数据模型与决策课程大作业(完整资料).doc
《数据模型与决策》练习题及答案1

《数据模型与决策》练习题及答案1 《管理统计学》习题解答(2010年秋MBA周末二班,邢广杰,学号: ) 第3章描述性统计量(一) P53 第1题抽查某系30个教工,年龄如下所示:61,54,57,53,56,40,38,33,33,45,28,22,23,23,24,22,21,45,42,36,36,35,28,25,37,35,42,35,63,21(i)求样本均值、样本方差、样本中位数、极差、众数;(ii)把样本分为7组,且组距相同。
作出列表数据和直方图;(iii)根据分组数据求样本均值、样本方差、样本中位数和众数。
解:n1(i)样本均值=37.1岁 x,x,in,i1nn211222样本方差=189.33448 s,(X,X),(X,nX),,iin-1n-1,,i1i1把样本按大小顺序排列:21,21,22,22,23,23,24,25,28,28,33,33,35,35,35,36,36,37,38,40,42,42,45,45,53,54,56,57,61,631样本中位数=(35+36)/2=35.5岁 m,(X,X)nn()(,1)222R,X,X,极差63-21=42岁 (n)(1)m,众数35岁 0(ii)样本分为7组、且组距相同的列表数据、直方图如下所示累计频教工分组教工年龄组中值数教职工岁数分组频数图f频数() 分组(岁) (x) i(16,23] 6 19.5 6 108(23,30] 4 26.5 106(30,37] 8 33.5 18 频数频数4(37,44] 4 40.5 222(44,51] 2 47.5 24 0(51,58] 4 54.5 28 23303744515865教职工岁数(58,65] 2 61.5 30(iii)根据分组数据求样本均值、样本方差、样本中位数和众数。
k1样本均值=36.3岁 X,Xif,in,i11kk211222样本方差=174.3724 s,(X,X)f,(Xf,nX),,iiiin-1n-1,,i1i1n30,F,1022样本中位数=34.375岁 m,I,i,30,7f8ff,84,mm-1众数33.5岁 mIi307,,,,,02fff2844,,,,,mm-1m,1 (二) P53 第2题某单位统计了不同级别的员工的月工资水平资料如下:月工资(元) 800 1000 1200 1500 1900 2000 2400员工数(人) 5 8 25 36 24 16 6累计频数 5 13 38 74 98 114 120求样本均值、样本标准差、样本中位数和众数。
数据模型与决策作业
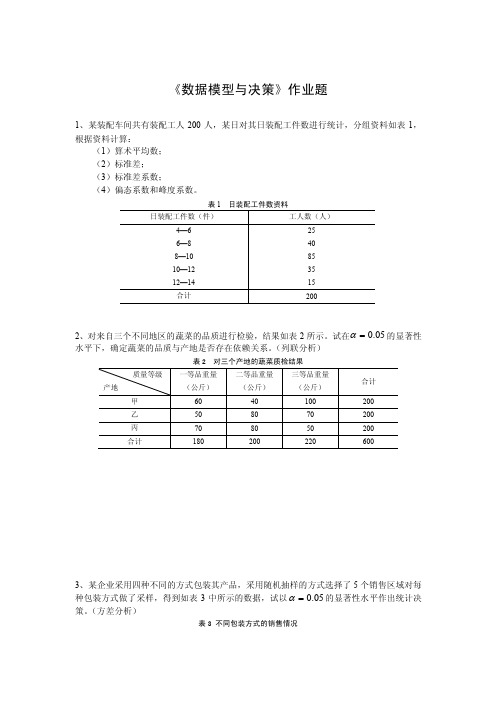
《数据模型与决策》作业题1、某装配车间共有装配工人200人,某日对其日装配工件数进行统计,分组资料如表1,根据资料计算:(1)算术平均数; (2)标准差;(3)标准差系数;(4)偏态系数和峰度系数。
表1 日装配工件数资料日装配工件数(件)工人数(人)4—6 6—8 8—10 10—12 12—14 25 40 85 35 15 合计2002、对来自三个不同地区的蔬菜的品质进行检验,结果如表2所示。
试在05.0=α的显著性水平下,确定蔬菜的品质与产地是否存在依赖关系。
(列联分析)表2 对三个产地的蔬菜质检结果质量等级 产地一等品重量 (公斤)二等品重量 (公斤)三等品重量 (公斤) 合计 甲 60 40 100 200 乙 50 80 70 200 丙 70 80 50 200 合计1802002206003、某企业采用四种不同的方式包装其产品,采用随机抽样的方式选择了5个销售区域对每种包装方式做了采样,得到如表3中所示的数据,试以05.0=α的显著性水平作出统计决策。
