第八章单方程回归模型的几个专题

第八章 单方程回归模型的几个专题
8.1虚拟变量(dummy variable )
8.1.1 概念与用作
在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质等因素的影响。这些因素也应该包括在模型中。为此人们采取了一种构造人工变量的方法,将这些定性变量进行量化,使其能与数值变量一样在回归模型中得以应用。
构造的规则是当某种属性存在时,人工变量取值为1;当某种属性不存在时时,取值为0。在计量经济学中,我们把反映定性因素变化,取值为0或1的人工变量称为虚拟变量。习惯上用D 表示。如:
引入虚拟变量的作用主要有三个:1)可以描述定性因素的影响;2)能够正确反映经济变量的相互关系,提高模型的精度;3)便于处理异常数据。当样本资料中存在异常数据时,一般有三种处理方式。一是直接剔除;二是平滑掉;三是设置虚拟变量。
8.1.2 虚拟变量的设置 1、设置规则
1)一个因素多个属性:若定性因素有M 个不同的属性,或相互排斥的类型,在模型中则只能引入M-1个虚拟变量,否则会引起完全多重共线性。
2)多个因素多个属性:每个因素的引入方法均按上述原则。 2、引入方式:
1)加法方式(截距移动) 设有模型,
y t =
+
1
x t +
2
D + u t ,
其中y t ,x t 为定量变量;D 为定性变量。当D = 0 或1时,上述模型可表达为,
D=
1 城镇居民
0 农村居民
D=
1 男性
0 女性 D=
1 就业
0 失业
y t =??
?=+++=++1
)(0
12010D u x D u x t
t t
t βββββ 020
40
60
20
40
60
X Y
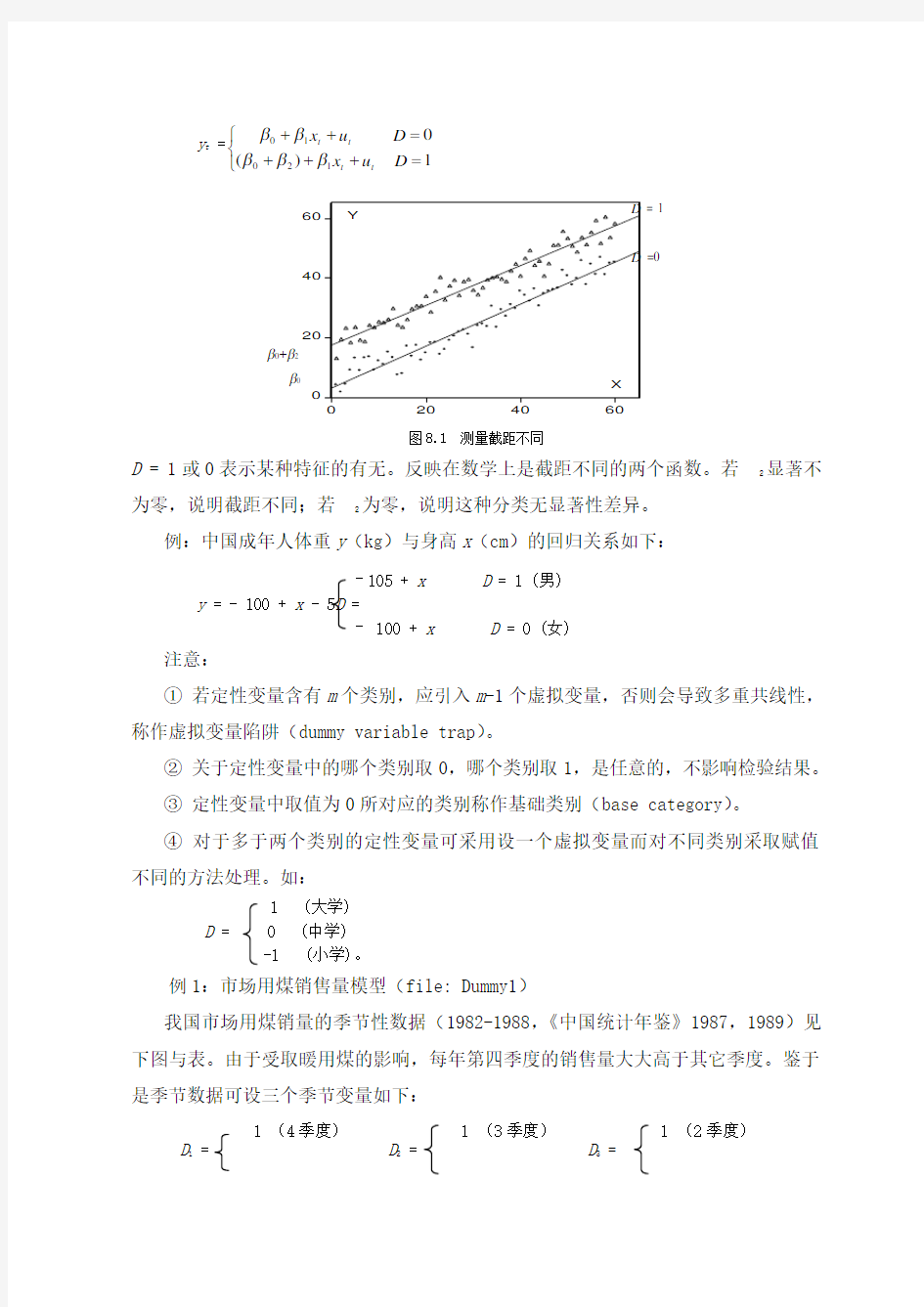
图8.1 测量截距不同
D = 1或0表示某种特征的有无。反映在数学上是截距不同的两个函数。若2
显著不
为零,说明截距不同;若
2
为零,说明这种分类无显著性差异。
例:中国成年人体重y (kg )与身高x (cm )的回归关系如下:
–105 + x D = 1 (男)
y = - 100 + x - 5D =
– 100 + x D = 0 (女)
注意:
① 若定性变量含有m 个类别,应引入m -1个虚拟变量,否则会导致多重共线性,称作虚拟变量陷阱(dummy variable trap )。
② 关于定性变量中的哪个类别取0,哪个类别取1,是任意的,不影响检验结果。 ③ 定性变量中取值为0所对应的类别称作基础类别(base category )。 ④ 对于多于两个类别的定性变量可采用设一个虚拟变量而对不同类别采取赋值不同的方法处理。如:
1 (大学) D = 0 (中学) -1 (小学)。
例1:市场用煤销售量模型(file: Dummy1)
我国市场用煤销量的季节性数据(1982-1988,《中国统计年鉴》1987,1989)见下图与表。由于受取暖用煤的影响,每年第四季度的销售量大大高于其它季度。鉴于是季节数据可设三个季节变量如下:
1 (4季度) 1 (3季度) 1 (2季度) D 1 = D
2 = D
3 =
β0
β0+β2
D = 1 D =0
0 (1, 2, 3季度) 0 (1, 2, 4季度) 0 (1, 3, 4季度)
2500
300035004000450050005500
82
83
84
85
86
87
88
Y
2500
30003500400045005000550082838485868788
Y
2731.03+57.15*T
全国按季节市场用煤销售量数据(file: Dummy1)
数据来源:《中国统计年鉴》1989。注:以季节数据D 1为例,EViews 命令是D1= @seas(4)。
以时间t 为解释变量(1982年1季度取t = 1)的煤销售量(y )模型如下:
y = 2431.20 + 49.00 t + 1388.09 D 1 + 201.84 D 2 + 85.00 D 3 (1)
(26.04) (10.81) (13.43) (1.96) (0.83)
R 2 = 0.95, DW = 1.2, s.e. = 191.7, F=100.4, T =28, t 0.05 (28-5) = 2.07 由于D 2,D 3的系数没有显著性,说明第2,3季度可以归并入基础类别第1季度。于是只考虑加入一个虚拟变量D 1,把季节因素分为第四季度和第一、二、三季度两类。从上式中剔除虚拟变量D 2,D 3,得煤销售量(y )模型如下:
y = 2515.86 + 49.73 t + 1290.91 D 1 (2)
(32.03 (10.63) (14.79)
R 2 = 0.94, DW = 1.4, s.e. = 198.7, F = 184.9, T =28, t 0.05 (25) = 2.06
进一步检验斜率是否有变化,在上式中加入变量t D 1,
y = 2509.07 + 50.22 t + 1321.19 D 1 - 1.95 t D 1 (3)
(28.24) (9.13) (6.85) (-0.17)
R 2 = 0.94, DW = 1.4, s.e. = 202.8, F = 118.5, T =28, t 0.05 (24) = 2.06
由于回归系数 -1.95所对应的t 值是 -0.17,可见斜率未发生变化。因此以模型 (2) 作为最后确立的模型。
若不采用虚拟变量,得回归结果如下,
y = 2731.03 + 57.15 t (4)
(11.6) (4.0)
R 2 = 0.38, DW = 2.5, s.e. = 608.8, T = 28, t 0.05 (26) = 2.06
与(2)式相比,回归式(4)显得很差。
2、乘法方式(斜率变化)
以上只考虑定性变量影响截距,未考虑影响斜率,即回归系数的变化。当需要考虑时,可建立如下模型:
y t =
+
1
x t +
2
D +
3
x t D + u t ,
其中x t 为定量变量;D 为定性变量。当D = 0 或1时,上述模型可表达为,
y t =??
