计量经济学上机教程(修正版)
《计量经济学》上机实验答案过程步骤
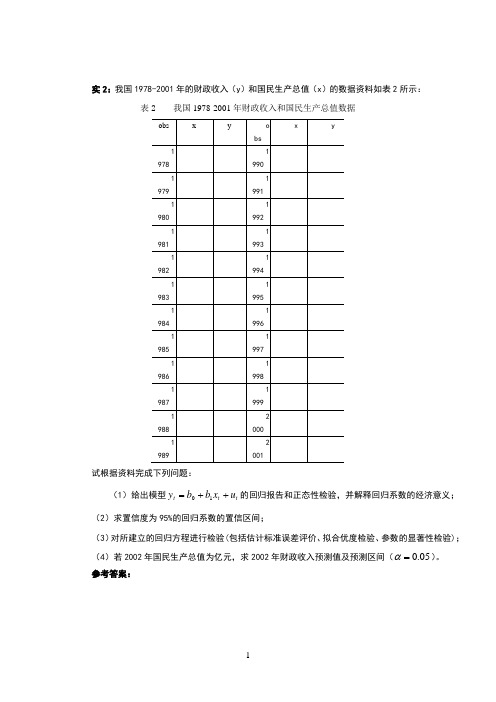
实2:我国1978-2001年的财政收入(y )和国民生产总值(x )的数据资料如表2所示:表2 我国1978-2001年财政收入和国民生产总值数据试根据资料完成下列问题:(1)给出模型t t t u x b b y ++=10的回归报告和正态性检验,并解释回归系数的经济意义; (2)求置信度为95%的回归系数的置信区间;(3)对所建立的回归方程进行检验(包括估计标准误差评价、拟合优度检验、参数的显著性检验); (4)若2002年国民生产总值为亿元,求2002年财政收入预测值及预测区间(05.0=α)。
参考答案:(1) t t x y133561.06844.324ˆ+= =)ˆ(i b s =)ˆ(ib t 941946.02=R 056.1065ˆ==σSE 30991.0=DW 9607.356=F 133561.0ˆ1=b ,说明GNP 每增加1亿元,财政收入将平均增加万元。
(2))ˆ()2(ˆ02/00b s n t b b ⋅-±=α=±⨯ )ˆ()2(ˆ12/11b s n t b b ⋅-±=α=±⨯ (3)①经济意义检验:从经济意义上看,0133561.0ˆ1〉=b ,符合经济理论中财政收入随着GNP 增加而增加,表明GNP 每增加1亿元,财政收入将平均增加万元。
②估计标准误差评价: 056.1065ˆ==σSE ,即估计标准误差为亿元,它代表我国财政收入估计值与实际值之间的平均误差为亿元。
③拟合优度检验:941946.02=R ,这说明样本回归直线的解释能力为%,它代表我国财政收入变动中,由解释变量GNP 解释的部分占%,说明模型的拟合优度较高。
④参数显著性检验:=)ˆ(1b t 〉0739.2)22(025.0=t ,说明国民生产总值对财政收入的影响是显著的。
(4)6.1035532002=x , 41.141556.103553133561.06844.324ˆ2002=⨯+=y根据此表可计算如下结果:102221027.223)47.32735()1()(⨯=⨯=-⋅=-∑n x x x tσ92220021002.5)47.327356.103553()(⨯=-=-x x ,109222/1027.21002.52411506.10650739.241.14155)()(11ˆ)2(ˆ⨯⨯++⨯⨯±=--++⋅⋅-±∑x x x x n n t yt f f σα=实验内容与数据3:表3给出某地区职工平均消费水平t y ,职工平均收入t x 1和生活费用价格指数t x 2,试根据模型t t t t u x b x b b y +++=22110作回归分析报告。
计量经济学上机实验

计量经济学上机实验上机实验一:一元线性回归模型实验目的:EViews软件的基本操作实验内容:对线性回归模型进行参数估计并进行检验上机步骤:中国内地2011年中国各地区城镇居民每百户计算机拥有量和人均总收入一.建立工作文件:1.在主菜单上点击File\New\Workfile;2.选择时间频率,A3.键入起始期和终止期,然后点击OK;二.输入数据:1.键入命令:DATA Y X2.输入每个变量的统计数据;3.关闭数组窗口(回答Yes);三.图形分析:1.趋势图:键入命令PLOT Y X2.相关图:键入命令 SCAT Y X 散点图:趋势图:上机结果:Yˆ11.958+0.003X=s (βˆ) 5.6228 0.0002t (βˆ) 2.1267 11.9826prob 0.0421 0.00002=0.831 R2=0.826 FR=143.584 prob(F)=0.0000上机实验二:多元线性回归模型实验目的:多元回归模型的建立、比较与筛选,掌握基本的操作要求并能根据理论对分析结果进行解释实验内容:对线性回归模型进行参数估计并进行检验上机步骤:商品的需求量与商品价格和消费者平均收入趋势图:散点图:上机结果:i Yˆ=132.5802-8.878007X1-0.038888X2s (βˆ) 57.118 4.291 0.419t (βˆ) 2.321 -2.069 -0.093prob 0.0533 0.0773 0.9286 R2=0.79 R2=0.73 F =13.14 prob(F)=0.00427三:非线性回归模型实验目的:EViews软件的基本操作实验内容:对线性回归模型进行参上机步骤:我国国有独立核算工业企业统计资料一.