第7章 LR语法分析
第7章 LR分析(8学时)

•
4) NFADFA
文法G: S’ E ET+E ET Ti*T Ti T (E)
① 文法的项目有: ② 确定初态、句柄/句子识别态 [1] S’ • E [1](初态) [2] S’ E • [2](句子识别态) [3] E • T + E [4] E T • + E [5] E T + • E [6] E T + E • [6](句柄识别态) [7] E • T [8] E T • [8](句柄识别态) [9] T • i * T [10] T i • * T [11] T i * • T [12] T i * T • [12](句柄识别态) [13] T • i [14] T i • [14](句柄识别态) [15] T •(E) [16] T (• E) [17] T (E •) [18] T (E) • [18](句柄识别态)
左部
•
右部
待识别部分
已识别部分
特例:空产生式 A → 只有一个项目 A → •
2. 根据项目构造识别活前缀的 DFA
1) 构造文法的所有产生式的所有项目,每个项目都为NFA 的一个状态
• • • • • • 移进项目:A→α•aβ 待约项目:A→α•Bβ 为A 归约项目:A→α• 接受项目:S’→α• 初态:S’ → • S 句柄识别态:所有的归约项目 (a∈VT)分析时把a移进符号栈 (B∈VN)期待着先归约为B再归约 表明句柄形成,可以归约 表明接受句子,分析成功
返回
构造识别活前缀的有穷自动机(形式定义法)
形式定义一(不包含句柄在内的所有活前缀的集合):
* 文法G,AVN , LC(A)={ |S’ A , V* , VT* } R
第07章、LR分析法
10
三、 LR分析器
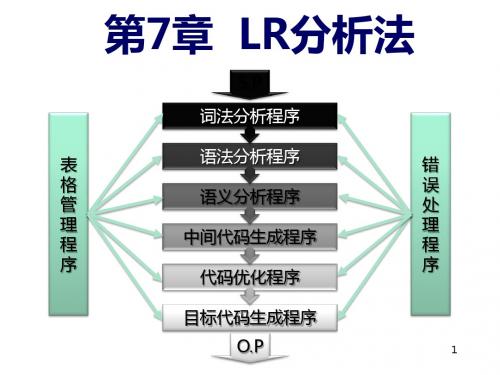
1. LR分析器的组成 由3部分组成:总控程序、分析表、分析栈。 2. LR分析器的构造 (1) 构造识别文法活前缀的确定有限自动机 (2) 根据该自动机构造相应的分析表(ACTION表、GOTO表)
圆点不在产生式右部最左边的项目称为核,唯一的 例外是S’ → • S。因此用GO(I,X)转换函数得到的J为 转向后状态所含项目集的核。 使用闭包函数(CLOSURE)和转换函数(GO (I,X)) 构造文法G’的LR(0)的项目集规范族,步骤如下: (1) 置项目S’→ • S为初态集的核,然后对核求闭包 CLOSURE({S’→ • S})得到初态的项目集; (2) 对初态集或其它所构造的项目集应用转换函数GO (I,X)= CLOSURE(J)求出新状态J的项目集; (3) 重复(2)直到不出现新的项目集为止。
28
例:文法G[S]: (1) S → aAcBe (2) A → b (3) A → Ab (4) B → d
a S2 ACTION c e b d # acc S5 r2 r3 r4 r1 S4 S6 r2 r3 r4 r1 3 r2 S8 r3 r4 r1 r2 r3 r4 r1 GOTO S A B 1
是否推导出abbcde?