?=++++=++1
)()(0
312010D u x D u x t
t t
t ββββββ 通过检验
3
是否为零,可判断模型斜率是否发生变化。
20
40
60
80
100
20
40
60
X
Y
01020
304050
6070
20
40
60
T Y
图8.5 情形1(不同类别数据的截距和斜率不同) 图8.6 情形2(不同类别数据的截距和斜率不同)
例2:用虚拟变量区别不同历史时期(file:dummy2)
中国进出口贸易总额数据(1950-1984)见上表。试检验改革前后该时间序列的斜率是否发生变化。定义虚拟变量D如下
0 (1950 - 1977)
D =
1 (1978 - 1984)
中国进出口贸易总额数据(1950-1984)(单位:百亿元人民币)
年trade tim
e D time D年trade tim
e
D time D
19500.4151001968 1.0851900
19510.5952001969 1.0692000
19520.6463001970 1.1292100
19530.8094001971 1.2092200
19540.8475001972 1.4692300
1955 1.0986001973 2.2052400
1956 1.0877001974 2.9232500
1957 1.0458001975 2.9042600
1958 1.2879001976 2.6412700
1959 1.49310001977 2.7252800
1960 1.28411001978 3.55029129
19610.90812001979 4.54630130
19620.80913001980 5.63831131
19630.857140019817.35332132
19640.975150019827.71333133
1965 1.184160019838.60134134
1966 1.2711700198412.01035135
1967 1.1221800
以时间time为解释变量,进出口贸易总额用trade表示,估计结果如下:
trade = 0.37 + 0.066 time - 33.96D + 1.20 time D
(1.86) (5.53) (-10.98) (12.42)
0.37 + 0.066 time (D = 0, 1950 - 1977)
=
- 33.59 + 1.27 time (D = 1, 1978 - 1984)
上式说明,改革前后无论截距和斜率都发生了变化。进出口贸易总额的年平均增长量扩大了18倍。
例3:香港季节GDP数据(单位:千亿港元)的拟合(虚拟变量应用, file:dummy6)
1.0
1.5
2.02.5
3.03.5
4.0
90919293949596979899000102
GDP
1.0
1.5
2.02.5
3.03.5
4.0
90919293949596979899000102GDP
1.6952+0.0377*T
1990~1997年香港季度GDP 呈线性增长。1997年由于遭受东南亚金融危机的影响,经济发展处于停滞状态,1998~2002年底GDP 总量几乎没有增长(见上图)。对这样一种先增长后停滞,且含有季节性周期变化的过程简单地用一条直线去拟合显然是不恰当的。为区别不同季节,和不同时期,定义季节虚拟变量D2、D3、D4和区别不同时期的虚拟变量DT 如下(数据见附录):
1 (1998:1~2002:4) DT =
0 (1990:1 ~1997:4)
得估计结果如下:
GDP t = 1.1573 + 0.0668 t + 0.0775 D 2 + 0.2098 D 3 + 0.2349 D 4+ 1.8338 DT - 0.0654 DT
t
(50.8) (64.6) (3.7) (9.9) (11.0) (19.9) (-28.0)
R 2
= 0.99, DW = 0.9, s.e. = 0.05, F=1198.4, T =52, t 0.05 (52-7) = 2.01
对于1990:1 ~1997:4
GDP t = 1.1573 + 0.0668 t + 0.0775 D 2 + 0.2098 D 3 + 0.2349 D 4 对于1998:1~2002:4
GDP t = 2.9911 + 0.0014 t + 0.0775 D 2 + 0.2098 D 3 + 0.2349 D 4
D2=
1 第2季度
0 其它季度
D3=
1 第3季度
0 其它季度 D4=
1 第4季度
0 其它季度
如果不采用虚拟变量拟合效果将很差。
GDP t = 1.6952 + 0.0377 t
(20.6) (13.9)
R 2 = 0.80, DW = 0.3, T =52, t 0.05 (52-2) = 2.01 例:P262略
8.1.3 虚拟变量的特殊应用 1、检验模型的稳定性
设根据同一总体两个样本的估计回归模型分别为: 样本1:1t o t t y b b x u =++ 样本2:1t o t t y a a x u =++
设置虚拟变量:
合并样本,估计模型:00111()()t o t t t t y b a b D b x a b XD u =++++-+
其中:t t t XD x D =?,利用t 检验判断两个虚拟变量系数的显著性,可以得到四种
D=
1 样本
2 0 样本1
检验结果:
1)两个系数均等于零,表明两个回归模型之间的没有显著差异。
2)第一个系数不等于零,第二个系数等于零,说明截距不同,称之为“平行回归”。
3)第一个系数等于零,第二个系数不等于零,说明斜率不同,称之为“汇合回归”。
4)两个系数均不等于零,表明两个模型完全不同,称之为相异回归。
2、分段回归
如:例2。
3、混合回归(即综合使用时序数据和截面数据)
首先检验用不同截面的数据样本建立的模型是否稳定,如果模型稳定,则可合并样本,综合使用时序数据和截面数据。
8.2 模型的设定误差
8.2.1 判断经济模型优劣的标准
1、建模过程:
1)根据经济理论或实践经验,选择变量与函数形式,构建理论模型。
2)依据研究对象的性质,对变量、参数及随机误差项做出相应的先验假定,作为模型检验的标准。
3)收集样本,估计参数。
4)对模型进行理论检验、统计检验及计量经济学准则检验,如果满足先验假设,接受模型,否则应当放弃。
2、判断计量经济模型优劣的基本准则
1)模型就力求简单
2)模型可识别
3)具有较高的按按拟合集成度
4)与理论相一致
5)具有较好的超样本功能
8.2.2 模型设定误差的类型与后果
1、模型遗漏了重要解释变量
如果模型遗漏了重要解释变量,参数的估计值将是有偏的,随机误差的估计值也是有偏的,应用惯常的检验程序,对参数进行显著性检验,容易得出错误的结论,检验的结果不可靠。可以说如果遗漏的重要解释变量的模型,将是一个不可能的模型。
例如:设正确的回归模型为: 122t o t t y b b x b x u =+++ (1) 我们实际采用的模型为:1t o t t y a a x v =++ (2)
假定模型满足古典假定,则参数的OLS 估计值为:112
1()()?()
t
t t
x x y y a x x --=-∑∑
将正确模型代入上式得:
[]
111122212
1()()()()?()t t t t t x x b x x b x x u u a
x x --+-+-=-∑∑
=122
112
2
2
11()()()()()()
t
t
t
t
t
t
x x x x x x u u b b x x x x ----++--∑∑∑∑
取期望,考虑x1为非随机变量,有
122121121
2
2
11()()cov(,)
?()()
var()
t
t
t
x x x x x x E a
b b b b
x x x --=+=+-∑∑ 说明:1)如果遗漏的变量与解释变量相关,即12cov(,)x x 非零,那么1?a
是有偏的,且不一致的。
2)如果遗漏的变量与解释变量无关,1?a
是无偏的,但0?a 是有偏的。 3)随机误差项的方差估计值,也是有偏的。在同样的样本下,(1)、(2)式给出的样本残差不会相同,因此,如果(1)式给出的正确的估计值,(2)式的估计值应是有偏的。
4)参数估计量1?a 的方差是1?b 方差的有偏估计: 2
12
1?var()()
t
a x
x σ=-∑
[]
2
1
21121?var()()1cov(,)/var()t b x x x x x σ=--∑
如前所述1
?var()b 是无偏的,即使两变量不相关,由于两式的残差估计值不相同,
线性回归方程的求法(需要给每个人发)
耿老师总结的高考统计部分的两个重要公式的具体如何应用 第一公式:线性回归方程为???y bx a =+的求法: (1) 先求变量x 的平均值,既1231()n x x x x x n = +++???+ (2) 求变量y 的平均值,既1231()n y y y y y n =+++???+ (3) 求变量x 的系数?b ,有两个方法 法112 1()()?()n i i i n i i x x y y b x x ==--=-∑∑(题目给出不用记忆)[]112222212()()()()...()()()()...()n n n x x y y x x y y x x y y x x x x x x --+--++--=??-+-++-?? (需理解并会代入数据) 法21 2 1()()?()n i i i n i i x x y y b x x ==--=-∑∑(题目给出不用记忆) []1122222212...,...n n n x y x y x y nx y x x x nx ++-?=??+++-??(这个公式需要自己记忆,稍微简单些) (4) 求常数?a ,既??a y bx =- 最后写出写出回归方程???y bx a =+。可以改写为:??y bx a =-(?y y 与不做区分) 例.已知,x y 之间的一组数据: 求y 与x 的回归方程: 解:(1)先求变量x 的平均值,既1(0123) 1.54x = +++= (2)求变量y 的平均值,既1(1357)44 y =+++= (3)求变量x 的系数?b ,有两个方法
法1?b = []11223344222212342222()()()()()()()()()()()()(0 1.5)(14)(1 1.5)(34)(2 1.5)(54)(3 1.5)(74)57(0 1.5)(1 1.5)(2 1.5)(3 1.5)x x y y x x y y x x y y x x y y x x x x x x x x --+--+--+--=??-+-+-+-??--+--+--+--==??-+-+-+-?? 法2?b =[][]11222222222212...011325374 1.5457 ...0123n n n x y x y x y nx y x x x nx ++-??+?+?+?-??==????+++-+++???? (4)求常数?a ,既525??4 1.577a y bx =-=-?= 最后写出写出回归方程525???77 y bx a x =+=+ 第二公式:独立性检验 两个分类变量的独立性检验: 注意:数据a 具有两个属性1x ,1y 。数 据b 具有两个属性1x ,2y 。数据c 具有两个属性2x ,2y 数据d 具有两个属性2x ,2y 而且列出表格是最重要。解题步骤如下 第一步:提出假设检验问题 (一般假设两个变量不相关) 第二步:列出上述表格 第三步:计算检验的指标 2 2 ()()()()()n ad bc K a b c d a c b d -=++++ 第四步:查表得出结论 例如你计算出2K =9大于表格中7.879,则查表可得结论:两个变量之间不相关概率为0.005,或者可以肯定的说两个变量相关的概率为0.995.或095.50 例如你计算出2K =6大于表格中5.024,则查表可得结论:两个变量之间不相关概率为0.025,或者可以肯定的说两个变量相关的概率为0.995.或097.50 上述结论都是概率性总结。切记事实结论。只是大概行描述。具体发生情况要和实际联系!! !!
