当前访问记录的首地址*/ union h ReadRec; /*从24LC16中读到的记录*/ result=0;
折半查找算法及程序实现教案
对分查找算法及程序实现 一、设计思想 对分查找是计算机科学中的一个基础算法。对于一个基础算法的学习,同样可以让学生在一定的情境下,经历分析问题、确定算法、编程求解等用计算机解决问题的基本过程。本堂课以一个游戏暖场,同时激活学生的思维,引导学生去探索游戏或生活背后的科学原理。为了让学生在教师的引导下能自我解析算法的形成过程,本课分解了问题动作,找出问题的全部可能情况,在对全部可能情况总结归纳的情况下,得出对分查找的基础算法,最后在程序中得到实现,从而使学生建立起对分查找算法形成的科学逻辑结构。 二、教材分析 本课的课程标准内容: (一)计算机解决问题的基本过程(1)结合实例,经历分析问题、确定算法、编程求解等用计算机解决问题的基本过程,认识算法和程序设计在其中的地位和作用。 (三)算法与问题解决例举 C 查找、排序与问题解决 (2)通过实例,掌握使用数据查找算法设计程序解决问题的方法。 本课的《学科教学指导意见》内容: 基本要求:1.初步掌握对分查找算法。 2.初步掌握对分查找算法的程序实现。
教材内容:第二章算法实例 2.4.3对分查找和第五章5.4查找算法的程序实现,课题定为对分查找算法及程序实现,安排两个课时,第一课时着重是对分查找算法的形成和初步程序实现,第二课时利用对分查找算法解决一些实际问题的程序实现,本教学设计为第一课时。 从《课程标准》和《学科教学指导意见》对本课教学内容的要求来看,要求学生能从问题出发,通过相应的科学步骤形成对分查找的算法。对学生来说,要求通过这一课时的学习能初步掌握或了解对分查找的前提条件、解决问题的对象,明确对分查找算法结构和对分查找的意义。 三、学情分析 学生应该已经掌握程序设计的基本思想,掌握赋值语句、选择语句、循环语句的基本用法和VB基本操作,这节课学生可能会遇到的最大问题是:如何归纳总结对分查找解决不同情况问题的一般规律,鉴于此,在教学中要积极引导学生采取分解动作、比较迁移等学习策略。 四、教学目标 知识与技能:理解对分查找的概念和特点,通过分步解析获取对分查找的解题结构,初步掌握对分查找算法的程序实现。 过程与方法:通过分析多种不同的可能情况,逐步归纳对分查找的基本思想和方法,确定解题步骤。 情感态度与价值观:通过实践体验科学解题的重要性,增强效率意识和全局观念,感受对分查找算法的魅力,养成始终坚持、不断积累才能获得成功的意志品质。 五、重点难点 教学重点和难点:分解并理解对分查找的过程。 六、教学策略与手段
五种查找算法总结
五种查找算法总结 一、顺序查找 条件:无序或有序队列。 原理:按顺序比较每个元素,直到找到关键字为止。 时间复杂度:O(n) 二、二分查找(折半查找) 条件:有序数组 原理:查找过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束; 如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。 如果在某一步骤数组为空,则代表找不到。 这种搜索算法每一次比较都使搜索范围缩小一半。 时间复杂度:O(logn) 三、二叉排序树查找 条件:先创建二叉排序树: 1. 若它的左子树不空,则左子树上所有结点的值均小于它的根结点的值; 2. 若它的右子树不空,则右子树上所有结点的值均大于它的根结点的值; 3. 它的左、右子树也分别为二叉排序树。 原理: 在二叉查找树b中查找x的过程为: 1. 若b是空树,则搜索失败,否则: 2. 若x等于b的根节点的数据域之值,则查找成功;否则: 3. 若x小于b的根节点的数据域之值,则搜索左子树;否则: 4. 查找右子树。 时间复杂度:
四、哈希表法(散列表) 条件:先创建哈希表(散列表) 原理:根据键值方式(Key value)进行查找,通过散列函数,定位数据元素。 时间复杂度:几乎是O(1),取决于产生冲突的多少。 五、分块查找 原理:将n个数据元素"按块有序"划分为m块(m ≤ n)。 每一块中的结点不必有序,但块与块之间必须"按块有序";即第1块中任一元素的关键字都必须小于第2块中任一元素的关键字; 而第2块中任一元素又都必须小于第3块中的任一元素,……。 然后使用二分查找及顺序查找。
二分搜索算法和快速排序算法及分治策略