(方差分析)表3 不同包装方式的销售情况包装方式 销售区域方式一 方式二 方式三 方式四 1 66 32 46 25 2 45 16 32 15 3 78 66 12 30 4 25 23 45 16 5344650404、已知我国1990年~1999年的货运量y 、工业总产值x 1、农业总产值x 2资料如表4所示:表4 1990年~1999年我国货运量、工业总产值和农业总产值资料年份 货运量(万吨)工业总产值(亿元)农业总产值(亿元)1990 970602 23924 7662.1 1991 985793 26625 8157.0 1992 1045899 34599 9084.7 1993 1115771 48402 10995.5 1994 1180273 70176 15750.5 1995 1234810 91894 20340.9 1996 1296200 99595 22353.7 1997 1278087 113733 23788.4 1998 1267200 119048 24541.9 1999129265012611124519.1要求计算:(1)相关系数(2)二元线性回归方程(3)进行各种统计显著性检验。
数据模型与决策--作业大全详解
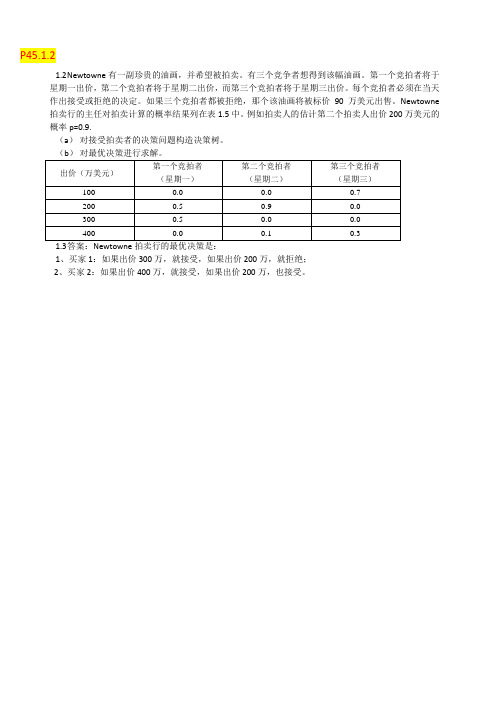
P45.1.21.2N ewtowne有一副珍贵的油画,并希望被拍卖。
有三个竞争者想得到该幅油画。
第一个竞拍者将于星期一出价,第二个竞拍者将于星期二出价,而第三个竞拍者将于星期三出价。
每个竞拍者必须在当天作出接受或拒绝的决定。
如果三个竞拍者都被拒绝,那个该油画将被标价90万美元出售。
Newtowne 拍卖行的主任对拍卖计算的概率结果列在表1.5中。
例如拍卖人的估计第二个拍卖人出价200万美元的概率p=0.9.(a)对接受拍卖者的决策问题构造决策树。
1、买家1:如果出价300万,就接受,如果出价200万,就拒绝;2、买家2:如果出价400万,就接受,如果出价200万,也接受。
接受买家1200 200200接受买家22002002000.50.9接受买家3买家1出价200万买家2出价200万0.7100 21买家3出价100万100100 0220020010100拒绝买家390拒绝买家290900190接受买家30.3400买家3出价400万400400拒绝买家1104000220拒绝买家3909090接受买家24004004000.1接受买家3买家2出价400万0.71001买家3出价100万100100040010100260拒绝买家390拒绝买家290900190接受买家30.3400买家3出价400万40040010400拒绝买家3909090接受买家1300 300300接受买家22002002000.50.9接受买家3买家1出价300万买家2出价200万0.7100 11买家3出价100万100100 0300020010100拒绝买家390拒绝买家290900190接受买家30.3400买家3出价400万400400拒绝买家1104000220拒绝买家3909090接受买家24004004000.1接受买家3买家2出价400万0.71001买家3出价100万100100040010100拒绝买家390拒绝买家290900190接受买家30.3400买家3出价400万40040010400拒绝买家39090902.9在美国有55万人感染HIV病毒。
