cpu核心数和线程数的使用情况
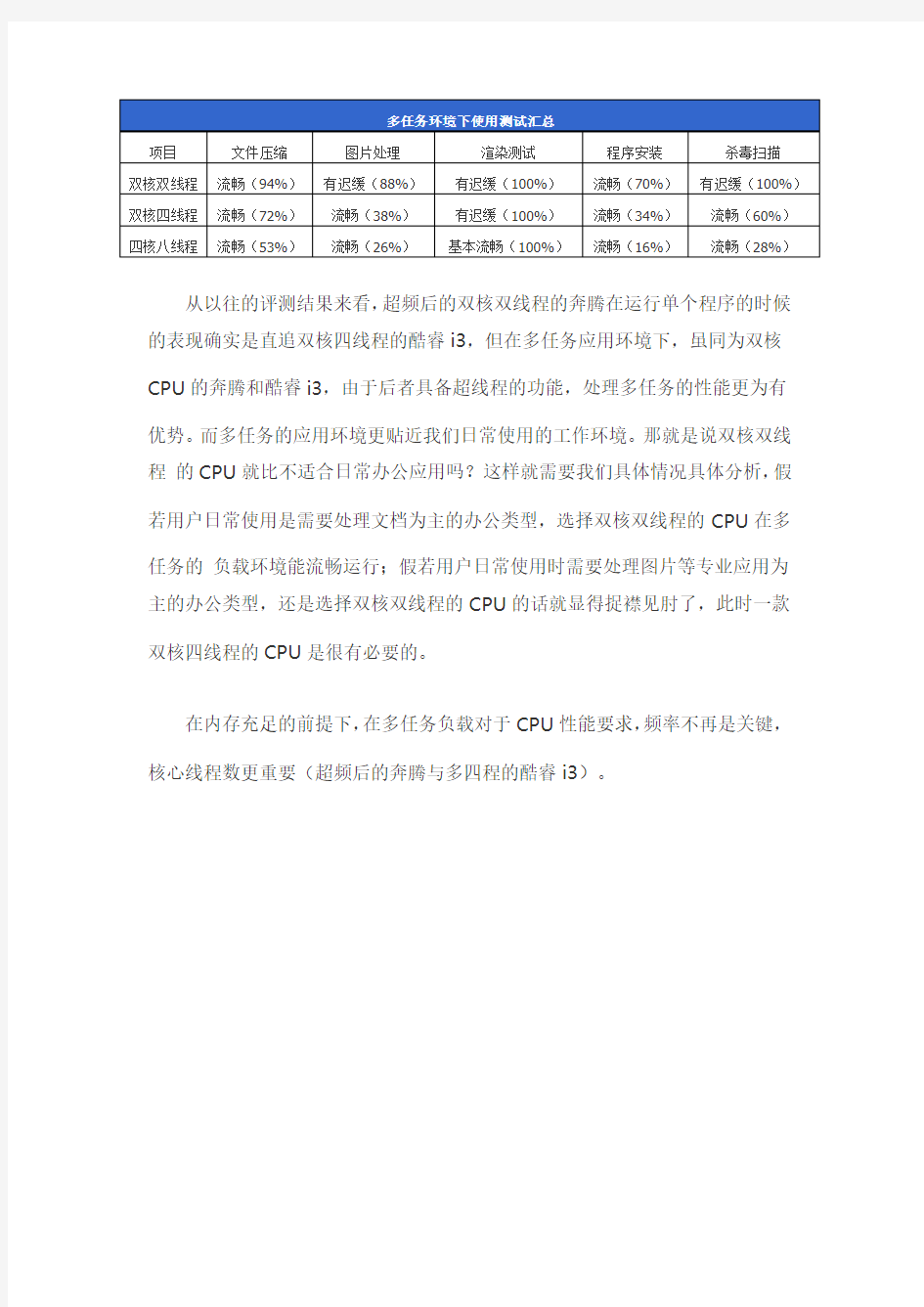
从以往的评测结果来看,超频后的双核双线程的奔腾在运行单个程序的时候的表现确实是直追双核四线程的酷睿i3,但在多任务应用环境下,虽同为双核CPU的奔腾和酷睿i3,由于后者具备超线程的功能,处理多任务的性能更为有优势。而多任务的应用环境更贴近我们日常使用的工作环境。那就是说双核双线程的CPU就比不适合日常办公应用吗?这样就需要我们具体情况具体分析,假若用户日常使用是需要处理文档为主的办公类型,选择双核双线程的CPU在多任务的负载环境能流畅运行;假若用户日常使用时需要处理图片等专业应用为主的办公类型,还是选择双核双线程的CPU的话就显得捉襟见肘了,此时一款双核四线程的CPU是很有必要的。
在内存充足的前提下,在多任务负载对于CPU性能要求,频率不再是关键,核心线程数更重要(超频后的奔腾与多四程的酷睿i3)。
CPU的核心数、线程数的关系和区别
我们在选购电脑的时候,CPU是一个需要考虑到核心因素,因为它决定了电脑的性能等级。CPU从早期的单核,发展到现在的双核,多核。CPU除了核心数之外,还有线程数之说,下面笔者就来解释一下CPU的核心数与线程数的关系和区别。 简单地说,CPU的核心数是指物理上,也就是硬件上存在着几个核心。比如,双核就是包括2个相对独立的CPU核心单元组,四核就包含4个相对独立的CPU核心单元组,等等,依次类推。 线程数是一种逻辑的概念,简单地说,就是模拟出的CPU核心数。比如,可以通过一个CPU核心数模拟出2线程的CPU,也就是说,这个单核心的CPU被模拟成了一个类似双核心CPU的功能。我们从任务管理器的性能标签页中看到的是两个CPU。 比如Intel 赛扬G460是单核心,双线程的CPU,Intel 酷睿i3 3220是双核心四线程,Intel 酷睿i7 4770K是四核心八线程,Intel 酷睿i5 4570是四核心四线程等等。 对于一个CPU,线程数总是大于或等于核心数的。一个核心最少对应一个线程,但通过超线程技术,一个核心可以对应两个线程,也就是说它可以同时运行两个线程。 CPU的线程数概念仅仅只针对Intel的CPU才有用,因为它是通过Intel超线程技术来实现的,最早应用在Pentium4上。如果没有超线程技术,一个CPU核心对应一个线程。所以,对于AMD的CPU来说,只有核心数的概念,没有线程数的概念。 CPU之所以要增加线程数,是源于多任务处理的需要。线程数越多,越有利于同时运行多个程序,因为线程数等同于在某个瞬间CPU能同时并行处理的任务数。 在Windows中,在cmd命令中输入“wmic”,然后在出现的新窗口中输入“cpu get *”即可查看物理CPU数、CPU核心数、线程数。其中, Name:表示物理CPU数 NumberOfCores:表示CPU核心数 NumberOfLogicalProcessors:表示CPU线程数
多核与多线程技术的区别到底在哪里
多核与多线程技术的区别到底在哪里? 【导读】:毫无疑问的,“多核”、“多线程”此二词已快成为当今处理器架构设计中的两大显学,如同历史战国时代以“儒”、“墨”两大派的显学,只不过当年两大治世思想学派是争得你死我亡,而多核、多线程则是相互兼容并蓄,今日几乎任何处理器都朝同时具有多核多线程的路线发展迈进。毫无疑问的,“多核”、“多线程”此二词已快成为当今处理器架构设计中的两大显学,如同历史战国时代以“儒”、“墨”两大派的显学,只不过当年两大治世思想学派是争得你死我亡,而多核、多线程则是相互兼容并蓄,今日几乎任何处理器都朝同时具有多核多线程的路线发展迈进。 虽然两词到处可见,但可有人知此二者的实际差异?在执行设计时又是以何者为重?到底是该多核优先还是多线程提前?关于此似乎大家都想进一步了解,本文以下试图对此进行个中差异的解说,并尽可能在不涉及实际复杂细节的情形下,让各位对两者的机制观念与差别性有所理解。 行程早于线程 若依据信息技术的发展历程,在软件程序执行时的再细分、再切割的小型化单位上,先是有行程(Process),之后才有线程(Thread),线程的单位比行程更小,一个行程内可以有多个线程,在一个行程下的各线程,都是共享同一个行程所建立的内存寻址资源及内存管理机制,包括执行权阶、内存空间、堆栈位置等,除此之外各个线程自身仅拥有少许因为执行之需的变量自属性,其余都依据与遵行行程所设立的规定。 