山东财经大学计量经济学课后
计量经济学(数字教材版)课后习题参考答案

课后习题参考答案第二章教材习题与解析1、 判断下列表达式是否正确:y i =β0+β1x i ,i =1,2,⋯ny ̂i =β̂0+β̂1x i ,i =1,2,⋯nE(y i |x i )=β0+β1x i +u i ,i =1,2,⋯n E(y i |x i )=β0+β1x i ,i =1,2,⋯nE(y i |x i )=β̂0+β̂1x i ,i =1,2,⋯ny i =β0+β1x i +u i ,i =1,2,⋯ny ̂i =β̂0+β̂1x i +u i ,i =1,2,⋯n y i =β̂0+β̂1x i +u i ,i =1,2,⋯n y i =β̂0+β̂1x i +u ̂i ,i =1,2,⋯n y ̂i =β̂0+β̂1x i +u ̂i ,i =1,2,⋯n答案:对于计量经济学模型有两种类型,一是总体回归模型,另一是样本回归模型。
两类回归模型都具有确定形式与随机形式两种表达方式:总体回归模型的确定形式:X X Y E 10)|(ββ+= 总体回归模型的随机形式:μββ++=X Y 10样本回归模型的确定形式:X Y 10ˆˆˆββ+= 样本回归模型的随机形式:e X Y ++=10ˆˆββ 除此之外,其他的表达形式均是错误的2、给定一元线性回归模型:y =β0+β1x +u (1)叙述模型的基本假定;(2)写出参数β0和β1的最小二乘估计公式;(3)说明满足基本假定的最小二乘估计量的统计性质; (4)写出随机扰动项方差的无偏估计公式。
答案:(1)线性回归模型的基本假设有两大类,一类是关于随机误差项的,包括零均值、同方差、不序列相关、满足正态分布等假设;另一类是关于解释变量的,主要是解释变量是非随机的,如果是随机变量,则与随机误差项不相关。
(2)12ˆi iix yxβ=∑∑,01ˆˆY X ββ=- (3)考察总体的估计量,可从如下几个方面考察其优劣性:1)线性性,即它是否是另一个随机变量的线性函数; 2)无偏性,即它的均值或期望是否等于总体的真实值;3)有效值,即它是否在所有线性无偏估计量中具有最小方差;4)渐进无偏性,即样本容量趋于无穷大时,它的均值序列是否趋于总体真值; 5)一致性,即样本容量趋于无穷大时,它是否依概率收敛于总体的真值;6)渐进有效性,即样本容量趋于无穷大时,它在所有的一致估计量中是否具有最小的渐进方差。
计量经济学---第三版-李子奈---课后习题--答案

ÿÿÿÿÿ******************************************************************************************************************************* ***********************ÿÿÿÿÿÿÿÿÿÿÿÿ第一章绪论(一)基本知识类题型1-1.什么是计量经济学?1-3.计量经济学方法与一般经济数学方法有什么区别?它在经济学科体系中的作用和地位是什么?1-6.计量经济学的研究的对象和内容是什么?计量经济学模型研究的经济关系有哪两个基本特征?1-7.试结合一个具体经济问题说明建立与应用计量经济学模型的主要步骤。
1-9.计量经济学模型主要有哪些应用领域?各自的原理是什么?1-12.模型的检验包括几个方面?其具体含义是什么?1-17.下列假想模型是否属于揭示因果关系的计量经济学模型?为什么?⑴ S t其中S t为第t年农村居民储蓄增加额(亿元)、R t为第t年城镇居民可支配收入总额(亿元)。
⑵ S t1其中S t1为第(t1)年底农村居民储蓄余额(亿元)、R t为第t年农村居民纯收入总额(亿元)。
1-18.指出下列假想模型中的错误,并说明理由:(1)RS t RI t其中,RS t为第t年社会消费品零售总额(亿元),RI t为第t年居民收入总额(亿元)(城镇居民可支配收入总额与农村居民纯收入总额之和),IV t为第t年全社会固定资产投资总额1(亿元)。
(2)C t180其中,C、Y分别是城镇居民消费支出和可支配收入。
(3)ln Y t ln K t L t其中,Y、K、L分别是工业总产值、工业生产资金和职工人数。
计量经济学金玉国第五章

yi 0 1x1i 2 x2i k xki ui
i=1,2,…, n
要求满足古典假设4:随机项u与解释变量x之间不相关,即:
Cov(xi, ui)=0
i=1,2, …, n
只要解释变量x1, x2,…, xk是确定性变量,则上述假设自动满
足。
2021年1月16日
山东财经大学统计学院 计量经济教研室
10
34500.6
20182.1
12998.0
3
10132.8
6542.0
3846.0
11
47110.9
27216.2
19260.6
4
11784.0
7451.2
4322.0
12
58510.5
33635.0
23877.0
5
14704.0
9360.1
5495.0
13
68330.4
40003.9
26867.2
第13页
三、随机解释变量模型的经济计量方法
模型中出现随机解释变量且与随机误差项相关时,OLS估计 量是有偏的。
如果随机解释变量与随机误差项异期相关,则可以通过增大 样本容量的办法来得到一致的估计量;
但如果是同期相关,即使增大样本容量也无济于事。这时, 最常用的估计方法是工具变量法(Instrument variables)。
xi*ui ] (xi* )2
我们分下列四种情况进行讨论
1. x 是非随机变量,x与u自然不相关
E
xi*ui ( xi* )2
xi* ( xi*
)2
E(ui
)
0
E(ˆ1) 1
最小二乘估计量是无偏的。
2021年1月16日
山经二专计量经济学课后山财大
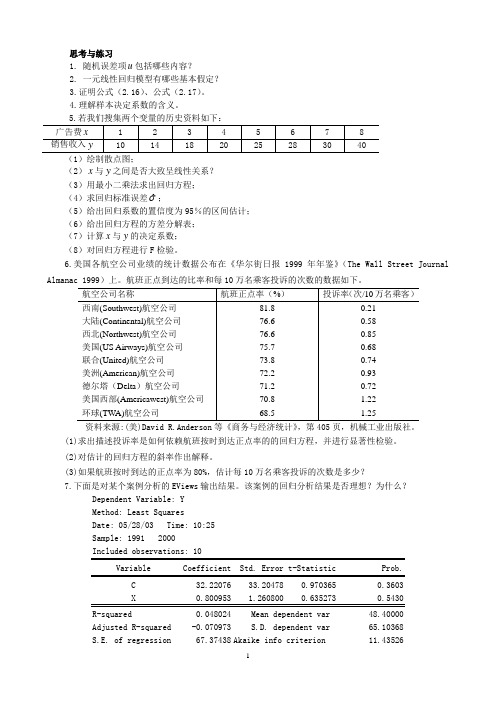
思考与练习1. 随机误差项u包括哪些内容?2. 一元线性回归模型有哪些基本假定?3.证明公式(2.16)、公式(2.17)。
4.理解样本决定系数的含义。
5.若我们搜集两个变量的历史资料如下:(1)绘制散点图;(2)x与y之间是否大致呈线性关系?(3)用最小二乘法求出回归方程;(4)求回归标准误差ˆ ;(5)给出回归系数的置信度为95%的区间估计;(6)给出回归方程的方差分解表;(7)计算x与y的决定系数;(8)对回归方程进行F检验。
6.美国各航空公司业绩的统计数据公布在《华尔街日报1999年年鉴》(The Wall Street Journal Almanac 1999)上。
航班正点到达的比率和每10万名乘客投诉的次数的数据如下。
(1)求出描述投诉率是如何依赖航班按时到达正点率的的回归方程,并进行显著性检验。
(2)对估计的回归方程的斜率作出解释。
(3)如果航班按时到达的正点率为80%,估计每10万名乘客投诉的次数是多少?7.下面是对某个案例分析的EViews输出结果。
该案例的回归分析结果是否理想?为什么?Dependent Variable: YMethod: Least SquaresDate: 05/28/03 Time: 10:25Sample: 1991 2000C 32.22076 33.20478 0.970365 0.3603R-squared 0.048024 Mean dependent var 48.40000Adjusted R-squared -0.070973 S.D. dependent var 65.10368S.E. of regression 67.37438 Akaike info criterion 11.43526Sum squared resid 36314.46 Schwarz criterion 11.49578Log likelihood -55.17632 F-statistic 0.403572 Durbin-Watson stat2.514737 Prob(F-statistic) 0.5429891. 解:一般说来,随机项u 来自以下几个方面:(1)变量的省略。
计量经济学第二版课后习题答案1-8章 - 编辑版
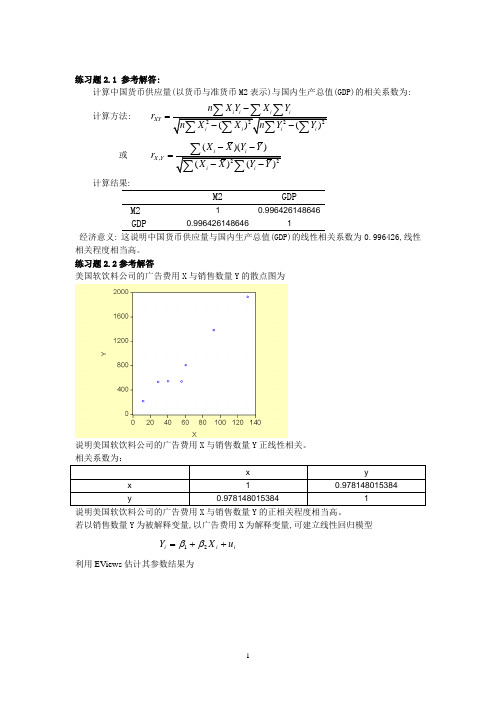
练习题2.1 参考解答:计算中国货币供应量(以货币与准货币M2表示)与国内生产总值(GDP)的相关系数为:计算方法: XY n X Y X Y r -=或,()()X Y X X Y Y r --=计算结果:M2GDPM2 10.996426148646GDP0.9964261486461经济意义: 这说明中国货币供应量与国内生产总值(GDP)的线性相关系数为0.996426,线性相关程度相当高。
练习题2.2参考解答美国软饮料公司的广告费用X 与销售数量Y 的散点图为说明美国软饮料公司的广告费用X 与销售数量Y 正线性相关。
