NetApp 双活架构与EMC双活架构比较
NetApp产品及架构介绍V10

10 PCIe 6 PCI-X
8 PCIe
PPT文档演模板
1 GB 4
1 GB 512 MB 256 MB
4
4
4
36
36
8 x 4Gb 8 x 2Gb
40
40
8
4x4 Gb
8
4
4x4 Gb
4
8 PCIe 8 PCI-X 2 PCIe
––
NetApp产品及架构介绍V10
FAS 存储系统升级的投资保护
PPT文档演模板
•存储资源管理
•信息可用性
• Snapshot™ • SnapRestore® • SnapMirror® • SnapVault® • SnapLock™
NetApp产品及架构介绍V10
NetApp 产品概览 (2)
•Data ONTAP GX 系统
PPT文档演模板
NetApp产品及架构介绍V10
NetApp GX 高性能运算平台
PPT文档演模板
2 ~ 24 节点 最大容量 6PB,最大数据卷 4PB 最大读写带宽 10GB/s NAS 性能世界纪录保持者 > 100万 SFS IOPS
• FAS6030
• 840 Drivers
• FAS3170 • 840TB
• 840 Drivers
• FAS3160 • 840TB
• 672 Drivers
• FAS3140 • 672TB
• 420 Drivers
• FAS2050
• 420TB
•
•
FAS2020
68 Drivers
•
•
104 Drivers 104TB
NetApp FAS与EMC VNX竞争分析报告

VNX Application Protection Suite
Total Protection Pack
Total Efficiency Pack
10Gb Enet
TBD
FC
iSCSI FCoE
10Gb Enet
TBD
VNX X-Blade VNX X-Blade VNX X-Blade VNX X-Blade VNX SP
Failover
VNX X-Blade VNX X-Blade VNX X-Blade VNX X-Blade
VNX OE FILE VNX OE BLOCK
*Initial support is for 1000 drives GATEWAY VNX8000 VG2 4000 N/A BE dependent VG8 4000 N/A BE dependent
125 600
250 1000
பைடு நூலகம்
500 2000
750 3000
1000 4200
1500* 4200
Failover
Power Supply
VNX SP
Power Supply
SPS LCC SPS LCC
Flash drives
Near-Line SAS drives
SAS drives
3
VNX软件套件无变化
Package/Suite Contents
VNX Operating Environment (REQUIRED)
N/A
N/A
VNX2底层架构设计无变化
Application servers Exchange servers
Clients VMware and Hyper-V Database Servers Object: Atmos VE SAN LAN
统一存储双活方案

NetAp统一存储双活方案NetApp统一存储双活方案1、双活存储架构建设目标系统灾难是指IT系统发生重要业务数据丢失或者使业务系统停顿过长时间(不可忍受)的事故。