每次归约句型的 前部分依次为: ab[2] aAb[3] aAcd[4] aAcBe[1]
9
二、LR分析要解决的问题
• LR分析需要构造识别活前缀的有穷自动机
可以把文法的终结符和非终结符都看成有 穷自动机的输入符号,每次把一个符号进 栈看成已识别过了该符号,同时状态进行 转换,当识别到可归前缀时,相当于在栈 中形成句柄,认为达到了识别句柄的终态。
wsx(编译原理第07章) LR分析法

LR分析法是给出一种能根据当前分析栈中的 符号串(通常以状态表示)和向右顺序查看输入 串的K个(K>=0)符号就可唯一地确定分析器的 动作是移进还是归约和用哪个产生式归约,因而 也就能唯一地确定句柄。 LR分析法的归约过程是规范推导的逆过程, 所以LR分析过程是一种规范归约过程。
LR(k)分析法可分析LR(k)文法产生的语言 –L :从左到右扫描输入符号, –R :最右推导对应的最左归约(反序完成最右推导)
第七章
• • • • • •
LR分析法
LR分析概述 LR(0)分析 SLR(1)分析 LR(1)分析 LALR(1)分析 二义性文法在LR分析中的应用
第1页,102页
• 前一部分我们已讨论过,自底向上分析方法是一种移 进-归约过程。 • 先复习一下:移进-归约分析
• 上一章的优先分析方法是当分析的栈顶符号串形成句 柄时就采取归约动作,因而自底向上分析法的关键问 题是在分析过程中如何确定句柄。 • 算符优先分析法存在的问题 –强调算符之间的优先关系的唯一性,这使得它的 适应面比较窄 –算法在发现最左素短语的尾时,需要回头寻找对 应的头
S
1 * 2 5
d
b
4 3 7
b
e
0
a
A
c B
6 9
第21页,102页
8
步骤 符号栈 输入符号串
动作
移进 移进 归约(A→b) 移进 归约(A→Ab) 移进 移进
S A B
8)
9) 10) 11)
# aAcd
#aAcB #aAcBe #S
e#
e# # #
归约(B→d)
移进 归约(S→aAcBe) 接受
A
对输入串abbcde#的移进-规约分析过程
ch7.1-7.3 LR(0)-SLR语法分析

一、1 LR分析器逻辑结构 输入、输出、栈、驱动程序和分析表组成
栈
S1 Xm … … S1 X1 S0 #
id+id*id#
LR驱动程序
动作 action 转移 goto
输 出
产生式表
5
状态 文法 符号
LR分析
特征:
规范的 符号栈中的符号是规范句型的前缀,且不含句 柄以后的任何符号 分析决策依据―栈顶状态和现行输入符号.识 别规范句型特定前缀(就到句柄为止)的 DFA.
栈
S1 Xm … … S1 X1 S0 #Βιβλιοθήκη id+id*id#
LR主控程序
动作 action 转移 goto
输 出
产生式表
9
状态 文法 符号
7.2 LR(0)分析
一、LR分析的基本原理
把每个句柄的识别过程划分为若干 个状态, 每个状态下,自左向右地识别 了句柄的一部分符号。 A→.XYZ 对于产生式 A→X.YZ A→XYZ 对应 句柄识 的句柄XYZ,其 A→XY.Z 别态 状态划分为: A→XYZ.
DFA状态集: 设I是文法G的一个LR(0)项目集合, closure(I)是从I出发用下面三个规则构造的项目集: (1) I中每一个项目都属于closure(I)。 (2)若项目A→α· Bβ closure(I)且B→ηP 则将B → · η加进closure(I)中。 (3)重复执行(2)直到closure(I)不再增大为止。
规范句型的活前缀 DFA的定义:M=(Q,Σ ,δ,q0,Z) 其中:Q--状态集 Σ—输入字母表 δ –Q xΣ →Q的映射函数 LR(0)项目:
13
右部符号到达的位置,若有规则 AXYZ, 则有下面四个项目: A→.XYZ A→X.YZ A→XY.Z A→XYZ. A a,aVT 移进项目
《编译原理》第7章LR分析法

7.2 LR(0)分析表的构造4.构造LR(0)分析表——举例G[S′]:[0] S′→S [1] S→S(S)[2] S→εG[S]:[1] S→S(S)[2] S→εG[S]:[0] S′→SS′→.SS→.S(S)S→S.(S)S→.S(S) S→.7.3 SLR(1)分析表的构造1.LR(0)方法的不足LR(0)分析表的构造方法实际上隐含了这样一个要求:构造出的识别规范句型活前缀的有穷自动机中,每个状态均不能有冲突项目,这显然对文法的要求太高,也限制了该方法的应用。
7.3 SLR(1)分析表的构造1.LR(0)方法的不足例如,对文法G[S]:0S→E1 E→E+T2 E→T3 T→T*F4 T→F5 F→(E)6 F→i1I S→E.E→E.+TT→.T*F T→.FFT E #)(*+i G[S]:7.3 SLR(1)分析表的构造2.LR(0)方法的问题分析状态{ E→T.,T→T.*F}该状态含有移进-归约冲突,在分析表中表现为重定义。
