pentaho-kettle-6.1.0.1-R 源码搭建ecplise工程
pentaho-kettle编译

Pentaho-Kettle是一款开源的ETL工具,它可以帮助用户实现各种数据集成、数据转换和数据加载的任务。
本文将对Pentaho-Kettle的编译过程进行详细介绍,以便读者能够更好地理解并使用这一工具。
一、Pentaho-Kettle编译概述1. Pentaho-Kettle的源代码是使用Java语言编写的,因此要进行编译,首先需要安装JDK(Java Development Kit)。
2. 在JDK安装完成后,需要下载Pentaho-Kettle的源代码,并解压到本地的开发环境中。
3. Pentaho-Kettle的源代码采用Ant构建系统进行编译,因此还需要安装Ant工具。
4. 接下来,就可以使用Ant工具进行编译Pentaho-Kettle的源代码了。
二、安装JDK1. 在冠方全球信息站(xxx)上下载最新版本的JDK安装包。
2. 安装JDK时,需要按照冠方指南进行操作,确保安装成功。
三、下载Pentaho-Kettle源代码1. 从Pentaho冠方全球信息站(xxx Integration/)上下载最新版本的Pentaho-Kettle源代码压缩包。
2. 将下载的压缩包解压到本地的开发环境目录中。
四、安装Ant工具1. 在冠方全球信息站(xxx)上下载最新版本的Ant安装包。
2. 安装Ant时,需要按照冠方指南进行操作,确保安装成功。
五、编译Pentaho-Kettle源代码1. 打开命令行工具,进入到Pentaho-Kettle源代码的根目录。
2. 执行命令“ant clean all”,等待编译过程完成。
3. 编译成功后,会在Pentaho-Kettle源代码的根目录生成相应的可执行文件和库文件。
六、常见问题及解决方法1. 编译过程中可能会遇到缺少依赖库的情况,这时需要根据错误提示下载并安装相应的依赖库。
2. 在安装JDK和Ant工具时,需要确保环境变量已正确配置,否则无法成功编译Pentaho-Kettle源代码。
pentaho介绍

一、Pentaho 整体架构cc二、Client tools1. Report Designer报表创建工具。
如果想创建复杂数据驱动的报表,这是合适工具。
2. Design Studio这是基于eclipse的工具,你可以使用它来创建手工编辑的报表或分析视图xaction 文件,一般用来对在report designer中无法增加修改的报表进行修改。
3. Aggregation Designer帮助改善Mondrian cube 性能的图形化工具。
4. Metadata Editor用来添加定制的元数据层到已经存在的数据源。
一般不需要,但是它对应业务用户在创建报表时解析数据库比较容易。
5. Pentaho Data Integration这是kettle etl工具。
6. Schema Workbench帮助你创建rolap的图形化工具。
这是为分析准备数据的必须步骤。
三、Pentaho BI suit community editon安装硬件要求:RAM:At least 2GBHard drive space:At least 1GBProcessor:Dual-core AMD64 or EM64T软件要求:需要JRE 1.5版本,1.4版本已经不再支持。
修改默认的端口8080,打开\biserver-ce\tomcat\conf目录下的server.xml文件,修改<connector port=8080为你想要的端口号。
同时在这部分可以调整Apache Tomcat参数。
在修改了该端口号后,必须同时修改\tomcat\webapps\pentaho\WEB-INF目录下的web.xml文件中的<context-param><param-name>base-url</param-name><param-value>http://localhost:8080/pe ntaho</param-value></context-param>中的端口号。
eclipse配置gradle详细教程

eclipse配置gradle详细教程
前⾔
Gradle是⼀个基于Apache Ant和Apache Maven概念的项⽬⾃动化构建⼯具。
它使⽤⼀种基于Groovy的特定领域语⾔来声明项⽬设置,⽽不是传统的XML。
Gradle就是⼯程的管理,帮我们做了依赖、打包、部署、发布、各种渠道的差异管理等⼯作。
Gradle优势:
1. ⼀款最新的,功能最强⼤的构建⼯具,⽤它逼格更⾼
2. 使⽤程序代替传统的XML配置,项⽬构建更灵活
3. 丰富的第三⽅插件,让你随⼼所欲使⽤
4. Maven、Ant能做的,Gradle都能做,但是Gradle能做的,Maven、Ant不⼀定能做。
1.下载并安装gradle 并解压⾄如下⽬录
官⽹下载地址:
下载后解压到⽬录:
D:\Software\
2.配置gradle环境
2.1 在系统设置系统变量⾥添加gradle 的配置
path系统变量追加
3 验证配置是否正确
gradle -v
4. 再eclipse 中下载插件gradle 插件并配置
5. 重启eclipse 新建项⽬就可以看见gradle 选项
新建项⽬时gradle 的设置要注意下图⼆
2.gradle 插件为我们提供了⼀个常⽤的task列表,便于我们加快我们开发速度。
eclipse环境搭建

1。
下载JDK先去/javase/downloads/index.jsp下载java开发文档JDK 现在版本1.5.0.0.9 这是进行java开发的根本所在!JDK的中文API帮助文件可以在sun中国技术社区/chinese_java_docs.html获得。
安装JDK. 也就安装JRE了,最好安装路径中不能包括中文字符。
2 。
搭构集成开发环境IDE我非常喜欢使用eclipse。
据说它有一统语言开发环境IDE所有开发平台的趋势。
先从/eclipse/downloads/下载eclipse 当前最新稳定版本eclipse 3.2.1当然若是需要汉化还应该下载Language Packs 3.2.1版本的下载地址/eclipse/downloads/drops/L-3.2.1_Language_Packs-20060921094 5/index.php由此获得了两个压缩包.解压elicpse压缩包到路径例如:F:\;若汉化则也须将汉化包须解压到同一路径F:\;或者将features ,plugins这两个文件夹复制到eclipse安装路径下这里需要注意。
如果在没有汉化之前就运行过eclipse.exe 可执行文件那么需要将:(例如我安装的eclipse )F:\eclipse\configuration 文件夹中除config.ini配置文件之外的所有文件夹删除重新打开eclipse.exe 获得的就是中文版了!这里有些小窍门:例如你想运行英文版的甚至繁体版的eclipse可以按照如下操作1.)在桌面上建立快捷方式;2).在桌面快捷方式下右键修改属性;若你安装了Language Packs参数-nl en 表示Eclipse版本语言为英语例如若改为-nl zh_tw 就是繁体文了参数-vmargs -Xms40m -Xmx512M 可以设置给eclipse分配的堆内存!可以在开发与调试大型应用软件时加快执行速度例如以上参数可分配512MB内存参数-data F:\eclipse\Workspace2 那么可以指定特地的工作区间这些参数的设置那么你的桌面就可以有几个不同作用的Eclispse桌面快捷方式了3。
pentaho-Kettle安装及使用说明(例子)

