lucene教案
《lucene全文检索》PPT课件

Lucene 是 一 个 高 性 能 、 可 伸 缩 的 信 息 搜 索 (IR) 库 。 Information Retrieval (IR) library.它使你可以为你的 应用程序添加索引和搜索能力。
精选ppt
18
IndexWriter
IndexWriter是在索引过程中的中心组件。
IndexWriter这个类创建一个新的索引并且添加文档到一个 已有的索引中。你可以把IndexWriter想象成让你可以对索 引进行写操作的对象,但是不能让你读取或搜索。
IndexWriter不是唯一的用来修改索引的类
Lucene的作者Doug Cutting是资深的全文索引/检索专家, 最开始发布在他本人的主页上,2001年10月贡献给APACHE, 成为APACHE基金的一个子项目。
/lucene/
精选ppt
5
全文检索系统的结构
精选ppt
6
为什么使用Lucene
• a - the analyzer to use
• create - true to create the index or overwrite the existing one; false to append to the existing
Strinigndinexdex = "C:\\tomcat\\webapps\\index1"; IndexWriter writer = new IndexWriter(index, new StandardAnalyzer(),true);
es lucene查询语法

es lucene查询语法(原创实用版)目录1.介绍 Lucene2.Lucene 查询语法的基本概念3.Lucene 查询语法的具体语法规则4.Lucene 查询语法的应用实例5.总结正文Lucene 是一个开源的全文搜索库,它提供了高度可定制和可扩展的全文搜索功能。
Lucene 查询语法是 Lucene 的核心功能之一,它允许用户通过特定的语法规则来构建搜索查询。
一、介绍 LuceneLucene 是一个全文搜索库,它可以快速地搜索和索引大量数据。
Lucene 支持多种数据类型,包括文本、数字、日期等,并且提供了高度可定制和可扩展的搜索功能。
Lucene 查询语法是 Lucene 的核心功能之一,它允许用户通过特定的语法规则来构建搜索查询。
二、Lucene 查询语法的基本概念Lucene 查询语法的基本概念包括以下几个方面:1.查询语句:查询语句是 Lucene 查询的核心,它定义了搜索的范围和搜索的条件。
2.查询词:查询词是用户输入的关键词,它是查询语句的核心部分。
3.布尔操作符:布尔操作符包括 AND、OR、NOT 等,它们用于组合查询词,以满足用户的搜索需求。
4.修饰词:修饰词是用于修饰查询词的词语,它可以改变查询词的搜索范围和搜索条件。
三、Lucene 查询语法的具体语法规则Lucene 查询语法的具体语法规则包括以下几个方面:1.查询语句的基本格式:查询语句的基本格式为“查询词 1AND/OR/NOT 查询词 2”,其中“查询词 1”和“查询词 2”可以是多个查询词和修饰词的组合。
2.布尔操作符的使用:布尔操作符包括 AND、OR、NOT 等,它们用于组合查询词,以满足用户的搜索需求。
3.修饰词的使用:修饰词包括普通修饰词和特殊修饰词,普通修饰词包括“+”和“-”,它们用于改变查询词的搜索范围和搜索条件;特殊修饰词包括“*”、“@”、“#”等,它们用于指定查询词的位置和数量。
4.查询语句的特殊格式:Lucene 查询语法还支持特殊格式的查询语句,包括短语查询、范围查询、通配符查询等。
一步一步跟我学习lucene(1...

一步一步跟我学习lucene(1...自定义排序说明我们在做lucene搜索的时候,可能会需要排序功能,虽然lucene 内置了多种类型的排序,但是如果在需要先进行某些值的运算然后在排序的时候就有点显得无能为力了;要做自定义查询,我们就要研究lucene已经实现的排序功能,lucene的所有排序都是要继承FieldComparator,然后重写内部实现,这里以IntComparator为例子来查看其实现;IntComparator相关实现其类的声明为public static class IntComparator extends NumericComparator<Integer>,这里说明IntComparator接收的是Integer类型的参数,即只处理IntField的排序;IntComparator声明的参数为:[java] view plain copy1.private final int[] values;2.private int bottom; // Value of bottom of queue3.private int topValue;查看copy方法可知•values随着类初始化而初始化其长度•values用于存储NumericDocValues中读取到的内容具体实现如下:values的初始化[java] view plain copy1./**2.* Creates a new comparator based on {@link Integer#co mpare} for {@code numHits}.3.* When a document has no value for the field, {@code mi ssingValue} is substituted.4.*/5.public IntComparator(int numHits, String field, Integer mi ssingValue) {6.super(field, missingValue);7.values = new int[numHits];8.}values值填充(此为IntComparator的处理方式)[java] view plain copy1.@Override2.public void copy(int slot, int doc) {3.int v2 = (int) currentReaderValues.get(doc);4.// Test for v2 == 0 to save Bits.get method call for5.// the common case (doc has value and value is non-zero):6.if (docsWithField != null && v2 == 0 && !docsWithField. get(doc)) {7.v2 = missingValue;8.}9.10.values[slot] = v2;11.}这些实现都是类似的,我们的应用实现自定义排序的时候需要做的是对binaryDocValues或NumericDocValues的值进行计算,然后实现FieldComparator内部方法,对应IntComparator就是如上的值copy操作;然后我们需要实现compareTop、compareBottom和compare,IntComparator的实现为:[java] view plain copy1.@Override2.public int compare(int slot1, int slot2) {3.return pare(values[slot1], values[slot2]);4.}5.6.@Override7.public int compareBottom(int doc) {8.int v2 = (int) currentReaderValues.get(doc);9.// Test for v2 == 0 to save Bits.get method call for10.// the common case (doc has value and value is non-zero):11.if (docsWithField != null && v2 == 0 && !docsWithFi eld.get(doc)) {12.v2 = missingValue;13.}14.15.return pare(bottom, v2);16.}[java] view plain copy1.@Override2.public int compareTop(int doc) {3.int docValue = (int) currentReaderValues.get(doc);4.// Test for docValue == 0 to save Bits.get method call for5.// the common case (doc has value and value is non-zero):6.if (docsWithField != null && docValue == 0 && !docsWit hField.get(doc)) {7.docValue = missingValue;8.}9.return pare(topValue, docValue);10.}实现自己的FieldComparator要实现FieldComparator,需要对接收参数进行处理,定义处理值的集合,同时定义BinaryDocValues和接收的参数等,这里我写了一个通用的比较器,代码如下:[java] view plain copy1.package com.lucene.search;2.3.import java.io.IOException;4.5.import org.apache.lucene.index.BinaryDocValues;6.import org.apache.lucene.index.DocValues;7.import org.apache.lucene.index.LeafReaderContext;8.import org.apache.lucene.search.SimpleFieldComparator;9.10.import com.lucene.util.ObjectUtil;11.12./**自定义comparator13.* @author lenovo14.*15.*/16.public class SelfDefineComparator extends SimpleFie ldComparator<String> {17.private Object[] values;//定义的Object[],同IntComparator18.private Object bottom;19.private Object top;20.private String field;21.private BinaryDocValues binaryDocValues;//接收的BinaryDocValues,同IntComparator中的NumericDocValues22.private ObjectUtil objectUtil;//这里为了便于拓展用接口代替抽象类23.private Object[] params;//接收的参数24.25.public SelfDefineComparator(String field, int numHits, Object[] params,ObjectUtil objectUtil) {26.values = new Object[numHits];27.this.objectUtil = objectUtil;28.this.field = field;29.this.params = params;30.}31.32.@Override33.public void setBottom(int slot) {34.this.bottom = values[slot];35.}36.37.@Override38.public int compareBottom(int doc) throws IOExcepti on {39.Object distance = getValues(doc);40.return (bottom.toString()).compareTo(distance.toStrin g());41.}42.43.@Override44.public int compareTop(int doc) throws IOException {45.Object distance = getValues(doc);46.return pareTo(top,distance);47.}48.49.@Override50.public void copy(int slot, int doc) throws IOException {51.values[slot] = getValues(doc);52.}53.54./**��ȡdocID��Ӧ��value55.* @param doc56.* @return57.*/58.private Object getValues(int doc) {59.Object instance = objectUtil.getValues(doc,params,bin aryDocValues) ;60.return instance;61.}62.63.@Override64.protected void doSetNextReader(LeafReaderContext context)65.throws IOException {66.binaryDocValues = DocValues.getBinary(context.reade r(), field);//context.reader().getBinaryDocValues(field);67.}68.69.@Override70.public int compare(int slot1, int slot2) {71.return pareTo(values[slot1],values[slot2]);72.}73.@Override74.public void setTopValue(String value) {75.this.top = value;76.}77.78.@Override79.public String value(int slot) {80.return values[slot].toString();81.}82.83.}其中ObjectUtil是一个接口,定义了值处理的过程,最终是要服务于comparator的compare方法的,同时对comparator的内部compare方法进行了定义ObjectUtil接口定义如下:[java] view plain copy1.package com.lucene.util;2.3.import org.apache.lucene.index.BinaryDocValues;4.5.public interface ObjectUtil {6.7./**自定义的获取处理值的方法8.* @param doc9.* @param params10.* @param binaryDocValues11.* @return12.*/13.public abstract Object getValues(int doc, Object[] par ams, BinaryDocValues binaryDocValues) ;14.15./**compare比较器实现16.* @param object17.* @param object218.* @return19.*/20.public abstract int compareTo(Object object, Object object2);21.22.}我们不仅要提供比较器和comparator,同时还要提供接收用户输入的FiledComparatorSource[java] view plain copy1.package com.lucene.search;2.3.import java.io.IOException;4.5.import org.apache.lucene.search.FieldComparator;6.import org.apache.lucene.search.FieldComparatorSource;7.8.import com.lucene.util.ObjectUtil;9.10./**comparator用于接收用户原始输入,继承自FieldComparatorSource实现了自定义comparator的构建11.* @author lenovo12.*13.*/14.public class SelfDefineComparatorSource extends Fie ldComparatorSource {15.private Object[] params;//接收的参数16.private ObjectUtil objectUtil;//这里为了便于拓展用接口代替抽象类17.18.public Object[] getParams() {19.return params;20.}21.22.public void setParams(Object[] params) {23.this.params = params;24.}25.26.public ObjectUtil getObjectUtil() {27.return objectUtil;28.}29.30.public void setObjectUtil(ObjectUtil objectUtil) {31.this.objectUtil = objectUtil;32.}33.34.public SelfDefineComparatorSource(Object[] params, ObjectUtil objectUtil) {35.super();36.this.params = params;37.this.objectUtil = objectUtil;38.}39.40.@Override41.public FieldComparator<?> newComparator(String fie ldname, int numHits,42.int sortPos, boolean reversed) throws IOException {43.//实际比较由SelfDefineComparator实现44.return new SelfDefineComparator(fieldname, numHit s, params, objectUtil);45.}46.}相关测试程序,这里我们模拟一个StringComparator,对String 值进行排序[java] view plain copy1.package com.lucene.search;2.3.import org.apache.lucene.analysis.Analyzer;4.import org.apache.lucene.analysis.standard.StandardAnal yzer;5.import org.apache.lucene.document.BinaryDocValuesFiel d;6.import org.apache.lucene.document.Document;7.import org.apache.lucene.document.Field;8.import org.apache.lucene.document.StringField;9.import org.apache.lucene.index.DirectoryReader;10.import org.apache.lucene.index.IndexReader;11.import org.apache.lucene.index.IndexWriter;12.import org.apache.lucene.index.IndexWriterConfig;13.import org.apache.lucene.index.IndexWriterConfig.Op enMode;14.import org.apache.lucene.index.Term;15.import org.apache.lucene.search.IndexSearcher;16.import org.apache.lucene.search.MatchAllDocsQuery;17.import org.apache.lucene.search.Query;18.import org.apache.lucene.search.ScoreDoc;19.import org.apache.lucene.search.Sort;20.import org.apache.lucene.search.SortField;21.import org.apache.lucene.search.TermQuery;22.import org.apache.lucene.search.TopDocs;23.import org.apache.lucene.search.TopFieldDocs;24.import org.apache.lucene.store.RAMDirectory;25.import org.apache.lucene.util.BytesRef;26.27.import com.lucene.util.CustomerUtil;28.import com.lucene.util.ObjectUtil;29.import com.lucene.util.StringComparaUtil;30.31./**32.*33.* @author 吴莹桂34.*35.*/36.public class SortTest {37.public static void main(String[] args) throws Exceptio n {38.RAMDirectory directory = new RAMDirectory();39.Analyzer analyzer = new StandardAnalyzer();40.IndexWriterConfig indexWriterConfig = new IndexWri terConfig(analyzer);41.indexWriterConfig.setOpenMode(OpenMode.CREATE_ OR_APPEND);42.IndexWriter indexWriter = new IndexWriter(directory,indexWriterConfig);43.addDocument(indexWriter, "B");44.addDocument(indexWriter, "D");45.addDocument(indexWriter, "A");46.addDocument(indexWriter, "E");mit();48.indexWriter.close();49.IndexReader reader = DirectoryReader.open(directory) ;50.IndexSearcher searcher = new IndexSearcher(reader);51.Query query = new MatchAllDocsQuery();52.ObjectUtil util = new StringComparaUtil();53.Sort sort = new Sort(new SortField("name",new SelfD efineComparatorSource(new Object[]{},util),true));54.TopDocs topDocs = searcher.search(query, Integer.MA X_VALUE, sort);55.ScoreDoc[] docs = topDocs.scoreDocs;56.for(ScoreDoc doc : docs){57.Document document = searcher.doc(doc.doc);58.System.out.println(document.get("name"));59.}60.}61.62.private static void addDocument(IndexWriter writer,S tring name) throws Exception{63.Document document = new Document();64.document.add(new StringField("name",name,Field.Sto re.YES));65.document.add(new BinaryDocValuesField("name", new BytesRef(name.getBytes())));66.writer.addDocument(document);67.}68.}其对应的ObjectUtil实现如下:[java] view plain copy1.package com.lucene.util;2.3.import org.apache.lucene.index.BinaryDocValues;4.import org.apache.lucene.util.BytesRef;5.6.public class StringComparaUtil implements ObjectUtil {7.8.@Override9.public Object getValues(int doc, Object[] params,10.BinaryDocValues binaryDocValues) {11.BytesRef bytesRef = binaryDocValues.get(doc);12.String value = bytesRef.utf8T oString();13.return value;14.}15.16.@Override17.public int compareTo(Object object, Object object2) {18.// TODO Auto-generated method stub19.return object.toString().compareTo(object2.toString());20.}21.22.}。
Lucene教程详解

Lucene教程详解Lucene-3.0.0配置一、Lucene开发环境配置step1.Lucene开发包下载step2.Java开发环境配置step3.Tomcat安装step4.Lucene开发环境配置解压下载的lucene-3.0.0.zip,可以看到lucene-core-3.0.0.jar和lucene-demos-3.0.0.jar这两个文件,将其解压(建议放在安装jdk的lib文件夹内),并把路径添加到环境变量的classpath。
二、Lucene开发包中Demo调试控制台应用程序step1.建立索引>java org.apache.lucene.demo.IndexFiles [C:\Java](已经存在的任意文件路径)将对C:\Java下所有文件建立索引,同时,在当前命令行位置将生成“index”文件夹。
step2.执行查询>java org.apache.lucene.demo.SearchFiles将会出现“Query:”提示符,在其后输入关键字,回车,即可得到查询结果。
Web应用程序step1.将lucene-core-3.0.0.jar和lucene-demos-3.0.0jar这两个文件复制到安装Tomcat 的\common\lib中step2.解压下载的lucene-3.0.0.zip,可以看到luceneweb.war文件。
将该文件复制到安装Tomcat的\webappsstep3.重启Tomcat服务器。
step4.建立索引>java org.apache.lucene.demo.IndexHTML -create -index [索引数据存放路径] [被索引文件路径](如:D:\lucene\temp\index D:\lucene\temp\docs)step5.打开安装Tomcat的\webapps\luceneweb\configuration.jsp文件,找到String indexLocation = "***",将"***"改为第四步中[索引数据存放路径],保存关闭。
Lucene搜索入门教程
Lucene搜索入门教程1.了解搜索技术1.1搜索引擎搜索引擎是指根据一定的策略、运用特定的计算机程序从互联网上搜集信息,在对信息进行组织和处理后,为用户提供检索服务,将用户检索相关的信息展示给用户的系统。
搜索引擎包括全文索引、目录索引、元搜索引擎、垂直搜索引擎、集合式搜索引擎、门户搜索引擎与免费链接列表等。
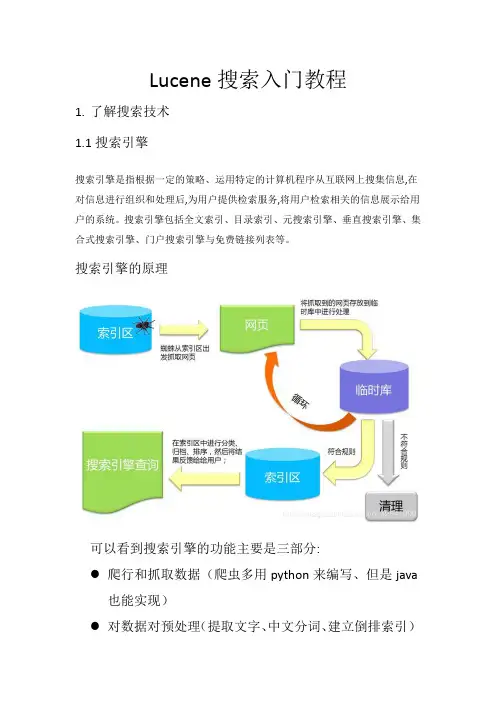
搜索引擎的原理可以看到搜索引擎的功能主要是三部分:●爬行和抓取数据(爬虫多用python来编写、但是java也能实现)●对数据对预处理(提取文字、中文分词、建立倒排索引)提供搜索功能(用户输入关键词后、去索引库搜索数据)在上述三个步骤中,java要解决的往往是后两个步骤:数据处理和搜索。
那么,我们之前学习的mysql知识也能实现数据的存储和搜索,为什么还要学新的东西呢?1.2传统数据库搜索的问题要实现类似百度的复杂搜索,或者京东的商品搜索,如果使用传统的数据库存储数据,那么会存在一系列的问题:●数据库数据单表存储能力有限,无法存储海量数据●解决大数据,可以进行分库分表。
但是分库分表会增加业务复杂度●搜索只能通过模糊匹配,效率极低●模糊搜索可能导致全表扫描,效率非常差在这里,比较棘手的其实是第二个问题:查询效率低,类似百度和京东这样的网站,对性能要求极高。
如果用户点击搜索需要很久才能拿到数据,没人愿意一直等待下去。
那么问题来了:如何才能提高模糊搜索时的效率呢?答案是:倒排索引技术1.3什么是倒排索引倒排索引是一种存储数据的方式,与传统查找有很大区别:●传统查找:采用数据按行存储,查找时逐行扫描,或者根据索引查找,然后匹配搜索条件,效率较差.概括来讲是先找到文档,然后看是否匹配.传统线性查找一个10MB的word文件,查找关键字如果在文档最后,大约3秒钟●倒排索引:首先对文档数据按照id进行索引存储,然后对文档中的数据分词,记录对词条进行索引,并记录词条在文档中出现的位置。
这样查找时只要找到了词条,就找到了对应的文档。
Lucene入门与使用

中国Lucene入门与使用本文主要面向具体使用,适用于已熟悉java编程的lucene初学者。
1. Lucene的简介1.1 Lucene 历史org.apache.lucene包是纯java语言的全文索引检索工具包。
Lucene的作者是资深的全文索引/检索专家,最开始发布在他本人的主页上,2001年10月贡献给APACHE,成为APACHE基金jakarta的一个子项目。
目前,lucene广泛用于全文索引/检索的项目中。
lucene也被翻译成C#版本,目前发展为(不过最近好象有流产的消息)。
1.2 Lucene 原理lucene的检索算法属于索引检索,即用空间来换取时间,对需要检索的文件、字符流进行全文索引,在检索的时候对索引进行快速的检索,得到检索位置,这个位置记录检索词出现的文件路径或者某个关键词。
在使用数据库的项目中,不使用数据库进行检索的原因主要是:数据库在非精确查询的时候使用查询语言“like %keyword%”,对数据库进行查询是对所有记录遍历,并对字段进行“%keyword%”匹配,在数据库的数据庞大以及某个字段存储的数据量庞大的时候,这种遍历是致命的,它需要对所有的记录进行匹配查询。
因此,lucene主要适用于文档集的全文检索,以及海量数据库的模糊检索,特别是对数据库的xml或者大数据的字符类型。
2.Lucene的下载和配置2.1 Lucene的下载lucene在jakarta项目中的发布主页:/lucene/docs/index.html。
以下主要针对windows 用户,其它用户请在上面的地址中查找相关下载。
lucene的.jar包的下载(包括.jar和一个范例demo):/jakarta/lucene/binaries/lucene-1.4-fina l.ziplucene的源代码下载:/mirrors/apache/jakarta/lucene/source/lucene-1 .4-final-src.ziplucene的api地址:/lucene/docs/api/index.html本文使用lucene版本:lucene-1.4-final.jar。
第十一讲-Lucene搜索深入实战进阶
欢迎访问我们的官方网站
北风网项目培训
第十一讲 Lucene搜索深入实战进阶
需要全套联系QQ:375537364
the quick brown fox jumped over the lazy dog
◦ 每个term均有一个位置:the是1,quick是2,brown是3……
◦ 如果跨度为3,则应该包括 the quick brown 3个term。
在某种跨度范围内,查找关键词并匹配文档,称为跨度搜索
SpanQuery是一个抽象类,实际的搜索功能由它的子类完成。
Direct Known Subclasses:
FieldMaskingSpanQuery, SpanMultiTermQueryWrapper, SpanNearQuery, S panNotQuery, SpanOrQuery,SpanPositionCheckQuery, SpanTermQuery
பைடு நூலகம்
代码实战:SpanQueryDemo.java
SpanQuery按照词在文章中的距离或者查询几个相邻词 的查询,SpanQuery包括以下几种:
◦ SpanTermQuery:词距查询的基础,结果和TermQuery相似,只不过是
增加了查询结果中单词的距离信息。
◦ ◦ ◦ ◦ SpanFirstQuery:在指定距离可以找到第一个单词的查询。 SpanNearQuery:查询的几个语句之间保持者一定的距离。 SpanOrQuery:把所有SpanQuery的结果综合起来,作为它的检索结果。 SpanNotQuery:从第一个SpanQuery的查询结果中,去掉第2个 SpanQuery的查询结果。
一步一步跟我学习lucene(1...
一步一步跟我学习lucene(1...这两天加班,不能兼顾博客的更新,请大家见谅。
有时候我们创建完索引之后,数据源可能有更新的内容,而我们又想像数据库那样能直接体现在查询中,这里就是我们所说的增量索引。
对于这样的需求我们怎么来实现呢?lucene内部是没有提供这种增量索引的实现的;这里我们一般可能会想到,将之前的索引全部删除,然后进行索引的重建。
对于这种做法,如果数据源的条数不是特别大的情况下倒还可以,如果数据源的条数特别大的话,势必会造成查询数据耗时,同时索引的构建也是比较耗时的,几相叠加,势必可能造成查询的时候数据缺失的情况,这势必严重影响用户的体验;比较常见的增量索引的实现是:•设置一个定时器,定时从数据源中读取比现有索引文件中新的内容或是数据源中带有更新标示的数据。
•对数据转换成需要的document并进行索引这样做较以上的那种全删除索引然后重建的好处在于:•数据源查询扫描的数据量小•相应的更新索引的条数也少,减少了大量的IndexWriter的commit和close这些耗时操作以上解决了增量的问题,但是实时性的问题还是存在的:•索引的变更只有在IndexWriter的commit执行之后才可以体现出来那么我们怎样对实时性有个提升呢,大家都知道lucene索引可以以文件索引和内存索引两种方式存在,相较于文件索引,内存索引的执行效率要高于文件索引的构建,因为文件索引是要频繁的IO操作的;结合以上的考虑,我们采用文件索引+内存索引的形式来进行lucene 的增量更新;其实现机制如下:•定时任务扫描数据源的变更•对获得的数据源列表放在内存中•内存中的document达到数量限制的时候,以队列的方式删除内存中的索引,并将之添加到文件索引•查询的时候采用文件+内存索引联合查询的方式以达到NRT效果定时任务调度器java内置了TimerT ask,此类是可以提供定时任务的,但是有一点就是TimerTask的任务是无状态的,我们还需要对任务进行并行的设置;了解到quartz任务调度框架提供了有状态的任务StatefulJob,即在本次调度任务没有执行完毕时,下次任务不会执行;常见的我们启动一个quartz任务的方式如下:[java] view plain copy1.Date runTime = DateBuilder.evenSecondDate(new Date()) ;2.StdSchedulerFactory sf = new StdSchedulerFactory();3.Scheduler scheduler = sf.getScheduler();4.JobDetail job = JobBuilder.newJob(XXX.class).build();5.Trigger trigger = TriggerBuilder.newTrigger().startAt(runTi me).withSchedule(SimpleScheduleBuilder.simpleSchedule().withI ntervalInSeconds(3).repeatForever()).forJob(job).build();6.scheduler.scheduleJob(job, trigger);7.8.scheduler.start();</span>以上我们是设置了每三秒执行一次定时任务,而任务类是XXX 任务类通用方法这里我定义了一个XXX的父类,其定义如下:[java] view plain copy1.package com.chechong.lucene.indexcreasement;2.3.import java.util.List;4.import java.util.TimerTask;5.6.import org.apache.lucene.store.RAMDirectory;7.import org.quartz.Job;8.import org.quartz.StatefulJob;9.10./**有状态的任务:串行执行,即不允许上次执行没有完成即开始本次如果需要并行给接口改为Job即可11.* @author lenovo12.*13.*/14.public abstract class BaseInCreasementIndex implem ents StatefulJob {15./**16.* 内存索引17.*/18.private RAMDirectory ramDirectory;19.public BaseInCreasementIndex() {20.}21.public BaseInCreasementIndex(RAMDirectory ramDire ctory) {22.super();23.this.ramDirectory = ramDirectory;24.}25.26./**更新索引27.* @throws Exception28.*/29.public abstract void updateIndexData() throws Excep tion;30./**消费数据31.* @param list32.*/33.public abstract void consume(List list) throws Excepti on;34.}任务类相关实现,以下方法是获取待添加索引的数据源XXXInCreasementIndex[java] view plain copy1.@Override2.public void execute(JobExecutionContext context) throw s JobExecutionException {3.try {4.XXXInCreasementIndex index = new XXXInCreasementIn dex(Constants.XXX_INDEX_PATH, XXXDao.getInstance(), RamDir ectoryControl.getRAMDireactory());5.index.updateIndexData();6.} catch (Exception e) {7.// TODO Auto-generated catch block8.e.printStackTrace();9.}10.}[java] view plain copy1.@Override2.public void updateIndexData() throws Exception {3.int maxBeanID = SearchUtil.getLastIndexBeanID();4.System.out.println(maxBeanID);5.List<XXX> sources = XXXDao.getListInfoBefore(maxBeanID);、、6.if (sources != null && sources.size() > 0) {7.this.consume(sources);8.}9.}这里,XXX代表我们要获取数据的实体类对象consume方法主要是做两件事:•数据存放到内存索引•判断内存索引数量,超出限制的话以队列方式取出超出的数量,并将之存放到文件索引[java] view plain copy1.@Override2.public void consume(List list) throws Exception {3.IndexWriter writer = RamDirectoryControl.getRAMIndex Writer();4.RamDirectoryControl.consume(writer,list);5.}上边我们将内存索引和队列的实现放在了RamDirectoryControl 中内存索引控制器首先我们对内存索引的IndexWriter进行初始化,在初始化的时候需要注意先执行一次commit,否则会提示no segments的异常[java] view plain copy1.private static IndexWriter ramIndexWriter;2.private static RAMDirectory directory;3.static{4.directory = new RAMDirectory();5.try {6.ramIndexWriter = getRAMIndexWriter();7.} catch (Exception e) {8.// TODO Auto-generated catch block9.e.printStackTrace();10.}11.}12.public static RAMDirectory getRAMDireactory(){13.return directory;14.}15.public static IndexSearcher getIndexSearcher() throw s IOException{16.IndexReader reader = null;17.IndexSearcher searcher = null;18.try {19.reader = DirectoryReader.open(directory);20.} catch (IOException e) {21. e.printStackTrace();22.}23.searcher = new IndexSearcher(reader);24.return searcher;25.}26./**单例模式获取ramIndexWriter27.* @return28.* @throws Exception29.*/30.public static IndexWriter getRAMIndexWriter() throw s Exception{31.if(ramIndexWriter == null){32.synchronized (IndexWriter.class) {33.Analyzer analyzer = new IKAnalyzer();34.IndexWriterConfig iwConfig = new IndexWriterConfig (analyzer);35.iwConfig.setOpenMode(OpenMode.CREATE_OR_APPE ND);36.try {37.ramIndexWriter = new IndexWriter(directory, iwConfig);mit();39.ramIndexWriter.close();40.iwConfig = new IndexWriterConfig(analyzer);41.iwConfig.setOpenMode(OpenMode.CREATE_OR_APPE ND);42.ramIndexWriter = new IndexWriter(directory, iwConfig);43.} catch (IOException e) {44.// TODO Auto-generated catch block45. e.printStackTrace();46.}47.}48.}49.50.return ramIndexWriter;51.}定义一个获取内存索引中数据条数的方法[java] view plain copy1./**根据查询器、查询条件、每页数、排序条件进行查询2.* @param query 查询条件3.* @param first 起始值4.* @param max 最大值5.* @param sort 排序条件6.* @return7.*/8.public static TopDocs getScoreDocsByPerPageAndSortFi eld(IndexSearcher searcher,Query query, int first,int max, Sort s ort){9.try {10.if(query == null){11.System.out.println(" Query is null return null ");12.return null;13.}14.TopFieldCollector collector = null;15.if(sort != null){16.collector = TopFieldCollector.create(sort, first+max, fal se, false, false);17.}else{18.SortField[] sortField = new SortField[1];19.sortField[0] = new SortField("createTime",SortField.Ty pe.STRING,true);20.Sort defaultSort = new Sort(sortField);21.collector = TopFieldCollector.create(defaultSort,first+ max, false, false, false);22.}23.searcher.search(query, collector);24.return collector.topDocs(first, max);25.} catch (IOException e) {26.// TODO Auto-generated catch block27.}28.return null;29.}此方法返回结果为T opDocs,我们根据TopDocs的totalHits来获取内存索引中的数据条数,以此来鉴别内存占用,防止内存溢出。
lunce搜索引擎框架教程
全文搜索lucene使用与优化2008-01-23 20:581lucene 简介1.1什么是luceneLucene是一个全文搜索框架,而不是应用产品。
因此它并不像或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品。
1.2 lucene能做什么要回答这个问题,先要了解lucene的本质。
实际上lucene的功能很单一,说到底,就是你给它若干个字符串,然后它为你提供一个全文搜索服务,告诉你你要搜索的关键词出现在哪里。
知道了这个本质,你就可以发挥想象做任何符合这个条件的事情了。
你可以把站内新闻都索引了,做个资料库;你可以把一个数据库表的若干个字段索引起来,那就不用再担心因为“紐ike%”而锁表了;你也可以写个自己的搜索引擎……1.3你该不该选择lucene下面给岀一些测试数据,如果你觉得可以接受,那么可以选择。
测试一:250万记录,300M左右文本,生成索引380M左右,800线程下平均处理时间300ms o测试二:37000记录,索引数据库中的两个varchar字段,索引文件2. 6M, 800 线程下平均处理时间1.5ms。
2lucene的工作方式lucene提供的服务实际包含两部分:一入一出。
所谓入是写入,即将你提供的源(本质是字符串)写入索引或者将其从索引中删除;所谓出是读出,即向用户提供全文搜索服务,让用户可以通过关键词定位源。
2.1写入流程源字符串首先经过analyzer处理,包括:分词,分成一个个单词;去除stopword (非索引字)(可选)。
将源中需要的信息加入Document的各个Field中,并把需要索引的Field索引起来,把需要存储的Field存储起来。
将索引写入存储器,存储器可以是内存或磁盘。
2.2读出流程用户提供搜索关键词,经过analyzer处理。
对处理后的关键词搜索索引找岀对应的Documento用户根据需要从找到的Document中提取需要的Field。
lucene第四讲-Lucene索引深入
Positions : 文件后缀名:.pos 保存了每个Term在Document中的位置集合。 样例截图:
Lucene 4.1 postings format, which encodes postings in packed integer blocks for fast decode. NOTE: this format is still experimental and subject to change without backwards compatibility.
Fields (Lucene 4.2字段集合信息文件格式): 文件后缀名:.fnm Field的名字都存储在Field信息文件中。 查看样例代码: 字段有: path modified contents
Field Index (field索引文件):
文件后缀名:.fdx
保存了每个Document的Field Data的地址指针。
修改run命令 加入 –update 参数 保证非每次新建索引 删除一个文件1.txt
再检索,查看是否生成了 _1_1.del 文件
Compound File(索引片段信息 Lucene 4.0 Segment info format. ): 文件后缀名:.cfs, .cfe 当采用复合文件建立索引时,所有索引文件会保存在一个.cfs文件 内。
not a limitation of the index file format, just of Lucene's current implementation.)
同理:也是使用int 对document文档源计数的。并且索引文件格式也是采用
的 Int32 在硬盘上存储document文档号的。这个限制即是实现版本也是索引文件格
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Lucene教案全文检索技术传智.关云长1Lucene介绍1.1为什么学习lucene问题1:如何根据某个词搜索数据库中存储的大文本信息?答案:只能使用like语句进行模糊查询,比如%传智播客%。
问题2:如果使用大量的like语句同时查询数据库,是否会存在问题?答案:使用数据库中的like语句查询数据的效率是很慢的,如果有大量的查询请求,响应结果的速度惨不忍睹。
如何解决以上的问题?解决方案:通过全文检索技术,可以解决该问题。
1.2全文检索是什么全文检索首先将要查询的目标文档中的词提取出来,组成索引,通过查询索引达到搜索目标文档的目的。
这种先建立索引,再根据索引搜索文档的过程就叫全文检索(Full-text Search)。
举例:全文检索的过程,就类似于查询字典的过程。
Lucene是全文检索技术中最常用的一种。
1.3全文检索流程通过架构分析,全文检索的流程分为两大部分:索引流程、搜索流程。
●索引流程:即采集数据→创建索引文档→存储到索引库。
●搜索流程:即用户输入搜索条件→搜索索引→从索引库获取文档→渲染搜索结果。
1.4Lucene是什么Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
常用的全文检索应用有:搜索引擎(百度、谷歌)、站内搜索(京东商城的商品搜索)Lucene和全文检索应用的区别:1、Lucene是全文检索引擎工具包,程序员使用它可以开发全文检索应用。
2、全文检索应用比如百度搜索引擎,它是一个完整的、可以单独运行的全文检索系统。
2入门程序2.1需求使用Lucene实现电商项目中图书类商品的索引和搜索功能。
2.2环境准备●Jdk环境:1.7.0_72●Ide环境:eclipse mars●数据库环境:mysql 5.1●Lucene:4.10.32.2.1数据库初始化b o o k.sq l2.2.2Lucene下载Lucene是开发全文检索功能的工具包,使用时从官方网站下载,并解压。
官方网站:/目前最新版本:5.2.1下载地址:/dist/lucene/java/下载版本:4.10.3JDK要求:1.7以上(从版本4.8开始,不支持1.7以下)2.3工程搭建(两步)2.3.1第一步:创建java工程2.3.2第二步:添加jar包入门程序只需要添加以下jar包:● mysql5.1驱动包:mysql-connector-java-5.1.7-bin.jar ● 核心包:lucene-core-4.10.3.jar● 分析器通用包:lucene-analyzers-common-4.10.3.jar ● 查询解析器包:lucene-queryparser-4.10.3.jar ● junit 包:junit-4.9.jar2.4 索引流程2.4.1 Lucene 实现索引流程分析IndexWriter 是Lucene 实现索引过程的核心组件,通过IndexWriter 可以创建新索引、更新索引、删除索引操作。
IndexWriter 需要通过Directory 对索引进行存储操作。
Directory 描述了索引的存储位置,底层封装了I/O 操作,负责对索引进行存储。
它是一个抽象类,它的子类常用的包括FSDirectory (在文件系统存储索引)、RAMDirectory (在内存存储索引)。
2.4.1.1 为什么要采集数据全文检索要搜索的数据信息格式多种多样,拿搜索引擎(百度, google )来说,通过搜索引擎网站能搜索互联网站上的网页(html)、互联网上的音乐(mp3..)、视频(avi..)、pdf 电子书等。
全文检索搜索的这些数据称为非结构化数据。
结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等。
如何对结构化数据搜索?由于结构化数据是固定格式,所以就可以针对固定格式的数据设计算法来搜索,比如数据库like查询,like查询采用顺序扫描法,使用关键字匹配内容,对于内容量大的like查询速度慢。
如何对非结构化数据搜索?需要将所有要搜索的非结构化数据通过技术手段采集到一个固定的地方,将这些非结构化的数据想办法组成结构化的数据,再以一定的算法去搜索。
2.4.1.2如何采集数据采集数据技术有哪些?1、对于互联网上网页采用http将网页抓取到本地生成html文件。
2、如果数据在数据库中就连接数据库读取表中的数据。
3、如果数据是文件系统中的某个文件,就通过文件系统读取文件的内容。
网页采集(了解)因为目前搜索引擎主要搜索数据的来源是互联网,搜索引擎使用一种爬虫程序抓取网页(通过http抓取html网页信息),以下是一些爬虫项目:Solr(/solr),solr是apache的一个子项目,支持从关系数据库、xml文档中提取原始数据。
Nutch(/nutch), Nutch是apache的一个子项目,包括大规模爬虫工具,能够抓取和分辨web网站数据。
jsoup(/),jsoup 是一款Java 的HTML解析器,可直接解析某个URL地址、HTML文本内容。
它提供了一套非常省力的API,可通过DOM,CSS以及类似于jQuery 的操作方法来取出和操作数据。
heritrix(/projects/archive-crawler/files/),Heritrix 是一个由java 开发的、开源的网络爬虫,用户可以使用它来从网上抓取想要的资源。
其最出色之处在于它良好的可扩展性,方便用户实现自己的抓取逻辑。
2.4.1.3索引文件的逻辑结构(重点)⏹文档域:用于存储。
将采集到的数据统一格式为Document文档格式,然后将数据存储到Document对象中的Field域中。
一个Document文档有多个field域,不同的文档其field 的个数可以不同,建议相同类型的文档包括相同的field。
本例子一个document对应一条book表的记录。
⏹索引域:用于搜索,索引域中存储的是一个个分好的词项(Term),它是索引的最小单位。
通过搜索词项,再根据该词项对应的倒排索引表,则可以找到对应的文档。
词项的表示方式【域名:词】,比如bookname:java,就是一个词项,表示该词是bookname 域中分出来的词。
⏹倒排索引表一个词项对应一个倒排索引表。
传统方法是先找到文件,如何在文件中找内容,在文件内容中匹配搜索关键字,这种方法是顺序扫描方法,数据量大就搜索慢。
倒排索引结构是根据内容(词语)找文档,倒排索引结构也叫反向索引结构,包括索引和文档两部分,索引即词汇表,它是在索引中匹配搜索关键字,由于索引内容量有限并且采用固定优化算法搜索速度很快,找到了索引中的词汇,词汇与文档关联,从而最终找到了文档。
2.4.2代码实现2.4.2.1数据采集针对电商站内搜索功能,全文检索的数据源在数据库中,需要通过jdbc访问数据库中book表的内容。
2.4.2.1.1Po2.4.2.1.2Dao2.4.2.2索引实现2.4.3使用Luke查看索引Luke作为Lucene工具包中的一个工具(/luke/),可以通过界面来进行索引文件的查询、修改。
打开Luke方法:●命令运行:cmd运行:java -jar lukeall-4.10.3.jar●手动执行:双击lukeall-4.10.3.jar2.4.4分词理解在对Docuemnt中的内容索引之前需要使用分词器进行分词,分词的目的是为了搜索。
分词的主要过程就是先分词后过虑。
●分词:采集到的数据会存储到document对象的Field域中,分词就是将Document中Field的value值切分成一个一个的词。
●过虑:包括去除标点符号过滤、去除停用词过滤(的、是、a、an、the等)、大写转小写、词的形还原(复数形式转成单数形参、过去式转成现在式。
)等。
什么是停用词?停用词是为节省存储空间和提高搜索效率,搜索引擎在索引页面或处理搜索请求时会自动忽略某些字或词,这些字或词即被称为Stop Words(停用词)。
比如语气助词、副词、介词、连接词等,通常自身并无明确的意义,只有将其放入一个完整的句子中才有一定作用,如常见的“的”、“在”、“是”、“啊”等。
对于分词来说,不同的语言,分词规则不同。
Lucene作为了一个工具包提供不同国家的分词器,如下图:本例子使用StandardAnalyzer,它可以对用英文进行分词。
如下是org.apache.lucene.analysis.standard.standardAnalyzer的部分源码:Tokenizer是分词器,负责将reader转换为语汇单元即进行分词处理,Lucene提供了很多的分词器,也可以使用第三方的分词,比如IKAnalyzer一个中文分词器。
tokenFilter是分词过滤器,负责对语汇单元进行过滤,tokenFilter可以是一个过滤器链儿,Lucene提供了很多的分词器过滤器,比如大小写转换、去除停用词等。
如下图是语汇单元的生成过程:从一个Reader字符流开始,创建一个基于Reader的Tokenizer分词器,经过三个TokenFilter生成语汇单元Token。
比如下边的文档经过分析器分析如下:同一个域中相同的语汇单元(Token)对应同一个Term(词),它记录了语汇单元的内容及所在域的域名等。
●不同的域中拆分出来的相同的单词对应不同的term。
●相同的域中拆分出来的相同的单词对应相同的term。
例如:图书信息里面,图书名称中的java和图书描述中的java对应不同的term2.5 搜索流程2.5.1 Lucene 实现搜索过程分析2.5.1.1 输入查询语句可以通过Query 对象输入查询语句。
同数据库的sql 一样,lucene 也有固定的查询语法: 最基本的有比如:AND, OR, NOT 等(必须大写)举个例子,用户想找一个description 中包括java 关键字和lucene 关键字的文档。
它对应的查询语句:description:java AND lucene如下是使用luke 搜索的例子:2.5.1.2搜索分词和索引过程的分词一样,这里要对用户输入的关键字进行分词,一般情况索引和搜索使用的分词器一致。
比如:输入搜索关键字“java培训”,分词后为java和培训两个词,与java和培训有关的内容都搜索出来了,如下:2.5.2代码实现3Field域3.1Field属性Field是文档中的域,包括Field名和Field值两部分,一个文档可以包括多个Field,Document只是Field的一个承载体,Field值即为要索引的内容,也是要搜索的内容。