7.3 SLR(1)分析表的构造2.LR(0)方法的问题①若U→x.ay ∈Ii ,且GO(Ii,a)=Ij,a∈VT,则ACTION[i,a]=“Sj”。
②若S′→S. ∈Ii,则置ACTION[i,$]=“acc”。
③若U→x. ∈Ii ,则对任意终结符a和$,均置ACTION[i,a]=“rj”或ACTION[i,$]=“rj”。
④若GOTO(Ii ,U)=Ij,其中U∈VN,则置GOTO[i,U]=“j”。
⑤除上述方法得到的分析表元素外,其余元素均置“报错标志”。
7.3 SLR(1)分析表的构造3.解决问题的方法所以在状态{ E→T.,T→T.*F}中,只需要向前看下一输入符号是*,还是FOLLOW(E)中的符号,便可解决冲突了。
7.3 SLR(1)分析表的构造3.解决问题的方法假设一个状态Ii中含有冲突项目I i ={ U1→x.b1y1,U2→x.b2y2,…,Um→x.bmym,V1→x.,V 2→x.,…,Vn→x.}若{b1,b2,…,bm}和FOLLOW(V1)、FOLLOW(V2)、…、FOLLOW(Vn)两两互不相交,就可以采用向前看一个输入符号的方法来解决状态中的冲突。
第七章LR分析-LR(1)

例2 G[S]: (0) S`→S → (3) L→ *R
(1) S→L=R →L=R (4) L→id
(2) S→R (5) R→L I4: L –> *•R R –> •L L –> •*R L –> •id I5: L –> id• I6: S –> L =•R R –> •L L –> •*R L –> •id I7: L –> *R• I8: R –> L• I9: S –> L=R•
SLR(1)的局限
follow 集包含了在任何句型中跟在 R 后的符号但没 有严格地指出在一个特定的推导里哪些符号跟在 R后.所以需要扩充状态以包含更多的信息:follow 集的哪些部分 才是进到该状态最恰当的归约依据. 处在状态 2时,试图构建句子有两条路: 1.S ⇒L = R 或 2.S ⇒ R ⇒ L. 如下一符号是 =, 那就不能用第二个选择,必须用 第一个,即移进. 只有下一个符号是#时才能归约. 尽 管 = 属于 Follow(R) ,那是因为一个 R 可以出现 在别的上下文中,在现在这个特定的情况,它不 合适,因为在用S ⇒ R ⇒ L推导句子时, = 不能跟 在R后.
2.若项目 →α.,b]属于 k, 那么置ACTION[k, b]为“用产生式 →α进行 若项目[A→α ,b]属于 属于I 那么置 →α进行 若项目 →α. 为 用产生式A→α 规约” 简记为“ 假定A→α为文法G 的第j 规约”,简记为“rj”;(假定 →α为文法G’的第j个产生式) 假定 →α为文法 的第 个产生式) 若项目[A→α aβ,b]属于 →α. 属于I 则置ACTION[k, a]为“把状 3.若项目 →α.aβ,b]属于 k且GO (Ik, a)= Ij,则置 则置 为 和符号a移进栈 态j和符号 移进栈”,简记为“sj”; 和符号 移进栈” 简记为“ 4.若项目 →S.,#]属于 k, 则置 若项目[S’→S 属于I 若项目 →S.,#]属于 则置ACTION[k, #]为“接受”,简记为“acc”; 为 接受” 简记为“ 为非终结符, 5.若GO (Ik, A)= Ij, A为非终结符,则置 为非终结符 则置GOTO(k, A)=j; 若 分析表中凡不能用规则1至 填入信息的空白格均置上 出错标志” 填入信息的空白格均置上“ 分析表中凡不能用规则 至5填入信息的空白格均置上“出错标志”。 按上述算法构造的含有ACTION和GOTO两部分的分析表,如果每个入口不 两部分的分析表, 按上述算法构造的含有 和 两部分的分析表 含多重定义,则称它为文法G的一张 的一张规范的LR(1)分析表。具有规范的LR(1) 含多重定义,则称它为文法 的一张 分析
LR分析方法

I0 I1 I2
1,3,11 2 4,6,9 4,6,9
b
12,14,17
c
6,7,9
d
10
E
2
A
5
B
I3
I4 I5 I6
12,14,17
6,7,9 14,15,17 5
14,15,17
6,7,9 14,15,17
18
10 18
8
13
16
I7
I8 I9 I10 I11
13
8 16 10 18
①据 NFA可以构 造DFA的转换矩 阵:
②状态转换图表示(P106):
对照转换矩阵
S0S2S5S2 r1 S0S2S5S2S5 S0S2S5S2S5S3 S0S2S5S2S5S2 S0S2S5S2S5S6 S0S2S5S6 S0S1
S0 S1 S2 S3 a
(1)LE,L (2)LE (3)Ea (4)Eb