建立工作文件:1.在主菜单上点击File\New\Workfile;2.选择时间频率,A3.键入起始期和终止期,然后点击OK;二.输入数据:1.键入命令:DATA Y L K2.输入每个变量的统计数据;3.关闭数组窗口(回答Yes);三.图形分析:1.趋势图:键入命令PLOT Y K L2.相关图:键入命令 SCAT Y K L四.估计回归模型:键入命令LS Y C K L上机结果:Y =4047.866K1.262204L-1.227157s (βˆ) 17694.18 0232593 0.759696t (βˆ) 0.228768 5.426669 -1.615325prob 0.8242 0.0004 0.1407R2=0.989758 R2=0.987482 F=434.8689 prob(F)=0.0000上机实验四:异方差实验目的::掌握异方差的检验与调整方法的上机实现实验内容:我国制造工业利润函数行业销售销售行业销售销售实验步骤:一.检验异方差性1.图形分析检验:1) 观察Y、X相关图:SCAT Y X2) 残差分析:观察回归方程的残差图LS Y C X在方程窗口上点击Residual按钮;2. Goldfeld-Quant检验:SORT XSMPL 1 10LS Y C X(计算第一组残差平方和)SMPL 19 28LS Y C X(计算第二组残差平方和)计算F统计量,判断异方差性3.White检验:SMPL 1 28LS Y C X在方程窗口上点击:View\Residual\Test\White Heteroskedastcity 由概率值判断异方差性。
计量经济学上机操作过程详解

上机操作步骤详解及分析假设检验部分类型一:会利用软件处理σ2已知关于μ的假设检验以及σ2未知关于μ的假设检验【例一】某车间用一台包装机包装葡萄糖。
袋装糖的净重量是一个随机变量,它服从正态分布。
当机器正常运行时,其均值为0.5KG ,标准差为0.015KG 。
某日开工后为检验及其运转是否正常,随机的抽取了它所包装的糖9袋,称得净重为(KG ):0.497 0.506 0.518 0.524 0.498 0.511 0.520 0.515 0.512问:机器运转是否正常?(假设样本方差不变) 仍然为上题,但如果方差未知的情况下呢?因为是研究型假设故0H :u=0.5 1H :u<>0.5第一步:将数据移入第二步:关闭后再次把数据打开,按如下路径打开下一个对话框第三步:根据已知的均值和标准差输入下列对话框(注意:是标准差,如果题目告诉的是方差,则还要进一步转化成为标准差)第四步:点击OK后,得到如下结果,并分析该题的方差已知,故看Z-statistic的P值,因为0.0248<a/2=0.025,故拒绝原假设,结论为:在5%的显著性水平下,该机器运转不正常若该题的方差未知,则看t-statistic的P值,结论依然是:在5%的显著性水平下,该机器运转不正常类型二:会利用软件处理来自两个正态总体均值的假设检验:等方差和异方差【例2】用两种方法(A、B)测定冰从-0.72摄氏度变为0摄氏度的比热。
测得下列数据:两个样本独立且来自与方差相等的两个正态总体方法A 79.98 80.04 80.02 80.04 80.03 80.0380.04 79.97 80.05 80.03 80.02 80.00 80.02方法B 80.02 79.94 79.98 79.97 79.97 80.03 79.9579.971、两种方法是否具有显著性差异2、A方法是否比B方法测得的比热要大?