相对的,程序与程序之间所用的就是不同的内存设定,包括分页、分段等起始地址的不同,执行权阶的不同,堆栈深度的不同等,一颗处理器若执行了A行程后要改去执行B行程,对此必须进行内存管理组态的搬迁、变更,而这个搬迁若是在处理器内还好,若是在高速缓存甚至是系统主存储器时,此种切换、转移程序对执行效能的损伤就非常大,因为完成搬迁、切换程序的相同时间,处理器早就可以执行数十到上千个指令。 两种路线的加速思维 所以,想避免此种切换的效率损耗,可以从两种角度去思考,第一种思考就是扩大到整体运算系统的层面来解决,在一部计算机内设计、配置更多颗的处理器,然后由同一个操作系统同时掌控及管理多颗处理器,并将要执行的程序的各个程序,一个程序喂(也称:发派)给一颗处理器去执行,如此多颗同时执行,每颗处理器执行一个程序,如此就可以加快整体的执行效率。 当然!这种加速方式必须有一个先决条件,即是操作系统在编译时就必须能管控、发挥及运用多行程技术,倘若以单行程的系统组态来编译,那么操作系统就无法管控服务器内一颗以上的处理器,如此就不用去谈论由操作系统负责让应用程序的程序进行同时的多颗同时性的执行派送。 即便操作系统支持多程序,而应用程序若依旧只支持单程序,那情形一样是白搭,操作
核心类型
核心(Die)又称为内核,是 CPU 最重要的组成部分。CPU 中心那块隆起的芯片就是核心,是由单晶硅以一定的生产工艺制造出来的,CPU 所有的计算、接受/存储命令、处理数据都由核心执行。各种 CPU 核心都具有固定的逻辑结构,一级缓存、二级缓存、执行单元、指令级单元和总线接口等逻辑单元,都会有科学的布局。为了便于 CPU 设计、生产、销售的管理,CPU 制造商会对各种 CPU 核心给出相应的代号,这也就是所谓的 CPU 核心类型。不同的 CPU (不同系列或同一系列)都会有不同的核心类型(例如 Pentium 4 的 Northwood,Willamette 以及 K6-2 的 CXT 和 K6-2+ 的 ST-50 等等),甚至同一种核心都会有不同版本的类型(例如 Northwood 核心就分为 B0 和 C1 等版本),核心版本的变更,是为了修正上一版存在的一些错误,并提升一定的性能,而这些变化,普通消费者是很少去注意的。每一种核心类型都有其相应的制造工艺(例如0.25um、0.18um、0.13um 以及 0.09um 等)、核心面积(这是决定 CPU 成本的关键因素,成本与核心面积基本上成正比)、核心电压、电流大小、晶体管数量、各级缓存的大小、主频范围、流水线架构和支持的指令集(这两点是决定 CPU 实际性能和工作效率的关键因素)、功耗和发热量的大小、封装方式(例如 S.E.P、PGA、FC-PGA、FC-PGA2 等等)、接口类型(例如 Socket 370,Socket A,Socket 478,Socket T,Slot 1、Socket 940 等等)、前端总线频率(FSB)等等。因此,核心类型在某种程度上决定了 CPU 的工作性能。一般说来,新的核心类型,往往比老的核心类型具有更好的性能(例如同频的 Northwood 核心Pentium 4 1.8A GHz 就要比 Willamette 核心的 Pentium 4 1.8 GHz 性能要高)。但这也不是绝对的。这种情况一般发生在新核心类型刚推出时,由于技术不完善或新的架构和制造工艺不成熟等原因,可能会导致新的核心类型的性能反而还不如老的核心类型的性能。例如,早期 Willamette 核心 Socket 423 接口的Pentium 4 的实际性能,不如 Socket 370 接口的 Tualatin 核心的 Pentium III 和赛扬,现在的低频 Prescott 核心 Pentium 4 的实际性能,不如同频的Northwood 核心 Pentium 4 等等。但随着技术的进步以及 CPU 制造商对新核心的不断改进和完善,新核心的中后期产品的性能,必然会超越老核心产品。