实验一 词法分析器的设计
词法分析程序实验报告

词法分析程序实验报告篇一:词法分析器_实验报告词法分析器实验报告实验目的:设计、编制、调试一个词法分析子程序-识别单词,加深对词法分析原理的理解。
实验要求:该程序要实现的是一个读单词过程,从输入的源程序中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分界符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(一)实验内容(1)功能描述:对给定的程序通过词法分析器弄够识别一个个单词符号,并以二元式(单词种别码,单词符号的属性值)显示。
而本程序则是通过对给定路径的文件的分析后以单词符号和文字提示显示。
(2)程序结构描述:函数调用格式:参数含义:String string;存放读入的字符串 String str; 存放暂时读入的字符串 char ch; 存放读入的字符 int rs 判断读入的文件是否为空 char []data 存放文件中的数据 int m;通过switch用来判断字符类型,函数之间的调用关系图:函数功能:Judgement()判断输入的字符并输出单词符号,返回值为空; getChar() 读取文件的,返回值为空;isLetter(char c) 判断读入的字符是否为字母的,返回值为Boolean类型; switch (m) 判断跳转输出返回值为空;isOperator(char c)判断是否为运算符的,返回值为Boolean类型; isKey(String string)判断是否为关键字的,返回值为Boolean类型; isDigit(char c) 判断读入的字符是否为数字的,返回值为Boolean类型。
(二)实验过程记录:本次实验出错3次,第一次无法输出双运算符,于是采用双重if条件句进行判断,此方法失败,出现了重复输出,继续修改if语句,仍没有成功。
然后就采用了直接方法调用解决此问题。
对于变量的判断,开始忘了考虑字母和数字组成的变量,结果让字母和数字分家了,不过改变if语句的条件,解决了此问题。
编译原理实验报告

编译原理实验报告一、实验目的本次编译原理实验的主要目的是通过实践加深对编译原理中词法分析、语法分析、语义分析和代码生成等关键环节的理解,并提高实际动手能力和问题解决能力。
二、实验环境本次实验使用的编程语言为 C/C++,开发工具为 Visual Studio 2019,操作系统为 Windows 10。
三、实验内容(一)词法分析器的设计与实现词法分析是编译过程的第一个阶段,其任务是从输入的源程序中识别出一个个具有独立意义的单词符号。
在本次实验中,我们使用有限自动机的理论来设计词法分析器。
首先,我们定义了单词的种类,包括关键字、标识符、常量、运算符和分隔符等。
然后,根据这些定义,构建了相应的状态转换图,并将其转换为程序代码。
在实现过程中,我们使用了字符扫描和状态转移的方法,逐步读取输入的字符,判断其所属的单词类型,并将其输出。
(二)语法分析器的设计与实现语法分析是编译过程的核心环节之一,其任务是在词法分析的基础上,根据给定的语法规则,判断输入的单词序列是否构成一个合法的句子。
在本次实验中,我们采用了自顶向下的递归下降分析法来实现语法分析器。
首先,我们根据给定的语法规则,编写了相应的递归函数。
每个函数对应一种语法结构,通过对输入单词的判断和递归调用,来确定语法的正确性。
在实现过程中,我们遇到了一些语法歧义的问题,通过仔细分析语法规则和调整函数的实现逻辑,最终解决了这些问题。
(三)语义分析与中间代码生成语义分析的任务是对语法分析所产生的语法树进行语义检查,并生成中间代码。
在本次实验中,我们使用了四元式作为中间代码的表示形式。
在语义分析过程中,我们检查了变量的定义和使用是否合法,类型是否匹配等问题。
同时,根据语法树的结构,生成相应的四元式中间代码。
(四)代码优化代码优化的目的是提高生成代码的质量和效率。
在本次实验中,我们实现了一些基本的代码优化算法,如常量折叠、公共子表达式消除等。
通过对中间代码进行分析和转换,减少了代码的冗余和计算量,提高了代码的执行效率。
词法分析器的设计与实现

《编译原理》课程实验报告实验题目:某种简单程序语言的词法分析器的设计与实现专业:计算机科学与技术班级:11060341学号:11060341姓名:实验目的:设计一个词法分析程序,理解词法分析器实现的原理,掌握程序设计语言中的各类单词的词法分析方法,加深对词法分析原理的理解。
实验任务:词法分析是从左向右扫描每行源程序的符号,拼成单词,换成统一的二元式(单词种别,单词符号的属性值)表示。
对给定的程序通过词法分析器识别一个个单词符号,并以二元式(单词种别,单词符号的属性值)显示,本程序则是通过对给定程序段分析后以单词符号和文字提示显示)实验流程:程序清单:#include<iostream>#include<cstdio>#include<cstring>using namespace std;int k=0;struct word{char name[10];int kind;} word[1000];char key[35][10]= {"scanf","short","int","long","float","double","char","struct","union","printf","typedef","const","unsigned","signed","extern","register","static","volatile","void","if","else","switch","case","for","do","while","goto","continue","break","default","sizeof","return","include","bool"};bool cmp(char a[]){int i;for(int k=0; k<35; k++){if(strcmp(a,key[k])==0)return 1;}return 0;}int main(){#ifdef LOCALfreopen("in.txt", "r", stdin);freopen("out.txt", "w", stdout);#endifint p,q,flag;char a[1000],b[10],ch;while(gets(a)){p=0;int