大数据分析工具 rapidminer 操作实践
大数据分析工具 rapidminer 操作实践

大数据+机器学习
支持向量机 决策树 贝叶斯 关联聚类 深度学习 神经网络
Machine Learning
回归
分布式机器学习
这张大数据领域知识架构网络图中,黄色部分代表着领域的前沿。解读网络图可知, 机器学习在大数据分析领域中的应用,激活了之前几个独立的应用领域,使得大数 据具备了自主学习能力,在预测分析与逆向检验方面取得快速发展。
通过往届球员身体素质样本数据,利用BP人 工神经网络进行大数据分析,在隐藏层中建立 了人类难以直接理解的目标特征属性(这是与 决策树算法中明显的判别标准截然不同的), 来预测一批新球员谁能够成为世界巨星。
BP神经网络的计算过程由正向计算和 反向计算组成。正向传播,输入模式 从输入层经隐藏层逐层处理,传向输 出层,每一层神经元的状态只影响下 一层神经元的状态。如果在输出层不 能得到期望的输出,则转入反向传播, 将误差信号沿原来的连接通路返回, 通过修改各神经元的权值,使得误差 信号最小。
是否周末 是 否 是否有促销 坏 是否有促销 是 高 否 低 好 高 是 天气 坏 低 否 低
决策树是对测试 集目标进行预测 的逻辑判断依据 概率判断结果
天气 好 高
人工神经网络 ANNs
人工神经网络(Artificial Neural Networks,ANNs),是模拟生物神 经网络进行信息处理的一种数学模 型。它以对大脑的生理研究成果为 基础,其目的在于模拟大脑的某些 机理与机制,实现一些特定的功能。
深度学习
深度学习算法计算结果 BP算法计算结果
深层神经网络
BP神经网络 在相同样本训练下,利用深层神经网络来进行 预测相较于BP算法结果存在明显的差异。 将大数据分析与深度学习相结合是时下最热门 的研究主题。
RapidMiner实验报告
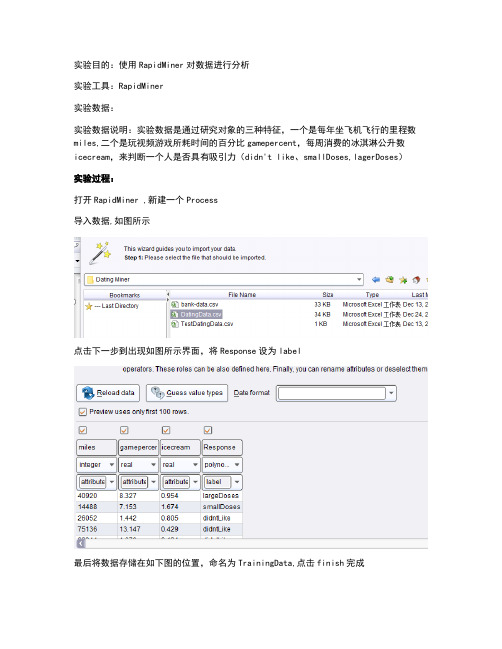
实验目的:使用RapidMiner对数据进行分析实验工具:RapidMiner实验数据:实验数据说明:实验数据是通过研究对象的三种特征,一个是每年坐飞机飞行的里程数miles,二个是玩视频游戏所耗时间的百分比gamepercent,每周消费的冰淇淋公升数icecream,来判断一个人是否具有吸引力(didn't like、smallDoses,lagerDoses)实验过程:打开RapidMiner ,新建一个Process导入数据,如图所示点击下一步到出现如图所示界面,将Response设为label最后将数据存储在如下图的位置,命名为TrainingData,点击finish完成将数据TrainingData拖拽到process窗口中,用线连接至result接口,可以看到如下数据其中有些Response的值丢失了,共有31个这时需要使用Filter Examples 过滤掉没有值得Response行,操作如下图数据筛选完成之后,选择Decision Tree Model,拖入到process中,连接起来,参数选择默认设置训练好模型之后,我们可以用模型预测一下TrainingData中没有标记的样例,与上面的数据过滤方法相同,只是设置有所不同,如下图使用Apply Model来运用模型整个连接图如下所示实验的预测结果部分决策树截图如图,加入一个Validation其参数如下图,默认的10表示将样例分为十份,取一份作为测试数据双击Validation右下角的矩形表框进入,建议决策树模型,应用模型退出Validation 如图连接到result运行输出结果如下上图显示准确率为96%左右,正负误差为%,表明训练所得模型是比较稳定的实验总结1.我在这个过程中运用的测试集与训练集是相同的,这可能会使整个模型的预测能力比实际要偏大2.该实验的难点是数据源的收集与筛选,选择什么样的数据,需要怎样的处理才有意义是不容易的3.模型算子的选择对于我来说比较难,因为对这个是不熟悉的,所以基本上所有的参数都是默认的,这个感觉不太好4.对结果的分析不是很明白。
rapidminer 数据导入及几个算子简单应用

rapidminer 数据导入及几个算子简单应用
2014年09月05日⁄综合⁄共 562字⁄字号小中大⁄评论关闭
一、数据集选择
本次实验选择的数据集为: bank-data.csv 其中有600条数据结构如下图:
二、数据集文件格式转换
Rapidminer 支持的导入数据格式有如下图所示:
所以我们需要把下载的数据集文件格式进行转换,由于本次实验下载的文件本身已是csv格式,此处不做任何操作。
三、数据集的导入保存
1:选择 import csv file
2:选择 Next
3:选择 Next
4:选择 Next
5:选择 Next
6:选择 Finish, 完成导入数据
7:查看目录中生成的导入数据
四、流程创建及简单算子测试
1:选择 FileàNew Process 即可创建一个空白流程:2:将上述中导入的数据拖放到流程中并链接:
运行查看结果:
2:sample算子使用
在Data Transformation 中选择 sample 算子拖到流程中:此处设置选择100条数据
运行,查看结果:
3: 在Data Transformation 中选择 sort 算子拖到流程中:此处设置以income属性进行升序排序:
运行查看结果:
4: 在Data Transformation 中选择 selection 算子拖到流程中:此处选择4个属性:
运行查看结果:
5: 在Data Transformation 中选择 filterexample 算子拖到流程中:此处过滤掉年龄小于30岁的数据:
运行查看结果:。
rapidminer的使用方法和流程

rapidminer的使用方法和流程一、快速介绍RapidMiner是一款强大的数据挖掘和数据分析工具,它提供了丰富的功能和易用的界面,使得用户能够快速地进行数据预处理、特征提取、模型训练和评估等操作。
本文档将详细介绍RapidMiner的使用方法和流程,帮助用户更好地掌握这款工具。
二、安装和配置1. 下载并安装RapidMiner软件:访问RapidMiner官方网站,下载适合您操作系统的安装包,并按照安装向导进行安装。
2. 配置环境变量:确保RapidMiner的路径被正确添加到系统环境变量中,以便系统能够找到并使用它。
3. 启动RapidMiner:打开RapidMiner软件,您将看到一个简洁的界面,其中包括各种可用的操作节点。
三、使用流程1. 数据准备:使用数据源节点导入数据,并进行必要的预处理操作,如清洗、转换等。
2. 特征提取:使用各种特征提取节点,如数值编码、聚类、分箱等,对数据进行特征提取。
3. 模型训练:使用适合您的算法和模型类型,如决策树、支持向量机、神经网络等,进行模型训练。
4. 模型评估:使用各种评估指标,如准确率、精度、召回率等,对模型进行评估和调整。
5. 结果展示:使用可视化节点将结果进行展示和导出,以便进一步分析和应用。
四、常见问题及解决方案1. 数据格式不正确:检查您的数据文件是否符合RapidMiner的输入要求,并进行必要的格式转换。
2. 节点无法连接:检查网络连接和节点配置,确保节点之间能够正常通信。
3. 算法或模型选择错误:根据您的数据和任务需求,选择适合的算法和模型,并进行必要的参数调整。
4. 结果不准确:检查评估指标是否合理,并进行必要的调整和优化。
五、进阶技巧1. 使用脚本进行自动化操作:通过编写脚本,实现数据的批量处理和模型的批量训练,提高工作效率。
2. 使用模型选择方法:根据评估指标和交叉验证结果,选择最佳的模型进行预测和分析。
3. 利用并行处理加速运算:利用RapidMiner的并行处理功能,加速模型的训练和评估过程。
数据挖掘RapidMiner工具使用

数据挖掘RapidMiner工具使用这里以学校的学生成绩进行聚类分析为案例1、背景随着我国经济的发展,网络已被应用到各个行业,人们对网络带来的高效率越来越重视,然而大量数据信息给人们带来方便的同时,也随之带来了许多新问题,大量数据资源的背后隐藏着许多重要的信息,人们希望能对其进行更深入的分析,以便更好地利用这些数据,从中找出潜在的规律。
那么,如何从大量的数据中提取并发现有用信息以提供决策的依据,已成为一个新的研究课题。
目前普遍使用的成绩分析方法一般只能得到均值、方差等一类信息,且仅仅是从一门课程独立数据进行的分析,但在实际教学中,比如学生在学习某一门课程时,是哪一门或者几门课程对其影响很大,包括教学以外的哪些因素对学生成绩造成了较大的影响等各种有价值的信息往往无法获知。
2、聚类分析在数据库中的知识发现和数据挖掘(KDDM)受到目前人工智能与数据库界的广泛重视。
KDDM的目的是从海量的数据中提取人们感兴趣的、有价值的知识和重要的信息,聚类则是KDDM领域中的一个重要分支。
所谓聚类是将物理或抽象的集合分组成为类似的对象组成的多个类的过程。