CPU 核心的发展方向,是更低的电压、更低的功耗、更先进的制造工艺、集成更多的晶体管、更小的核心面积(这会降低 CPU 的生产成本从而最终会降低 CPU 的销售价格)、更先进的流水线架构和更多的指令集、更高的前端总线频率、集成更多的功能(例如集成内存控制器,等等)以及双核心和多核心(也就是一个CPU 内部有 2 个或更多个核心)等。CPU 核心的进步,对普通消费者而言,最有意义的就是能以更低的价格买到性能更强的 CPU。在 CPU 漫长的历史中,伴随着纷繁复杂的 CPU 核心类型。以下分别就 Intel CPU 和 AMD CPU 的主流核心类型,作一个简介。主流核心类型介绍(仅限于台式机 CPU,不包括笔记本CPU 和服务器/工作站 CPU,而且不包括比较老的核心类型)。Intel CPU 的核心类型核心类型1) Tualatin 这也就是大名鼎鼎的图拉丁核心,是Intel 在 Socket 370 架构上的最后一种 CPU 核心,采用 0.13um 制造工艺,封装方式采用 FC-PGA2 和 PPGA,核心电压也降低到了 1.5V 左右,主频范围从1GHz 到 1.4GHz,外频分别为 100MHz(赛扬)和 133MHz(Pentium III),二级缓存分别为 512KB(Pentium III-S)和 256KB(Pentium III 和赛扬),这是最强的 Socket 370 核心,其性能甚至超过了早期低频的 Pentium 4系列CPU。核心类型2) Willamette 这是早期的 Pentium 4 和 P4 赛扬采用的核心,最初采用 Socket 423 接口,后来改用 Socket 478 接口(赛扬只有
多线程编程的原则及要点
2.4多线程编程的原则及要点: 随着多核CPU的出世,多核编程方面的问题将摆上了程序员的日程,有许多老的程序员以为早就有多CPU的机器,业界在多CPU机器上的编程已经积累了很多经验,多核CPU上的编程应该差不多,只要借鉴以前的多任务编程、并行编程和并行算法方面的经验就足够了。 但是,多核机器和以前的多CPU机器有很大的不同,以前的多CPU机器都是用在特定领域,比如服务器,或者一些可以进行大型并行计算的领域,这些领域很容易发挥出多CPU的优势,而现在多核机器则是应用到普通用户的各个层面,特别是客户端机器要使用多核CPU,而很多客户端软件要想发挥出多核的并行优势恐怕没有服务器和可以进行大型并行计算的特定领域简单。 多核CPU中,要很好地发挥出多个CPU的性能的话,必须保证分配到各个CPU上的任务有一个很好的负载平衡。否则一些CPU在运行,另外一些CPU处于空闲,无法发挥出多核CPU 的优势来。 要实现一个好的负载平衡通常有两种方案,一种是静态负载平衡,另外一种是动态负载平衡。 1、静态负载平衡 静态负载平衡中,需要人工将程序分割成多个可并行执行的部分,并且要保证分割成的各个部分能够均衡地分布到各个CPU上运行,也就是说工作量要在多个任务间进行均匀的分配,使得达到高的加速系数。 2、动态负载平衡 动态负载平衡是在程序的运行过程中来进行任务的分配达到负载平衡的目的。实际情况中存在许多不能由静态负载平衡解决的问题,比如一个大的循环中,循环的次数是由外部输入的,事先并不知道循环的次数,此时采用静态负载平衡划分策略就很难实现负载平衡。 动态负载平衡中对任务的调度一般是由系统来实现的,程序员通常只能选择动态平衡的调度策略,不能修改调度策略,由于实际任务中存在很多的不确定因素,调度算法无法做得很优,因此动态负载平衡有时可能达不到既定的负载平衡要求。 3、负载平衡的难题在那里? 负载平衡的难题并不在于负载平衡的程度要达到多少,因为即使在各个CPU上分配的任务执行时间存在一些差距,但是随着CPU核数的增多总能让总的执行时间下降,从而使加速系数随CPU核数的增加而增加。 负载平衡的困难之处在于程序中的可并行执行块很多要靠程序员来划分,当然CPU核数较少时,比如双核或4核,这种划分并不是很困难。但随着核数的增加,划分的粒度将变得越来越细,到了16核以上时,估计程序员要为如何划分任务而抓狂。比如一段顺序执行的代码,放到128核的CPU上运行,要手工划分成128 个任务,其划分的难度可想而知。
电脑核心知识,来了解cpu是怎么工作的吧!
