9 最近邻元素
高考化学考点26 元素周期表的结构
一、一、元素周期表及其结构1.编排原则(1)周期:把电子层数相同的元素按原子序数递增顺序从左到右排列成一横行。
(2)族:把不同横行中最外层电子数相同的元素,按电子层数递增的顺序从上到下排成一纵行。
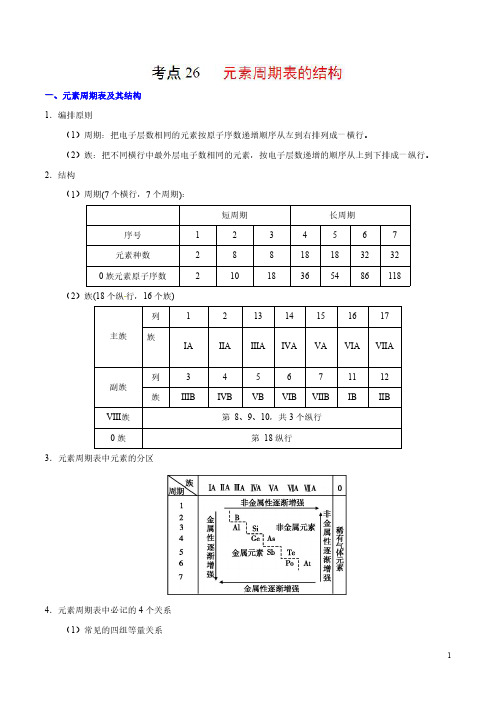
2.结构(1)周期(7个横行,7个周期):短周期长周期序号1234567元素种数288181832320族元素原子序数21018365486118(2)族(18个纵行,16个族)主族列121314151617族ⅠA ⅡA ⅢA ⅣA ⅤA ⅥA ⅦA 副族列345671112族ⅢBⅣBⅤBⅥBⅦBⅠBⅡBⅧ族第8、9、10,共3个纵行0族第18纵行3.元素周期表中元素的分区4.元素周期表中必记的4个关系(1)常见的四组等量关系①核电荷数=质子数=原子序数;②核外电子层数=周期序数;③主族序数=最外层电子数=最高正价;④非金属元素:最低负价=最高正价−8。
(2)同主族元素的原子序数差的关系①位于过渡元素左侧的主族元素,即第ⅠA、第ⅡA族,同主族、邻周期元素原子序数之差为上一周期元素所在周期所含元素种数;②位于过渡元素右侧的主族元素,即第ⅢA~第ⅦA族,同主族、邻周期元素原子序数之差为下一周期元素所在周期所含元素种数。
例如,氯和溴的原子序数之差为35−17=18(溴所在第四周期所含元素的种数)。
(3)同周期第ⅡA族和第ⅢA族元素原子序数差的关系周期序数1234567原子序数差无1111112525增加了过渡元素和原因——增加了过渡元素镧系或锕系元素(4)奇偶关系①原子序数是奇数的主族元素,其所在主族序数必为奇数;②原子序数是偶数的主族元素,其所在主族序数必为偶数。
二、元素周期表的应用考向一元素周期表的结构典例1如图为元素周期表中前四周期的一部分,若B元素的核电荷数为x,则这五种元素的核电荷数之和为A.5x+10B.5x C.5x+14D.5x+16【解析】【答案】A【规律总结】同主族、邻周期元素的原子序数差的关系①ⅠA族元素,随电子层数的增加,原子序数依次相差2、8、8、18、18、32。
几种常见的晶体结构

晶体的一个基本特点是各向异性,沿晶格的不同 方向晶体的性质不同,因此有必要识别和标志晶格中 的不同方向。 点阵的格点可以分列在一 系列平行的直线系上,这些直 线系称作晶列。同一点阵可以 形成不同的晶列,每一个晶列 定义一个方向,称作晶向。如 果从一个阵点到最近一个阵点 的位移矢量为:(以基矢为单 位) l1a1 l2a2 l3a3
例如: (1) 以O为原点的直角坐标系 OX、OY、OZ(选择的晶 面与坐标原点O不能有交点)
(2) 以一个晶格常数a为度量单位求出该晶面与坐标轴的截 距(m=1,n=1/2,p=1/2)。 (3) 取截距的倒数(1/m=1,1/n=2,1/p=2),化简成 最小整数放入(hkl)内,晶面指数为(122)
(1)一个晶面指数代表空间相互平行的一组晶面,将晶面指 数各乘以-1表示同一晶面。 111, (1 1 1)
表示同一晶面。
(2)晶面空间方位不同,但原子排列规律相同属于同一 晶面族用{hkl}表示。 {100}=(100)+(010)+(001)
(3)可以证明,如此确定的晶面指数=晶面法线方向和三 个坐标轴夹角的方向余弦之比。
注意:晶向和晶面指数的定义都涉及到坐标轴的选 取,或者选点阵原胞的基矢a1a2a3,或者选惯用晶胞 的三个边abc,当二者不一致时,比如体心立方和面 心立方情形,用两个坐标系定义出的晶向和晶面指 数是不一致的,使用时必须注意到它们的差别。多 数情况下,我们习惯使用惯用晶胞a,b,c做单位进行 的标注。
d HKL
d HKL
a H K L a
2 2 2
a = b= c
四方晶系:
六角晶系:
d HKL
H 2 K 2 L2 2 a2 c a
第七章SPSS聚类分析

例如,学校里有些同学经常在一起,关系比较
密切,而他们与另一些同学却很少来往,关系比较 疏远。究其原因可能会发现,经常在一起的同学的 家庭情况、性格、学习成绩、课余爱好等方面有许 多共同之处,而关系比较疏远的同学在这些方面有 较大的差异性。为了研究家庭情况、性格、学习成 绩、课余爱好等是否会成为划分学生小群体的主要 决定因素,可以从有关这些方面的数据入手,进行 客观分组,然后比较所得的分组是否与实际相吻合。 对学生的客观分组就可采用聚类分析方法。
最近邻元素(Nearest Neighbor):个体与小类中每个 个体距离的最小值。 最远邻元素(Furthest Neighbor ):个体与小类中每 个个体距离的最大值。 组间联接(Between-groups linkage):个体与小类 中每个个体距离的平均值。 组内联接(Within-groups linkage):个体与小类中 每个个体距离以及小类内各个体间距离的平均值。 质心聚类法(Centroid clustering):个体与小类的重 心点的距离。重心点通常是由小类中所有样本在各变量上的 均值所确定的点。 离差平方和法(Ward’s method):聚类过程中使小类 内离差平方和增加最小的两小类应首先合并为一类。
• 例:下表是同一批客户对经常光顾的五座商场在购物环境和
服务质量两方面的平均得分,现希望根据这批数据将五座商
场分类。
编号
购物环境 服务质量
A商场
73
68
B商场
66
64
C商场
84
82
D商场
91
88
E商场
94
90
7.1.2 聚类分析中“亲疏程度”的度量方法
• 聚类分析中,个体之间的“亲疏程度”是极为重要 的,它将直接影响最终的聚类结果。对“亲疏”程 度的测度一般有两个角度:第一,个体间的相似程 度;第二,个体间的差异程度。衡量个体间的相似 程度通常可采用简单相关系数等,个体间的差异程 度通常通过某种距离来测度。
高级统计学作业-聚类分析

全国各地区消费价格增长水平的聚类分析摘要:针对我国各省(直辖)市的2009年度消费价格增长水平数据,选取9个经济指标进行系统聚类分析,得到我国3类不同的地区消费价格增长水平类型。
聚类结果为制订有针对性的地区消费市场战略提供依据。
关键词:SPSS;聚类分析;消费水平。
1.引言由于传统的经济发展起点不同,加上地域、资源、技术和政策等条件的差异,各个地区的经济发展水平高低不齐,导致各地区的工资水平和消费价格增长水平的不同。
因此,对各地区消费价格增长水平进行分类、比较和研究,总结出有助于市场调节和商业发展的对策,有针对性地制订地区经济发展战略,对促进国民经济协调发展有重要意义。
聚类分析和判别分析是是进行以上分析的两个重要的方法。
1.1聚类分析[1]定义:聚类分析又称群分析、点群分析。
根据研究对象特征对研究对象进行分类的一种多元分析技术,把性质相近的个体归为一类,使得同一类中的个体都具有高度的同质性,不同类之间的个体具有高度的异质性。
聚类分析的基本思想:我们所研究的样品或指标(变量)之间存在程度不同的相似性(亲疏关系),于是根据一批样品的多个观测指标,具体找出一些能够度量样品或指标之间相似程度的统计量,以这些统计量作为划分类型的依据,把一些相似程度较大的样品(或指标)聚合为一类,把另外一些相似程度较大的样品(或指标)又聚合为另一类;关系密切的聚合到一个小的分类单位,关系疏远的聚合到一个大的分类单位,直到把所有的样品(或指标)聚合完毕。
1.1.1 系统聚类法系统聚类法的基本原理:首先将一定数量的样本或指标各自看成一类,然后根据样本(或指标)的亲疏程度,将亲疏程度最高的两类进行合并,然后考虑合并后的类与其他类之间的亲疏程度,再进行合并。
重复这一过程,直到将所有的样本(或指标)合并为一类。
系统聚类分为Q型聚类和R型聚类两种:Q型聚类是对样本进行聚类,它使具有相似特征的样本聚集在一起,使差异性大的样本分离开来;R型聚类是对变量进行聚类,它使差异性大的变量分离开来,相似的变量聚集在一起,这样就可以在相似变量中选择少数具有代表性的变量参与其他分析,实现减少变量个数、降低变量维度的目的。
高考化学专题元素周期表

第3课时元素周期表一、元素周期表的结构1.元素周期表的编排原则(1)横行原则:把电子层数目相同的元素,按原子序数递增的顺序从左到右排列。
(2)纵行原则:把不同横行中最外层电子数相同的元素,按电子层数递增的顺序由上而下排列。
2.元素周期表的结构(1)周期①数目:元素周期表有7个横行,即有7个周期。
②分类短周期:第1、2、3周期,每周期所含元素的种类数分别为2、8、8。
长周期:第4、5、6、7周期,每周期所含元素的种类数分别为18、18、32、32。
③周期数=电子层数。
(2)族①数目:元素周期表有18个纵行,但只有16个族。
②分类主族,共7个(由长、短周期元素构成,族序数后标A)。
副族,共7个(只由长周期元素构成,族序数后标B)。
第Ⅷ族,包括8、9、10三个纵行。
0族,最外层电子数是8(He是2)。
③主族序数=最外层电子数。
(3)过渡元素元素周期表中从ⅢB到ⅡB共10个纵行,包括了第Ⅷ族和全部副族元素,共60多种元素,全部为金属元素,统称为过渡元素。
(1)元素周期表的结构(2)列序数与族序数的关系①列序数<8,主族和副族的族序数=列序数;②列序数=8或9或10,为第Ⅷ族;③列序数>10,主族和副族的族序数=列序数-10(0族除外)。
例1下列关于元素周期表的说法正确的是()A.在元素周期表中,每一纵行就是一个族B.主族元素都是短周期元素C.副族元素都是金属元素D.元素周期表中每个长周期均包含32种元素考点元素周期表的结构题点元素周期表的结构答案 C解析A项,第8、9、10三个纵行为第Ⅷ族;B项,主族元素由短周期元素和长周期元素共同组成。
例2(2017·聊城高一检测)若把元素周期表原先的主副族及族号取消,由左至右改为18列,如碱金属元素为第1列,稀有气体元素为第18列。
按此规定,下列说法错误的是() A.只有第2列元素的原子最外层有2个电子B.第14列元素形成的化合物种数最多C.第3列元素种类最多D.第18列元素都是非金属元素考点元素周期表的结构题点元素周期表的结构答案 A解析周期表中各族元素的排列顺序为ⅠA、ⅡA、ⅢB→ⅦB、Ⅷ、ⅠB、ⅡB、ⅢA→ⅦA、0族,18列元素与以上对应,所以A项中为ⅡA族,最外层有2个电子,但He及多数过渡元素的最外层也是2个电子,故A项错误;第14列为碳族元素,形成化合物种类最多,故B项正确;第3列包括镧系和锕系元素,种类最多,故C项正确;第18列为稀有气体元素,全部为非金属元素,故D项正确。
主成分分析与聚类分析和判别分析

实验三主成分分析、聚类分析和判别分析学院:地理科学学院专业:自然地理学姓名:郭国洋实验内容(1)中国31个省份、直辖市、自治区(不包括港澳台)经济状况的7项指标。
(2)用主成分分析剖析出影响中国大陆经济状况的主要指标,并对中国大陆的经济综合实力进行排序。
(3)用主成分剖析出的指标,用聚类分析对中国大陆的经济状况进行评价,并对每类的经济综合状况进行评价。
(4)结合本题,谈谈聚类分析和主成分分析两种方法如何结合使用来分析问题。
实验目的(1)巩固主成分和聚类分析的基本原理和方法步骤以及在实际分析中的意义。
(2)用SPSS软件完成地理的主成分分析和聚类分析。
第一部分主成分分析1 实验数据查阅2012年中国统计年鉴,数据表示2011年的指标。
得到中国31个省份、直辖市、自治区(不含港澳台)的7项经济统计指标数据,包括:总人口/10^4人,城镇人口比例/%,第一产业总产值/10^8元,工业生产总值/10^8元,公共财政预算收入/10^8元,城乡居民储蓄余额/10^8元,城镇单位就业人员工资总额/10^8元。
样本容量:31,变量:7,如图1。
2 实验步骤及分析(1)点击“分析”—“降维”—“因子分析”,将上述的7个指标选择为变量。
SPSS中的“主成分分析”嵌入到“因子分析”中,因此在操作的过程中我们要先进行因子分析。
如2。
图2 选择因子分析变量(2)依次点击“因子分析”框中的“描述”、“抽取”、“旋转”、“得分”、“选项”,勾选相应的选项,如图3、4、5、6、7所示图3抽取图4 旋转图4描述统计图5因子得分图6选项图7旋转(3)点击“确定”,得到相应的结果并分析。
图8 KMO和Bartlett检验分析:图8中,在进行因子分析之前,需要检验变量之间是否具备进行分析的条件。
由图中可知KMO值为0.787>0.5,说明数据变量之间具有结构效度,Sig<0.05,说明可以进行因子分析。
图9 公因子方差分析:图9是指全部公共因子对于变量的总方差做所的贡献,说明了全部公共因子反映出的原变量的信息的百分比。
材料科学基础经典习题及答案

第一章 材料科学根底1.作图表示立方晶体的()()()421,210,123晶面及[][][]346,112,021晶向。
2.在六方晶体中,绘出以下常见晶向[][][][][]0121,0211,0110,0112,0001等。
3.写出立方晶体中晶面族{100},{110},{111},{112}等所包括的等价晶面。
4.镁的原子堆积密度和所有hcp 金属一样,为。
试求镁单位晶胞的体积。
Mg 的密度3Mg/m 74.1=m g ρ,相对原子质量为,原子半径。
5.当CN=6时+Na 离子半径为,试问:1) 当CN=4时,其半径为多少?2) 当CN=8时,其半径为多少?6. 试问:在铜〔〕的<100>方向及铁(bcc,a=0.286nm)的<100>方向,原子的线密度为多少?7.镍为面心立方构造,其原子半径为nm 1246.0=Ni r 。
试确定在镍的〔100〕,〔110〕及〔111〕平面上12mm 中各有多少个原子。
8. 石英()2SiO 的密度为3Mg/m 。
试问: 1) 13m 中有多少个硅原子〔与氧原子〕?2) 当硅与氧的半径分别为与时,其堆积密度为多少〔假设原子是球形的〕?9.在800℃时1010个原子中有一个原子具有足够能量可在固体内移动,而在900℃时910个原子中那么只有一个原子,试求其激活能〔J/原子〕。
10.假设将一块铁加热至850℃,然后快速冷却到20℃。
试计算处理前后空位数应增加多少倍〔设铁中形成一摩尔空位所需要的能量为104600J 〕。
11.设图1-18所示的立方晶体的滑移面ABCD 平行于晶体的上、下底面。
假设该滑移面上有一正方形位错环,如果位错环的各段分别与滑移面各边平行,其柏氏矢量b ∥AB 。
1) 有人认为“此位错环运动移出晶体后,滑移面上产生的滑移台阶应为4个b ,试问这种看法是否正确?为什么?2)指出位错环上各段位错线的类型,并画出位错运动出晶体后,滑移方向及滑移量。
固体物理重点知识点总结——期末考试、考研必备!!

固体物理概念总结——期末考试、考研必备!!第一章1、晶体-----内部组成粒子(原子、离子或原子团)在微观上作有规则的周期性重复排列构成的固体。
晶体结构——晶体结构即晶体的微观结构,是指晶体中实际质点(原子、离子或分子)的具体排列情况。
金属及合金在大多数情况下都以结晶状态使用。
晶体结构是决定固态金属的物理、化学和力学性能的基本因素之一。
2、晶体的通性------所有晶体具有的共通性质,如自限性、最小内能性、锐熔性、均匀性和各向异性、对称性、解理性等。
3、单晶体和多晶体-----单晶体的内部粒子的周期性排列贯彻始终;多晶体由许多小单晶无规堆砌而成。
4、基元、格点和空间点阵------基元是晶体结构的基本单元,格点是基元的代表点,空间点阵是晶体结构中等同点(格点)的集合,其类型代表等同点的排列方式。
倒易点阵——是由被称为倒易点或倒易点的点所构成的一种点阵,它也是描述晶体结构的一种几何方法,它和空间点阵具有倒易关系。
倒易点阵中的一倒易点对应着空间点阵中一组晶面间距相等的点格平面。
5、原胞、WS原胞-----在晶体结构中只考虑周期性时所选取的最小重复单元称为原胞;WS原胞即Wigner-Seitz原胞,是一种对称性原胞。
6、晶胞-----在晶体结构中不仅考虑周期性,同时能反映晶体对称性时所选取的最小重复单元称为晶胞。
7、原胞基矢和轴矢----原胞基矢是原胞中相交于一点的三个独立方向的最小重复矢量;晶胞基矢是晶胞中相交于一点的三个独立方向的最小重复矢量,通常以晶胞基矢构成晶体坐标系。
8、布喇菲格子(单式格子)和复式格子------晶体结构中全同原子构成的晶格称为布喇菲格子或单式格子,由两种或两种以上的原子构成的晶格称为复式格子。
9、简单格子和复杂格子(有心化格子)------一个晶胞只含一个格点则称为简单格子,此时格点位于晶胞的八个顶角处;晶胞中含不只一个格点时称为复杂格子,其格点除了位于晶胞的八个顶角处外,还可以位于晶胞的体心(体心格子)、一对面的中心(底心格子)和所有面的中心(面心格子)。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
最近邻居数量 K 在最近邻元素分析模块建 模中起到了很大的作用。K 的取值不同, 分类结果不同。 如图 1 所示,每个实例根据其目标变量取 值(0 和 1)的不同,被分入两个类别集合。 当 K=5 时,目标变量取值为 1 的实例数更 多,所以新实例被分到类别 1 当中。 当 K=9 时,新实例被分到类别 0 当中。 Statistics 的最近邻元素分析模型既允许用 户指定固定的 K 值,也支持根据具体数据 自动为用户选择 K 值。
分析过程—预估汽车类型
运行设置时增加一个目标变量,Vehicle type(汽车类型),我们可以更好的了解 新车型应该被匹配到哪个类型当中。 要额外说明的是,增加了目标变量,最近 邻元素分析过程将支持自动选择一个“最 优”的邻居个数,并通过 Variable Importance(变量重要性)来衡量个案之 间的距离。
功能
支持 feature selection(预测变量选择)的 功能,允许在用户输入的众多的预测变量 当中,只选择一部分预测变量用作建模, 使得建立的模型效果更好。 允许建立目标变量是连续型变量的模型, 在这种情况下,目标变量的平均值或者中 位数值将作为新的实例目标的预测值。
商业案例
Peers Chart(对等图)
初始内容将显示每一个焦点个案的 3 个邻 居们在每一个预测变量上的取值分布。系 统默认将在前 6 个用户选择的预测变量上 显示数值。 当我们在预测变量空间子视图当中用鼠标 点击选择某个点,在右边的 Peers Chart (对等图)中,将显示该个案及它的 3 个 邻居们在每一个预测变量上的取值分布。 每一个单独的图表显示了某个预测变量的 一维空间。比如,newCar 处于 Engine
本次分析过程只寻找 K 个最近的邻居,而 不做分类和预测,所以我们没有选择目标 变量。 为了图形显示更加清晰,本步骤选择含有 少数个案的数据集进行示例。 分析结束后,“Output 输出视图”当中, 双击新产生的 Model Viewer(模型视图), 打开模型视图浏览器
Predictor Space (预测变量空间)视图
当向模型中引入一条新的实例,它和模型 当中已经存在的每一个实例之间的距离将 会被计算出来。这样,与这条新实例最相 近的邻居就被区分出来了。 图 1 描述了一个目标变量是离散型变量的 最近邻模型, 红色五角星是新实例,白色 和蓝色的点是模型当中已有实例。与他最 近的邻居们都被用红线连接了起来。
K的作用
计;
Variance:代表 Training (训练)数据的
计算拟合优度
Rsquare = 1-errorSummay/(Variance*(N1)) = 1- 631717.253/(4628.002*(157-1)) = 0.125
结论
理论上,Rsquare 值应该在 0 和 1 之间, Rsquare 值越接近 1,则表示所创建的模 型越好。本例中的值小于 0.5,说明我们的 模型不是很好。预测不是特别可信。 现在来看看最近邻居数目在建模过程中是 如何确定的,可以看到,当 K 值为 6 的时 候,模型的 Sum of Squares Error(预测 错误率)是最低的,因此最邻近元素分析 自动地为我们选择了 6 作为最终的 K 值。
增加新记录
标记新记录
再增加一个新变量 partition
区分 Training( 训练数据子集 ) 和 Holdout( 测试 ) 子集,我们将已有车型视为训练数 据子集,而新车型为测试子集。 由于算法中规定:partition > 0 表示为训练 数据
最近邻元素分析模型的分析过程
第一次分析
某汽车制造厂商的研发部门制定出两款新 预研车型的技术设计指标。 厂商希望将其和已经投放到市场上的已有 车型的相关数据进行比较,从而分析新车 型的技术指标是否符合预期,并预测新车 型投放到市场之后,预期的销售额多少。 在本文当中,对每一个车型实例,我们都 用个案来称呼它。 Car_sales.sav
表 1.两款新预研车型的技术指标数据
最近邻元素
模型简介
最近邻元素分析是一种针对样本实例进行 的分类算法,它根据某些样本实例与其他 实例之间的相似性进行分类。 将两个实例间的距离作为他们的“不相似 度”的一种度量标准。相互临近的实例被 称之为“Neighbors(邻居)” 支持两种距离,Euclidean Distance( 欧氏 距离法 ) 和 City-block Distance(城区距离 法)。
分析
原始数据最右边,可以看到数据增加了一 列,名为“KNN_PredictedValue”,我们称 其为预测值,它是对原始数据每个个案, 利用所产生的模型,根据预测变量的取值 计算出的目标变量值。 在这一列中我们注意到,newCar 的预测 type(分类)是 0,newTruck 的预测 type (分类)是 1。下面我们来检查这些预测 分类计算的是否合理。
分析过程—预测销售额
设置目标变量为 Sales in thousands(销售 额(千元)),再进行一次分析,从而获 得如果将两个新车型投放到市场后的预期 销售额。售额是 80.818,newTruck 的预测销售额是 42.455。 那么,这些预测值计算的是否合理,我们 所建的模型怎么样呢?
效果分析
本例中的目标变量是连续型变量,上例中 预估分类模型(目标变量是离散型)的方 法在此处不再适合。我们可以通过判断该 模型的统计量 Rsquare 的值,来评定所建 模型的好坏。 Rsquare = 1- errorSummary/ ( Variance *( N -1) ),其中, errorSummary:代表建模后得到的错误合
三维视图,图中的三条轴分布代表了 Horsepower (马力)、Engine size(引 擎尺寸)、Price in thousands(价格)三 个预测变量。 该视图是可交互的,用户可以通过鼠标点 击和拖拽,将视图旋转到更好的视角来观 察个案样本点在空间中的分布。 图中的每个点都代表 training(训练分区) 数据集中的个案,用圆形表示。只有两个 新车型个案属于 focal(焦点)个案,其外