Java中的堆和栈的区别
java面试题库java面试题目及答案(3篇)

第1篇一、基础知识1. Java简介题目:请简述Java的基本特点。
答案:- 简单易学:Java设计之初就考虑了易学性,使用面向对象编程。
- 原生跨平台:Java通过JVM(Java虚拟机)实现跨平台运行。
- 安全性:Java提供了强大的安全机制,如沙箱安全模型。
- 体系结构中立:Java不依赖于特定的硬件或操作系统。
- 高效:Java的运行速度接近C/C++。
- 多线程:Java内置多线程支持,便于实现并发处理。
- 动态性:Java在运行时可以进行扩展和修改。
2. Java虚拟机题目:请解释Java虚拟机(JVM)的作用。
答案:JVM是Java程序的运行环境,其主要作用包括:- 将Java字节码转换为本地机器码。
- 管理内存,包括堆、栈、方法区等。
- 提供垃圾回收机制。
- 管理线程和同步。
3. Java内存模型题目:请简述Java内存模型的组成。
答案:Java内存模型主要由以下部分组成:- 堆(Heap):存储对象实例和数组。
- 栈(Stack):存储局部变量和方法调用。
- 方法区(Method Area):存储类信息、常量、静态变量等。
- 本地方法栈(Native Method Stack):存储本地方法调用的相关数据。
- 程序计数器(Program Counter Register):存储线程的当前指令地址。
4. Java关键字题目:请列举并解释Java中的几个关键字。
答案:- `public`:表示访问权限为公开。
- `private`:表示访问权限为私有。
- `protected`:表示访问权限为受保护。
- `static`:表示属于类本身,而非对象实例。
- `final`:表示常量或方法不能被修改。
- `synchronized`:表示线程同步。
- `transient`:表示数据在序列化时不会被持久化。
二、面向对象编程5. 类和对象题目:请解释类和对象之间的关系。
答案:类是对象的模板,对象是类的实例。
java模拟面试题目(3篇)

第1篇一、Java基础知识1. 请简述Java语言的特点。
2. 什么是Java虚拟机(JVM)?它有什么作用?3. 什么是Java的内存模型?请解释Java内存模型中的几个关键概念:堆、栈、方法区、程序计数器、本地方法栈。
4. 什么是Java中的反射机制?请举例说明反射在Java中的应用。
5. 什么是Java中的泛型?请解释泛型的原理和作用。
6. 请简述Java中的四种访问控制符:public、protected、default、private。
7. 什么是Java中的继承和多态?请举例说明继承和多态在实际开发中的应用。
8. 什么是Java中的封装?请举例说明封装在实际开发中的应用。
9. 什么是Java中的接口和抽象类?它们之间有什么区别?10. 什么是Java中的异常处理?请解释try-catch-finally语句的执行顺序。
二、Java集合框架1. 请列举Java集合框架中的常用集合类及其特点。
2. 请简述ArrayList、LinkedList、HashMap、HashSet的区别。
3. 什么是Java中的泛型集合?请举例说明泛型集合的应用。
4. 什么是Java中的迭代器(Iterator)和枚举器(Enum)?请比较它们的区别。
5. 什么是Java中的List、Set、Map的遍历方法?6. 请解释Java中的ArrayList和LinkedList的内部实现原理。
7. 什么是Java中的HashMap的扩容机制?8. 什么是Java中的HashSet的内部实现原理?9. 请解释Java中的线程安全集合类,如CopyOnWriteArrayList、ConcurrentHashMap。
三、Java多线程与并发1. 什么是Java中的线程?请解释线程的创建、调度和同步。
2. 请简述Java中的线程状态,如新建、就绪、运行、阻塞、等待、超时等待、终止。
3. 什么是Java中的同步机制?请解释synchronized关键字的作用。
农业银行Java基础面试题

