LIST_ENTRY结构图详解
Linux内核中的算法和数据结构

Linux内核中的算法和数据结构算法和数据结构纷繁复杂,但是对于Linux Kernel开发⼈员来说重点了解Linux内核中使⽤到的算法和数据结构很有必要。
在⼀个国外问答平台的Theoretical Computer Science⼦板有⼀篇讨论实际使⽤中的算法和数据结构,Vijay D做出了详细的解答,其中有⼀部分是Basic Data Structures and Algorithms in the Linux Kernel对Linux内核中使⽤到的算法和数据结构做出的归纳整理。
详情参考。
下⾯就以Vijay D的回答作为蓝本进⾏学习总结。
测试⽅法准备由于需要在内核中进⾏代码测试验证,完整编译安装内核⽐较耗时耗⼒。
准备采⽤module形式来验证。
Makefileobj-m:=linked-list.oKERNELBUILD:=/lib/modules/$(shell uname -r)/builddefault:make -C ${KERNELBUILD} M=$(shell pwd) modulesclean:rm -rf *.o *.cmd *.ko *.mod.c .tmp_versionslinked-list.c#include <linux/module.h>#include <linux/init.h>#include <linux/list.h>int linked_list_init(void){printk("%s\n", __func__);return 0;}void linked_list_exit(void){printk("%s\n", __func__);}module_init(linked_list_init);module_exit(linked_list_exit);MODULE_AUTHOR("Arnold Lu");MODULE_LICENSE("GPL");MODULE_DESCRIPTION("Linked list test");安装modulesudo insmod linked-list.ko查找安装情况lsmod | grep linked-list执⾏log<4>[621267.946711] linked_list_init<4>[621397.154534] linked_list_exit删除modulesudo rmmod linked-list链表、双向链表、⽆锁链表, , .有⼀篇关于内核链表《》值得参考。
linux 内核list使用

linux 内核list使用
在Linux内核中,list是一种常用的数据结构,用于实现链表。
它在内核中被广泛使用,包括进程管理、文件系统、网络等多个方面。
在内核中使用list时,有几个常见的操作和用法需要注意:
1. 初始化list,在使用list之前,需要先对其进行初始化。
可以使用宏INIT_LIST_HEAD来初始化一个空的list。
2. 添加元素到list,使用list_add、list_add_tail等函数
可以将新元素添加到list中。
这些函数会在指定位置插入新元素,
并更新相关指针。
3. 遍历list,可以使用list_for_each、
list_for_each_entry等宏来遍历list中的元素。
这些宏会帮助我
们遍历整个list,并执行指定的操作。
4. 删除元素,使用list_del和list_del_init函数可以从
list中删除指定的元素。
需要注意的是,在删除元素之后,需要手
动释放相关资源,以避免内存泄漏。
除了上述基本操作外,list还支持一些高级操作,如合并两个list、反转list等。
在编写内核代码时,合理地使用list可以提高代码的可读性和性能。
总的来说,Linux内核中的list是一种非常灵活和强大的数据结构,合理地使用它可以帮助我们更好地管理和组织数据。
在实际编程中,需要根据具体的需求和场景来选择合适的list操作,以达到最佳的效果。
list_for_each_entry_safe用法

list_for_each_entry_safe用法list_for_each_entry_safe是Linux内核中提供的一个用于遍历链表元素的宏,它与list_for_each_entry宏完全相同,只是list_for_each_entry_safe允许在遍历期间修改链表。
一般在Linux中,创建链表和栈的宏有以下两种:(1)list_add()、list_del()宏;(2)list_for_each_entry()、list_for_each_entry_safe宏 list_for_each_entry()宏的定义如下:#define list_for_each_entry(pos, head, member)ttttfor (pos = list_entry((head)->next, typeof(*pos), member);tt &pos->member != (head); tttttt pos = list_entry(pos->member.next, typeof(*pos), member))先,需要注意上面宏定义中涉及到的list_entry()函数,该函数的作用是从一个链表1成员(list_head类型)中取得链表1所属的数据结构,list_entry函数的定义为/** container_of - cast a member of a structure out to the containing structure* @ptr:tthe pointer to the member.* @type:tthe type of the container struct this is embedded in.* @member:tthe name of the member within the struct.**/#define container_of(ptr, type, member) ({ttttconst typeof( ((type *)0)->member ) *__mptr = (ptr);t t(type *)( (char *)__mptr - offsetof(type,member) );})list_entry的第一个参数是指向struct list_head的指针,第二个参数是包含list_head的数据结构的类型,第三个参数是list_head在数据结构中的成员名称。
Dll 模块隐藏技术

