【原创】r语言twitter 文本挖掘 语义分析分析附代码数据
library(dplyr)
library(purrr)
library(twitteR)
library(ggplot2)
Read the Twitter data
load("E:/service/2017/3 19 guoyufei17 smelllikeme@https://www.360docs.net/doc/d35936065.html,/trump_tweets_df.rda") Clean up the data
library(tidyr)
Find Twitter source is Apple's mobile phone or Android phone samples, clean u p other sources of samples
tweets <-trump_tweets_df %>%
select(id, statusSource, text, created) %>%
extract(statusSource, "source", "Twitter for (.*?)<") %>%
filter(source %in%c("iPhone", "Android"))
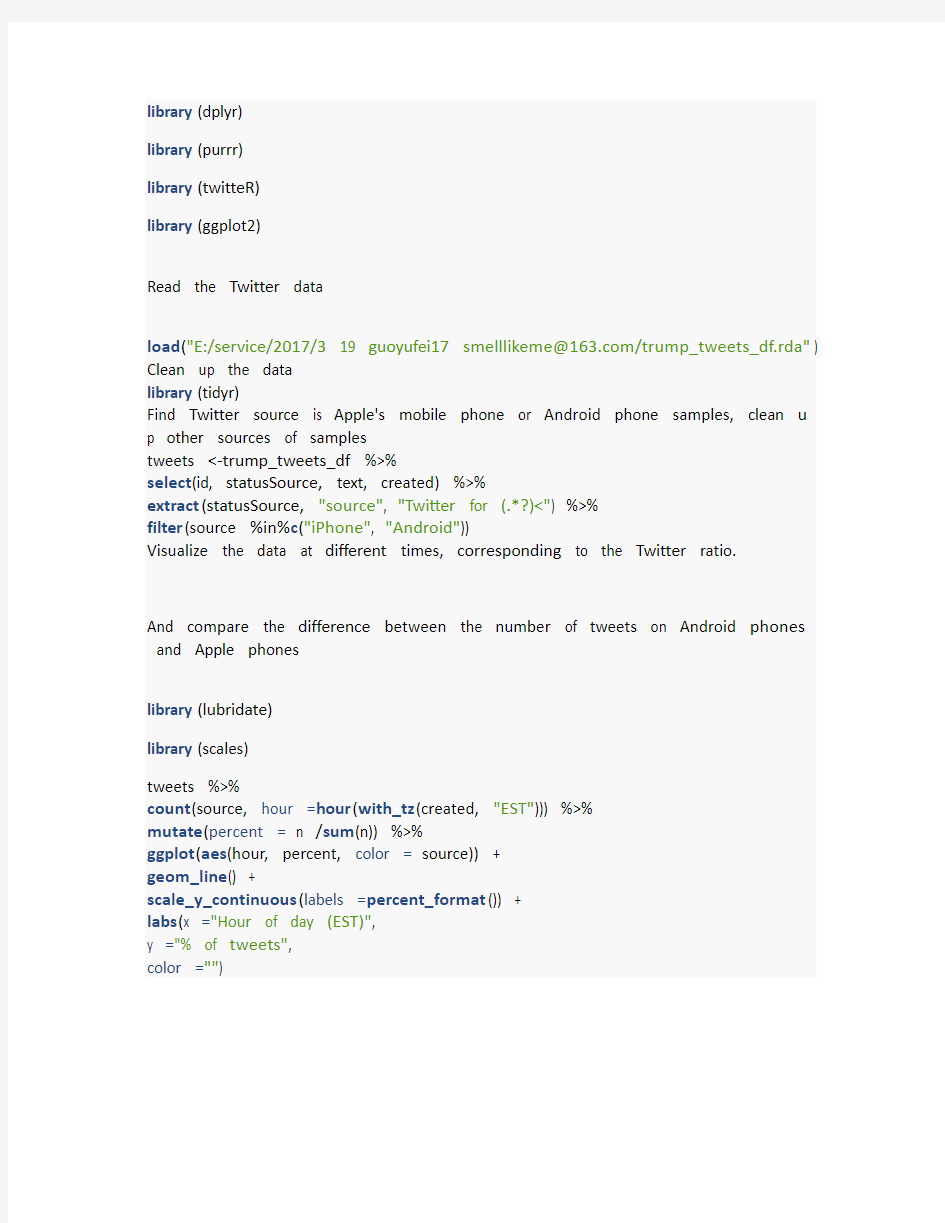
Visualize the data at different times, corresponding to the Twitter ratio.
