THUFIBER使用过程
BO导入导出
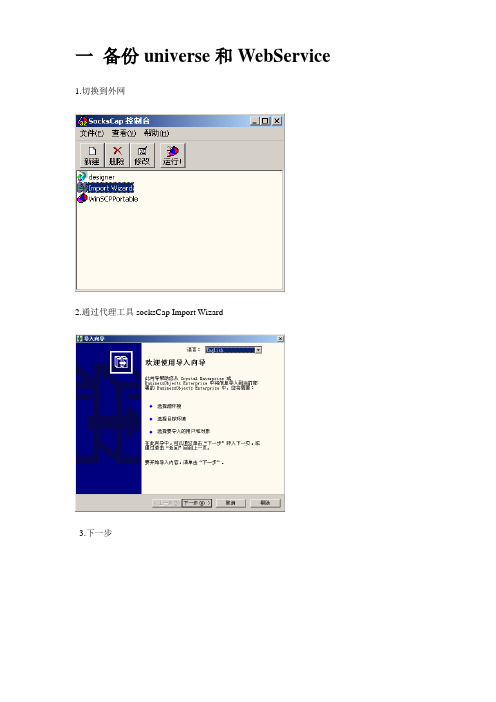
一备份universe和WebService 1.切换到外网
2.通过代理工具socksCap Import Wizard
3.下一步
Cms名称改为:
下一步
在“目标”选择存档资源(BIAR) 文件
导出biar文件
命名为20091010.biar 单击下一步
全部清楚之后,选择“导入应用程序文件夹和对象”导入universe 两项
下一步
单击“全选”之后下一步
是否要导出webi , 若无全部清楚, 下一步
导出webservice , 选择QaaWS Folder
选择第三项可以选择具体的Universe
备注: 如果有Universe名称和文件夹名称相同,选择全选会忽略相同名称Universe的选择
下一步
单击“完成”
单击“完成”
二导入universe和WebService 切换导内网
下一步
在来源中选择在存档资源(biar)文件
选择已备份文件
跟导出一样, 先全部清楚”导出应用程序文件夹和对象”及“导出Universe”
全选,下一步
关于webi文件不用导出, 直接单击下一步
选择QaaWs Folder ,下一步
选择第三项,导入选择对话框,下一步
全选别忘了相同名称的Universe 如: 多维分析
直接下一步
完成over。
ultimascraper 使用方法

UltimaScraper使用方法一、简介UltimaScraper是一款功能强大的网页数据爬取工具,能够帮助用户轻松快捷地获取网页上的所需数据。
它具有友好的用户界面和丰富的功能,可以满足用户不同的数据爬取需求,是一款非常实用的工具。
二、下载与安装1. 用户可以在UltimaScraper冠方全球信息站上下载安装包,根据系统版本选择合适的安装文件。
2. 下载完成后,双击安装包进行安装,按照提示进行操作,即可完成安装。
三、使用方法1. 打开UltimaScraper软件,进入主界面。
2. 在主界面的URL输入框中输入要爬取数据的网页信息。
3. 点击“开始”按钮,软件将开始获取网页上的数据。
4. 用户可以根据需求,设置数据提取规则,包括字段名称、数据类型、提取方式等。
5. 在设置完成后,点击“确定”按钮,软件将根据设置的规则进行数据提取并显示在界面上。
6. 用户可以选择将提取的数据保存为CSV、Excel等格式,也可以通过API接口连接到其他应用程序。
四、注意事项1. 在使用UltimaScraper时,需要保证网络畅通,否则可能影响数据的获取。
2. 用户在设置数据提取规则时,需要确保规则的准确性,以免获取到错误的数据。
五、结语UltimaScraper是一款强大而实用的网页数据爬取工具,它为用户提供了方便快捷的数据获取方式,能够满足用户不同的数据爬取需求。
希望以上介绍能够帮助用户更好地了解UltimaScraper,从而更好地使用该软件。
六、高级功能除了基本的网页数据爬取功能外,UltimaScraper还具有一些高级功能,帮助用户更加灵活地进行数据操作和提取。
1. 自动化任务UltimaScraper支持设置自动化任务,用户可以通过定时任务或者事件触发来执行数据爬取操作。
这样可以节省用户的时间和精力,也可以保证数据的及时更新和准确性。
用户可以根据实际需求,设置不同的触发条件和执行时间,使数据爬取操作更加智能化。
surfer的使用流程