面板数据分析简要步骤与注意事项(面板单位根—面板协整—回归分析)
面板数据分析简要步骤与注意事项(面板单位根检验—面板协整—回归分析) 面板数据分析方法: 面板单位根检验—若为同阶—面板协整—回归分析 —若为不同阶—序列变化—同阶建模随机效应模型与固定效应模型的区别不体现为R2的大小,固定效应模型为误差项和解释变量是相关,而随机效应模型表现为误差项和解释变量不相关。先用hausman检验是fixed 还是random,面板数据R-squared值对于一般标准而言,超过0.3为非常优秀的模型。不是时间序列那种接近0.8为优秀。另外,建议回归前先做stationary。很想知道随机效应应该看哪个R方?很多资料说固定看within,随机看overall,我得出的overall非常小0.03,然后within是53%。fe和re输出差不多,不过hausman检验不能拒绝,所以只能是re。该如何选择呢? 步骤一:分析数据的平稳性(单位根检验) 按照正规程序,面板数据模型在回归前需检验数据的平稳性。李子奈曾指出,一些非平稳的经济时间序列往往表现出共同的变化趋势,而这些序列间本身不一定有直接的关联,此时,对这些数据进行回归,尽管有较高的R平方,但其结果是没有任何实际意义的。这种情况称为称为虚假回归或伪回归(spurious regression)。他认为平稳的真正含义是:一个时间序列剔除了不变的均值(可视为截距)和时间趋势以后,剩余的序列为零均值,同方差,即白噪声。因此单位根检验时有三种检验模式:既有趋势又有截距、只有截距、以上都无。 因此为了避免伪回归,确保估计结果的有效性,我们必须对各面板序列的平稳性进行检验。而检验数据平稳性最常用的办法就是单位根检验。首先,我们可以先对面板序列绘制时序图,以粗略观测时序图中由各个观测值描出代表变量的折线是否含有趋势项和(或)截距项,从而为进一步的单位根检验的检验模式做准备。单位根检验方法的文献综述:在非平稳的面板数据渐进过程中,Levin andLin(1993)很早就发现这些估计量的极限分布是高斯分布,这些结果也被应用在有异方差的面板数据中,并建立了对面板单位根进行检验的早期版本。后来经过Levin et al.(2002)的改进,提出了检验面板单位根的LLC法。Levin et al.(2002)指出,该方法允许不同截距和时间趋势,异方差和高阶序列相关,适合于中等维度(时间序列介于25~250之间,截面数介于10~250之间)的面板单位根检验。Im et al.(1997)还提出了检验面板单位根的IPS法,但Breitung(2000)发现IPS法对限定性趋势的设定极为敏感,并提出了面板单位根检验的Breitung法。Maddala and Wu(1999)又提出了ADF-Fisher和PP-Fisher面板单位根检验方法。 由上述综述可知,可以使用LLC、IPS、Breintung、ADF-Fisher和PP-Fisher5种方法进行面板单位根检验。 其中LLC-T、BR-T、IPS-W、ADF-FCS、PP-FCS、H-Z分别指Levin,Lin&Chu t*
【精品】第八章单方程回归模型的几个专题
第八章单方程回归模型的几个专题 8.1虚拟变量(dummyvariable) 8。1。1概念与用作 在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质等因素的影响.这些因素也应该包括在模型中。为此人们采取了一种构造人工变量的方法,将这些定性变量进行量化,使其能与数值变量一样在回归模型中得以应用. 构造的规则是当某种属性存在时,人工变量取值为1;当某种属性不存在时时,取值为0。在计量经济学中,我们把反映定性因素变化,取值为0或1的人工变量称为虚拟变量。习惯上用D表示。如: 引入虚拟变量的作用主要有三个:1)可以描述定性因素的影响;2)能够正确反映经济变量的相互关系,提高模型的精度;3)便于处理异常数据。当样本资料中存在异常数
据时,一般有三种处理方式。一是直接剔除;二是平滑掉;三是设置虚拟变量. 8.1。2虚拟变量的设置 1、设置规则 1)一个因素多个属性:若定性因素有M个不同的属性,或相互排斥的类型,在模型中则只能引入M-1个虚拟变量,否则会引起完全多重共线性。 2)多个因素多个属性:每个因素的引入方法均按上述原则。 2、引入方式: 1)加法方式(截距移动) 设有模型, y t=β0+β1x t+β2D+u t, 其中y t,x t为定量变量;D为定性变量.当D=0或1时,上述模型可表达为,
y t =?? ?=+++=++1 )(0 12010D u x D u x t t t t βββββ 020 40 60 20 40 60 X Y 图8。1测量截距不同 D =1 或0 表示某种特征的有无。反映在数学上是截距不同的两个函数。若β2显著不为零,说明截距不同;若β2为零,说明这种分类无显著性差异。 例:中国成年人体重y (kg)与身高x (cm) 的回归关系如下: –105+xD =1(男) y =—100+x —5D = –100+xD =0(女) 注意: ①若定性变量含有m 个类别,应引入m -1个虚拟变量,否则会导致多重共线性,称作虚拟变量陷阱(dummyvariabletrap )。 ②关于定性变量中的哪个类别取0,哪个类别取1,是任意的,不影响检验结果. ③定性变量中取值为0所对应的类别称作基础类别(basecategory)。 ④对于多于两个类别的定性变量可采用设一个虚拟变量而对不同类别采取赋值不同的方法处理。如: 1(大学) D =0(中学) -1(小学)。 例1:市场用煤销售量模型(file:Dummy1) 我国市场用煤销量的季节性数据(1982-1988,《中国统计年鉴》1987,1989)见下图与表。由于受取暖用煤的影响,每年第四季度的销售量大大高于其它季度。鉴于是季节数据可设三个季节变量如下: 1(4季度)1(3季度)1(2季度) D 1=D 2=D 3= 0(1,2,3季度)0(1,2,4季度)0(1,3,4季度) β0 β0+β2 D =1 D =0
