Effectiveness of clustering in ad-hoc retrieval
一种基于AdHoc网络的信任评估分簇算法

( 防灾 科 技 学 院 信 息 技 术 系 , 北 三 河 0 50 ) 河 6 2 1
摘
要 :提出了一种新 的信任评估分簇算法( E A) T C 。该 算法能根据有 限的局部信息 自动地 对整个网络
进行分割 , 从而实现对信任关系的有效管理 。实验与结果分析表明 :E A算 法提供 了一种有 效的信任评 TC 估机制 , 在成簇通信代价 、 维护开销等性能方面与现有 的典型传统分簇方 法相近 , 在安全性上有 明显 的 而
L n,G a g pn ,F NG J— n,L h n ,L u IXi AO F n — ig E i i l IZ o g IJ n ( e at n f noma o eh ooy Isi t o i s r rv n o c nea dT c o g ,a h 50 , hn ) D p rme t fr t nT c n lg ,ntue f s t eet nS i c n eh l y S n e 6 2 1 C ia oI i t D ae P i e n o 0
12 2
传感器 与微 系统 ( rndcr dM c ss m Tcn l i ) Tasue ir yt eh o g s n a o e oe
21 0 0年 第 2 9卷 第 1 0期
一
种 基 于 A c网络 的信 任 评 估 分 簇 算 法 dHo
无线自组织网络

摘要Ad Hoc网络是近年来发展起来的一种无线移动分组网络,它具有动态变化的拓扑结构,网络中的节点可以任意移动,也可以动态的加入或退出网络。
Ad Hoc网络无任何中心和固定基础设施,网络中各个节点的地位平等,每个节点都具有主机与路由器的双重功能,形成了一个以中间主机节点为中继的多跳的分布式网络结构。
路由技术是Ad Hoc网络的关键技术,也是影响网络整体性能最重要的因素之一。
与单跳的无线网络不同,移动Ad Hoc网络中节点之间是通过多跳数据转发机制进行数据交换,需要路由协议进行分组转发决策。
无线信道变化的不规则性,节点的移动、加入、退出等都会引起网络拓扑结构的动态变化。
路由协议的作用就是在这种环境中,监控网络拓扑结构变化,交换路由信息,定位目的节点位置,产生、维护和选择路由,并根据选择的路由转发数据,提供网络的连通性。
本文首先介绍移动Ad Hoc网络的概念、产生、定义,详细总结了移动Ad Hoc 网络的特点、应用场合和研究热点。
然后对Ad Hoc网络体系结构和信道接入协议进行了介绍。
第三章对Ad Hoc网络的路由协议进行了研究分析,并对DSDV、DSR和AODV协议进行了详细的分析研究。
最后,介绍了Ad Hoc网络的分簇算法,详细说明了AOW算法。
关键词:Ad Hoc,自组织网络,AODV,分簇算法ABSTRACTAd hoc network is a kind of wireless and mobile network developed in recent years. It has a dynamic and variable topology, each node not only can move but can join or exit the network freely. It has no center and fix e d infrastructure distributed multi-hop structure,all nodes have an equal status and act as two roles-router and node itself.Routing technique is the key technique of the Ad Hoc network, but also one of the most important factors affect the performance of the whole network. It is different from single hop wireless network,mobile Ad hoc network nodes intercommunicate according to multi-hops data store-forward,which need the support of routing protocol packet forwarding decisions. The regular change of bandwidth and node motivation,pass in and out will lead to the dynamic changes of network topology. The routing protocols will monitor the changing topology,exchange routing information,locate the position of destination nodes,product, select and maintain routing, According to the selected routing and forwarding data to provide network connectivity.In this paper, first of all, introduces the concept, produce, definition of the MANET, summarizes the characteristics, applications, and research focus of the MANET. And then the Ad Hoc network architecture and the channel access protocol is introduced. In chapter 3, we researches and analysis routing protocol of the Ad Hoc network, and carried out a detailed analysis of the DSDV, DSR and AODV protocol. At last, introduces clustering algorithm