Surfer的使用流程流程概述Surfer是一款功能强大的数据可视化工具。
它可以帮助用户将数据转化为直观、易懂的图表和图形,提供更好的数据分析和决策依据。
本文将介绍Surfer的使用流程,并提供一些使用技巧和注意事项。
安装和启动Surfer1.下载Surfer安装包,双击运行安装程序。
2.按照安装向导提示完成安装过程。
3.在桌面或启动菜单中找到Surfer图标,双击启动应用程序。
创建图表使用Surfer创建图表的过程如下:1.打开Surfer应用程序界面,在菜单栏中选择“文件”->“新建”。
选择数据文件并导入到Surfer中。
2.在数据文件导入完成后,选择合适的数据列进行图表绘制。
3.在Surfer的“绘图”菜单中选择合适的图表类型,如折线图、柱状图等。
4.根据需要调整图表样式、轴标签、图例等属性。
5.点击“绘图”按钮生成图表。
数据分析和编辑在生成图表后,可以进行数据分析和编辑。
1.使用Surfer的“数据编辑”功能,对数据进行筛选、排序、过滤等操作。
2.利用Surfer提供的统计分析工具,对数据进行描述性统计、回归分析、假设检验等。
3.根据数据分析结果,调整图表样式、标签、线条等,以更好地展示数据。
导出和分享当图表生成和编辑完成后,可以导出并分享图表。
1.在Surfer中选择“文件”->“导出”菜单,选择合适的导出格式,如图片格式(PNG、JPEG、BMP)或PDF格式。
2.根据需要设置导出参数,如分辨率、图表大小等。
3.点击“导出”按钮完成导出操作,保存图表文件到本地或分享给他人。
使用技巧和注意事项在使用Surfer时,以下技巧和注意事项可能对您有帮助:1.导入数据前,确保数据文件格式正确,并仔细选择需要导入的数据列。
2.在绘制图表前,先观察数据的分布和趋势,选择最适合的图表类型。
3.在编辑图表时,保持图表简洁和易读性,避免过多的线条和标签。
4.尝试使用Surfer提供的多种颜色方案和样式,使图表更具吸引力。
fluent 解算方法的一些说明

FLUENT-manual 中解算方法的一些说明,摘录翻译了其中比较重要的细节,希望对初学FLUENT的朋友在选择设置上提供一些帮助,不致走过多的弯路离散1、QUICK格式仅仅应用在结构化网格上,具有比second-order upwind 更高的精度,当然,FLUENT也允许在非结构网格或者混合网格模型中使用QUICK格式,在这种情况下,非结构网格单元仍然使用second-order upwind 格式计算。
2 、MUSCL格式可以应用在任何网格和复杂的3维流计算,相比second-order upwind,third-order MUSCL 可以通过减少数值耗散而提高空间精度,并且对所有的传输方程都适用。
third-order MUSCL 目前在FLUENT中没有流态限制,可以计算诸如冲击波类的非连续流场。
3、有界中心差分格式bounded central differencing 是LES默认的对流格式,当选择LES后,所有传输方程自动转换为bounded central differencing 。
4 、low diffusion discretization 只能用在亚音速流计算,并且只适用于implicit-time,对高Mach流,或者在explicit time公式下运行LES ,必须使用second-order upwind 。
5、改进的HRIC格式相比QUICK 与second order 为VOF计算提供了更高的精度,相比Geo-Reconstruct格式减少更多的计算花费。
6 、explicit time stepping 的计算要求苛刻,主要用在捕捉波的瞬态行为,相比implicit time stepping 精度更高,花费更少。
但是下列情况不能使用explicit time stepping:(1)分离计算或者耦合隐式计算。
explicit time stepping只能用于耦合显式计算。
shuffle函数的用法

shuffle函数的用法摘要:1.引言2.shuffle 函数的定义3.shuffle 函数的基本用法4.shuffle 函数的参数和返回值5.shuffle 函数在实际编程中的应用6.总结正文:1.引言在编程中,有时候我们需要对数据进行随机排序。
在Python 中,内置的shuffle 函数可以帮助我们实现这个功能。
本文将详细介绍shuffle 函数的用法。
2.shuffle 函数的定义shuffle 函数是Python 内置的random 模块中的一个函数,用于随机打乱序列中的元素。
它的定义如下:```pythonrandom.shuffle(sequence)```其中,sequence 是一个可迭代对象,如列表、元组等。
3.shuffle 函数的基本用法使用shuffle 函数非常简单。
首先,需要导入random 模块,然后调用shuffle 函数,并传入需要打乱的序列。
例如:```pythonimport randommy_list = [1, 2, 3, 4, 5]random.shuffle(my_list)print(my_list)```运行上述代码,输出结果可能为:[2, 5, 3, 1, 4]。
4.shuffle 函数的参数和返回值shuffle 函数只有一个参数,即需要打乱的序列。
它没有返回值,而是直接修改原始序列。
5.shuffle 函数在实际编程中的应用shuffle 函数在实际编程中有很多应用,例如:- 随机生成验证码- 随机排列扑克牌- 随机选择试题6.总结本文介绍了Python 内置的shuffle 函数的用法。
通过导入random 模块,调用shuffle 函数,并传入需要打乱的序列,我们可以实现对数据进行随机排序。
使用thulac分词