Kettle安装及使用说明1.什么Kettle?Kettle是一个开源的ETL(Extract-Transform-Load的缩写,即数据抽取、转换、装载的过程)项目,项目名很有意思,水壶。
按项目负责人Matt的说法:把各种数据放到一个壶里,然后呢,以一种你希望的格式流出。
Kettle包括三大块:Spoon——转换/工作(transform/job)设计工具(GUI方式)Kitchen——工作(job)执行器(命令行方式)Span——转换(trasform)执行器(命令行方式)Kettle是一款国外开源的etl工具,纯java编写,绿色无需安装,数据抽取高效稳定。
Kettle中有两种脚本文件,transformation和job,transformation完成针对数据的基础转换,job则完成整个工作流的控制。
2.Kettle简单例子2.1下载及安装Kettle下载地址:/projects/pentaho/files现在最新的版本是 3.6,为了统一版本,建议下载 3.2,即下载这个文件pdi-ce-3.2.0-stable.zip。
解压下载下来的文件,把它放在D:\下面。
在D:\data-integration文件夹里,我们就可以看到Kettle的启动文件Kettle.exe或Spoon.bat。
2.2 启动Kettle点击D:\data-integration\下面的Kettle.exe或Spoon.bat,过一会儿,就会出现Kettle的欢迎界面:稍等几秒,就会出现Kettle的主界面:2.3 创建transformation过程a.配置数据环境在做这个例子之前,我们需要先配置一下数据源,这个例子中,我们用到了三个数据库,分别是:Oracle、MySql、SQLServer,以及一个文本文件。
而且都放置在不同的主机上。
Oralce:ip地址为192.168.1.103,Oracle的实例名为scgtoa,创建语句为:create table userInfo(id int primary key,name varchar2(20) unique,age int not null,address varchar2(20));insert into userInfo values(1,'aaa',22,'成都市二环路');insert into userInfo values(2,'东方红',25,'中国北京');insert into userInfo values(3,'123',19,'广州白云区');MySql:ip地址为192.168.1.107,数据库名为test2,创建语句为:create database test2;use test2;create table login(id int primary key,realname varchar(20) unique,username varchar(20) unique,password varchar(20) not null,active int default 0);insert into login values(1,'aaa','admin','admin',0);insert into login values(2,'东方红','test','test',1);insert into login values(3,'123','xxx123','123456',1);SQLServer:本机,ip为192.168.1.115,创建语句为:create database test3;use test3;create table student(sid varchar(20) primary key,sname varchar(20) unique,teacher varchar(20) not null,);insert into student values('078','aaa','李老师');insert into student values('152','东方红','Mr Wu');insert into student values('034','123','徐老师');文本文件:名为dbtest.log,位于192.168.1.103\zhang\上,即跟Oracle同一个主机。
搭建Eclipse+MyEclipse+tomcat开发环境+开发J2EE的第一步
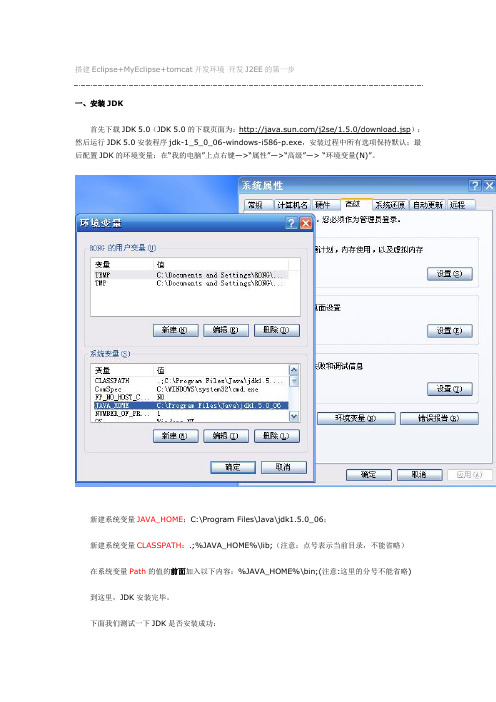
搭建Eclipse+MyEclipse+tomcat开发环境开发J2EE的第一步一、安装JDK首先下载JDK 5.0(JDK 5.0的下载页面为:/j2se/1.5.0/download.jsp);然后运行JDK 5.0安装程序jdk-1_5_0_06-windows-i586-p.exe,安装过程中所有选项保持默认;最后配置JDK的环境变量:在“我的电脑”上点右键—>“属性”—>“高级”—> “环境变量(N)”。
新建系统变量JAVA_HOME:C:\Program Files\Java\jdk1.5.0_06;新建系统变量CLASSPATH:.;%JAVA_HOME%\lib;(注意:点号表示当前目录,不能省略)在系统变量Path的值的前面加入以下内容:%JAVA_HOME%\bin;(注意:这里的分号不能省略) 到这里,JDK安装完毕。
下面我们测试一下JDK是否安装成功:将以下内容复制到记事本中:public class HelloJAVA{public static void main(String srg[]){System.out.println("Hello JAVA!");}}另存为“HelloJAVA.java”(不含引号,下同),并保存到D盘根目录下。
在命令行依次输入下图中红线所标注的命令:如果出现上图红框中所标注的内容,则说明JDK安装成功!注意:如果以后要安装诸如Eclipse、Borland JBuilder、JCreator、IntelliJ IDEA等集成开发环境(IDE,Integrated Developm ent Environment),应该在IDE中编译运行一个简单的HelloWorld程序,以保证IDE可以识别出JDK的位置。
二、安装Tomcat首先下载jakarta-tomcat-5.0.30.zip,之所以下载免安装版的好处是可以使用多个Tomcat (jakarta-tomcat-5.0.30.zip的下载页面为:/tomcat/tomcat-5/v5.0.30/bin/);然后将jakarta-tomcat-5.0.30.zip直接解压到D盘根目录:最后配置Tomcat的环境变量:在“我的电脑”上点右键—>“属性”—>“高级”—> “环境变量(N)”。
pentaho之kettle篇---kettle基本操作
pentaho之kettle篇---kettle基本操作今天先来做⼀个简单的kettle的例⼦。
打开输⼊,选择CSV⽂件输⼊。
双击CSV⽂件输⼊图标,可以看见如下:步骤名称:就是你这⼀步的名字,可以任意取,原则就是要明⽩,清楚这⼀步是做了什么操作。
⽂件名:是你要选取的这个.CSV结尾的⽂件的名称。
列分隔符:每个CSV⽂件都是有⼀定的规则的,要么是分号是分隔符,要么是逗号是分隔符等等。
包含列头⾏:这个是针对你的这个CSV是否具有表头,如果有就勾上,否则他就把第⼀⾏的表头当成数据导⼊了。
这样选择⼀个CSV格式的⽂件之后就可以了,接下来点击⼀下获取字段,得到如下图所⽰:点击⼀下预览,会提⽰要预览的⾏数没输⼊你要预览的⾏数就⾏了。
以上就是预览的内容了。
之后点击确定就OK了。
之后再来说说输出的操作。
这次输出的操作我们选择的是MySQL数据库,⾸先需要⽂件---->新建------->数据库连接。