数据模型与决策课程学习大作业.doc

数据模型与决策课程大作业以我国汽油消费量为因变量,乘用车销量、城镇化率和90#汽油吨价与城镇居民人均可支配收入的比值为自变量时行回归(数据为年度时间序列数据)。
试根据得到部分输出结果,回答下列问题:1)“模型汇总表”中的R方和标准估计的误差是多少?2)写出此回归分析所对应的方程;3)将三个自变量对汽油消费量的影响程度进行说明;4)对回归分析结果进行分析和评价,指出其中存在的问题。
1)“模型汇总表”中的R方和标准估计的误差是多少?答案:R方为0.993^2=0.986 ;标准估计的误差为120910.147^(0.5)=347.722)写出此回归分析所对应的方程;答案:假设汽油消费量为Y,乘用车销量为a,城镇化率为b,90#汽油吨价/城镇居民人均可支配收入为c,则回归方程为:Y=240.534+0.00s027a+8649.895b-198.692c3)将三个自变量对汽油消费量的影响程度进行说明;乘用车销量对汽油消费量相关系数只有0.00027,数值太小,几乎没有影响,但是城镇化率对汽油消费量相关系数是8649.895,具有明显正相关,当城镇化率每提高1,汽油消费量增加8649.895。
乘用90#汽油吨价/城镇居民人均可支配收入相关系数为-198.692,呈明显负相关,即乘用90#汽油吨价/城镇居民人均可支配收入每增加1个单位,汽油消费量降低198.692个单位。
a, b, c三个自变量的sig 值为0.000、0.000、0.009,在显著性水平0.01情形下,乘用车消费量对汽油消费量的影响显著为正。
(4)对回归分析结果进行分析和评价,指出其中存在的问题。
在学习完本课程之后,我们可以统计方法为特征的不确定性决策、以运筹方法为特征的策略的基本原理和一般方法为基础,结合抽样、参数估计、假设分析、回归分析等知识对我国汽油消费量影响因素进行了模拟回归,并运用软件计算出回归结果,故根据回归结果,对具体回归方程,回归准确性,自变量影响展开分析。
(完整版)30447数据模型与决策2014年07月【答案】

1-5、ACBAD 6-10、BBACD 11、数学模型 12、双相抽样 13、4.8814、一个测量原点,也叫绝对零点 15、熵16、置信度或置信水平 17、方差分析 18、自变量 19、循环变动 20、波动问题21、数据质量检查的抽样方法:在一次调查之后,紧接着再从这些被调查单位中抽取一定数量的单位组成样本,重新调查登记,最后将两者的结果进行对比,以检查先前调查数据的质量并进行适当的调整。
22、控制图:它是运用统计方法确定管理界限,并用于管理监控的一种图标。
23、中位数:把观察值按从小到大的顺序排列位置居中的数叫做中位数。
24、变异系数:是把算术平均数与标准差联系起来的一个测度,它的公式为100%Ss C x25、折中准则:小中求大准则过于悲观,大中求大准则过于乐观。
折中准则就是小中求大和大众求大准则之间进行平衡,以希望决策更符合现实。
通过对行样本频率能进行列类别间的比较,志愿活动是为了体现个人价值的男性比超过女性比。
2292644.8232868.220.4269133743289614.44468.22通过计算说明救济水平与解雇率之间有一定的相关性,但不是很高。
