应用统计学作业
应用统计学作业答案

第1章导论作业1指出下面的变量哪一个属于分类变量:A、年龄B、工资C、汽车产量D、购买商品时的方式(现金、信用卡、支票)我的答案:D得分:4.3分2指出下面哪个变量属于顺序变量:A、年龄B、工资C、汽车产量D、员工对企业某项改革措施的态度(赞成、中立、反对)我的答案:D得分:4.3分3指出下面哪一个变量属于数值型变量:A、年龄B、性别C、企业类型D、员工对企业某项改革措施的态度(赞成、中立、反对)我的答案:A得分:4.3分4一名统计学专业的学生为了完成其统计作业,在《统计年鉴》中找到了2006年城镇家庭的人均收入。
这一数据属于:A、分类数据B、顺序数据C、截面数据D、时间序列数据我的答案:C得分:4.3分5下列不属于描述统计问题的是:A、根据样本信息对总体进行的推断了解数据分布的特征C、分析感兴趣的总体特征D、利用图、表或其他数据汇总工具分析数据我的答案:A得分:4.3分6某大学的一位研究人员希望估计该大学本科生平均每月的生活费支出,为此,他调查了200名学生,发现他们每月平均生活费支出是500元。
该研究人员感兴趣的总体是:A、该大学的所有学生B、该校所有大学生的总生活费支出C、该大学所有的在校本科生D、所调查的200名学生我的答案:C得分:5.4分7某大学的以为研究人员希望估计该大学本科生平均每月的生活费支出,为此,他调查了200名学生,发现他们每月平均生活费支出是500元。
该研究人员感兴趣的参数是:A、该大学的所有学生人数B、该大学所有本科生的月平均生活费支出C、该大学所有本科生的月生活费支出D、所调查的200名学生的月平均生活费支出我的答案:B得分:4.3分8某大学的以为研究人员希望估计该大学本科生平均每月的生活费支出,为此,他调查了200名学生,发现他们每月平均生活费支出是500元。
该研究人员感兴趣的统计量是:A、该大学的所有学生人数B、该大学所有本科生的月平均生活费支出该大学所有本科生的月生活费支出D、所调查的200名学生的月平均生活费支出我的答案:D得分:4.3分9在下列叙述中,采用推断统计方法的是:A、用饼图描述某企业职工的学历构成B、从一个果园中采摘36个橘子,利用这36个橘子的平均重量估计果园中橘子的平均总量C、一个城市在1月份的平均汽油价格D、反映大学生统计学成绩的条形图我的答案:B得分:4.3分10一项民意调查的目的是想确定年轻人愿意与其父母讨论的话题。
统计学作业——精选推荐

《应用统计学》第一阶段作业一、 选择题1. 一个容量为20的样本数据,分组后,组距与频数如下: 组 距]20,10( ]30,20( ]40,30( ]50,40( ]60,50( ]70,60( 频 数2 3 4 5 4 2 则样本在]50,10(上的频率为( D) A .201 B .41 C .21 D .107 2. 对总数为N 的一批零件抽取一个容量为30的样本,若每个零件被抽取的概率为0.25,则N 等于 ( B )A. 100B. 120C. 150D. 2003. 某校为了了解学生的课外阅读情况,随机调查了50名学生,得到他们在某一天各自课外阅读所用时间的数据,结果用下面的条件图表示,根据条形图可得这50名学生这一天平均每人的课外阅读时间为 ( B )051015200小时1小时2小时0小时0.5小时1小时1.5小时2小时A 0.6小时B 0.9小时C 1.0小时D 1.5小时4.一个样本的方差是])15()15()15[(101S 21022212-+⋅⋅⋅+-+-=x x x ,则这个样本的平均数与样本容量分别是 ( C )A .10,10B .6,15C .15.10D .由1021x x ,x ⋅⋅⋅确定,10 5.从甲、乙两种玉米苗中各抽10株,测得它们的株高分别如下:(单位:cm )甲 25 41 40 37 22 14 19 39 21 42乙 27 16 44 27 44 16 40 40 16 40根据以上数据估计 ( D )A .