Dll模块隐藏技术学习各种外挂制作技术,马上去百度搜索"魔鬼作坊"点击第一个站进入、快速成为做挂达人。
如果你细细读完这篇文章,你会学到一下内容:1.PEB,TEB,LDR_DATA_TABLE_ENTRY等数据结构2.自己覆盖掉自己执行过的一段代码3.调试这个Dll你会发现DLL_PROCESS_ATTACH中的代码在OD首次停下即加载停止时已经执行完了!多么美妙啊!哈哈,OD不会发现你执行了什么4.本例最后附件有个ASM的控制台程序,用SDK编写,你可以学到用汇编写一个基本的控制台程序的格式5.最后那个控制台源码还包含完整的CreateRemoteThread注入进程的写法本文主要讲的是怎样隐藏一个dll模块,这里说的隐藏是指,dll被加载后怎样使它用一般的工具无法检测出来。
为什么要这么做呢?1.远程线程中的应用(1)大家都知道,远程线程注入主要有两种一种是直接copy母体中预注入的代码到目标进程地址空间(WriteProcessMemory),然后启动注入的代码(CreateRemoteThread),这种远程线程一旦成功实现,那么它只出现在目标进程的内存中,并没有对应的磁盘文件,堪称进程隐藏中的高招,可是缺点就是,你必须要在注入代码中对所有直接寻址的指令进行修正,这可是个力气活,用汇编写起来很烦。
(2)另一种更为常用的方法是注入一个dll文件到目标进程,这种方法的实现可以是以一个消息Hook为由进行注入,或者仍然使用CreateRemoteThread,这种方法的优点是Dll文件自带重定位表,也就是说你不必再为修正直接寻址指令而烦恼了!,dll自己会重定位!~~~嗯,真是不错的方法---可是我们说它不如上面说的方法牛。
为什么?因为它的致命伤就是可以用进程管理工具看见被加载的dll文件名、文件路径。
这真是太不爽了,因为只要用户看看模块列表很容易发现可疑模块!,再依据名字,找到路径,定位文件---dll文件就这样暴露了.这样也就不是很完美的隐藏进程。
线性表的链式存储结构

线性表的链式存储结构
线性表的链式存储结构是指用一组任意的存储单 元(可以连续,也可以不连续)存储线性表中的数据 元素。为了反映数据元素之间的逻辑关系,对于每个 数据元素不仅要表示它的具体内容,还要附加一个表 示它的直接后继元素存储位置的信息。假设有一个线 性表(a,b,c,d),可用下图2所示的形式存储:
27
p
s
图 2-9
28
完整的算法:
int DuListInsert(DuLinkList *L,int i,EntryType e)
if (L.head->next==NULL) return TRUE; else return FALSE; }
12
6. 通过e返回链表L中第i个数据元素的内容 void GetElem(LinkList L,int i,EntryType *e) {
LNode *p; int j; //j为计数器,记载所经过的结点数目 if (i<1||i>ListLength(L)) exit ERROR; //检测i值的合理性 for (p=L.head,j=0; j!=i;p=p->next,j++); //找到第i个结点 *e=p->data; //将第i个结点的内容赋给e指针所指向的存储单元中 }
10
4. 求链表L的长度
int ListLength(LinkList L)
{
LNode *p;
int len;
for(p=L.head, len=0;p->next==NULL; p=p->next,len++);
return(len);
循环条件表达式 重复执行的语句
kernel_list

要实现上述目的就得使用另外一个宏list_entry(): #define list_entry(ptr, type, member) \ ((type*)((char*)(ptr)-(unsigned long)(&((type*)0)-> member))) 其中ptr为list_head结构体指针,type为你所定义的结构体 类型,member是结构体中list_head结构体成员变量的名. type的作用是为了强制转换,即宏中两次用到(type *) 指针ptr指向结构体type中的成员member;通过指针ptr, 返回应用
到这里我们已经理解了内核中双向链表如何实现的,但是我 们如果仅仅到此为止,而没有在我们的程序中应用它,那不 免有些可惜。所以经过改造后的list. h(见源程序),让我们 可以在平时的编程中方便这种结构。程序example2.c(见源 代码example2.c)使用了上述改造后的list. h来实现一系列操 作。
例如前面的例子就可以按如下方式定义: struct my_list{ void *mydata; struct list_head list; }; 几点说明: a) list字段,隐藏了链表的指针特性,但正是它,把我们要 链接的数据组织成了链表。 b) struct list_head可以位于结构的任何位置 c) 可以给struct list_head起任何名字。 d) 在一个结构中可以有多个list
为了方便大家阅读,我把上面的结构体写成这样 ( (type*) ( (char*)(ptr) (unsigned long) (&((type*)0)->member) ) ) 这个表达式最终的结果就是type 型的地址, ((size_t) &(type *)0)->member)把0地址转化为type结构的 指针,然后获取该结构中member成员的指针,并将其强制转 换为size_t类型。于是,由于结构从0地址开始定义,因此,这 样求出member的成员地址,实际上就是它在结构中的偏移量. 然后ptr减去这个偏移量就得到了所要的结构体指针。
Linux内核分析及编程
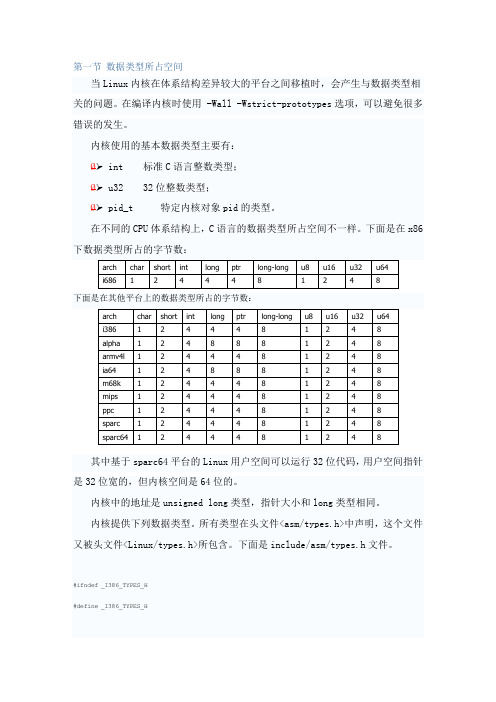
其中基于sparc64平台的Linux用户空间可以运行32位代码,用户空间指针是32位宽的,但内核空间是64位的。
内核中的地址是unsigned long类型,指针大小和long类型相同。
内核提供下列数据类型。
所有类型在头文件<asm/types.h>中声明,这个文件又被头文件<Linux/types.h>所包含。
下面是include/asm/types.h文件。
#ifndef _I386_TYPES_H#define _I386_TYPES_H#ifndef __ASSEMBLY__typedef unsigned short umode_t;// 下面__xx类型不会损害POSIX 名字空间,在头文件使用它们,可以输出给用户空间typedef __signed__ char __s8;typedef unsigned char __u8;typedef __signed__ short __s16;typedef unsigned short __u16;typedef __signed__ int __s32;typedef unsigned int __u32;#if defined(__GNUC__) && !defined(__STRICT_ANSI__)typedef __signed__ long long __s64;typedef unsigned long long __u64;#endif#endif /* __ASSEMBLY__ *///下面的类型只用在内核中,否则会产生名字空间崩溃#ifdef __KERNEL__#define BITS_PER_LONG 32#ifndef __ASSEMBLY__#include <Linux/config.h>typedef signed char s8;typedef unsigned char u8;typedef signed short s16;typedef unsigned short u16;typedef signed int s32;typedef unsigned int u32;typedef signed long long s64;typedef unsigned long long u64;/* DMA addresses come in generic and 64-bit flavours. */ #ifdef CONFIG_HIGHMEM64Gtypedef u64 dma_addr_t;#elsetypedef u32 dma_addr_t;#endiftypedef u64 dma64_addr_t;#ifdef CONFIG_LBDtypedef u64 sector_t;#define HAVE_SECTOR_T#endiftypedef unsigned short kmem_bufctl_t;#endif /* __ASSEMBLY__ */#endif /* __KERNEL__ */#endif下面是Linux/types.h的部分定义。
【转载】64位Windows内核虚拟地址空间布局(基于X64CPU)

【转载】64位Windows内核虚拟地址空间布局(基于X64CPU)对于原⽂中,较难理解或者论述过于简单的部分,则添加了译注;译注来⾃于内核调试器验证的结果,以及 WRK 源码中的逻辑,还有《深⼊解析 Windows 操作系统》⼀书中的译⽂。
本⽂档解释 X64 版本的 Windows 7 与 Server 2008 R2 上,内核虚拟地址空间的细节。
调试器扩展命令 !CMKD.kvas 应⽤这⼀理论来显⽰X64 虚拟地址空间,并且将⼀个给定的地址映射到其中⼀个地址范围。
内核虚拟地址布局X64 CPU 仅⽀持 64 位虚拟地址中的 48 位,这 48 位虚拟地址被运⾏在该 CPU 上的软件使⽤。
对于⽤户模式地址,64 位虚拟地址中的⾼16 位总是被设置为 0x0;对于内核模式地址,总是设置为 0xF。
这有效地将 X64 地址空间分开成2部分——⽤户模式地址的范围:0x00000000`00000000~0x0000FFFF`FFFFFFFF;内核模式地址的范围:0xFFFF0000`00000000~0xFFFFFFFF`FFFFFFFF。
此内核虚拟地址范围总计为 256 TB,⽤于 Windows 上可访问的全部内核虚拟地址空间。
然后,Windows 静态划分此空间成多个固定⼤⼩的虚拟地址范围(VA),每个范围被赋予特定⽤途。
每个范围的起始和结束地址如下表所⽰:因此,为了简化处理器芯⽚架构以及避免⾮必要的开销——尤其是地址翻译⽅⾯(后⾯会讨论)—— 当前 AMD 和 Intel 的 x64 处理器仅实现了 16 EB 虚拟地址空间中的 256 TB。
换⾔之,⼀个 64 位的虚拟地址中,仅有低 48 位被实现(使⽤)。
然⽽,虚拟地址仍旧是 64 位宽,在寄存器中,或存储在内存中,它们都占⽤ 8 字节。
虚拟地址中的⾼ 16 位(⽐特位 48~63)需要被设置成与最⾼的“实现位”(也就是⽐特位 47)相同的值,这是通过⼀种类似于⼆进制补码运算的符号扩展来完成的。