And compare the difference between the number of tweets on Android phones and Apple phones
library(lubridate)
library(scales)
tweets %>%
count(source, hour =hour(with_tz(created, "EST"))) %>%
mutate(percent =n /sum(n)) %>%
ggplot(aes(hour, percent, color =source)) +
geom_line() +
scale_y_continuous(labels =percent_format()) +
labs(x ="Hour of day (EST)",
y ="% of tweets",
color ="")
From the comparison chart we can find, Andrews mobile phone and Apple mobile phone release Twitter time there is a significant difference, Andrews mobile phone tend to 5:00 to 10 points between the release of Twitter, and Apple phones generally in 10:00 to 20 points Around the release of Twitter. At the same time we can see, Andrews mobile phone release the number of Twitter is higher than the proportion of Apple And then check whether the Twitter contains references, and compare the number of different platforms
library(stringr)
tweets %>%
count(source,
quoted =ifelse(str_detect(text, '^"'), "Quoted", "Not quoted")) %>%
ggplot(aes(source, n, fill =quoted)) +
geom_bar(stat ="identity", position ="dodge") +
labs(x ="", y ="Number of tweets", fill ="") +
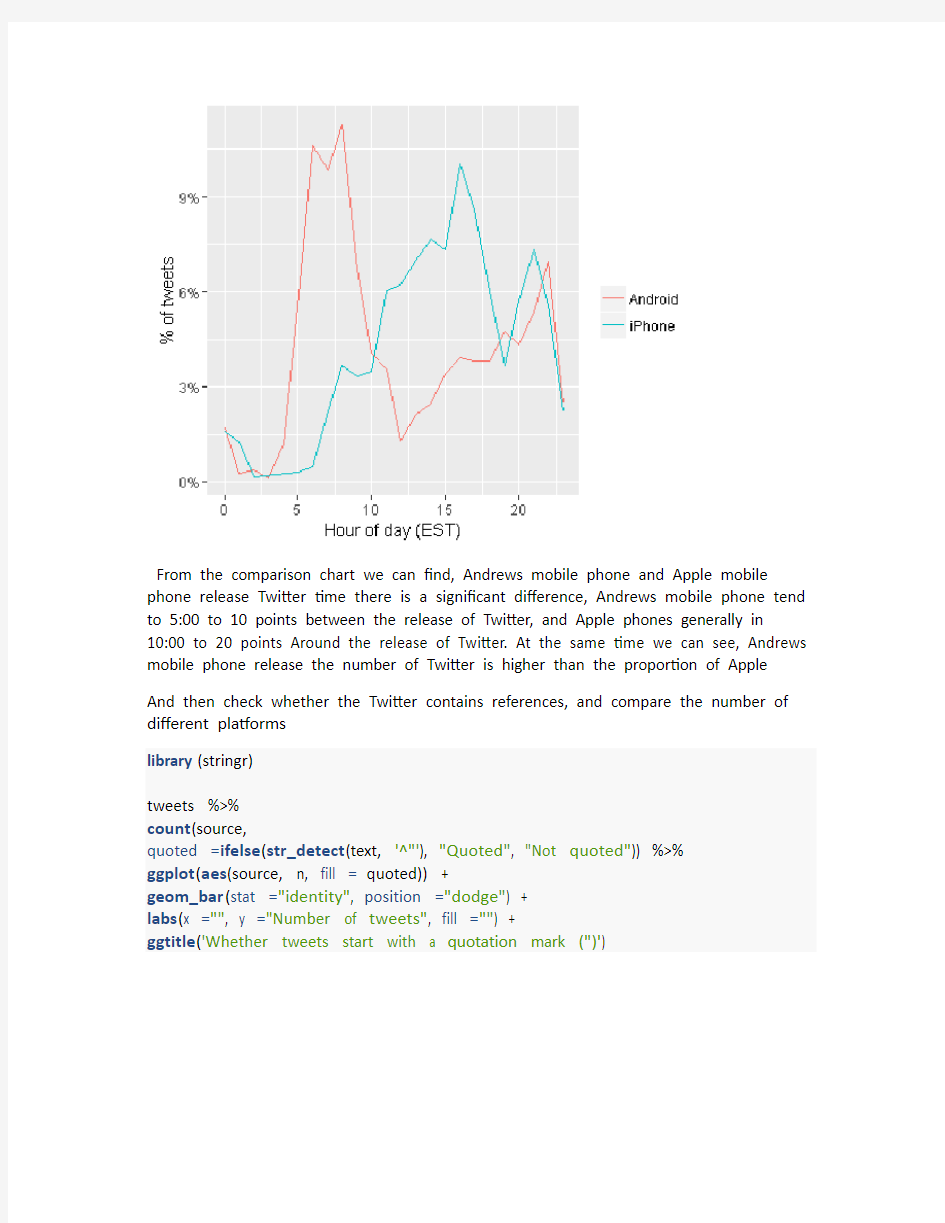
ggtitle('Whether tweets start with a quotation mark (")')
From the comparison of the results, Andrews phone, no reference to the ratio was significantly lower than Apple's mobile phone. While the number of Andrews mobile phone applications to be significantly larger than the Apple phone. So you can think that Apple's mobile phone Twitter content is mostly original, and Andrews mobile phone mostly within the application
And then check whether there are links in Twitter or pictures, and compare the situation of different platforms
tweet_picture_counts <-tweets %>%
filter(!str_detect(text, '^"')) %>%
count(source,
picture =ifelse(str_detect(text, "t.co"),
"Picture/link", "No picture/link"))
ggplot(tweet_picture_counts, aes(source, n, fill =picture)) +
geom_bar(stat ="identity", position ="dodge") +
labs(x ="", y ="Number of tweets", fill ="")