聚类分析就是将一组数据分组,使其具有最大的组内相似性和最小的组间相似性。
简单的说就是达到不同聚类中的数据尽可能不同,而同一聚类中的数据尽可能相似,它与分类不同,分类是对于目标数据库中存在哪些类这一信息是知道的,所要做的就是将每一条记录分别属于哪一类标记出来;而聚类是在预先不知道目标数据库到底有多少类的情况下,希望将所有的记录组成不同的簇或者说“聚类”,并且使得在这种分类情况下,以某种度量为标准的相似性,在同一聚类之间最小化,而在不同聚类之间最大化。
事实上,聚类算法中很多算法的相似性都基于距离而且由于现实数据库中数据类型的多样性,关于如何度量两个含有非数值型字段的记录之间的距离的讨论有很多,并提出了相应的算法。
聚类分析的算法可以分为以下几类:划分方法、层次方法、基于密度方法等。
快速数据挖掘数据分析实战RapidMiner工具应用第4章 数据和结果可视化

第4章数据和结果可视化前面的部分中,我们已经看到了RapidMiner Studio图形用户界面是如何建立起来的,以及如何用它来定义和执行分析流程。
在流程的最后,流程结果会显示在结果视图中。
现在在工具栏上点击一下就能跳转到结果视图了。
这一章会详细阐述结果视图。
依据您是否已经生成了可被描述的结果,在默认设置前提下,您现在应该至少能大致看到这些显示内容,如图4.1所示。
图4.1:RapidMiner的结果透视图或者,您可以在“View(视图)”菜单中=“Restore Default Perspective(恢复默认透视图)”这一选项重新建立这个预设透视图。
在介绍过的设计透视图之后,结果透视图是RapidMiner Studio的第二个主要工作环境。
我们已经讨论了右侧的资源库视图,因此这一章节我们会关注视图的其他组成部分。
4.1结果可视化我们已经看到了在流程执行完成后,流程中右侧结果端口的结果会自动显示在结果视图中。
结果视图中左上角的大部分会被用到,那里显示了分析结果概述,在这一章节的结尾我们会讨论这些分析结果。
目前每一个打开的和显示的结果都会在这一区域以一个附加标签显示,如图4.2所示。
严格来说,每个结果都是一个视图,像以往一样,您可以随心所欲的移动这些视图。
这样的话就能同时看到几个结果视图了。
图4.2:每个打开的结果都在左侧的区域显示为附加的一个标签当然您也可以单机标签上的×号来关闭单个视图,也就是标签。
视图的其他功能例如最大化也是完全可以的。
RapidMiner Studio会关闭之前的结果后再显示新的结果。
4.1.1显示结果的方法您可以通过很多方法显示结果。
以下是所有显示方法:1.自动打开我们已经看到了流程的最终分析结果,即在流程中右侧结果端口自动显示的内容。
在断点状态下,连接到结果端口的内容荣也能自动显示。
您可以在一个分析流程结束以后,在结果端口只收集所有您想要的分析结果,这些结果会在结果透视图中以一个个标签的形式展示出来。
rapidminer使用流程

rapidminer使用流程下载温馨提示:该文档是我店铺精心编制而成,希望大家下载以后,能够帮助大家解决实际的问题。
文档下载后可定制随意修改,请根据实际需要进行相应的调整和使用,谢谢!并且,本店铺为大家提供各种各样类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,如想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by theeditor. I hope that after you download them,they can help yousolve practical problems. The document can be customized andmodified after downloading,please adjust and use it according toactual needs, thank you!In addition, our shop provides you with various types ofpractical materials,such as educational essays, diaryappreciation,sentence excerpts,ancient poems,classic articles,topic composition,work summary,word parsing,copy excerpts,other materials and so on,want to know different data formats andwriting methods,please pay attention!RapidMiner 使用流程。