解析:该题属于双样本的等方差检验,故在EXCEL背景下操作第一小问:第一步:移入数据,将原本的两行数据,分别调整为一行第二步:EXCEL的调试,“工具”——“加载宏”后选择如下选项:第三步:点击“工具”——“数据分析”——“t检验-双样本等方差检验”第四步:输入相应的数据第五步:分析相应结果解析:第一小问只需判断是否有显著性差异,也就是说只需要判断A U 与B U 是否相等,属于双侧检验,在统一用P(T<=t) 单尾分析的时候,与的是a/2比较0H :AU-B U =0 1H :A U -B U <>0如上图结果所示,P(T<=t) 单尾=0.001276<a/2=0.025,所以拒绝原假设,也就是说在5%的显著性水平下,方法A 和方法B 具有显著性差异第二小问:解析:第二小问不同于第一小问,判断的是A 与B 的大小,是研究型假设检验, 将认为研究结果是无效的说法或理论作为原假设H00H :AU<=B U 1H :A U >B U因为是单侧检验,故与a 相比,因为P(T<=t) 单尾=0.001276<a=0.05,所以拒绝原假设,结论是在5%的显著性水平下,A 方法测得的比热比B 方法的大【例3】下表给出两位文学家马克吐温的8篇小品文以及斯诺特格拉斯的10篇小品文中由3个字母组成的单字的比例 马克吐温0.225 0.262 0.217 0.240 0.2300.229 0.235 0.217 斯诺特格拉斯0.209 0.205 0.196 0.210 0.202 0.207 0.224 0.223 0.2200.201两组数据均来自正态总体,且方差相等。
计量经济学上机实验手册

计量经济学上机实验手册标准化工作室编码[XX968T-XX89628-XJ668-XT689N]实验三异方差性实验目的:在理解异方差性概念和异方差对OLS回归结果影响的基础上,掌握进行异方差检验和处理的方法。
熟练掌握和运用Eviews软件的图示检验、G-Q检验、怀特(White)检验等异方差检验方法和处理异方差的方法——加权最小二乘法。
实验内容:书P116例4.1.4:中国农村居民人均消费函数中国农村居民民人均消费支出主要由人均纯收入来决定。
农村人均纯收入除从事农业经营的收入外,还包括从事其他产业的经营性收入以及工资性收入、财产收入和转移支付收入等。
为了考察从事农业经营的收入和其他收入对中国农村居民消费支出增长的影响,建立双对数模型:其中,Y表示农村家庭人均消费支出,X1表示从事农业经营的纯收入,X2表示其他来源的纯收入。
表4.1.1列出了中国内地2006年各地区农村居民家庭人均纯收入及消费支出的相关数据。
注:从事农业经营的纯收入由从事第一产业的经营总收入与从事第一产业的经营支出之差计算,其他来源的纯收入由总纯收入减去从事农业经营的纯收入后得到。
资料来源:《中国农村住户调查年鉴(2007)》、《中国统计年鉴(2007)》。
实验步骤:一、创建文件1.建立工作文件CREATE U 1 31 【其中的“U”表示非时序数据】2.录入与编辑数据Data Y X1 X2 【意思是:同时录入Y、X1和X2的数据】3.保存文件单击主菜单栏中File→Save或Save as→输入文件名、路径→保存。
二、数据分析1.散点图①Scat X1 Y从散点图可看出,农民农业经营的纯收入与农民人均消费支出呈现一定程度的正相关。
②Scat X2 Y从散点图可看出,农民其他来源纯收入与农民人均消费支出呈现较高程度的正相关。
2.数据取对数处理Genr LY=LOG(Y)Genr LX1=LOG(X1)Genr LX2=LOG(X2)三、模型OLS参数估计与统计检验LS LY C LX1 LX2得到模型OLS参数估计和统计检验结果:Dependent Variable: LYMethod: Least SquaresSample: 1 31LX1Adjusted R-squared . dependent var. of regression Akaike infocriterionSum squared resid Schwarz criterionLog likelihood F-statistic【注意:在学术文献中一般以这种形式给出回归方程的输出结果,而不是把上面的软件输出结果直接粘贴到文章中】可决系数,调整可决系数,显示模型拟合程度较高;同时,F 检验统计量,在5%的显着性水平下通过方程总体显着性检验。
计量经济学上机实验指导书

得到估计结果之后,就可以根据输出统计 量中表现出的特性,对模型进行检验和合 适的修正。 得到满意结果后,可以使用模型进行预测。
第二节:一元线性回归模型的预 测
要对一元线性模型进行预测,需要在已知解释 变量值的条件下进行。要得到解释变量值的方 法有很多,练习时大多是已知的。在实际分析 问题时,方法之一是对时间T进行回归,再趋势 外推得到解释变量的值,即利用时间序列外推 预测。下面仍以前面的例子输入时间变量T,从 1981到2001年分别赋值1到21,建立时间序 列模型(略去随机项) GDP=a+Bt