相关系数为:说明美国软饮料公司的广告费用X 与销售数量Y 的正相关程度相当高。
若以销售数量Y 为被解释变量,以广告费用X 为解释变量,可建立线性回归模型 i i i u X Y ++=21ββ 利用EViews 估计其参数结果为经t 检验表明, 广告费用X 对美国软饮料公司的销售数量Y 确有显著影响。
回归结果表明,广告费用X 每增加1百万美元, 平均说来软饮料公司的销售数量将增加14.40359(百万箱)。
练习题2.3参考解答: 1、 建立深圳地方预算内财政收入对GDP 的回归模型,建立EViews 文件,利用地方预算内财政收入(Y )和GDP 的数据表,作散点图可看出地方预算内财政收入(Y )和GDP 的关系近似直线关系,可建立线性回归模型: t t t u GDP Y ++=21ββ 利用EViews 估计其参数结果为即 ˆ20.46110.0850t tY GDP =+ (9.8674) (0.0033)t=(2.0736) (26.1038) R 2=0.9771 F=681.4064经检验说明,深圳市的GDP 对地方财政收入确有显著影响。
20.9771R =,说明GDP 解释了地方财政收入变动的近98%,模型拟合程度较好。
模型说明当GDP 每增长1亿元时,平均说来地方财政收入将增长0.0850亿元。
计量经济学课后习题答案郭存芝

计量经济学郭存芝版1~9章答案第一章1.计量经济学是一门什么样的学科?答:计量经济学的英文单词是Econometrics,本意是“经济计量”,研究经济问题的计量方法,因此有时也译为“经济计量学”。
将Econometrics译为“计量经济学”是为了强调它是现代经济学的一门分支学科,不仅要研究经济问题的计量方法,还要研究经济问题发展变化的数量规律。
可以认为,计量经济学是以经济理论为指导,以经济数据为依据,以数学、统计方法为手段,通过建立、估计、检验经济模型,揭示客观经济活动中存在的随机因果关系的一门应用经济学的分支学科。
2.计量经济学与经济理论、数学、统计学的联系和区别是什么?答:计量经济学是经济理论、数学、统计学的结合,是经济学、数学、统计学的交叉学科(或边缘学科)。
计量经济学与经济学、数学、统计学的联系主要是计量经济学对这些学科的应用。
计量经济学对经济学的应用主要体现在以下几个方面:第一,计量经济学模型的选择和确定,包括对变量和经济模型的选择,需要经济学理论提供依据和思路;第二,计量经济分析中对经济模型的修改和调整,如改变函数形式、增减变量等,需要有经济理论的指导和把握;第三,计量经济分析结果的解读和应用也需要经济理论提供基础、背景和思路。
计量经济学对统计学的应用,至少有两个重要方面:一是计量经济分析所采用的数据的收集与处理、参数的估计等,需要使用统计学的方法和技术来完成;一是参数估计值、模型的预测结果的可靠性,需要使用统计方法加以分析、判断。
计量经济学对数学的应用也是多方面的,首先,对非线性函数进行线性转化的方法和技巧,是数学在计量经济学中的应用;其次,任何的参数估计归根结底都是数学运算,较复杂的参数估计方法,或者较复杂的模型的参数估计,更需要相当的数学知识和数学运算能力,另外,在计量经济理论和方法的研究方面,需要用到许多的数学知识和原理。
计量经济学与经济学、数学、统计学的区别也很明显,经济学、数学、统计学中的任何一门学科,都不能替代计量经济学,这三门学科简单地合起来,也不能替代计量经济学。
山东财经大学计量经济学习题

计量经济学习题第一、二章单选题:1.计量经济学是一门()学科。
A.数学 B 。
经济C 。
统计D 。
测量2.狭义计量经济模型是指()。
A 。
投入产出模型B 。
数学规划模型C.包含随机方程的经济数学模型D.模糊数学模型3.计量经济模型分为单方程模型和()。
A.随机方程模型 B 。
行为方程模型C.联立方程模型D.非随机方程模型4.经济计量分析的工作程序()A 。
设定模型,检验模型,估计模型,改进模型B 。
设定模型,估计参数,检验模型,应用模型C 。
估计模型,应用模型,检验模型,改进模型D 。
搜集资料,设定模型,估计参数,应用模型5.同一统计指标按时间顺序记录的数据列称为()A 。
横截面数据 B.时间序列数据C.修匀数据 D 。
平行数据6.判断模型参数估计量的符号、大小、相互之间关系的合理性属于()准则.A 。
经济计量准则B 。
经济理论准则C 。