可能引发系统灾难的因素包括:•系统软、硬件故障,如:软、硬件缺陷、数据库或其他关键应用发生问题、病毒、通信障碍等;•机房环境突发性事故,如:电源中断、建筑物倒塌、机房内火灾等;•人为因素,如:因管理不完善或工作人员操作不当、人为蓄意破坏、暴力事件等;•自然灾害:如火灾、地震、洪水等突发而且极具破坏性的事故。
其特点是突发性、高破坏强度、大范围。
在灾难性事故的影响下,计算中心机房的硬件设备会部分或完全损坏,造成业务的停顿。
请参见下图:当前用户IT系统缺乏有效的灾难防范手段,难以在灾难发生后,不间断或者迅速地恢复运行。
灾难恢复就是在IT系统发生系统灾难后,为降低灾难发生后造成的损失,重新组织系统运行,从而保证业务连续性。
其目标包括:●保护数据的完整性、一致性,使业务数据损失最少;●快速恢复业务系统运行,保持业务的连续性。
灾难恢复的目标一般采用RPO和RTO两个指标衡量。
技术指标RPO、RTO:RPO (Recovery Point Objective): 以数据为出发点,主要指的是业务系统所能容忍的数据丢失量。
即在发生灾难,容灾系统接替原生产系统运行时,容灾系统与原生产中心不一致的数据量。
RPO是反映恢复数据完整性的指标,在半同步数据复制方式下,RPO等于数据传输时延的时间;在异步数据复制方式下,RPO基本为异步传输数据排队的时间。
在实际应用中,同步模式下,RPO一般为0,而在非同步模式下,考虑到数据传输因素,业务数据库与容灾备份数据库的一致性是不相同的,RPO表示业务数据与容灾备份数据的时间差。
换句话说,发生灾难后,启动容灾系统完成数据恢复,RPO就是新恢复业务系统的数据损失量。
RTO (Recovery Time Objective):即应用的恢复时间目标。
EMC与IBM、HP、HDS、NATAPP等多家产品的对比
有限的
否
是**
是
否
否
否
是
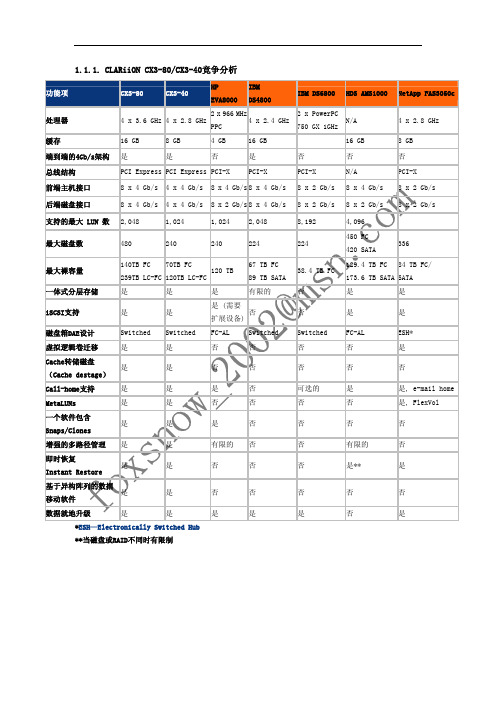
1.1.2. CLARiiON CX3-20竞争分析
Description
CX3-20
HP EVA6000
IBM DS4500
IBM DS4300 Turbo
HDS AMS500
处理器 缓存 端到端的4Gb/s架构
2 x 2.8 GHz 4 GB 是
2 x 966 MHz PPC 2 x 850 MHz 2 x 600 MHz
实现跨平台的数据迁移
CLARiiON CX700 与 Sun StorEdge 6920 之比较
功能
CX700
SE6920
EMC 的优势
处理器体系结构
4 个 3 GHz 处理器 未知
CLARiiON 明显的处理优势
最大容量
74 TB
每秒最大 I/O
200,000 IOPS
最大带宽
1,520 MB/s
224
112
210 SATA
56 TB
67 TB FC 33.6 TB FC 67.8 TB FC 89 TB SATA 44.8 TB SATA 88.5 SATA
是
是
是
是
是 (需要扩展设
否
否
否
备)
FC-AL
Switched Switched
FC-AL
否
否
否
否
是
否
否
否
否
Call-home支持
是
是
否
阵列
是
是
否
是
是
是
否
否
否
否
双活数据中心及灾备解决方案技术部分

NSX利用层叠网络实现双活数据中心
站点A
三层 网络
站点A 边界网关
上联网络A
VM1
VM 2
vCenter Server
分布式逻辑路由器
逻辑交换机A 172.16.10.0/24
VM
4
逻辑交换机B
172.16.20.0/24
数据存储1
which also aligns with vMotion using Enterprise Plus
• vMSC enables disaster avoidance and basic Disaster Recovery (without the orchestration or testing