From the above comparison chart, we can see the Android phone without pictures or links to the situation with Apple, that is, the use of Apple's mobile phone users in the hair when the general will publish photos or links
At the same time you can see the Andrews platform users to push the general do not use pictures or links, and Apple mobile phone users just the opposite
spr <-tweet_picture_counts %>%
spread(source, n) %>%
mutate_each(funs(. /sum(.)), Android, iPhone)
rr <-spr$iPhone[2] /spr$Android[2]
Then we detect the abnormal characters in the Twitter, and delete them Then find the keywords in Twitter, and sort by number
library(tidytext)
reg <-"([^A-Za-z\\d#@']|'(?![A-Za-z\\d#@]))"
tweet_words <-tweets %>%
filter(!str_detect(text, '^"')) %>%
mutate(text =str_replace_all(text, "https://t.co/[A-Za-z\\d]+|&", "")) %>% unnest_tokens(word, text, token ="regex", pattern =reg) %>%
filter(!word %in%stop_words$word,
str_detect(word, "[a-z]"))
tweet_words
## # A tibble: 8,753 × 4
## id source created wor d
##
## 1 676494179216805888 iPhone 2015-12-14 20:09:15 record ## 2 676494179216805888 iPhone 2015-12-14 20:09:15 health ## 3 676494179216805888 iPhone 2015-12-14 20:09:15 #makeamericagreatagain ## 4 676494179216805888 iPhone 2015-12-14 20:09:15 #trump201 6
## 5 676509769562251264 iPhone 2015-12-14 21:11:12 accolade ## 6 676509769562251264 iPhone 2015-12-14 21:11:12 @trumpgol f
## 7 676509769562251264 iPhone 2015-12-14 21:11:12 highly ## 8 676509769562251264 iPhone 2015-12-14 21:11:12 respected ## 9 676509769562251264 iPhone 2015-12-14 21:11:12 golf ## 10 676509769562251264 iPhone 2015-12-14 21:11:12 odyssey ## # ... with 8,743 more rows
tweet_words %>%
count(word, sort =TRUE) %>%
head(20) %>%
mutate(word =reorder(word, n)) %>%
ggplot(aes(word, n)) +
geom_bar(stat ="identity") +
ylab("Occurrences") +
coord_flip()
From the figure we can see Hillary's keyword ranking is the first, followed by Trump 2016 this keyword. At the same time in the back of the keywords, we also see Trump, and Clinton and so on.
