One-class svm for learning in image retrieval
支持向量机(SVM)、支持向量机回归(SVR):原理简述及其MATLAB实例

支持向量机(SVM)、支持向量机回归(SVR):原理简述及其MATLAB实例一、基础知识1、关于拉格朗日乘子法和KKT条件1)关于拉格朗日乘子法2)关于KKT条件2、范数1)向量的范数2)矩阵的范数3)L0、L1与L2范数、核范数二、SVM概述1、简介2、SVM算法原理1)线性支持向量机2)非线性支持向量机二、SVR:SVM的改进、解决回归拟合问题三、多分类的SVM1. one-against-all2. one-against-one四、QP(二次规划)求解五、SVM的MATLAB实现:Libsvm1、Libsvm工具箱使用说明2、重要函数:3、示例支持向量机(SVM):原理及其MATLAB实例一、基础知识1、关于拉格朗日乘子法和KKT条件1)关于拉格朗日乘子法首先来了解拉格朗日乘子法,为什么需要拉格朗日乘子法呢?记住,有需要拉格朗日乘子法的地方,必然是一个组合优化问题。
那么带约束的优化问题很好说,就比如说下面这个:这是一个带等式约束的优化问题,有目标值,有约束条件。
那么你可以想想,假设没有约束条件这个问题是怎么求解的呢?是不是直接 f 对各个 x 求导等于 0,解 x 就可以了,可以看到没有约束的话,求导为0,那么各个x均为0吧,这样f=0了,最小。
但是x都为0不满足约束条件呀,那么问题就来了。
有了约束不能直接求导,那么如果把约束去掉不就可以了吗?怎么去掉呢?这才需要拉格朗日方法。
既然是等式约束,那么我们把这个约束乘一个系数加到目标函数中去,这样就相当于既考虑了原目标函数,也考虑了约束条件。
现在这个优化目标函数就没有约束条件了吧,既然如此,求法就简单了,分别对x求导等于0,如下:把它在带到约束条件中去,可以看到,2个变量两个等式,可以求解,最终可以得到,这样再带回去求x就可以了。
那么一个带等式约束的优化问题就通过拉格朗日乘子法完美的解决了。
更高一层的,带有不等式的约束问题怎么办?那么就需要用更一般化的拉格朗日乘子法,即KKT条件,来解决这种问题了。
oneclasssvm原理

oneclasssvm原理
One-Class SVM(支持向量机)是一种用于异常检测的机器学习算法。
它的原理基于支持向量机的思想,旨在通过构建一个边界来区分正常样本和异常样本。
One-Class SVM的原理可以分为以下几个步骤:
1. 数据预处理:首先,将训练数据集中的正常样本作为训练样本,不包含异常样本。
这些正常样本被假设为来自同一分布。
2. 特征转换:接下来,对训练样本进行特征转换,将其映射到高维空间中。
这可以通过使用核函数(如线性核、多项式核或高斯核)来实现。
3. 构建边界:在高维空间中,One-Class SVM试图找到一个超平面,使得正常样本位于超平面的一侧,而异常样本位于另一侧。
这个超平面被称为决策边界。
4. 寻找支持向量:One-Class SVM选择离决策边界最近的一些正常样本作为支持向量。
这些支持向量将决定决策边界的位置。
5. 异常检测:对于新的未知样本,通过计算其在高维空间中与决策边界的距离来进行异常检测。
如果距离超过某个阈值,那么该样本被判定为异常。
One-Class SVM的原理基于正常样本的分布特点,通过构建一个边界来区分正常样本和异常样本。
它在异常检测领域有着广泛的应用,例如网络入侵检测、欺诈检测等场景。
one-class分类方法

one-class分类方法一类分类(One-Class Classification)是指仅有一种已知类别的分类问题,这种方法广泛应用于异常检测、数据压缩等领域。
一类分类方法主要用于从一个数据集中找出属于“正常”类的样本,而不是识别“异常”类的样本,因此称为单类分类或异常检测。
一类分类方法的目标是将“正常”和“异常”样本分离开来,通过学习“正常”样本的特点来建立模型。
当新的样本进入系统时,模型将通过计算其与“正常”样本的差异来决定其是属于“正常”还是“异常”类。
在实际应用中,一类分类方法遇到了许多实际问题,如数据分布不均匀、样本数据过少等。
近年来,研究者们已经为这些问题提出了多种解决方法。
接下来,我们将介绍一些经典的一类分类方法及其应用情况。
1. One-Class SVM支持向量机(Support Vector Machine,SVM)是机器学习中常用的一种分类算法。
在一类分类问题中,SVM被扩展为一类分类SVM(One-Class SVM)。
在一类分类SVM中,模型只考虑正样本。
模型的目标是找到一个超平面,将正样本分离出来,同时最小化这个超平面与其他点之间的距离。
通过这种方法,模型可以自适应地选择一个最优符合数据分布的超平面,并将“正常”样本与“异常”样本分开。
One-Class SVM适用于高维空间和非线性分类。
实际应用中的例子有:文本分类、图像分类、医学诊断、网络安全等领域。
2. Deep One-Class Classification深度一类分类(Deep One-Class Classification)通过深度神经网络模型加强了一类分类的性能。
该方法通过从数据集中提炼特征,优化数据的表示,从而提高一类分类的效果。
深度神经网络模型包含一系列的隐藏层和非线性激活函数。
通过前向传播,网络模型可以从原始数据中学习到高级特征,并在后续层中优化这些特征。
与传统的一类分类不同,深度一类分类方法不仅仅是为了提取特征,更希望深度模型能够更好地拟合数据分布,从而提高一类分类的精度和鲁棒性。
单类支持向量机(One-ClassSVM)

单类⽀持向量机(One-ClassSVM)假如现在有ℓ个同⼀分布的观察数据,每条数据都有p个特征。
如果现在加⼊⼀个或多个观察数据,那么是否这些数据与原有的数据⼗分不同,甚⾄我们可以怀疑其是否属于同⼀分布呢?反过来讲,是否这些数据与原有的数据⼗分相似,我们⽆法将其区分呢?这便是异常检测⼯具和⽅法需要解决的问题。
即现在只有正常的数据,那么当异常数据加⼊时,我们是否可以将其分辨出来呢?通常情况下,要学习训练出⼀个在p维空间上的粗糙封闭的边界线,来分割出初始观测分布的轮廓线。
然后,如果观测数据位于边界限定的⼦空间内,则认为它们来⾃与初始观测相同的总体。
否则,如果他们在边界之外,我们可以在⼀定程度上说他们是异常的。
OCSVM⼀种实现⽅法是 One-Class SVM (OCSVM),⾸次是在论⽂《Support Vector Method for Novelty Detection》中由 Bernhard Schölkopf 等⼈在 2000 年提出,其与 SVM 的原理类似,更像是将零点作为负样本点,其他数据作为正样本点,来训练⽀持向量机。
策略是将数据映射到与内核相对应的特征空间,在数据与原点间构建超平⾯,该超平⾯与原点呈最⼤距离。
现在假设该超平⾯为:w⋅Φ(x)−ρ=0⽬标就是在分类正确的基础上最⼤化超平⾯与原点的距离:max同时根据超平⾯的定义,实际上\rho的正负和w向量中的元素正负同时调整就不会影响超平⾯,那么假如\rho > 0,那么优化问题可以重写为:\mathop{ \max} \limits_ { w \in F , \rho \in \mathbb { R } } { \rho} / { \| w \| ^ { 2 }}为了防⽌参数求解的耦合问题,可以将其拆解为\begin{aligned} \mathop{ \max} \limits_ { w \in F , \rho \in \mathbb { R } } { \rho} + 1/{ \| w \| ^ { 2 }} \\ \mathop{ \min} \limits_ { w \in F , \rho \in\mathbb { R } } - { \rho} + { \| w \| ^ { 2 }} \end{aligned}这样的话在求解问题时,由于w向量中元素的整体正负不会影响{ \| w \| ^ { 2 }}的取值,那么其会保证\rho的最终取值为正值,也就是满⾜假设。
SVM模式识别与回归软件包(LibSVM)详解
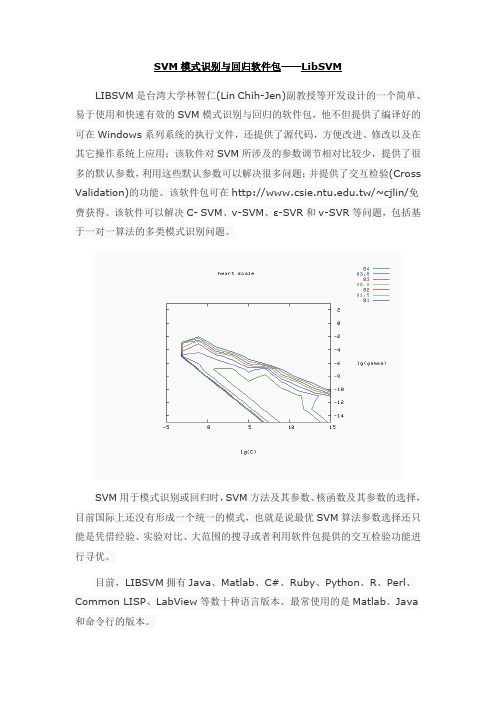
SVM模式识别与回归软件包——LibSVMLIBSVM是台湾大学林智仁(Lin Chih-Jen)副教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数可以解决很多问题;并提供了交互检验(Cross Validation)的功能。
该软件包可在.tw/~cjlin/免费获得。
该软件可以解决C- SVM、ν-SVM、ε-SVR和ν-SVR等问题,包括基于一对一算法的多类模式识别问题。
SVM用于模式识别或回归时,SVM方法及其参数、核函数及其参数的选择,目前国际上还没有形成一个统一的模式,也就是说最优SVM算法参数选择还只能是凭借经验、实验对比、大范围的搜寻或者利用软件包提供的交互检验功能进行寻优。
目前,LIBSVM拥有Java、Matlab、C#、Ruby、Python、R、Perl、Common LISP、LabView等数十种语言版本。
最常使用的是Matlab、Java 和命令行的版本。
就要做有关SVM的报告了!由于SVM里面的有关二次优化的不是那么容易计算得到的,最起码凭借我现在的理论知识和编程能力是不能达到!幸好,现在又不少的SVM工具,他可以帮助你得到支持向量(SV),甚至可以帮助你得到预测结果,归一化数据等等。
其中SVM-light,LibSVM是比较常用的!SVM-light我们实验室有这方面的代码,而我自己就学习了下怎么使用LIBSVM(来自台湾大学林智仁)。
实验步骤如下:1:首先安装LIBSVM,这个不用多说,直接去他的官网上看:.tw/~cjlin/libsvm/index.html2:处理数据,把数据制作成LIBSVM的格式,其每行格式为:label index1:value1 index2:value2 ...其中我用了复旦的分类语料库,当然我先做了分词,去停用词,归一化等处理了3:使用svm-train.exe训练,得到****.model文件。
SVM Aggregation SVM, SVM Ensemble, SVM Classification Tree

SVM Aggregation: SVM, SVM Ensemble, SVM Classification TreeBy Shaoning Pang1. IntroductionSupport Vector Machine (SVM), since first proposed by Vapnik and his group at AT\&T laboratory has been extensively studied and discussed to develop its working principle of classification and regression. As a result, different types of SVM and SVM extensions [1] have been proposed. Suykens introduced the quadratic cost function in SVM and proposed LSSVM (Least Squares Support Vector Machine). Mangasarian et al. used an implicit Lagrangian reformulation in SVM, and proposed LSVM (Lagrangian Support Vector Machine) and NSVM (Newton Support Vector Machine). Later, Lee and Mangasarian used a smooth unconstrained optimization in SVM, and had SSVM (Smooth Support Vector Machine). Recently, new interesting SVM models were published, such as, Chun-fu Lin's FSVM (Fuzzy Support Vector Machine). Zhang et al proposed HSSVMs (Hidden Space Support Vector Machines). Shilton et al. proposed an incremental version of SVM. All these SVM types have significantly enhanced the original SVM performance. Most importantly, they have applied the original SVM to suit different real application needs.SVM aggregation, as an alternative aspect of SVM study, specializes on combining a family of concurrent SVMs for advanced artificial intelligence. The well known SVM aggregation methods are the One-against-all and One-against-one methods. The purpose of such aggregations is to expand SVM binary classification to multi-class classification. A typical procedure of SVM aggregation can be summarized as three steps, SVM model selection, convex aggregation, and aggregation training.Over the last 5 years, I have been working on SVM aggregation, and have developed the original single SVM classification in our previous work, to SVM ensemble for classification, SVM classification tree (including 2-class SVM tree (2-SVMT), and Multi-class SVMT tree (m-SVMT)). Evolving SVM classification tree is an ongoing research topic of adapting SVMTto the incremental learning of data stream by evolving SVM and SVM tree structure.2. SVM EnsembleIn SVM ensemble, individual SVMs are aggregated to make a collective decision in several ways such as the majority voting, least-squares estimation-based weighting, and the double layer hierarchical combing. The training SVM ensemble can be conducted in the way of bagging or boosting. In bagging, each individual SVM is trained independently using the randomly chosen training samples via a boostrap technique. In boosting, each individual SVM is trained using the training samples chosen according to the sample’s probability distribution that is updated in proportion to the error in the sample. SVM ensemble is essentially a type of cross-validation optimization of single SVM, having a more stable classification performance than other models. The details on SVM ensemble construction and application are described in [2,3].3. 2-class SVM Tree (2-SVMT)The principle of SVMT is to encapsulate a number of binary SVMs into a multi-layer hierarchy by adapting a "divide and conquer" strategy. The benefits of SVMT model can be summarized as: (1) SVMT is capable of effectively reducing classification difficulties from class mixture and overlap through a supervised LLE data partitioning.(2) Importantly, SVMT outperforms single SVM and SVM ensemble on the robustness to class imbalance.A 2-class SVM tree can be modeled under the ‘depth first’ policy. The employed partitioning function for depth first is a binary data splitting whose targeting function is to partition all samples of class 1 into one cluster and all samples of class 2 into the other cluster. 2-SVMT of this type is particularly useful for the 2-class task with serious class overlap. Fig 1 shows an example of 2-class SVM binary tree over a face membership authentication [3,4] case with 30 of 271 persons as membership group.Fig. 1.Example of 2-class SVM binary treeAlternatively, a 2-class SVM tree also can be modeled under the ‘width first’ policy, where the employed partitioning function is a multiple data splitting, and the targeting function for partitioning here is to steer data samples in the same cluster with the same class label. A multiple data splitting is capable of controlling the size of the tree to a limited size, which is very optimal for decision making in such a tree structural model. Fig 3 gives an example of 2-class SVM multiple tree over the same case of face membership authentication as Fig. 2.Fig. 2.Example of 2-class SVM multiple tree.3. multi-class SVM Tree (m -SVMT)The above SVMTs are merely two-class SVM classification tree (2-SVMT) model, which are not sustainable for normal multi-class classification tasks. However in real application, class imbalance of multi-class problem is also a critical challenge for most classifiers, thus it is desirable to develop a multi-class SVM tree with the above properties of 2-SVMT.Fig. 3.Example m-SVMT over a 3 class taskThe construction of m-SVMT [9] is to decompose an m -class task into a certain number of 1-m classes regional tasks, under the criterion of minimizing SVM tree loss function. The proposed m-SVMT is demonstrated very competitive in discriminability as compared to other typical classifiers such as single SVMs, C4.5, K-NN, and MLP neural network, and particularly has a superior robustness to class imbalance, which other classifiers can not match. Fig.3 gives an example of m-SVMT for a 3-class task.4. Evolving SVMT, an ongoing research topicLearning over datasets in real-world application, we often confront difficult situations where a complete set of training samples is not given in advance. Actually in most of cases, data is being presented as a data stream where we can not know what kind of data, even what class of data, is coming in the future. Obviously, one-pass incremental learning gives a method to deal with such data streams [8,9].For the needs of incremental learning over data stream, I am working to realize a concept of evolving SVM classification tree (eSVMT) for the classification of streaming data, where chunks of data is being presented at different time. The constructed eSVMT is supposed to be capable of accommodating new data by adjusting SVM classification tree as in the simulation shown in Fig. 4.Fig.4. A simulation of evolving SVM classification treeT=1 T=2 T=3T=4T=5The difficulty for eSVMT modelling is, (1) eSVMT needs to acquire knowledge with a single presentation of training data, and retaining the knowledge acquired in the past without keeping a large number of training samples in memory. (2) eSVMT needs to accommodate new data continuously, while always keeping a good size of SVM tree structure, and a good classification in real time.Acknowledgement:The research reported in the article was partially funded by the ministry of Education, South Korea under the program of BK21, and the New Zealand Foundation for Research, Science and Technology under the grant: NERF/AUTX02-01. Also the author would like to present the thanks to Prof. Nik Kasabov of Auckland University of Technology, Prof. S. Y.Bang, and Prof. Dajin Kim of Pohang University of Science and Technology, for their support and supervision during 2001 to 2005, when most of the reported research in this article was carried out.References:1.;; /dmi/2.Hyun-Chul Kim, Shaoning Pang, Hong-Mo Je, Daijin Kim, Sung Yang Bang: Constructing support vector machine ensemble. Pattern Recognition vol. 36, no. 12, pp. 2757-2767, 20033.Shaoning Pang, D. Kim, S. Y. Bang, Membership authentication in the dynamic group by face classification using SVM ensemble. Pattern Recognition Letters, vol. 24, no. (1-3), pp. 215-225, 2003.4.Shaoning Pang, D. Kim, S. Y. Bang, Face Membership Authentication Using SVM Classification Tree Generated by Membership-based LLE Data Partition, IEEE Trans. on Neural Network, vol. 16 no. 2, pp. 436-446, 2005.5.Shaoning Pang, Constructing SVM Multiple Tree for Face Membership Authentication. ICBA 2004, Lecture Notes in Computer Science 3072, pp. 37-43, Springer 2004.6.Shaoning Pang, Seiichi Ozawa, Nikola Kasabov, One-pass Incremental Membership Authentication by Face Classification. ICBA 2004, Lecture Notes in Computer Science 3072, pp. 155-161, Springer 2004.7.Shaoning Pang, and Nikola Kasabov, Multi-Class SVM Classification Tree, (submitted), 2005.8. Shaoning Pang, Seiichi Ozawa and Nik Kasabov, Incremental Linear Discriminant Analysis for Classification of Data Streams ,IEEE Trans. on System, Man, and Cybernetics-Part B, vol. 35, no. 5, pp. 905 – 914, 20059.Seiichi Ozawa, Soon Toh, Shigeo Abe, Shaoning Pang and Nikola Kasabov, Incremental Learning for Online Face Recognition, Neural Network, vol.18, no. (5-6), pp. 575-584, 2005.Dr. Shaoning PANGKnowledge Engineering & Discovery Research Institute Auckland University of Technology, New Zealand Email: spang@。
一种新的基于SVM的相关反馈图像检索算法_许月华

本文提出了一种新的基于的相关反馈算法。
我们SVM 认为检索过程中的样本集合是一个动态增长的集合。
对于用户每次反馈的图像,可以分为感兴趣的样本正例和不感兴()趣的样本反例两类,用来更新原有的样本集合。
通过不断()的积累,样本集合会逐渐达到学习的要求,从而解决SVM 上述算法中样本不足的困难。
本文算法的第个改进之处在2于考虑了检索过程中历史信息的利用。
每一次新的反馈之后,旧的权值经过衰减和新的权值共同决定图像库中所有图像的排序。
实验结果证明了文中算法的有效性和系统检索能力的提高。
支持向量机1 (SVM)给定线性可分样本(x i ,y i …),i=1,,N, y i ∈,,{-11}x i ∈R d 。
0b w x+=⋅假定某个超平面可以将正例与反例分开称之为(()g x b w x =+⋅分类超平面,对应分类函数为。
最优分类) 面是令正例和反例之间的距离最大化的分类超平面。
将g(x )w 归一化之后,求解最优分类面的问题等价于最小化,目标函数为:2min ()12w w Φ= (1)()10i i y w x b ⋅+−≥公式的约束条件为:(1)i=1, 2, … , N i α定义个算子N Lagrange ,i=1,…。
求解该二次优化, N ∑==N i i i i x w y 1αx i 问题,可以得到最优分类面,其中,是 位于分类间隔面上的样本,称为支持向量。
分类函数为:()()b y sign f x x x i i i i +•=∑α (2)在数据不是线性可分的情况下,一方面,引入惩SVM 罚系数和松弛系数C ξi ,…,修改目标函数为:i=1, , N()()()11,2Ni C w w w φξ•=+∑⋅(3)另外,注意到公式中仅仅出现了点积的形式(2)xx ji •。
假设先将数据映射到某个欧氏空间,映射ψ:H ψ : R d →H ()()i j x x Ψ•Ψ则公式中的点积转化为中的点积。
一种新的中文文本分类算法-One ClassSVM—KNN算法

A w x a sfc t n Alo i mm On a s S Ne Te tCl si a i g rt i o h e Cls VM - KNN
LI W e WU e U n, Ch n
( h p nn a oa r f n lgn C m uigJ n s nvr t o c neadT cn l y T eO eigL b rt yo t l et o p t 。i guU i sy f i c n eh oo 。 o Iei n a e i S e g
及存 储和 计算 的开销 大等缺 陷 。单 类 S M对 只有 一类 的分类 问题 具有 很好 的效果 , 不适 用 于 多类 分类 问题 , V 但 因此针 对 K N存 在 的缺陷及 单类 S M 的特 点提 出 O eCas V K N算法 , 给 出 了算 法 的定 义及 详 细分 析 。通过 实 验 证 明此 N V n l M— N sS 并
Z ej n 10 3 C ia hni g22 0 。hn ) a
Ab t a t T x l s i c t n i d l s d i aa s n e r h e g n . s r c : e tca s ai s wi e y u e n d tba e a d s ac n i e KNN s wi e y u e n Ch n s e tc t g rz t n, o v r i f o i d l s d i i e e tx ae o ia o h we e 。 i KNN a n e e t n t e a p ia o ftx l s i c t n. e d fce c fKNN l sf ai n ag r m st a l t e tan n a h s ma y d f cs i h p l t n o tca sf a o Th e in y o ci e i i i ca i c t l o t s i o i h i t l i i g s m- h a h r
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ONE-CLASS SVM FOR LEARNING IN IMAGE RETRIEVAL Yunqiang Chen, Xiang Zhou, and Thomas S. Huang{chenyq, xzhou2,huang}@405 N. Mathews Ave., Beckman InstituteUniversity of Illinois at Urbana-ChampaignUrbana, IL 61820ABSTRACTRelevance feedback schemes using linear/quadratic estimators have been applied in content-based image retrieval to significantly improve retrieval performance. One major difficulty in relevance feedback is to estimate the support of target images in high dimensional feature space with a relatively small number of training samples. In this paper, we develop a novel scheme based on one-class SVM, which fits a tight hyper-sphere in the non-linearly transformed feature space to include most of the target images based on the positive examples. The use of kernel provides us an elegant way to deal with non-linearity in the distribution of the target images, while the regularization term in SVM provides good generalization ability. To validate the efficacy of the proposed approach, we test it on both synthesized data and real-world images. Promising results are achieved in both cases.1. INTRODUCTION1.1 BackgroundContent-based image retrieval has received much interest in the last decades due to the large digital storage and easy access of images on computers and through the World Wide Web [1]. A major challenge in CBIR system comes from the dynamic interpretation of images by different users at different times, thus adaptive real-time learning and/or classification is required. The computer can only detect the low-level features, e.g., texture, color histogram and edge features while the user’s demand may be very high-level concepts. To bridge this large gap between humans and computers, computers have to be able to learn which features best describe the pictures in user’s mind on-line.Relevance feedback and on-line learning techniques have been shown to provide dramatic performance boost in CBIR systems [3][5][9][10]. The strategy is to ask the user to give some feedbacks on the results returned in the previous query round and try to refine the search strategy and come up with a better result-set based on these feedbacks. Majority of the work uses relevance feedback to learn the relative importance of different features, with some tries to learn a feature weighting scheme either with [5] or without [3][6] considering correlations among feature components; while others either use a probabilistic scheme [4], or Self-Organizing Maps [15], or boosting technique [13], etc., to do so. Many of the algorithms are heuristics-based, which are fast and robust, but relying on the condition that one can find the right parameters [4][5][14]. Discriminant analysis on the examples given by the user is applied for dimensionality reduction, assuming two classes, before the Expectation-Maximization (EM) algorithm is used in a transductive learning framework [10]. This scheme has the potential difficulty in computational expenses, especially when the database is large. Recently there is also preliminary attempt to incorporate Support Vector Machine (SVM) into relevance feedback process [8].1.2 One Class or Two ClassesA typical problem with CBIR system with relevance feedback is the relatively small number of training samples and the high dimension of the feature space. The system can only present the user with a few dozen of images to label (relevant or irrelevant). The interesting images to the user are only a very small portion of the large image database, in which most images remain unlabeled. Much work regards the problem as a strict two-class classification problem, with equal treatments on both positive and negative examples. It is reasonable to assume positive examples to cluster in certain way, but negative examples usually do not cluster since they can belong to any class. It is almost impossible to estimate the real distribution of negative images in the database based on the relevant feedback. An illustration of the undesirable result reached by two-class SVM is given in Figure 1.1.3 Prior Knowledge (Assumptions)Different assumptions about the distribution of the target images have been proposed in the literature.In Proc. IEEE Int'l Conf. on Image Processing 2001, Thessaloniki, GreeceGaussian assumption is the most common and convenient one [14]. It assumes the target pictures are distributed in the feature space as a single mode Gaussian. But because of the large gap between the high level concepts and low level features, it is hard to justify this assumption. Some go to another extreme. They assume each returned positive image as a mode and try to get the target images from the nearest neighbor of each relevant image. This method will be too sensitive to the training images and it does not have good generalization capability.Figure 1 Decision boundary of a two-class SVM: Thecircles are the positive images, the crosses are thenegative ones, and the black dots are the unlabeledimages. The decision boundary (the dashed line) willclassify many non-target images as positive.1.4 The Proposed SchemeIn this paper, we try to fit a tight hyper-sphere in the feature space to include most positive training samples. This task is formulated into an energy optimization problem. It is then changed to a dual form and kernels are introduced. Because the distribution of the target images cannot be decided, we should not restrict ourselves to a special kind of distribution assumption. In this scheme, the non-linearity can be represent implicitly in the kernel evaluations. The computational cost will not change much from the non-kernel counterpart. As long as the assumption about the distribution can be represented in a kernel form, our algorithm can be used with high efficiency for online image retrieval.The rest of the paper is organized as follows. Section 2 describe our One-class SVM in details and give some discussion on different kernels. Section 3 presents the experimental results on the real database. The conclusions and future work are listed in section 4.2. ONE-CLASS SVMIn this paper, we try to estimate the distribution of the target images in the feature space without over-fitting to the user feedbacks. Because of the good generalization ability of SVM [7], we try to estimate the support that can include most of the relevant images with some regularization to single out outliers. The algorithm is named One-class SVM [11] since only positive examples are used in training and testing.2.1 One class SVMWe first introduce terminology and notation conventions. We consider training dataℵ∈lXXX,,21where l∈Ν is the number of observations. Let Φ be a feature map F→ℵ.Our strategy is to map the data into the feature space and then try to use a hyper-sphere to describe the data in feature space and put most of the data into the hyper-sphere. This can be formulated into an optimization problem. We want the ball to be as small as possible while at the same time, including most of the training data. We only consider the positive points and get the objective function in the following form (primal form):+∈ℜ∈ℜ∈iiFcR vlRlζζ1min2,,][,)(..22liforRcXt siii∈≥+≤−ΦζζThe trade off between the radius of the hyper-sphere and the number of training samples that it can hold is set by the parameter v∈[0,1]. When v is small, we try to put more data into the “ball”. When v is larger, we try to squeeze the size of the “ball”.We can solve this optimization with Lagrangian multipliers:[]===−+−−−Φ+=liiiliiliiiivlRcXRcRL1112221)(),,,,(ζβζζαβαζ1)1(2==−=∂∂iiRRLαα(1)vlvlLiiii11≤≤=−−=∂∂αβαζ(2)()Φ==−Φ−=∂∂)()(2iiiiXccXcLαα(3)The equation (1) and (2) turn out to be the constraints while equation (3) tell us the c (center of the ball) can be expressed as the linear combination of Φ(X), which make it possible to express the dual form with kernel functions.1,1..),(),(min,=≤≤−i iii iiiji jijivlt sXXkXXkααααααThe optimal ’s can be got after solving this dual problem by the QP optimization methods. We can rank all the images in the database by the following decision function:−+−=ii i j i j i j i X X k X X k X X k R X f ),(),(2),()(,2αααThe images with higher scores are more likely to be the target images.2.2 Linear Case: LOC-SVM (One-Class SVM) First we try the linear case. For linear case, the algorithm just tries to fit a hyper-sphere to cover the training points with outlier detection. A synthetic training data set is generated to illustrate our algorithm. The training sample is randomly generated according to x = N (, ), where = (5, 0)T , = I. One can see that in Figure 2(b), the learning machine catches the distribution without over-fitting. The decision function evaluates the largest value at [5.0, 0.15] which is very close to the true center. It tries to put a circle in the 2D dimension to include most positive samples while leave some out as outlier. The parameter can be tuned to control the amount of outliers.(a)(b)Figure 2: (a) shows the training points we generated. The dots are the samples that have positive evaluation from the decision function after training. The crosses are the samples that are detected as outliers and have negative evaluation from the decision function. (b) is the decision value for all the points in the 2D feature space. It takes the largest value at [5.0, 0.15] But in feature space, we cannot assume that the target images are clustered in spherical shape—images can have complicated non-linear distributions. However by using kernel-based form of this algorithm, non-linear distribution can be dealt with in the same framework.2.3 Non-linear Case Using Kernel (KOC-SVM) In this section, we discuss the use of reproducing kernel to deal with non-linear, multi-mode distributions using KOC-SVM (Kernel One-class SVM). A good choice is the Gaussian kernel in the following form:222/),(σYX eY X K −−=To test KOC-SVM’s ability to capture non-linearity such as a multi-mode distribution, training data are jointly sampled from three Gaussian modes. We also generate some sparse outliers from a uniform distribution over the feature space. After training, the decision function in the feature space is shown in Figure 3 (b). It is apparent that KOC-SVM captures the multimode fairly well. It is important to note that this learning machine has the capability of removing outliers in an intelligent way, unlike the way a non-parametric Parzen window densityestimator works.(b)Figure 3: (a) shows all the training set we generated from three Gaussians. The dots are the samples which have positive evaluation from the decision function. The crosses are the samples which are detected as outliers and get negative decision function values. (b) decision values for all the points in the 2D feature space. White means high value while black means low value.3. EXPERIMENT RESULTSFinally, tests on the real-world images are conducted. We constructed a fully labeled image database. It has five classes each with 100 images. These are: airplanes, cars, horses, eagles and stained glasses. 10 images are randomly drawn as training samples and the learned decision function is applied to rank all the 500 images in the database. The hit rates in the first 20 and 100 images are used as the performance measures. Specifically, for each class 100 tests are performed with only 10 randomly drawn training samples and the average error rate is recorded as shown in the following table. Tested against is the WT (Whitening Transform), which is the relevance feedback technique reported in [3][6] (Note that in [6], a two-level structure is adopted to better deal with singularity issues. Here we use one-level and use regularization terms to bring the covariance matrix out of singularity.) LOC-SVM is the worst for apparent reasons that it lacks flexibility in modeling variations in distributions. WT is better since it can model multivariate Gaussian distribution. KOC-SVM gives the best results due to its capability in nonlinear modeling.Table 1: Averaged Error rate for image retrievalusing LOC-SVM (One-class SVM), WT(Whitening Transform), and KOC-SVM (KernelOne-class SVM), all with 10 training samples.Average Error Rate LOC-SVM WT KOC-SVMin top 20 8.63% 2.20% 1.47%in top 100 35.12% 29.28%26.38%4. CONCLUSION AND FUTURE WORKIn this paper, statistical learning method is used to attack the problems in content-based image retrieval. We developed a common framework to deal with the problem of training with small samples. Kernel machines provide us a way to deal with non-linearity in an elegant way. Promising results are presented.Some more research should be done in how to choose appropriate kernel for CBIR. Also, it is desirable to have a systematic scheme for tuning the parameters such as the spread of the Gaussian and the strength of the regularization term.ACKNOWLEDGEMENTSThis work was supported in part by National Science Foundation Grant CDA 96-24396, IIS-00-85980 and EIA 99-75019.REFERENCES[1] M. Flickner. et al., “Query by image and video content: Theqbic system”, IEEE Computers. 1995[2] G. Rätsch, B. Schölkopf, S. Mika, and K. R. Müller. “SVMand boosting: One class”, Technical Report 119, GMD FIRST, Berlin, November 2000.[3] Y. Ishikawa, R. Subramanya, and C. Faloutsos,“MindReader Query databases through multiple examples”, in Proc. Of the 24th VLDB Conf. (New York), 1998[4] J. Peng, B. Bhanu, and S.Qing, “Probabilistic featurerelevance learning for content-based image retrieval”, Computer Vision and Image Understanding, 75:150-164, 1999[5] Y. Rui, T. S. Huang, M. Ortega, and S. Mehrotra“Relevance Feedback: A Power Tool in Interactive Content-Based Image Retrieval”, IEEE Tran on Circuits and Systems for Video Technology, Vol 8, No. 5, Sept., 644-655, 1998,[6] Y. Rui, T. S. Huang, “Optimizing learning in imageretrieval”, Proc. IEEE CVPR, 2000, 236-243[7] V. Vapnik, “The Nature of Statistical Learning Theory”,Springer Verlag, New York, 1995[8] Q. Tian, P. Hong, T. S. Huang, "Update Relevant ImageWeights for Content-Based Image Retrieval Using Support Vector Machines", IEEE International Conference on Multimedia and Expo (ICME'2000), Hilton New York & Towers, New York, NY, July 30 - Aug. 2, 2000.[9] N. Vasconcelos, A. Lippman, “Bayesian relevancefeedback for content-based image retrieval”, in Proc.IEEE Workshop on Content-based Access of Image and Video Libraries, CVPR’00, Hilton Head Island, SC, 2000 [10] Y. Wu, Q. Tian, T. S. Huang, "Discriminant EM Algorithmwith Application to Image Retrieval", IEEE Conf.Computer Vision and Pattern Recognition (CVPR)'2000, Hilton Head Island, South Carolina, June 13-15, 2000. [11] B. Scholkopf, J. C. Platt, J. T. Shawe, A. J. Smola, R. C.Williamson, “Estimation the support of a high-dimensional Distribution”, Technical Report MSR-TR-99-87, Microsoft Research[12] I. J. Cox, M. Miller, T. Minka, P. Yianilos, “An OptimizedInteraction Strategy for Bayesian Relevance Feedback”, IEEE Conf. Computer Vision and Pattern Recognition (CVPR'98)[13] K. Tieu and P. Viola, “Boosting Image Retrieval”, IEEEConf Computer Vision and Pattern Recognition (CVPR'00), Hilton Head, South Carolina[14] C. Nastar, M. Mitschke and C. Meilhac “Efficient QueryRefinement for Image Retrieval”, IEEE Conf. Computer Vision and Pattern Recognition CVPR'98, Santa Barbara, CA, June 1998.[15] J. Laaksonen, M. Koskela, and E. Oja. “PicSOM: Self-Organizing Maps for Content-Based Image Retrieval”, Proc. of IJCNN'99. Washington, DC. July 1999。