1. 数据导入。
从文件、数据库或 Web 服务中导入数据。
RapidMiner实验报告

实验报告实验目的:使用RapidMiner对数据进行分析实验工具:RapidMiner实验数据:实验数据说明:实验数据是通过研究对象的三种特征,一个是每年坐飞机飞行的里程数miles,二个是玩视频游戏所耗时间的百分比gamepercent,每周消费的冰淇淋公升数icecream,来判断一个人是否具有吸引力(didn't like、smallDoses,lagerDoses)实验过程:打开RapidMiner ,新建一个Process导入数据,如图所示点击下一步到出现如图所示界面,将Response设为label最后将数据存储在如下图的位置,命名为TrainingData,点击finish完成将数据TrainingData拖拽到process窗口中,用线连接至result接口,可以看到如下数据其中有些Response的值丢失了,共有31个这时需要使用Filter Examples 过滤掉没有值得Response行,操作如下图数据筛选完成之后,选择Decision Tree Model,拖入到process中,连接起来,参数选择默认设置训练好模型之后,我们可以用模型预测一下TrainingData中没有标记的样例,与上面的数据过滤方法相同,只是设置有所不同,如下图使用Apply Model来运用模型整个连接图如下所示实验的预测结果部分决策树截图如图,加入一个Validation其参数如下图,默认的10表示将样例分为十份,取一份作为测试数据双击Validation右下角的矩形表框进入,建议决策树模型,应用模型退出Validation 如图连接到result运行输出结果如下上图显示准确率为96%左右,正负误差为%,表明训练所得模型是比较稳定的实验总结1.我在这个过程中运用的测试集与训练集是相同的,这可能会使整个模型的预测能力比实际要偏大2.该实验的难点是数据源的收集与筛选,选择什么样的数据,需要怎样的处理才有意义是不容易的3.模型算子的选择对于我来说比较难,因为对这个是不熟悉的,所以基本上所有的参数都是默认的,这个感觉不太好4.对结果的分析不是很明白。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Linear Discriminant Analysis 线性辨别分析操作符
训练数据集
辨别分析可解决的实际问题: 教练根据体校往届学生的身 体素质条件和他们擅长的运 动项目为新一届体校学员制 定专项训练计划。
测试数据集
逻辑回归分析(预测分析类)
Logistic回归建模步骤繁多且复杂,在本软件 中,已经高度整合在一个算子之中,使用者只 需要调整个别参数即可实现快速建模。
大数据+机器学习
支持向量机 决策树 贝叶斯 关联聚类 深度学习 神经网络
Machine Learning
回归
分布式机器学习
这张大数据领域知识架构网络图中,黄色部分代表着领域的前沿。解读网络图可知, 机器学习在大数据分析领域中的应用,激活了之前几个独立的应用领域,使得大数 据具备了自主学习能力,在预测分析与逆向检验方面取得快速发展。
大数据分析工具--RapidMiner
基于机器学习的大数据分析
Big data analysis frontier sharing
RapidMiner软件介绍
目录
CONTENT S
数据访问、准备、清洗 基本大数据分析实战
RapidMiner+机器学习
01
rapidMiner软件介绍
RapidMiner a Leader in the 2018 The Forrester Wave™: Multimodal Predictive Analytics And Machine Learning Solutions
深度学习
深度学习算法计算结果 BP算法计算结果
深层神经网络
BP神经网络 在相同样本训练下,利用深层神经网络来进行 预测相较于BP算法结果存在明显的差异。 将大数据分析与深度学习相结合是时下最热门 的研究主题。
显著性差异
感谢您的聆听
Your opinion is the most valuable asset.