* * 0
* t
ut
第五讲 多重共线性
1.多重共线性的检测--简单相关系数法 命令:cor x1 x2 x3 x4 解释变量两两之间都
有非常高的线性相关, 可以判断模型中存在 多重共线性
2.多重共线性的修正--逐步回归法 用Y分别对X1,X2,X3,X4作回归,得 Y对X1作回归:
Y对X2作回归:
点击ok, 完成最后 一步
最后结果和命令方式完全相同
第四讲 自相关
自相关的检验与修正一般包括如下步骤: 1.对原模型做回归得到残差。 2.描绘残差项与其滞后项的散点图,看是否 存在自相关。 3.利用回归结果中得Durbin-Watson统计量 判断模型是否存在自相关。 4.利用Durbin两步法对自相关做修正。 (数据来自课本87表5-1)
Weekly数据格式的解释
起始和终止日期都是一个日期。 它们必须是不同星期中的同一天,否则会 报错。 一个星期中的任何一天都可以作为一周的 起始日期。
第二讲 一元线性回归模 型
第一节:一元线性回归模型的估计
示例一: 一元线性模型的OLS估计
计量经济学上机报告(1)

一.多元线性回归模型年份GDP(亿元)工业废气排放量(亿标立方米)总户口数(万户)1982 337.07 2439.55 1180.51 1983 351.81 2671.32 1194.01 1984 390.85 2833.93 1204.78 1985 466.75 3010.3 1216.69 1986 490.83 3076.18 1232.33 1987 545.46 3488.83 1249.51 1988 648.3 3552.15 1262.42 1989 696.54 3616.13 1276.54 1990 781.66 3534.92 1283.35 1991 893.77 3999.94 1287.2 1992 1114.32 4418.08 1289.37 1993 1519.23 3859.24 1294.74 1994 1990.86 4183.77 1298.81 1995 2499.43 4624.55 1301.37 1996 2957.55 4756.89 1304.43 1997 3438.79 4754.47 1305.46 1998 3801.09 4912.36 1306.58 1999 4188.73 4946.65 1313.12 2000 4771.17 5755.23 1321.631.数据的输入2数据描述(1).数据的查看方式(2).数据的统计性质3.多个序列的走势图4.生成新的序列4.多元回归分析由图知,回归方程为LNGDP=4.28LNGY-4.21LNHK=1.83,并且通过了F检验和t检验,并且可决系数为0.905301,调整后的可决系数为0.893464,表明建立的回归方程的统计性质是是比较好的。
可以看出实际值和拟合值是非常的接近的。
可以看出残差在0的上下摆动,可以对其进行正态性检验。
通过正态性检验。
二.异方差的检验与处理(1)采用OLS估计通过了T检验和F检验(2)观察e2—X图。
计量经济学上机操作
计量经济学上机操作大小写没有区别一、图形趋势图PLOT相关图(散点图) SCA T二、OLS回归模型一元:LS Y C X (Y指被解释变量,X指解释变量,下同)多元:LS Y C X1 X2 X3三、非线性回归模型1、可线性化(重点掌握)如:LNY=a + bLNX则LS LOG(Y) C LOG(X)以及多项式模型、指数模型、幂函数等。
2、不可线性化如:Y=a(X-b)/(X-c)则(1) 设定待估参数的初始值。
方式1:使用PARAM命令,格式为:PARAM 1 初始值1 2 初始值2 ……方式2:在工作文件窗口中双击序列C,并在序列窗口中直接输入参数的初始值(2)估计非线性模型NLS Y= C(1)*(X-C(2))/(X-C(3))四、多重共线性1、简单相关系数检验COR X1 X2 X3 X42、某一解释变量(如X1)的VIFLS X1 C X2 X3 X4VIF=1/(1-R2)3、某一解释变量(如X1)的TOLTOL=1/VIF=1-R24、采用逐步回归法建立最终方程五、异方差见习题1、Goldfeld-Quandt 检验Sort xSmpl 1 24Ls y c xRss1=Smpl 37 60Ls y c xRss2=F=rss2/rss1= >F0.05(22,22) ≈2.05模型存在异方差。