线性回归方程公式证明
112233^ ^^^2 211(,),(,),(,)(,)1,2,3),()()n n i i i i i i n i i i i i i n x y x y x y x y y bx a x i n y bx a y y y a b Q y y bx a y ===+==+-=-=+-∑L L 设有对观察值,两变量符合线生回归设其回归方程为:,把自变量的某一观测值代(入入回归方程得:,此值与实际观测值存在一个差值,此差值称为剩余或误差。现要决定取何值时,才能够使剩余的平方和有最小值,即求11 2 21122 221 1111 22111:,()[()()()]()()()2()()2()()2()() ()2n n n i i i i n n i i i i i i n n n i i i i i i n n i i i i i n i i x x y y n n Q bx a y a bx y y y b x x n a bx y y y b x x a bx y y y a bx y x x b x x y y b x x =============+-=+---+-=+-+-+--+---+-----=--∑∑∑∑∑∑∑∑∑∑∑的最小值知又22 111 122211()()()()()()()()n n i i i i i n n i i i i i i n n i i i i b x x y y n a bx y y y b x x y y x y nx y b x x x n x a y bx ======--++-+----==--=-∑∑∑∑∑∑此式为关于的一元二次方程,当
第三章-经典单方程计量经济学模型教学文稿
第三章 经典单方程计量经济学模型:多元线性回归模型 3—1 解释下列概念 (1)多元线性回归模型 解答:在现实经济活动中往往存在着一个变量受到其他多个变量的影响的现象,表现为在线性回归模型中有多个解释变量,这样的模型被称为多元线性回归模型,多元指多个解释变量。 (2)偏回归系数 解答:在多元回归模型中,每一个解释变量前的参数即为偏回归系数,它测度了当其他解释变量保持不变时,该解释变量增加1个单位对被解释变量带来的平均影响程度。 (3)正规方程组 解答:正规方程组指采用OLS 估计线性回归模型时,对残差平方和关于各参数求偏导,并 令偏导数为零得到的一组方程,其矩阵形式为Y X X X '=' β? (4)调整的多元可决系数 解答:调整的多元可决系数2 R ,又称独院判定系数,是一个用于描述伴随模型中解释变量的增加和多个解释变量对被解释变量的联合影响程度的量。它与2 R 有如下关系: 1 1 ) 1(122-----=k n n R R (5)多重共线性 解答:多重共线性是多元回归中特有的一个概念,指多个解释变量间存在线性相关的情形。如果存在完全的线性相关性,则模型的参数就无法求出,OLS 回归无法进行。 (6)联合假设检验 解答:联合假设检验是相对于单个假设检验来说的,指假设检验中的假设有多个,不止一个。如多元回归中的方程的显著性检验就是一个联合假设检验,而每个参数的t 检验就是单个假设检验。 (7)受约束回归
解答:在世纪经济活动中,常常需要根据经济理论对模型中的变量参数施加一定的约束条件,对模型施加约束条件后进行回归,称为受约束回归。 (8)无约束回归 解答:无约束回归是与受约束回归相当对的一个概念,无需对模型中变量的参数施加约束条件进行的回归称为无约束回归 3—2 观察下列方程并判断其变量是否呈线性?系数是否呈线性?或都是?或都不是? (1)i i i X Y εββ++=3 10 (2)i i i X Y εββ++=log 10 (3)i i i X Y εββ++=ln ln 10 (4)i i i X Y εβββ++=)(210 (5)i i i X Y εββ+= 10 (6)i i i i X Y εββ +-+=)1(10 (7)i i i i X X Y εβββ+++=10 22 110 解答:(1),(2),(3),(7)变量非线性,系数线性: (4)变量线性,系数非线性: (5),(6)变量和系数均为非线性。 3—4 为什么说最小二乘估计量是最优的线性无偏估计量?多元线性回归最小二乘估计的正规方程组,能解出唯一的参数估计的条件是什么? 解答:在多元回归的参数模型中,在模型满足经典假设的条件下,参数的最小二乘估计量具有线性性、无偏性以及最小方差性,所以被称为最有线性无偏估计量(BLUE )。 对于多元线性回归最小二乘估计的正规方程组,能解出唯一的参数估计量的条件是 1)(-'X X 存在,或者说各解释变量间不完全线性相关。
线性回归方程高考题
线性回归方程高考题 1、下表提供了某厂节能降耗技术改造后生产甲产品过程中记录的产量(吨)与相应的生产能耗(吨标准煤)的几组对照数据: 3 4 5 6 2.5 3 4 4.5 (1)请画出上表数据的散点图; (2)请根据上表提供的数据,用最小二乘法求出关于的线性回归方程; (3)已知该厂技改前100吨甲产品的生产能耗为90吨标准煤.试根据(2)求出的线性回归方程,预测生产100吨甲产品的生产能耗比技改前降低多少吨标准煤? (参考数值:)
2、假设关于某设备的使用年限x和所支出的维修费用y(万元)统计数据如下: 使用年限x 2 3 4 5 6 维修费用y 2.2 3.8 5.5 6.5 7.0 若有数据知y对x呈线性相关关系.求: (1) 填出下图表并求出线性回归方程=bx+a的回归系数,; 序号x y xy x2 1 2 2.2 2 3 3.8 3 4 5.5 4 5 6.5 5 6 7.0 ∑ (2) 估计使用10年时,维修费用是多少.
