模式分类之关于分类器错误率的估计问题
模式识别习题及答案

模式识别习题及答案第⼀章绪论1.什么是模式具体事物所具有的信息。
模式所指的不是事物本⾝,⽽是我们从事物中获得的___信息__。
2.模式识别的定义让计算机来判断事物。
3.模式识别系统主要由哪些部分组成数据获取—预处理—特征提取与选择—分类器设计/ 分类决策。
第⼆章贝叶斯决策理论1.最⼩错误率贝叶斯决策过程答:已知先验概率,类条件概率。
利⽤贝叶斯公式得到后验概率。
根据后验概率⼤⼩进⾏决策分析。
2.最⼩错误率贝叶斯分类器设计过程答:根据训练数据求出先验概率类条件概率分布利⽤贝叶斯公式得到后验概率如果输⼊待测样本X ,计算X 的后验概率根据后验概率⼤⼩进⾏分类决策分析。
3.最⼩错误率贝叶斯决策规则有哪⼏种常⽤的表⽰形式答:4.贝叶斯决策为什么称为最⼩错误率贝叶斯决策答:最⼩错误率Bayes 决策使得每个观测值下的条件错误率最⼩因⽽保证了(平均)错误率最⼩。
Bayes 决策是最优决策:即,能使决策错误率最⼩。
5.贝叶斯决策是由先验概率和(类条件概率)概率,推导(后验概率)概率,然后利⽤这个概率进⾏决策。
6.利⽤乘法法则和全概率公式证明贝叶斯公式答:∑====m j Aj p Aj B p B p A p A B p B p B A p AB p 1)()|()()()|()()|()(所以推出贝叶斯公式7.朴素贝叶斯⽅法的条件独⽴假设是(P(x| ωi) =P(x1, x2, …, xn | ωi)= P(x1| ωi) P(x2| ωi)… P(xn| ωi))8.怎样利⽤朴素贝叶斯⽅法获得各个属性的类条件概率分布答:假设各属性独⽴,P(x| ωi) =P(x1, x2, …, xn | ωi) = P(x1| ωi) P(x2| ωi)… P(xn| ωi)后验概率:P(ωi|x) = P(ωi) P(x1| ωi) P(x2| ωi)… P(xn| ωi)类别清晰的直接分类算,如果是数据连续的,假设属性服从正态分布,算出每个类的均值⽅差,最后得到类条件概率分布。
《模式识别》线性分类器设计实验报告
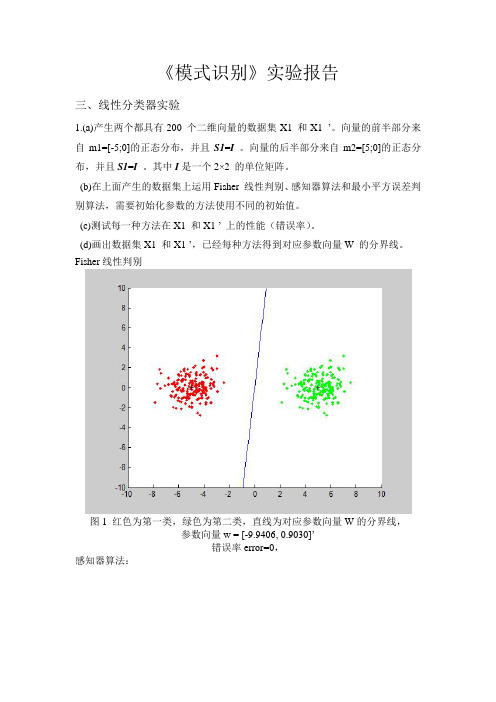
《模式识别》实验报告三、线性分类器实验1.(a)产生两个都具有200 个二维向量的数据集X1 和X1 ’。
向量的前半部分来自m1=[-5;0]的正态分布,并且S1=I 。
向量的后半部分来自m2=[5;0]的正态分布,并且S1=I。
其中I是一个2×2 的单位矩阵。
(b)在上面产生的数据集上运用Fisher 线性判别、感知器算法和最小平方误差判别算法,需要初始化参数的方法使用不同的初始值。
(c)测试每一种方法在X1 和X1 ’ 上的性能(错误率)。
(d)画出数据集X1 和X1 ’,已经每种方法得到对应参数向量W 的分界线。
Fisher线性判别图1 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数向量w = [-9.9406, 0.9030]’错误率error=0,感知器算法:图2 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1;0.1];迭代次数iter=2参数向量w = [-4.8925, 0.0920]’错误率error=0图3 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];迭代次数iter=2参数向量w = [-3.9925, 0.9920]’错误率error=0图4 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[10; 10];迭代次数iter=122参数向量w = [-5.6569, 