28、20001999199819972001169.2144.5126.1103.5135.82544x x x x x 2000199919981997200194.7116.0137.9178.3131.72544x x x x x 200019991998199********.6141.2159.2152.9142.97544x x x x x 20001999199819972001109.3131.9146.8166.0138.544x x x x x29、1(200.015)(200.015)2022u T Tˆ20x ,可以直接利用公式进行计算1(200.015)(200.015)16660.005u pST T T C30、解:设每种型号的拖拉机各购买1234,,,x x x x 台。
数据模型与决策 习题答案

数据模型与决策习题答案数据模型与决策习题答案在当今信息时代,数据的价值越来越受到重视。
数据模型作为一种描述和组织数据的方式,对于决策过程起着重要的作用。
本文将通过解答一些与数据模型和决策相关的习题,来探讨数据模型在决策中的应用和意义。
1. 什么是数据模型?为什么在决策过程中需要使用数据模型?数据模型是对现实世界进行抽象和描述的一种方式。
它通过定义实体、属性和关系的方式,将现实世界中的事物转化为计算机可以处理的形式。
数据模型可以帮助我们更好地理解和组织数据,为决策提供支持。
在决策过程中,数据模型的使用具有以下几个重要的作用:1) 数据模型可以帮助我们对现实世界进行建模和描述,将复杂的现实问题转化为可计算的形式,从而更好地理解问题的本质。
2) 数据模型可以帮助我们组织和管理大量的数据,使得数据更易于存储、检索和分析,为决策提供必要的信息支持。
3) 数据模型可以帮助我们对不同的决策方案进行评估和比较,通过模拟和预测的方式,帮助我们选择最佳的决策方案。
2. 数据模型的种类有哪些?请简要介绍其中的几种。
常见的数据模型包括层次模型、网状模型、关系模型和面向对象模型等。
层次模型是最早的数据模型之一,它将数据组织成一种树状结构,其中每个节点代表一个实体,每个节点之间通过父子关系连接。
层次模型的优点是结构简单,易于理解和实现,但缺点是不适合处理复杂的关系和多对多的关联。
网状模型是层次模型的扩展,它允许多个父节点指向同一个子节点,从而解决了层次模型不适合处理多对多关联的问题。
但网状模型的缺点是结构复杂,不易理解和维护。
关系模型是目前应用最广泛的数据模型,它将数据组织成一张二维表格,其中每一行代表一个实体,每一列代表一个属性。
关系模型通过定义实体间的关系和约束,实现了数据的灵活查询和操作。
面向对象模型是一种基于对象的数据模型,它将数据组织成一组对象,每个对象包含了数据和对数据的操作。
面向对象模型适用于处理复杂的关系和行为,但在实际应用中较为复杂和庞大。
数据模型与决策课

数据模型与决策课程大作业数据模型与决策课程大作业以我国汽油消费量为因变量,乘用车销量、城镇化率和90#汽油吨价与城镇居民人均可支配收入的比值为自变量时行回归(数据为年度时间序列数据)。
试根据得到部分输出结果,回答下列问题:1)“模型汇总表”中的R方和标准估计的误差是多少?2)写出此回归分析所对应的方程;3)将三个自变量对汽油消费量的影响程度进行说明;4)对回归分析结果进行分析和评价,指出其中存在的问题。
1)“模型汇总表”中的R方和标准估计的误差是多少?答案:R方为0.993^2=0.986 ;标准估计的误差为120910.147^(0.5)=347.722)写出此回归分析所对应的方程;答案:假设汽油消费量为Y,乘用车销量为a,城镇化率为b,90#汽油吨价/城镇居民人均可支配收入为c,则回归方程为:Y=240.534+0.00s027a+8649.895b-198.692c3)将三个自变量对汽油消费量的影响程度进行说明;乘用车销量对汽油消费量相关系数只有0.00027,数值太小,几乎没有影响,但是城镇化率对汽油消费量相关系数是8649.895,具有明显正相关,当城镇化率每提高1,汽油消费量增加8649.895。