实验课程:算法分析与设计 实验名称:实验二C/C++环境及递归算法(综合性/设计性) 实验目标: 1、熟悉二分搜索算法和快速排序算法; 2、初步掌握分治算法; 实验任务: 掌握分治策略的概念和基本思想。 实验题: 1、设a[0:n-1]是一个已排好序的数组。请改写二分搜索算法,使得当搜索元素x不在数组中时,返回小于x的最大元素的位置i和大于x的最小元素位置j。当搜索元素在数组中时,I 和j相同,均为x在数组中的位置。设有n个不同的整数排好序后存放于t[0:n-1]中,若存在一个下标i,0≤i<n,使得t[i]=i,设计一个有效的算法找到这个下标。要求算法在最坏的情况下的计算时间为O(logn)。 2、在快速排序中,记录的比较和交换是从两端向中间进行的,关键字较大的记录一次就能交换到后面单元,关键字较小的记录一次就能交换到前面单元,记录每次移动的距离较大,因而总的比较和移动次数较少。 实验设备及环境: PC;C/C++的编程环境Visual C++。 实验主要步骤: (1)明确实验目标和具体任务; (2)理解实验所涉及的分治算法; (3)编写程序并实现分治算法; (4)设计实验数据并运行程序、记录运行的结果; 实验数据及运行结果、实验结果分析及结论: 1、#include
二分法查找算法
二分查找算法是在有序数组中用到的较为频繁的一种算法,在未接触二分查找算法时,最通用的一种做法是,对数组进行遍历,跟每个元素进行比较,其时间为O(n).但二分查找算法则更优,因为其查找时间为O(lgn),譬如数组{1,2,3,4,5,6,7,8,9},查找元素6,用二分查找的算法执行的话,其顺序为: 1.第一步查找中间元素,即5,由于5<6,则6必然在5之后的数组元素中,那么就在{6,7,8,9}中查找, 2.寻找{6,7,8,9}的中位数,为7,7>6,则6应该在7左边的数组元素中,那么只剩下6,即找到了。 二分查找算法就是不断将数组进行对半分割,每次拿中间元素和goal进行比较。 #include
if(index != -1) cout<
几种经典快速块匹配运动估计算法的比较研究
Computer Knowledge and Technology 电脑知识 与技术计算机工程应用技术本栏目责任编辑:梁书 第6卷第32期(2010年11月)几种经典快速块匹配运动估计算法的比较研究 肖敏连 (湖南人文科技学院计算机科学技术系,湖南娄底417000) 摘要:块匹配运动估计算法被许多视频编码标准采用以消除视频序列帧间的时间冗余信息,而运动估计往往是视频编码器中的最耗时的部分,为了加快视频编码速度,许多快速运动估计被相继提出,该文首先对三种经典的快速运动估计算法进行详细的分析,然后把这三种经典快速运动估计算法嵌入到国际视频编码标准H.264/AVC 中,在相同的条件下分别对这三种算法进行性能测试,最后通过比较测试结果对三种经典快速运动估计算法的各自的特点进行了总结。 关键词:块匹配;运动估计;算法 中图分类号:TP312文献标识码:A 文章编号:1009-3044(2010)32-9152-03 Comparative Research on Several Classical Rapid Algorithms of Block-matching Motion Estimation XIAO Min-lian (Department of Computer Science and Technology of Hunan Institute of Humanities,Science and Technology,Loudi 417000,China) Abstract:Block-matching motion estimation was adopted by many video standards to eliminate the temporal redundancy information be -tween successive frames,and usually the motion estimation is the most time consuming part of the whole encoding process.Many rapid motion estimation algorithms are developed in the past twenty years successively.This paper firstly analyzed