2、White检验Smpl 1 60Ls y c x在方程窗口点View/residual/white………χ(2)=5.99,nR2= ,> 2.005或P=0.0044结论:3、Glejser检验(假定h=1时)Ls y c xGenr e1=abs(resid)Ls e1 c xF= ,或P=结论:4、Park检验Ls y c xGenr lne2=log(resid^2)Genr lnx=log(x)Ls lne2 c lnxF= , 或P=结论:5、wls估计ls y c xgenr w1=1/resid^2(建议采用此权重变量,也可以使用其他权重变量)ls(w=w1) y c xYˆ=再次用WHITE 检验法检验此模型是否存在异方差。
《计量经济学》上机实验报告样板
《计量经济学》上机实验报告样板《计量经济学》上机实验报告样板实验名称:单变量线性回归模型实验时间:xxxx年xx月xx日实验目的:通过对单变量线性回归模型的实验学习,掌握计量经济学中的基本数据处理方法,理解回归模型的建立和应用。
实验内容:使用给定的数据集,运用最小二乘法估计单变量线性回归模型的参数,并进行模型评估、推断统计和预测。
具体步骤如下:1. 数据准备:导入实验所需数据集,并进行数据的初步查看和处理,包括缺失值处理、异常值检测等。
2. 模型建立:选择合适的变量,建立单变量线性回归模型,确定模型的形式。
3. 参数估计:使用最小二乘法估计模型的参数,计算斜率和截距,并进行显著性检验。
4. 模型评估:通过残差分析、拟合优度等指标,评估模型的拟合效果和可解释性。
5. 推断统计:对模型参数进行推断统计,包括置信区间估计、假设检验等,判断回归系数是否显著。
6. 预测应用:应用模型进行预测,给出对新数据的预测结果,并分析预测的可信度。
实验结果及分析:1. 数据准备:对实验所用数据进行初步查看后发现,数据集中存在缺失值和异常值,需要进行处理。
经过处理后,得到完整的数据集。
2. 模型建立:根据实验要求,选择自变量X和因变量Y,建立线性回归模型。
假设模型为Y = β0 + β1X,其中Y为因变量,X为自变量。
3. 参数估计:使用最小二乘法对模型进行参数估计,计算出斜率β1和截距β0。
斜率β1表示X对Y的影响程度,截距β0表示当X为0时,Y的取值。
4. 模型评估:通过残差分析和拟合优度等指标,评估模型的拟合效果。
残差分析结果显示,残差的分布符合正态分布,拟合优度指标R^2较高,表明模型的拟合效果较好。
5. 推断统计:对模型参数进行推断统计,计算出斜率和截距的置信区间估计,并进行假设检验。
结果显示,斜率和截距的置信区间不含0,说明回归系数是显著的。
6. 预测应用:应用建立好的模型对新的数据进行预测。
根据模型得到的预测结果,并分析了预测结果的可信度。
《计量经济学》上机实践
第三节 建立与应用计量经济 模型的主要步骤
一、根据经济理论建立计量经济模 型
二、样本数据的收集 三、估计参数 四、模型的检验 五、计量经济模型的应用
一、根据经济理论建立 计量经济模型
设定一个合理的计量经济模型,应当注 意以下几个方面:
(一)要有科学的理论依据 (二)模型要选择适当的数学形式 (三)方程中的变量要具有可观测性
数学知识(函数性质等)对计量建模的 作用。
计量经济学不是数学,是经济学。
计量经济学的内容体系
(一)从内容角度,可以将计量经济 学划分为理论计量经济学和应用计 量经济学。
(二)从学科角度,可以将计量经济 学划分为广义计量经济学与狭义计 量经济学。
计量经济学在经济学科中的地位
省略
第二节 计量经济学的基本概念
《计量经济学》上机实践
1、介绍EViews软件的基本情况和操作使用说明 2、使用EViews的基本概念,并学会数据的输入等 3、利用EViews对一元回归模型进行计算操作 4、利用EViews对多元回归模型案例进行计算操 5、利用EViews检验模型的异方差性 6、利用EViews检验模型的自相关性 7、利用EViews检验模型的多重共线性 8、利用EViews对联立方程模型进行计算 9、上机考试