统计准则 D.统计准则和经济理论准则7.对下列模型进行经济意义检验,哪一个模型通常被认为没有实际价值的()。
A.i C (消费)i I 8.0500+=(收入)B.di Q (商品需求)i I 8.010+=(收入)i P 9.0+(价格)C.si Q (商品供给)i P 75.020+=(价格)D.i Y (产出量)6.065.0i K =(资本)4.0iL (劳动) 8。
回归分析中定义的()A 。
解释变量和被解释变量都是随机变量B 。
解释变量为非随机变量,被解释变量为随机变量C.解释变量和被解释变量都为非随机变量D.解释变量为随机变量,被解释变量为非随机变量9.最小二乘准则是指使()达到最小值的原则确定样本回归方程.A.()∑=-n t tt Y Y 1ˆ B 。
∑=-nt t t Y Y 1ˆ C.t t Y Y ˆmax - D 。
()21ˆ∑=-n t t t Y Y10. 参数估计量βˆ是i Y 的线性函数称为参数估计量具有( )的性质.A.线性B.无偏性C.有效性 D 。
计量经济学课后习题答案

第一章1.计量经济学是一门什么样的学科?答:计量经济学的英文单词是Econometrics,本意是“经济计量”,研究经济问题的计量方法,因此有时也译为“经济计量学”。
将Econometrics译为“计量经济学”是为了强调它是现代经济学的一门分支学科,不仅要研究经济问题的计量方法,还要研究经济问题发展变化的数量规律。
可以认为,计量经济学是以经济理论为指导,以经济数据为依据,以数学、统计方法为手段,通过建立、估计、检验经济模型,揭示客观经济活动中存在的随机因果关系的一门应用经济学的分支学科。
2.计量经济学与经济理论、数学、统计学的联系和区别是什么?答:计量经济学是经济理论、数学、统计学的结合,是经济学、数学、统计学的交叉学科(或边缘学科)。
计量经济学与经济学、数学、统计学的联系主要是计量经济学对这些学科的应用。
计量经济学对经济学的应用主要体现在以下几个方面:第一,计量经济学模型的选择和确定,包括对变量和经济模型的选择,需要经济学理论提供依据和思路;第二,计量经济分析中对经济模型的修改和调整,如改变函数形式、增减变量等,需要有经济理论的指导和把握;第三,计量经济分析结果的解读和应用也需要经济理论提供基础、背景和思路。
计量经济学对统计学的应用,至少有两个重要方面:一是计量经济分析所采用的数据的收集与处理、参数的估计等,需要使用统计学的方法和技术来完成;一是参数估计值、模型的预测结果的可靠性,需要使用统计方法加以分析、判断。
计量经济学对数学的应用也是多方面的,首先,对非线性函数进行线性转化的方法和技巧,是数学在计量经济学中的应用;其次,任何的参数估计归根结底都是数学运算,较复杂的参数估计方法,或者较复杂的模型的参数估计,更需要相当的数学知识和数学运算能力,另外,在计量经济理论和方法的研究方面,需要用到许多的数学知识和原理。
计量经济学与经济学、数学、统计学的区别也很明显,经济学、数学、统计学中的任何一门学科,都不能替代计量经济学,这三门学科简单地合起来,也不能替代计量经济学。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Sig- F 1.25E-05
(7)计算
x 与 y 的决定系数: R 2 0.966
(8)对回归方程进行 F 检验:因为 Sig-f=1.25E-5<1%,所以通过α=1%的总体显著性检验(F 检验) 。
6. 解:(1)描述投诉率是如何依赖航班按时到达正点率的的回归方程及显著性检验如下:
ˆ 6.018 0.070 x y t (5.719 ** )(4.967 ** ) R 2 0.779, F 24.674
即在任意两次观测时, ui , u j 是相互独立的,不相关的,也就是无序列相关。 假定4: Cov (ui , xi ) =0。即解释变量 xi 与误差项 ui 同期独立无关。因为如果两者相关,就不可能把 区分开来。 假定5: ui
x 对 y 的影响和 u 对 y 的影响
~ N (0, u 2 ) 。即对于给定的 xi , ui 为服从正态分布的随机变量。
(1)绘制散点图;
x 与 y 之间是否大致呈线性关系? ˆ;
(3)用最小二乘法求出回归方程; (4)求回归标准误差
(5)给出回归系数的置信度为 95%的区间估计; (6)给出回归方程的方差分解表; (7)计算
x 与 y 的决定系数;