电脑核心知识,来了解cpu是怎么工作的吧! 大家都知道,对于一台电脑来说,cpu就相当于电脑的大脑,负责处理信息的核心配件,那么下面小编就带你具体的来了解一下什么事cpu吧,赶紧和小编一起来看看吧! 1、CPU的形状及构制 CPU是局部计算肌体系的当中部件,内里构制以下图所示。CPU顾上往非常非常杂洁,是一个矩形片状物体。此二头凸起部分是CPU当中,它着名是一片指甲年夜小的、薄薄的硅晶片,正在那块小小的硅片上,稀布着数以千万计的晶体管,它们互相共共调战,停止千般烦复的运算战支配。为协帮散热,着名正在CPU的当中上皆减拆一个金属启拆壳,金属启拆壳周遭是CPU基板,它将CPU内里的旌旗灯号引接到CPU针足上。基板的背后有很多稀稀层层的镀金针足,它是CPU与内里电路衔接的通道。 2、CPU的形成部分 CPU内里次要由运算器、克制器战寄放器组形成。 运算器用往对付数据处理千般算术运算战逻辑运算。克制器是CPU的指挥中间,它能对付计算机指令处理阐收,产死千般克制型旌旗灯号。寄放器组用到临时寄放减进运算的数据战计算的二头结果。 3、CPU的任务原理 CPU的任务原理便像一个工厂对付产品的减工历程:进人为厂的本料(法度指令),颠终物量部分(克制器)的调度分拨,被支往出产线(运算器),出产出制品(寄放器组)后,再死存正在堆栈(内存)中,最初等着拿到阛阓上往买(接由利用法度支配)。那个历程顾起往相称少,中貌上不过一刹时产死的处世。也不妨那么相识CPU只真止三种底子的支配,鉴别是读出数据、措置处奖数据战往内存写数据。 现在,开流CPU仍旧Intel战AMD二家的世界。无论是矮端仍旧矮端,二年夜品牌皆有着齐线的产品。简直型号及产品可自止百度。
cpu各参数的含义
cpu各参数的含义 2013-09-22 11:20处理器(Processor)框内的信息: 1、名称(Name):代表CPU的名字,比如E2140,Q6600之类。 2、代号(CodeName):代表CPU核心架构的代号,不同核心的cpu性能差距很大. 3、封装(Package):即用绝缘的材料将cpu内核和其他原件一块打包的技术。 4、工艺(Technology):工艺越高,CPU的功耗和发热量就越小,可超频性就越强。 5、核心电压(Core Voltage):核心电压是一个很重要的参数,尤其是对超频来说。一般的核心电压越低,越容易超频。因为核心电压低了,可提升的余地就大,功耗就低,发热量就小,有利于超频玩。所以高手选CPU的时候很注重修订(下面介绍),CPU不同的修订代表了不同的品质,一些就体现在核心电压这块,苛刻的玩家甚至只买生产日期是哪一年那一周的那一批次的产品。 6、规格(Specification):就是对CPU的描述,没啥意思。 7、系列(Family)、扩展系列(Ext.Family)、型号(Model)、扩展型号(Ext.Model):应该是CPU厂商对CPU的定义,该CPU属于那一系列哪一个型号。对一般人没用。 8、步进(Stepping)、修订(Reversion):代表了CPU厂商对该CPU的的改进信息,类似我们开发程序时候的版本号。一般较新的
步进的CPU都比老的好一些,但世事无绝对,可能之前步进的CPU超频性更好一些呢,这也说不准。尽量选择步进新的,毕竟CPU厂不会将它越改越烂。 以上就是处理器(Processor)框内的信息,买到一个CPU后,可对比这些信息,瞅瞅这个CPU是不是真滴,也可看看CPU是否自己中意的那个修订版的。 时钟(Clock)框内的信:(如果是多核心CPU,可在下面选核心,这里显示核心的时钟状态。) 1、核心速度(Core Speed):就是主频。越高越好,超频后也可在这里体现出来。计算方法是主频 = 外频 * 倍频。 2、倍频(Multiplier):就是主频与外频的比例。当一个CPU 主频相对较低,制作工艺较高,倍频也较高,这意味着这个CPU超频比较厉害,比如赛扬系列。大多数CPU的倍频是不允许修改的。但现在的AMD出了不少黑盒版CPU,黑盒版意味着CPU的倍频是可以修改的,这就更容易超频了。此外intel的高端至尊系列好像外频也是不锁的。 3、总线速度(Bus Speed):其实就是外频吧。同主频的情况下,外频越高(倍频不同)性能也就越高。 4、前端总线(FSB):前端总线就是连接CPU跟北桥芯片的总线,这个频率当然是越高越好,但前提是主板支持。对Intel的CPU来说,前端总线连接了CPU跟内存控制器(北桥内),CPU操作内存通过内
操作系统对多核处理器的支持方法
随着多核处理器的发展,对软件开发有非常大的影响,而且核心的瓶颈在软件上。软件开发在多核环境下的核心是多线程开发。这个多线程不仅代表了软件实现上多线程,要求在硬件上也采用多线程技术。可以说多核提供了可以大幅提升性能的机制,多核软件就是可以真正利用这一特点的策略。只有与多核硬件相适应的软件,才能真正地发挥多核的性能。多核对软件的要求包括对多核操作系统的要求和对应用软件的要求。 多核操作系统的关注点在于进程的分配和调度。进程的分配将进程分配到合理的物理核上,因为不同的核在共享性和历史运行情况都是不同的。有的物理核能够共享二级cache,而有的却是独立的。如果将有数据共享的进程分配给有共享二级cache的核上,将大大提升性能;反之,就有可能影响性能。进程调度会涉及到比较广泛的问题,比如负载均衡、实时性等。 面向多核体系结构的操作系统调度目前多核软件的一个热点,其中研究的热点主要有下面几方面:程序的并行研究;多进程的时间相关性研究;任务的分配与调度;缓存的错误共享;一致性访问研究;进程间通信;多处理器核内部资源竞争等等。这些探讨相互独立又相互依赖。考虑一个系统的性能时必须将其中的几点同时加以考虑,有时候对一些点的优化会造成另一些点的性能下降,需要用程序进行性能优化评测,所以合适的多核系统软件方案正在形成过程中。 任务的分配是多核时代提出的新概念。在单核时代,没有核的任务分配的问题,一共只有一个核的资源可被使用。而在多核体系下,有多个核可以被使用。如果系统中有几个进程需要分配,是将他们均匀地分配到各个处理器核,还是一起分配到一个处理器核,或是按照一定的算法进行分配。并且这个分配还受底层系统结构的影响,系统是SMP构架还是CMP构架,在CMP构架中会共享二级缓存的核的数量,这是影响分配算法的因子。任务分配结束后,需要考虑任务调度。