10 11 12 13
b #E,E,L
S3
#E,L #L
S4
r1(LE,L)
1 S5
# #
r (LE,L) r accr3
r4
6 r1
r3
分析成功
2
S4
S5 S6 S3 S4
r4
5.3.1 LR(0)分析表的构造
在LR分析算法中,所使用的“状态”是跟活前缀有关的, 它就是能够识别文法所有活前缀的有限自动机的状态,每个 状态由一个或多个项目构成。 一、项目、活前缀: 希望用产生式S的右 1.定义:对于文法G,其产生式的右部添加一个特殊符号“.” 部进行归约,当前的 就构成文法的一个LR(0)项目,简称项目。 用产生式SaAcBe进行 输入应为a 归约时,a已经匹配(进 每个项目中圆点的左 2.例如: S.aAcBe 栈),需分析S a.AcBe 部表示在分析过程中, 对于产生式: 有项目: Sa.AcBe Aa.cBe 要用该产生式归约时, SaAcBe SaA.cBe 产生式SaAcBe右部 句柄已识别的部分 每个产生式对应的 SaAc.Be 分析结束,句柄已经 (进入符号栈),右部 项目个数等于它右部 SaAcB.e 形成,可以归约了。 表示等待识别的部分。 的长度加1 SaAcBe. A的项目为A.
第7章 LR分 析 法

编译原理
• • • • •
一般而言,假定LR(0)规范族的一个 项目集I中含有m个移进项目: A1→α·a1β1 , A2→α·a2β2 , … , Am→α·amβm 同时含有n个归约项目: B1→α·, B2→α·, …, Bn→α· 如果集合{a1,…,am}、 FOLLOW(B1)、…、FOLLOW(Bn)两两不相交 (包括不得有两个FOLLOW集含有“#”),则隐 含在I中的动作冲突可通过检查现行输入符号a 属于上述n+1个集合中的哪个集合而获得解决,
• [解答]
将文法G[S]拓广为文法G'[S']: G'[S']: (0) S'→S (1) S→BB (2) B→aB (3) B→b
编译原理
列出LR(0)的所有项目: 1.S‘→·S 6. B→·aB 2.S'→S· 7.B→a·B 3.S→·BB 8.B→aB· 4.S→B·B 9.B→·b 5. S→BB· 10.B→b·
编译原理
分类: 移进项目: A→ α.aδ,将a 移入符号栈 . 将 待约项目:A→ α.Bδ,需将待分析串归约成 . 需将待分析串归约成 需将待分析串归约成B 归约项目:A→α. 句柄已形成,可以归约 句柄已形成 可以归约 接受项目: 接受项目 S’ →α.
编译原理
(2)LR(0)项目集规范族的构造 2 LR(0
编译原理
每一项ACTION[s, a]所规定的动作是以下四种情况之一: (1) 移进:使(s, a)的下一状态s' =GOTO[s, a]和输入符号a进栈, 下一输入符号变成现行输入符号。 (2) 归约:指用某一产生式A→β进行归约。假若β 的长度为γ, γ A s' 则归约的动作是去掉栈顶的γ个项,A进符号栈,满足s' =GOTO[s, a] 的状态S'进栈。 (3) 接受:宣布分析成功,停止分析器的工作。 (4) 报错:报告发现源程序含有错误,调用出错处理程序。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
编译原理
2014年5月28日
25
拓广文法:
在原文法G中增加产生式S’→S,S’是拓广后文法G’的开 始符号。
文法G[S]拓广后得到文法G[S']: [0] S'→S [1] S→aS [2] S→b
编译原理
2014年5月28日
26
构造识别活前缀的DFA 有两种方法
( 1 )求出文法的所有项目,按一定规则构造 NFA 再确定化 为DFA (2)直接构造DFA(重点掌握)
else error( );
}
编译原理
2014年5月28日
12
表7.2
编译原理
2014年5月28日
13
7.1.2 LR(0)分析法
• LR(k)分析法通过活前缀来帮助确定句柄
活前缀:规范句型中不含句柄右边任何符号的前缀
规范句型:通过规范推导(规约)得到的句型
前缀:句型的任意首部 如abc的前缀有ε,a,b,ab,abc
编译原理
2014年5月28日
27
构造活前缀的方法一:NFA DFA
(1)设所有LR(0)项目分别对应NFA的一个状态,其中含 有文法开始符号的产生式S'→S的第一个项目(S'→· S) 作为NFA的唯一初态,归约项目对应为终态。
(2)若状态i和j中的LR(0)项目出自同一条产生式,只是 圆点的位置相差一个符号,即 i为:X→X1X2…Xi-1 · Xi…Xn j为:X→X1X2…Xi-1 Xi · Xi+1…Xn 则从状态 i到状态 j连一条标记为 Xi 的箭弧,说明在状态 i 下,识别了符号Xi后,NFA从状态i转换为状态j。
