计算机系统应用2011年排版样式20101130
《Office 2010办公自动化高级应用》第1章 计算机基础知识 任务3:计算机中信息的表现形式

)16 =
()2
5 数字在计算机内的表示
(1).正数与负数 (2).原码、补码、反码 (3).定点数和浮点数
(1).正数与负数
在计算机中数的符号也是用数码来表示 的,一般用“0”表示正数的符号,“1” 表示负数的符号,并放在数的最高位。
例如: (01011)2 = (+11)10
1. 进位计数制
根据不同的进位原则,可以得到不同的进位制。在日常 生活中,人们广泛使用的是十进制数,有时也会遇到其他 进制的数,例如,钟表上,六十秒钟为一分钟,六十分钟 为一小时,即为六十进制。
在计算机中,最常使用的是:
(1)十进制 (2)二进制 (3)八进制 (4)十六进制
(1)十进制
十进制记数法有两个特点:
(11011)2 = (-11)10
(2).原码、补码、反码
原码表示法:用符号位和数值表示带符号数,正数的符 号位用“0”表示,负数的符号位用“1”表示,数值部分 用二进制形式表示。
3.十进制数与八、十六进制数之间的转换
(1)八进制、十六进制数转换成十 进制数
(2)十进制数转换成八进制、十六 进制数
(1)八进制、十六进制数转换成十进制数
同二进制数到十进制数的转换一样,分别套 用相应公式 。
CD==cdnn--11816n-n1-+1c+nd-n2-82n1-62n+-…2 ++…c 18 1 +
(2)二进制
为什么采用二进制?
① 数字符号表示简单容易,只要选用双态元件,如 单向导电元件,磁性元件,发光元件,就可以十 分简单地表示出数位上的数字0和1了;因此代价 低廉,容易实现和使用。
《计算机应用基础》教案——office2010版2014

2.8.2 精装图书
2.8.3 常见版式及其规格
2.8.4 版心设计
2.9 页面设置
2.9.1 设置纸张大小与纸张方向
2.9.2 设置页边距
2.10 文档的分页与分节
2.10.1 设置分页
2.10.2 设置分节符
2.11 页码
2.12 设置页眉与页脚
2.12.1 创建页眉或页脚
2.12.2 为奇偶页创建不同的页眉和页脚
2.1.5 关闭文档
2.1.6 认识Word2010的视图模式
2.2 输入文本
2.2.1 输入中/英文字符
2.2.2 插入符号和特殊符号
2.2.3 插入公式
2.3 修改文本的内容
2.3.1 选择文本
2.3.2 复制文本
2.3.3 移动文本内容
2.3.4 删除文本内容
2.3.5 查找与替换文本
2.4 设置文本格式
窍门4:取消自动插入项目符号和编号的功能
窍门5:为文档设置水印
第3章使用表格与图文混排
3.1 创建表格
3.1.1 自动创建表格
3.1.2 手动创建表格
3.1.3 在表格中输入文本
3.2 编辑表格
3.2.1 在表格中选定内容
3.2.2 移动或复制行或列
3.2.3 在表格中插入与删除行和列3.2.4 在表格中插入与删除单元格
《计算机应用基础》
电子教案
《计算机应用基础》教案
《计算机应用基础》教案
《计算机应用基础》教案
《计算机应用基础》教案
《计算机应用基础》教案
《计算机应用基础》教案
《计算机应用基础》教案
《计算机应用基础》教案
《计算机应用基础》教案
Word2010职场排版应用(经典版)PPT模板

1-14利用样式进行排版样式是Word效 率排版的利器....
1-15如何套用自定义样式自定义样式... 及模板保存方法!
1-16样式表的迁移样式表迁移,可以 让你快速排出风格一样的文档.
1-17文档部件构建基块(新功能) Word2010的新功能,用来干嘛的呢? 想了解的可以进来看看!