• VMotion an数d S据to保ra护ge VMotion
• 高效的数据备份与恢复 • 可通过运行计划与脚本实现自动化操作
灾难恢复
• 基于虚拟化层的异步复制 • 基于硬件设备的同异步复制 • 自动化应用切换管理 • 城域集群
方案特点
• 与应用程序和操 作系统无关 • 与硬件设备无关 • 完善的保护 • 简单,经济
9
Fault Tolerance vs. High Availability
• Fault tolerance
– Ability to recover from component loss – Example: Hard drive failure
• High avail percentage in one year 99 99.9 99.99 99.999 “five nines”
Downtime in one year 3.65 days 8.76 hours 52 minutes 5 minutes
DELL EMC ”双活“解决方案

一、总体架构图为了进一步保障核心应用的高可用性,提高生产的安全级别,计划对目前的存储系统进行虚拟化整合,并搭建双活存储系统,保证关键业务所使用的存储系统即使有一台存储系统出现故障,也不会出现业务停顿,达到更高的生产安全保障。
经讨论分析,结合系统目前的现状,我们建议存储整合的架构设计,如下图所示:如上图所示,在生产中心的SAN网络中配置一套存储虚拟化设备——EMC VPLEX,将目前的存储系统接入VPLEX,所有应用系统只需要访问VPLEX上的卷即可,接入VPLEX上的存储可以做到镜像关系(即双活)或级联关系。
建议对重要应用的数据存储在镜像的两台存储系统上。
整个方案的组成部分为:A.中心机房-光纤交换网络:由两台速度为8Gbps的光纤交换机组成光纤交换网络,为所有系统提供基于光纤协议的访问;两台光纤交换机之间互为冗余,为系统的网络提供最大的可靠性保护。
用户可自行建设冗余SAN网络。
B.中心机房-主存储系统:配置一台EMC存储系统,与当前的EMC存储通过虚拟化存储进行本地数据保护,对外提供统一的访问接口;重要应用系统的数据都保存在这两台的存储系统上;➢EMC存储系统可同时提供光纤SAN、IP SAN、NAS等多种存储模式,支持光纤盘、闪存盘、SATA盘、SAS盘、NL-SAS盘等多种磁盘混插,大大增强存储系统的可扩展性;➢支持将闪存盘作为可读写的二级缓存来使用,同时支持自动的存储分层(FAST),提高存储系统的整体性能;➢支持LUN的条带化或级联式扩展,以将数据分散到更多的磁盘上;C.中心机房-存储虚拟化:以EMC VPLEX Local作为存储虚拟化;应用系统只需要访问虚拟化存储,而不需要直接管理后端的具体的存储系统;通过存储虚拟化,可以达到两台存储之间双活,可以支持异构的存储系统,对数据进行跨存储的本地及远程保护,统一管理接口和访问接口;D.中心机房-利旧存储:除了用来做“存储双活”的存储系统外,如果还有其他的SAN存储系统,EMC建议,通过VPLEX虚拟化功能,将这些旧存储系统挂接到VPLEX虚拟化存储中,加以利用;这些存储资源将作为存储资源池共享,按需使用;(注:挂接到VPLEX后端的其他存储品牌需要在VPLEX的兼容列表内。
“两地三中心”和“双活”简介--容灾技术方案

“两地三中⼼”和“双活”简介--容灾技术⽅案当前市场上常见的容灾模式可分为同城容灾、异地容灾、双活数据中⼼、两地三中⼼⼏种。
1、同城容灾同城容灾是在同城或相近区域内( ≤ 200K M )建⽴两个数据中⼼ : ⼀个为数据中⼼,负责⽇常⽣产运⾏ ; 另⼀个为灾难备份中⼼,负责在灾难发⽣后的应⽤系统运⾏。