本章总结
重要的知识点:
1.1933年《计量经济学》会刊的出版,标志着 计量经济学作为一个独立的学科正式诞生。
2.什么计量经济学? 3.计量经济学的学科性质与其他学科的关系 4.计量经济学的学科体系 5.计量经济学的基本概念:变量、数据、参数
及其估计准则、计量经济模型 6.建立与应用计量经济学模型的主要步骤
通过P180案例分析,掌握以下内容: 1.异方差的图示检验法 2.G-Q检验法 3.怀特检验法 4.戈里瑟检验和帕克检验法 5.WLS估计法 6.对数变换法
修正版-计量经济学上机实验
实验一EViews软件的基本操作【实验目的】了解EViews软件的基本操作对象,掌握软件的基本操作。
【实验内容】一、运行Eviews;二、数据的输入、编辑与序列生成;三、图形分析与描述统计分析;四、数据文件的存贮、调用与转换。
实验内容中后三步以表1-1所列出的税收收入和国内生产总值的统计资料为例进行操作。
资料来源:《中国统计年鉴1999》【实验步骤】一、单击任务栏上的“开始”→“程序”→“Eviews”程序组→“Eviews”图标二、数据的输入、编辑与序列生成1创建工作文件启动Eviews软件之后,在主菜单上依次点击File\New\Workfile2输入Y、X的数据可在命令窗口键入如下命令:DATA Y X3生成log(Y)、log(X)、X^2、1/X时间变量T等序列在命令窗口中依次键入以下命令即可:GENR LOGY=LOG(Y)GENR LOGX=LOG(X)GENR X1=X^2GENR X2=1/XGENR T=@TREND(1984)4选择若干变量构成数组,在数组中增加、更名和删除变量5在工作文件窗口中删除、更名变量三、图形分析与描述统计分析1利用PLOT命令绘制趋势图2利用SCAT命令绘制X、Y的相关图3观察图形参数的设置情况双击图形区域中任意处或在图形窗口中点击Procs/Options4在序列和数组窗口观察变量的描述统计量单独序列窗口,从序列窗口菜单选择View/Descriptive Statistics/Histogram and Stats,则会显示变量的描述统计量;数组窗口,从数组窗口菜单选择View/Descriptive Stats/Individual Samples,就对每个序列计算描述统计量四、数据文件的存贮、调用与转换1存贮并调用工作文件2存贮若干个变量,并在另一个工作文件中调用存贮的变量3将工作文件分别存贮成文本文件和Excel文件4在工作文件中分别调用文本文件和Excel文件实验二一元回归模型【实验目的】掌握一元线性、非线性回归模型的建模方法【实验内容】建立我国税收预测模型【实验步骤】表1列出了我国1985-1998年间税收收入Y和国内生产总值(GDP)x的时间序列数据,请利用统计软件Eviews建立一元线性回归模型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
操作步骤如下:
6
计量经济学上机教程
Made By 08 经济 林盛楷
打开 hprice1.wf1 文件,点击 resid 文件,操作 view→graph→line,我们可以看到:
我们可以观察到,残差随着收入的变化,波动较大,故初步推断,模型存在异方差; 我们在空白框内输入:ls price c lotsize sqrft bdrms,得到方程,命名为 eq01,如下 图所示:
这里采用了工具变量估计的方法: 转化成式子,就是:
最后出现了一个 β 文件,点击之后,会发现:
我们惊奇地发现,R1-R4 的系数的值竟然与方程 eq01 的自变量的系数一样! ! 以上就是 eviews 的矩阵运算。
约束检验
书上第 144-145 页: 操作步骤如下: 打开文件 mlb1.wf1,我们估计无约束模型: 点击 Quick——Estimate Equation →输入 log(salary) c years gamesyr bavg hrunsyr
rbisyr,得到方程 eq01,如下图:
3
计量经济学上机教程
Made By 08 经济 林盛楷
然后进行系数约束检验,即 wald 检验:假定 bavg,hrunsyr 和 rbisyr 的系数为 0,即
c(4)=c(5)=c(6)=0