len=strlen(a);while(p<len){ch=a[p];memset(b,0,sizeof(b));while(ch==' '){p++;ch=a[p];}if((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||ch=='_'){flag=0;q=0;while((ch>='a'&&ch<='z')||(ch>='A'&&ch<='Z')||ch=='_'||(ch>='0'&&ch<='9')) {if((ch>='0'&&ch<='9')||ch=='_')flag=1;b[q++]=ch;p++;ch=a[p];}if(flag==1){strcpy(word[k].name,b);word[k++].kind=1;}else if(flag==0){if(ch=='\''||ch=='"'){strcpy(word[k].name,b);word[k++].kind=2;}else if(cmp(b)==1){strcpy(word[k].name,b);word[k++].kind=3;}else{strcpy(word[k].name,b);word[k++].kind=1;}}}else if((ch>='0'&&ch<='9')||ch=='-'){if(a[t]>='0'&&a[t]<='9'||a[t]>='a'&&a[t]<='z'||a[t]>='A'&&a[t]<='Z'){p++;ch=a[p];if(ch=='-'||ch=='='){b[0]='-';b[1]=ch;strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='-';strcpy(word[k].name,b);word[k++].kind=5;}}else{q=0;b[q++]=ch;p++;ch=a[p];while((ch>='0'&&ch<='9')||ch=='.'){b[q++]=ch;p++;ch=a[p];}strcpy(word[k].name,b);word[k++].kind=2;}}elseif(ch=='('||ch==')'||ch=='['||ch==']'||ch=='{'||ch=='}'||ch==','||ch==';'||ch==':'||ch=='\''||ch=='"')//ch=='('| |ch==')'||ch=='['||ch==']'||ch=='{'||ch=='}'||{b[0]=ch;strcpy(word[k].name,b);word[k++].kind=4;}else if(ch=='%'||ch=='^'){b[0]=ch;strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else if(ch=='+'){p++;ch=a[p];if(ch=='+'||ch=='='){b[0]='+';b[1]=ch;strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='+';strcpy(word[k].name,b);word[k++].kind=5;}}else if(ch=='*'){p++;ch=a[p];if(ch=='*'||ch=='='){b[0]='*';b[1]=ch;strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='*';strcpy(word[k].name,b);word[k++].kind=5;}}else if(ch=='/'){p++;ch=a[p];if(ch=='/'||ch=='='){b[0]='/';b[1]=ch;strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='/';strcpy(word[k].name,b);word[k++].kind=5;}}else if(ch=='='){p++;ch=a[p];if(ch=='='){b[0]=b[1]='=';strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='=';strcpy(word[k].name,b);word[k++].kind=5;}}else if(ch=='>'){p++;ch=a[p];if(ch=='>'||ch=='='){b[0]='>';b[1]=ch;strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='>';strcpy(word[k].name,b);word[k++].kind=5;}}else if(ch=='<'){p++;ch=a[p];if(ch=='<'||ch=='='){b[0]='<';b[1]=ch;strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='<';strcpy(word[k].name,b);word[k++].kind=5;}}else if(ch=='!'){p++;ch=a[p];if(ch=='='){b[0]='!';b[1]='=';strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='!';strcpy(word[k].name,b);word[k++].kind=5;}}else if(ch=='&'){p++;ch=a[p];if(ch=='&'){b[0]=b[1]='&';strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='&';strcpy(word[k].name,b);word[k++].kind=5;}}else if(ch=='|'){p++;ch=a[p];if(ch=='|'){b[0]=b[1]='|';strcpy(word[k].name,b);word[k++].kind=5;ch=a[++p];}else{b[0]='|';strcpy(word[k].name,b);word[k++].kind=5;}}}}for(int i=0; i<k; i++){switch(word[i].kind){case 1:{printf("(标识符,");break;}case 2:{printf("(常量,");break;}case 3:{printf("(关键字,");break;}case 4:{printf("(界符,");break;}case 5:{printf("(运算符,");break;}}printf("%s)\n",word[i].name); }int a1=0,a2=0,a3=0,a4=0,a5=0; for(int i=0;i<k;i++){if(word[i].kind==1)a1++;else if(word[i].kind==2)a2++;else if(word[i].kind==3)a3++;else if(word[i].kind==4)a4++;else if(word[i].kind==5)a5++;}printf("标识符:%d\n常量:%d\n关键字:%d\n界符:%d\n运算符:%d\n",a1,a2,a3,a4,a5);return 0;}运行结果:。
编译原理实验-词法分析器的设计
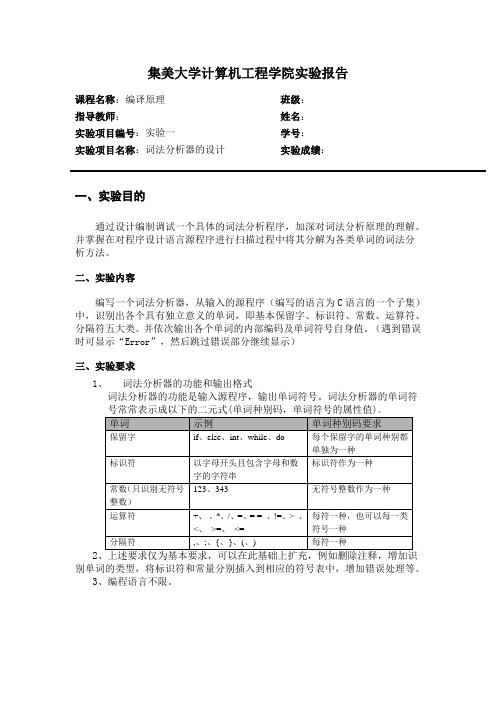
集美大学计算机工程学院实验报告课程名称:编译原理班级:指导教师:姓名:实验项目编号:实验一学号:实验项目名称:词法分析器的设计实验成绩:一、实验目的通过设计编制调试一个具体的词法分析程序,加深对词法分析原理的理解。
并掌握在对程序设计语言源程序进行扫描过程中将其分解为各类单词的词法分析方法。
二、实验内容编写一个词法分析器,从输入的源程序(编写的语言为C语言的一个子集)中,识别出各个具有独立意义的单词,即基本保留字、标识符、常数、运算符、分隔符五大类。
并依次输出各个单词的内部编码及单词符号自身值。
(遇到错误时可显示“Error”,然后跳过错误部分继续显示)三、实验要求1、词法分析器的功能和输出格式词法分析器的功能是输入源程序,输出单词符号。
词法分析器的单词符号常常表示成以下的二元式(单词种别码,单词符号的属性值)。
单词示例单词种别码要求保留字if、else、int、while、do 每个保留字的单词种别都单独为一种标识符以字母开头且包含字母和数字的字符串标识符作为一种常数(只识别无符号整数)123、343 无符号整数作为一种运算符+、-、*、/、=、= = 、!=、> 、<、>=、<= 每符一种,也可以每一类符号一种分隔符,、;、{、}、(、) 每符一种2、上述要求仅为基本要求,可以在此基础上扩充,例如删除注释,增加识别单词的类型,将标识符和常量分别插入到相应的符号表中,增加错误处理等。
3、编程语言不限。
四、实验设计方案1、数据字典本实验用到的数据字典如下表所示:单词示例标识ID1 保留字void、if、else、for、while、do、return、break、main、int、float、char、double、String标识符以字母开头且包含字母和数字的字符串 2无符号整数和小数 3 常数(只识别无符号整数)运算符+、-、*、/、=、> 、<、 4分隔符,、;、{、}、(、) 5 本实验所使用的开发语言是C语言,在Test2类中定义了以下几个函数:2.程序流程图:YNY NNY YN Y N Y YN NN Y YN N N Y Y开始读入文件,把内容存入string 中,m=0,check=ture ,error=false从string 中读出一个字符放入ch 中输出str ,标识为无法识别的串check=ture ,error=falsech 是运算符?error=ture ? check=false ? 输出str ,标识为标示符check=ture 输出str ,标识为运算符输出str ,标识为无法识别的串check=ture ,error=falseerror=ture ? check=false ? 输出str ,标识为标示符check=ture 输出str ,标识为分隔符ch 是分隔符?ch 是数字?check=ture ?清空str ,ch 加到str 中,check=false ch 加到str 中Ch 是字母?check=ture ?清空str ,ch 加到str 中,check=falsech 加到str 中打印出错ch 是最后一个字符? 结束YN Y N3、实验程序#include<stdio.h> #include<string.h> #include<ctype.h> #include<windows.h>//判断读入的字符是否为字母 bool isLetter(char c){if((c >= 'a' && c <= 'z') || (c >= 'A' && c <= 'Z')){ return true; } else return false; }//判断读入的字符是否为数字 bool isDigit(char c){if(c >='0' && c <= '9'){ return true; } else return false; }//判断是否为关键字 bool isKey(char *string) { if(!strcmp(string,"void")|| !strcmp(string,"if")|| !strcmp(string,"for")|| !strcmp(string,"while")|| !strcmp(string,"do")|| !strcmp(string,"return")|| !strcmp(string,"break")|| !strcmp(string,"main")|| !strcmp(string,"int")|| !strcmp(string,"float")|| !st rcmp(string,"char") || !strcmp(string,"double")|| !strcmp(string,"String")) { return true;ch 是数字?ch 加到str 中,error=true ch 是关键字? 输出str ,标识为关键字,check=true}else return false;}bool isError(char ch){if(ch == '@' || ch == '$' || ch == '&' || ch == '#' || ch == '~' || ch == '^'){return true;}elsereturn false;}void main(){char string[500]="";//存放文件中读出来的字符串char str[10]="";//存放需要对比的字符串char ch,c;//ch存放文件中的单个字符(翻译时用),c存放文件中的单个字符(从文件中提取信息时用)char filename[20];//文件名int j=0;printf("请输入文件名进行词法翻译:");scanf("%s",filename);FILE *cfPtr;if((cfPtr=fopen(filename,"r"))==NULL)printf("文件未找到!");else{while(!feof(cfPtr)){if(isspace(c=fgetc(cfPtr))){//判断是否是字符串;}else{string[j]=c;//从文件中一一提取字符j++;}}}int m = 0,k=0;//m翻译时用,k是str数组的下标string[j]=' ';j++;bool check=true,error=false;//用于判断标识for(int i = 0;i < j;i++){//实现语法翻译器switch (m){ch = string[i];if(ch == '+' || ch == '-' || ch == '*' || ch == '/' || ch == '='|| ch == '>' || ch == '<'){if(error){printf("%s,此字符无法是识别!\n",str);error=false;check=true;}else if(!check){printf("(2,%s)标示符\n",str);check=true;}m = 4;}else if(ch == ',' || ch == ';' || ch == '{' || ch == '}' || ch == '(' || ch == ')'){if(error){printf("%s此字符无法识别\n",str);error=false;check=true;}else if(!check){printf("(2,%s)标示符\n",str);check=true;}m = 5;}else if ( isDigit((ch =string[i]) ) ){if(check){memset(str, 0, strlen(str));//清空k=0;str[k]=ch;k++;m = 3;check=false;} else{str[k]=ch;k++;}}else if ( isLetter(ch = string[i]) )if(check){check=false;memset(str, 0, strlen(str));k=0;str[k]=ch;k++;}else{str[k]=ch;k++;if(isKey(str)){printf("(1,%s)关键字\n",str);check=true;}}}else if(isError(ch = string[i])){if(check){memset(str, 0, strlen(str));//清空k=0;str[k]=ch;k++;check=false;error=true;}else{str[k]=ch;k++;error=true;}}else{}break;case 3:if(isLetter(ch =string[i])){printf("程序有错误!!!\n");str[k] = ch;k++;error=true;m = 0;break;}if(isError(ch = string[i])){printf("程序有错误!!!\n");str[k] = ch;k++;error=true;m = 0;break;}if (isDigit((ch =string[i] ) )){str[k] = ch;k++;}else if(ch=='.'){str[k]=ch;k++;}else{printf("( 3,%s) 数字\n",str);i --;m = 0;check=true;}break;case 4:i--;printf("( 4 ,%c) 运算符\n",ch);m = 0;break;case 5:i --;printf("( 5 ,%c) 分隔符\n",ch);m = 0;break;}}return;}五、实验结果六、实验小结本次实验中,运用C语言进行实验,实验刚开始的时候,能够对输入的字符进行判断,但是却不能排错以及只能识别全是字母的标识符,后来经过修改程序代码和编程的逻辑最终实现了,既能排错又能分析句子;通过实验掌握了词法分析,能实现对普通程序的语法分析翻译。
词法分析器实验报告

词法分析器实验报告词法分析器实验报告一、引言词法分析器是编译器中的重要组成部分,它负责将源代码分解成一个个的词法单元,为之后的语法分析提供基础。
本实验旨在设计和实现一个简单的词法分析器,以深入理解其工作原理和实现过程。
二、实验目标本实验的目标是设计和实现一个能够对C语言代码进行词法分析的程序。
该程序能够将源代码分解成关键字、标识符、常量、运算符等各种词法单元,并输出其对应的词法类别。
三、实验方法1. 设计词法规则:根据C语言的词法规则,设计相应的正则表达式来描述各种词法单元的模式。
2. 实现词法分析器:利用编程语言(如Python)实现词法分析器,将源代码作为输入,根据词法规则将其分解成各种词法单元,并输出其类别。
3. 测试和调试:编写测试用例,对词法分析器进行测试和调试,确保其能够正确地识别和输出各种词法单元。
四、实验过程1. 设计词法规则:根据C语言的词法规则,我们需要设计正则表达式来描述各种词法单元的模式。
例如,关键字可以使用'|'操作符将所有关键字列举出来,标识符可以使用[a-zA-Z_][a-zA-Z0-9_]*的模式来匹配,常量可以使用[0-9]+的模式来匹配等等。
2. 实现词法分析器:我们选择使用Python来实现词法分析器。
首先,我们需要读取源代码文件,并将其按行分解。
然后,针对每一行的代码,我们使用正则表达式进行匹配,以识别各种词法单元。
最后,我们将识别出的词法单元输出到一个结果文件中。
3. 测试和调试:我们编写了一系列的测试用例,包括各种不同的C语言代码片段,以测试词法分析器的正确性和鲁棒性。
通过逐个测试用例的运行结果,我们可以发现和解决词法分析器中的问题,并进行相应的调试。
五、实验结果经过多次测试和调试,我们的词法分析器能够正确地将C语言代码分解成各种词法单元,并输出其对应的类别。
例如,对于输入的代码片段:```cint main() {int a = 10;printf("Hello, world!\n");return 0;}```我们的词法分析器将输出以下结果:```关键字:int标识符:main运算符:(运算符:)运算符:{关键字:int标识符:a运算符:=常量:10运算符:;标识符:printf运算符:(常量:"Hello, world!\n"运算符:)运算符:;关键字:return常量:0运算符:;```可以看到,词法分析器能够正确地将代码分解成各种词法单元,并输出其对应的类别。
实验一、词法分析器(含源代码)

词法分析器实验报告一、实验目的及要求本次实验通过用C语言设计、编制、调试一个词法分析子程序,识别单词,实现一个C语言词法分析器,经过此过程可以加深对编译器解析单词流的过程的了解。
运行环境:硬件:windows xp软件:visual c++6.0二、实验步骤1.查询资料,了解词法分析器的工作过程与原理。
2.分析题目,整理出基本设计思路。
3.实践编码,将设计思想转换用c语言编码实现,编译运行。
4.测试功能,多次设置包含不同字符,关键字的待解析文件,仔细察看运行结果,检测该分析器的分析结果是否正确。
通过最终的测试发现问题,逐渐完善代码中设置的分析对象与关键字表,拓宽分析范围提高分析能力。
三、实验内容本实验中将c语言单词符号分成了四类:关键字key(特别的将main说明为主函数)、普通标示符、常数和界符。
将关键字初始化在一个字符型指针数组*key[]中,将界符分别由程序中的case列出。
在词法分析过程中,关键字表和case列出的界符的内容是固定不变的(由程序中的初始化确定),因此,从源文件字符串中识别出现的关键字,界符只能从其中选取。
标识符、常数是在分析过程中不断形成的。
对于一个具体源程序而言,在扫描字符串时识别出一个单词,若这个单词的类型是关键字、普通标示符、常数或界符中之一,那么就将此单词以文字说明的形式输出.每次调用词法分析程序,它均能自动继续扫描下去,形成下一个单词,直到整个源程序全部扫描完毕,从而形成相应的单词串。
输出形式例如:void $关键字流程图、程序流程图:程序:#include<string.h>#include<stdio.h>#include<stdlib.h>#include<ctype.h>//定义关键字char*Key[10]={"main","void","int","char","printf","scanf","else","if","return"}; char Word[20],ch; // 存储识别出的单词流int IsAlpha(char c) { //判断是否为字母if(((c<='z')&&(c>='a'))||((c<='Z')&&(c>='A'))) return 1;else return 0;}int IsNum(char c){ //判断是否为数字if(c>='0'&&c<='9') return 1;else return 0;}int IsKey(char *Word){ //识别关键字函数int m,i;for(i=0;i<9;i++){if((m=strcmp(Word,Key[i]))==0){if(i==0)return 2;return 1;}}return 0;}void scanner(FILE *fp){ //扫描函数char Word[20]={'\0'};char ch;int i,c;ch=fgetc(fp); //获取字符,指针fp并自动指向下一个字符if(IsAlpha(ch)){ //判断该字符是否是字母Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)||IsAlpha(ch)){ //判断该字符是否是字母或数字Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0'; //'\0' 代表字符结束(空格)fseek(fp,-1,1); //回退一个字符c=IsKey(Word); //判断是否是关键字if(c==0) printf("%s\t$普通标识符\n\n",Word);//不是关键字else if(c==2) printf("%s\t$主函数\n\n",Word);else printf("%s\t$关键字\n\n",Word); //输出关键字 }else //开始判断的字符不是字母if(IsNum(ch)){ //判断是否是数字Word[0]=ch;ch=fgetc(fp);i=1;while(IsNum(ch)){Word[i]=ch;i++;ch=fgetc(fp);}Word[i]='\0';fseek(fp,-1,1); //回退printf("%s\t$无符号实数\n\n",Word);}else //开始判断的字符不是字母也不是数字{Word[0]=ch;switch(ch){case'[':case']':case'(':case')':case'{':case'}':case',':case'"':case';':printf("%s\t$界符\n\n",Word); break;case'+':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);//运算符“+=”}else if(ch=='+'){printf("%s\t$运算符\n\n",Word); //判断结果为“++”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“+”}break;case'-':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); }else if(ch=='-'){printf("%s\t$运算符\n\n",Word); //判断结果为“--”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“-”}break;case'*':case'/':case'!':case'=':ch=fgetc(fp);if(ch=='='){printf("%s\t$运算符\n\n",Word);}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'<':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word); //判断结果为运算符“<=”}else if(ch=='<'){printf("%s\t$运算符\n\n",Word); //判断结果为“<<”}else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word); //判断结果为“<”}break;case'>':ch=fgetc(fp);Word[1]=ch;if(ch=='=') printf("%s\t$运算符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$运算符\n\n",Word);}break;case'%':ch=fgetc(fp);Word[1]=ch;if(ch=='='){printf("%s\t$运算符\n\n",Word);}if(IsAlpha(ch)) printf("%s\t$类型标识符\n\n",Word);else {fseek(fp,-1,1);printf("%s\t$取余运算符\n\n",Word);}break;default:printf("无法识别字符!\n\n"); break;}}}main(){char in_fn[30]; //文件路径FILE *fp;printf("\n请输入源文件名(包括路径和后缀名):");while(1){gets(in_fn);//scanf("%s",in_fn);if((fp=fopen(in_fn,"r"))!=NULL) break; //读取文件内容,并返回文件指针,该指针指向文件的第一个字符else printf("文件路径错误!请重新输入:");}printf("\n******************* 词法分析结果如下 *******************\n");do{ch=fgetc(fp);if(ch=='#') break; //文件以#结尾,作为扫描结束条件else if(ch==' '||ch=='\t'||ch=='\n'){} //忽略空格,空白,和换行else{fseek(fp,-1,1); //回退一个字节开始识别单词流scanner(fp);}}while(ch!='#');return(0);}4.实验结果解析源文件:void main(){int a=3;a+=b;printf("%d",a);return;}#解析结果:5.实验总结分析通过本次实验,让再次浏览了有关c语言的一些基本知识,特别是对文件,字符串进行基本操作的方法。
词法分析器的实验报告
词法分析器的实验报告词法分析器的实验报告引言:词法分析器是编译原理中的重要组成部分,它负责将源代码中的字符序列转换为有意义的词法单元,为后续的语法分析提供基础。
本实验旨在设计和实现一个简单的词法分析器,并对其进行测试和评估。
实验设计:1. 词法规则设计:在开始实验之前,我们首先需要设计词法规则,即定义源代码中的合法词法单元。
例如,对于一门类C的语言,我们可以定义关键字(如if、while、int等)、标识符、运算符(如+、-、*等)、分隔符(如()、{}等)等。
2. 有限自动机(DFA)的设计:基于词法规则,我们可以设计一个有限自动机,用于识别和分析源代码中的词法单元。
有限自动机是一个状态转换图,其中每个状态代表一种词法单元,而边表示输入字符的转换关系。
3. 实现代码:根据有限自动机的设计,我们可以使用编程语言(如Python、C++等)实现词法分析器的代码。
代码的主要功能包括读取源代码文件、逐个字符进行词法分析、识别和输出词法单元。
实验过程:1. 词法规则设计:我们以一门简单的算术表达式语言为例,设计了以下词法规则:- 数字:由0-9组成的整数或浮点数。
- 运算符:包括+、-、*、/等。
- 分隔符:包括括号()和逗号,。
- 标识符:以字母开头,由字母和数字组成的字符串。
2. 有限自动机(DFA)的设计:我们基于词法规则,设计了一个简单的有限自动机。
该自动机包含以下状态:- 初始状态:用于读取和识别源代码中的字符。
- 数字状态:用于识别和输出数字。
- 运算符状态:用于识别和输出运算符。
- 分隔符状态:用于识别和输出分隔符。
- 标识符状态:用于识别和输出标识符。
3. 实现代码:我们使用Python编程语言实现了词法分析器的代码。
代码主要包括以下功能:- 读取源代码文件。
- 逐个字符进行词法分析,根据有限自动机的设计进行状态转换。
- 识别和输出词法单元。
实验结果:我们对几个测试样例进行了词法分析,并对结果进行了评估。
实验一 编写词法分析程序
实验一编写词法分析程序1 实验类型设计型实验,4学时。
2 实验目的通过设计、调试词法分析程序,掌握词法分析程序的设计工具,即有穷自动机,进一步理解自动机理论;掌握文法转换成自动机的技术及有穷自动机实现的方法;会确定词法分析器的输出形式及标识符与关键字的区分方法;加深对课堂教学的理解,提高词法分析方法的实践能力。
3 背景知识词法分析作为相对独立的阶段来完成(对源程序或中间结果从头到尾扫描一次,并作相应的加工处理,生成新的中间结果或目标程序)。
在词法分析过程中,编译程序从外部介质中读取源程序文件中的各个字符,为正确地识别单词,有时还需进行超前搜索和回退字符等操作。
因此,为了提高读盘效率和便于扫描器进行工作,通常可采用缓冲输入的方案,即在内存中设置一个适当大小的输入缓冲区,将磁盘上的源程序字符串分批送入该缓冲区中,供扫描器进行处理。
词法分析程序的一般设计方案是:1、程序设计语言词法规则⇒正则文法⇒ FA;或:词法规则⇒正则表达式⇒ FA;2、NFA确定化⇒ DFA;3、DFA最小化;4、确定单词符号输出形式;5、化简后的DFA+单词符号输出形式⇒构造词法分析程序。
从设计方案可知,要构造词法分析程序,必须掌握以下三个知识点:文法、正则表达式和FA。
文法与语言的形式定义如下:一个形式文法G 是下述元素构成的一个元组(V N,V T,P,S )。
其中:1、V T—非空有限的终结符号集,即Σ;终结符:一个语言不可再分的基本符号。
2、V N—非空有限的非终结符号集;非终结符:也称语法变量,用来代表语法范畴。
一个非终结符代表一个一定的语法概念,是一个类(集合)记号,而不是一个体记号。
3、S —开始符号/识别符号,S∈V N;4、P —产生式规则集(或叫规则或生成式或重写规则);产生式:形如α → β或α ::= β的表达式,其中α为左部,β为右部。
α∈(V T∪V N)+且至少含一个V N;β∈(V T∪V N)*。
词法分析器的设计与实现
词法分析器的设计与实现
1.定义词法规则:根据编程语言的语法规范,定义不同的词法规则,
如关键字、标识符、操作符、常量等。
每个词法规则由一个正则表达式或
有限自动机来描述。
2.构建有限自动机:根据词法规则,构建一个有限自动机(DFA)来
识别词法单元。
有限自动机是一种形式化模型,用于在输入字符序列上进
行状态转换。
3.实现状态转换函数:根据有限自动机的定义,实现状态转换函数。
状态转换函数接受一个输入字符,并返回当前状态和输出的词法单元。
4.实现输入缓冲区:为了方便词法分析器的实现,通常需要实现一个
输入缓冲区,用于存储源代码,并提供一些读取字符的函数。
5. 实现词法分析器:将前面实现的状态转换函数和输入缓冲区结合
起来,实现一个完整的词法分析器。
词法分析器可以使用迭代器模式,每
次调用next(函数来获取下一个词法单元。
6.处理错误情况:在词法分析过程中,可能会遇到一些错误情况,如
未定义的词法单元、不符合语法规范的词法单元等。
词法分析器需要能够
检测并处理这些错误情况。
7.构建测试用例:为了验证词法分析器的正确性,需要构建测试用例,包括各种不同的源代码片段,并验证分析结果是否符合预期。
8.进行性能优化:词法分析是编译器中的一个耗时操作,因此可以进
行一些性能优化,如使用缓存机制、减少状态转换次数等。
以上是词法分析器的设计与实现的一般步骤,具体实现过程可能因编程语言和编译器的不同而有所差异。
实验一词法分析的手工构造
实验一词法分析的手工构造1.1.目的通过运行TEST编译器演示系统,直观理解编译程序词法分析的具体过程。
通过手工实现TEST语言词法分析器功能的一个子集,掌握造词法分析器手工构造方法。
1.2.内容从本实验开始,将尝试用不同手段实现一个简化语言(如TEST)编译系统。
词法分析是其第一步。
词法分析目前有不少自动构造工具,其中Le某工具就是一种可以将输入的正规式集合转化为c语言程序的常用工具。
但是为了进一步了解词法分析器的实现细节,本实验的主要内容是采用c语言手工编码的方式来实现TEST语言的词法分析器。
当然在具体实验的过程中大家可以进一步对其进行简化,或者实现另外一种子集定义的语言。
具体实验内容如下:1)TEST编译器演示系统的使用。
2)TEST语言词法规则的学习。
3)手工编写词法分析器的练习。
1.3.知识1.4.步骤在自己编写词法分析器的C语言代码前,可以先运行TEST语言编译器演示程序,理解词法分析的具体过程,然后再参考我提供给大家的VC++词法分析程序。
一定要将参考代码理解掌握,然后自己再模仿该程序编写自己的词法分析器。
在编写词法分析程序时一定要先确定下所处理的语言。
我们实验不对所处理的语言进行统一要求,大家可以实现TEST语言或其进一步简化的版本。
当然,大家也可以对其进行简化或者实现一种已经存在的一种语言,如C,Pacal,Baic的子集。
实验的具体步骤如下:1、定义好所要处理的语言,比如TEST语言。
2、读懂参考代码,在文件夹“词法分析例程(VC版)”下。
3、手工编写词法分析器,比如起名为Demo.c。
4、在C语言编译器中得到其可执行文件Demo.e某e。
5、写一段你所定义语言(比如TEST语言)的测试程序。
如TEST语言中的测试程序:{inta;a=10;}则输出序列为:{{intintIDa;;IDa==NUM10;;}}6、用你所编写的词法分析器Demo.e某e处理测试程序,并根据所定义语言(如TEST)单词编码序列对照输出结果进行验证。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验一词法分析器的设计 (2)1.1 词法分析器的结构和主要任务 (2)1.1.1 输入输出接口 (2)1.1.2 条件限制 (2)1.2 词法分析程序的总体设计 (3)1.3 词法分析程序的详细设计 (4)1.4实验步骤 (5)1.5输入数据 (15)1.6结果输出 (15)实验一词法分析器的设计实验目的:掌握词法分析的概念,设计方法,熟悉高级语言中词法的定义,词法分析程序的编写。
实验要求:在8学时内实现SAMPLE语言的词法分析器,要求用VC窗口界面实现。
实验内容:分为4次实验完成。
1.1 词法分析器的结构和主要任务1.1.1 输入输出接口图1-1词法分析器的输入输出界面词法分析程序的主要任务是从左到右扫描每行源程序,拼成单词,换成统一的内部表示(token)输出,送给语法分析器。
具体包括:1.组织源程序的输入;2.按规则拼单词,并转换成二元形式;3.滤掉空白符,跳过注释、换行符及一些无用的符号(如字符常数的引号)4.进行行列计数,用于指出出错的行列号,并复制出错部分;5.列表打印源程序;6.发现并定位词法错误;7.生成符号表。
token文件和符号表用作语法分析的输入部分。
1.1.2 条件限制本实验可以作如下假定:(1) 假定SAMPLE语言采用自由格式书写;(2) 可以使用注解,用/*……*/或者{……}标识,但注解不能插在单词内部,注解要在一行内结束,若一行结束,没有遇到注释后面的结束标记,自动认为注释也结束;(3) 一行可以有多个语句,一个语句也可以分布在多行中,单词之间和语句之间可以插入任意空格,单词中间不能有空白符号,单词中间也不能有回车换行符,即单词不能跨行书写;(4) 关键字都是保留字。
1.2 词法分析程序的总体设计图1-2 词法分析程序的顶层数据流图图1-2是词法分析程序的顶层数据流图,即是词法分析程序的输入输出界面图,由此可以看出词法分析程序的功能就是从源程序中读入一个个字符,依据一定的构词规则,识别出各类有用的单词。
其中源程序清单和错误信息从屏幕、打印机或文件输出,其余文件均以顺序文件的形式输出到外存储器上,以供下一阶段使用。
由此可以得到更详细的数据流图,如图1-3。
图1-3词法分析程序的详细数据流图在上面的数据流图中,各个加工处理完成的功能如下:加工1.1(读一行并打印):收到读下一行命令后,从源程序读入一行,装入缓冲区,行计数,并打印。
在这里需要注意的是,回车换行在源程序(文本文件)中用两个字符0D0AH 来表示,而用高级语言(C语言)读入内存后,就用一个字符0AH来表示,这是在用高级语言编写词法分析器时常被忽略导致错误的原因。
加工1.2(读一非空字符):收到读一字符命令后,从缓冲区读入一非空字符,列计数。
若缓冲区已空,则再读—行,列计数置0。
加工1.3(分类):根据单词的首字符以决定对不同类单词的处理。
加工1.4(识别标识符);当输入字母时,开始识别标识符或关键宇,边拼写边从缓冲区读入下一符号,当读入一非字母数字符号时,标识符识别完成,但已多读入一个符号,所以列记数回退。
然后查关键字表,判断拼出的符号串是否为关键字。
若是关键字,输出其种别码。
否则识别的单词就是标识符,同时输出标识符及其种别码。
加工1.5(识别常数):当输入数字时,开始识别整数或实数。
边拼写边读入下一符号,当遇到“.”时,还要继续拼写该常数(实数情况)。
如果遇到E,要识别带指数的常数,当遇到其它非数字符号时,数字常数拼写完毕,列计数也要退1。
输出常数及其种别码。
加工1.6(处理注解);当输入“/”时,开始识别注解或除号,若是注解时,最后两个连续读出的符号是“*/”,不需再读下一符号,列计数不变。
当判定是除号“/”时,已多读入一字符,列计数-1,输出“/”的种别码。
加工1.7(识别分界符):识别其它界符,对于<、>、:、|、·等符号,还需要再读入下一符号,判别是否为双界符。
若不是,列计数-1,输出单词的种别码。
加工1.8(识别文字常数):当输入引号时,引号忽略,开始拼写字符常数,不断拼读下一符号,搜索下一个引号,当读入第二个引号时,字符常数拼写结束。
最后列计数不减1,然后输出该常数。
以上加工1.4~1.8都需要从缓冲区A每次读出一个字符,进行列计数。
由于假定每个单词不跨行,所以不用考虑从源程序中读出下一行到缓冲区的功能。
加工1.9(输出TOKEN):对各种界符与关键字输出其相应的二元式(TOKEN),对常数与标识符则让它流入下一个加工。
加工2(查填符号表):如果是标识符或字符常数,首先查看名字栏和类型栏(字符常数的类型栏中填有“字符常数”,标识符栏的类型栏空白)判断有无同名和同类型的入口。
如果有同名入口P1,则把P1作为TOKEN的自身值填入它的二元式中;如果不同名,则将字符中存入字符串表中,把它的长度和在字符串表中的开始位置及其类型(标识符为空白)填入符号表的新入口P中,并把P作为TOKEN的自身值填入的二元式中。
对数字常数的处理如下:先查符号表VAL栏,若发现相同的常数则直接输出其二元式。
若表内无相同的常数,则将数字常数填入符号表内,在TYPE栏内填入整型或实型,然后输出其二元式。
二元式中包含该常数在符号表中的入口。
1.3 词法分析程序的详细设计图1-3的数据流图属于输入-变换-输出形式的变换型数据流图,但加工1.3-1.9构成了典型的事务处理型数据流图。
根据数据流图,可以得到词法分析程序的总体框架,如图1-4。
图1-4词法分析器的程序框架1.4 实验步骤1.4.1 步骤一编写词法分析的总控程序(1) 编写词法分析的主函数scanner( )词法分析的总控程序就是图1-4的程序框架。
词法分析中要使用的函数将逐步在下面的三个实验中分别实现。
要实现词法分析的功能,必须按照总控程序的安排,在适当的位置进行调用,当所有的函数都实现了,就构成了一个完整的词法分析程序。
主函数的描述如下:a. 打开输入源文件,设置行计数器为0;b. 如果源文件没有结束,读入一行到string,行计数+1,设置列计数器为0;c. 如果缓冲区非空,将缓冲区中的符号串分割为一个一个的单词,否则转b。
(区分一个单词结束的方法是:从缓冲区读入一个非空字符,列计数+1,继续读入字符(每读入一个字符,列计数+1),直到一个单词读完(单词结束的标志是单词分隔符,如空格符号、空白符号、换行符和界符等,但单词的分隔符不属于该单词,读入的符号串是否可以构成一个正确的单词,要根据单词的构成规则来判断,不同类别的单词其构词规则不一样,这样就可以根据不同类别的单词的识别函数来判断相应的单词构成是否有错误。
单词的类别是根据读入的该单词的首字符来判断的,可以单独写一个分类函数,根据首字符判断该单词属于关键字、标识符、常数、运算符和界符中的哪一类)。
d. 将识别出来的单词及其种别码写入Token字表中。
e. 根据单词的类别,进行不同的后期处理,如果是标识符或常数,需要将其唯一值填入符号表中。
g. 如果源文件已结束,关闭打开的源文件。
f. 打印token字表和符号表到相应的文件中;(2) 编写分类函数sort()单词分为标识符、常数、关键字、运算符和界符,单词必须分类进行识别。
根据读入该单词的第一个字符进行分类,判断该单词是属于哪一类。
如图1-4,根据单词的分类结果调用相应的识别函数识别一个单词是否正确。
int sort(char ch) /* 传入参数ch为已读入的单词的第一个字符,据此进行分类*/{if(isdigit(ch))return 常数; /* 如果第一个字符是数字,则是数;*/else if(isalpha(ch))return 标识符; /* 如果第一个字符是字母,则是标识符或关键字*/else if(ch=='/')return 注释; /* 如果读入的是/,则可能是注释和除号*/else if(ch=='\'')return 字符常数; /* 如果第一个字符是’,则是字符常数;*/else if(isdelimeter(ch))return 界符; /* 如果出现了定义中的其它符号,则是界符*/elsereturn OTHER; /* 否则出错处理,出现不识别的字符*/}(3) 实验思考题1.为什么要编写分类函数,在词法分析器中起什么作用?2.词法分析的功能是什么?你编写的词法分析程序完成了哪些功能?你认为还有哪些功能是应该实现而你没有实现的功能?3.词法分析程序能给出哪些错误?4.符号表的作用是什么?5.词法分析器是如何定位错误的?【步骤二定义符号表编写查找和插入函数】(1)定义关键字和界符表每一种已经定义的语言的关键字和界符都是固定的,为了给出单词的种别码,我们在编写SAMPLE语言的词法分析器时采取关键字和界符一符一种,标识符、整型常数、实型常数、字符型常数分别给一个种别码,再根据其值定义判断。
Sample语言中的单词(关键字、界符、数的类型)的种别码如表1-1。
表1-1SAMPLE语言单词的编码在C/C++语言中,这些表格可以使用结构数组定义,在pascal中可以使用记录数组定义,也可以使用其它方法来定义,如直接定义成链表的形式,可根据所设计的总体结构自行选择定义方法,具体内容可以根据程序编写的方式采取初值输入方式或后期使用时再输入的方式。
上述表格可以定义成一个整体,也可以分成关键字、界符和各种常数表等多个部分分别定义。
如在C语言中定义关键字如下:structentry{/*定义结构*/charword[10];/*单词本身*/inttoken;/*token值*/};structentrykeyword[]={"and",1,"array",2,"begin",3,"bool",4,"call",5,"case",6,"char",7,"do",9,"else",10};/*存放该语言能识别的关键字*/(2)编写查找函数iskeyword(char*str)和isdelimeter(char*str)判断给定的符号串是否是关键字和界符iskeyword(char*str)函数的功能是:在上述给定的关键字表中查找指定的字符串str是否存在,若存在,返回其种别码(token值),否则返回0。
查找函数可以使用顺序查找,也可以使用折半查找。
例如:使用顺序查找方法查找给定单词key是否是关键字的函数原型和算法描述如下:intiskeyword(char*str)/*设keyword为所有关键字列表*//*该函数返回0表示str不是关键字,不为0表示str是关键字*/{while(关键字表没有结束)if(str=keyword[i].word)返回keyword.token;/*表示str是关键字*/elsei++;返回0;/*表示str不是关键字*/}同样编写查找是否是界符的函数isdelimeter()。