同城灾难备份的数据中⼼与灾难备份中⼼的距离⽐较近,通信线路质量较好,⽐较容易实现数据的同步复制,保证⾼度的数据完整性和数据零丢失。
同城灾难备份⼀般⽤于防范⽕灾、建筑物破坏、供电故障、计算机系统及⼈为破坏引起的灾难。
2、异地容灾异地容灾主备中⼼之间的距离较远(> 200KM ) ,因此⼀般采⽤异步镜像,会有少量的数据丢失。
异地灾难备份不仅可以防范⽕灾、建筑物破坏等可能遇到的风险隐患,还能够防范战争、地震、⽔灾等风险。
由于同城灾难备份和异地灾难备份各有所长,为达到最理想的防灾效果,数据中⼼应考虑采⽤同城和异地各建⽴⼀个灾难备份中⼼的⽅式解决。
本地容灾是指在本地机房建⽴容灾系统,⽇常情况下可同时分担业务及管理系统的运⾏,并可切换运⾏;灾难情况下可在基本不丢失数据的情况下进⾏灾备应急切换,保持业务连续运⾏。
与异地灾备模式相⽐较,本地双中⼼具有投资成本低、建设速度快、运维管理相对简单、可靠性更⾼等优点;异地灾备中⼼是指在异地建⽴⼀个备份的灾备中⼼,⽤于双中⼼的数据备份,当双中⼼出现⾃然灾害等原因⽽发⽣故障时,异地灾备中⼼可以⽤备份数据进⾏业务的恢复。
本地机房的容灾主要是⽤于防范⽣产服务器发⽣的故障,异地灾备中⼼⽤于防范⼤规模区域性灾难。
本地机房的容灾由于其与⽣产中⼼处于同⼀个机房,可通过局域⽹进⾏连接,因此数据复制和应⽤切换⽐较容易实现,可实现⽣产与灾备服务器之间数据的实时复制和应⽤的快速切换。
异地灾备中⼼由于其与⽣产中⼼不在同⼀机房,灾备端与⽣产端连接的⽹络线路带宽和质量存在⼀定的限制,应⽤系统的切换也需要⼀定的时间,因此异地灾备中⼼可以实现在业务限定的时间内进⾏恢复和可容忍丢失范围内的数据恢复。
Oracle数据库双活Extended RAC实现技术对比(EMC VPLEX Metro,Oracle IOE,一体机)

网络心跳和磁盘心跳都走IB网络,带宽达40-56Gbps, 可实现端到端延迟<200ns。
★
IB网络比传统以太网的延时 低很多
理论值:<100km公里 ★ 实际案例:<80KM。超过10KM要借助波分复用设备来延 依托IB设备的扩展RAC能支 伸距离。经实测,80KM网络RTT值在0.45-0.5ms
每个站点均配备统一存储。整个双活中心仅有一套数据库(一个 磁盘组内须创建2个及以上故障组,故障组分别在不同的站点)
双份,数据在所有VPLEX存储上做条带化。由vplex实现数据冗 余,一般不再设置ASM磁盘组冗余级别。 不同站点之间的副本利用vplex metro存储复制技术实现双向复 制,任何站点的写操作将同时发给另一个站点的副本执行,属于 同步模式的复制。(双活解决方案不提供异步模式,该模式用于 传统容灾) (参考实际案例数据:经过VPLEX设备,会比第一种方案的延时 还增加1MS) ORACLE RAC: 1、网络心跳走以太网,要求带宽至少1G,延时在毫秒级; 2、磁盘心跳走裸纤,要求带宽至少10G; VPLEX: 3、存储网络至少需8G链路; 在本方案中RAC的磁盘心跳走VPLEX存储网络,带宽至少要满足 10G 理论值:<100km,网络延迟不超过5ms; 实际案例:oracle官方建议不超过10KM,网络延迟不能超过 1ms;超过该距离性能会随着距离增加呈线性衰减。超过10KM要 借助波分复用设备来延伸距离。
相关技术资料
ORACLE原厂白皮书 \\10.194.50.44\平台运维科\8-其它\平台组台帐\双活技术 \oracle
基于VPLEX Metro的Extended RAC (EMC公司)