乘用90#汽油吨价/城镇居民人均可支配收入相关系数为-198.692,呈明显负相关,即乘用90#汽油吨价/城镇居民人均可支配收入每增加1个单位,汽油消费量降低198.692个单位。
a, b, c三个自变量的sig 值为0.000、0.000、0.009,在显著性水平0.01情形下,乘用车消费量对汽油消费量的影响显著为正。
(4)对回归分析结果进行分析和评价,指出其中存在的问题。
在学习完本课程之后,我们可以统计方法为特征的不确定性决策、以运筹方法为特征的策略的基本原理和一般方法为基础,结合抽样、参数估计、假设分析、回归分析等知识对我国汽油消费量影响因素进行了模拟回归,并运用软件计算出回归结果,故根据回归结果,对具体回归方程,回归准确性,自变量影响展开分析。
MBA数据、模型课堂大作业资料

《数据、模型与决策》案例案例1 北方化工厂月生产计划安排(0.7+0.3)一. 问题提出根据经营现状和目标,合理制定生产计划并有效组织生产,是一个企业提高效益的核心。
特别是对于一个化工厂而言,由于其原料品种多,生产工艺复杂,原材料和产成品存储费用较高,并有一定的危险性,对其生产计划作出合理安排就显得尤为重要。
现要求我们对北方化工厂的生产计划做出合理安排。
二. 有关数据1.生产概况北方化工厂现在有职工120人,其中生产工人105名。
主要设备是2套提取生产线,每套生产线容量为800kg,至少需要10人看管。
该工厂每天24小时连续生产,节假日不停机。
原料投入到成品出线平均需要10小时,成品率约为60%,该厂只有4吨卡车1辆,可供原材料运输。
2.产品结构及有关资料该厂目前的产品可分为5类,多有原料15种,根据厂方提供的资料,经整理得表1。
3.供销情况①根据现有运出条件,原料3从外地购入,每月只能购入1车。
②根据前几个月的销售情况,产品1和产品3应占总产量的70%,产品2的产量最好不要超过总产量的5%,产品1的产量不要低于产品3与产品4的产量之和。
问题:a.请作该厂的月生产计划,使得该厂的总利润最高。
b.找出阻碍该厂提高生产能力的瓶颈问题,提出解决办法。
案例2 石华建设监理公司监理工程师配置问题(0.8+0.2)石华建设监理公司(国家甲级),侧重国家大中型项目的监理,仅在河北省石家庄市就正在监理七项工程,总投资均在5000万元以上。
由于工程开工的时间不同,多工程工期之间相互搭接,具有较长的连续性,2012年监理的工程量与2011年监理的工程量大致相同。
每项工程安排多少监理工程师进驻工地,一般是根据工程的投资,建筑规模,使用功能,施工的形象进度,施工阶段来决定的。
监理工程师的配置数量是随之而变化的。
由于监理工程师从事的专业不同,他们每人承担的工作量也是不等的。
有的专业一个工地就需要三人以上,而有的专业一人则可以兼管三个以上的工地。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【最新整理,下载后即可编辑】
数据模型与决策课程大作业
以我国汽油消费量为因变量,乘用车销量、城镇化率和90#汽油吨价与城镇居民人均可支配收入的比值为自变量时行回归(数据为年度时间序列数据)。
试根据得到部分输出结果,回答下列问题:
1)“模型汇总表”中的R方和标准估计的误差是多少?
2)写出此回归分析所对应的方程;
3)将三个自变量对汽油消费量的影响程度进行说明;
4)对回归分析结果进行分析和评价,指出其中存在的问题。
1)“模型汇总表”中的R方和标准估计的误差是多少?