使用thulac分词
要使用THULAC进行800字的分词,您需要按照以下步骤进行操作:
1. 安装THULAC:首先,您需要安装THULAC(天元语言模型工具包)。
您可以从THULAC的官方网站或GitHub仓库下载并按照说明进行安装。
2. 准备文本数据:将需要进行分词的800字文本保存为一个文件,例如命名为"input.txt"。
3. 运行分词命令:打开终端或命令提示符,并导航到包含THULAC可执行文件的目录。
然后,运行以下命令来执行分词操作:
thulac -i input.txt -o output.txt
这将使用THULAC对"input.txt"中的文本进行分词,并将结果保存到"output.txt"文件中。
4. 查看分词结果:打开"output.txt"文件,您将看到分词结果。
每个词将被单独一行显示。
请注意,以上步骤提供了一个基本的概述,具体操作可能会因您的操作系统和环境而有所不同。
确保按照THULAC的文档和说明进行正确的安装和配置。
ultimascraper 使用方法 -回复

ultimascraper 使用方法-回复Ultimascraper是一种强大的网络爬虫工具,它可以帮助用户从网站上自动抓取数据,并将其保存为结构化的数据。
本文将一步一步地介绍Ultimascraper的使用方法,以让初学者快速上手。
第一步:安装和配置Ultimascraper要使用Ultimascraper,首先需要将其安装在您的计算机上。
Ultimascraper适用于多个操作系统,包括Windows、Mac和Linux。
您可以从Ultimascraper官方网站下载最新版本的软件。
安装完成后,您需要配置Ultimascraper以适应您的工作环境和目标网站。
在配置文件中,您可以设置要使用的代理服务器、请求头、超时时间等。
您还可以指定要抓取的目标网站的URL、要提取的数据字段等详细信息。
第二步:编写抓取规则一旦安装和配置完成,接下来您需要编写抓取规则。
抓取规则是一个针对目标网站的脚本,用于指定您希望Ultimascraper如何抓取和解析数据。
抓取规则使用XPath或CSS选择器来定位和提取网页上的元素。
您可以使用DevTools或类似的工具来检查目标网站的HTML结构,并确定要抓取的字段的位置和属性。
例如,如果您想要提取一个新闻网站上的标题、作者和发布日期,您可以使用以下XPath表达式:h2[@class='title']span[@class='author']div[@class='date']将这些XPath表达式添加到您的抓取规则中,指定每个字段的名称和数据类型。
第三步:运行和保存抓取结果完成抓取规则后,您可以通过运行Ultimascraper来启动抓取过程。
Ultimascraper将根据您的规则访问目标网站,并从中提取数据。
抓取结果可以保存为各种文件格式,如CSV、JSON或Excel。
您可以在配置文件中指定要保存的文件名和路径。
关于therefore的用法

关于therefore的用法一、Therefore的定义与基本用法"Therefore"是一个连接副词,常用于上下文之间进行因果关系的推理和论证。
它起到了衔接句子并引导逻辑推断的作用。
当我们使用"Therefore"时,我们表达了根据前提的合理推论或结论。
对于这个任务,我们将探讨"Therefore"在句子中的正确用法以及如何使用它来确保句子的逻辑连贯和清晰度。
二、标点符号与Thereof之间的分隔符号在使用"Therefore"时,它通常位于句子中间,并且需要两个逗号包围,以使其从主题中分离出来。
例如:原因 A, 原因 B, therefore, 结论 C.这种标点符号使用的方式有助于读者准确地辨别出论证步骤和结论,并帮助概括作者所要表达的内容。
这种标点规范也体现了写作者对论点发展层次结构以及提供线索给读者以方便理解和理解作者意图的重视。
三、触发词与Therefore当我们使用"Therefore"来表达因果关系时,前一句通常是原因或条件,在此之后才会引入结果或结论。
为了确切地传达思想并避免歧义,我们可以使用其他一些触发词来引导读者正确地理解句子的逻辑关系。
一些常见的触发词包括:"thus"、"hence"、"consequently"等。
例如:原因 A, 原因 B, consequently, 结论 C.这样使用"Therefore"和其他触发词有助于确保句子的逻辑连贯性,使读者能够清楚地辨别出前提与结论之间的因果关系。
四、注意法律写作中Therefore的使用在法律写作中,经常使用"Therefore"来得出结论或总结某个案例或法律原则。
这种用法被认为是一种规范而推荐的方式,它充分区分了事件描述和讨论部分以及结论部分。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
4.具体的钢筋和混凝土的本构都写在MARC_Fiber_Example.for原程序中。
在marc中建模过程:
1.在mesh中画出单元,单元建立时要沿着坐标系的正向依次选取,以免出错。
2.在“几何”中,选择solid section beam(在05r2中时,3D->elastic beam):
1.在AREA中要求填入面积,而IXX和IYY不需要填入;
2.根据提示要填入X轴的方向,由于沿着梁的方向已经了局部z轴的方向,只
要再给出x轴的方向(有的版本是要给出x-z平面的外法线方向)就能确定其局部坐标系;
3.在PLOT SETTINGS->BEAM中通过DRAW ORIENTATION查看beam的方
向是否正确;
4.在“材料”中,选择HYPOELASTIC,在METHOD中选择USER SUB.UBEAM,
一般只要设置mass density,其他选项,如阻尼和蠕变则根据需要设置;
5.Mat的编号必须与matcode相对应,且必须放在所有自定义材料的最前边,
如果不确定需要定义的THUFIBER材料的个数,可以在前边定义许多空的材料备用;
6.接下来就是在JOB中选择MARC_Fiber_Example.for子程序。