hadoop入门学习资料大全
Hadoop 初步学习文档
Hadoop初步学习文档1 Hadoop简介Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。
它支持在商品硬件构建的大型集群上运行的应用程序。
Hadoop是根据Google 公司发表的MapReduce和Google文件系统的论文自行实现而成。
1.1Hadoop基本构成Hadoop是一个能够对大量数据进行分布式处理的软件框架, Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
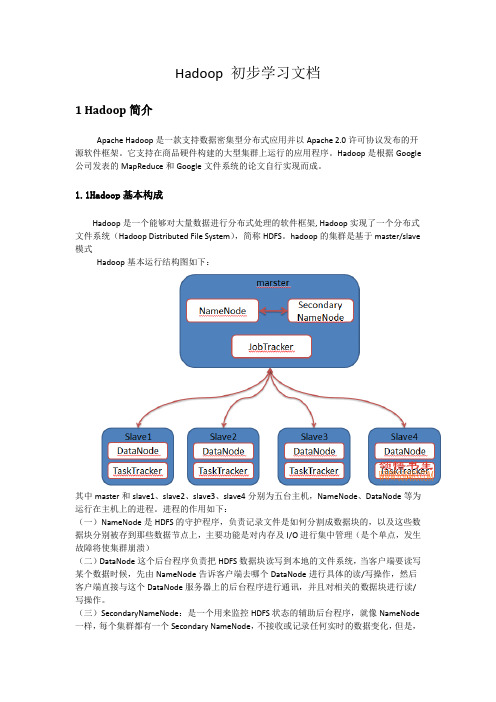
hadoop的集群是基于master/slave 模式Hadoop基本运行结构图如下:其中master和slave1、slave2、slave3、slave4分别为五台主机,NameNode、DataNode等为运行在主机上的进程。
进程的作用如下:(一)NameNode是HDFS的守护程序,负责记录文件是如何分割成数据块的,以及这些数据块分别被存到那些数据节点上,主要功能是对内存及I/O进行集中管理(是个单点,发生故障将使集群崩溃)(二)DataNode这个后台程序负责把HDFS数据块读写到本地的文件系统,当客户端要读写某个数据时候,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后客户端直接与这个DataNode服务器上的后台程序进行通讯,并且对相关的数据块进行读/写操作。
(三)SecondaryNameNode:是一个用来监控HDFS状态的辅助后台程序,就像NameNode 一样,每个集群都有一个Secondary NameNode,不接收或记录任何实时的数据变化,但是,他会与NameNode进行通信,以便定期的保存HDFS元数据的快照,如果Name发生问题,SecondaryNameNode可以及时的作为备用NameNode。
(四)JobTracker:用来连接应用程序与Hadoop,用户代码提交到集群以后,由JobTracker 决定那个文件将被处理,并且为不同的task分配节点,同时,他还监控所有运行的task一旦某个task失败了JobTacker就会自动重新开启task。
Hadoop基础知识培训

存储+计算(HDFS2+Yarn)
集中存储和计算的主要瓶颈
Oracle IBM
EMC存储
scale-up(纵向扩展)
➢计算能力和机器数量成正比 ➢IO能力和机器数量成非正比
多,Intel,Cloudera,hortonworks,MapR • 硬件基于X86服务器,价格低,厂商多 • 可以自行维护,降低维护成本 • 在互联网有大规模成功案例(BAT)
总 结
• Hadoop平台在构建数据云(DAAS)平台有天 然的架构和成本的优势
成本投资估算:从存储要求计算所需硬件及系统软件资源(5000万用户 为例)
往HDFS中写入文件
• 首要的目标当然是数 据快速的并行处理。 为了实现这个目标, 我们需要竟可能多的 机器同时工作。
• Cient会和名称节点达 成协议(通常是TCP 协议)然后得到将要 拷贝数据的3个数据节 点列表。然后Client将 会把每块数据直接写 入数据节点中(通常 是TCP 协议)。名称 节点只负责提供数据 的位置和数据在族群 中的去处(文件系统 元数据)。
• 第二个和第三个数据 节点运输在同一个机 架中,这样他们之间 的传输就获得了高带 宽和低延时。只到这 个数据块被成功的写 入3个节点中,下一 个就才会开始。
• 如果名称节点死亡, 二级名称节点保留的 文件可用于恢复名称 节点。
• 每个数据节点既扮演者数据存储的角色又 冲当与他们主节点通信的守护进程。守护 进程隶属于Job Tracker,数据节点归属于 名称节点。
hadoop入门学习资料大全

Hadoop是一个分布式系统基础架构,由Apache基金会开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力高速运算和存储。
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。
而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
搜索了一些WatchStor存储论坛关于hadoop入门的一些资料分享给大家希望对大家有帮助jackrabbit封装hadoop的设计与实现/thread-60444-1-1.html用Hadoop进行分布式数据处理/thread-60447-1-1.htmlHadoop源代码eclipse编译教程/thread-60448-1-2.htmlHadoop技术讲解/thread-60449-1-2.htmlHadoop权威指南(原版)/thread-60450-1-2.htmlHadoop源代码分析完整版/thread-60451-1-2.html基于Hadoop的Map_Reduce框架研究报告/thread-60452-1-2.htmlHadoop任务调度/thread-60453-1-2.htmlHadoop使用常见问题以及解决方法/thread-60454-1-2.html HBase:权威指南/thread-60455-1-2.htmlCentOS下Hadoop-0.20.2集群配置文档/thread-60457-1-2.html[Hadoop实战].(Hadoop.in.Action)m.文字版/thread-60458-1-2.html基于Hadoop_平台的数据分析方案的设计应用/thread-60459-1-2.html基于单机的Hadoop伪分布式运行模拟实现即其分析过程(完整版) /thread-60460-1-2.html精通Hadoop/thread-60462-1-2.htmlMongoDB高级查询/thread-60463-1-1.htmlHadoop分布式文件系统:架构和设计/thread-60465-1-1.htmlEclipse Hadoop环境配置/thread-60466-1-1.htmlHadoop集群配置/thread-60467-1-1.htmlMapReduce&Hadoop技术、原理及应用/thread-60469-1-1.html使用Hadoop构建云计算平台/thread-60471-1-1.html实战Hadoop——开启通向云计算的捷径/thread-60473-1-1.htmlHadoop云计算技术介绍/thread-60474-1-1.htmlhadoop源码分析-mapreduce部分/thread-60475-1-1.htmlHbase_分析报告白皮书/thread-60476-1-1.htmlHadoop in Action/thread-60477-1-1.htmlHadoop Map/Reduce教程/thread-60478-1-1.htmlHadoop+Ubuntu学习笔记/thread-60479-1-1.htmlhadoop-0.20_程式设计/thread-60480-1-1.htmlHadoop FAQ/thread-60481-1-1.html。
hadoop 三大部件基础知识

hadoop 三大部件基础知识Hadoop是一个分布式计算框架,由三个主要部件组成:Hadoop分布式文件系统(Hadoop Distributed File System,简称HDFS)、Hadoop MapReduce和Hadoop YARN(Yet Another Resource Negotiator)。
HDFS是Hadoop的文件系统,它被设计为能够容纳大规模数据集,并且能够在廉价硬件上高效运行。
HDFS将数据划分为多个块,并将这些块分布在集群的不同节点上,以实现数据的可靠存储和高效读写。
HDFS还提供了高容错性和高可伸缩性,通过数据冗余和自动数据备份来保证数据的安全性。
MapReduce是Hadoop的计算模型,它能够并行地处理大规模数据集。
MapReduce将任务分为两个主要阶段:Map阶段和Reduce阶段。
在Map阶段,数据被划分为多个小任务,并由集群中的不同节点并行处理。
在Reduce阶段,Map阶段的结果被整合和汇总。
MapReduce模型的优势在于能够充分利用大规模集群的计算能力,从而加速数据处理过程。
YARN是Hadoop的资源管理系统,它负责集群资源的调度和管理。
YARN将集群的计算资源划分为多个容器,每个容器都有一定的计算能力和内存资源。
YARN可以根据任务的需求,动态地分配和管理集群资源,以提高系统的利用率和性能。
YARN的灵活性和可扩展性使得Hadoop能够更好地适应不同类型的工作负载。
通过使用HDFS、MapReduce和YARN,Hadoop能够处理大规模的数据,并提供高效的分布式计算能力。
它已经被广泛应用于各个领域,包括搜索引擎、社交网络分析、数据挖掘等。
Hadoop的三大部件相互协作,共同构建了一个强大的分布式计算平台,为大数据处理提供了可靠和高效的解决方案。
无论是处理海量数据还是提供实时分析,Hadoop都是一个不可或缺的工具。
hadoop知识点

hadoop知识点一、Hadoop简介Hadoop是一个开源的分布式计算系统,由Apache基金会开发和维护。
它能够处理大规模数据集并存储在集群中的多个节点上,提供高可靠性、高可扩展性和高效性能。
Hadoop主要包括两个核心组件:Hadoop Distributed File System(HDFS)和MapReduce。
二、HDFS1. HDFS架构HDFS是一个分布式文件系统,它将大文件分割成多个块并存储在不同的节点上。
它采用主从架构,其中NameNode是主节点,负责管理整个文件系统的命名空间和访问控制;DataNode是从节点,负责存储实际数据块。
2. HDFS特点HDFS具有以下特点:(1)适合存储大型文件;(2)数据冗余:每个数据块都会复制到多个节点上,提高了数据可靠性;(3)流式读写:支持一次写入、多次读取;(4)不适合频繁修改文件。
三、MapReduce1. MapReduce架构MapReduce是一种编程模型,用于处理大规模数据集。
它将任务分为两个阶段:Map阶段和Reduce阶段。
Map阶段将输入数据划分为若干组,并对每组进行处理得到中间结果;Reduce阶段将中间结果进行合并、排序和归约,得到最终结果。
2. MapReduce特点MapReduce具有以下特点:(1)适合处理大规模数据集;(2)简化了分布式计算的编程模型;(3)可扩展性好,可以在数百甚至数千台服务器上运行。
四、Hadoop生态系统1. Hadoop Common:包含Hadoop的基本库和工具。
2. HBase:一个分布式的、面向列的NoSQL数据库。
3. Hive:一个数据仓库工具,可以将结构化数据映射成HiveQL查询语言。
4. Pig:一个高级数据流语言和执行框架,用于大规模数据集的并行计算。
5. ZooKeeper:一个分布式协调服务,用于管理和维护集群中各个节点之间的状态信息。
五、Hadoop应用场景1. 日志分析:通过Hadoop收集、存储和分析日志数据,帮助企业实现对用户行为的监控和分析。
hadoop复习

算数据和计算任务
1.3 Hadoop 集群的启动过程
首先启动 hdfs start-dfs.sh
然后启动 yarn start-yarn.sh
最后启动 mr-jobhistory-daemo.sh start historyserver
1.4 Hadoop 启动成功的标志。
在 hadoop1 上 jps
Jps
DataNode
NameNode
在 hadoop2 上 jps
Jps
DataNode
ResourceManager
NodeManager
在 hadoop3 上 jpsLeabharlann JpsDataNode
JobHistoryServer
NodeManager
SecondaryNameNode
1.5 Master/Slave 架构的概念
MapReduce
1.7 HDFS 的存储原理、DataNode 与 NameNode 的概念
Hdfs 中最基本的存储单位就是数据块,DFS 上的文件被划分为块大小的多个分块,作为
Hadoop大数据处理入门指南

Hadoop大数据处理入门指南第一章:大数据概述1.1 什么是大数据大数据指的是数据量庞大、种类多样、处理速度快的数据集合。
随着互联网的普及和信息化的发展,大数据愈发普遍,这些数据包括来自社交媒体、传感器、日志文件等多个来源。
1.2 大数据的挑战大数据的处理面临着四个主要挑战,即数据量庞大、数据多样性、数据处理速度和数据价值挖掘。
第二章:Hadoop概述2.1 Hadoop的定义Hadoop是一个开源的分布式计算框架,能够处理大规模数据集,提供了可靠性、可扩展性和分布式计算的特性。
2.2 Hadoop的架构Hadoop的架构由HDFS(分布式文件系统)和MapReduce(分布式计算框架)组成。
HDFS用于存储和管理大数据集,MapReduce用于处理和分析这些数据。
第三章:Hadoop生态系统3.1 Hadoop生态系统简介Hadoop生态系统由多个组件组成,包括Hive、HBase、Pig、Spark等工具和技术,用于进一步扩展Hadoop的功能和应用范围。
3.2 HiveHive是一个基于Hadoop的数据仓库工具,可以用SQL语言查询和分析大数据集。
它提供了类似于关系数据库的功能,简化了大数据处理的复杂性。
3.3 HBaseHBase是一个分布式、可扩展且高性能的数据库,用于存储和查询海量结构化数据。
它具有快速随机读写功能,适用于需要实时访问大数据集的应用。
3.4 PigPig是一个用于大数据分析的平台,它提供了一种类似于脚本的语言Pig Latin来处理结构化和半结构化数据。
3.5 SparkSpark是一个快速、通用的集群计算系统,用于大规模数据处理。
它支持多种编程语言,并提供了高级API,以便于进行复杂数据分析和机器学习算法。
第四章:Hadoop的安装与配置4.1 下载与安装在本节中,将介绍如何从官方网站下载Hadoop,并进行详细的安装说明。
4.2 配置Hadoop集群探讨如何配置Hadoop集群,包括修改配置文件,设置环境变量和网络连接等。
hadoop大数据开发基础笔记

Hadoop大数据开发基础笔记一、概述随着互联网和信息技术的迅猛发展,大数据技术已成为当前热门的领域之一。
Hadoop作为大数据处理领域的重要工具,对于开发者来说是必须掌握的技能之一。
本文将从Hadoop的概念、架构、组件以及基本操作等方面进行系统的介绍和总结,帮助读者快速掌握Hadoop大数据开发的基础知识。
二、Hadoop概述1. Hadoop的概念Hadoop是一个开源的分布式存储和计算评台,最初是由Apache基金会开发的。
它能够处理海量数据,并提供高性能的分布式数据存储和处理能力。
Hadoop的核心是HDFS(Hadoop分布式文件系统)和MapReduce(分布式计算框架),它们共同构成了Hadoop评台的基础架构。
2. Hadoop的特点Hadoop具有高可靠性、高可扩展性和高效能处理大规模数据的能力。
它支持海量数据的存储和处理,并且能够快速地处理数据,从而为用户提供快速的数据分析和挖掘能力。
三、Hadoop架构1. Hadoop的架构组成Hadoop的架构分为HDFS和MapReduce两部分。
其中,HDFS负责数据的存储和管理,而MapReduce负责数据的计算和处理。
另外,Hadoop还包括了YARN(资源调度和管理),这是最新版本中引入的资源管理框架,它为Hadoop提供了更好的资源管理和任务处理能力。
2. Hadoop的工作流程Hadoop的工作流程包括数据的存储、计算和结果的输出等基本步骤。
数据被分割成小的块并存储在HDFS中,然后MapReduce框架将数据分发给不同的计算节点进行处理,最后将处理结果输出到HDFS中。
四、Hadoop组件1. HDFSHDFS是Hadoop分布式文件系统的简称,它是Hadoop的核心组成部分之一。
HDFS采用主从架构,包括一个NameNode节点和多个DataNode节点。
NameNode负责管理文件系统的命名空间和数据块的映射信息,而DataNode负责实际的数据存储。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
hadoop入门学习资料大全
Hadoop是一个分布式系统基础架构,由Apache基金会开发。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。
充分利用集群的威力高速运算和存储。
简单地说来,Hadoop是一个可以更容易开发和运行处理大规模数据的软件平台。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。
HDFS有着高容错性(fault-tolerent)的特点,并且设计用来部署在低廉的(low-cost)硬件上。
而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。
搜索了一些WatchStor存储论坛关于hadoop入门的一些资料分享给大家希望对大家有帮助
注:咱们坛子里资料很丰富如果您想下载更多关于hadoop方面的技术资料可以用论坛搜
)
索搜索“大数据(Big data”即可。
jackrabbit封装hadoop的设计与实现
/thread-60444-1-1.html
用Hadoop 进行分布式数据处理
/thread-60447-1-1.html
Hadoop源代码eclipse编译教程
/thread-60448-1-2.html
Hadoop技术讲解
/thread-60449-1-2.html
Hadoop权威指南(原版)
/thread-60450-1-2.html
Hadoop源代码分析完整版
/thread-60451-1-2.html
基于Hadoop的Map_Reduce框架研究报告
/thread-60452-1-2.html
Hadoop任务调度
/thread-60453-1-2.html
Hadoop使用常见问题以及解决方法
/thread-60454-1-2.html
HBase:权威指南
/thread-60455-1-2.html
CentOS下Hadoop-0.20.2集群配置文档
/thread-60457-1-2.html
[Hadoop实战].(Hadoop.in.Action)m.文字版
/thread-60458-1-2.html
基于Hadoop_平台的数据分析方案的设计应用
/thread-60459-1-2.html
基于单机的Hadoop伪分布式运行模拟实现即其分析过程(完整版) /thread-60460-1-2.html
精通Hadoop
/thread-60462-1-2.html
MongoDB高级查询
/thread-60463-1-1.html
Hadoop分布式文件系统:架构和设计
/thread-60465-1-1.html
Eclipse Hadoop环境配置
/thread-60466-1-1.html
Hadoop集群配置
/thread-60467-1-1.html
MapReduce & Hadoop 技术、原理及应用/thread-60469-1-1.html
使用Hadoop构建云计算平台
/thread-60471-1-1.html
实战Hadoop ——开启通向云计算的捷径/thread-60473-1-1.html
Hadoop云计算技术介绍
/thread-60474-1-1.html
hadoop源码分析-mapreduce部分
/thread-60475-1-1.html
Hbase_分析报告白皮书
/thread-60476-1-1.html
Hadoop in Action
/thread-60477-1-1.html
Hadoop Map/Reduce教程
/thread-60478-1-1.html
Hadoop+Ubuntu学习笔记
/thread-60479-1-1.html
hadoop-0.20_程式设计
/thread-60480-1-1.html
Hadoop FAQ
/thread-60481-1-1.html
Hadoop云计算技术介绍
/thread-60474-1-2.html
使用Hadoop构建云计算平台
/thread-60471-1-1.html Hadoop任务调度
/thread-60453-1-2.html
Hadoop分布式文件系统:架构和设计
/thread-60465-1-2.html
hadoop-0.20_程式设计
/thread-60480-1-1.html
Hadoop Map/Reduce教程
/thread-60478-1-1.html
Hadoop源代码eclipse编译教程
/thread-60448-1-2.html
hadoop+hbase+zookeeper集群安装方法/thread-70933-1-3.html
实战Hadoop ——开启通向云计算的捷径/thread-60473-1-2.html
基于Hadoop的Map_Reduce框架研究报告/thread-60452-1-1.html
掌握方法如何利用Hadoop廉价大数据分析/thread-60359-1-1.html
其他推荐:
Linux 系统管理学习笔记
/thread-161437-1-2.html
vSphere 4系列教程
/thread-162743-1-2.html
一起学Shell
/thread-161616-1-2.html
AIX小机学习资料下载
/thread-60888-1-2.html
OpenStack详细解读
/thread-113626-1-4.html
更多请访问WatchStor存储论坛。