1-18利用样式实现文档标题章节化想 知道第一章的第1部分第一节这种带编 号的样式设置嘛?弄成样式集之后,你 懂得,排版那还是排版吗?那是秒排.
1-3理解段落的分页与换行段落属性面 板你都理解吗?这是根本中的根本....
1-2段落的精准控制段落如何在Word 中控制....还是细节....
1-4制表位的精准对齐对齐靠什么,就 靠制表位....
1-5理解段落的分页与换行段落属性面 板你都理解吗?这是根本中的根本....
1-6默认快速制表位有时候对齐不需要 那么精确,但速度要跟上...
第1章页面排版的精髓
1-7标尺快速制表位制表位设置的 方法非常灵活,这不有一招,非常 厉害的。
1-8高级制表位如果你想对齐的效 率更高更快....这个视频不可不看.....
1-9小数点制表位的秘密(2013) 有一天,一哥们说他不想小数点对 齐,要等好对齐,要加号对齐,要 各种对齐...秦老师以不变应万变, 牛牛的搞定...这个秘密,一般人不 告诉的哟。
1-10替换在word中的重要性替换 是进行排版前,文本初始化时候很 好的一个工具...
1-11快速创建满足列宽的表格都说 在word中调整表格很麻烦...你学完 这集....你就完全明白了。
1-12如何快速制作填空题替换的一 种应用...
第1章页面排版的精髓
1-13利用文本框链接排版文本框排版 有时候比直接排版方便...
第4章Word样式排版

本章要点
表格的制作与设计 主题 应用样式 修改样式 新建样式 使用样式排版文档的制作流程
任务提出
• 吕小布是舞蹈协会的宣传部部长,要为 新会员街舞知识培训制作一份街舞知识 手册。
• 如何才能制作出一份图文并茂、活泼生 动的知识手册呢?又该如何利用Word 2010来对这些资料进行内容管理和排版 制作呢?
路线图
使用标题样式制作大纲结构 完善内容
应用主题设置文档整体风格 应用内置样式对文档进行排版
新建样式对文档进行排版 文档细节处理
文档的大纲结构
标题1
标题2 标题3
标题3
标题3 标题3
输入大纲、应用标题样式
“快速样式库”列表
丰富Word文档内容
• 文档内容单调!文档目前只有文字内容 ,读者阅读时难免觉得枯燥无味,如何 解决这个问题呢?
规划本文档中用到的样式
样式名
应用内容
样式来源
标题 标题1 标题2 标题3 要点 文档正文 表格标题 表格正文
标题“街舞知识手册”
内置样式
标题“起源”、“舞种”、“舞蹈要点”内置样式 舞种下的子标题、舞蹈要点下的子标题 内置样式
第3级标题 段落中的重点文字
内置样式 内置样式
所有的正文文本
新建样式
表格中的标题 表格中其它的文字
课后习题
• 打开Word文档“世界自然文化遗产之 黄山(素材)”,对其进行排版,要 求:
• 插入封面。 • 插入图片并设置图片格式。 • 插入表格并设计表格样式。 • 利用样式进行排版,格式自定。
2.41倍行距,段前17磅,段后16.5 磅
1.15倍行距,段前间距24磅
主题标题字体,三号,加粗 1.73倍行距,段前13磅
2010~2011学年度第一学期

2010~2011学年度第一学期
授课课程:Photoshop 授课教师:闫双
4、栅格化文字
选择菜单“图层 >
如果要取消文字的变形效果,可以调出“变形文字”对话框,在“样式”
2、课堂案例——制作食品宣传单
【练习知识要点】使用文字工具输入文字,使用创建变形文字命令制作变形文
3、课堂案例——制作旅游宣传卡片
【练习知识要点】使用段落文本框制作文字,使用钢笔工具绘制路径,使用文本工具沿着路径排列文字。
4、课堂练习——制作首饰广告
【练习知识要点】使用图层样式命令为图像添加投影效果。
使用羽化命令制作图形的模糊效果。
使用图层混合模式命令制作图像的叠加效果。
使用圆角矩形工具和高斯模糊命令制作戒指投影效果。
使用自定形状工具绘制装饰花形。
使用钢
四、课堂小结。
word综合排版操作步骤图解说明2010版本
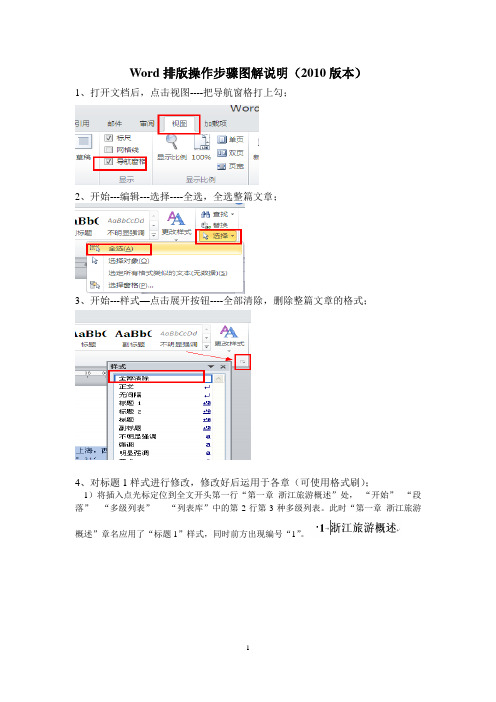