(8)对回归方程进行 F 检验。 6.美国各航空公司业绩的统计数据公布在《华尔街日报 1999 年年鉴》 (The Wall Street Journal Almanac 1999)上。航班正点到达的比率和 每 10 万名乘客投诉的次数的数据如下。 航空公司名称 西南(Southwest)航空公司 大陆(Continental)航空公司 西北(Northwest)航空公司 美国(US Airways)航空公司 联合(United)航空公司 美洲(American)航空公司 德尔塔(Delta)航空公司 美国西部(Americawest)航空公司 环球(TWA)航空公司 航班正点率(%) 81.8 76.6 76.6 75.7 73.8 72.2 71.2 70.8 68.5 投诉率(次/10 万名乘客) 0.21 0.58 0.85 0.68 0.74 0.93 0.72 1.22 1.25
显著。反之,可以推测总体线性相关关系不显著,即
1 与零没有显著差异,回归方程不显著。
5. 解: (1)利用 EXCEl 绘制 xy 散点图,如下所示:
(2)通过 xy 的散点图,可以明显的看出
x 与 y 之间大致呈线性关系。 ˆ 5.714 3.869 x y
(3)利用最小二乘法可以求出回归方程如下:
11.49578 0.403572 0.542989
1. 解:一般说来,随机项 u 来自以下几个方面: (1)变量的省略。由于人们认识的局限不能穷尽所有的影响因素或由于受时间、费用、数据质量等制约而没有引入模型之中的对被解释变量 有一定影响的自变量。 (2)统计误差。数据搜集中由于计量、计算、记录等导致的登记误差;或由样本信息推断总体信息时产生的代表性误差。
Included observations: 10 Variable C X R-squared Adjusted R-squared S.E. of regression Coefficient 32.22076 0.800953 0.048024 -0.070973 Std. Error 33.20478 1.260800 Mean dependent var S.D. dependent var t-Statistic 0.970365 0.635273 Prob. 0.3603 0.5430 48.40000 65.10368 11.43526
67.37438 Akaike info criterion
1
Sum squared resid Log likelihood Durbin-Watson stat
36314.46 -55.17632 2.514737
Schwarz criterion F-statistic Prob(F-statistic)
( xi x ) 2 1 ( x ) Var ( y i ) n ( xi x ) 2
( xi x ) 2 ( xi x ) 1 2 2 [ 2 x x ] u2 2 2 2 n ( xi x ) n ( ( xi x ) ) ( xi x ) 2 1 2 ( xi x ) 2 2 [ x x ] u n ( ( xi x ) 2 ) 2 n ( xi x ) 2 1 x2 [ ] u2 2 n ( xi x )
资料来源:(美)David R.Anderson 等《商务与经济统计》 ,第 405 页,机械工业出版社。 (1)求出描述投诉率是如何依赖航班按时到达正点率的的回归方程,并进行显著性检验。 (2)对估计的回归方程的斜率作出解释。 (3)如果航班按时到达的正点率为 80%,估计每 10 万名乘客投诉的次数是多少? 7.下面是对某个案例分析的 EViews 输出结果。该案例的回归分析结果是否理想?为什么? Dependent Variable: Y Method: Least Squares Date: 05/28/03 Sample: 1991 Time: 10:25 2000
思考与练习 1. 随机误差项 u 包括哪些内容? 2. 一元线性回归模型有哪些基本假定? 3.证明公式(2.16) 、公式(2.17) 。 4.理解样本决定系数的含义。 5.若我们搜集两个变量的历史资料如下:
x 销售收入 y
广告费 (2)
1 10
2 14
3 18
4 20
5 25
6 28
7 30
8 40
思考与练习 1.写出多元线性回归模型的一般形式。 2.多元线性回归模型的基本假定有哪些? 3.写出