The emotional analysis of the data, and calculate the relative impact of Andrews and Apple mobile phone ratio
The emotional ratio of the different platforms is calculated by the emotional tendencies of the characteristic words, and the visualization is carried out
android_iphone_ratios <-tweet_words %>%
count(word, source) %>%
filter(sum(n) >=5) %>%
spread(source, n, fill =0) %>%
ungroup() %>%
mutate_each(funs((. +1) /sum(. +1)), -word) %>%
mutate(logratio =log2(Android /iPhone)) %>%
arrange(desc(logratio))
nrc <-sentiments %>%
文本分析平台TextMiner_光环大数据培训
https://www.360docs.net/doc/d35936065.html, 文本分析平台TextMiner_光环大数据培训 互联网上充斥着大规模、多样化、非结构化的自然语言描述的文本,如何较好的理解这些文本,服务于实际业务系统,如搜索引擎、在线广告、推荐系统、问答系统等,给我们提出了挑战。例如在效果广告系统中,需要将Query(User or Page) 和广告 Ad 投影到相同的特征语义空间做精准匹配,如果Query 是用户,需要基于用户历史数据离线做用户行为分析,如果 Query 是网页,则需要离线或实时做网页语义分析。 文本语义分析(又称文本理解、文本挖掘)技术研究基于词法、语法、语义等信息分析文本,挖掘有价值的信息,帮助人们更好的理解文本的意思,是典型的自然语言处理工作,关键子任务主要有分词、词性标注、命名实体识别、Collection 挖掘、Chunking、句法分析、语义角色标注、文本分类、文本聚类、自动文摘、情感分析、信息抽取等。 (摘自https://https://www.360docs.net/doc/d35936065.html,/nlp/,稍作修改) 在解决文本处理需求过程中,我们发现保证文本分析相关的概念、数据和代码的一致性,避免重复开发是非常关键的,所以设计并搭建一套灵活、可扩展、通用的文本分析底层处理平台,供上层应用模块使用,是非常必要的。 既然是文本分析,我们很自然的想到是否可以使用已有的自然语言处理开源代码呢?为此,我们不妨一起了解下常见的相关开源项目:
https://www.360docs.net/doc/d35936065.html, Natural Language Toolkit(NLTK),https://www.360docs.net/doc/d35936065.html,/,In Python,主要支持英文 Stanford CoreNLP,https://www.360docs.net/doc/d35936065.html,/software/index.shtml,In Java,主要支持英文,阿拉伯语,中文,法语,德语 哈工大-语言技术平台(Language Technolgy Platform,LTP),https://www.360docs.net/doc/d35936065.html,/,In C/C++,支持中文 ICTLAS 汉语分词系统,https://www.360docs.net/doc/d35936065.html,/,In C/C++,支持中文 遗憾的是,我们发现尽管这些项目都极具学习和参考价值,和学术界研究结合紧密,但并不容易直接用于实际系统。也许这正源于学术界和工业界面临的问题不同,定位不同。对比如下: 根据我们的实践经验,尝试给出一套文本分析平台设计框架 TextMiner,供大家参考、交流。 设计之初,我们想 TextMiner 应该支持以下主要功能点: 提供细粒度的中文分词、词性标注和命名实体识别; 抽取与文本内容语义相关的词或短语; 获取能够表达文本语义的主题语义; 获取能够表达文本语义的行业信息; 提供统一的数据资源管理功能,尤其,要支持同时加载多份不同版本的数据资源,便于进行更新及效果对比。 参考斯坦福大学自然语言处理组开源项目: Stanford CoreNLP 和哈尔滨工业大学社会计算与信息检索研究中心开源项目:语言技术平台 (Language