the three classical rapid block-matching motion estimation algorithms.Then these algorithms were inserted into the H.264/AVC reference software.The three classic rapid block-matching motion estimation algorithms'performances were tested under the same condition.Finally,the characteristics of the three classical rapid algorithms were summarized according to the experimental results. Key words:block-matching;motion estimation;algorithm 对于视频图像序列,如果帧与帧之间不是场景变换,运动幅度不是很大,则两帧之间就会存在很大的时间相关性即时间冗余,可以通过运动估计来消除时间冗余,从而达到视频压缩的目的。块匹配运动估计算法是目前应用最广泛的一种运动估计算法,它已被许多视频编码标准所采纳,如MPEG-1/2/4、H.261、H.263及H.264/AVC 等等[1-2]。最基本的块匹配算法是全搜索(FS ,Full Search )算法,虽然它能通过对搜索范围内所有的点进行搜索而找到最佳匹配点,但其计算量非常巨大,因此寻求快速的块匹配运动估计算法成了视频编码中热点问题。 1几种快速经典运动估计算法的搜索策略 运动搜索的目的就是要寻找最优匹配点。在搜索过程中可以采用上述不同的起点预测方法和块匹配准则来加快搜索速度或提高精度。搜索策略选择适当与否对运动估计的准确性、运动估计的速度都有很大的影响。最简单、最可靠、搜索精度最高的是全搜索法,但由于它计算复杂度高,不易于实时应用,为此人们提出了各种改进的快速算法,下面介绍几种经典的快速运动估计算法。 1.1三步搜索算法 三步搜索算法[3](Three Step Search ,TSS)于1981年由T.KOGA 等人提出,作为 一种简单有效的运动估计技术,被广泛使用在低比特率视频压缩场合中,当最大搜 索距离为7,搜索精度取1个像素,则步长为4、2、1,共需三步即可满足要求,因此 而得名三步法。 TSS 采用一种由粗到细的搜索模式,从搜索窗中心点开始,按一定步长取周围 8个点构成每次搜索的点群,然后进行匹配计算,跟踪到最小块误差MBD 点。 TSS 算法具体执行步骤:①它先确定一个中心点,确定最大搜索长度,然后以 最大搜索长度的1/2作为步长,在中心点周围取离中心点距离为一个步长的8个 点,将这9个点按照匹配原则进行计算,得到最佳匹配点;②然后以上一步得到的 最匹配的块为中心,搜索与此相距为最大搜索长度1/4搜索窗口距离的8个点进 行比较,再通过比较找出最匹配的块;③最后比到步长为1时,找出此时的最佳匹 配点就是最终的结果。 图1为TSS 的一个搜索图示。该算法简单、健壮、性能良好。但第一步的搜索步收稿日期:2010-09-07 基金项目:湖南人文科技学院教改课题(RKJGY0928,RKJGZ0706)资助 作者简介:肖敏连(1969-),女,湖南娄底人,实验师,本科,主要研究方向为多媒体技术。 图1TSS 搜索图示 ISSN 1009-3044Computer Knowledge and Technology 电脑知识与技术Vol.6,No.32,November 2010,pp.9152-9154E-mail:kfyj@https://www.360docs.net/doc/c02940412.html, https://www.360docs.net/doc/c02940412.html, Tel:+86-551-569096356909649152
折半查找法