甲种玉米比乙种玉米不仅长得高而且长得整齐B .乙种玉米比甲种玉米不仅长得高而且长得整齐C .甲种玉米比乙种玉米长得高但长势没有乙整齐D .乙种玉米比甲种玉米长得高但长势没有甲整齐二、 简答题1.用公式表示概率的三大性质性质2 0()1≤≤P A性质3 ()1,()0P PΩ=Φ=2. 写出几种常用随机变量分布离散型:二项分布、泊松分布、超几何分布连续型:均匀分布、正态分布、指数分布、其他分布三、计算题某学院数学课程考试成绩资料如下:按成绩分组学生人数60~70 1570~80 3080~90 2590~100 10合计80计算考试成绩的众数、中位数、均值和标准差。
应用统计学作业
F=
= 40.1965
13 − 1 − 1
对给定的α =0.01,查 F(1,11)得临界值λ =9.65,由于 F>λ ,检验效果显著,拒绝 H0,即 回归方程有意义。
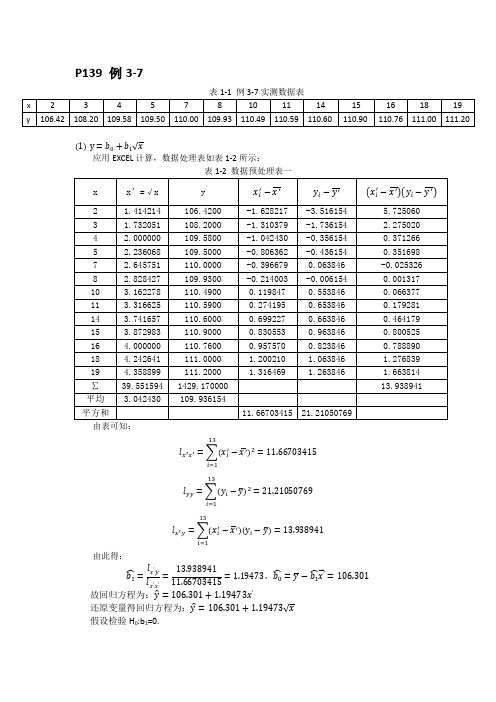
(2) y = ������0 + ������1 ������ 应用 EXCEL 计算,数据处理表如表 1-3 所示: 表 1-3 数据预处理表二
������������′ − ������ ′
������������ − ������ ′
2 1.414214 3 1.732051 4 2.000000 5 2.236068 7 2.645751 8 2.828427 10 3.162278 11 3.316625 14 3.741657 15 3.872983 16 4.000000 18 4.242641 19 4.358899 ∑ 39.551594 平均 3.042430 平方和 由表可知:
������������′ − ������ ′
������������ − ������ ′
2 0.500000 3 0.333333 4 0.250000 5 0.200000 7 0.142857 8 0.125000 10 0.100000 11 0.090909 14 0.071429 15 0.066667 16 0.062500 18 0.055556 19 0.052632 ∑ 2.050882 平均 0.157760 平方和 由表可知:
2.168044 0.764783 0.112390 0.095367 -0.004631 0.000089 0.045623 0.080925 0.151691 0.249122 0.236028 0.359205 0.456411 4.715045
中国石油大学(华东)《应用统计学》在线作业(一)

《应用统计学》在线作业(一)总指数的计算形式分为()A:数量指标指数和质量指标指数B:综合指数和平均指数C:加权算术平均数指数和加权调和平均数D:固定构成指数和结构影响指数参考选项:B说明现象在较长时期内发展的总速度的指标是( )。
A:环比发展速度B:平均发展速度C:定基发展速度D:定基增长速度参考选项:C如果一个变量的取值完全依赖于另一个变量,各观测点落在一条直线上,则称这两个变量之间为()。
A:完全相关关系B:正线性相关关系C:非线性相关关系D:负线性相关关系参考选项:A人口普查规定标准时间是为了( )。
A:避免登记的重复和遗漏B:确定调查对象的范围C:确定调查单位D:确定调查时限参考选项:A标志是说明总体单位特征的名称,标志有数量标志和品质标志,因此()。
A:标志值有两大类:品质标志值和数量标志值B:品质标志才有标志值C:数量标志才有标志值D:品质标志和数量标志都具有标志值参考选项:C每一吨铸铁成本(元)倚铸件废品率(%)变动的回归方程为:yc=56+8x, 这意味着( )。
A:废品率每增加1%,成本每吨增加64元B:废品率每增加1%,成本每吨增加8%C:废品率每增加1%,成本每吨增加8元D:废品率每增加1%,则每吨成本为56元参考选项:C题目和选项如下:A:AB:BC:CD:D参考选项:C假设检验中,如果原假设为假,而根据样本所得到的检验结论是不拒绝原假设,则可认为()。