7.8096]’错误率error=0图5 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 50];迭代次数iter=600参数向量w = [-27.0945, 37.4194]’错误率error=0图6 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[50; 100];迭代次数iter=1190参数向量w = [-54.0048, 74.5875]’错误率error=0最小平方误差判别算法:图7 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.1; 0.1];参数向量w = [-0.1908, -0.0001]’错误率error=0图8 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[0.5; 0.5];参数向量w = [-0.1924, 0.1492]’错误率error=0图9 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 0.5];参数向量w = [-0.1914, 0.0564]’错误率error=0图10 红色为第一类,绿色为第二类,直线为对应参数向量W的分界线,参数的初始值为[1; 1];参数向量w = [-0.1943, 0.3359]’错误率error= 0.00502.重复1.中的实验内容,数据集为X2 和X2 ’。
模式识别与数据挖掘期末总结

模式识别与数据挖掘期末总结第一章概述1.数据分析是指采用适当的统计分析方法对收集到的数据进行分析、概括和总结,对数据进行恰当地描述,提取出有用的信息的过程。
2.数据挖掘(Data Mining,DM) 是指从海量的数据中通过相关的算法来发现隐藏在数据中的规律和知识的过程。
3.数据挖掘技术的基本任务主要体现在:分类与回归、聚类、关联规则发现、时序模式、异常检测4.数据挖掘的方法:数据泛化、关联与相关分析、分类与回归、聚类分析、异常检测、离群点分析、5.数据挖掘流程:(1)明确问题:数据挖掘的首要工作是研究发现何种知识。
(2)数据准备(数据收集和数据预处理):数据选取、确定操作对象,即目标数据,一般是从原始数据库中抽取的组数据;数据预处理一般包括:消除噪声、推导计算缺值数据、消除重复记录、完成数据类型转换。
(3)数据挖掘:确定数据挖掘的任务,例如:分类、聚类、关联规则发现或序列模式发现等。
确定了挖掘任务后,就要决定使用什么样的算法。
(4)结果解释和评估:对于数据挖掘出来的模式,要进行评估,删除冗余或无关的模式。
如果模式不满足要求,需要重复先前的过程。
6.分类(Classification)是构造一个分类函数(分类模型),把具有某些特征的数据项映射到某个给定的类别上。
7.分类过程由两步构成:模型创建和模型使用。
8.分类典型方法:决策树,朴素贝叶斯分类,支持向量机,神经网络,规则分类器,基于模式的分类,逻辑回归9.聚类就是将数据划分或分割成相交或者不相交的群组的过程,通过确定数据之间在预先指定的属性上的相似性就可以完成聚类任务。
划分的原则是保持最大的组内相似性和最小的组间相似性10.机器学习主要包括监督学习、无监督学习、半监督学习等1.(1)标称属性(nominal attribute):类别,状态或事物的名字(2):布尔属性(3)序数属性(ordinal attribute):尺寸={小,中,大},军衔,职称【前面三种都是定性的】(4)数值属性(numeric attribute): 定量度量,用整数或实数值表示●区间标度(interval-scaled)属性:温度●比率标度(ratio-scaled)属性:度量重量、高度、速度和货币量●离散属性●连续属性2.