什么是LR(k)分析: L:从左到右扫描 R:最右推导的逆过程(最左归约) k:是指为了作出分析决定而向前看的输入符号的个数
是一种规范归约过程 LR(k)分析技术Knuth于1965年首先提出
编译原理
2014年5月28日
3
Knuth
《计算机程序设计艺术 第1卷 基本算法》 98元 《计算机程序设计艺术 第2卷 半数值算法》 98元 《计算机程序设计艺术 第3卷 排序与查找》 98元
10
15
A
图7-1识别活前缀的不确定自动机
编译原理
2014年5月28日
24
有穷自动机的输入字符:终结符和非终结符 状态转换:每把一个符号进栈,就看成识别过了 该符号,进行状态转换。因为LR分析时栈中始终 保持是活前缀,所以有穷自动机识别过的符号串 也是活前缀。 终态:当识别到可归约前缀(表明在栈中形成句 柄),认为到达了识别句柄的终态,执行归约.
/~knuth/
编译原理
2014年5月28日
4
LR分析法的优缺点
优点
适用范围广,适用于多数无二义性的 上下文无关文法 分析效率高,报错及时 可以自动生成
缺点
手工实现工作量大
编译原理
2014年5月28日
5
7.1.1 LR分析器的逻辑结构和工作过程 LR分析器的逻辑结构:分析栈、分析表、总控程序
若项目集中有A→· B,则必有B→·γ,其中B→γ是产生 式。如,I0 和I2。
为实现这一步,先给出两个定义: A.项目集闭包函数closure B.状态转移函数GO
编译原理
32
2014年5月28日
A.项目集闭包函数closure (I) (1)每一个I中的项目都加进closure(I); (2)若A→α· Bβ∈closure(I)且有B→γ产生式, 则将B→· γ加进closure(I); (3)重复执行(2)直到closure(I)不再增大为止。 例:I= { S'→·S} closure(I)=? { S'→·S , S→·aS , S→·b }
编译原理
2014年5月28日
9
分析表:行标题为状态,列标题为文法符号
表7.1
GOTO表示当前状态面临文法符号时应转向的下一个状态 ACTION表示当前状态面临输入符号时应采取的动作 编译原理
2014年5月28日 10
控制程序
1、根据栈顶状态和现行输入符号,查分析动作 表(ACTION表),执行分析表所规定的操作
编译原理
2014年5月28日
22
如何确定规范句 型的活前缀
• 回顾:有穷自动机——一种识别装置
分DFA和NFA
0 X 1 1 A 1 B
0
C
1 Y
识别1(0|1)*101的NFA
编译原理
2014年5月28日 23
0 X
S a a a a
1 3 6
*
1
5 9 14
b A
A
4
7 11 16 b c c 8 12 17 d B 13 18 e 19
这种表适用的文法类及其实现上难易在LR(1) 和SLR(1)两种之间,比较实用。使用LALR分 析表进行语法分析的分析器叫LALR分析器 说明:四种分析表对应四类文法
编译原理
2014年5月28日 8
LR分析器的工作过程 【例7.1】表7.1是一个算术表达式文法G[E]的LR分析表,该 文法如下: (1)E→E+T (2)E→T (3)T→T*F (4)T→F (5)F→(E) (6)F→i 对于符号串i+i*i,利用 LR分析算法给出分析过程。
期望从剩余输入串中能看到由某产生式A→ 的右部所推出的符号串
编译原理
2014年5月28日 18
项目的直观意义: 在分析过程中的某一时刻已经归约的部分和等待归约部分
一个产生式对应的项目个数是右部符号长度加1 产生式A→的项目个数只有一个,即A→·
【例7.2】 文法G[S]: S→aS|b 写出其所有的LR(0)项目。 S→·aS S→a·S S→aS· S→·b S→b·
编译原理
2014年5月28日
20
项目分为四类
③归约项目:A→α· 圆点在最后,表示栈顶的部分内容已构成所期望 的句柄,应使用产生式A→α进行归约。 ④接受项目:S′→α· 特殊的归约项目,使用产生式S′→α进行归约, 表示整个句子已经分析完毕,分析成功,也即输 入串为该文法的句子。
编译原理
2014年5月28日
【例7.2】 (0)S'→·S (1)S'→S· (2)S→·aS ( 3 ) S →a · S (4)S→aS· (5)S→·b ( 6 ) S →b ·
练习:I= { S→a·S} closure(I)=? { S'→a·S , S→·aS , S→·b }
编译原理
2014年5月28日
33
B.状态转移函数GO,X是文法符号 GO(I,X)=closure(J) J={形如A→αX· β的项目|A→α· Xβ∈I} 例:I= {S'→·S , S→·aS , S→·b } 求GO (I , b )=? GO(I,b)=closure({S→b·})={ S→b·} 求GO (I , a )=?