of the Ad Hoc network, and detailed description of the AOW algorithm.KEY WORDS:Ad Hoc network, self-organizing network, AODV, clustering algorithm目录第一章绪论 (4)1.1A D H OC网络概述 (4)1.1.1 Ad Hoc网络的产生 (5)1.1.2 Ad Hoc网络的定义 (5)1.1.3 Ad Hoc网络的特点 (6)1.1.4 Ad Hoc网络的应用场合 (8)1.2A D H OC网络研究的主要问题 (9)1.3论文的主要研究内容 (10)第二章体系结构与信道接入 (10)2.1节点结构 (10)2.2网络结构 (11)2.3A D H OC协议栈 (13)2.4A D H OC网络体系结构的跨层设计 (13)2.4.1 设计策略 (13)2.4.2 设计方法 (14)2.4.3 跨层设计的优势与挑战 (15)2.5信道接入协议 (15)2.5.1简介 (15)2.5.2面临的问题 (15)2.5.3协议的分类 (18)第三章路由协议的设计 (19)3.1A D H OC网络路由协议的分类 (20)3.1.1平面式路由协议和分级式路由协议 (20)3.1.2表驱动路由协议和按需路由协议 (20)3.1.3 评价路由协议的标准 (21)3.1.4 各类路由协议之间的性能比较 (21)3.2几种典型的A D H OC网络路由协议 (23)3.2.1 DSDV路由协议 (23)3.2.2 DSR路由协议 (24)3.2.3 AODV路由协议 (27)第四章AD HOC网络的分簇算法 (30)4.1概述 (30)4.2基本概念和目标 (31)4.3A D H OC网络中分簇算法的分类和比较 (32)4.3.1 基于节点ID的分簇算法 (32)4.3.2 最高节点度分簇算法 (33)4.3.3 最低节点移动性分簇算法 (33)4.4自适应按需加权分簇算法(AOW) (33)4.4.1一般介绍 (33)4.4.2 AOW算法的特点和目标 (34)4.4.3算法描述 (35)4.4.4网络初始化和簇维护策略 (36)4.5基于分簇结构的A D H OC网络路由协议 (36)4.5.1 CBRP (37)4.5.2 CEDAR (37)4.5.3 ZHLS (37)总结 (38)致谢 (39)参考文献 (40)第一章绪论1.1 Ad Hoc网络概述Ad Hoc网络是一种特殊的无线移动通信网络。
主动碰撞解决Ad_Hoc网络隐藏_暴露终端问题的方法
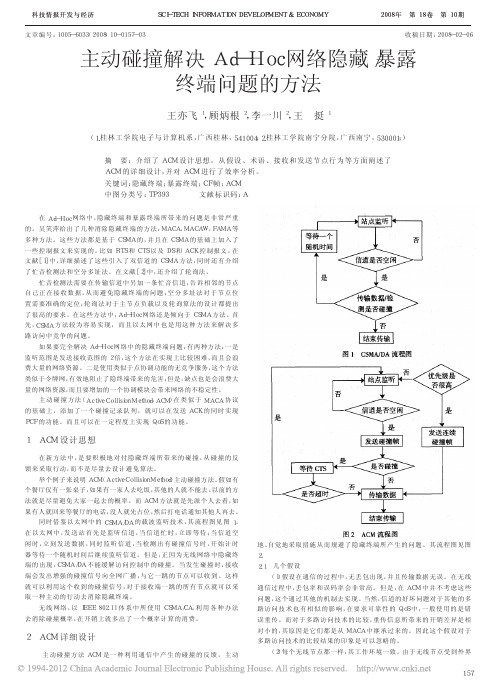
在无线通信中, 有几个软件是常用的: OPNET, NS2, Matlab 等等, 但 是这些软件归根到底就是对一些规则的计算。为了达到这些规则, 就必 须 去 建 立 一 个 符 合 这 个 软 件 的 模 型 。而 这 些 软 件 的 本 身 所 提 供 的 模 型 库 完全不能符合这个新方法的要求, 而编写一个这样的模型的工作量相当 于重新开发一套这种仿真软件。因此从最直接的手段入手, 直接计算方 法的效率不但简化了建模的复杂度, 同时更能灵活客观地体现其价值。
当有数据发送时, 节点首先监听信道。如果信道空闲, 就直接发送 CF 帧; 或者有信息但接收节点不是自己的一跳节点, 则说明接收方是个 暴露节点, 可以认为信道空闲, 直接发送 CF 帧。
当收到 CTS 后就 可 以 发 送 数 据 , 如 果 这 时 碰 撞 , 则 等 待 碰 撞 节 点 的 仲裁。仲裁允许发送信息后从起始重新开始。
若发送数据时碰撞, 则等待碰撞信号结束后直接发送数据, 直至收 到 ACK。 2.5 QoS 优先级的实现
根据 QoS 所提供的优先级, 在 ACM 中, 可以把信息分为两类优先级 来服务: 高优先级与低优先级。在高优先级中, 后到的信息要比先到的信 息优先级高; 在低优先中, 先到的优先级要比后到的优先级高。当要发送 一个高优先级信息时, 可以连续多个 CF 帧通知相邻节点要占用信道, 并 且这时相邻节点暂停了相关的发送。等到高优先级信息发送完毕后, 发 送 ACK 来恢复相邻节点的数据通信。
无线网络的隐藏终端问题不容易解决的原因主要是由于无线节点大 部分都使用的是半双工机制。当使用多信道, 例如把 RTS- CTS 机制中的控 制信号和数据信号的信道分开, 那么隐藏终端问题也就容易解决; 另外, 当 监听信道的覆盖范围是数据传输信道的覆盖范围 2 倍时, 隐藏终端也就不 存在了。但是这两种解决方案都在资源利用率上存在较大的浪费。
认知无线ad hoc网的多尺度跨层路由协议

2018年4月第45卷第2期西安电子科技大学学报(自然科学版)J O U R N A L OF X ID IA N U N IV E R S IT YApr. 2018Vol. 45 No. 2doi:10.3969/j.issn.1001-2400.2018.02.014认知无线ad h o c网的多尺度跨层路由协议曹静S武君胜2,杨文超S王硕晨2(1.西北工业大学计算机学院,陕西西安710072;2.西北工业大学软件与微电子学院,陕西西安710072)摘要:近年来,随着可用频谱资源的日益稀缺和无线业务量的剧增,认知无线自组网相关的研究得到广泛的关注,其中路由问题是应用中需要解决的重要问题之一.由于频谱机会具有动态性,认知无线网的路由问题要将功率控制、路径选择和信道分配联合起来,实现跨层优化设计.文中提出一种多尺度认知路由协议,根据用户的业务类型和服务质量需求进行尺度选择,并结合频谱机会为认知用户提供适用的解决方案.通过网络拓扑模型指出多径路由问题,并分别结合物理层、介质访问控制层和网络层的分析提出了多尺度优化模型.实验表明,该路由方法在端到端时延、吞吐量和数据投递率等参数上,都能够一定程度地改进服务质量.