对于不同的核,每个处理器核可以有自己独立的调度算法来执行不同的任务(实时任务或者交互性任务),也可以使用一致的调度算法。此外,还可以考虑一个进程上一个时间运行在一个核上,下一个时间片是选择继续运行在这个核上,还是进行线程迁移;怎样直接调度实时任务和普通任务;系统的核资源是否要进行负载均衡等等。任务调度是目前研究的热点之一。 在单核处理器中,常见的调度策略有先到先服务(FCFS),最短作业调度(SJF),优先级调度(Priority-scheduling algorithm),轮转法调度(round-robin RR),多级队列调度(multilevel queue-schedule algorithm)等。例如在Linux操作系统中对实时任务采取FCFS和RR两种调度,普通任务调度采取优先级调度。 对于多核处理器系统的调度,目前还没有明确的标准与规范。由于系统有多个处理器核可用,必须进行负载分配,有可能为每个处理器核提供单独的队列。在这种情况下,一个具有空队列的处理器就会空闲,而另一个处理器会很忙。所以如何处理好负载均衡问题是这种调度策略的关键问题所在。为了解决这种情况,可以考虑共同就绪队列,所有处理器公用一个就绪队列。但是这无疑对进程上下文切换、锁的转换增加了执行时间,降低了性能。另外一种想法就是选择一个处理器来为其他处理器调度,因而创建了主从结构。有的系统将主从结构作进一步扩
CPU-Z 参数解读
CPU-Z怎么看参数利用CPU-Z检测电脑CPU型号方法全面图解 16-07-18 16:28作者:脚本之家 写这篇文章的目的很简单,教大家怎么看CPU-Z软件的显示结果,鉴于不少电脑爱好者新人朋友对CPU-Z检测出来的结果不太了解或者存在一些疑问,比如CPU-Z检测结果是否准确、能否作为鉴别真假处理器的依据等等,下面本文将统一解答。 CPU-Z的处理器选项卡下显示的参数就是处理器的核心参数知识,下面我们具体来解读看。
图为Intel六代I5-6600K的CPU-Z检测结果 ①名字 CPU-Z检测结果出来之后,第一栏叫“名字”,但是这个“名字”只具有参考价值,如果你看CPU-Z检测的处理器型号是看“名字”这一栏,只能说明你并不会用这款软件。
CPU-Z经常会出现这样的检测结果,名字和规格显示的结果并不一样,这是为什么呢?我之前已经说了,名字栏可以理解为这是CPU-Z拿到处理器后与自身数据库比对后第一反应的结果,这个结果对检测ES型号不显的处理器有一定的帮助,而对于我们正式版或者正显型号的产品,只会多几分误导,所以小白们,千万不要去看【名字】这一栏参数! ②代号 即为核心代号,用于区分处理的核心架构,比如Skylake就是我们常说的进入酷睿I时代的第六代处理器核心代号,第五代是Broadwell,而第四代则是Haswell。 ③TDP热设计功耗 这个参数非常难解释!绝大部分人都不懂什么是TDP,小白们以为TDP越大功耗越大,但并非如此!现阶段最通俗的解释就是:同一系列处理器,TDP越大,性能越强。TDP是一个可以修改的参数,并不是实际功耗,而至于怎么修改,英特尔以及OEM制造商可以根据
电脑CPU核心供电处上下管D极对地阻值
电脑CPU核心供电处上下管D极对地阻值 内容出处:易家电子https://www.360docs.net/doc/ce13499376.html, CPU核心供电处上下管D极对地阻值(可大不可小) 370针CPU座 上管D极≥150Ω(品牌机只有80Ω左右)上管G极≥100Ω 下管D极≥100Ω下管G极≥100Ω 462针CPU座 上管D极≥150Ω上管G极≥400Ω 下管D极≥20Ω下管G极≥400Ω 478针CPU座 上管D极≥250Ω上管G极≥400Ω 下管D极≥20Ω下管G极≥400Ω 754针CPU座 上管D极≥200Ω上管G极≥300Ω 下管D极≥15Ω下管G极≥300Ω 775针CPU座 上管D极≥250Ω上管G极300Ω-500Ω下管D极≥15Ω下管G极300Ω-500Ω939针CPU座 上管D极≥200Ω上管G极≥500Ω 下管D极≥30Ω下管G极≥500Ω --------------------------------- CPU核心供电电压范围!(在此范围内都是正常的) 电压测试点 370针CPU座 核心电压 1.8-2.0V 1.2-1.35V 3-5V(少数老板.采用8角的针插式电压IC,下管为复合二极管) 复位 1.2-1.5VU左右 PG信号2-3.5V 外核电压 2.5V(无此电压可上图拉丁) 参考电压0.8-1.5V 主时钟0.8-1.5V 辅时钟 1.1-1.8V 462针CPU座 核心电压 1.6~1.8V 参考电压 1.6V+0.8V+2.5V 复位 1.5-1.6V PG信号≥1.25V 478针CPU座 核心电压 1.7-1.95V(常见) 0.9-1.2V(848,865,875主板常见,上2.0G以上CPU)
服务器CPU主频和内核数量及性能之间关系的探讨
服务器CPU主频和内核数量及性能之间关系的探讨 上周打电话咨询dell售后关于R720服务器CPU内核数量和主频之间的关系的一个问题,和售后磨叽了2个多小时后售后工程师一直也没有给出一个令人信服的答案,笔者只好通过查阅相关资料以及和同事讨论后有了个清晰的答案。现将该问题整理了一下分享出来,以供大家学习和参考。 疑惑1:服务器的主频怎么计算?单颗主频*内核数量吗? 疑惑2:服务器cpu的性能依赖于cpu的主频? 疑惑3:多核处理出现的原因? 疑惑4:多核处理器的优势在哪里? 疑惑5:多核处理器带来的挑战是什么? 疑惑6:如何发挥多核服务器应有的性能? 首先对于问题1 服务器的主频怎么计算?单颗主频*内核数量吗? 服务器cpu的主频和内核的数量是没有关系的,也就是说如果你的cpu的一个线程(一个core)的主频是2GHZ的话那么你的服务器的主频就是2GHZ。 对于问题2 服务器cpu的性能依赖于cpu的主频? cpu的性能依赖于CPU的主频吗?非也,主频只是其中一个比较重要的参考依据而已,其中还有其他重要的参数指标决定了cpu的性能。 其中CPU的性能由主频、管线架构或长度、功能单元数目、缓存设计四个方面决定,我扪常将“管线架构或长度、功能单元数目、缓存设计”这三个方面统称为CPU的架构,也就是说CPU的性能由CPU的主频和CPU的架构这两个方面来综合决定。 