填写上基本的数据库信息就OK了,点击测试出现说明你的连库信息是正确的,点击确定就可以了。
这⼀步的连接数据库只是针对于这个装换的。
对于其他转换我们需要重新制定数据库!双击表输出:数据库连接就是我们刚才创建的数据库连接,如果不是我们想要的,可以另外再创建⼀个连接。
⽬标数据库如果没有创建的话,我们可以先写⼀个名字,然后再点击SQL,就出现了⼀个执⾏创建的sql的界⾯:⾥⾯有些字段的类型是可以改的,改成你需要的字段的类型。
之后点击执⾏就⾏了。
这⼀次我们再查看⼀下我们数据库⾥⾯的表,就有字段了。
下⾯我们点击Run,输出⽇志如下:步骤度量如下:之前表⾥⾯有2823个数据,所以这⼀次执⾏成功了!但是这⾥⾯有⼀个问题,我们可以再Run⼀下这个转换,发现⼜导⼊了2823条记录。
再来看看数据库⾥⾯的数据:纳尼,怎么是5646怎么解决这中间是需要⼀个过滤的操作的,基本的思想就是:ID⼀样的就是Update,ID不⼀样的就是插⼊就去就可以了。
开源ETL工具-PentahoKettle使用入门
2. 下载和安装 要运行此工具你必须安装 SUN 公司的 JAVA 运行环境 1.4 或者更高版本, 相关资源你 可以到网络上搜索 JDK 进行下载。设置 JAVA 运行环境变量,JAVA_HOME 和 PATH KETTLE 的下载可以到 /取得最新版本,下载后解压,就可 以直接运行。
第 12页 共 69页
各个组件有不同的用途, 这些组件组合起来可以把数据从数据源经过一系列处理, 最终保存 到目标表。 4.3.3. 添加 TABLE INPUT
鼠标选中左边窗口 INPUT 文件夹下的 TABLE INPUT 组件,然后拖动该组件到右边主窗口中。 如图:
第 13页 共 69页
双击主窗口中 TABLE INPUT 组件,进入 TABLE INPUT 的设置窗口:
第 9页 共 69页
点击左上角的 NEW 按钮或者菜单 FILE->NEW,创建新的 TRANSFORM
主窗口出现一个新的标签页:TRANSFORMATION 1
在主窗口空白处点击右键, 出现菜单, 选择 TRANSFORMATION SETTINGS.进入 TRANSFORMATION SETTINGS 窗口。
JOB 实际上就是 ETL 中的任务流,用于调度 TRANSFORMATION 或者 JOB. 点击左上角的 NEW 按钮或者菜单 FILE->NEW,创建新的 JOB
在主窗口空白处点击右键,出现菜单,选择 JOB SETTINGS
进入 JOB SETTING 窗口。
第 21页 共 69页
A. B. C.
第 14页 共 69页
1) 2) 3)
按照命名规范设置 STEP NAME 在 CONNECTION 下拉框,选择源表所在的数据源,如果没有则新建数据源,参考”设置 资料库”节的新建数据源说明 点击 GET SQL SELECT STATEMENT 按钮,进入源表选择窗口:
Pentaho Data Integration 完全自学手册.2016.12.11
Pentaho Data Integration 完全自学手册(孟菲斯著)文档目录文档目录 (2)更新记录 (17)第一章.KETTLE 基础介绍 (18)1.1.核心组件 (18)1.2.组成部分 (18)1.3.概念模型 (19)1.3.1.Transformation(转换) (19)1.3.2.Steps(步骤) (20)1.3.3.Hops(节点连接) (20)1.3.4.Jobs(工作) (20)1.3.5.Variable(变量) (21)1.3.5.1.设置环境变量 (21)1.3.5.2.设置变量 (21)1.4.查看版本 (22)1.5.选项设置 (23)第二章.KETTLE 环境搭建 (25)2.1.单机部署 (25)2.1.1.下载kettle (25)2.1.2.安装kettle (25)2.1.3.运行Spoon (25)2.2.集群部署 (26)1. Carte简介 (26)2. Carte部署配置 (26)2.1 启动方法 (26)2.2 启动配置 (26)2.3 Carte xml文件配置详解 (27)2.3.1 slaveserver节点 (28)2.3.2 masters节点 (28)2.3.3 report_to_masters节点 (28)2.3.4 max_log_lines节点 (28)2.3.5 max_log_timeout_minutes节点 (28)2.3.6 object_timeout_minutes节点 (29)2.3.7 (*) repository节点 (29)3. Carte集群 (29)3.1 普通集群 (30)3.2 动态集群 (30)2.3.运行方式 (30)2.3.1.转换执行器Pan (30)2.3.1.2.Pan 实例讲解:Windows (31)2.3.1.3.Pan 实例讲解:Linux (31)2.3.2.任务执行器Kitchen (32)2.3.2.1.Kitchen 参数介绍 (32)2.3.2.2.Kitchen 实例讲解:Windows (33)2.3.2.3.Kitchen 实例讲解:Linux (34)2.4.定时任务 (35)2.4.1.Windows (35)2.4.2.Linux (35)第三章.KETTLE 基本功能 (40)3.1.新建转换 (40)3.1.1.方法1 (40)3.1.2.方法2 (40)3.1.3.方法3 (41)3.1.4.主对象树 (41)3.1.5.核心对象 (42)3.1.6.新建数据库连接 (42)3.2.转换实例 (43)3.2.1.转换实例1 (43)3.2.2.转换实例2 (43)3.3.新建作业 (44)3.3.1.方法1 (44)3.3.2.方法2 (44)3.3.3.方法3 (45)3.3.4.主对象树 (45)3.3.5.核心对象 (46)3.4.作业实例 (46)3.4.1.作业实例1 (46)3.4.2.作业实例2 (46)第四章.KETTLE 设计环境 (46)4.1.T RANSFORMATION:转换步骤(24-228) (46)4.1.1.Input:输入(38) (46)4.1.1.1.Csv file input (46)4.1.1.1.1.功能描述 (47)4.1.1.1.2.操作步骤 (47)4.1.1.1.3.实例讲解 (48)4.1.1.2.DataGrid (48)4.1.1.3.De-serialize from file:文件反序列化 (48)4.1.1.4.ESRI Shapefile Reader (48)4.1.1.5.Email messages input (48)4.1.1.6.Fixed file input (48)4.1.1.7.GZIP CSV Input (48)4.1.1.9.Generate random credit card numbers (48)4.1.1.10.Generate random value (49)4.1.1.11.Get File Names (49)4.1.1.12.Get Files Rows Count (49)4.1.1.13.Get SubFolder names (49)4.1.1.14.Get System Info:获取系统信息 (49)4.1.1.14.1.功能描述 (50)4.1.1.14.2.操作步骤 (51)4.1.1.14.3.