关键词:认知无线自组网;多尺度路由策略;服务质量;跨层设计;网络性能中图分类号:TP393 文献标识码:八文章编号:1001-2400(2018)02-0077-07Multi-metric cross layer routing protocol forcognitive radio ad hoc networksCAO Jing1 , WU Junsheng2 , YANG Wenchao1 , WANG Shuochen2(1. School of Computer Science and ^Engineering, Northwestern Polytcchnical Univ. , Xi5an 710072, China;2. School of Software and Microelectronics, Northwestern Polytcchnical Univ. , Xi’an 710072,China)Abstract:With the aggravation of spectrum scarcity and the rapid increase of wireless service, thecognitive radio ad hoc network has become a hot research topic recently, and efficient routing protocoldesign is important in application. Owing to the dynamic feature of spectrum opportunity, the routeprotocol in the cognitive ad hoc network is complex and should be combined with power control andspectrum allocation. "Phis paper proposes a multi-metric cognitive routing protocol M M-CAODV from thecross-layer prospect. They define routing metrics according to Quality of Service requirements, and providemulti-metrics solutions to secondary users considering spectrum opportunity. This paper points out themulti-path problem through the network topology model, analyzes different routing metrics of delay,transmit rate and stability, and then proposes the multi-metric optimization model. Simulation results showthat the routing protocol in this paper has better network performance in three parameters: end-to-enddelay, throughput, and packet delivery ratio.Key Words:cognitive radio ad hoc networks; cross layer design; quality of service; route metric;network performance随着各种新型无线网络(无线传感网、软件定义网,普适网络等)的迅速普友,近年来《无线通信的业务量 剧増*未来的无线网络将呈现出高速化、宽带化、异构化、泛在化等M势.认知无线网络(Cognitive Radio W etworkwCRNt*)作为5G网络的核心技术之一 *是提蒿频谱利用率,解决当前存在的频谱匮乏、带宽受限、收稿日期:7-05-0 9网络出版时间:2Q_i7-H2S基金项目:陕菌省料被f f自_:然料学,墨础研*资:助项目(2〇l|J_M I.;34 7 >作者简介:曹静(1982—),女,西北工业大学博士研究生,E-mail: caojing919@mail. nwpu. edu. cn.网络出版地址:http:/’/kns. enki. net/kcnis/detail/61. 1076. TN. 20170928. 2210. 028. html78西安电子科技大学学报(自然科学版)第45卷适应能力不足等问题的有效途径.CRNs f t有认知和自适应特性,各个网络节点都能够感知当前的网络环 境.并根据感知结果进行学习和决策,貞适应地调整传输参数,通过学习推理来改进网络的端到端性能.认知 无线自组.网络_(CQgniti.w;.Radi_Q.Ad H'q c:N e tw o rks,.G R A H:N»5:是由一麗者认知决策的节点.以多跳自.治的方式组成的智能网络,能够为用户动态接人物联网提供基础通信平台n—气在认知环境下,路由设计问题较之传统的无线自组网更复杂,不仅包括认知用户(Secondary U sen SU)的移动性造成的网络拓扑动态变化、链路不稳定等问题•还包括由S用户(P nm ary'U ser.P U)行为的不确走 性带来的频谱机会(Spectrum O p p o rtu n ity,SOP.)时变河题t3].近年来,辱很多学者背对CRAHT%的路由优 化问题进行研究,并提出多种解决方案:文献D C提出一种跨层.路由策略,该策略能够计算出从任一源节点 到目的节点的链路时延和路径时延,结合算法可以通过求解最短路径问题来获得最隹选路方案.文献[5]从潜在博弈的角度出发,为多跳匸只咏提出二维的信道-路由交换算法.该算法从频域和空间域两个角 度进行资源管理,在不完全信息博弈下能够计弇出贝叶斯纳什均衡点,从而获得最小资源开销的方案.文献 [6]财按.需距离矢量路由协议(A d On—deirand_Distane,e,V ector ro u tin g,A O T W)协议做了认知性的扩展提:出:一种具有服务质量丨(Q uality of Service.,Q〇S_).保障的基爭认.知的A()D V协议(Cognitive-baged A O D V,C A O D V);C R A H H s到端吞吐f i■然而缺乏对信道切换是否会增加时延的分析•在P前的研究中,大部分学者关.往于通过有效的 资源管理机制来提高频谱利用率、缓解频谱拥塞和优化端到端性能.这些方法在一定程度上实现了资源优化 配置并提禽了路由效率和稳定性,然而随着移动网络的发展,多种无线异构业务将共存和相真融合,因此需 要在认知路由设计时考虑业务特征和路由尺度的选择.综上所述,笔者提出丨一神多尺度跨.层舊由协议(.M.u lti-Mtjttic c〇.gnitiY_i e.Cro.ss-lay'e.i"A.O DV:,.MM-CAO DV).