从以往CPU发展历史来看,CPU频率的增长带来的是性能上量的增长,而架构的改变往往带来其性能上质的飞跃,所以相对而言同样的架构,主频高低不同,CPU处理能力才有可比较性;而不同架构的CPU 之间性能的差别就可能给人们带来完全不同的体验了。也正是CPU架构方面的原应才造成了很多同频的AthlonXP比P4处理器更快这一现实。 所以只有在同一家族的CPU中进行比较,核心数量、主频与CPU的运行速度才有正比关系,还有影响的因素是2、3级缓存的大小。核心版本和工艺的升级也有影响。一般在同一家族的CPU中,核心越多、主频越高、缓存越多、版本越新的CPU越快。 疑惑3:为什么会出现多核处理器呢? 多核技术的开发源于工程师们认识到,仅仅提高单核芯片的速度会产生过多热量且无法带来相应的性能改善,先前的处理器产品就是如此。他们认识到,在先前产品中以那种速率,处理器产生的热量很快会超过太阳表面。即便是没有热量问题,其性价比也令人难以接受,速度稍快的处理器价格要高很多。
浅谈多核CPU、多线程与并行计算
0.前言 最近发觉自己博客转帖的太多,于是决定自己写一个原创的。笔者用过MPI 和C#线程池,参加过比赛,有所感受,将近一年来,对多线程编程兴趣一直不减,一直有所关注,决定写篇文章,算是对知识的总结吧。有说的不对的地方,欢迎各位大哥们指正:) 1.CPU发展趋势 核心数目依旧会越来越多,依据摩尔定律,由于单个核心性能提升有着严重的瓶颈问题,普通的桌面PC有望在2017年末2018年初达到24核心(或者16核32线程),我们如何来面对这突如其来的核心数目的增加?编程也要与时俱进。笔者斗胆预测,CPU各个核心之间的片内总线将会采用4路组相连:),因为全相连太过复杂,单总线又不够给力。而且应该是非对称多核处理器,可能其中会混杂几个DSP处理器或流处理器。 2.多线程与并行计算的区别 (1)多线程的作用不只是用作并行计算,他还有很多很有益的作用。 还在单核时代,多线程就有很广泛的应用,这时候多线程大多用于降低阻塞(意思是类似于 while(1) { if(flag==1) break;
sleep(1); } 这样的代码)带来的CPU资源闲置,注意这里没有浪费CPU资源,去掉sleep(1)就是纯浪费了。 阻塞在什么时候发生呢?一般是等待IO操作(磁盘,数据库,网络等等)。此时如果单线程,CPU会干转不干实事(与本程序无关的事情都算不干实事,因为执行其他程序对我来说没意义),效率低下(针对这个程序而言),例如一个IO操作要耗时10毫秒,CPU就会被阻塞接近10毫秒,这是何等的浪费啊!要知道CPU是数着纳秒过日子的。 所以这种耗时的IO操作就用一个线程Thread去代为执行,创建这个线程的函数(代码)部分不会被IO操作阻塞,继续干这个程序中其他的事情,而不是干等待(或者去执行其他程序)。 同样在这个单核时代,多线程的这个消除阻塞的作用还可以叫做“并发”,这和并行是有着本质的不同的。并发是“伪并行”,看似并行,而实际上还是一个CPU在执行一切事物,只是切换的太快,我们没法察觉罢了。例如基于UI 的程序(俗话说就是图形界面),如果你点一个按钮触发的事件需要执行10秒钟,那么这个程序就会假死,因为程序在忙着执行,没空搭理用户的其他操作;而如果你把这个按钮触发的函数赋给一个线程,然后启动线程去执行,那么程序就不会假死,继续响应用户的其他操作。但是,随之而来的就是线程的互斥和同步、死锁等问题,详细见有关文献。 现在是多核时代了,这种线程的互斥和同步问题是更加严峻的,单核时代大都算并发,多核时代真的就大为不同,为什么呢?具体细节请参考有关文献。我
四核心CPU采用OR拷机的正确方法
四/六核心CPU采用OR拷机的正确方法 最近教唆一朋友采购了一台i5 3570K的主机,由于是刚买回的电脑,想用ORTHOS(以下简称OR)来拷机一下,以检验稳定性。于是乎从网上下回来了OR打开,发现了一个很诡异的问题。如图 即便是4开OR,CPU占用也只有60%左右,内存使用率大概在50%。相对应的:CPU核心温度也有两颗偏低。很明显,OR只能占用到2个核心,换句话说,系统只分配了2个核心给这个软件。
其实类似的问题可以归结为该软件对多核心的兼容不太好。再来看我另一个朋友的主机,很奇怪的,同样也是i5 3570K的CPU,只开了2个OR,CPU已经占用100%了,但内存占用还是不足,16GB的内存只用去6GB。 那么是否我们就不能用OR拷4核心以上的CPU了呢?当然不是。我们先从问题症结找起,软件对多核心的兼容问题其实根本上就是系统给该软件的核心分配的问题,如果系统不能自动地、合理地给程序来分配核心,我们也可以采用手动分配的方式来分配。 首先,我们先打开一个OR,在进程管理器里面对着OR的进程点右键,打开“处理器关联选项”,我们可以看到默认是所有核心都可以管理该进程(实际上是有系统分配单个核心来管理的,全部选勾只是说系统可以任意分配)。如图
那么我可以去所有处理器的勾,手动CPU 0来管理该进程,勾选之后我点OR运行。 然后,我再打开一个OR,这样我可以看到进程管理器里面有一个OR占用了25%的处理器资源,另一个占用为0,那么我就知道0%的那个OR进程就是还没有分配处理器的那个,我再分配CPU 1给这个新开的OR。如图 以此类推,我们可以开四个OR进程,分别把CPU 0 ~ CPU 3分配给这四个进程。当这四个OR全部凯奇以后,我们可以看到内存和CPU占用接近处理器的峰值,而且4个核心的温度都达到了60~70℃(拷机一段时间以后达到70~75℃)。如图
cpu数-物理核-逻辑核