数据的基本统计描述三个主要方面:中心趋势度量、数据分散度量、基本统计图●中心趋势度量:均值、加权算数平均数、中位数、众数、中列数(最大和最小值的平均值)●数据分散度量:极差(最大值与最小值之间的差距)、分位数(小于x的数据值最多为k/q,而大于x的数据值最多为(q-k)/q)、说明(特征化,区分,关联,分类,聚类,趋势/跑偏,异常值分析等)、四分位数、五数概括、离群点、盒图、方差、标准差●基本统计图:五数概括、箱图、直方图、饼图、散点图3.数据的相似性与相异性相异性:●标称属性:d(i,j)=1−m【p为涉及属性个数,m:若两个对象匹配为1否则p为0】●二元属性:d(i,j)=p+nm+n+p+q●数值属性:欧几里得距离:曼哈顿距离:闵可夫斯基距离:切比雪夫距离:●序数属性:【r是排名的值,M是排序的最大值】●余弦相似性:第三章数据预处理1.噪声数据:数据中存在着错误或异常(偏离期望值),如:血压和身高为0就是明显的错误。
模式识别大作业
作业1 用身高和/或体重数据进行性别分类(一)基本要求:用和的数据作为训练样本集,建立Bayes分类器,用测试样本数据对该分类器进行测试。
调整特征、分类器等方面的一些因素,考察它们对分类器性能的影响,从而加深对所学内容的理解和感性认识。
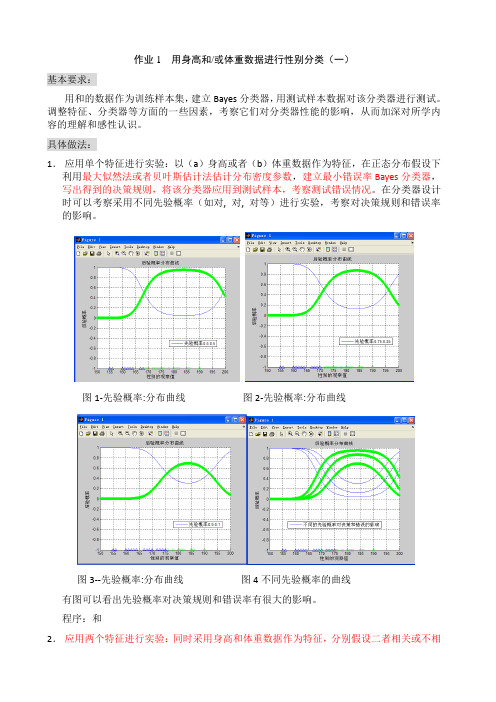
具体做法:1.应用单个特征进行实验:以(a)身高或者(b)体重数据作为特征,在正态分布假设下利用最大似然法或者贝叶斯估计法估计分布密度参数,建立最小错误率Bayes分类器,写出得到的决策规则,将该分类器应用到测试样本,考察测试错误情况。
在分类器设计时可以考察采用不同先验概率(如对, 对, 对等)进行实验,考察对决策规则和错误率的影响。
图1-先验概率:分布曲线图2-先验概率:分布曲线图3--先验概率:分布曲线图4不同先验概率的曲线有图可以看出先验概率对决策规则和错误率有很大的影响。
程序:和2.应用两个特征进行实验:同时采用身高和体重数据作为特征,分别假设二者相关或不相关(在正态分布下一定独立),在正态分布假设下估计概率密度,建立最小错误率Bayes 分类器,写出得到的决策规则,将该分类器应用到训练/测试样本,考察训练/测试错误情况。
比较相关假设和不相关假设下结果的差异。
在分类器设计时可以考察采用不同先验概率(如vs. , vs. , vs. 等)进行实验,考察对决策和错误率的影响。
训练样本female来测试图1先验概率vs. 图2先验概率vs.图3先验概率vs. 图4不同先验概率对测试样本1进行试验得图对测试样本2进行试验有图可以看出先验概率对决策规则和错误率有很大的影响。
程序和3.自行给出一个决策表,采用最小风险的Bayes决策重复上面的某个或全部实验。
W1W2W10W20close all;clear all;X=120::200; %设置采样范围及精度pw1=;pw2=; %设置先验概率sample1=textread('') %读入样本samplew1=zeros(1,length(sample1(:,1)));u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布figure(1);subplot(2,1,1);plot(X,y1);title('F身高类条件概率分布曲线');sample2=textread('') %读入样本samplew2=zeros(1,length(sample2(:,1)));u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布subplot(2,1,2);plot(X,y2);title('M身高类条件概率分布曲线');P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