编译原理
2014年5月28日
17
活前缀与句柄的关系
为刻划产生式右部符号已有多大一部 分被识别,用项目来指示位置 项目:产生式的右部添加一个圆点 A→·
①活前缀已含有句柄的全部符号
A→的右部已出现在栈顶,可以归约 ②活前缀只含有句柄的部分符号 A→1· 2
A→12的右部子串1已出现在栈顶,正期 待从剩余输入串中能看到由2推出的符号串 ③活前缀不含有句柄的任何符号 A→·
21
例7.3 文法G[S]: (1)S → aAcBe (2)A → b (3)A → Ab (4)B → d
1.写出其LR(0)项目 2.给出句子abbcde的归约过程
ab[2]b[3]cd[4]e[1] aAb[3]cd[4]e[1] aAbcd[4]e[1] aAbcde[1] S 用产生式(2)归约 用产生式(3)归约 用产生式(4)归约 用产生式(1)归约
编译原理
28
2014年5月28日
(3)若状态i为待约项目,即 i为:A→· B 则也会有以非终结符 B为左部的相关项目及其相应状态, 如状态k, k为:B→·γ 则从状态i到状态k连一条标记为的箭弧。
编译原理
2014年5月28日
29
识别活前缀的NFA
ε b ε ε S a ε
编译原理
I5: S→· b ε I0: S'→· S ε I2: S→· aS
I0,I1,I2,I3,I4:分别称为项目集 {I0,I1,I2,I3,I4}称为项目集规范族
I3: S→b· b I2: S→a· S S→· aS ε→· S b S I4: S→aS·
a
编译原理
2014年5月28日
31
构造活前缀的方法二:直接构造DFA
方法一工作量大,不适用 分析DFA状态的项目集之间、项目集内的项目之间的规律性 直接构造出DFA 若项目集中有Y→· X,另一项目集中有Y→X· ,则这 两个项目集之间必有一条X弧。如,I0 和I1、I2、I3等。
构造简单,最易实现,大多数上下文无关文法都 可以构造出SLR分析表,所以具有较高的实用 价值。使用SLR分析表进行语法分析的分析器 叫SLR分析器
编译原理
2014年5月28日
7
LR(1)分析表(规范LR分析表)
(了解)
适用文法类最大,几乎所有上下文无关文法都能 构造出LR(1)分析表,但其分析表体积太大,实 用价值不大. LALR分析表(超前LR分析表) (了解)
2、根据GOTO表设置新的栈顶状态(即实现状 态转移)
编译原理
2014年5月28日
11
LR分析算法描述
将S0移进状态栈,# 移进符号栈,S为状态栈栈顶状态 a=getsym( ) //读入第一个符号给a while(ACTION[S,a]!=acc ) { if ACTION[S,a]=Si{ PUSH i,a(分别进栈); a=getsym( ) ;//读入下一个符号给a} else if ACTION[S,a]=rj (第j条产生式为A→β) { 将状态栈和符号栈分别弹出|β| 项;push(A); 将GOTO[S’,A] 移进状态栈(S’为当前栈顶状态);}