实例讲解 (52)4.1.1.15.Get data from XML (53)4.1.1.16.Get repository names (53)4.1.1.17.Get table names (53)4.1.1.18.Google Analytics (53)4.1.1.19.HL7 Input (53)4.1.1.20.JSON Input (53)4.1.1.21.LDAP Input (53)4.1.1.22.LDIF Input (54)4.1.1.23.Load file content in memory (54)4.1.1.24.Microsoft Access input (54)4.1.1.25.Microsoft Excel Input (54)4.1.1.25.1.功能描述 (54)4.1.1.25.2.操作步骤 (54)4.1.1.25.2.1.指定文件名 (55)4.1.1.25.2.2.指定内容 (55)4.1.1.25.2.3.字段 (55)4.1.1.25.2.4.错误处理 (55)4.1.1.25.2.5.其他输出字段 (55)4.1.1.25.3.实例讲解 (55)4.1.1.26.Mondrian Input (55)4.1.1.27.OLAP Input (56)4.1.1.28.Property Input (56)4.1.1.29.RSS Input (56)4.1.1.30.S3 CSV Input (56)4.1.1.31.SAP Input (56)4.1.1.32.SAS Input (56)4.1.1.33.SalesForce Input (56)4.1.1.34.Table input:表输入 (56)4.1.1.34.1.功能描述 (56)4.1.1.34.2.操作步骤 (57)4.1.1.34.3.实例讲解 (58)4.1.1.35.Text file input:文本文件输入 (58)4.1.1.35.1.功能描述 (58)4.1.1.35.2.操作步骤 (58)4.1.1.35.2.2.从先前的步骤中接受文件名 (59)4.1.1.35.2.3.内容指定 (59)4.1.1.35.2.4.错误处理 (62)4.1.1.35.2.5.过滤 (63)4.1.1.35.2.6.字段 (64)4.1.1.35.2.7.其他输出字段 (65)4.1.1.35.3.格式化 (65)4.1.1.35.3.1.Number格式化 (65)4.1.1.35.3.2.Date格式化 (66)4.1.1.35.3.3.其它 (66)4.1.1.35.4.实例讲解 (67)4.1.1.36.XBase input:XBase输入 (67)4.1.1.36.1.功能描述 (67)4.1.1.37.XML Input Stream(StAX) (67)4.1.1.37.1.功能描述 (67)4.1.1.38.Yaml Input (69)4.1.2.Output:输出(22) (69)4.1.2.1.Automatic Documentation Output (69)4.1.2.2.Delete:删除 (69)4.1.2.2.1.功能描述 (69)4.1.2.2.2.操作步骤 (69)4.1.2.3.Insert / Update:插入/更新 (70)4.1.2.3.1.功能描述 (70)4.1.2.3.2.操作步骤 (71)4.1.2.4.JSON Output (72)4.1.2.5.LDAP Output (72)4.1.2.6.Mircosoft Access Output (72)4.1.2.7.Mircosoft Excel Output:Excel输出 (72)4.1.2.7.1.功能描述 (72)4.1.2.7.2.操作步骤 (72)4.1.2.8.Pentaho Reporting Output (75)4.1.2.9.Properties Output (75)4.1.2.10.RSS Output (75)4.1.2.11.S3 File Output (75)4.1.2.12.SQL File Output (75)4.1.2.13.Saleforce Delete (75)4.1.2.14.Saleforce Insert (75)4.1.2.15.Saleforce Update (75)4.1.2.16.Saleforce Upsert (75)4.1.2.17.Serialize to file (75)4.1.2.18.Synchronize after merge (76)4.1.2.19.Table output (76)4.1.2.19.1.功能描述 (76)4.1.2.20.Text file output:文本文件输出 (79)4.1.2.20.1.功能描述 (79)4.1.2.20.2.操作步骤 (80)4.1.2.21.Update:更新 (81)4.1.2.21.1.功能描述 (81)4.1.2.21.2.操作步骤 (82)4.1.2.22.XML Output (83)4.1.3.Transform:转换(26) (84)4.1.3.1.Add XML (84)4.1.3.2.Add a checksum (84)4.1.3.3.Add constants:增加常量 (84)4.1.3.3.1.功能描述 (84)4.1.3.3.2.操作步骤 (84)4.1.3.4.Add sequence (85)4.1.3.4.1.功能描述 (85)4.1.3.4.2.操作步骤 (85)4.1.3.5.Add value fields changing seqence (86)4.1.3.6.!Calculator:计算器 (86)4.1.3.6.1.功能描述 (87)4.1.3.6.2.操作步骤 (88)4.1.3.7.Closure Generator (89)4.1.3.8.Concat Fields (89)4.1.3.9.Get ID From slave server (89)4.1.3.10.Number range (89)4.1.3.11.Replace in string:字符串替换 (89)4.1.3.11.1.功能描述 (89)4.1.3.11.2.操作步骤 (89)4.1.3.12.!Row Normaliser:行转列 (90)4.1.3.12.1.功能描述 (90)4.1.3.12.2.操作步骤 (91)4.1.3.13.Row denormaliser:列转行 (92)4.1.3.13.1.功能描述 (92)4.1.3.13.2.操作步骤 (92)4.1.3.14.!Row flattener:行扁平化 (92)4.1.3.14.1.功能描述 (93)4.1.3.14.2.操作步骤 (93)4.1.3.15.!Select values:字段选择 (94)4.1.3.15.1.功能描述 (94)4.1.3.15.2.操作步骤 (95)4.1.3.16.Set field value (96)4.1.3.17.Set field value to a constant (96)4.1.3.18.Sort rows (96)4.1.3.18.1.功能描述 (96)4.1.3.19.Split Fields:拆分字段 (97)4.1.3.19.1.功能描述 (97)4.1.3.19.2.操作步骤 (97)4.1.3.20.Split Fields to rows (99)4.1.3.21.String operations (99)4.1.3.22.String cut:裁剪字符串 (99)4.1.3.22.1.功能描述 (99)4.1.3.22.2.操作步骤 (99)4.1.3.23.Unique rows:去除重复记录 (100)4.1.3.23.1.功能描述 (100)4.1.3.23.2.操作步骤 (100)4.1.3.25.!Value Mapper:值映射 (101)4.1.3.25.1.功能描述 (101)4.1.3.25.2.操作步骤 (101)4.1.3.26.XSL Transformation (103)4.1.4.Utility(15) (103)4.1.4.1.Change file encoding (103)4.1.4.2.Clone row (103)4.1.4.3.Delay row (103)4.1.4.4.Edit to xml (103)4.1.4.5.Execute a process (103)4.1.4.6.If field value is null (103)4.1.4.7.Mail (103)4.1.4.8.Metadata structure of stream (103)4.1.4.9.Null if:设置为空值 (103)4.1.4.9.1.功能描述 (103)4.1.4.10.Process files (104)4.1.4.11.Run SSH commands (104)4.1.4.12.Send message to Syslog (104)4.1.4.13.Table Compare (104)4.1.4.14.Write to log (104)4.1.4.15.Zip file (104)4.1.4.15.1.功能描述 (104)4.1.4.15.2.操作步骤 (104)4.1.5.Flow(16) (106)4.1.5.1.Abort:中止 (106)4.1.5.1.1.功能描述 (106)4.1.5.2.Annotate Stream (106)4.1.5.3.Append streams:追加流 (106)4.1.5.3.1.功能描述 (106)4.1.5.3.2.操作步骤 (106)4.1.5.4.Block this step unitil steps finish (107)4.1.5.5.Blocking Step:阻塞数据 (107)4.1.5.5.2.操作步骤 (107)4.1.5.6.Detect empty stream (108)4.1.5.7.Dummy (do nothing):空操作(什么也不做) (108)4.1.5.7.1.功能描述 (108)4.1.5.8.ETL Metadata Injection (109)4.1.5.9.!Filter rows: 过滤记录(过滤行) (109)4.1.5.9.1.功能描述 (109)4.1.5.9.2.操作步骤 (109)4.1.5.10.Identify last row in a stream (110)4.1.5.11.Java fileter (111)4.1.5.12.Job Executor (111)4.1.5.13.Prioritize streams (111)4.1.5.14.Single Threader (111)4.1.5.15.Switch / Case (111)4.1.5.15.1.功能描述 (111)4.1.5.15.2.操作步骤 (111)4.1.5.16.Transformation Executor (113)4.1.6.Scripting(9) (113)4.1.6.1.!Execute SQL script:执行SQL脚本 (113)4.1.6.1.1.功能描述 (113)4.1.6.1.2.操作步骤 (114)4.1.6.1.3.实例讲解 (115)4.1.6.2.Execute row SQL script:执行SQL脚本(字段流替换) (116)4.1.6.2.1.功能描述 (116)4.1.6.2.2.操作步骤 (116)4.1.6.3.Formula (117)4.1.6.4.!Modified Java Script Value (118)1)Transformation scripts (118)2)Transformation constants (118)3)Transformation functions (118)1)过滤Null字段 (119)2)字符串截取 (119)3)过滤记录行,控制转换流程 (119)4)使用java类库 (119)4.1.6.4.1.实例讲解 (124)4.1.6.5.Regex Evaluation (124)4.1.6.6.Rules Accumulator (124)4.1.6.7.Rules Executor (124)er Defined Java Class (124)er Defined Java Expression (124)4.1.7.BA Server(3) (125)4.1.7.1.Call endpoint (125)4.1.7.2.Get session varables (125)4.1.8.Lookup(15) (125)4.1.8.1.!Call DB Procedure:调用DB存储过程 (125)4.1.8.1.1.功能描述 (125)4.1.8.1.2.操作步骤 (125)4.1.8.2.Check if a column exists (127)4.1.8.3.Check if file is locked (127)4.1.8.4.Check if webservice is available (127)4.1.8.5.!Database join:数据库连接 (127)4.1.8.5.1.功能描述 (127)4.1.8.5.2.操作步骤 (127)4.1.8.6.!Database lookup:数据库查询 (128)4.1.8.6.1.功能描述 (129)4.1.8.6.2.操作步骤 (129)4.1.8.7.Dynamic SQL row (131)4.1.8.8.File exists (131)4.1.8.9.Fuzzy match (131)4.1.8.10.HTTP client (131)4.1.8.10.1.功能描述 (131)4.1.8.10.2.操作步骤 (131)4.1.8.11.HTTP Post (132)4.1.8.12.REST Client (132)4.1.8.13.Stream lookup (132)4.1.8.14.Table exists (132)4.1.8.15.Web services lookup (132)4.1.9.Joins(6) (133)4.1.9.1.!Join Rows(Cartesian product):记录关联(笛卡尔输出) (133)4.1.9.1.1.功能描述 (133)4.1.9.2.!Merge join (133)4.1.9.2.1.功能描述 (133)4.1.9.3.!Merge Rows (diff) (134)4.1.9.4.Multiway Merge Join (134)4.1.9.5.Sorted Merge (134)4.1.9.6.XML Join (134)4.1.10.Data Warehouse(2) (135)4.1.10.1.!Combination lookup/update (135)4.1.10.2.!Dimension lookup/update (135)4.1.11.Validation(4) (136)4.1.11.1.Credit card validator (136)4.1.11.2.Data Validator (136)4.1.11.3.Mail Validator (136)4.1.11.4.XSD Validator (136)4.1.12.!Statistics:统计(7) (136)4.1.12.1.Analytic Query (136)4.1.12.2.1.功能描述 (136)4.1.12.2.2.