Word排版操作步骤图解说明(2010版本)1、打开文档后,点击视图----把导航窗格打上勾;2、开始---编辑---选择----全选,全选整篇文章;3、开始---样式—点击展开按钮----全部清除,删除整篇文章的格式;4、对标题1样式进行修改,修改好后运用于各章(可使用格式刷);1)将插入点光标定位到全文开头第一行“第一章浙江旅游概述”处,“开始”--“段落”---“多级列表”-----“列表库”中的第2行第3种多级列表。
此时“第一章浙江旅游概述”章名应用了“标题1”样式,同时前方出现编号“1”。
2)开始---样式—点击展开按钮---标题1---修改3)编号—定义编号格式---在原编号“1”的前、后分别增加“第”和“章”字4)找到全文后方的所有四章的章名,全部应用为修改好后的“标题1”样式。
5、开始---样式—点击展开按钮---标题2---修改,对标题2样式进行修改,修改好后运用于各小节(可使用格式刷);6、新建样式设置。
把光标放到正文处,进行新建样式设置。
开始---样式—点击展开按钮---新建样式,对字体与段落进行设置。
7、图题注设置。
选中图后右击---插入题注---新建标签---输入标签“图”----确定,点击---编号---把包含章节号打上勾---分隔符选择连字符。
8、表题注设置。
选中表后右击---插入题注---新建标签----输入标签“表”----确定;点击---编号---把包含章节号打上勾---分隔符选择连字符;位置选择所选项目上方。
9、对图与表中的下图下表进行交叉引用。
选中下图文字引用---题注---交叉引用---引用类型选择图,引用内容选择只有标签和编号,引用哪一个题注选择对应的图名---插入。
相似进行下表交叉引用设置,引用类型改成表,其他相似。
10、插入脚注。
光标放在正文开始处,搜索要插入脚注的文字(开始—编辑---查找—高级查找---输入查找的文字—确定),把光标放在对应文字的后边,引用---脚注---插入---插入脚注-输入对应文字。
《计算机应用基础》教案——office2010年版2014年.5.15

应用范围 科学计算
第二代 第三代
58-64 65-70
晶体管
高级语言
小规模集成 操作系统 电路
科学计算、数据处理、 工业控制 科学计算、数据处理、 工业控制、文字处理、 图形处理
第四代 70 至今 大规模集成 数 据 库 网 各个领域
电路
络等
3、计算机技术发展的趋势
巨型化、高性能、开放式、多媒体化、智能化、网络化
操作系统:是管理和控制计算机的全部硬件、软件资源的程序。 主要功能 有:用户与计算机硬件的接口、硬件功能的扩充、计算机系统的控制及管理等。 (2) 语言处理程序
机器语言 汇编语言 高级语言:Basic 语言、Pascal 语言、 C 语言、 Java 语言等。
(3)实用程序
一些公用的工具性程序,如:编辑程序 EDIT,调试程序 DEBUG,诊断程序等。
详细内容及要求
第三讲、数据编码和进制转换(2 学时) 1、编码指采用少量的基本符号按照一定原则,用以表示大量的、复杂多样的信 息。 1)BCD 编码
BCD 码是指“二- 十进制码”,即一位十进制对应四位二进制数。 2)字符编码
字符编码采用的是“ASCII 码”,即美国标准信息交换代码。 3)汉字编码
《计算机应用基础》教案
教学对象
第一章 计算机基础知识 教学内容 1.2 计算机病毒初步知识概述
教学目的
1.什么是计算机病毒; 2.计算机病毒谁来制作 3. 计算机病毒的特征, 4. 怎么预防计算机病毒
教学重点 掌握计算机病毒的方法。
教学时间Biblioteka 月日教学难点 了解计算机病毒
建议学时 理论:2
教学教具
多媒体教学系统
教学时间
教学重点
计算机应用基础期末试卷A(A3版)

7、在页面视图中可通过拖动栏调节标志调整栏宽。 ( √ )
8、关闭幻灯片可以从“文件”菜单中关闭。 ( √ )
9、鼠标不能取代键盘。 (√ )
10、操作系统是软件和硬件的接口。 ( √ )
三、简答题(每小题10分,共40分)
1、简述“样式”的概念、功能及用法。
C)瑞星2008D)Internet Explorer
24、在Word文档中,要把多处同样的错误一次更正,正确的方法是( D )。
A)插入光标逐字查找,先删除错误文字,再输入正确文字
B)使用“定位”命令
C)使用“撤消”菜单中的“恢复”命令
D) 使用“编辑”菜单中的“替换”命令
25、下面关于Word中字号的说法,错误的是( D )。
39、下列各项中,不是微型计算机的主要性能指标的是( B )。
A)内存容量 B)硬盘容量
C)字长 D)主频
40、ISP的中文名称为(B)。
A)Internet软件提供者B)Internet服务提供者
C)Internet访问提供者D)Internet应用提供者
二、判断题(每小题2分,共20分,对的打“√”,错的打“ⅹ”。请在答题纸上填写答案。)
3、简述计算机网络的发展历程。
一、计算机网络的形成与发展经历了四个阶段:
第一阶段:计算机技术与通信技术相结合,形成了初级的计算机网络模型。此阶段网络应用主要目的是提供网络通信、保障网络连通。这个阶段的网络严格说来仍然是多用户系统的变种。美国在1963年投入使用的飞机定票系统SABBRE-1就是这类系统的代表。
A)作者 B)地址
C)设计原则D)制作过程
37、PowerPoint 2003中自带很多的图片文件,将它们加入演示文稿中,应插入的对象是(A)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2011年第20卷第1期 计算机系统应用①基金项目:安徽省教育厅自然科学基金(2005KJ004ZD)收稿时间:2010-01-06;收到修改稿时间:2010-02-26System Construction 系统建设1Web信息抽取及知识表示系统的研究与实现①谭守标1, 徐超1, 江元1, 宁仁霞1,21(安徽大学电子科学与技术学院,合肥230039)2(黄山学院电子信息工程系,黄山245021)摘要:研究了从数据密集型Web页面中自动提取结构化数据并形成知识表示系统的问题。
基于知识数据库实现动态页面获取,进行预处理后转换为XML文档,采用基于PAT-array的模式发现算法自动发现重复模式,结合基于本体的关键词库自动识别页面数据显示结构模型,利用XML的对象-关系映射技术将数据存入知识数据库,由此实现Web数据自动抽取。
同时,利用知识数据库已有知识从互联网抽取新知识,达到知识数据库的自扩展。
以交通信息自动抽取及混合交通出行方案生成与表示系统进行的实验表明该系统具有高抽取准确率和良好的适应性。
关键词:Web信息提取;知识表示;数据密集型Web页面;基于本体的关键词库Research and Realization of a Web Information Extraction and Knowledge Presentation System TAN Shou-Biao1, XU Chao1, JIANG Y uan1, NING Ren-Xia1,21(School of Electronic Science and Technology, Anhui University, Hefei 230039, China)2(Electronic Information Engineering, Huangshan University, Huangshan 245021, China)Abstract:The Web Information Extraction and Knowledge Presentation System is proposed to extract information from data intensive web pages. It downloads dynamic web pages, based on a knowledge database, changes them to XML documents after preprocessing, finds repeated patterns