读/写---读/写 硬件平台最少配备: 2台EMC VPLEX设备 2台独立存储设备 光纤网络交换设备2台(用于连接VPLEX设备、服务器、存储设 备) 4台Oracle数据库服务器 1台VPLEX Witness仲裁服务器 1台位于第三站点的仲裁服务器(挂载仲裁盘) 网络:以太网路由及交换设备则包括广域网互联设备(10KM以上 使用波分复用设备)、每个站点的核心、汇聚、接入层设备
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
NetApp 双活架构与EMC双活架构比较:
1,拓扑图架构比较
从拓扑图可以看到,EMC是采用vplex存储网关的方式实现,主机到存储的数据流需要经过vplex网关,然后再写入到后端的存储,需要通过两个SAN网络,数据的通路比较长。
NetApp则摈弃了存储网关模式,直接将双活的metrocluster软件集成到存储的控制器内,直接通过存储控制器实现双活功能,数据的通路比较短。
2,两种模式的性能比较:我们分别比较读写模式下,两种架构的性能比较:
a.写数据:
VPLEX Local对于数据写入采用“直写模式”,也就是主机写入数据的流程为:
主机发起数据写入→数据写入VPLEX→VPLEX写入2个后端存储→2个后端存储均
写入完成→报告主机写入完成。
可见在这个过程中,VPLEX的缓存无法发挥任何作用,反而因为数据多经过了一个
通路,导致写入速度变慢。
总的主机写入时间=VPLEX写入时间+后端存储写入时间。
而相比NetApp MetroCluster,写入数据时并无类似的网关设备,所以写入时间=存
储写入时间。
b.读数据:
VPLEX的引擎内存分为本地内存和全局内存,全局内存在local模式无效,
数据LUN如果在引擎上找不到缓存,需要从存储缓存中寻找;如果存储缓存也无
法找到数据,则从存储硬盘中读数据。
NetApp的模式,读数据直接从存储缓存中寻找,如果存储缓存无法找到数据,可
以在两个存储节点中同步读出数据(类似LUN的RAID 1)而提升读性能。
c.总结
以上可见,应用的写入IO速度是最影响应用响应速度的环节,而在写数据环节,
VPLEX的缓存非但不能发挥作用(因为采用直写技术),反而因为数据多流经一个
网关设备而造成额外的延迟。
从本质上讲,VPLEX仅仅是数据通道上的一个网关,数据最终还是需要从存储上进
行读写,网关性能标称的再高也不可能提升后端存储的速度,仅仅只能做到不影响
后端的存储性能而已,但是由于多一个数据路径环节,所以对整体速度有额外的延
迟。
3,双活功能比较:EMC VPLEX网关型架构与NetApp Metrocluster的架构比较
a.增加的网关设备导致更多连线,复杂的拓扑,引入的新的故障点。
相比netapp
metrocluster而言架构比较简洁。
b.VPLEX网关对外仅能提供FC SAN功能,无法支持iSCSI和NAS,对未来统一存储
整合不利,netapp metrocluster可支持各种统一存储协议。
c.VPLEX网关采用按容量许可的方式,后续扩容还需收取vplex扩容费,netapp
metrocluster后续无需收容量许可
d.VPLEX网关因为采用了最简单的FC仿真模式(对后端存储而言,它模拟自己为
一台服务器),这样实际上屏蔽了后端存储的特色软件功能(存储池、去重、
存储分层等功能均没有了)
e.VPLEX网关需要一个独立的管理工具
4,后端存储自身性能比较
EMC的VNX5600,标称缓存为48GB,但是实际可用内存仅为10多G,写缓存则更少,仅为2G多(可在EMC unisphere管理界面内看到,其余均被系统所开销),
而netapp FAS8020存储设备拥有专用的48GB读缓存、8GB的专用写缓存(系统开销均已除外),读写性能均高于VNX5600存储设备。