緒合物理层的償道参数和功率分配,以及介质访问控制(Media Access Control,M A C)层的频谱 債息来制定路由策略,并根据业夯类型和Q oS需求来为认知用户选择适当的路由尺度权重.结合频谱可用性来避免对P U的业务流造成千扰,并通过频谱—路由联合分配来增加吞ttfc暈、改善链路的稳定性和减少 端到端时延.由于目前大部分业务(尤其是移动多媒体)具有较高的Q oS栗求,如高速率、时延敏感、高数据 投递率等.针对业务流的网络性能进行分析•通过时延、吞吐量、数据投递率等Q oS参数对MM-C A O D V协 议做仿真实验.从而获取路由策略的评价指标.1网络模型文中考虑的认知Ad h〇c网络由IV个认知用户S U、M个可用信道组成,S U之间以多跳的方式通信•各 个S U使用P U的空闲频段进行业务传输.为了避免对P U的传输造成午扰,S U必须获得当前的可用频谱 列表,也就是频霉机会s o p;{i f p u的行为具有不确定性,s i!的s o p会随时间变化,各个用户:的s o p通 过周期性的频谱感知来获取.当旦仅当两个S U的S O P之间存在交集,弁且它们之间的距离在有效传输范,围之内时,才可以建立传输链路•图1给出了抽象的网络拓扑模型•节点S和D分别代表路由的源节点和I的节点,彳A.B,C.E,代 表多跳路由的中间节点,C s.C,}表示不同的授权频段.对于各个链路,由?信道带宽、路径时延、地理位置等#异,传输性能也不同,用一个二元组(delay,cost)来表示信道参数,其中delay表示路径时延■cost表示流量占用网络带宽的开销.受*用户行为的影响.各个信道在使用中随时会被:用户收回而不可用,这种情况下需要进行路由恢复,有两个解决方法:①在中断的两个节点间进行信道切换,选择另外一个 共用信道,原路由方案不变;@重新进行源节点到_的节点间的路径逸择.在图1(a)中,从源节点S到I目的节点D,有如下几条路径可以选择:(1) S ^ A ^ B ^D;total delay = 7 ,cost = 6 ;(2)S — C —D; total delay = 6,cost = 7 ;(3) S ^ C ^F ^D;total delay = 5 ,cost = 10;(4) S ^ E ^ F ^ D;total delay = 3 ,cost = 11.在这4条路径中,按照不同的尺度标准有多种选路方案:如果数据流是时延敏感型业务(如在线视频),则应当选择(4),以期望通过最小时延到达目的地;但是成本较高,会消耗较多的带宽资源.如果是时延容忍第2期曹静等:认知无线ad hoc 网的多尺度跨层路由协议79图1 C R A H N 的路由模型型数据业务(如浏览页面、文件传输等),则虛当选择(1),以占用较少的网络资源来完成数据流传输.如果从 节能和链路稳定性的角度考虑,则应当选择(2),以经过最小跳数到达目的节点.在图1(b )中,当信道C 2被 主用户收回时,S — C 的路径被中断时,当前可用路径仅剩(1)和(4).这时如果剩余路径的处理能力有限,就 要恢复S 到C 之间的链路,通过多径路由来处理网络负荷.这时可以选择从信道C 2切换到信道C 3来实现链 路重建.在图1(c )中,当S ^C 之间的信道切换到C 3时,从(1)到(4)的路径全部可用,这时对路径(3)进行 更新,total delay = 3,cost = 10,路径(3)成为比(4)总体性能更优的路由方案.2多尺度优化模型2.1路由尺度分析2. 1. 1 时延认知Ad h o c 网络是多跳、分布式的无线网络,由于S O P 是动态变化的,S U _要根据P U 的行为进行信 道切换和选择,因此,网络的端到端总时延D trtal 由两部分组成:路径时延D p a tk 和切换时延D s w l t d l ,可以表 示为^to ia i —乃fafh 十 Dswiteii * .(1》路径时延是由数据流在多跳节点间的传输引起的,当多个数据流竞争同|个信道时会带来退避时延 D wk 」71.因此,路径时延也分为两部分:数据流传输时延和退避时延D w kn l r ., + Dh 'Tt nRk a - p c ) (l - a - pcy -wa (2)其中,乃表示业务数据流的流量,表示当前路径的跳数,尺,表示链路々的数据传输速率;A 表示竞争 同一信道的节点数量,久为多个节点竞争同一信道而发生碰撞的概率,W 。
What the difference between financial accounting and management accounting

What the difference between financial accounting and management accountingAccounting as a profession has really developed over the years. According to Hendriksen (1977), accounting records concepts can be traced as far back as the Roman and Greek periods. According to the American Institute of Certified Public Accountants (AICPA), accounting is defined as: “The art of recording, classifying, and summarizing in a significant manner, and in terms of money, transactions, and events, which are, in part at least, of financial character, and interpreting the results thereof.” financial accounting and management accounting appear in the contemporary society, which are two relatively new branches of accounting. This essay will explain the main difference between financial accounting and