二分查找是在我们整个数据结构当中一个比较重要的算法,它的思想在我们的实际开发过程当中应用得非常广泛。 在实际应用中,有些数据序列是已经经过排序的,或者可以将数据进行排序,排序后的数据我们可以通过某种高效的查找方式来进行查找,今天要讲的就是折半查找法(二分查找),它的时间复杂度为O(logn),将以下几个方面进行概述 了解二分查找的原理与思想 分析二分查找的时间复杂度 掌握二分查找的实现方法 了解二分查找的使用条件和场景 1 二分查找的原理与思想 在上一个章节当中,我们学习了各种各样的排序的算法,接下来我们就讲解一下针对有序集合的查找的算法—二分查找(Binary Search、折半查找)算法,二分查找呢,是一种非常容易懂的查找算法,它的思想在我们的生活中随处可见,比如说:同学聚会的时候喜欢玩一个游戏——猜数字游戏,比如在1-100以内的数字,让别人来猜从,猜的过程当中会被提示是猜大了还是猜小了,直到猜中为止。这个过程其实就是二分查找的思想的体现,这是个生活中的例子,在我们
现实开发过程当中也有很多应用到二分查找思想的场景。比如说仙现在有10个订单,它的金额分别是6、12 、15、19、24、26、29、35、46、67 请从中找出订单金额为15的订单,利用二分查找的思想,那我们每一次都会与中间的数据进行比较来缩小我们查找的范围,下面这幅图代表了查找的过程,其中low,high代表了待查找的区间的下标范围,mid表示待查找区间中间元素的下标(如果范围区间是偶数个导致中间的数有两个就选择较小的那个) 第一次二分查找 第二次二分查找
第三次二分查找 通过这个查找过程我们可以对二分查找的思想做一个汇总:二分查找针对的是一个有序的数据集合,查找思想有点类似于分治思想。每次都通过跟区间的中间元素对比,将待查找的区间范围缩小为原来的一半,直到找到要查找的元素,或者区间被缩小为0。 一:查找的数据有序 二:每次查找,数据的范围都在缩小,直到找到或找不到为止。 2 二分查找的时间复杂度 我们假设数据大小为n,每次查询完之后,数据就缩减为原来的一半,直到最后的数据大小被缩减为1 n,n/2,n/4,n/8,n/16,n/32,…………,1
搜索方法
1.怎样成为搜索高手——选择适当的查询词 搜索技巧,最基本同时也是最有效的,就是选择合适的查询词。选择查询词是一种经验积累,在一定程度上也有章可循: A.表述准确百度会严格按照您提交的查询词去搜索,因此,查询词表 述准确是获得良好搜索结果的必要前提。 一类常见的表述不准确情况是,脑袋里想着一回事,搜索框里输入 的是另一回事。 例如,要查找2004年国内十大新闻,查询词可以是“2004年国内十 大新闻”;但如果把查询词换成“2004年国内十大事件”,搜索结果就 没有能满足需求的了。 另一类典型的表述不准确,是查询词中包含错别字。 例如,要查找林心如的写真图片,用“林心如写真”,当然是没什么 问题;但如果写错了字,变成“林心茹写真”,搜索结果质量就差得 远了。 不过好在,百度对于用户常见的错别字输入,有纠错提示。您若输 入“林心茹写真”,在搜索结果上方,会提示“您要找的是不是: 林心 如写真”。
B.查询词的主题关联与简练目前的搜索引擎并不能很好的处理自然 语言。因此,在提交搜索请求时,您最好把自己的想法,提炼成简单的,而且与希望找到的信息内容主题关联的查询词。 还是用实际例子说明。某三年级小学生,想查一些关于时间的名人名言,他的查询词是“小学三年级关于时间的名人名言”。 这个查询词很完整的体现了搜索者的搜索意图,但效果并不好。 绝大多数名人名言,并不规定是针对几年级的,因此,“小学三年级” 事实上和主题无关,会使得搜索引擎丢掉大量不含“小学三年级”,但非常有价值的信息;“关于”也是一个与名人名言本身没有关系的词,多一个这样的词,又会减少很多有价值信息;“时间的名人名言”,其中的“的”也不是一个必要的词,会对搜索结果产生干扰;“名人名言”,名言通常就是名人留下来的,在名言前加上名人,是一种不必要的重复。 因此,最好的查询词,应该是“时间名言”。 试着找出下述查询词的问题,并想出更好的能满足搜索需求的查询词: 所得税会计处理问题探讨 周星驰个人档案和所拍的电影
各种查找算法的性能比较测试(顺序查找、二分查找)
算法设计与分析各种查找算法的性能测试