语义分析的一些方法
语义分析的一些方法 语义分析的一些方法(上篇) 5040 语义分析,本文指运用各种机器学习方法,挖掘与学习文本、图片等的深层次概念。wikipedia上的解释:In machine learning, semantic analysis of a corpus is the task of building structures that approximate concepts from a large set of documents(or images)。 工作这几年,陆陆续续实践过一些项目,有搜索广告,社交广告,微博广告,品牌广告,内容广告等。要使我们广告平台效益最大化,首先需要理解用户,Context(将展示广告的上下文)和广告,才能将最合适的广告展示给用户。而这其中,就离不开对用户,对上下文,对广告的语义分析,由此催生了一些子项目,例如文本语义分析,图片语义理解,语义索引,短串语义关联,用户广告语义匹配等。 接下来我将写一写我所认识的语义分析的一些方法,虽说我们在做的时候,效果导向居多,方法理论理解也许并不深入,不过权当个人知识点总结,有任何不当之处请指正,谢谢。 本文主要由以下四部分组成:文本基本处理,文本语义分析,图片语义分析,语义分析小结。先讲述文本处理的基本方法,这构成了语义分析的基础。接着分文本和图片两节讲述各自语义分析的一些方法,值得注意的是,虽说分为两节,但文本和图片在语义分析方法上有很多共通与关联。最后我们简单介绍下语义分析在广点通“用户广告匹配”上的应用,并展望一下未来的语义分析方法。
1 文本基本处理 在讲文本语义分析之前,我们先说下文本基本处理,因为它构成了语义分析的基础。而文本处理有很多方面,考虑到本文主题,这里只介绍中文分词以及Term Weighting。 1.1 中文分词 拿到一段文本后,通常情况下,首先要做分词。分词的方法一般有如下几种: ?基于字符串匹配的分词方法。此方法按照不同的扫描方式,逐个查找词库进行分词。根据扫描方式可细分为:正向最大匹配,反向最大匹配, 双向最大匹配,最小切分(即最短路径);总之就是各种不同的启发规则。 ?全切分方法。它首先切分出与词库匹配的所有可能的词,再运用统计语言模型决定最优的切分结果。它的优点在于可以解决分词中的歧义问 题。下图是一个示例,对于文本串“南京市长江大桥”,首先进行词条检索(一般用Trie存储),找到匹配的所有词条(南京,市,长江,大桥,南京市,长江大桥,市长,江大桥,江大,桥),以词网格(word lattices)形式表示,接着做路径搜索,基于统计语言模型(例如n-gram)[18]找到最优路径,最后可能还需要命名实体识别。下图中“南京市长江大桥” 的语言模型得分,即P(南京市,长江,大桥)最高,则为最优切分。 图1. “南京市长江大桥”语言模型得分
【原创】r语言twitter 文本挖掘 语义分析分析附代码数据
library(dplyr) library(purrr) library(twitteR) library(ggplot2) Read the Twitter data load("E:/service/2017/3 19 guoyufei17 smelllikeme@https://www.360docs.net/doc/d35936065.html,/trump_tweets_df.rda") Clean up the data library(tidyr) Find Twitter source is Apple's mobile phone or Android phone samples, clean u p other sources of samples tweets <-trump_tweets_df %>% select(id, statusSource, text, created) %>% extract(statusSource, "source", "Twitter for (.