答案:R方为0.993^2=0.986 ;标准估计的误差为120910.147^(0.5)=347.72
2)写出此回归分析所对应的方程;
答案:假设汽油消费量为Y,乘用车销量为a,城镇化率为b,90#汽油吨价/城镇居民人均可支配收入为c,则回归方程为:
Y=240.534+0.00s027a+8649.895b-198.692c
3)将三个自变量对汽油消费量的影响程度进行说明;
乘用车销量对汽油消费量相关系数只有0.00027,数值太小,几乎没有影响,但是城镇化率对汽油消费量相关系数是8649.895,具有明显正相关,当城镇化率每提高1,汽油消费量增加8649.895。
乘用90#汽油吨价/城镇居民人均可支配收入相关系数为-198.692,呈明显负相关,即乘用90#汽油吨价/城镇居民人均可支配收入每增加1个单位,汽油消费量降低198.692个单位。
a, b, c三个自变量的sig值为0.000、0.000、0.009,在显著性水平0.01情形下,乘用车消费量对汽油消费量的影响显著为正。
(4)对回归分析结果进行分析和评价,指出其中存在的问题。
在学习完本课程之后,我们可以统计方法为特征的不确定性决策、以运筹方法为特征的策略的基本原理和一般方法为基础,结合抽样、参数估计、假设分析、回归分析等知识对我国汽油消
费量影响因素进行了模拟回归,并运用软件计算出回归结果,故根据回归结果,对具体回归方程,回归准确性,自变量影响展开分析。
Anova表中,sig值是t统计量对应的概率值,所以t和sig 两者是等效的,sig要小于给定的显著性水平,越接近于0越好。
F是检验方程显著性的统计量,是平均的回归平方和平均剩余平方和之比,越大越好。
在图表中,回归模型统计值F=804.627,p 值为0.000,因此证明回归模型有统计学意义,表现回归极显著。
即因变量与三个自变量之间存在线性关系。
系数表中,除了常数项系数显著性水平大于0.05,不影响,其它项系数都是0.000,小于0.005,即每个回归系数均具有意义。
当然,这其中也存在一定的问题:
在模型设计中,乘用车销量为、城镇化率为、90#汽油吨价/城镇居民人均可支配收入为三个自变量的单位均不同,因此会造成自变量前面的回归系数不具有准确的宏观意义,因此需要对模型进行实现标准化,也就是引入β系数,消除偏回归系数带来的数量单位影响。
根据共线性统计量中的变量的容差t和方差膨胀因子(VIF),自变量间存在共性问题,容差和膨胀因子为倒数关系,容差越小,膨胀因子越大,尤其是城镇化率VIF为11.213,说明共线性明显,可能原因是由于样本容量太小,也可能是城镇化之后乘用车销售量和、90#汽油吨价/城镇居民人均可支配收入本身就具有相关
性。
缺乏模型异方差检验。
在多元回归模型中,由于数据质量原因、模型设定原因,异方差的存在会使回归系数估计结果误差较多,所以在建立模型分析的过程红要对异方差进行检验。
数据模型与决策使我们学会使用科学的分析和决策,对经营管理活动实现合理化、精细化、科学化,从而避免了盲目的生产活动。
通过数据预测、假设检验、公式、分析、验证等一系列的步骤,将数据结果逐一展现。
为我们的学习和工作提供了一些非常有用、便捷的,处理问题的方法。
附表:t分布表:
df 单尾检验的显著水平
0.050 0.025 0.010 0.005 双尾检验的显著水平
0.10 0.05 0.02 0.01
3 2.353 3.182 4.541 5.841
4 2.132 2.776 3.747 4.604
5 2.015 2.571 3.365 4.032
6 1.943 2.44
7 3.143 3.707
7 1.895 2.365 2.998 3.499
8 1.860 2.306 2.896 3.355
9 1.833 2.262 2.821 3.250
10 1.812 2.228 2.764 3.169
11 1.796 2.201 2.718 3.106
12 1.782 2.179 2.681 3.055
13 1.771 2.160 2.650 3.012。