目录 摘要 (3) 第一章:简介(Introduction) (4) 1.1 算法背景 (4) 第二章:算法定义(Algorithm Specification) (4) 2.1 数据结构 (4) 2.2顺序查找法的伪代码 (5) 2.3 二分查找(递归)法的伪代码 (5) 2.4 二分查找(非递归)法的伪代码 (6) 第三章:测试结果(Testing Results) (8) 3.1 测试案例表 (8) 3.2 散点图 (9) 第四章:分析和讨论 (11) 4.1 顺序查找 (11) 4.1.1 基本原理 (11) 4.2.2 时间复杂度分析 (11) 4.2.3优缺点 (11) 4.2.4该进的方法 (12) 4.2 二分查找(递归与非递归) (12) 4.2.1 基本原理 (12) 4.2.2 时间复杂度分析 (13) 4.2.3优缺点 (13) 4.2.4 改进的方法 (13) 附录:源代码(基于C语言的) (15) 声明 ................................................................................................................ 错误!未定义书签。
摘要 在计算机许多应用领域中,查找操作都是十分重要的研究技术。查找效率的好坏直接影响应用软件的性能,而查找算法又分静态查找和动态查找。 我们设置待查找表的元素为整数,用不同的测试数据做测试比较,长度取固定的三种,对象由随机数生成,无需人工干预来选择或者输入数据。比较的指标为关键字的查找次数。经过比较可以看到,当规模不断增加时,各种算法之间的差别是很大的。这三种查找方法中,顺序查找是一次从序列开始从头到尾逐个检查,是最简单的查找方法,但比较次数最多,虽说二分查找的效率比顺序查找高,但二分查找只适用于有序表,且限于顺序存储结构。 关键字:顺序查找、二分查找(递归与非递归)
百度搜索技巧的四个方法
百度搜索技巧的四个方法 大家都知道搜索方法正确后可以大大提高搜索效率,会使大家的工作既省心又省力!网上针对百度搜索技巧的方法也很多,但是我在这里做一个总结,总结出十大百度搜索技巧!这十大百度搜索技巧可以帮助大家更迅速准确的找到相应信息,详情如下: 1、十大百度搜索技巧之(一)—-“-” 百度支持减除不相关的资料的“-”功能,可以用于删除某些无关页面,注意建号前面必须要有空格 例如:“A-B”意思就是说想在搜索A的同时屏蔽关于B的信息 2、十大百度搜索技巧之(二)—-“|“ 百度支持并行搜索功能来搜索例如:“A|B”意思是想要搜索包含A的信息或者包含B的信息比方说你要查询seo和侯瑞男时,可以用”seo|侯瑞男“来搜索,无需分两次查询,百度就会提供跟“|”前后任何相关关键词相关的网站和资料 3、十大百度搜索技巧(三)—-intitle intitle的作用是把搜索范围限定在网页标题中,网页标题往往就是本篇内容的简要概括,将查询内容界定在网页标题中会起到很好的效果。 使用方法:把查询内容中,特别关键的部分用”intitle:“做前缀 例如:想要查找标题中带有Yadid’s World的如何优化长尾关键词的内容,您就可以如下: 可以用[如何优化长尾关键词intitle:Yadid's World]输入搜索框就可以查
到想要得到的结果注意:“intitle:”后面不能有空格 4、十大百度搜索技巧(四)—-site site的作用就是将搜索范围界定在指定网站中,有时我们如果知道某一个站内就有自己想要的东西,那么我们就可以把这个界定界定到这个站内,来提高查询效率 本文由销售技巧培训整理编辑https://www.360docs.net/doc/c02940412.html,/
折半查找算法及程序实现教案
折半查找算法及程序实现 一、教材分析 教学重点:以图示法方式,演示折半查找算法的基本思想。 教学难点:由折半查找算法的思想到程序代码编写的转换,尤其是其中关键性语句的编写是教学中的难点。 二、学情分析 学生应该已经掌握程序设计的基本思想,掌握赋值语句、选择语句、循环语句的基本用法和VB基本操作,这节课学生可能会遇到的最大问题是:如何归纳总结对分查找解决不同情况问题的一般规律,鉴于此,在教学中要积极引导学生采取分解动作、比较迁移等学习策略。 三、教学目标 知识与技能:理解对分查找的概念和特点,通过分步解析获取对分查找的解题结构,初步掌握对分查找算法的程序实现。 过程与方法:通过分析多种不同的可能情况,逐步归纳对分查找的基本思想和方法,确定解题步骤。 情感态度与价值观:通过实践体验科学解题的重要性,增强效率意识和全局观念,感受对分查找算法的魅力,养成始终坚持、不断积累才能获得成功的意志品质。 四、教学策略与手段 1、教学线索:游戏引领---提出对分查找原理--- 解析对分查找的算法特征---实践解决问题。 2、学习线索:分解问题---归纳问题---实践提升,在三个阶段的不断推进中明确对分查找算法,总结规律。 五、教学过程