management accounting.There are five differences between financial accounting and management accountingFirstly, the principal objectives are different. Financial accounting combines accounting knowledge and finance knowledge, which mainly focus on periodic reporting of accounting information. The principal objective of financial accounting is a stewardship of business for benefit of shareholders, government agencies and other parties. However, management accounting contains accounting knowledge and management knowledge, which based on the accounting information to identify, measure, analyse, interpret and communicate information f or the pursuit of an organization’s goals. It seeks to improve economy, efficiency and effectiveness of operations, which aims at helping managers within the organization make decisions.Secondly, the time horizons of financial accounting and management accounting are different. Financial accounting is predominately based on past transactions and events. One of significant convention is the assertion of the historical cost concept. Nevertheless, management accounting not only consider the past cost concept, but the present and the future that affect the operation of company.Thirdly, the report recipients are different. There is statutory requirement for companies to prepare annual financial statements. The annual financial statements which includes the profit and loss account, balance sheet, statement of equity and cash flow statement, which reveal the monetary performance and value of the company. The report recipient of financial accounting is biased in favour of external the shareholders and government for tax. However, the report recipients of management accounting are internal party like directors and company managers.Fourthly, the outputs are different.The central outputs from financial accounting are audited financial statements such as profit and loss account, balance sheet and cash flow statement. However, the outputs from management accounting should detail monthly and annual management accounts, which cold show results by product and function ad hoc reports. Fifthly, the regulate frameworks in financial accounting l and management accounting are different. The financial accounting framework concept in must lie down by the accounting standards board that looks like GAAP, which plus statutory requirements of the companies’ acts. However, the framewor k of management accounting need not prescribe, although the guidance and formats of CIMA Terminology should follow in most organisations.In conclusion, as detailed work in contemporary society, financial accounting and management accounting appear. Five differences between financial accounting and management accounting, which are the principal objectives, the time horizons, report recipients, outputs and the regulate frameworks. In the future, it might that more and more branches in accounting appear. Reference:1. Hendriksen, R (1977) Accounting Theory, Irwin ProfessionalPublishing; 5 Sub edition (22/10/1991). Isbn: 978-025*******2. The American Institute of Certified Public Accountants/Pages/Default.aspx( access in 02/10/2010)。