from them, by using a PA T-array based Pattern Discovery Algorithm, recognizes their data display structure models, automatically based on the repeated patterns and an ontology-based keyword library, and then extracts the data and stores them in the knowledge database with the object-relational mapping technology of XML. Through these steps, web data is extracted automatically, and the knowledge database is also expanded automatically. Experiments on the traffic information auto-extraction and mixed traffic travel schemes auto-creation system showed that the system has high precision and is adaptive to web pages in different domains with different structures.Keywords:web information extraction; knowledge presentation; data intensive web pages; ontology-based keyword library随着Internet的迅猛发展,Web已经成为全球传播与共享科研、教育、商业和社会信息等最重要和最具潜力的巨大信息源。
Web信息抽取是指从Web页面所包含的无结构或半结构的信息中识别用户感兴趣的数据,并将其转化为结构和语义更为清晰的格式,以统一的形式集成在一起,使Web信息的再利用成为可能,成为当前研究的一个热点[1]。
目前关于Web信息抽取的工作可以大致分为以下几个类别:基于特征模式匹配的信息抽取、基于归纳学习的信息抽取、基于网页结构特征分析的信息抽取、基于本体的Web信息抽取等。
由于Web页面的种类繁多且信息抽取目的也不尽相同,不存在一种Web信息抽取系统,能够适应这种千变万化的应用环境。
现有各种抽取方法针对不同领域、不同结构页面的通用性上也都存在一些问题[2-9]。
由于目前很多Web页面是动态生成的,以列表或表格的方式集中显示后台数据库中的数据,这种类型的页面对于数据集成等现实应用具有重要意义,抽取准确度也相对较高。
本文针对于数据密集型的Web页面,开发出一种新的Web信息抽取和知识表示系统,通过基于PA T-array的模式发现算法[10]和基于本体的计算机系统应用 2011年第20卷第1期2系统建设 System Construction 关键词库的结合大大提高了信息抽取算法的准确性和通用性,基于Web 信息抽取的混合交通出行方案生成与表示系统的成功实验也证明了本文提出的Web 信息抽取算法的实用性。
1 系统概述本系统总体分成三部分:相关Web 页面获取模块、Web 信息抽取模块、知识表示模块。
系统总体框图如图1所示。
图1 系统总体框图相关Web 页面获取模块:以知识数据库中现有知识为基础,根据Web 站点配置信息生成动态URL 从互联网上获取与所需知识相关的Web 页面。
Web 信息抽取模块:采用基于PAT-array 的模式发现算法发现数据密集型Web 页面中的重复模式,结合基于本体的关键词库自动识别页面数据显示结构模型,利用XML 的对象-关系映射技术,将数据存入知识数据库。
知识表示模块:以B/S 架构提供知识表示服务,根据用户的输入从知识数据库中智能化搜索并生成用户需要的解决方案。