*?)<") %>% filter(source %in%c("iPhone", "Android")) Visualize the data at different times, corresponding to the Twitter ratio. And compare the difference between the number of tweets on Android phones and Apple phones library(lubridate) library(scales) tweets %>% count(source, hour =hour(with_tz(created, "EST"))) %>% mutate(percent =n /sum(n)) %>% ggplot(aes(hour, percent, color =source)) + geom_line() + scale_y_continuous(labels =percent_format()) + labs(x ="Hour of day (EST)", y ="% of tweets", color ="")
文本信息分析
文本信息分析 1.中文文本信息过滤技术研究 1.1文本过滤技术 文本信息过滤是指依据一定的标准和运用一定的工具从大量的文本数据流中选取用户需要的信息或剔除用户不需要的信息的方法[1]。文本过滤和文本检索及文本分类有很大的相似之处。 1.1.1文本信息过滤技术发展 1958年Luhn提出的“商业智能机器”是信息过滤的最早雏形。Luhn所提出的构想涉及了信息过滤系统的每一个方面,为后来的文本过滤做了很好的铺垫。1982年,Dernzing 首次提出了“信息过滤”的概念,在他描述的例子中,可以通过“内容过滤器”识别出紧急邮件和一般邮件,以此提示对信息内容进行有效控制。1987年,Malone等人提出了三种信息选择模式,即认知、经济、社会。认知模式相当于“基于内容的信息过滤”;经济模式来自于Denning的“阈值接受思想”;社会模式是他最重要的贡献,即“协同过滤”。1989年,美国消息理解大会(Message Understand Conference)成立,将自然语言处理技术引入到信息研究中来,极大地推动了信息过滤的发展。 20世纪90年代以来,著名的文本检索会议TREC(Text Retrieval Conference)每年都把文本过滤当作一个很重要的一个研究内容,这很大程度上促进了文本过滤技术的发展。从TREC-4开始,增加了文本过滤的项目;从1997年TREC-6开始,文本过滤主要任务确定下来;TREC-7又将信息分为自适应过滤、批过滤和分流过滤,使得对信息过滤的研究更加深入。 随着信息过滤需求的增长和研究的深入发展,其他领域的许多技术被应用到文本过滤中来,并取得了很好的效果。如信息检索中的相关反馈、伪相关反馈以及文本检索中的向量空间模型的相关技术,文本分类和聚类技术,机器学习以及语言底层的处理技术都被应用到信息过滤中来,极大地拓展了信息过滤的研究广度,推动着信息过滤理论研究与技术应用不断走向完善与成熟。 1.1.2中文本过滤技术 中文文本过滤技术在最近几年得到了业内人士的普遍关注。国内对于信息过滤研究起步较晚,但是目前发展也很快,尤其是随着信息安全、信息定制等应用在国内的兴起,对信息过滤技术的研究也得到人们普遍的重视。其中,中科院计算所、复旦大学都曾参加了TREC 评测中的信息过滤任务,取得了较好的成绩;哈工大、南开大学等重点科研单位也已经开始对信息过滤进行研究。 然而,基于目前提出的中文文本过滤模型开发出的试验系统在不同的领域达到的过滤精度也不相同。由于中英文语法差异较大,对于文本信息的预处理方法不同,因此面向英文的众多过滤算法是否适合中文文本过滤还有待检验[2]。 1.2中文文本过滤的关键技术 文本过滤工作基本上可以概括为两项:一是建立用户需求模型,表达用户对信息的具体需求;二是匹配技术,即用户模板与文本匹配技术。因此,文本过滤的主要流程首先是根据用户的信息需求,建立用户需求模型,然后在相应的文本流中搜索符合用户需求的文本,同时,利用反馈改进需求模型。文本过滤系统的一般模型如图1所示:
文本情感分析综述
随着企业信息化与互联网的发展,信息以爆炸性速度飞速增长,其中包括了大量的非结构化与半结构化数据。非结构化与半结构化数据,主要是文本型数据,阐述5w问题,即who,when,where,what,Why。如何充分利用非结构化数据与半结构化数据,分析其包含的潜在信息,拥有支持决策,成为了众多企业与研究者关注的重点。尤其,针对互联网(如博客和论坛)上大量的用户参与的、对于诸如人物、事件、产品等有价值的评论信息。这些评论信息表达了人们的各种情感色彩和情感倾向性,如喜、怒、哀、乐和批评、赞扬等。基于此,潜在的用户就可以通过浏览这些主观色彩的评论来了解大众舆论对于某一事件或产品的看法。由于越来越多的用户乐于在互联网上分享自己的观点或体验,这类评论信息迅速膨胀,仅靠人工的方法难以应对网上海量信息的收集和处理,因此迫切需要计算机帮助用户快速获取和整理这些相关评价信息。因此,如何从这些Web文本中进行情感挖掘,获取情感倾向已经成为当今商务智能领域关注的热点。情感分析(sentiment analysis)技术也就应运而生(本文中提及的情感分析,都是指文本情感分析)。 文本情感分析(sentiment analysis),又称为意见挖掘,是对带有情感色彩的主观性文本进行分析、处理、归纳和推理的过程。其中,主观情感可以是他们的判断或者评价,他们的情绪状态,或者有意传递的情感信息。因此,情感分析的一个主要任务就是情感倾向性的判断,Pang等人在文献1中将情感倾向分为正面、负面和中性,即褒义、贬义和客观评价。研究初期,大量研究者都致力于针对词语和句子的倾向性判断研究,但随着互联网上大量主观性文本的出现,研究者们逐渐从简单的情感词语的分析研究过渡到更为复杂的情感句研究以及情感篇章的研究。文本情感分析主要可以归纳为3项层层递进的研究任务,即情感信息的抽取、情感信息的分类以及情感信息的检索与归纳[2]。情感信息抽取就是将无结构的情感文本转化为计算机容易识别和处理的结构化文本。情感信息分类则是利用情感信息抽取的结果将情感文本单元分为若干类别,供用户查看,如分为褒、贬、客观或者其他更细致的情感类别。情感信息检索和归纳可以看作是与用户直接交互的接口,强调检索和归纳的两项应用。 情感分析是一个新兴的研究课题,具有很大的研究价值和应用价值,正受到国内外众多研究者的青睐。目前实现情感分析的技术主要包括基于机器学习法和基于语义方法两类。本文主要针对这两大方法的研究进展进行比较分析,接着介绍国内外现有的资源建设情况,最后介绍情感分析的几个重要应用和展望它的发展趋势。 1 基于统计机器学习法 随着大规模语料库的建设和各种语言知识库的出现,基于语料库的统计机器学习方法进入自然语言处理的视野。多种机器学习方法应用到自然语言处理中并取得了良好的效果,促进了自然语言处理技术的发展。机器学习的本质是基于数据的学习(Learning from Data)。利用机器学习算法对统计语言模型进行训练,最后用训练好的分类器对新文本情感进行识别。2002年,Pang 等人就在文献[1]中提出用机器学习的方法进行情感倾向的挖掘工作,他们以互联网上的电影评论文本作为语料,采用了不同的特征选择方法,应用朴素贝叶斯(Naive Bayes)、最大熵(Maximum Entropy)、向量机(SVM)对电影评论分别进行分类,实验表明SVM 的分类性能最好,准确率达到87.5%。该研究引起学术界的关注,之后用于倾向性判断的机器学习算法的改进被陆续提出,基本的算法有:支持向量机(SVM)、朴素贝叶斯(NB)、K-近邻(KNN)、简单线性分类器(SLC)和最大熵(ME)等。他们在另一项工作中,将文本极性分类问题转换成求取句子连接图的最小分割问题,实现了一个基于minimum-cut的分类器。[7]。Whitelaw等人[11]关注研究带形容词的词组及其修饰语(如“extremely boring”或“not really verygood”),他们提取带形容词的词组作为特征,基于这些特征,用向量空间模型表示文