u 2 的无偏估计量的计算公式。
4.如果一个样本回归方程的样本决定系数为 0.98,我们能否判定这个样本回归方程就很理想? 5.根据例 3.1 数据,利用 OLS 的正规方程组,估计样本回归方程。 6.已知我国 1990 年~1999 年的货运量 y、工业总产值 x1.农业总产值 x2 资料如下表所示: 年份 1990 1991 1992 1993 1994 1995 1996 1997 1998 1999 要求计算: (1)二元线性回归方程 (2)对系数、方程分别进行显著性检验。 (3)当工业总产值达到 130000 亿元,农业总产值达到 25000 亿元时,货运量能达到多少?(给定置信水平为 95%) 货运量(万吨) 970602 985793 1045899 1115771 1180273 1234810 1296200 1278087 1267200 1292650 工业总产值(亿元) 23924 26625 34599 48402 70176 91894 99595 113733 119048 126111 农业总产值(亿元) 7662.1 8157.0 9084.7 10995.5 15750.5 20340.9 22353.7 23788.4 24541.9 24519.1
2
(2) Cov (
ˆ , ˆ ) E{[ ˆ E ( ˆ )][ ˆ E ( ˆ )]} E[( ˆ )( ˆ )] 0 1 0 0 1 1 0 0 1 1 ˆ x y E ( ˆ ) x ][ ˆ E ( ˆ )]} x E[ ˆ E ( ˆ )] 2 E{[ y 1 1 1 1 1 1 ˆ) x Var ( 1
4. 答: ESS 是由回归方程确定的,也就是由自变量
可解释平方和。不难看出,回归平方和(可解释平方和) 小,说明回归的效果就越好,即样本回归线 为样本决定系数,记为
ˆ ˆ x 与样本观测值 ( x , y ) 拟合得越好。为此我们把回归平方和占总平方和的比重定义 ˆi y i i 0 1 i
4
7.以下是某个案例的方差分解结果,填上所缺数据。 ANOVA Model 1 Regression Residual Total 71776.951 Sum of Squares 42555.461 df Mean Square 6079.352 F 4.785 Sig. .002
a. Predictors: (Constant), X8, X6, X1, X7, X2, X5, X3 b. Dependent Variable: Y 8.以下是某个案例的 EViews 分析结果。你对分析结果满意吗?为什么? Dependent Variable: Y Method: Least Squares Sample(adjusted): 1991 2000 Included observations: 10 after adjusting endpoints Variable C X1 X2 X3 R-squared Adjusted R-squared S.E. of regression Sum squared resid Log likelihood Durbin-Watson stat Coefficient 4.826789 0.178381 0.688030 -022644 0.852805 0.779207 16.11137 1557.457 -39.43051 1.579994 Std. Error 917366 0.308178 009899 0.156400 Mean dependent var S.D. dependent var Akaike info criterion t-Statistic 0.523663 0.578827 377910 -1.423556 Prob. 0.6193 0.5838 0.0169 0044 41.90000 348783 8.686101 8.807135 11.58741 0.006579
ˆ 0.418 。 y
7. 解:不理想,从相关的检验数据来看,拟合优度检验 R2=0.048024,F=0.403572(Sig-f=0.542989) ,t=0.635273 (P=0.543,一次项回归系数) ,显 然各类检验结果均不理想,说明该模型无论从总体而言还是从单个解释变量而言都是不显著的。