操作步骤 (136)4.1.12.3.Memory Group by (138)4.1.12.4.Output steps metrics (138)4.1.12.5.Reservoir Sampling (138)4.1.12.6.Sample rows (138)4.1.12.7.Univariate Statistics (138)4.1.13.Big Data(13) (138)4.1.13.1.Avro Input (138)4.1.13.2.Cassandra Input (138)4.1.13.3.Cassandra output (138)4.1.13.4.CouchDb Input (138)4.1.13.5.HBase Input (138)4.1.13.6.HBase Row Decoder (138)4.1.13.7.Hadoop File Input (138)4.1.13.8.Hadoop File Output (138)4.1.13.9.MapReduce Input (138)4.1.13.10.MapReduce output (139)4.1.13.11.MongoDB Input (139)4.1.13.12.MongoDB output (139)4.1.13.13.SSTable Output (139)4.1.14.Agile(2) (139)4.1.14.1.MonetDB Agile Mart (139)4.1.14.2.Table Agile mart (139)4.1.15.Cryptography(4) (139)4.1.15.1.PGP Decrypt stream (139)4.1.15.2.PGP Encrypt stream (139)4.1.15.3.Secret key generator (139)4.1.15.4.Symmetric Cryptography (139)4.1.16.Palo(4) (139)4.1.16.1.Palo Cell Input (139)4.1.16.2.Palo Cell Output (139)4.1.16.3.Palo Dim Input (140)4.1.16.4.Palo Dim Output (140)4.1.17.Open ERP(3) (140)4.1.17.1.OpenERP Object Delete (140)4.1.17.2.OpenERP Object Input (140)4.1.17.3.OpenERP Object OUtput (140)4.1.18.Job:作业(6) (140)4.1.18.1.Copy rows to result:复制记录到结果 (140)4.1.18.1.1.功能描述 (140)4.1.18.2.Get Variables:获取变量 (140)4.1.18.2.1.功能描述 (140)4.1.18.3.Get files from result:从结果获取文件 (141)4.1.18.3.1.功能描述 (141)4.1.18.3.2.操作步骤 (142)4.1.18.4.Get rows from result:从结果获取记录 (142)4.1.18.4.1.功能描述 (142)4.1.18.5.Set Variables:设置变量 (142)4.1.18.5.1.功能描述 (143)4.1.18.5.2.操作步骤 (143)4.1.18.6.Set files in result:复制文件到结果 (143)4.1.18.6.1.功能描述 (143)4.1.18.6.2.操作步骤 (143)4.1.19.!Mapping(4) (144)4.1.19.1.Mapping(sub-transformation) (144)4.1.19.2.Mapping input specification (144)4.1.19.3.Mapping output specitication (144)4.1.19.4.Simple Mapping(sub-transformation) (144)4.1.20.Bulk loading(11) (145)4.1.20.1.ElasticSearch Bulk Insert (145)4.1.20.2.Greenplum load (145)bright loader (145)4.1.20.4.Ingres VectorWise Bulk Loader (145)4.1.20.5.MonetDB Bulk Loader (145)4.1.20.6.MySQL Bulk loader (145)4.1.20.7.!Oracle Bulk loader (145)4.1.20.7.1.功能描述 (145)4.1.20.8.PostgresSQL Bulk loader (146)4.1.20.9.Teradata Fastload Bulk Loader (146)4.1.20.10.Teradata TPT Bulk loader (146)4.1.20.11.Vertica Bulk loader (146)4.1.21.Inline(3) (146)4.1.21.1.Injector: 记录注射器 (146)4.1.21.2.Socket reader: 套接字读入器 (147)4.1.21.2.1.功能描述 (147)4.1.21.3.Socket writer (147)4.1.22.Experimental(2) (148)4.1.22.1.SFTP Put (148)4.1.22.2.Script (148)4.1.23.Deprecated(4) (148)4.1.23.1.Example Step (148)4.1.23.2.Greenplum Bulk loader (148)4.1.23.3.LicidDB Streaming Loader (148)4.1.23.4.Old Text file input (148)4.1.24.History(9) (148)4.1.24.2.Table input (148)4.1.24.3.Text file output (148)4.1.24.4.Table output (148)4.1.24.5.Moding java Script Value (148)4.1.24.6.Add sequence (148)4.1.24.7.Generate Rows (149)4.1.24.8.Get System Info (149)4.1.24.9.Sort rows:行排序 (149)4.1.24.9.1.功能描述 (149)4.2.JOB:作业步骤(15-92) (149)4.2.1.General:通用(6) (149)4.2.1.1.Start:开始 (149)4.2.1.1.1.功能描述 (149)4.2.1.1.2.操作步骤 (150)4.2.1.2.Dummy:空操作 (150)4.2.1.2.1.功能描述 (150)4.2.1.3.OK (151)4.2.1.4.Job:作业 (151)4.2.1.4.1.功能描述 (151)4.2.1.4.2.操作步骤 (151)4.2.1.5.Set variables:设置变量 (152)4.2.1.5.1.功能描述 (152)4.2.1.6.Transformation (152)4.2.1.6.1.功能描述 (152)4.2.1.6.2.操作步骤 (153)4.2.1.7.Success (154)4.2.2.Mail:邮件(3) (154)4.2.2.1.Mail validator (154)4.2.2.2.Mail:发送邮件 (154)4.2.2.2.1.功能描述 (154)4.2.2.2.2.操作步骤 (154)4.2.2.3.Get mails from POP:接收邮件 (156)4.2.2.3.1.