1、新课导入 (1)热身:游戏(2分钟) 找同学上来找一本上千页电话册里面的一个名字。(课程导入我写的不是很详细,自己设计哦) (2)教师引导:所以我不希望只有他一个人体验这种方便,我们教室里还有一大帮人,其实这种什么不止用于查找电话铺,还可以运用到实际生活中,教室里有这么多人,坦白说,按学校的老方法一个人一个人的数,对所有老师来说都及其费力,那我们想想,是不是数数2368,这样好点对吗?。不要小看这种想法,他其实是非常棒的,他能把解决问题的时间缩短一半,因此我们提出了这种算法 2、新课: 首先我们一起来看一看折半查询算法中的“折半”的含义。 师:何为折半呢? 生:减半;打一半的折扣。 例如,我手里拿着一根绳子,现在我们来进行折半试验,首先拿住绳子的两个端点, 然后从中点的位置进行对折,这样绳子就缩短为原来长度一半,然后将一半的绳子继续执行与刚才相同的操作,使得绳子的长度逐渐的缩短,直到绳子长度短得不能再进行折半了。 师:那什么时候就不能再折半了呢? 生:即绳子的两个端点合二为一为止。 折半查找算法的思想与绳子折半的过程基本相同。下面我们先通过图示来看看折半查找算法究竟是什么? 教学步骤二:分解对分查找算法(5分钟)
各种查找算法性能分析
项目名称:各种查找算法的性能测试 项目成员: 组编号: 完成时间: 目录 前言 (2) 正文 (2) 第一章简介 (2) 1.1顺序查找问题描述 (2) 1.2二分查找问题描述 (2) 第二章算法定义 (2) 2.1顺序查找算法定义 (2) 2.2二分查找算法定义 (3) 第三章测试结果(Testing Results) (5) 3.1 实验结果表 (5) 3.2 散点图记录 (5) 第四章分析和讨论 (6) 4.1顺序查找分析 (6) 4.2二分查找分析 (6) 附录:源代码(基于C语言的) (7) 声明 (13)
前言 查找问题就是在给定的集合(或者是多重集,它允许多个元素具有相同的值)中找寻一个给定的值,我们称之为查找键。 对于查找问题来说,没有一种算法在任何情况下是都是最优的。有些算法速度比其他算法快,但是需要较多的存储空间;有些算法速度非常快,但仅适用于有序数组。查找问题没有稳定性的问题,但会发生其他的问题(动态查找表)。 在数据结构课程中,我们已经学过了几种查找算法,比较有代表性的有顺序查找(蛮力查找),二分查找(采用分治技术),哈希查找(理论上来讲是最好的查找方法)。 第一章:简介(Introduction) 1.1顺序查找问题描述: 顺序查找从表中最后一个记录开始,逐个进行记录的关键字和给定值的比较,若某个记录的关键字和给定值比较相等,则查找成功,找到所查记录;反之,若直至第一个记录,其关键字和给定值比较都不等,则表明表中没有所查记录,查找不成功。 1.2二分查找问题描述: (1)分析掌握折半查找算法思想,在此基础上,设计出递归算法和循环结构两种实现方法的折半查找函数。 (2)编写程序实现:在保存于数组a[i]有序数据元素中查找数据元素k是否存在。数元素k要包含两种情况:一种是数据元素k包含在数组中;另一种是数据元素k不包含在数组中 (3)数组中数据元素的有序化既可以初始赋值时实现,也可以设计一个排序函数实现。(4)根据两种方法的实际运行时间,进行两种方法时间效率的分析对比。 第二章:算法定义(Algorithm Specification) 2.1顺序查找 从表的一端向另一端逐个进行记录的关键字和给定值(要查找的元素)的比较,若某个记录的关键字和给定值比较相等,则查找成功,找到所查找记录;反之,若直至第一个记录,其关键
二分查找算法详解
二分查找算法详解 二分查找算法,是一种在有序数组中查找某一特定元素的搜索算法。 注意两点: (1)有序:查找之前元素必须是有序的,可以是数字值有序,也可以是字典序。为什么必须有序呢?如果部分有序或循环有序可以吗? (2)数组:所有逻辑相邻的元素在物理存储上也是相邻的,确保可以随机存取。 算法思想: 搜素过程从数组的中间元素开始,如果中间元素正好是要查找的元素,则搜素过程结束;如果某一特定元素大于或者小于中间元素,则在数组大于或小于中间元素的那一半中查找,而且跟开始一样从中间元素开始比较。如果在某一步骤数组为空,则代表找不到。这种搜索算法每一次比较都使搜索范围缩小一半。 这里我们可以看到: (1) 如果查找值和中间值不相等的时候,我们可以确保可以下次的搜索范围可以缩小一半,正是由于所有元素都是有序的这一先决条件 (2) 我们每次查找的范围都是理应包含查找值的区间,当搜索停止时,如果仍未查找到,那么此时的搜索位置就应该是查找值应该处于的位置,只是该值不在数组中而已算法实现及各种变形: 1. 非降序数组A, 查找任一个值==val的元素,若找到则返回下标位置,若未找到则返回-1 2. 非降序数组A, 查找第一个值==val的元素,若找到则返回下标位置,若未找到则返回-1 (类似:查找数组中元素最后一个小于val 值的位置) 3. 非降序数组A, 查找最后一个值==val的元素,若找到则返回下标位置,若未找到则返回-1 (类似:查找数组中元素第一个大于val 值的位置) 4. 非降序数组A, 查找任一值为val的元素,保证插入该元素后数组仍然有序,返回可以插入的任一位置 5. 非降序数组A, 查找任一值为val的元素,保证插入该元素后数组仍然有序,返回可以插入的第一个位置 6. 非降序数组A, 查找任一值为val的元素,保证插入该元素后数组仍然有序,返回可以插入的最后一个位置 7. 非降序数组A, 查找任一个值==val的元素,若找到则返回一组下标区间(该区间所有值==val),若未找到则返回-1 8. 非降序字符串数组A, 查找任一个值==val的元素,若找到则返回下标位置,若未找到则返回-1(类似:未找到时返回应该插入点) 9. 循环有序数组中查找== val 的元素,若找到则返回下标位置,若未找到则返回-1 1. 非降序数组A, 查找任一个值==val的元素,若找到则返回下标位置,若未找到则返回-1 1 int binary_search(int* a, int len, int val) 2 { 3 assert(a != NULL && len > 0); 4 int low = 0; 5 int high = len - 1;
双边界直线搜索法
栅格向矢量转换中最为困难的是边界线搜索、拓扑结构生成和多余点去除。一种栅格数据库数据双边界直接搜索算法(Double Boundary Direct Finding,缩写为DBDF),较好地解决了上述问题。 双边界直接搜索算法的基本思想是通过边界提取,将左右多边形信息保存在边界点上,每条边界弧段由两个并行的边界链组成,分别记录该边界弧段的左右多边形编号。边界线搜索采用2×2栅格窗口,在每个窗口内的四个栅格数据的模式可以唯一地确定下一个窗口的搜索方向和该弧段的拓扑关系,这一方法加快了搜索速度,拓扑关系也很容易建立。具体步骤如下: (1)边界点和节点提取:采用2×2栅格阵列作为窗口顺序沿行、列方向对栅格图像全图扫描,如果窗口内四个栅格有且仅有两个不同的编号,则该四个栅格标识为边界点并保留各栅格所有多边形原编号;如果窗口内四个栅格有三个以上不同编号,则标识为节点(即不同边界弧段的交汇点),保证各栅格原多边形编号信息。对于对角线上栅格两两相同的情况,由于造成了多边形的不连通,也作为节点处理P72。 (2)边界线搜索与左右多边形信息记录:边界线搜索是逐个弧段进行的,对每个弧段从一组已标识的四个节点开始,选定与之相邻的任意一组四个边界点和节点都必定属于某一窗口的四个标识点之一。首先记录开始边界点组的两个多边形编号作为该弧段的左右多边形,下一点组的搜索方向则由前点组进入的搜索方向和该点的可能走向决定,每个边界点组只能有两个走向,一个是前点组进入的方向,另一个则可确定为将要搜索后续点组的方向。边界点组只可能有两个走向,即下方和右方,如果该边界点组由其下方的一点组被搜索到,则其后续点组一定在其右方;反之,如果该点在其右方的点组之后被搜索到(即该弧段的左右多边形编号分别为b和a),对其后续点组的搜索应确定为下方,其它情况依次类推。可见双边界结构可以唯一地确定搜索方向,从而大大地减少搜索时间,同时形成的矢量结构带有左右多边形编号信息,容易建立拓扑结构和与属性数据的联系,提高转换的效率。 (3)多余点去除:多余点的去除基于如下思想:在一个边界弧段上连续的三个点,如果在一定程度上可以认为在一条直线上(满足直线方程),则三个点中间一点可以被认为是多余的,予以去除。即满足: 由于在算法上的实现,要尽可能避免出现除零情形,可以转化为以下形式: (x1-x2)(y1-y3)=(x1-x3)(y1-y2) 或 (x1-x3)(y2-y3)=(x2-x3)(y1-y3) 其中(x1,y1),(x2,y2),(x3,y3)为某精度下边界弧段上连续三点的坐标,则(x2,y2)为多余点,可予以去除。 多余点是由于栅格向矢量转换时逐点搜索边界造成的(当边界为或近似为一直线时),这一算法可大量去除多余点,减少数据冗余。