决策树算法
机器学习的训练过 程生成了决策树 决策树算法的通俗理解是: 根据已有的一个训练数据集,通过机器学 习对数据集里的数据进行逻辑联系判断, 生成一个带有复杂判断条件的决策树,当 有新的数据集(测试数据集)需要在某一 标签下进行预测时,软件就调用新的数据 进入决策树中,来进行判断预测。 销售量决策树
数据访问、准备、清洗
可以自动对数据源中的异常数 据进行分析过滤,防止在数据 分析过程中出现程序性错误
可以调节数据源中数据的类型, 支持多种文字编码格式,有效 防止解码错误。 主动检测BUG,在最大限度上 保证数据源的质量和完整性。
数据清洗。
03
基本大数据分析实战
RapidMiner a Leader in the 2018 The Forrester Wave™: Multimodal Predictive Analytics And Machine Learning Solutions
RapidMiner软件介绍
Rapid Miner 是技术性和适用性的完美结合,专业 为最新建立的人性化数据挖掘分析提供服务。通过推拽 算子,设置参数及组合算子,在RapidMiner 中定义分 析流程,可以使各专业技术人员专注于业务而非编程。
内置1500多个专业数据分析流程
强大的视觉化功能
GUI或编程界面
支持访问各种类型数据库
多模态数据分析预测
深层人工神经网络
高超的建模能力
RapidMiner软件介绍
RapidMiner软件介绍
02
数据访问、准备、清洗
RapidMiner a Leader in the 2018 The Forrester Wave™: Multimodal Predictive Analytics And Machine Learning Solutions
通过往届球员身体素质样本数据,利用BP人 工神经网络进行大数据分析,在隐藏层中建立 了人类难以直接理解的目标特征属性(这是与 决策树算法中明显的判别标准截然不同的), 来预测一批新球员谁能够成为世界巨星。
BP神经网络的计算过程由正向计算和 反向计算组成。正向传播,输入模式 从输入层经隐藏层逐层处理,传向输 出层,每一层神经元的状态只影响下 一层神经元的状态。如果在输出层不 能得到期望的输出,则转入反向传播, 将误差信号沿原来的连接通路返回, 通过修改各神经元的权值,使得误差 信号最小。
根据挖掘目的设置指标变量 y ; x1 , x 2 ,… x p
列出回归方程
p Ln 0 1 x1 1 p p xp
估计回归系数
逻辑回归分析可解决的实际问题:
模型检验F检验 应用方差分析表对模型检验
回归系数检验t检验 应用参数估计表对回归系数 进行t检验
是否周末 是 否 是否有促销 坏 是否有促销 是 高 否 低 好 高 是 天气 坏 低 否 低
决策树是对测试 集目标进行预测 的逻辑判断依据 概率判断结果
Hale Waihona Puke 天气 好 高人工神经网络 ANNs
人工神经网络(Artificial Neural Networks,ANNs),是模拟生物神 经网络进行信息处理的一种数学模 型。它以对大脑的生理研究成果为 基础,其目的在于模拟大脑的某些 机理与机制,实现一些特定的功能。
利用训练好的模型,可以对测试 数据集中各个个体是否容易罹患 二次心脏病做出基于概率的预测。
预测控制
04
RapidMiner+机器学习
RapidMiner a Leader in the 2018 The Forrester Wave™: Multimodal Predictive Analytics And Machine Learning Solutions
K-Means 聚类分析
模型
Cluster
聚类分析可解决的实际问题: 1) 如何通过用餐客户的餐饮选择来找到有价值 的客户群和需要关注的客户群? 2) 如何合理对菜品进行分析,以便区分哪些菜 品畅销毛利又高,哪些菜品滞销毛利又低?
分析结果
可视化
辨别分析(预测分析类)
模型应用操作符:将测试数据集 输入进已经训练好的分析模型中。 学 员 姓 名 预 测 结 果
数据访问、准备、清洗
RapidMiner提供了大量数据连接器。 包括60种结构化和非结构化的数据读取。 进一步支持文本,网络和多媒体数据挖掘处理。 支持纯文本,HTML,PDF,RTF,CSV以及更 多非数据库数据。
RapidMiner Cloud提供超大数据分析所需要的计 算能力,为用户的预测分析进行最大支持。 用户可在在云的弹性计算环境中运行大量的任务, 使得本地机器得以释放,任务并行提交给 RAPIDIMSER云。