功能描述 (156)4.2.2.3.2.操作步骤 (156)4.2.3.File management(19) (158)4.2.3.1.Process result filenames (158)4.2.3.2.File Compare:比较文件 (158)4.2.3.2.1.功能描述 (158)4.2.3.2.2.操作步骤 (158)4.2.3.3.Create a folder:创建文件夹 (159)4.2.3.3.1.功能描述 (159)4.2.3.3.2.操作步骤 (159)4.2.3.4.Unzip file:解压ZIP文件 (159)4.2.3.4.2.操作步骤 (160)4.2.3.5.Delete file:删除文件 (161)4.2.3.5.1.功能描述 (161)4.2.3.5.2.操作步骤 (161)4.2.3.6.HTTP (162)4.2.3.7.Write to file (162)4.2.3.7.1.功能描述 (162)4.2.3.7.2.操作步骤 (162)4.2.3.8.Convert file between Windows and Unix (163)pare folders:比较文件夹 (163)4.2.3.9.1.功能描述 (163)4.2.3.9.2.操作步骤 (163)4.2.3.10.Zip file:压缩文件 (164)4.2.3.10.1.功能描述 (164)4.2.3.11.Copy Files (165)4.2.3.11.1.功能描述 (165)4.2.3.11.2.操作步骤 (165)4.2.3.12.Add filenames to result添加文件名到结果 (166)4.2.3.12.1.功能描述 (166)4.2.3.12.2.操作步骤 (166)4.2.3.13.Delete folders:删除文件夹 (167)4.2.3.13.1.功能描述 (167)4.2.3.13.2.操作步骤 (167)4.2.3.14.Delete filenames from result:在结果中删除文件名 (168)4.2.3.14.1.功能描述 (168)4.2.3.14.2.操作步骤 (168)4.2.3.15.Delete files:删除多个文件 (169)4.2.3.15.1.功能描述 (169)4.2.3.15.2.操作步骤 (169)4.2.3.16.Wait for file:等待文件 (170)4.2.3.16.1.功能描述 (170)4.2.3.16.2.操作步骤 (170)4.2.3.17.Move Files移动文件 (171)4.2.3.17.1.功能描述 (171)4.2.3.17.2.操作步骤 (171)4.2.3.18.Create file:创建文件 (171)4.2.3.18.1.功能描述 (172)4.2.3.18.2.操作步骤 (172)4.2.3.19.Copy or Move result filenames:根据结果复制或移动文件 (172)4.2.3.19.1.功能描述 (172)4.2.3.19.2.操作步骤 (173)4.2.4.Conditions(12) (174)4.2.4.1.Check webservice availability:检查WEB服务是否可用 (174)4.2.4.1.2.操作步骤 (174)4.2.4.2.Check files locked:判断是否有文件被锁定 (175)4.2.4.2.1.功能描述 (175)4.2.4.2.2.操作步骤 (175)4.2.4.3.Colums exist in a table:检查列在表中是否存在 (176)4.2.4.3.1.功能描述 (176)4.2.4.3.2.操作步骤 (176)4.2.4.4.Wait for (177)4.2.4.4.1.功能描述 (177)4.2.4.4.2.操作步骤 (177)4.2.4.5.Evaluate files metrics (177)4.2.4.6.Check Db connections (177)4.2.4.6.1.功能描述 (177)4.2.4.6.2.操作步骤 (178)4.2.4.7.File Exists:文件存在 (178)4.2.4.7.1.功能描述 (178)4.2.4.7.2.操作步骤 (178)4.2.4.8.Evaluate rows number in a table:判断标中行数 (178)4.2.4.8.1.功能描述 (178)4.2.4.8.2.操作步骤 (179)4.2.4.9.Checks if files exist:检查文件是否存在 (180)4.2.4.9.1.功能描述 (180)4.2.4.9.2.操作步骤 (180)4.2.4.10.Check if a folder is empty检查文件夹是否为空 (180)4.2.4.10.1.功能描述 (181)4.2.4.10.2.操作步骤 (181)4.2.4.11.Simple evaluation:简单评估 (181)4.2.4.11.1.功能描述 (181)4.2.4.11.2.操作步骤 (182)4.2.4.12.Table exists:表存在 (182)4.2.4.12.1.功能描述 (183)4.2.4.12.2.操作步骤 (183)4.2.5.Scripting(3) (183)4.2.5.1.Shell (183)4.2.5.1.1.功能描述 (183)4.2.5.1.2.操作步骤 (184)4.2.5.2.SQL (186)4.2.5.2.1.功能描述 (186)4.2.5.2.2.操作步骤 (186)4.2.5.3.JavaScript:Java脚本 (187)4.2.5.3.1.功能描述 (187)4.2.5.3.2.操作步骤 (188)4.2.6.Bulk loading(3) (190)4.2.6.1.BulkLoad form Mysql into file (190)4.2.6.2.BulkLoad into MSSQL (190)4.2.6.3.BulkLoad into Mysql (190)4.2.7.Big Data(10) (190)4.2.7.1.Oozie Job Execcutor (190)4.2.7.2.Hadoop Job Executor (190)4.2.7.3.Pig Script Executor (190)4.2.7.4.Amazon Hive Job Executor (190)4.2.7.5.Spark Submit (190)4.2.7.6.Sqoop Export (190)4.2.7.7.Sqoop Import (190)4.2.7.8.Pentaho Mapreduce (190)4.2.7.9.Hadoop Copy Files (190)4.2.7.10.Amazon EMR Job Executor (190)4.2.8.Modeling(2) (191)4.2.8.1.Build Model (191)4.2.8.2.Publish Model (191)4.2.9.XML(4) (191)4.2.9.1.XSD Validator (191)4.2.9.2.Check if XML file is well formed (191)4.2.9.3.XSL Transformation (191)4.2.9.4.DTD Validator (191)4.2.10.Utility(13) (191)4.2.10.1.Truncate tables (191)4.2.10.2.Display Msgbox Info (191)4.2.10.3.Wait for SQL (191)4.2.10.4.Abort