无线传感网HEAD协议原文

Index Terms- sensor networks. clustering, energy efficiengr,
network lifetime
l. INTRODUCTION
Sensor networks have recently emerged as an important computing platform [1], [2]. Sensor nodes are typically less mobile and more densely deployed than mobile ad-hoc networks (MANETs). Sensor nodes must be left unattended e.g .. in hostile environments, which makes it difficult or impossible to re-charge or replace lheir batteries (solar energy is not always an option). This necessitates devising novel energy-efficient solutions to some of the conventional wireless networking problems, such as medium access control. routing, self-organization. bandwidth sharing, and security. Exploiting the tradeoffs among energy. accuracy, and latency, and using hierarchical (tiered) architectures are important techniques for prolonging network lifetime [1]. Network lifetime can be det1ned as the time elapsed until the fust node (or the last node) in the network depletes its energy (dies). For example. in a military field where sensors are monitoring chemical activity. the lifetime of a sensor is critical for maximum field coverage. Energy consumption in
WebSphere中间件详细介绍

路由—服务之间的信息 协调—请求者和服务之间的传输协议 转换—请求者和服务之间的消息格式 处理—来自不同业务源的事信息
16
WebSphere MQ
WebSphere MBreosksearge连接性服务 WebSphere ESB
Server WebSphere Information Integrator
Tivoli Intelligent Orchestrator
IT 服务管理
Tivoli Monitoring Tivoli Access Manager
7
WebSphere 应用服务器:支持随需应变的业务要求
业务应用程序服务
提供从开发平台到生产平台的平滑迁移。
利用一个广泛的软件架构,不需要你为每一个 新的功能或产品学习一个新的界面。
提供一个简单、稳健的开发和部署环境,包括Java Server Faces 和WebSphere Rapid Deployment 来加快 实施。
提供一些帮助开发者提升技能,节省时间的特性: Service Data Objects, 增强的 Application Assembly Toolkit, Channel Framework, Work Manager, Timer Service, 和内置Java 数据库来提供持久性和测试。
Information Integrator
WebSphere
WebSphere MQ
Message Bro连ke接r 性服务
WebSphere
ESB
WebSphere DataPower
合作伙伴服务
业务应用程序服务 应用程序和信息资产
Ad Hoc网络动态分簇算法及路由研究的开题报告

Ad Hoc网络动态分簇算法及路由研究的开题报告一、选题背景及意义随着移动计算、物联网及无线传感器网络的快速发展,Ad Hoc网络已经成为了无线通信领域的一个热门研究方向。
Ad Hoc网络是一种不依赖于基础设施,由一些具有相似功能的节点组成的自组织网络,其特点是节点通信不需要事先建立通信链路,而是通过自组织的方式建立通信链路,是实现移动计算及无线传感器网络应用的重要手段。
在Ad Hoc网络中,节点的分布、移动及失效等因素都可能会影响网络的性能与稳定性,因此如何合理地组织节点,建立有效的通信链路,保证网络的稳定性及可靠性是Ad Hoc网络研究的重点之一。
本文将研究Ad Hoc网络中的动态分簇算法及路由协议,旨在提出一种适合实际应用的Ad Hoc网络组织方案,并提高网络性能及可靠性,为实现Ad Hoc网络的应用提供技术支持。
二、研究内容及主要思路1. 研究动态分簇算法针对Ad Hoc网络中节点分布及移动的不确定性,将研究一种动态分簇算法,能够根据节点分布及移动情况调整簇的大小、数量及位置,保证簇内节点通信质量及簇间通信效率。