);figure(2);subplot(2,1,1);plot(X,P1);title('F身高后验概率分布曲线');subplot(2,1,2);plot(X,P2);title('M身高后验概率分布曲线');P11=pw1*y1;P22=pw2*y2;figure(3);subplot(3,1,1);plot(X,P11);subplot(3,1,2);plot(X,P22);subplot(3,1,3);plot(X,P11,X,P22);sample=textread('all ') %读入样本[result]=bayes(sample1(:,1),sample2(:,1),pw1,pw2);%bayes分类器function [result] =bayes(sample1(:,1),sample2(:,1),pw1,pw2);error1=0;error2=0;u1=mean(sample1(:,1));m1=std(sample1(:,1));y1=normpdf(X,u1,m1); %类条件概率分布u2=mean(sample2(:,1));m2=std(sample2(:,1));y2=normpdf(X,u2,m2); %类条件概率分布P1=pw1*y1./(pw1*y1+pw2*y2);P2=pw2*y2./(pw1*y1+pw2*y2);for i = 1:50if P1(i)>P2(i)result(i)=0;pe(i)=P2(i);elseresult(i)=1;pe(i)=P1(i);endendfor i=1:50if result(k)==0error1=error1+1;else result(k)=1error2=error2+1;endendratio = error1+error2/length(sample); %识别率,百分比形式sprintf('正确识别率为%.2f%%.',ratio)作业2 用身高/体重数据进行性别分类(二)基本要求:试验直接设计线性分类器的方法,与基于概率密度估计的贝叶斯分离器进行比较。
adaboost例题

adaboost例题AdaBoost(Adaptive Boosting)是一种集成学习方法,通过反复迭代训练多个弱分类器,最终得到一个强分类器。
下面我们来看一个AdaBoost的例题。
假设我们有一个数据集,包含100个样本和两个特征,目标变量为二分类问题。
我们希望使用AdaBoost算法来训练一个分类器,能够对新样本进行准确的分类。
首先,我们随机初始化样本的权重,假设每个样本的初始权重都为1/100。
然后,我们开始迭代训练弱分类器。
在第一次迭代中,我们使用第一个弱分类器来训练样本。
弱分类器在训练时会根据样本权重来调整权重,以更加关注被错误分类的样本。
训练完成后,我们计算出分类器的错误率,并根据错误率来更新样本权重。
在第二次迭代中,我们使用第二个弱分类器来训练样本。
同样地,训练完后我们计算错误率并更新样本权重。
迭代过程持续进行,直到达到预设的迭代次数或错误率达到某个阈值。
最后,将所有弱分类器的权重相加,得到最终的分类器。
AdaBoost算法的特点是能够逐渐提升分类器的性能,并且对于弱分类器的选择没有特别的限制,可以使用任意的分类算法作为弱分类器。
除了二分类问题,AdaBoost也可以用于多分类问题和回归问题。
在多分类问题中,可以使用一对多的方式来训练多个分类器。
在回归问题中,可以将AdaBoost算法应用于基于树的回归模型。
总结起来,AdaBoost是一种强大的集成学习算法,通过迭代训练多个弱分类器,能够得到一个准确性能较高的强分类器。
它在实际应用中取得了很好的效果,被广泛应用于各种机器学习问题中。
模式识别(山东联盟)知到章节答案智慧树2023年青岛大学