2 各模块的算法设计与实现2.1 相关Web 页面获取数据密集型页面往往由Web 站点根据用户的查询请求动态生成,从同一站点能得到大量同类型的动态页面。
据此,系统以知识数据库为基础,采用Web 站点配置方式,根据Web 站点响应查询请求方式,人工配置含特定知识的Web 站点信息及其动态页面URL 生成规则。
用知识数据库中现有知识作为查询参数,生成相关Web 站点的动态URL ,通过HTTP 协议自动获取相关Web 页面。
如网站 提供根据地名查询经过该地的所有列车车次信息,其响应查询请求的方式为/tr/category91.asp?categoryid=$,此处$代表要查询的站名。
系统从知识数据库的地点信息中检索得到各个地名,替换$即生成该网站动态URL 。
2.2 Web 信息抽取本模块算法流程如图2所示:图2 Web 信息抽取流程2.2.1 页面精简普通网页常常包含很多Header 部页面属性信息、脚本、样式、注释、图片、隐含数据、空格、标签属性设置及一些无用标签等,这些信息中不含有集中式数据,对造成后续处理速度缓慢,甚至使后续处理无法进行,需要首先进行页面精简,去掉这些冗余信息。
本系统采取采用正则表达式技术进行如下页面精简操作:① 清除body 以外的部分;② 清除文档中的脚本(<script 脚本内容 </script>)、样式(<style 样式内容</style>)、注释(<!--注释内容-->)、隐含内容(<input type=”hidden ” 隐含内容>)、图片内容(<img 图片内容>);③清除文档中没有实际内容的标签对(只含空2011年第20卷第1期 计算机系统应用System Construction 系统建设 3格、换行符等)(递归清除);④ 将连续多个“  ”和“ ”替换成一个空格“ ”;⑤ 清除标签的属性信息。
2.2.2 XML 转换由于HTML 语法的随意性,即使经过页面精简,仍无法保证HTML 文档的结构特性。
而XML 是一种结构化的自解释语言,更方便于进行重复模式发现,且在数据抽取过程中采用了XML 的对象-关系映射技术,需要将HTML 文档转换成XML 文档。
本系统采用开源的Jtidy 工具,实现HTML 文档到XML 文档的转换[11]。
2.2.3 重复模式发现数据密集型Web 页面的一个显著特点是数据显示区域(绝大部分情况是列表或表格形式)具有很强的重复模式,针对这一特点,可以通过重复模式的发现,很方便的确定页面数据显示区域的结构。
本系统采用基于PAT-array 的算法实现快速的文档内重复模式的发现。
具体步骤如下:① 令牌翻译:对HTML 中与数据显示相关的标签进行编码,将转换得到的XML 文档翻译成二进制字符串;② PAT 数组构造:罗列二进制字符串的所有半串(从每个编码到结束位置构成一个半串),按序排列后得到每个半串起始位置序号构成PAT 数组;③ 候选重复模式发现:使用栈操作,搜索得到所有半串的共同前缀即为候选重复模式;④ 最佳重复模式确定:根据最优化标准从候选重复模式中确定出最佳重复模式。
2.2.4 概念消歧单纯的重复模式发现算法只能得到笼统的数据显示结构,无法区分真正的数据及其语义(标题)。
本系统采用基于本体的关键词库从重复模式中区分出标题项和数据项,最终确定准确的数据显示结构。
对于自然语言表示的Web 文档,其中存在大量同义的词汇,在进行标题识别前需要进行概念消歧处理,利用概念标注库,将特定领域的同义词汇转换为关键词库中的本体词。
2.2.5 页面数据显示结构识别本系统采用XML 的对象-关系映射技术实现数据抽取,页面数据显示结构的识别即为XML 文档对象模型(DOM)的确定。
步骤如下:① 标题定位:使用关键词库中特定领域的本体词集合,对页面中符合重复模式的数据进行搜索和定位,确定出其中的标题项;② 标题-数据映射关系识别:根据确定出来的标题项集合的相对关系及与重复模式中其他数据项的相对关系,确定出各个标题项与数据项的映射关系;③ DOM 树生成:根据重复模式及确定出的各个标题项与数据项的映射关系,生成对应的DOM 树。