3、某车间为了规定工时定额,需要确定加工零件所花费的时间,为此作了四实试验,得到的数据如下: 零件的个数x(个) 2 3 4 5 加工的时间y(小时) 2.5 3 4 4.5 (1)在给定的坐标系中画出表中数据的散点图; (2)求出y关于x的线性回归方程,并在坐标系中画出回归直线; (3)试预测加工10个零件需要多少时间? (注:
4、某服装店经营的某种服装,在某周内获纯利(元)与该周每天销售这种服装件数之间的一组数据关系如下表: 3 4 5 6 7 8 9 66 69 73 81 89 90 91 已知:. (Ⅰ)画出散点图; (1I)求纯利与每天销售件数之间的回归直线方程. 5、某种产品的广告费用支出与销售额之间有如下的对应数据: 2 4 5 6 8 30 40 60 50 70 (1)画出散点图: (2)求回归直线方程; (3)据此估计广告费用为10时,销售收入的值.
第八章 单方程回归模型的几个专题
第八章 单方程回归模型的几个专题 8.1虚拟变量(dummy variable ) 8.1.1 概念与用作 在实际建模过程中,被解释变量不但受定量变量影响,同时还受定性变量影响。例如需要考虑性别、民族、不同历史时期、季节差异、企业所有制性质等因素的影响。这些因素也应该包括在模型中。为此人们采取了一种构造人工变量的方法,将这些定性变量进行量化,使其能与数值变量一样在回归模型中得以应用。 构造的规则是当某种属性存在时,人工变量取值为1;当某种属性不存在时时,取值为0。在计量经济学中,我们把反映定性因素变化,取值为0或1的人工变量称为虚拟变量。习惯上用D 表示。如: 引入虚拟变量的作用主要有三个:1)可以描述定性因素的影响;2)能够正确反映经济变量的相互关系,提高模型的精度;3)便于处理异常数据。当样本资料中存在异常数据时,一般有三种处理方式。一是直接剔除;二是平滑掉;三是设置虚拟变量。 8.1.2 虚拟变量的设置 1、设置规则 1)一个因素多个属性:若定性因素有M 个不同的属性,或相互排斥的类型,在模型中则只能引入M-1个虚拟变量,否则会引起完全多重共线性。 2)多个因素多个属性:每个因素的引入方法均按上述原则。 2、引入方式: 1)加法方式(截距移动) 设有模型, y t = β0 + β1 x t + β2D + u t , 其中y t ,x t 为定量变量;D 为定性变量。当D = 0 或1时,上述模型可表达为,
y t =?? ?=+++=++1 )(0 12010D u x D u x t t t t βββββ 020 40 60 20 40 60 X Y 图8.1 测量截距不同 D = 1或0表示某种特征的有无。反映在数学上是截距不同的两个函数。若β2显著不为零,说明截距不同;若β2为零,说明这种分类无显著性差异。 例:中国成年人体重y (kg )与身高x (cm )的回归关系如下: –105 + x D = 1 (男) y = - 100 + x - 5D = – 100 + x D = 0 (女) 注意: ① 若定性变量含有m 个类别,应引入m -1个虚拟变量,否则会导致多重共线性,称作虚拟变量陷阱(dummy variable trap )。 ② 关于定性变量中的哪个类别取0,哪个类别取1,是任意的,不影响检验结果。 ③ 定性变量中取值为0所对应的类别称作基础类别(base category )。 ④ 对于多于两个类别的定性变量可采用设一个虚拟变量而对不同类别采取赋值不同的方法处理。如: 1 (大学) D = 0 (中学) -1 (小学)。 例1:市场用煤销售量模型(file: Dummy1) 我国市场用煤销量的季节性数据(1982-1988,《中国统计年鉴》1987,1989)见下图与表。由于受取暖用煤的影响,每年第四季度的销售量大大高于其它季度。鉴于是季节数据可设三个季节变量如下: 1 (4季度) 1 (3季度) 1 (2季度) D 1 = D 2 = D 3 = 0 (1, 2, 3季度) 0 (1, 2, 4季度) 0 (1, 3, 4季度) β0 β0+β2 D = 1 D =0
线性回归方程题型
线性回归方程 1.【2014高考全国2第19题】某地区2007年至2013年农村居民家庭纯收入y(单位:千元)的数据如下表: (Ⅰ)求y关于t的线性回归方程; (Ⅱ)利用(Ⅰ)中的回归方程,分析2007年至2013年该地区农村居民家庭人均纯收入的变化情况,并预测该地区2015年农村居民家庭人均纯收入. 附:回归直线的斜率和截距的最小二乘法估计公式分别为: ()() () 1 2 1 n i i i n i i t t y y b t t ∧ = = -- = - ∑ ∑ ,? ?a y bt =- 2.【2016年全国3】下图是我国2008年至2014年生活垃圾无害化处理量(单位:亿吨)的折线图. 注:年份代码1–7分别对应年份2008–2014. (Ⅰ)由折线图看出,可用线性回归模型拟合y与t的关系,请用相关系数加以说明;
(Ⅱ)建立y 关于t 的回归方程(系数精确到0.01),预测2016年我国生活垃圾无害化处理量. 附注: 参考数据: 7 1 9.32i i y ==∑,7 1 40.17i i i t y ==∑ 0.55=,≈2.646. 参考公式:()() n i i t t y y r --= ∑ 回归方程y a bt =+ 中斜率和截距的最小二乘估计公式分别为: 1 2 1 ()() ()n i i i n i i t t y y b t t ==--= -∑∑ ,=.a y bt - 3.【2015全国1】某公司为确定下一年度投入某种产品的宣传费,需了解年宣传费x (单位:千元)对年销售量y (单位:t )和年利润z (单位:千元)的影响,对近8年的宣传费i x 和年销售量()1,2,,8i y i = 数据作了初步处理,得到下面的散点图及一些统计量的值.
经典单方程计量经济学模型一元线性回归模型
经典单方程计量经济学模型一元线性回归模型
第二章经典单方程计量经济学模型:一元线性回归模型 一、内容提要 本章介绍了回归分析的基本思想与基本方法。首先,本章从总体回归模型与总体回归函数、样本回归模型与样本回归函数这两组概念开始,建立了回归分析的基本思想。总体回归函数是对总体变量间关系的定量表述,由总体回归模型在若干基本假设下得到,但它只是建立在理论之上,在现实中只能先从总体中抽取一个样本,获得样本回归函数,并用它对总体回归函数做出统计推断。 本章的一个重点是如何获取线性的样本回归函数,主要涉及到普通最小二乘法(OLS)的学习与掌握。同时,也介绍了极大似然估计法(ML)以及矩估计法(MM)。 本章的另一个重点是对样本回归函数能否代表总体回归函数进行统计推断,即进行所谓的统计检验。统计检验包括两个方面,一是先检验样本回归函数与样本点的“拟合优度”,第二是检验样本回归函数与总体回归函数的“接近”程度。
后者又包括两个层次:第一,检验解释变量对被解释变量是否存在着显著的线性影响关系,通过变量的t检验完成;第二,检验回归函数与总体回归函数的“接近”程度,通过参数估计值的“区间检验”完成。 本章还有三方面的内容不容忽视。其一,若干基本假设。样本回归函数参数的估计以及对参数估计量的统计性质的分析以及所进行的统计推断都是建立在这些基本假设之上的。其二,参数估计量统计性质的分析,包括小样本性质与大样本性质,尤其是无偏性、有效性与一致性构成了对样本估计量优劣的最主要的衡量准则。Goss-markov定理表明OLS估计量是最佳线性无偏估计量。其三,运用样本回归函数进行预测,包括被解释变量条件均值与个值的预测,以及预测置信区间的计算及其变化特征。 二、典型例题分析 例1、令kids表示一名妇女生育孩子的数目,educ表示该妇女接受过教育的年数。生育率对教育年数的简单回归模型为
第七章单方程计量经济学应用模型
第七章单方程计量经济学应用模型 一、内容题要 本章主要介绍了若干种单方程计量经济学模型的应用模型。包括生产函数模型、需求函数模型、消费函数模型以及投资函数模型、货币需求函数模型等经济学领域常见的函数模型。本章所列举的内容更多得关注了相关函数模型自身的发展状况,而不是计量模型估计本身。其目的,是使学习者了解各函数模型是如何发展而来的,即掌握建立与发展计量经济学应用模型的方法论。 生产函数模型,首先介绍生产函数的几个基本问题,包括它的定义、特征、发展历程等,并对要素的替代弹性、技术进步的相概念进行了归纳。然后分别以要素之间替代性质的描述为线索与以技术要素的描述这线索介绍了生产函数模型的发展,前者包括从线性生产函数、C-D生产函数、不变替代弹性(CES)生产函数、变替代弹性(VES )生产函数、多要素生产函数到超越对数生产函数的介绍;后者包括对技术要素作为一个不变参数的生产函数模型、改进的C-D、CES 生产函数模型、含体现型技术进步的生产函数模型、边界生产函数模型的介绍。最后对各种类型的生产函数的估计以及在技术进步分析中的应用进行了了讨论。 与生产函数模型相仿,需求函数模型仍是从基本概念、基本特性、各种需求函数的类型及其估计方法等方面进行讨论,尤其是对线性支出系统需求函数模型的发展及其估计问题进行了较详细的讨论。 消费函数模型部分,主要介绍了几个重要的消费函数模型及其参数估计问题,包括绝对收入假设消费函数模型、相对收入假设消费函数模型、生命周期假设消费函数模型、持久收入假设消费函数模型、合理预期的消费函数模型适应预期的消费函数模型。并对消费函数的一般形式进行了讨论。 在其他常用的单方程应用模型中主要介绍了投资函数模型与货币需求函数模型,前者主要讨论了加速模型、利润决定的投资函数模型、新古典投资函数模型;后者主要讨论了古典货币学说需求函数模型、Keynes 货币学说需求函数模型、现代货币主义的货币需求函数模型、后Keynes 货币学说需求函数模型等。
多元线性回归模型公式().docx
二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量 y 受 k 个自变量 x 1, x 2 ,..., x k 的影响,其 n 组观测值为( y a , x 1 a , x 2 a ,..., x ka ), a 1,2,..., n 。那么,多元线性回归模型的结构形式为: y a 0 1 x 1a 2 x 2 a ... k x ka a () 式中: 0 , 1 ,..., k 为待定参数; a 为随机变量。 如果 b 0 , b 1 ,..., b k 分别为 0 , 1 , 2 ..., k 的拟合值,则回归方程为 ?= b 0 b 1x 1 b 2 x 2 ... b k x k () 式中: b 0 为常数; b 1, b 2 ,..., b k 称为偏回归系数。 偏回归系数 b i ( i 1,2,..., k )的意义是,当其他自变量 x j ( j i )都固定时,自变量 x i 每变 化一个单位而使因变量 y 平均改变的数值。 根据最小二乘法原理, i ( i 0,1,2,..., k )的估计值 b i ( i 0,1,2,..., k )应该使 n 2 n 2 Q y a y a y a b 0 b 1 x 1a b 2 x 2a ... b k x ka min () a 1 a 1 有求极值的必要条件得 Q n 2 y a y a b 0 a 1 () Q n 2 y a y a x ja 0( j 1,2,..., k) b j a 1 将方程组()式展开整理后得:
Eview面板数据之固定效应模型
Eviews 面板数据之固定效应模型 在面板数据线性回归模型中,如果对于不同的截面或不同的时间序列,只是模型的截距项是不同的,而模型的斜率系数是相同的,则称此模型为固定效应模型。固定效应模型分为三类: 1.个体固定效应模型 个体固定效应模型是对于不同的纵剖面时间序列(个体)只有截距项不同的模型: 2 K it i k kit it k y x u λβ==++∑ (1) 从时间和个体上看,面板数据回归模型的解释变量对被解释变量的边际影响均是相同的,而且除模型的解释变量之外,影响被解释变量的其他所有(未包括在回归模型或不可观测的)确定性变量的效应只是随个体变化而不随时间变化时。 检验:采用无约束模型和有约束模型的回归残差平方和之比构造F 统计量,以检验设定个体固定效应模型的合理性。F 模型的零假设: 01231:0N H λλλλ-===???== () 1(1,(1)1)(1) RRSS URSS N F F N N T K URSS NT N K --= ---+--+: RRSS 是有约束模型(即混合数据回归模型)的残差平方和,URSS 是无约束模型ANCOV A 估计的残差平方和或者LSDV 估计的残差平方和。 实践: 一、数据:已知1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(cp ,不变价格)和人均收入(ip ,不变价格)居民,利用数据(1)建立面板数据(panel data )工作文件;(2)定义序列名并输入数据;(3)估计选择面板模型;(4)面板单位根检验。年人均消费(consume )和人均收入(income )数据以及消费者价格指数(p )分别见表1,2和3。 表1 1996—2002年中国东北、华北、华东15个省级地区的居民家庭人均消费(元)数据
线性回归方程
线性 回归 方程 统计总课时第18课时分课题线性回归方程分课时第1 课时 教学目标了解变量之间的两种关系,了解最小平方法〔最小二乘法〕的思想,会用公式求解回归系数. 重点难点最小平方法的思想,线性回归方程的求解. 线性回归方程 某小卖部为了了解热茶销量与气温之间的关系,随机统计并制作了某6天卖出热茶的杯数与当天气温的对照表: 气温/C ?26 18 13 10 4 -1 杯数20 24 34 38 50 64假设某天的气温是C? -5,那么你能根据这些数据预测这天小卖部卖出热茶的杯数吗? 新课教学 1.变量之间的两类关系: 〔1〕函数关系: 〔2〕相关关系: 2.线性回归方程: 〔1〕散点图: 〔2〕最小平方法〔最小二乘法〕:〔3〕线性相关关系: 〔4〕线性回归方程、回归直线:3.公式: [来源:https://www.360docs.net/doc/ca14252328.html,] 4.求线性回归方程的一般步骤: x y O