job (192)4.2.10.5.Talend Job Execution (192)4.2.10.6.HL7 MLLP Acknowledge (192)4.2.10.7.Send Nagios passive check (192)4.2.10.8.Ping a host (192)4.2.10.9.Write To Log (192)4.2.10.10.Telnet a host (193)4.2.10.11.HL7 MLLP Input (193)4.2.10.12.Send information using Syslog (193)4.2.10.13.Send SNMP trap (193)4.2.11.Reposotory(2) (194)4.2.11.1.Export repository to XML file (194)4.2.11.2.Check if connected to repository (194)4.2.12.File transfer(8) (194)4.2.12.1.Get a file with FTP (194)4.2.12.1.1.功能描述 (195)4.2.12.1.2.操作步骤 (195)4.2.12.2.Put a file with FTP (197)4.2.12.2.1.功能描述 (198)4.2.12.2.2.操作步骤 (198)4.2.12.4.FTP Delete:删除FTP文件 (199)4.2.12.4.1.功能描述 (199)4.2.12.4.2.操作步骤 (199)4.2.12.5.Get a file with SFTP (199)4.2.12.5.1.功能描述 (199)4.2.12.5.2.操作步骤 (200)4.2.12.6.Put a file with SFTP (200)4.2.12.6.1.功能描述 (201)4.2.12.6.2.操作步骤 (201)4.2.12.7.Upload files to FTPS (201)4.2.13.File encryption(3) (202)4.2.13.1.Verify file signature with PGP (202)4.2.13.2.Decrypt files with PGP (202)4.2.13.3.Encrypt files with PGP (202)4.2.14.Palo(2) (202)4.2.14.1.Palo Cube Delete (202)4.2.14.2.Palo Cube Create (202)4.2.15.Deprecated(2) (202)4.2.15.1.MS Access Bulk Load (202)4.2.15.2.Example Job (202)更新记录第一章.Kettle 基础介绍1.1.核心组件Spoon是构建ETL Jobs和Transformations的工具。
kettle7 源码编译
Kettle是一款ETL(Extract, Transform, Load)工具,主要用于数据的抽取、转换和加载。
其前身是Pentaho Data Integration (PDI)。
如果你想要从源代码编译Kettle 7,可以按照以下步骤进行:
获取源代码:首先,你需要从Kettle的官方网站或者Git仓库获取最新的源代码。
一般来说,这可以通过克隆Kettle的Git仓库完成。
环境准备:编译Kettle需要Java JDK 1.8或更高版本,还需要Maven和一些其他依赖。
确保你的开发环境已经安装了这些工具。
编译源代码:进入Kettle的源代码目录,然后运行mvn clean install命令来编译源代码。
Maven 会处理所有的依赖关系,并编译项目。
构建解决方案:如果Kettle的源代码包含了Pentaho的解决方案文件(例如solution.jps),你可能还需要使用Pentaho构建工具(PBT)来构建解决方案。
这通常涉及到运行pbt build -s solution.jps命令。
测试和验证:编译完成后,你可以运行一些测试脚本来验证Kettle是否正确编译。
这些测试脚本通常在src/test/resources目录下。
构建发行版:如果你要构建Kettle的发行版,可以使用mvn package命令,这将创建一个包含所有必要文件的发行版包。
请注意,由于Kettle是一个大型项目,编译过程可能需要一些时间,并且可能会遇到依赖问题或其他问题。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
pentaho-kettle-6.1.0.1-R 源码搭建ecplise工程
Pentaho Data Integration(Kettle) 插件开发调试环境搭建(上)
本文转自:/thread-576-1-1.html1. 下载源码https:///pentaho/pentaho-kettle/
https:///pentaho/pentaho-kettle/releases2. 下载kettle发行版本
/projects/data-integration/ (主要是为了获取依赖的jar包)以上两者版本请尽量保持一致。
源码的readme文件中描述了源码编译方法,你可以照着步骤作,此方法需要联网下载所有的依赖包,一般非常慢,多数情况会出错。
本文所述方法不需要联网下载依赖包,因为几乎所有需要下载的jar包已经在发行版中了。
3. 将源码拷贝到eclipse的当前workspace目录下(如
/path/to/eclipse/workspace/pentaho-kettle-master)4. 在当前workspace中新建工程,名称与刚拷贝的目录名称相同(如pentaho-kettle-master)此时eclipse会自动引入编译时代码目录,暂时不理会编译错误。
5. 在工程目录下新建libs目录(名称可自己自定义),此目录用于存放源码编译依赖的jar包,来源如下:1) 将kettle发行版本中lib
目录下所有jar包复制到新建的libs目录下2) 将kettle发行版本中libswt目录下相应平台的swt.jar复制到新建的libs目录下(请注意jvm版本,如果系统是win64,但jvm是32,则要选择win32下的swt.jar文件)3) 将kettle发行版本中plugins目录下所有插件目录中lib目录下的jar文件复制到新建的libs目录下4) 如要消除import中mockito相关错误,需要下载mockito-all,并复制到新建的libs目录下,参考下载地址
/maven2/org/mockito/mockito-all/1.
9.5/mockito-all-1.9.5.jar6. 在工程属性中java build path部分,libraries标签页下点击add library,选择JUnit并确定。
然后点击add jars,选择libs目录下所有的jar文件(如果未显示libs目录,试试刷新工程再操作),此时基本上编译没
问题了。
7. 源码中单元测试部分可能有冲突的类名,此时在工程属性中java build path部分,source标签页下,排除相应的文件即可。
8. 修改工程目录(源码目录)中的unch文件,重命名为<工程名>.launch,如unch,然后修改内容,将所有
"@@@"替换为工程名,如pentaho-kettle-master9. 在eclipse中刷新工程,右键点击unch,选择run as 工程名,如果工程编译无错误,此时应该可以启动spoon。
10. 在eclipse 工具栏中debug,run中已经有
了相应的launch配置。
至此kettle开发调试环境初步搭建完成。