操作步骤如下: 点击 view→coefficient tests→Wald-coefficient restrictions,如下图:
1
计量经济学上机教程
Made By 08 经济 林盛楷
由于杨海生老师前几次的上机主要是让我们熟悉 Eviews 软件的操作,主要 重点放在了约束检验与矩阵运算,所以杨海生老师的上机就只有这两章节了。 如果有同学需要另外的章节的话,欢迎联系我 (15013222060)~
矩阵运算
Example 5.3:
Goldfeld-Quandt 检验:
双击 Price 文件,然后点击 Sort→price 和 Ascending,对其进行升序排列;如下图所示:
11
计量经济学上机教程
然后在 Sample 下面填上 1 33,如下图所示:
Made By 08 经济 林盛楷
然后对模型进行OLS估计:Quick→Estimate Equation, 输入:price c sqrft lotsize bdrms
7
计量经济学上机教程
操作如下图:
Made By 08 经济 林盛楷
然后, 点击 view →residual test →white heteroskedasticity(no cross terms)或者 cross terms:
White Test 原理:利用原 OLS 回归中得到的残差平方对所有的自变量、自变量的平方及自 变量的交叉项(因为异方差不一定只是与一次项相关)进行回归,然后对此回归方程进行 系数联合检验,如果所有系数为零的原假设不成立,即表明方程存在异方差。 No cross (即不包含自变量的交叉项) , 我们得到的解释变量为 C LOTSIZE LOTSIZE^2 SQRFT SQRFT^2 BDRMS BDRMS^2 而 cross(即包含自变量的交叉项),我们得到的解释变量为 C LOTSIZE LOTSIZE^2 LOTSIZE*SQRFT LOTSIZE*BDRMS SQRFT SQRFT^2 SQRFT*BDRMS BDRMS BDRMS^2 我们选择 white heteroskedasticity(no cross terms) 生成报告,如下图所示:
点击前面估计得到的方程 eq01,然后点击 Proc→make residual series 取出方程的残差,命 名为 res; 接着,在空白框中输入:scalar sigma=eq01.@ssr/88 然后继续在空白框中输入:scalar g=res^2/sigma-1 然后我们将 g 对 Z 回归,(PS:其中 Z 是你认为的跟异方差的有关的解释变量的集合(包括常 数项)),求得回归平方和,计算 LM 统计量: 具体操作如下: 在空白框中输入: ls g c lotsize sqrft bdrms 得到估计方程, 命名为 eq02;
8
计量经济学上机教程
Made By 08 经济 林盛楷
这里,我们观察到 F 统计值和 LM 统计值的 Prob 的值很小,故拒绝原假设,即判断模型中 存在异方差。 检验对变量采用对数形式是否能有效降低异方差? 我们将 price、 lotsize、 sqrft 都取了对数形式, 输入 ls log(price) log(lotsize) log(sqrft) bdrms,做 OLS 估计,命名为 eq02,然后与上述一样的做怀特检验,选择 white heteroskedasticity(no cross terms),我们得到下图:
计量经济学上机教程
Made By 08 经济 林盛楷
Eviews 上机教程
我收集了杨海生和徐淑一两位老师在这学期的上机课的 Eviews 的操作,通过整理,编写成了这份教程。虽然不是什么宏篇巨作,但 希望可以在 2011 年到来之际,献给大家一份新年礼物! 由于编写教程的想法事出突然, 这几天我熬夜赶工, 再加上本人 学术水平还有待提升, 教程本身可能会存在一些纰漏, 希望大家在阅 读的同时能指出错误,本人不胜感激! ——08 经济 林盛楷
9
计量经济学上机教程
Made By 08 经济 林盛楷
此时,对比之前的 F 统计值和 LM 统计值的 Prob,我们发现新的模型的 F 统计值和 LM 统计 值的 Prob 显著增大了。因此,我们不能拒绝不存在异方差的原假设,从而验证了对变量取 对数形式可以显著地降低方程中的异方差的说法!!!