目录 cpu数,物理核,逻辑核的关系: (1) 查看检查/proc/cpuinfo文件: (1) 查看CPU(各个逻辑核)占用情况: (2) 进程绑定逻辑核: (2) linux下查看cpu物理个数和逻辑个数 (5) cpu数,物理核,逻辑核的关系: 逻辑CPU个数> 物理CPU个数* CPU内核数开启了超线程 逻辑CPU个数= 物理CPU个数* CPU内核数没有开启超线程 查看检查/proc/cpuinfo文件: (注意cpuinfo就是一个文本文件,记录了当前CPU信息) 例如我的CPU #cat /proc/cpuinfo processor :0 vendor_id :GenuineIntel cpu family :6 model :26 model name :Intel(R) Xeon(R) CPU E5520 @ 2.27GHz stepping :5 cpu MHz :1600.000 cache size :8192 KB physical id :0 siblings :8 core id :0 cpu cores :4 apicid :0 fpu :yes fpu_exception :yes cpuid level :11 wp :yes flags :fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush dts acpi mmx fxsr sse sse2 ss ht tm syscall nx rdtscp lm constant_tsc ida nonstop_tsc pni monitor ds_cpl vmx est tm2 cx16 xtpr popcnt lahf_lm bogomips :4522.12 clflush size :64 cache_alignment :64 address sizes :40 bits physical, 48 bits virtual power management : 以上输出项的含义如下: processor :系统中逻辑处理核的编号。对于单核处理器,则课认为是其CPU编号,对于多核处理器则可以是物理核、或者使用超线程技术虚拟的逻辑核 vendor_id :CPU制造商 cpu family :CPU产品系列代号 model :CPU属于其系列中的哪一代的代号 model name:CPU属于的名字及其编号、标称主频 stepping :CPU属于制作更新版本
同步多线程-(SMT)-技术基础
同步多线程(SMT) 技术基础 介绍 微处理器设计的发展和我们对速度的需求,诞生了很多新技术并使它们迅速发展,也使现在的以及下一代的处理器的效率和性能都有了提升。一定的体系结构下,在提高性能、降低开销和指令级并行性(ILP之间)加以平衡,可以降低平均CPI。 同步多线程技术(SMT)是一种体系结构模型,其目的是在现有硬件条件下,通过提高计算能力来提高处理器的性能。因此,同步多线程技术结合了多重启动处理器(超标量和VLIW)和多线程处理器的思想来增加并行度,进而提高性能。 多重启动处理器可以在一个周期内执行多条(2,4甚至8条)指令,而多线程和多处理器(SMP和CMP)结构可以同时或者在很少的延迟内执行来自不同线程的指令。SMT结构中,不仅在一周期内启动多条指令,而且也能在同一周期内启动来自相互独立的线程(或上下文)的指令。在理论上,这种改进运用了指令级并行性(ILP)和线程级并行性(TLP)技术来提高执行功能单元的效率。 同步多线程技术之前的研究 多重启动处理器(Multiple Issue Processors) 运用在超标量和VLIW上的多重启动处理器,其目的是为了降低平均CPI,通过在一个周期内启动多条指令,充分利用处理器的功能单元。要想有效利用多重启动处理器资源的关键就是在运行的程序中,发现足够的指令级并行性,通常这种并行性是由硬件决定的。超长指令字(VLIW)处理器每周期启动固定数目的操作,而这些操作是由编译器决定的。 超标量处理器通常是指“动态调度”(dynamically scheduled)的多重启动处理器,因为他们是通过硬件来发现代码中的并行性。不同的是,VLIW处理器通常是“静态调度”(statically scheduled)的,因为他们依靠编译器来发现并优化指令级并行性。 无论是动态或是静态调度,如何有效利用多重启动处理器,依赖于发现并利用指令级并行性。指令级并行性来自同一个上下文环境、程序或线程。CPU和编译器重新安排和启动指令,以此来最大限度的利用资源而不改变应用程序的完整性。在多重启动处理器中,如果不能发现足够的并行指令来填满发射槽(issue slot),那么资源就被浪费了。 超标量处理器现在大致有DEC/Compaq 21164, PowerPC, MIPS R10000, Sun UltraSparc 和 Hewlett Packard PA-8000。而VLIW处理器则包括Intel IA-64 (Itanium) 和Transmeta Crusoe。对多重启动处理器和使用记分牌(scoreboarding)和Tomasulo算法的动态调度已经有了很多研究,我将不再花费时间分析他们。 多线程处理器(Multithreaded Processors) 多线程处理器主要通过降低操作延迟以提高处理器的效率,比如说cache失效和需要长执行周期的指令。一个多线程处理器通过分配给每个线程独立的PC(program counter)和寄存器来保持线程间相互独立的状态。由于每个处理器在切换上下文时几乎没有延迟,所以每个周期可以启动来自不同线程的指令。如果处理器在每个周期切换上下文,这就叫做细颗粒(fine-grained)的多线程或交叉(interleaving)。粗颗粒(Course grain)的多线程处理器则是在某一线程出现长延迟时,才切换线程,以保证指令的持续启动。正是由于存在分离的、独立的上下文和指令资源,多线程体系结构才能利用线程级并行性(TLP),从而提高处理器的效率。多线程处理器通过比传统处理器更精细地共享处理器资源,从而
CPU知识全面讲解
CPU知识全面讲解 CPU,全称“Central Processing Unit”,中文名为“中央处理器”,在大多数网友的印象中,CPU只是一个方形配件,正面是金属盖,背面是一些密密麻麻的针脚或触点,可以说毫无美感可言。但在这个小块头的东西上,却是汇聚了无数的人类智慧在里面,我们今天能上网、工作、玩游戏等全都离不开这个小小的东西,它可谓是小块头有大智慧。 作为普通用户、网友,我们并不需要解读CPU里的所有“大智慧”,但CPU 既然是电脑中最重要的配件、并且直接决定电脑的性能,了解它里面的部分知识还是有必要的。下面笔者将给大家介绍CPU里最重要的基础知识,让大家对CPU 有新的认识。 1、CPU的最重要基础:CPU架构 CPU架构: 采用Nehalem架构的Core i7/i5处理器 CPU架构,目前没有一个权威和准确的定义,简单来说就是CPU核心的设计方案。目前CPU大致可以分为X86、IA64、RISC等多种架构,而个人电脑上的CPU架构,其实都是基于X86架构设计的,称为X86下的微架构,常常被简称为CPU架构。