A:抽样是不科学的B:检验结论是正确的C:犯了第一类错误D:犯了第二类错误参考选项:D社会经济统计的研究对象是()。
A:抽象的数量关系B:社会经济现象的规律性C:社会经济现象的数量特征和数量关系D:社会经济统计认识过程的规律和方法参考选项:C平均发展速度是( )。
A:定基发展速度的算术平均数B:环比发展速度的算术平均数C:环比发展速度的几何平均数D:增长速度加上100%参考选项:C统计一词包含统计工作、统计资料和统计学三种含义。
东华《应用统计学》平时作业

(单选题) 1: 计算向上累计频数及频率时,各组累计数的意义是各组()A: 上限以下的累计频数或频率B: 上限以上的累计频数或频率C: 下限以上的累计频数或频率D: 下限以下的累计频数或频率正确答案:(单选题) 2: 当所有的观测值y都落在直线yc=a+bx上时,则x与y之间的相关系数为()。
A: Y=0B: 丨y丨=±1C: -1<y<1D: 0<y<1正确答案:(单选题) 3: 下列指标中属于时期指标的是()A: 企业数B: 在册职工人数C: 某种商品的销售量D: 某地区2004年人口数正确答案:(单选题) 4: 置信概率定得愈大,则置信区间相应()。
A: 愈小B: 愈大C: 变小D: 有效正确答案:(单选题) 5: 单项式分组适合运用于()A: 连续性数量标志B: 品质标志C: 离散性数量标志中标志值变动范围比较小D: 离散型数量标志中标志值变动范围很大正确答案:(单选题) 6: 已知各期环比增长速度为2%、5%、8%和7%,则相应的定基增长速度的计算方法为()。
A: (102%×105%×108%×107%)-100%B: 102%×105%×108%×107%C: 2%×5%×8%×7%D: (2%×5%×8%×7%)-100%正确答案:(单选题) 7: 一个统计总体()A: 只能有一个标志B: 可以有多个标志C: 可以有多个指标D: 只能有一个指标正确答案:(单选题) 8: 抽样平均误差是()。
A: 抽样指标的标准差B: 总体参数的标准差C: 样本变量的函数D: 总体变量的函数正确答案:(单选题) 9: 下列各项中属于数量指标的是()A: 动生产率B: 产量C: 人口密度D: 资金利税率正确答案:(单选题) 10: 计算某厂工人平均月工资时,权数是下述哪个指标?()A: A、工人数B: 全月劳动工时总数C: 每一个工人平均月工资D: 车间工人月工资总额正确答案:(单选题) 11: 电站按发电量的分配数列,变量是:(甲)电站个数;(乙)发电量。
应用统计学作业(专)

1、统计调查的种类(1)按调查对象包括的范围不同可分为全面调查和非全面调查全面调查是对被调查对象中所有的单位全部进行调查,其主要目的是要取得总体的全面、系统、完整的总量资料。
如普查。
全面调查要耗费大量的人力、物力、财力和时间。
非全面调查是对被调查对象中一部分单位进行调查。
如重点调查、典型调查、抽样调查和非全面统计报表等。
全面调查和非全面调查是以调查对象所包括的单位范围不同来区分的,而不是以最后取得的结果是否反映总体特征的全面资料而言的。
(2)按登记时间是否连续,可分为经常性调查与一次性调查经常性调查,是随着调查对象在时间上的发展变化,而随时对变化的情况进行连续不断的登记。
其主要目的是获得事物全部发展过程及其结果的统计资料。
一次性调查:是不连续登记的调查,它是对事物每隔一段时期后在一定时点上的状态进行登记。
其主要目的是获得事物在某一时点上的水平、状况的资料。
一次性调查又分为定期和不定期两种。
定期调查是每隔一段固定时期进行一次调查,不定期调查是时间间隔不完全相等,而且间隔很久才调查一次。
(3)按调查的组织方式不同,可分为统计报表制度和专门调查统计报表制度:它是按照国家统一规定的调查要求与文件(指标、表格形式、计算方法等)自下而上的提供统计资料的一种报表制度。
专门调查:是为了某一特定目的而专门组织的统计调查。
包括:普查、抽样调查、重点调查、典型调查等。
①普查:普查是专门组织一次性的全面调查,用来调查属于一定时点或时期内的社会经济现象的总量。
普查要遵循以下几点:a.确定普查的标准时间:普查的标准时间是指登记调查单位项目所依据的统计时点。
所有的调查资料都必须是反映这一时点上的情况。
例如,我国第四人口普查,1990年7月1日零时为普查登记的标准时点。
凡是在这个时点以前死亡和这个时点以后出生的,都不能计入这次普查的人口数内。
这样才可避免所登记的生重复或遗漏。
b.普查的登记工作应在整个普查范围内同时进行,以保证普查资料的实效性、准确性,避免资料的搜集工作拖的太久。
应用统计学作业

作业(第7章)、问答题1.什么是方差分析?它有哪些类型?答:方差分析就是检验多个总体均值是否相等的统计方法。
可以分为单因素分析和双因素分析。
2.方差分析有哪些基木假定?答:每个总体都服从正态分布;各总体的方差必须相同;观察值是独立的。
3.方差分析的基本思想是什么?答:方差分析的基本思想是:通过分析研究不同来源度的变异对总变异的贡献大小,而确定可控因素对研究结果影响力的大小。
4.解释总误差平方和、组间误差平方和、组内误差平方和的含义。
答:总误差平方和,全部观察值与总平均的误差的平方和组间误差平方和,每组均值与总的均值之间的离差。
又因为考虑到这种离差可能是对每组的处理方法不同引起的,我们又把它称为处理的平方和。
组内误差平方和,根据n个观察值拟合适当的模型后,余下未能拟合部份(ei 二y 1y平均)称为残差,其中y平均表示n个观察值的平均值,所有n个残差平方之和称为组内平方和。
5.方差分析中多重比较的作用是什么?答:进一步检验到底有哪些均值之间有差异。
6.什么是交互作用?解释有交互作用的双因素方差分析和无交互作用的双因素方差分析。
答:两个因素在不同水瓶的搭配会对因变量产生新的影响。
二、选择题1.方差分析作为一种统计研究方法,研究的是(B )。
2 .3 .4 .5 .6 .7 . A.分类变量之间的关系C.数值型变量与分类型变量之间的关系D.分类型变量与数值型变量之间的关系方差分析中检验统计量的抽样分布是(A.正态分布C. F分布单因素方差分析中,A. n 1C. n k单因素方差分析中,MSAA.MSTMSEC.MSA单因素方差分析中,A. F FC. F F /2B.数值型变量之间的关系B.D.分布分布组内误差平方和对应的自由度是下列检验统计量止确的是(给定显著性水平有交互作用的双因素方差分析中,rstA.i 1 jB.D.B.D.MSEMSTMSAMSE,确定拒绝原假设的是B. F FD. F F /2反映交互作用的误差平方和是(2(xijk x)lkl(xgjg x)2jl有交互作用的双因素方差分析中,A. F[ (r 1), rs (t 1)]C. F[(r 1) (s 1), rs(tB. st (Xi g g x)ilrsiljlijg x igggjg检验交互作用的统计量服从(B. F[ (s 1), rs (t 1)1计算题1)]D. F[ (r 1) (s 1), rs]1.某化学公司需要采购一批用于混合原料的机器, 经过一番调研分析后, 小到A > B. C三家制造商,该公司还收集了这三家制造商的机器关于混合原料所需时间X)2)O采购范圉缩料所需平均时间是否相同?设二0.05 o表7.1三家制造商的机器关于混合一批原料所需时间制造商2.选择检验统计量并计算其值:F二10.63636364>4. 263.统计决断:dfb二2, dfw=9, F (2,9) 0. 05=4. 26F二10. 63636364>4. 26, P<0. 05,拒绝HO,接受Hl。
应用统计学作业

应用统计学作业
P64−T6统计描述
均值标准差方差和平方和最小值位数中位数73.73 12.36 152.65 3318.00 251364.00 50.00 65.50 74.00
上四分位数最大值极差众数的 N 均值标准误
83.50 99.00 49.00 72, 74 3 1.84
P127−T6参数估计
假定标准差 = 0.9
N 均值标准差均值标准误 95% 置信区间
40 3.230 1.601 0.142 (2.951, 3.509)
假定标准差 = 0.95
N 均值标准差均值标准误 95% 置信区间
40 3.230 1.601 0.150 (2.936, 3.524)
P146−T5方差分析
原假设:来自不同家庭职业背景的学员计算机培训成绩无显著差异
F=7.66
F∝(t-1,n-t)=F∝(2,20)=3.49
F> F∝
拒绝原假设,即来自不同家庭职业背景的学员计算机培训成绩有显著差异
P185−T2线性回归
(1)建立一元线性回归模型
回归方程为:y = 2.09 + 1.93 x
(2)计算相关系数R,取显著性水平∝=0.05,对回归模型进行显著性检验
R= 99.5%u
(3)计算估计标准误S y
S y=0.05433。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
为研究探讨肾细胞癌转移受哪些因素的影响,本文收集了某研究人员收集的一批行根治性肾切除术患者的肾癌标本资料,并利用线性回归分析方法进行分析。
这里,被解释变量为肾细胞癌转移情况(y),解释变量为确诊时患者的年龄(X1) 、肾细胞癌血管内皮生长因子(X2)、肾细胞癌组织内微血管数(X3)、肾癌细胞核组织学分级(X4)、肾细胞癌分期(X5),结束变量筛选策略先采用强制进入策略(Enter),并作多重共线性检测,分析结果如下:
整的判定系数R—2、回归方程的估计标准误差。
由于调整的判定系数(0.603)不是很接近于1,
因此认为拟合优度不是很高,被解释变量可以被模型解释的部分较少,为能被解释的部分较多。
由上表可知,被解释变量的总离差平方和为5.885,回归平方和及均方分别为4.015和0.803,剩余平方和及均方分别为1.869和0.093,F检验统计量的观测值为8.591,对应的概率p近似为0.依据该表可进行回归方程显著性检验。
如果显著性水平为0.05,由于概率p值小
于显著水平,应拒绝回归方程显著性检验的零假设,认为各回归系数不同时为0,被解释变量与解释变量全体的线性关系是显著的,可建立线性模型。
由上表可知,如果显著水平为0.05,除了肾癌细胞核组织学分级和肾细胞癌血管内皮生长因子(VEGF)以外,其他变量的回归系数显著性t检验的概率p值都大于显著水平,因此不应拒绝原假设,认为这些偏回归系数与0无显著性差异,它们与被解释变量的线性关系不显著,
建模。
从容忍度和方差膨胀因子看,肾癌细胞核组织学分级与其他解释表里那个的多重共线性较严重,在重新建模时是可考虑剔除该变量。
依据上表可进行多重共线性检测。
从方差比来看,第5个特征根既能解释肾癌细胞核组织
学分级的89%也可以解释肾细胞癌血管内皮生长因子(VEGF)的25%,同时还解释肾细胞癌分期的15%,因此有理由认为这些变量间确实存在多重共线性;从条件指数看,第5,6个条件指数都大于10,说明变量间确实存在多重共线性。
总之,通过上述分析指导上面的回归方程存在一些不容忽视的问题,应该重建回归方程。
这里我采用向后筛选策略完成观测检验并进行残差分析和强影响点探测。
Variables Entered/Removed b
Model Variables Entered Variables Removed Method
1 肾细胞癌分期期, 确诊时患
者的年龄(岁), 肾细胞癌
组织内微血管数(MVC) ,
肾细胞癌血管内皮生长因子
(VEGF), 肾癌细胞核组织学
分级
. Enter
2 . 肾细胞癌分期期Backward (criterion: Probability of
F-to-remove >= .100).
3 . 肾细胞癌组织内微血
管数(MVC) Backward (criterion: Probability of F-to-remove >= .100).
4 . 确诊时患者的年龄
(岁)Backward (criterion: Probability of F-to-remove >= .100).
a. All requested variables entered.
b. Dependent Variable: 肾细胞癌转移情况(有转移y=1; 无转移y=0)。
e
a. Predictors: (Constant), 肾细胞癌分期期, 确诊时患者的年龄(岁), 肾细胞癌组织内微血
管数(MVC) , 肾细胞癌血管内皮生长因子(VEGF), 肾癌细胞核组织学分级
b. Predictors: (Constant), 确诊时患者的年龄(岁), 肾细胞癌组织内微血管数(MVC) , 肾
细胞癌血管内皮生长因子(VEGF), 肾癌细胞核组织学分级
c. Predictors: (Constant), 确诊时患者的年龄(岁), 肾细胞癌血管内皮生长因子(VEGF), 肾
癌细胞核组织学分级
d. Predictors: (Constant), 肾细胞癌血管内皮生长因子(VEGF), 肾癌细胞核组织学分级
e. Dependent Variable: 肾细胞癌转移情况(有转移y=1; 无转移y=0)。
由上表知,利用向后筛选策略共经过四步完成回归方程的建立,最终模型为第四个模型。
从方程的建立过程看,随着解释变量的不断减少方程的拟合优度下降了。
依次剔除方程的变量是
肾细胞癌分期、肾细胞癌组织内微血管数(MVC)、确诊时患者的年龄(岁)。
如果显著性水平
为0.05,可以看到这些被剔除的变量的偏F检验的概率p值均大于显著水平,因此不能拒绝检验的零假设,这些变量的偏回谷啊系数与零无显著差异,他们对被解释变量的线性解释没有显著贡献,不应保留在方程中。
最终保留在方程中的变量是肾癌细胞核组织学分级和肾细胞癌血
上表中的第四个模型是最终的方程。
如果显著水平为0.05,由于回归方程显著性检验的概率p值小于显著性水平,因此被解释变量与解释变量间的线性关系显著,建立线性模型是恰当的。
上表中,如果显著水平为0.05,则前三个模型中由于存在回归系数不显著的解释变量,因此这些方程都不可用,第四个模型是最终的方程,其回归系数显著性检验的概率p值小于显著水平,因此肾细胞癌血管内皮生长因子(VEGF)和肾癌细胞核组织学分级与被解释变量间的线性关系显著,它保留在模型中是合理的。
最终的回归方程是,立项课题数=—0.619+0.258肾细胞癌血管内皮生长因子(VEGF)+0.182肾癌细胞核组织学分级,意味着胞癌血管内皮生长因子(VEGF)每增加一个单位会使立项课题数平均增加0.258个单位,肾癌细胞核组织学分级每增加一个单位会使立项课题数平均增加0.182个单位。
上表展示了变量剔除方程的过程。
各数据项的含义依次是:在剔除其他变量的情况下,如果该变量保留在模型中其标准化回归系数,t检验值和概率p值将是什么。
上图中,数据点围绕基准线存在一定的规律性。