模式识别(山东联盟)知到章节测试答案智慧树2023年最新青岛大学第一章测试1.关于监督模式识别与非监督模式识别的描述正确的是参考答案:非监督模式识别对样本的分类结果是唯一的2.基于数据的方法适用于特征和类别关系不明确的情况参考答案:对3.下列关于模式识别的说法中,正确的是参考答案:模式可以看作对象的组成成分或影响因素间存在的规律性关系4.在模式识别中,样本的特征构成特征空间,特征数量越多越有利于分类参考答案:错5.在监督模式识别中,分类器的形式越复杂,对未知样本的分类精度就越高参考答案:错第二章测试1.下列关于最小风险的贝叶斯决策的说法中正确的有参考答案:最小风险的贝叶斯决策考虑到了不同的错误率所造成的不同损失;最小错误率的贝叶斯决策是最小风险的贝叶斯决策的特例;条件风险反映了对于一个样本x采用某种决策时所带来的损失2.我们在对某一模式x进行分类判别决策时,只需要算出它属于各类的条件风险就可以进行决策了。
参考答案:对3.下面关于贝叶斯分类器的说法中错误的是参考答案:贝叶斯分类器中的判别函数的形式是唯一的4.当各类的协方差矩阵相等时,分类面为超平面,并且与两类的中心连线垂直。
参考答案:错5.当各类的协方差矩阵不等时,决策面是超二次曲面。
参考答案:对第三章测试1.概率密度函数的估计的本质是根据训练数据来估计概率密度函数的形式和参数。
参考答案:对2.参数估计是已知概率密度的形式,而参数未知。
参考答案:对3.概率密度函数的参数估计需要一定数量的训练样本,样本越多,参数估计的结果越准确。
参考答案:对4.下面关于最大似然估计的说法中正确的是参考答案:最大似然估计是在已知概率密度函数的形式,但是参数未知的情况下,利用训练样本来估计未知参数。
;在最大似然估计中要求各个样本必须是独立抽取的。
;在最大似然函数估计中,要估计的参数是一个确定的量。
5.贝叶斯估计中是将未知的参数本身也看作一个随机变量,要做的是根据观测数据对参数的分布进行估计。
机器学习试卷——XXX

机器学习试卷——XXX一、判断题1)F 极大似然估计不一定是无偏估计,也不一定是方差最小的无偏估计,但是在大样本情况下,极大似然估计通常是渐进无偏的。
2)T 简单的模型比复杂的模型更容易泛化,因此在测试集上表现更好。
3)F 全局线性回归只需要利用部分样本点来预测新输入的对应输出值,而局部线性回归需要利用查询点附近的全部样本来预测输出值,因此局部线性回归的计算代价更高。
4)F Boosting算法容易过拟合,需要采用一些措施来防止过拟合。
5)T6)T7)T8)F ICA方法对于非高斯分布的数据更有效。
9)F 回归问题属于监督研究的一种方法。
10)T二、考虑一个二分类器问题(Y为1或0),每个训练样本X有两个特征X1、X2(取值为1或0)。
给出P(Y=0)=P(Y=1)=0.5,条件概率如下表。
分类器预测的结果错误的概率为期望错误率,Y是样本类别的实际值,Y'(X1,X2)为样本类别的预测值,那么期望错误率为:0.251)给出X1,X2的所有可能值,使用贝叶斯分类器预测结果,填写下表:X1 X2 P(X1,X2,Y=0) P(X1,X2,Y=1) Y'(X1,X2)1 1 0.1 0.2 11 0 0.2 0.1 00 1 0.1 0.2 10 0 0.2 0.1 02)计算给定特征(X1,X2)预测Y的期望错误率,假设贝叶斯分类器从无限的训练样本中研究所得。
期望错误率为0.2.3)下面哪个有更小的期望错误率?a、仅仅给出X1,采用XXX分类器预测Y。
b、仅仅给出X2,采用XXX分类器预测Y。
答:b 更简单的特征更容易泛化,因此使用X2更容易得到更小的期望错误率。
4)给出一个新的特征X3,X3的与X2保持完全相同,现在计算给定(X1,X2,X3)采用贝叶斯分类器预测Y的期望错误率,假设分类器从无限的训练数据中研究所得。
期望错误率不会改变,仍为0.2.5)使用贝叶斯分类器会产生什么问题,为什么?贝叶斯分类器假设特征之间是独立的,但实际上很多情况下特征之间是相关的,这会导致贝叶斯分类器的性能下降。
模式识别_青岛大学中国大学mooc课后章节答案期末考试题库2023年

模式识别_青岛大学中国大学mooc课后章节答案期末考试题库2023年1.贝叶斯决策是通过计算样本后验概率的大小来进行决策的,下面表达式中wi代表类别,x代表样本,能够表示后验概率的是答案:P(wi|x)2.下列表达中不能影响贝叶斯估计结果的是答案:数据的线性变换3.下列关于感知器算法的说法中错误的是答案:感知器算法也适用于线性不可分的样本4.下面关于BP神经网络的说法错误的是答案:BP算法由误差的正向传播和数据的反向传播两个过程构成。
5.在利用神经网络进行分类时,神经网络的输入节点的个数______输入的特征数量。
答案:等于6.下面不能用来度量概率距离的参数是答案:欧式距离7.下面关于错误率的说法中错误的是答案:在实际当中,人们主要采用理论分析的方法来评价监督模式识别系统中分类器的错误率。
8.下面关于BP神经网络的说法错误的是答案:BP算法由误差的正向传播和数据的反向传播两个过程构成。
9.下面关于熵的说法中,错误的是答案:熵表示不确定性,熵越小不确定性越大。
10.下面关于PCA算法的说法中错误的是答案:PCA算法是通过变换矩阵得到原有特征的线性组合,新特征之间是线性相关的。
11.下列属于监督模式识别的是答案:字符识别人脸识别车牌识别12.基于最小错误率的贝叶斯决策规则可以采用不同的形式,下列能表达其决策规则的是答案:似然比后验概率类条件概率13.下面关于最大似然估计的说法中正确的是答案:最大似然估计是在已知概率密度函数的形式,但是参数未知的情况下,利用训练样本来估计未知参数。
在最大似然函数估计中,要估计的参数是一个确定的量。
在最大似然估计中要求各个样本必须是独立抽取的。
14.在基于样本直接设计分类器时,属于分类器设计三要素的是答案:准则函数的形式寻优算法判别函数的类型15.下面关于最小平方误差判别的说法中正确的是答案:在最小平方误差判别中可以使用梯度下降法来求解最小平方误差判别方法中的准则函数是误差长度的平方和。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
标准差 = 10%
例:两个测试样本集的错误率为 95% 和 85%
平均错误率 = 90%
标准差 = 5%
在某些实际应用中,需要计算每一个类的错误率:
该类的错分样本数
类错误率 = 该类的样本总数
例:有一个五类测试集,每一个类有200个样本。
其中四个类全部正确分类,而有一个类错分100
N P (1 ) P ( 2 ) 1, N i NP ( i ) 1 P (1 ) 2 P ( 2 )
[ 1 P (1 ) 1 2 P (1 ) P ( 2 ) 2 P ( 2 )
置信水平
真 实 值
估计值
图的使用方法
(1) 计算出测试样本集的错误率估计值
(2) 已知测试样本集的样本数 N
(3) 找出估计值 与两条标注 N 的曲线的交点
(4) 对应的两个纵轴坐标就是置信区间(ε1 , ε2) , 即真实错误率的范围
0.5, N 10
(1 , 2 ) (0.18, 0.83)
设计集 = 测试集
设计集的参数是真实 参数 测试集的参数是某一 个估计值
0 (θ,θ) 0 (θ N ,θ)
0 (θ N ,θ N ) 0 (θ,θ N )
对它们取期望,则
0 (θ,θ) E[ 0 (θ N ,θ)]
E[ 0 (θ N ,θ N )] E[ 0 (θ,θ N )]
说明: (1) 对于c 类情况,我们只需要将上述连乘与求 和符号中的上限改成 c 即可 (2) 这里我们没有针对一个具体的分类器来讨论,
这些结果同样适合于后面介绍的分类器
3.7.2 关于未设计好分类器时错误率的估计问题
3.7.2.1 基本理论
面临的问题是:在只有有限的 N 个样本的条件下,
我们如何将样本集划分成设计集与测试集,用设计 集来设计分类器,用测试集来估计错误率,同时希
k N k
N k
ln P ( k ) ln C k ln
k N
( N k ) ln(1 )
则 ln P ( k )
N k 0 1 k
得
k ˆ N
k ˆ N
结论:错分样本数 k 与测试集样本总数 N 之比是 错误率 ε 的最大似然估计量
2 2 2 2
P (1 ) 1 P (1 ) 1 P ( 2 ) 2 P ( 2 ) 2 ]
2 2
其中:四个红线部分之和等于0 青颜色部分:
P(1 )1 1 P (1 ) P(1 )1 (1 P(1 )) P(1 ) P(2 )1
2 2 2 2
们倾向于选择方差较小的估计量,其含义是它的 值更加密集地聚集在真实值的附近
两个错误率估计量的比较
' Var[ ] Var[ ]
1 N
[ (1 ) P (1 ) 1 (1 1 ) P ( 2 ) 2 (1 2 )]
1 N1 2 N 2
测试集是随机抽取的,错分样本数 k 是随机变量
k N
它是随机变量 k 的函数,同样
也是随机变量
可以用期望、方差、置信区间来评估错误率估 计量的统计性质
二项分布的期望、方差为:
期望
E (k ) N
Var ( k ) N (1 )
方差
则
ˆ
的期望
k E[ k ] N ˆ) E E ( N N N
望错误率越小越好
针对两类问题,以最小错误率Bayes分类器为 例来分析如何划分样本集,以及如何快速地估
计错误率(减小错误率估计的计算量)
Bayes分类器的似然决策规则
P (1 ) p(x | 1 ) l (x, θ) 1 P (2 ) p(x | 2 )
1 x 2
ln P (k1 , k2 ) k1 N1 k1 0 1 1 1 1
ln P (k1 , k2 ) k2 N 2 k2 0 2 2 1 2
1
k1 N1
2
k2 N2
总错误率的估计
k1 k2 1 NP (1 ) 2 NP (2 ) N N N 2 1 P (1 ) 2 P ( 2 ) i P ( i ) ' N2
无偏估计量
方差
k Var[k ] ˆ ] Var Var[ 2 N N N (1 ) (1 ) 2 N N
随着 N 的增大而减小
95%置信系数下的置信区间(ε1 , ε2) 与 ˆ 和N 的 关系
P (1 2 ) 1 /100 0.95
[ P(1 ) P(2 )(1 2 ) ] 0
1 N 2
结论:选择性抽样时错误率的方差更小,其原因是 利用了先验信息
结论
错误率的估计量是最大似然估计意义下的最好 估计 错误率估计是无偏估计量。选择性抽样错误率
的方差更小。 随着样本数的增加,其置信区间(真实错误率
的范围)将减小
假设从 N 个实际样本得到的估计值
0 (θ,θ) 0 (θ,θ)
θN
0 (θ,θ) 0 (θ N ,θ)
具体值代入
设计集的参数是某一个估计值 测试集的参数是真实参数
0 (θ,θ) 0 (θ,θ)
0 (θ N ,θ N ) 0 (θ,θ N )
错误率=0.45
N=10(红色) N=100(绿色)
结果:随着样本数目的增加,置信区间(真实错 误率的范围)将变小
错误率 = 0.00
N=50, 真实错误率 < 0.08 N=250,真实错误率 < 0.02
2 先验概率已知的选择性抽样
当我们已知两类( ω1,ω2 )的先验概率 P(ω1) 和 P(ω2),可以从两个类别的总体中分别抽取
机抽样
对于 N 个样本的测试集,结果出现了 k 个错分样 本,此时 k 是一个随机变量
假设真实的错误率为 ε ,k 的密度函数满足二
项分布
P(k ) C (1 )
k N k
N k
N! C k !( N k )!
k N
ε 的最大似然估计: max lnP (k )
P(k ) C (1 )
其中,θ 是概率密度函数中的参数
对于一个实际问题,θ 是未知的,只能用样本集 的估计量
ˆ θ
来代替
我们可以用设计集和测试集分别估计出两个估
计量
θ1 ,θ2
θ1 ,θ2
都有关
因为我们利用设计集的估计量来计算测试集错 误率,所以分类器的错误率与
记测试集的错误率为 0 (θ1 ,θ 2 )
N1= P(ω1) N
N2= P(ω2) N 个样本(其中N = N1 + N2)作为测试集,这种样
本抽取方法称为选择性抽样
设 k1 和 k2 分别是 ω1,ω2 类的错分样本数,它们是
随机变量、并且相互独立,因此它们的联合概率为
ki ki N i ki P ( k1 , k2 ) P ( k1 ) P ( k2 ) C N (1 ) i i i i 1
(1) 错误率估计量是不是最好的?
(2) 估计量具有什么样的统计性质?
(3) 当考试样本增加时,估计量是否有改善?
针对两类问题,分两种情况来讨论这三个问题:
1 先验概率未知的随机抽样
2 先验概率已知的选择性抽样
1 先验概率未知的随机抽样
当我们不知道两类的先验概率时,只能随机抽取
N 个样本作为测试集,这种样本抽取方法称为随
标准差 =
1 M
2 ( e e ) i av i 1
M
第 i 个样本集的错误率 结果的表示:平均错误率 ± 标准差
平均错误率
说明: (1) 对训练集与测试集,都可以计算错误率、平
均错误率、标准差
(2) 三个指标越小越好
(3) 有时也使用正确率或者精度的概念
正确率= 1-错误率
例:两个测试样本集的错误率为 100% 和 80%
3.7 关于分类器错误率的估计问题
讨论的问题是: 如何利用样本集来估计错误率?
样本集分成两种: 检验(考试、测试)(样本)集:只用于估计分
类器错误率的样本集 训练(设计、学习)(样本)集:只用于设计分
类器的样本集 说明:两个集合不应该有相同的样本
对于已经设计好的分类器,我们只需要用测
试集来估计错误率 对于未设计好的分类器,我们要用设计集来
个样本。则总的错误率为 100/1000 = 10.00%,四
个类的类错误率为0.00%,一个类的类错误率为
50.00%
3.7.1 关于已设计好分类器时错误率的估
计问题
3.7.2 关于未设计好分类器时错误率的估 计问题
3.7.1 关于已设计好分类器时错误率的估计问题 关于测试集的错误率,讨论三个问题:
2
其中, εi 是 ωi 类的真实错误率
用最大似然法求εi 的估计量
ki ki N i ki P ( k1 , k2 ) C N (1 ) i i i i 1
2
2
ki ln P (k1 , k2 ) ln C N ki ln i ( N i ki )ln(1 i ) i i 1
从理论上来说,Bayes分类器可以是错误率达到 最小。但是,对于具体的问题,还需要检查设
计集的参数、测试集的参数、真实参数是否相 等