2. 研究路由协议针对Ad Hoc网络中节点失效的情况,将研究一种适应节点失效的路由协议,能够根据网络拓扑结构及节点失效情况调整路由路径,保证数据能够快速有效地传输。
3. 综合考虑算法与协议将以上两部分的研究内容进行综合,提出适合实际应用的Ad Hoc网络组织方案,提高网络性能及可靠性。
三、预期研究成果及创新点1. 提出一种适应Ad Hoc网络节点分布、移动及失效等因素的动态分簇算法,在保证簇内节点通信质量及簇间通信效率的同时,减少网络的能耗及延迟。
2. 提出一种适应节点失效的路由协议,在保证数据快速有效传输的同时,能够动态调整路由路径,提高网络的稳定性和鲁棒性。
3. 提出一种适合实际应用的Ad Hoc网络组织方案,该方案综合考虑了算法与协议的特点,并能保证网络的性能、稳定性及可靠性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
initial, manually prepared queries in all subsequent steps. Eight subjects were enlisted as "users". Their task was to submit the initial queries to a database consisting of the target corpus (excluding the Federal Register collection), and judge results. Results were presented either as relevance-ranked lists of 300 returned documents (the baseline or “ranked” run) or as clustered groups of the top 150 returned documents (the “cluster” run). Each user was assigned some number of queries; half were processed as baseline and half as cluster runs. Users' judgments (documents marked relevant, non-relevant, or merely viewed) were automatically collected at 10, 15, 20, and 30 minutes. During the first 15 minutes, no user interactions with the system were allowed except for the reading and marking of documents. Between 15 and 30 minutes, users were also allowed to reformulate queries and retrieve potentially new results. All fifty queries were processed in each mode; each user processed a query only once in one or the other mode. In terms of efficiency alone, we observed a positive effect for cluster representations. At all collection points (10, 15, 20, and 30 minutes) the average number of positive judgments per query is higher for the cluster mode. For example, the average number of marked-relevant documents at each point is 8.7, 11.8, 13.9, and 18.7 for the baseline and 9.1, 12.6, 15.9, and 20.5 for the cluster runs. In terms of overall performance—average precision and recall—our official results further demonstrate the higher performance of the cluster runs. In the following sections, we report on our experimental design, the results we obtained in the several modes of processing, our overall performance on the TREC-7 task, and the results of several follow-up analyses we conducted.
1 Introduction
The most successful approaches to ad-hoc retrieval in recent TREC evaluations have typically involved a combination of manual query formulation, interaction with a user to determine some number of candidate relevant documents, and "relevance" feedback to the system for use in expanding a query and automatically generating a final set of ranked documents. Based on our results in TREC 6 in particular [1], we have come to regard accurate, selective relevance feedback as the dominant factor in determining a successful outcome. In any practical system, such relevance feedback depends on the ability of a user to review and judge a sample of documents in a relatively short amount of time. Virtually all TREC systems that have utilized user feedback have presented the user with "relevance ranked" lists of documents to review. But such lists may not represent unbiased samples of potentially relevant documents. Serialorder presentation may not be the most appropriate way to organize results. Making the user read or browse documents in isolation may not contribute to the user’s efficiency, in particular, in deciding whether to continue reviewing documents, to stop, or to reformulate the query and try again. Our ad-hoc retrieval experiments in TREC 7 were designed to assess the effectiveness of clustered groups of documents as an alternative to relevance-ranked lists in assisting the user in making relevance judgments. The fifty queries (351−400) were entered into the CLARIT system and edited by a member of the team; these constituted a fixed set of
Effectiveness of Clustering in Ad-Hoc Retrieval
David A. Evans, Alison Huettner, Xiang Tong, Peter Jansen, Jeffபைடு நூலகம்ey Bennett CLARITECH Corporation
A Justsystem Group Company
2 Experiment Design
The CLARIT TREC-7 ad hoc retrieval experiment was designed to measure the effect of document clustering on the speed and quality of user relevance judgments. To conduct our experiment, we needed a group of subjects (“users”), an interactive retrieval system with the ability to present results in relevance-ranked lists or in organized clusters, and a design that would insure, as much as possible, that the essential variables in performance would be due to user judgments of documents. For subjects, we enlisted eight members of the CLARITECH staff. We chose only native speakers of English and tried to
Abstract
In this paper, we describe the experiment underlying the CLARITECH entries in the TREC-7 Ad Hoc Retrieval Track. Based on past results, we have come to regard accurate, selective relevance feedback as the dominant factor in effective retrieval. We hypothesized that a clustered rather than a ranked presentation of documents would facilitate judgments of document relevance, allowing a user to judge more documents accurately in a given period of time. This in turn should yield better feedback performance and ultimately better retrieval results. We found that users were indeed able to find more relevant documents in the same time period when results were clustered rather than ranked. Retrieval results from the cluster run were better than results from the ranked run, and those from a combined run were better still. The difference between the ranked and combined runs was statistically significant for both recall and average precision.