例题剖析 例1 下表为某地近几年机动车辆数与交通事故数的统计资料,请判断机动车辆数与交通事故数之间是否具有线性相关关系,如果具有线性相关关系,求出线性回归方程;如果不具有线性相关关系,说明理由.[来源:学&科&网] 机动车辆数x/千辆95 110 112 120 129 135 150 180 交通事故数y/千件 6.2 7.5 7.7 8.5 8.7 9.8 10.2 13 [来源:1ZXXK]
思考:如图是1991年到2000年北京地区年平均气温〔单位:C 〕与年降雨量〔单位:mm 〕的散点图,根据此图能求出它的回归直线方程吗?如果能,此时求得的回归直线方程有意义吗? 巩固练习 1x /百万元 [来 源:Z+xx+https://www.360docs.net/doc/ca14252328.html,] 2 4 5 6 8 y /百万元 30 40 60 50 70 〔1〕画出散点图; 〔2〕求线性回归方程. 课堂小结 了解变量之间的两种关系,了解最小平方法的思想,会用公式求解回归系数. x y 100 200 300 400 500 600 12.40 12.60 12.80 13.00
第二讲 面板数据线性回归模型
第二讲 面板数据线性回归模型估计、检验和应用 第一节 单因素误差面板数据线性回归模型 对于面板数据y i 和X i ,称 it it it y αε′=++X βit i it u εξ=+ 1,,; 1,,i N t T =="" 为单因素误差面板数据线性回归模型,其中,i ξ表示不可观测的个体特殊效应,it u 表示剩余的随机扰动。 案例:Grunfeld(1958)建立了下面的投资方程: 12it it it it I F C αββε=+++ 这里,I it 表示对第i 个企业在t 年的实际总投资,F it 表示企业的实际价值(即公开出售的股份),C it 表示资本存量的实际价值。案例中的数据是来源于10个大型的美国制造业公司1935-1954共20年的面板数据。 在EViews6中设定面板数据(GRUNFELD.wf1) Eviews6 中建立面板数据 EViews 中建立单因素固定效应模型
1.1 混合回归模型 1 面板数据混合回归模型 假设1 ε ~ N (0, σ2I NT ) 对于面板数据y i 和X i ,无约束的线性回归模型是 y i = Z i δi + εi i =1, 2, … , N (4.1) 其中' i y = ( y i 1, … , y iT ),Z i = [ ιT , X i ]并且X i 是T×K 的,' i δ是1×(K +1)的,εi 是T×1的。 注意:各个体的回归系数δi 是不同的。 如果面板数据可混合,则得到有约束模型 y = Z δ + ε (4.2) 其中Z ′ = (' 1Z ,' 2Z , … ,'N Z ),u ′ = ('1ε,'2ε, … ,' N ε)。 2 混合回归模型的估计 当满足可混合回归假设时, ()1''?Z Z Z Y ?=δ 在假设1下,对于Grunfeld 数据,基于EViews6建立的混合回归模型 3 面板数据的可混合性检验 假设检验原理:基于OLS/ML 估计,对约束条件的检验。 (1) 面板数据可混合的检验 推断面板数据可混合的零假设是: 1 H :对于所有的i 都有δi = δ. 检验约束条件的统计量是Chow 检验的F 统计量
多元线性回归的计算方法
多元线性回归的计算方法 摘要 在实际经济问题中,一个变量往往受到多个变量的影响。例如,家庭 消费支出,除了受家庭可支配收入的影响外,还受诸如家庭所有的财富、物价水平、金融机构存款利息等多种因素的影响,表现在线性回归模型中的解释变量有多个。这样的模型被称为多元线性回归模型。 多元线性回归的基本原理和基本计算过程与一元线性回归相同,但由 于自变量个数多,计算相当麻烦,一般在实际中应用时都要借助统计软件。这里只介绍多元线性回归的一些基本问题。 但由于各个自变量的单位可能不一样,比如说一个消费水平的关系式中,工资水平、受教育程度、职业、地区、家庭负担等等因素都会影响到消费水平,而这些影响因素(自变量)的单位显然是不同的,因此自变量前系数的大小并不能说明该因素的重要程度,更简单地来说,同样工资收入,如果用元为单位就比用百元为单位所得的回归系数要小,但是工资水平对消费的影响程度并没有变,所以得想办法将各个自变量化到统一的单位上来。前面学到的标准分就有这个功能,具体到这里来说,就是将所有变量包括因变量都先转化为标准分,再进行线性回归,此时得到的回归系数就能反映对应自变量的重要程度。这时的回归方程称为标准回归方程,回归系数称为标准回归系数,表示如下: Zy=β1Zx1+β2Zx2+…+βkZxk 注意,由于都化成了标准分,所以就不再有常数项a 了,因为各自变量都取平均水平时,因变量也应该取平均水平,而平均水平正好对应标准分0,当等式两端的变量都取0时,常数项也就为0了。 多元线性回归模型的建立 多元线性回归模型的一般形式为 Yi=β0+β1X1i+β2X2i+…+i i i i h x υβ+ =1,2,…,n 其中 k 为解释变量的数目,j β=(j=1,2,…,k)称为回归系数 (regression coefficient)。上式也被称为总体回归函数的随机表达式。它的非随机表达式为 E(Y∣X1i,X2i,…Xki,)=β0+β1X1i+β2X2i+…+βkXki βj 也被称为偏回归系数(partial regression coefficient) 多元线性回归的计算模型
第三讲 面板数据线性回归模型_n
第三讲 面板数据线性回归模型估计、检验和应用 单因素误差面板数据线性回归模型 对于面板数据y i 和X i ,称 it it it y u α′=++X βit i it u v μ=+ 1,,;1,,i N t T =="" 为单因素误差面板数据线性回归模型,其中,i μ表示不可观测的个体特殊效应,it v 表示剩余的随机扰动。 案例:Grunfeld(1958)建立了下面的投资方程: 12it it it it I F C u αββ=+++ 这里,I it 表示对第i 个企业在t 年的实际总投资,F it 表示企业的实际价值(即公开出售的股份),C it 表示资本存量的实际价值。案例中的数据是来源于10个大型的美国制造业公司1935-1954共20年的面板数据。 在Stata 中设定面板数据(GRUNFELD.dta ) . xtset FN YR panel variable: FN (strongly balanced) time variable: YR, 1935 to 1954 delta: 1 unit 混合回归模型 假设1 u ~ N (0, σ2I NT ) 对于面板数据y i 和X i ,无约束的线性回归模型是 y i = Z i δi + u i i =1, 2, … , N (4.1) 其中'i y = ( y i 1, … , y iT ),Z i = [ ιT , X i ]并且X i 是T×K 的,'i δ是1×(K +1)的,u i 是T×1的。 注意:各个体的回归系数δi 是不同的。 如果面板数据可混合,则得到有约束模型 y = Z δ + u (4.2) 其中Z ′ = ('1Z ,'2Z , … ,'N Z ),u ′ = ('1u ,'2u , … ,' N u )。 在假设1下,对于Grunfeld 数据,建立的混合回归模型 Stata 命令:. regress I F C
线性回归方程
2.4线性回归方程 重难点:散点图的画法,回归直线方程的求解方法,回归直线方程在现实生活与生产中的应. 考纲要求:①会作两个有关联变量数据的散点图,会利用散点图认识变量间的相关关系. ②了解最小二乘法的思想,能根据给出的线性回归方程系数公式建立线性回归方程. 经典例题:10.有10名同学高一(x)和高二(y)的数学成绩如下: ⑴画出散点图; ⑵求y对x的回归方程。 当堂练习: 1.下表是某小卖部一周卖出热茶的杯数与当天气温的对比表:若热茶杯数y与气温x近似地满足线性关系,则其关系式最接近的是() . .