基础测试 基础知识部分: 1.谈谈final, finally, finalize的区别。 final 用于声明属性,方法和类,分别表示属性不可变,方法不可覆盖,类不可继承。 finally 是异常处理语句结构的一部分,表示总是执行。 finalize 是 Object 类的一个方法,在垃圾收集器执行的时候会调用被回收对象的此方法,可以覆盖此方法提供垃圾收集时的其他资源回收,例如关闭文件等。
2.HashM ap和Hashtable的区别。 HashMap 是 Hashtable 的轻量级实现(非线程安全 的实现),他们都完成了 Map 接口,主要区别在于 HashMap 允许空( null )键值( key ) , 由于非线程安全,效率上可能高于 Hashtable 。
HashMap 允许将 null 作为一个 entry 的 key 或者 value ,而 Hashtable 不允许。
HashMap 把 Hashtable 的 contains 方法去掉了,改成 containsvalue 和containsKey 。因为 contains 方法容易让人引起误解。 Hashtable 继承自Dictionary 类,而 HashMap 是 Java1.2 引进的 Map interface 的一个实现。最大的不同是, Hashtable 的方法是 Synchronize 的,而 HashMap 不是,在多个线程访问 Hashtable 时,不需要自己为它的方法实现同步,而 HashMap 就必须为之提供外同步。
Hashtable 和 HashMap 采用的 hash/rehash 算法都大概一样,所以性能不会有很大的差异。 3.public,private,protected,friendly,internal 的作用范围。 private同一个类中 protected同一类中,同一包中,不同包中的该类子类 public同一类中,同一包中,不同包中的该类子类,不同包中的该类的非子类 friendly同一个类中,同一包中 internal 表示在同一个应用程序(Application)或类库(Library)中都可以使用,不过这个我们基本上不用
JVM调优总结

JVM调优总结作者: 和你在一起程序员其实很痛苦的,每隔一段时间就会听到、看到很多很多新名词、新技术---囧.幸而有了互联网,有了开源、有了wiki、有了分享:)—人人为我,我为人人。
拓荒者走过的时候很痛苦,但是如果能给后来人留下点路标,是不是可以让他们少走一些弯路呢?踏着前辈的足迹我走到了这里,也应该为后来的人留下点东西。
走夜路其实不可怕,可怕的是一个人走夜路:) - 做最棒的软件开发交流社区A-PDF Number Pro DEMO: Purchase from to remove the watermark目 录1. java路上1.1 JVM调优总结-序 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .3 1.2 JVM调优总结(一)-- 一些概念 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .4 1.3 JVM调优总结(二)-一些概念 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .7 1.4 JVM调优总结(三)-基本垃圾回收算法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .9 1.5 JVM调优总结(四)-垃圾回收面临的问题 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .12 1.6 JVM调优总结(五)-分代垃圾回收详述1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .14 1.7 JVM调优总结(六)-分代垃圾回收详述2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .18 1.8 JVM调优总结(七)-典型配置举例1 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .26 1.9 JVM调优总结(八)-典型配置举例2 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .31 1.10 JVM调优总结(九)-新一代的垃圾回收算法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .34 1.11 JVM调优总结(十)-调优方法 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .38 1.12 JVM调优总结(十一)-反思 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .47 1.13 JVM调优总结(十二)-参考资料 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . .501.1 JVM调优总结-序发表时间: 2009-11-17几年前写过一篇关于JVM调优的文章,前段时间拿出来看了看,又添加了一些东西。
java必背面试题

.011# 面试题11.为什么要使用static?使用方式: 通过类名调用创建多个对象时,共享一个静态属性和方法,当有一个对象修改了,其他对象使用时,也会改变一个类只能有一个同名的静态属性和静态方法,这样每个对象创建时,就不会再分配额外空间了,存储在方法区(静态区)节省空间。
2. jvm 内存模型有哪些,分别介绍一下?包括: 堆虚拟机栈本地方法栈程序计数器方法区堆:存储对象数组集合存储new出来的东西方法区: 存储类的信息常量(常量池中)静态变量编译器编译后的数据程序计数器: 相当于当前程序制定的字节码行号,指向下一行代码(因为多线程并发,如何实现轮流切换的,是因为每一个线程都会独立有一个程序计数器,可以保证每个线程切换之后,可以回到原来的位置)虚拟机栈: 存放的是每一个栈帧,每一个栈帧对应的一个被调用的方法栈帧包括: 局部变量表操作数栈常量池引用返回地址 .....局部变量表 : 存储局部变量操作数栈 : 程序中所有的计算过程都是它来完成常量池引用: 在方法运行时,用于引用类中的常量返回地址: 当方法被调用时,方法执行结束,还要回到调用的位置所以要保存一个方法返回地址。
本地方法栈:类似于虚拟机栈,只不过虚拟机栈运行是 java 方法,而它是运行native修饰的方法(本地方法)本地方法是操作系统帮你实现的,java只负责调用即可。
3.创建对象的方式有哪些?1.new2. 克隆3.反射4.反序列化调用构造的: 1. new 2. 反射 newInstance() 调用底层无参构造不用构造: 1. 克隆 : 在堆内存直接将已经存在的对象拷贝一份。
2.反序列化: 表示将本地文件生成一个java对象。
克隆:实现一个接口Cloneable 重写clone()User u = new User();User u2 = u.clone();深克隆:如果对象属性中也有引用类型,这些引用类型也需要实现Cloneable接口,重写clone(), 如果不重写克隆出来的对象基本类型可以克隆,引用类型不会克隆,是指向同一个对象4.什么是自动装箱和拆箱?装箱:就是自动将基本类型转换成封装类型拆箱:就是自动将封装类型转成基本类型。
java 技术栈 描述

java 技术栈描述Java技术栈作为当前软件开发领域的重要技能组合,为广大开发者提供了强大的工具和框架。
本文将为您详细描述Java技术栈的相关内容,帮助您更好地理解和掌握这一技术体系。
一、Java技术栈概述Java技术栈是指使用Java编程语言进行软件开发时所涉及的一系列技术、工具和框架。
它涵盖了Java语言本身以及与之相关的各种库、框架、数据库、中间件等。
Java技术栈具有跨平台、高性能、安全稳定等优势,被广泛应用于企业级应用、大数据、云计算、Android开发等领域。
二、Java技术栈核心组成部分1.Java语言:Java技术栈的基础,提供了面向对象编程、泛型、异常处理、多线程等核心特性。
2.Java虚拟机(JVM):Java程序运行的环境,负责加载和执行Java字节码,实现跨平台运行。
3.核心库:Java API,提供了丰富的数据结构、算法、I/O操作、网络编程等功能。
4.开发工具:Eclipse、IntelliJ IDEA等集成开发环境,以及Maven、Gradle等构建工具。
5.框架:Spring、Hibernate、MyBatis等主流框架,简化开发过程,提高开发效率。
6.数据库:MySQL、Oracle、PostgreSQL等关系型数据库,以及MongoDB、Redis等NoSQL数据库。
7.中间件:Tomcat、Jetty等Web服务器,以及RabbitMQ、Kafka等消息中间件。
8.大数据技术:Hadoop、Spark、Flink等大数据处理框架,以及HBase、Cassandra等分布式数据库。
9.云计算:Spring Cloud、Dubbo等微服务框架,以及AWS、阿里云等云平台。
三、Java技术栈的优势与应用1.跨平台:Java技术栈具有跨平台的特性,可以在Windows、Linux、Mac OS等操作系统上运行,降低了开发成本和运维难度。
2.丰富的生态:Java技术栈拥有丰富的开源库、框架和工具,为开发者提供了强大的支持。
数据结构之Heap(Java)
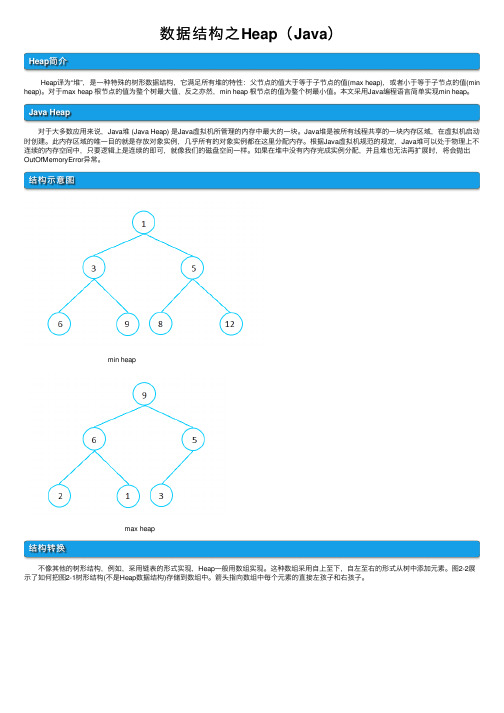
数据结构之Heap(Java)Heap简介 Heap译为“堆”,是⼀种特殊的树形数据结构,它满⾜所有堆的特性:⽗节点的值⼤于等于⼦节点的值(max heap),或者⼩于等于⼦节点的值(min heap)。
对于max heap 根节点的值为整个树最⼤值,反之亦然,min heap 根节点的值为整个树最⼩值。
本⽂采⽤Java编程语⾔简单实现min heap。
Java Heap 对于⼤多数应⽤来说,Java堆 (Java Heap) 是Java虚拟机所管理的内存中最⼤的⼀块。
Java堆是被所有线程共享的⼀块内存区域,在虚拟机启动时创建。
此内存区域的唯⼀⽬的就是存放对象实例,⼏乎所有的对象实例都在这⾥分配内存。
根据Java虚拟机规范的规定,Java堆可以处于物理上不连续的内存空间中,只要逻辑上是连续的即可,就像我们的磁盘空间⼀样。
如果在堆中没有内存完成实例分配,并且堆也⽆法再扩展时,将会抛出OutOfMemoryError异常。
结构⽰意图min heapmax heap结构转换 不像其他的树形结构,例如,采⽤链表的形式实现,Heap⼀般⽤数组实现。
这种数组采⽤⾃上⾄下,⾃左⾄右的形式从树中添加元素。
图2-2展⽰了如何把图2-1树形结构(不是Heap数据结构)存储到数组中。
箭头指向数组中每个元素的直接左孩⼦和右孩⼦。
图2-1 图2-2 仅⽤⼀个数组是不⾜以表⽰⼀个堆,程序在运⾏时的操作可能会超过数组的⼤⼩。
因此我们需要⼀个更加动态的数据结构,满⾜以下特性: 1.我们可以指定数组的初始化⼤⼩。
2.这种数据结构封装了⾃增算法,当程序需要时,能够增加数组的⼤⼩以满⾜需求。
这会使我们联想起ArrayList的实现,正是采⽤这种数据结构。
本⽂就采⽤了ArrayList的⾃增算法。
因为我们使⽤数组,我们需要知道如何计算指定节点(index)的⽗节点、左孩⼦和右孩⼦的索引。
parent index : (index - 1) / 2 left child : 2 * index + 1 right child : 2 * index + 2实现Insertion 为堆设计⼀个插⼊算法很简单,但是我们需要保证每次插⼊过后,依旧满⾜堆的顺序。
Java逃逸分析详解及代码示例

Java逃逸分析详解及代码⽰例概念引⼊我们都知道,Java 创建的对象都是被分配到堆内存上,但是事实并不是这么绝对,通过对Java对象分配的过程分析,可以知道有两个地⽅会导致Java中创建出来的对象并⼀定分别在所认为的堆上。
这两个点分别是Java中的逃逸分析和TLAB(Thread Local Allocation Buffer)线程私有的缓存区。
基本概念介绍逃逸分析,是⼀种可以有效减少Java程序中同步负载和内存堆分配压⼒的跨函数全局数据流分析算法。
通过逃逸分析,Java Hotspot编译器能够分析出⼀个新的对象的引⽤的使⽤范围从⽽决定是否要将这个对象分配到堆上。
在计算机语⾔编译器优化原理中,逃逸分析是指分析指针动态范围的⽅法,它同编译器优化原理的指针分析和外形分析相关联。
当变量(或者对象)在⽅法中分配后,其指针有可能被返回或者被全局引⽤,这样就会被其他过程或者线程所引⽤,这种现象称作指针(或者引⽤)的逃逸(Escape)。
通俗点讲,如果⼀个对象的指针被多个⽅法或者线程引⽤时,那么我们就称这个对象的指针发⽣了逃逸。
Java在Java SE 6u23以及以后的版本中⽀持并默认开启了逃逸分析的选项。
Java的 HotSpot JIT编译器,能够在⽅法重载或者动态加载代码的时候对代码进⾏逃逸分析,同时Java对象在堆上分配和内置线程的特点使得逃逸分析成Java的重要功能。
代码⽰例package me.stormma.gc;/*** <p>Created on 2017/4/21.</p>** @author stormma** @title <p>逃逸分析</p>*/public class EscapeAnalysis {public static B b;/*** <p>全局变量赋值发⽣指针逃逸</p>*/public void globalVariablePointerEscape() {b = new B();}/*** <p>⽅法返回引⽤,发⽣指针逃逸</p>* @return*/public B methodPointerEscape() {return new B();}/*** <p>实例引⽤发⽣指针逃逸</p>*/public void instancePassPointerEscape() {methodPointerEscape().printClassName(this);}class B {public void printClassName(EscapeAnalysis clazz) {System.out.println(clazz.getClass().getName());}}}逃逸分析研究对于 java 编译器有什么好处呢?我们知道 java 对象总是在堆中被分配的,因此 java 对象的创建和回收对系统的开销是很⼤的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Java中的堆和栈的区别
Java中存在栈这样一个后进先出(Last In First Out)的顺序的数据结构,这就是
java.util.Stack。
事实上,堆和栈都是内存中的一部分,有着不同的作用,而且一个程序需要在这
片区域上分配内存。众所周知,所有的Java程序都运行在JVM虚拟机内部,我们这
里介绍的自然是JVM(虚拟)内存中的堆和栈。
区别:
java中堆和栈的区别自然是面试中的常见问题,下面几点就是其具体的区别。
各司其职
最主要的区别就是栈内存用来存储局部变量和方法调用。 堆内存用来存储
Java中的对象。无论是成员变量,局部变量,还是类变量,它们指向的对象都存储在
堆内存中。
独有还是共享
栈内存归属于单个线程,每个线程都会有一个栈内存,其存储的变量只能在其所
属线程中可见,即栈内存可以理解成线程的私有内存。 堆内存中的对象对所有线
程可见,堆内存中的对象可以被所有线程访问。
异常错误
如果栈内存没有可用的空间存储方法调用和局部变量,JVM会抛出
java.lang.StackOverFlowError; 如果是堆内存没有可用的空间存储生成的对象,
JVM会抛出java.lang.OutOfMemoryError。
空间大小
栈的内存要远远小于堆内存,如果你使用递归的话,那么你的栈很快就会充满。
如果递归没有及时跳出,很可能发生StackOverFlowError问题。 可以通过-Xss
选项设置栈内存的大小;
-Xms选项可以设置堆的开始时的大小;
-Xmx选项可以设置堆的最大值。
这就是Java中堆和栈的区别。理解好这个问题的话,可以对你解决开发中的问
题,分析堆内存和栈内存使用,甚至性能调优都有帮助。