Breusch-Pagan Test:
操作如下: 打开 crime.wf1 文件,做 OLS 估计 点击 Quick——Estimate Equation →输入 narr86 c pcnv ptime86 qemp86,得到估计 方程,命名为 eq01,如下图:
我们可以看到自变量的系数(红框里面所示) 接下来,我们采用矩阵的形式来得到同样的估计结果: 在空白框中输入 series i=1 得到一个全为 1 的列向量; 接下来,继续在空白框中输入 group group01 i pcnv ptime86 qemp86 上述操作是把 i,pcnv,ptime86 和 qemp86 合并成一个向量组; 接着,继续在空白框中输入连续 3 行:
13
计量经济学上机教程
Made By 08 经济 林盛楷
我们可以得到以下结果:(PS:如果输出结果中出现 White Heteroskedasticity-Consistent Standard Errors & Covariance ,表示以完成怀特一致协方差估计)
怀特一致协方差估计:
我们在对可能存在异方差的数据模型进行估计时,可以点击 options,然后选择 heteroskedasticity consistent coefficient 中的 white 一致协方差估计,即是采用怀特方法对 数据模型中的异方差性进行修正(PS:Newey West 一致协方差估计则是同时可以对模型中 可能存在的异方差与序列相关进行修正),如图所示:
然后构建 LM 统计量:输入:scalar lm=eq02.@ssr*(eq02.@r2/(1-eq02.@r2))/2 得到 LM 统计量,然后我们继续输入:scalar chi=@qchisq(0.975,3)
10
计量经济学上机教程
9.3484036045。
Made By 08 经济 林盛楷
结果得到 LM 统计量为 30.0227300855,而自由度为 3,置信水平为 5%的卡方统计量为
异方差检验(一)
Example8.4:研究 HPRICE1 的数据。 1.估计 Example8.4 的方程;观察残差随收入变化的分布特征,你能得出什么结 论? 2.用 White 方法检验 1.的模型是否存在异方差; 3.用 Breusch-Pagan 方法检验 1.的模型是否存在异方差; 4.以 lotsize 作为划分样本的依据,取 C 22 ,将样本分成相等的两个子样本, 用 Goldfeld-Quandt 方法检验 1.的模型是否存在异方差; 如果以 sqrft 作为划分 样本的依据呢? 5.求 White 一致协方差估计,与 1.的 OLS 估计结果进行比较。
得到方程,命名为 eq04;如下图所示:
同样的,我们对另一阶段进行估计,与上述操作一致,不同的是 Sample 要改为 56 得到方程 eq05,如下图所示:
88;
12
计量经济学上机教程
Made By 08 经济 林盛楷
然后,在空白框中输入:scalar f=eq05.@ssr/eq04.@ssr 我们可以得到 f 值为 2.02264039761 ; 然后在空白框中进一步输入 scalar fgqx=@qfdist(0.95,33,33) 表示显著性水平 5%的 F 统计量临界值 对比可知,f 值大于 fgqx 的值,所以拒绝原假设,即到 LM 统计量为 14.0923855146 然后在空白框中输入 scalar f=@qchisq( 0.975,3) ,得到置信水平为 5%的卡方统计 量为 f=9.3484036045 通过比较可以知道,LM 统计量比 f 值大,故我们可以拒绝原假设,即模型存在异方差。
在对话框中输入:
4
计量经济学上机教程
Made By 08 经济 林盛楷
得到如下结果:
我们观察到 F 统计量和卡方统计量的 Prob 均为 0,表明原假设成立的概率为 0,即我们应 该拒绝 c(4)=c(5)=c(6)=0 的原假设。 然后我们估计约束模型,即去掉 bavg,hrunsyr 和 rbisyr 三个解释变量。 点击 Quick——Estimate Equation →输入 log(salary) c years gamesyr, 得到估计方程, 命名为 eq02; 如图所示: