西安电子科技大学编译原理04-4
电子科技大学编译原理--A2答案--网络教育

《计算机编译原理》试卷A2参考答案一、单项选择题(每小题1分,共25分)1、构造编译程序应掌握___D___。
A、源程序B、目标语言C、编译方法D、以上三项都是2、变量应当___C___。
A、持有左值B、持有右值C、既持有左值又持有右值D、既不持有左值也不持有右值3、编译程序绝大多数时间花在___D___上。
A、出错处理B、词法分析C、目标代码生成D、管理表格4、___D___不可能是目标代码。
A、汇编指令代码B、可重定位指令代码C、绝对指令代码D、中间代码5、使用___A___可以定义一个程序的意义。
A、语义规则B、词法规则C、产生规则D、词法规则6、词法分析器的输入是___B___。
A、单词符号串B、源程序C、语法单位D、目标程序7、中间代码生成时所遵循的是___C___。
A、语法规则B、词法规则C、语义规则D、等价变换规则8、编译程序是对___D___。
A、汇编程序的翻译B、高级语言程序的解释执行C、机器语言的执行D、高级语言的翻译9、文法G:S→xSx|y所识别的语言是___C___。
A、xyxB、(xyx)*C、x n yx n(n≥0)D、x*yx*10、文法G描述的语言L(G)是指___A___。
A、L(G)={α|S+ ⇒α ,α∈V T*}B、L(G)={α|S*⇒α,α∈V T*}C、L(G)={α|S*⇒α,α∈(V T∪V N*)}D、L(G)={α|S+ ⇒α,α∈(V T∪V N*)}11、有限状态自动机能识别___C___。
A、上下文无关文法B、上下文有关文法C、正规文法D、短语文法12、设G为算符优先文法,G的任意终结符对a、b有以下关系成立___C___。
A、若f(a)>g(b),则a>bB、若f(a)<g(b),则a<bC、A~B都不一定成立D、A~B一定成立13、如果文法G是无二义的,则它的任何句子α___A___。
A、最左推导和最右推导对应的语法树必定相同B、最左推导和最右推导对应的语法树可能不同C、最左推导和最右推导必定相同D、可能存在两个不同的最左推导,但它们对应的语法树相同14、由文法的开始符经0步或多步推导产生的文法符号序列是___C___。
西电编译原理_第二章习题解答

最终的正规式: 1* | 1*(01|0)* = 1*(01|0)*
© 西安电子科技大学 · 软件学院
5
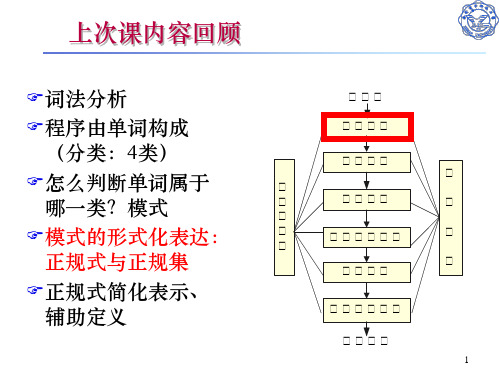
1. 根据模式写出正规式
习题2.4 (2) 所有不含有子串 011 的01串 思路2:考虑包含 011 的串,然后构造没有011的串 ① 含有 子串 011 的最简单的串:
© 西安电子科技大学 · 软件学院
?
| (01|10) (00|11)* (01|10) )*
4
1. 根据模式写出正规式
习题2.4 (2) 所有不含有子串 011 的01串 思路1:简单例子,观察规律 (1) 最简单的串: 0 , 1, 11, 00, 10, 01, 010, …
(2) 上述各串重复: (0 | 00 | 01 | 010 )* = (01 | 0)*
© 西安电子科技大学 · 软件学院
7
2.依据NFA/DFA,给出正规式
思路1: 回顾“正规式 与 FA的关系”
正规集 描述 正规式 识别 有限自动机
正规式、FA是从两个不同的侧面表示一个集合(即正 规集)。所以,根本的方法是以正规集为桥梁, - 先分析清楚 FA 识别的集合之结构特征, - 然后再设计此集合的正规式。
© 西安电子科技大学 · 软件学院
2
1. 根据模式写出正规式
一般思路:(1)分析题意 (2)列举一些最简单的例子 (3)寻找统一规律*,考虑所有可能情况**
习题2.4 (1) 由偶数个0和奇数个1构成的01串
解:① 最简单的串有 0个0和1个1组成的串: 1 2个0和1个1组成的串:010 ,001,100 ② 在上述串的中间、两头添加偶数个0和/或偶数个1,即可 得到满足题意的其他串。 设偶数个0/偶数个1组成的串,可用正规式 A 表示,则最 终正规式: A1A | A0A1A0A
7西安电子科技大学《编译原理》

3.5.1 自下而上分析的基本方法
思路:从句子ω开始,从左到右扫描ω,反复用产生式的左部替换 产生式的右部、谋求对ω的匹配,最终得到文法的开始符号,或者 发现一个错误。
3.5.1.1 规范归约与“剪句柄”
定义3.13 设αβδ是文法G的一个句型, 若 存在S =*>αAδ,A =+>β, 则 称β是句型αβδ相对于A的短语, 特别的,若 有A→β, A→β 则 称β是句型αβδ相对于产生式A→β的直接短语。 一个句型的最左直接短语被称为句柄。 ■ ① 直观上,句型是一个完整结构,短语是句型中的某部分(针对 某非终结符)。S是一个句型,而不是一个短语(树根不是短语)。 ② 短语形成的两个要素: 1.从S可以推导出A,即S=*>αAδ; 2.从A至少一次推导出β,即A=+>β。
13
结
束
上节主要内容: 1. 自下而上分析的基本方法:归约(短语、直接短语、句柄、规 范(最左)归约) 2. 规范归约的形象表示-剪句柄; 3. 移进-归约分析工作模式:格局与格局变换 4. LR分析与LR文法: <1> 分析表:动作表与转移表 <2> 模拟算法:改变格局的两个重要动作-移进与归约 <3> LR分析器的实例分析 <4> LR文法
5
3.5.1.2 移进-归约分析器工作模式
移进-归约分析器的工作模式:
输入记号流 ip top 符 号 状 态 栈 驱动器 移进-归约 分析表 输出
与预测分析对比:
输入记号流 符 top 号 栈 ip 输出
驱动器 预测分析表 (b) 预测分析器模型
预测分析器: 移进-归约分析器: 1.分析方法:格局与格局变换 1. 分析方法:格局与格局变换 2.分析表 2. 分析表 3. 驱动器(模拟算法) 3. 驱动器(模拟算法) 4. LR(文法、语言、分析器) 4. 预测分析表的构造 5. LL(文法、语言、分析器) 5. SLR分析表的构造
西安电子科技大学编译原理 (10)

L →E ; L | ε E →TE' E'→ + T E' | - T E' | ε T →FT' T'→*F T'|/FT'|mod FT'|ε F →(E) | id | num
L →E ; L | ε E →TE' E'→ + T E' | - T E' | ε T →FT' T'→*F T'|/FT'|mod FT'|ε F →(E) | id | num
对文法的每个产生式A→α ② 对FIRST(α)的每个终结符a,加入α 到M[A,a]; ③ 若ε∈FIRST(α),则FOLLOW(A)每 个终结符b(包括#),加入α到M[A, b];
/ mod ( E;L TE' ε ε ) ; # ε
+
-
*
E'
T T' F
id
num
(E)
3.4 自上而下语法分析
...
E
T T F F id T FT
T
T FT
6
非终 结符 E E T T
输 入 符 号
id
E TE
+
E +TE
...
T FT T T FT
F
F id
栈
输
入
输
出
$E
id id + id$
id id + id$ id id + id$ id id + id$ id + id$ id + id$ id + id$ id + id$ F id
编译原理

习惯称法 汇编语言-机器指令:汇编(或交叉汇编) 程序设计语言-汇编语言或机器指令:编译(或解释) 高级语言之间:转换(或预编译) 逆向:反汇编、反编译
19
1.3 编译器与解释器
语言翻译的两种基本形态 先翻译后执行
源程序 编译器 目标程序 输出
边翻译边执行
源程序 输入数据
解释器
1.4 编译器的工作原理与基本组成
position = initial + rate 60
词法分析器
• 标识符position形成的记号是<id, 1> • id是标识符的总称 • 1代表position在符号表中的条目 • 符号表的条目用来存放标示符的 各种属性
• 赋值号=形成的记号是<assign> id, 1 = id, 2 + id, 3 60 •该记号只有一个实例,不需 要属性值来区分实例 •为了直观,记作<=> 符 号 表 • 标识符initial形成的记号是<id,2> 1 position ...
Java 处 理 过 程
计算机能够识别的语言
2
课程简介
翻译
汉语普通话
课程简介
高级程序设计语言
编译 (解释)
处 理 过 程
C 处 理 过 程
C++ 处 理 过 程
Java 处 理 过 程
My PL 处 理 过 程
计算机能够识别的语言
课程简介 介绍编 译器的 原理和 基本实 现方法
源程序 词法分析 语法分析 符 号 表 管 理 语义分析 中间代码生成 代码优化 目标代码生成 目标代码
17
1.1 从面向机器的语言到面向人类的语言
西安电子科技大学编译原理 (1)
8
b
2.3 记号的识别-有限自动机
NFA如何识别记号? 对字符串,从初态开始,是否可以经过一系列状态转 移到达终态? 例如:字符串abb是否可以被上页的NFA所识别
S = {0, 1, 2, 3} Σ = {a, b} move = { move(0, a) = {0, 1}, move(0, b) = 0, move(1, b) = 2, move(2, b) = 3 } s0 = 0 F = {3}
digit1=[1-9]
num=digit1(digit)*(ε |.digit*digit1)
3
2.3 记号的识别-有限自动机
正规式(模式的描述)
有限状态自动机(识别记号)
id = letter(letter|num)*
69fed? F987y?
正规式:(((letter|digit)*num)*|digit*}num)*
辅助定义
letter=[a-z,A-Z] digit=[0-9]
id = letter(letter|digit)* literal=“(letter|digit)*”
integer=digit digit*
num=integer(ε| . integer)
0000.0000 ? 0000.0000?
18
2.3 记号的识别-有限自动机
DFA对NFA施加的两条限制: 限制1:没有ε状态转移 限制2:同一状态经过同一字符最多有一个状态转移 [例2.10] 正规式(a|b)*abb的DFA,识别输入序列abb和abab:
a a b 0 b a a 3 2 b 1 b
0 1 2 3
a 1 1 1 1
西电编译原理_第二章习题解答
最终的正规式: 1* | 1*(01|0)* = 1*(01|0)*
© 西安电子科技大学 · 软件学院
5
1. 根据模式写出正规式
习题2.4 (2) 所有不含有子串 011 的01串 思路2:考虑包含 011 的串,然后构造没有011的串 ① 含有 子串 011 的最简单的串:
然后据上,考查每条从初态到终态的路径,综合正规式即可。
© 西安电子科技大学 · 软件学院 9
2.依据NFA/DFA,给出正规式
习题2.10 (2) 用正规式描述 DFA 所接受的语言;
0 b,c 2 b,c a b a a,c 1
该DFA从初态到终态有三条路径:0b2,0c2,0a1b2 用正规式表示为: b | c | a(a|c)*b, 而且是这三条路径均至少重复一次, 故最终的正规式为:(b|c|a(a|c)*b)+
© 西安电子科技大学 · 软件学院 13
其它
习题2.9 构造 10*1 的最小DFA 解: 活用 Thompson 算法 (1) 分解为三部分:1,0*,1; (2) 画出三者的状态转换图:
0 1 0 1 2 3 1 4
(3) 连接运算:子图首尾相连
0
1
0 1 1
1
4
这已经是最小的DFA
© 西安电子科技大学 · 软件学院
© 西安电子科技大学 · 软件学院
11
其它
关于:正规式 -> NFA -> DFA -> DFA最小化:
说明:(一般)逐步计算 正规式->NFA: (1)呆板Thompson算法: 自上而下分解正规式—— 语法树, 自下而上构造NFA —— 后续遍历; 特点:每个运算对应一次构造,繁琐! (2)活用Thompson算法: 分解正规式:得到若干规模适中的子正规式; 为每个子正规式:画出其最简的状态转换图(子图); 按Thompson算法,将子图组合,得到完整的图。
电子科技大学-计算机学院-编译原理实验-词法分析

#include<>#include<>#include<>#define MAX_COUNT 1024#define ILLEGAL_CHAR_ERR 1#define UNKNOWN_OPERATOR_ERR 2/*从标准输入读入第一个非空白字符(换行符除外)*/char getnbc(){char ch;ch = getchar();while (1){if (ch == '\r' || ch == '\t' || ch == ' '){ch = getchar();}else{break;}}return ch;}/*判断character是否为字母*/bool letter(char character){if ((character >= 'a'&&character <= 'z') || (character >= 'A'&&character <= 'Z')) return true;elsereturn false;}/*判断character是否为数字*/bool digit(char character){if (character >= '0'&&character <= '9')return true;elsereturn false;}/*回退字符*/void retract(char& character){ungetc(character, stdin);character = NULL;}/*返回保留字的对应种别*/int reserve(char* token){if (strcmp(token, "begin") == 0)return 1;else if (strcmp(token, "end") == 0)return 2;else if (strcmp(token, "integer") == 0)return 3;else if (strcmp(token, "if") == 0)return 4;else if (strcmp(token, "then") == 0)return 5;else if (strcmp(token, "else") == 0)return 6;else if (strcmp(token, "function") == 0) return 7;else if (strcmp(token, "read") == 0)return 8;else if (strcmp(token, "write") == 0)return 9;elsereturn 0;}/*返回标识符的对应种别*/int symbol(){return 10;}/*返回常数的对应种别*/int constant(){return 11;}/*按照格式输出单词符号和种别*/void output(const char* token, int kindNum){printf("%16s %2d\n", token, kindNum);}/*根据行号和错误码输出错误*/bool error(int lineNum, int errNum){char* errInfo;switch (errNum){case ILLEGAL_CHAR_ERR:errInfo = "出现字母表以外的非法字符";break;case UNKNOWN_OPERATOR_ERR:errInfo = "出现未知运算符";break;default:errInfo = "未知错误";}if (fprintf(stderr, "***LINE:%d %s\n", lineNum, errInfo) >= 0) return true;elsereturn false;}/*词法分析函数,每调用一次识别一个符号*/bool LexAnalyze(){static int lineNum = 1;char character;char token[17] = "";character = getnbc();switch (character){case'\n':output("EOLN", 24);lineNum++;break;case EOF:output("EOF", 25);return false;;if (fullName != NULL)strncpy(out, fullName + 1, strlen(fullName) - 1 - strlen(extension));elsestrncpy(out, in, strlen(in) - strlen(extension));}/*初始化函数,接收输入文件地址,并打开输入、输出、错误文件、将标准输入重定向到输入文件,将标准输出重定向到输出文件,标准错误重定向到错误文件*/bool init(int argc, char* argv[]){if (argc != 2){return false;}else{char* inFilename = argv[1];yd");rr");if (freopen(inFilename, "r", stdin) != NULL&&freopen(outFilename, "w", stdout) !=NULL&&freopen(errFilename, "w", stderr) != NULL)return true;elsereturn false;}}void main(int argc,char* argv[])//argv[1]是输入文件地址{if (init(argc,argv)){while (LexAnalyze()){}}fclose(stdin);fclose(stdout);fclose(stderr);return;}。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
先声明后引用原则 • 若过程定义出现在对它的引用之后或引用时看不到的地方,则 必须在调用前先声明该过程。 • 若引用前已出现定义,则声明可省略,因为定义已包括了声明。
10
4.5.3.1 左值与右值
直观上,出现在赋值号左边和右边的量分别称为 左值和右值; 如 C 语句: a = b 实质上,左值必须具有存储空间,右值可以仅是 一个值,而没有存储空间。 形象地讲,左值是容器,右值是内容。
4
<2> 变量声明的语法制导翻译(续1) T → array [num] of T (5)
此文法可以声明多维数组,如数组A的声明形式可以是: A : array [d1] of A2 : array [2] of array [d2] of array [3] of int ... array [dn] of int 此多维数组以行为主存储。 因为: 第一维是有d1个元素的一维数组, 每个元素又是一个n-1维的数组; 依此类推。
值调用的特点: 过程内部对参数的修改,不影响作为实参的变量原来的值。
14
值调用举例: program reference ( input, output); var a, b : integer;
<1> 值调用(续1)
procedure swap(x, y : integer); var temp : integer; begin temp:=x; x:=y; y:=temp end; begin a:=1; b:=2; swap(a, b); writeln('a=', a); writeln('b=', b) end. 运行结果: a=1 b=2
9
4.5.3 过程的定义与声明(续) 例:Ada过程 定义: procedure swap(x,y:in out integer) -- 规格说明 is -- 过程体开始 temp : integer; -- 体中的声明 begin temp := x; x := y; y := temp; -- 可执行语句 end swap; -- 过程体结束 声明与调用: procedure swap(x, y: in out integer); -- 过程声明 swap(a, b); -- 过程调用
15
<1> 值调用(续2)
等价的C++程序 // ---------- 值调用参数传递的演示程序 #include <iostream> using namespace std; void swap(int x, int y) { int temp; temp=x; x=y; y=temp; } void main () { int a = 1, b = 2; cout<<"before: a="<<a<<" b="<<b<<endl; swap(a, b); cout<<"after: a="<<a<<" b="<<b<<endl; } 执行该程序
4.5 声明语句的翻译
• 声明语句的作用是为可执行语句提供信息,以便于 其执行。 • 对声明语句的处理,主要是将所需要的信息正确地 填写进合理组织的符号表中。
1
4.5.1 变量的声明 <1> 变量的类型定义与声明
类型定义:为编译器提供存储空间大小的信息 变量声明:为变量分配存储空间 组合数据的类型定义和变量声明: 定义与声明在一起,定义与声明分离。
3
<2> 变量声明的语法制导翻译 (a) 变量声明的文法: D → D ; D (1) | id : T (2) T → int (3) | real (4) | array [num] of T (5) | ^T (6)
G4.5
产生式(5)是数组类型的声明,其中的数组元素个数由num 表示,如num可以是5或10等,这是一个简化了的表示方法,它 等价于1..5或1..10。 产生式(6)是指针类型的声明,其宽度(大小)是一个常量。 数组元素的类型和指针所指对象的类型可以是任意合法类型。
8
4.5.3 过程的定义与声明
1.过程(procedure): 过程头(做什么) + 过程体(怎么做); 函 数: 有返回值的过程 主程序: 被操作系统调用的过程/函数
2.过程的三种形式:过程定义、过程声明和过程调用。 过程定义:过程头+过程体; 过程声明:过程头;
• • 本节重点讨论过程的规格说明、过程体中的声明的处理 本节将过程定义和过程声明统称为过程声明。
13
<1> 值调用 实参的特点: 任何可以作为右值的对象均可作为实参 参数传递和过程内对参数的使用原则: 1. 过程定义时形参被当作局部量看待,并在过程内部为形 参分配存储单元; 2. 调用过程前,首先计算实参并将其值(实参的右值)放 入形参的存储单元; 3. 过程内部对形参单元中的数据直接访问。 调用时: 调用中: 定义时: 返回后: f(a,b)过程内 f(x,y)过程外 f(a,b)过程内 f(x,y)过程外 x 1 a ? x 1 a y 2 b ? y 2 b
12
4.5.3.2 参数传递
1. 形参与实参 • 声明时的参数称为形参(parameter或formal parameter) • 引用时的参数称为实参 (argument或actual parameter) 2. 常见的参数传递形式:(不同的语言提供不同的形式) • 值调用(call by value) • 引用调用(call by reference) • 复写-恢复(copy-in/copy-out) • 换名调用(call by name) 参数传递方法的本质区别: 实参是代表左值、右值、还是实参本身的正文。
运行结果: a=2 b=', b) b=1
18
<2> 引用调用(续2)
等价的C++程序 // ---------- 引用调用参数传递的演示程序 #include <iostream> using namespace std; void swap(int & x, int & y) { int temp; temp=x; x=y; y=temp; } void main () { int a = 1, b = 2; cout<<"before: a="<<a<<" b="<<b<<endl; swap(a, b); cout<<"after: a="<<a<<" b="<<b<<endl; } 执行该程序
16
<2> 引用调用
实参的特点:必须是左值。 参数传递和过程内对参数的使用原则: 1. 定义时形参被当作局部量看待,并在过程内部为形参 分配存储单元; 2. 调用过程前,将作为实参的变量的地址放进形参的存 储单元; 3. 过程内把形参单元中的数据当作地址,间接访问。
定义时: f(a,b)过程内 a b
5ห้องสมุดไป่ตู้
<2> 变量声明的语法制导翻译(续2) (b) 填写符号表信息的语法制导翻译
1. 全局量offset:记录当前符号存储地址(偏移量,初值设为0) 2. 属性.type和.width:变量的类型和所占据的存储空间大小 3. 过程enter(name, type, offset):为type类型的变量name 建立符号表条目,并为其分配存储空间(位置)offset 4. array(n,type)生成数组类型,pointer(type)生成指针类型 (1)D→D;D (2)D→id:T {enter(, T.type, offset); offset:=offset+T.width;} (3)T→int {T.type:=integer; T.width:=4;} (4)T→real {T.type:=real; T.width:=8;} (5)T→array [num] of T1 {T.type:=array(num.val, T1.type); T.width:=num.val*T1.width;} (6)T→^T1 {T.type:=pointer(T1.type); T.width:=4;}
调用时: f(x,y)过程外 x 1 y 2
调用中: f(a,b)过程内 a &x 3 b &y 5
返回后: f(x,y)过程外 x 3 y 5
引用调用的特点: 过程内部对形参的修改,实质上是对实参的修改。
17
引用调用举例: 值调用举例: program reference ( input, output); var a, b : integer;
11
4.5.3.1 左值与右值
(1) (2) (3) const two = 2; -- 声明一个值为2的常量two x : integer; -- 声明一个类型为整型数的变量x function max(a, b : integer) return integer; -- 声明一个返回值类型是整型数的函数max (4) x := two; -- 赋值句执行后,x当前值为2 (5) x := two + x; -- 赋值句执行后,x当前值变为4 (6) x := max(two,x)+x; -- 赋值句执行后,x当前值变为8 (7) 4 := x; -- 字面量不能作为左值 (8) two := x; -- 常量不能作为左值 (9) max(two,x) := two; -- 函数返回值不能作为左值 (10) x+two := x+two; -- 表达式的值不能作为左值