. . A . B . C . D . 2.线性回归方程表示的直线必经过的一个定点是( ) A . B . C . D . 3.设有一个直线回归方程为 ,则变量x 增加一个单位时 ( ) A . y 平均增加 1.5 个单位 B. y 平均增加 2 个单位 C . y 平均减少 1.5 个单位 D. y 平均减少 2 个单位 4.对于给定的两个变量的统计数据,下列说确的是( ) A .都可以分析出两个变量的关系 B .都可以用一条直线近似地表示两者的关系 C .都可以作出散点图 D. 都可以用确定的表达式表示两者的关系 5.对于两个变量之间的相关系数,下列说法中正确的是( ) A .|r|越大,相关程度越大 B .|r|,|r|越大,相关程度越小,|r|越小,相关程度越大 杯 数 24 34 39 51 63
C.|r|1且|r|越接近于1,相关程度越大;|r|越接近于0,相关程度越小D.以上说法都不对 6.“吸烟有害健康”,那么吸烟与健康之间存在什么关系() A.正相关B.负相关C.无相关D.不确定 7.下列两个变量之间的关系不是函数关系的是() A.角度与它的余弦值B.正方形的边长与面积 C.正n边形的边数和顶点角度之和D.人的年龄与身高 8.对于回归分析,下列说法错误的是() A.变量间的关系若是非确定性关系,则因变量不能由自变量唯一确定 B.线性相关系数可正可负 C.如果,则说明x与y之间完全线性相关 D.样本相关系数 9.为了考察两个变量x和y之间的线性相关性,甲、乙两个同学各自独立的做10次和15V次试验,并且利用线性回归方法,求得回归直线分布为和,已知 . .
多元线性回归模型公式
二、多元线性回归模型 在多要素的地理环境系统中,多个(多于两个)要素之间也存在着相互影响、相互关联的情况。因此,多元地理回归模型更带有普遍性的意义。 (一)多元线性回归模型的建立 假设某一因变量 y 受k 个自变量x 1,x 2,...,x k 的影响,其n 组观测值为(y a ,x 1a ,x 2a ,...,x ka ), a 1,.2..,n 。那么,多元线性回归模型的结构形式为: y a 1x 1a 2x 2a ... k x ka a (3.2.11) 式中: 0,1 ,..., k 为待定参数; a 为随机变量。 如果b 0,b 1,...,b k 分别为 0,1, 2 ... , k 的拟合值,则回归方程为 ?=b 0 b 1x 1 b 2x 2 ... b k x k (3.2.12) 式中: b 0为常数; b 1,b 2,...,b k 称为偏回归系数。 偏回归系数b i (i1,2,...,k )的意义是,当其他自变量 x j (j i )都固定时,自变量 x i 每 变化一个单位而使因变 量 y 平均改变的数值。 根据最小二乘法原理, i (i 0,1,2,...,k )的估计值b i (i 0,1,2,...,k )应该使 n 2 n 2 Q y a y a y a b 0 b1x1a b2x2a ... bkxk a min (3.2.13) a 1 a1 有求极值的必要条件得 Q n 2 y a y a 0 b 0 a 1 (3.2.14) Q n 2 y a yaxja 0(j 1,2,...,k) b j a1 将方程组(3.2.14)式展开整理后得:
计量经济学 第三章、经典单方程计量经济学模型:多元线性回归模型
第三章、经典单方程计量经济学模型:多元线性回归模型 一、内容提要 本章将一元回归模型拓展到了多元回归模型,其基本的建模思想与建模方法与一元的情形相同。主要内容仍然包括模型的基本假定、模型的估计、模型的检验以及模型在预测方面的应用等方面。只不过为了多元建模的需要,在基本假设方面以及检验方面有所扩充。 本章仍重点介绍了多元线性回归模型的基本假设、估计方法以及检验程序。与一元回归分析相比,多元回归分析的基本假设中引入了多个解释变量间不存在(完全)多重共线性这一假设;在检验部分,一方面引入了修正的可决系数,另一方面引入了对多个解释变量是否对被解释变量有显著线性影响关系的联合性F检验,并讨论了F检验与拟合优度检验的内在联系。 本章的另一个重点是将线性回归模型拓展到非线性回归模型,主要学习非线性模型如何转化为线性回归模型的常见类型与方法。这里需要注意各回归参数的具体经济含义。 本章第三个学习重点是关于模型的约束性检验问题,包括参数的线性约束与非线性约束检验。参数的线性约束检验包括对参数线性约束的检验、对模型增加或减少解释变量的检验以及参数的稳定性检验三方面的内容,其中参数稳定性检验又包括邹氏参数稳定性检验与邹氏预测检验两种类型的检验。检验都是以F检验为主要检验工具,以受约束模型与无约束模型是否有显著差异为检验基点。参数的非线性约束检验主要包括最大似然比检验、沃尔德检验与拉格朗日乘数检验。它们仍以估计无约束模型与受约束模型为基础,但以最大似然原 χ分布为检验统计量理进行估计,且都适用于大样本情形,都以约束条件个数为自由度的2 的分布特征。非线性约束检验中的拉格朗日乘数检验在后面的章节中多次使用。 二、典型例题分析 例1.某地区通过一个样本容量为722的调查数据得到劳动力受教育的一个回归方程为36 .0 . + = - 10+ 094 medu fedu .0 sibs edu210 131 .0 R2=0.214 式中,edu为劳动力受教育年数,sibs为该劳动力家庭中兄弟姐妹的个数,medu与fedu分别为母亲与父亲受到教育的年数。问