更新CPU架构能有效地提高CPU的执行效率,但也需要投入巨大的研发成本,因此CPU厂商一般每2-3年才更新一次架构。近几年比较著名的X86微架构有Intel的Netburst(Pentium 4/Pentium D系列)、Core(Core 2系列)、Nehalem (Core i7/i5/i3系列),以及AMD的K8(Athlon 64系列)、K10(Phenom系列)、K10.5(Athlon II/Phenom II系列)。 Intel以Tick-Tock钟摆模式更新CPU 自2006年发布Core 2系列后,Intel便以“Tick-Tock”钟摆模式更新CPU,简单来说就是第一年改进CPU工艺,第二年更新CPU微架构,这样交替进行。目前Intel正进行“Tick”阶段,即改进CPU的制造工艺,如最新的Westmere架构其实就是Nehalem架构的工艺改进版,下一代Sandy Bridge架构将是全新架构。AMD方面则没有一个固定的更新架构周期,从K7到K8再到K10,大概是3-4年更新一次。 制造工艺:
多处理器多线程软件性能优化
多处理器多线程软件性能优化 ——JAWS框架案例分析 摘要:随着应用软件日趋复杂,对性能的要求不断提高,多处理器技术成为服务器技术的重要技术支点。然而,多处理器需要有操作系统、编译器以及应用软件架构和工具的支持,否则根本达不到性能提升的目的。本文以JAWS框架为例,首先讨论如何通过通讯模式优化和多处理器优化,提升基于JAWS框架的通讯服务器在多处理器平台下的性能;然后介绍一个基于JAWS框架开发的多播服务器的性能测试环境,通过对性能测试结果进行分析,研究软件架构对多处理器平台下软件性能的影响。 关键字:多处理器多线程性能优化 JAWS 1 引言 回首处理器的发展历程,并行技术从指令级的超标量发展到线程级的超线程或者并发多线程,再到今天处理器级的多内核,总的趋势都没有改变。随着科学计算、政府的大型数据库管理系统、数字医疗领域、通讯、金融、大型企业的ERP、CRM等应用软件日趋复杂,对性能的要求不断提高。如目前的通讯服务器应用,在功能不断增强的同时,还要求更高的吞吐率和更多的用户容量。无论是需求推动技术,还是技术激发了新的需求,多处理器技术已经成为服务器技术的重要技术支点。然而,多处理器需要有操作系统、编译器以及应用软件架构和工具的支持,否则根本达不到性能提升的目的;如果使用多处理器运行单线程软件,性能方面不会得到提升。 本文以JAWS框架为例,讨论在软件架构层面上的上多处理器优化技术,并建立性能测试环境,通过对性能测试结果进行分析,研究软件架构对多处理器平台下软件性能的影响。 JAWS是一种高性能和自适配的、实现了HTTP协议的Web服务器。它还是一个平台无关的应用构架,其他类型的通信服务器可以通过它来构建。 JAWS被构造为框架的框架(framework of frameworks)。整个JAWS构架含有以下组件和构架:并发框架(Concurrency Frameworks)、事件框架(Event Frameworks)、I/O事件(I/O Events)、定时事件(Timing Events)和协议框架(Protocol Frameworks)。各个框架都被构造为一组使用ACE中的组件实现的协作对象。 本文组织如下:第2节描述JAWS框架的通讯模式优化;第3节描述在通讯模式优化基础上进行的多处理器优化;第4节描述测试环境及测试结果分析;第5节是结束语。 2 通讯模式优化 典型的客户/服务器系统采用简单的同步通讯模式:服务器等待客户端发送一个完整的请求消息,处理该请求,然后向客户端发送响应消息。当客户端发送完请求消息,但未接收到服务器的响应消息之前,客户端不会发送下一条请求消息。这种通讯模式容易理解和实现,然而存在效率低的缺点。当服务器因为某种资源的缺乏而导致消息处理过程被阻塞时,客户端却不能发送其它服务器可以并发处理的请求。这种典型的客户/服务器系统包括HTTP、
CPU主要参数
CPU,全称“Central Processing Unit”,中文名为“中央处理器”,在大多数网友的印象中,CPU只是一个方形配件,正面是金属盖,背面是一些密密麻麻的针脚或触点,可以说毫无美感可言。但在这个小块头的东西上,却是汇聚了无数的人类智慧在里面,我们今天能上网、工作、玩游戏等全都离不开这个小小的东西,它可谓是小块头有大智慧。 作为普通用户、网友,我们并不需要解读CPU里的所有“大智慧”,但CPU既然是电脑中最重要的配件、并且直接决定电脑的性能,了解它里面的部分知识还是有必要的。下面笔者将给大家介绍CPU里最重要的基础知识,让大家对CPU有新的认识。 1、CPU的最重要基础:CPU架构 CPU架构: 采用Nehalem架构的Core i7/i5处理器 CPU架构,目前没有一个权威和准确的定义,简单来说就是CPU核心的设计方案。目前CPU大致可以分为X86、IA64、RISC等多种架构,而个人电脑上的CPU架构,其实都是基于X86架构设计的,称为X86下的微架构,常常被简称为CPU架构。 更新CPU架构能有效地提高CPU的执行效率,但也需要投入巨大的研发成本,因此CPU 厂商一般每2-3年才更新一次架构。近几年比较著名的X86微架构有Intel的Netburst (Pentium 4/Pentium D系列)、Core(Core 2系列)、Nehalem(Core i7/i5/i3系列),以及AMD的K8(Athlon 64系列)、K10(Phenom系列)、K10.5(Athlon II/Phenom II 系列)。
Intel以Tick-Tock钟摆模式更新CPU 自2006年发布Core 2系列后,Intel便以“Tick-Tock”钟摆模式更新CPU,简单来说就是第一年改进CPU工艺,第二年更新CPU微架构,这样交替进行。目前Intel正进行“Tick”阶段,即改进CPU的制造工艺,如最新的Westmere架构其实就是Nehalem架构的工艺改进版,下一代Sandy Bridge架构将是全新架构。AMD方面则没有一个固定的更新架构周期,从K7到K8再到K10,大概是3-4年更新一次。 制造工艺: