DM_Chap4_数据理解
chap4(27-28)
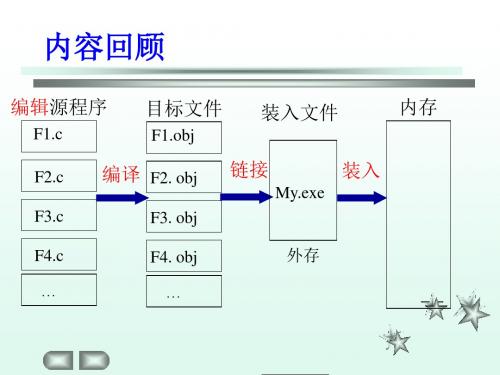
装入模块
模块 A …… If () JSR “L” Else JSR L+M
Return 模块 B
内存
K
L-1
0
M-1
L-1 L L+M-1 L+M
Return 模块 C
Return
…… If () JSR K+L Else JSR K+L+M ……
0 N-1
4、1 程序的装入和链接
装入时动态链接(Load-time Dynamic Linking):
0 A B C
系统区 作业区 空闲区 用户区
4、2 连等待装入 内存的作业排成一个作业队列。当主存储器中 无作业或一个作业执行结束,就可以让作业队 列中的下一个作业装入内存。
地址转换方式:静态重定位 缺点:
( 1 )当作业执行中出现了某个等待事件, CPU 处 于空闲状态,不能被充分利用。
0 1 2 3 … 200 … 2500 …
重定位寄存器 1000
…
LOAD R1,2500 … 9 …
+
F1.exe
重定位的实现
• 动态运行时装入方式的特点:
1.为了提高运行速度,需要重定位寄存器的支 持。 2.在装入程序的同时将装入的起始地址写入重 定位寄存器中。 3.程序装入时使用的仍然是逻辑地址;而在程 序运行时才将逻辑地址修改为物理地址。 4.物理地址=重定位寄存器中的地址+逻辑地址 5.装入内存的程序可以移动,将移动后的起始 地址记入重定位寄存器。
在分区使用表中按作业名找到相应的表项:作 业名=结束的作业名&&状态=“已分配”
将状态修改为“未分配”
数据库系统基础教程课后答案第四章

4.2.7 In below figure there exists a many-to-one relationship between Babies and Births and another many-to-one relationship between Births and Mothers. From transitivity of relationships, there is a many-to-one relationship between Babies and Mothers. Hence a baby has a unique mother while a birth can allow more than one baby.
4.1.7
4.1.8 a)
(b)
4.1.9
Assumptions A Professor only works in at most one department. A course has at most one TA. A course is only taught by one professor and offered by one department. Students and professors have been assigned unique email ids. A course is uniquely identified by the course no, section no, and semester (e.g. cs157-3 spring 09).
4.2.4 The entity sets should have single attribute. a) Stars: starName b) Movies: movieName c) Studios: studioName. However there exists a many-to-many relationship between Studios and Contracts. Hence, in addition, we need more information about studios involved. If a contract always involves two studios, two attributes such as producingStudio and starStudio can replace the Studios entity set. If a contact can be associated with at most five studios, it may be possible to replace the Studios entity set by five attributes viz. studio1, studio2, studio3, studio4, and studio5. Alternately, a composite attribute containing concatenation of all studio names in a contact can be considered. A separator character such as "$" can be used. SQL allows searching of such an attribute using query like '%keyword%'
四川大学研究生计算机学院数据库原理与概念复习

18/74
第四题 (题目部分
20 分: SQL )
• 上题是 relational algebra and tuple calculus, 本题SQL • Consider the relational schema of question 3. Express the following queries in SQL (feel free to abbreviate relation and attribute names and to use INTERSECT and EXCEPT if you need to): • a) (5分) Find the cities that have direct (non-stop) flights to both Honolulu and Newark • b) (5分) Find the passenger_id of all 19/74
第二题 题目 (考察分析问题、解决问题、文字叙述的能力)
高校中心数据库的解决方案(10分) 最近教育部要求各高校建立中心数据库。目 前高校中各职能部门的数据库现状参差不齐, 若干职能部门(如财务处,人事处,教务处) 已有了较成熟的数据库系统(各种DBMS), 并积累大量数据;若干职能还没有像样的数 据库系统。整个工程要求全国高校及主管部 门能共享数据,数据一致、可靠、及时动态 地更新,又方便职能部门和师生用B/S方式 查询更新。 请根据你的经验,分析可预见的 困难,解决的方案和建成后的概貌。(字数
D1.plane_type = D2.plane_type)))}
17/74
第三题 (答案 c)
c) (5 分) Find the flight_num and date of all flights for which there are no reservations.
数据库第六版第四章答案

Intermediate SQLPractice Exercises4.1Write the following queries in SQL:a.Display a list of all instructors,showing their ID,name,and the num-ber of sections that they have taught.Make sure to show the numberof sections as0for instructors who have not taught any section.Yourquery should use an outerjoin,and should not use scalar subqueries.b.Write the same query as above,but using a scalar subquery,withoutouterjoin.c.Display the list of all course sections offered in Spring2010,alongwith the names of the instructors teaching the section.If a section hasmore than one instructor,it should appear as many times in the resultas it has instructors.If it does not have any instructor,it should stillappear in the result with the instructor name set to“—”.d.Display the list of all departments,with the total number of instructorsin each department,without using scalar subqueries.Make sure tocorrectly handle departments with no instructors.Answer:a.Display a list of all instructors,showing their ID,name,and the num-ber of sections that they have taught.Make sure to show the numberof sections as0for instructors who have not taught any section.Yourquery should use an outerjoin,and should not use scalar subqueries.select ID,name,count(course id,section id,year,semester)as’Number of sections’from instructor natural left outer join teachesgroup by ID,nameThe above query should not be written using count(*)since count*counts null values also.It could be written using count(section id),or1920Chapter4Intermediate SQLany other attribute from teaches which does not occur in instructor,which would be correct although it may be confusing to the reader.(Attributes that occur in instructor would not be null even if the in-structor has not taught any section.)b.Write the same query as above,but using a scalar subquery,withoutouterjoin.select ID,name,(select count(*)as’Number of sections’from teaches T where T.id=I.id)from instructor Ic.Display the list of all course sections offered in Spring2010,alongwith the names of the instructors teaching the section.If a section hasmore than one instructor,it should appear as many times in the resultas it has instructors.If it does not have any instructor,it should stillappear in the result with the instructor name set to“−”.select course id,section id,ID,decode(name,NULL,’−’,name)from(section natural left outer join teaches)natural left outer join instructorwhere semester=’Spring’and year=2010The query may also be written using the coalesce operator,by re-placing decode(..)by coalesce(name,’−’).A more complex versionof the query can be written using union of join result with anotherquery that uses a subquery tofind courses that do not match;refer toexercise4.2.d.Display the list of all departments,with the total number of instructorsin each department,without using scalar subqueries.Make sure tocorrectly handle departments with no instructors.select dept name,count(ID)from department natural left outer join instructorgroup by dept name4.2Outer join expressions can be computed in SQL without using the SQLouter join operation.To illustrate this fact,show how to rewrite each of thefollowing SQL queries without using the outer join expression.a.select*from student natural left outer join takesb.select*from student natural full outer join takesAnswer:a.select*from student natural left outer join takescan be rewritten as:Exercises21 select*from student natural join takesunionselect ID,name,dept name,tot cred,NULL,NULL,NULL,NULL,NULLfrom student S1where not exists(select ID from takes T1where T1.id=S1.id)b.select*from student natural full outer join takescan be rewritten as:(select*from student natural join takes)union(select ID,name,dept name,tot cred,NULL,NULL,NULL,NULL,NULLfrom student S1where not exists(select ID from takes T1where T1.id=S1.id))union(select ID,NULL,NULL,NULL,course id,section id,semester,year,gradefrom takes T1where not exists(select ID from student S1where T1.id=S1.id))4.3Suppose we have three relations r(A,B),s(B,C),and t(B,D),with allattributes declared as not null.Consider the expressions•r natural left outer join(s natural left outer join t),and•(r natural left outer join s)natural left outer join ta.Give instances of relations r,s and t such that in the result of thesecond expression,attribute C has a null value but attribute D has anon-null value.b.Is the above pattern,with C null and D not null possible in the resultof thefirst expression?Explain why or why not.Answer:a.Consider r=(a,b),s=(b1,c1),t=(b,d).The second expression wouldgive(a,b,NULL,d).b.It is not possible for D to be not null while C is null in the result of thefirst expression,since in the subexpression s natural left outer join t,it is not possible for C to be null while D is not null.In the overallexpression C can be null if and only if some r tuple does not have amatching B value in s.However in this case D will also be null.4.4Testing SQL queries:To test if a query specified in English has been cor-rectly written in SQL,the SQL query is typically executed on multiple test22Chapter4Intermediate SQLdatabases,and a human checks if the SQL query result on each test databasematches the intention of the specification in English.a.In Section Section3.3.3The Natural Joinsubsection.3.3.3we saw an ex-ample of an erroneous SQL query which was intended tofind whichcourses had been taught by each instructor;the query computed thenatural join of instructor,teaches,and course,and as a result uninten-tionally equated the dept name attribute of instructor and course.Givean example of a dataset that would help catch this particular error.b.When creating test databases,it is important to create tuples in refer-enced relations that do not have any matching tuple in the referencingrelation,for each foreign key.Explain why,using an example queryon the university database.c.When creating test databases,it is important to create tuples with nullvalues for foreign key attributes,provided the attribute is nullable(SQL allows foreign key attributes to take on null values,as long asthey are not part of the primary key,and have not been declared asnot null).Explain why,using an example query on the universitydatabase.Hint:use the queries from Exercise Exercise4.1Item.138.Answer:a.Consider the case where a professor in Physics department teaches anElec.Eng.course.Even though there is a valid corresponding entryin teaches,it is lost in the natural join of instructor,teaches and course,since the instructors department name does not match the departmentname of the course.A dataset corresponding to the same is:instructor={(12345,’Guass’,’Physics’,10000)}teaches={(12345,’EE321’,1,’Spring’,2009)}course={(’EE321’,’Magnetism’,’Elec.Eng.’,6)}b.The query in question0.a is a good example for this.Instructors whohave not taught a single course,should have number of sections as0in the query result.(Many other similar examples are possible.)c.Consider the queryselect*from teaches natural join instructor;In the above query,we would lose some sections if teaches.ID is al-lowed to be NULL and such tuples exist.If,just because teaches.ID isa foreign key to instructor,we did not create such a tuple,the error inthe above query would not be detected.4.5Show how to define the view student grades(ID,GP A)giving the grade-point average of each student,based on the query in Exercise??;recallthat we used a relation grade points(grade,points)to get the numeric pointsExercises23 associated with a letter grade.Make sure your view definition correctly handles the case of null values for the grade attribute of the takes relation.Answer:We should not add credits for courses with a null grade;further to to correctly handle the case where a student has not completed any course, we should make sure we don’t divide by zero,and should instead return a null value.We break the query into a subquery thatfinds sum of credits and sum of credit-grade-points,taking null grades into account The outer query divides the above to get the average,taking care of divide by0.create view student grades(ID,GP A)asselect ID,credit points/decode(credit sum,0,NULL,credit sum)from((select ID,sum(decode(grade,NULL,0,credits))as credit sum,sum(decode(grade,NULL,0,credits*points))as credit pointsfrom(takes natural join course)natural left outer join grade pointsgroup by ID)unionselect ID,NULLfrom studentwhere ID not in(select ID from takes))The view defined above takes care of NULL grades by considering the creditpoints to be0,and not adding the corresponding credits in credit sum.The query above ensures that if the student has not taken any course with non-NULL credits,and has credit sum=0gets a gpa of NULL.This avoid the division by0,which would otherwise have resulted.An alternative way of writing the above query would be to use student natural left outer join gpa,in order to consider students who have not taken any course.4.6Complete the SQL DDL definition of the university database of Figure Fig-ure4.8Referential Integrityfigcnt.50to include the relations student,takes, advisor,and prereq.Answer:create table student(ID varchar(5),name varchar(20)not null,dept name varchar(20),tot cred numeric(3,0)check(tot cred>=0),primary key(ID),foreign key(dept name)references departmenton delete set null);24Chapter4Intermediate SQLcreate table takes(ID varchar(5),course id varchar(8),section id varchar(8),semester varchar(6),year numeric(4,0),grade varchar(2),primary key(ID,course id,section id,semester,year),foreign key(course id,section id,semester,year)references sectionon delete cascade,foreign key(ID)references studenton delete cascade);create table advisor(i id varchar(5),s id varchar(5),primary key(s ID),foreign key(i ID)references instructor(ID)on delete set null,foreign key(s ID)references student(ID)on delete cascade);create table prereq(course id varchar(8),prereq id varchar(8),primary key(course id,prereq id),foreign key(course id)references courseon delete cascade,foreign key(prereq id)references course);4.7Consider the relational database of Figure Figure4.11figcnt.53.Give an SQLDDL definition of this database.Identify referential-integrity constraintsthat should hold,and include them in the DDL definition.Answer:create table employee(person name char(20),street char(30),city char(30),primary key(person name))Exercises25create table works(person name char(20),company name char(15),salary integer,primary key(person name),foreign key(person name)references employee,foreign key(company name)references company)create table company(company name char(15),city char(30),primary key(company name))pp create table manages(person name char(20),manager name char(20),primary key(person name),foreign key(person name)references employee,foreign key(manager name)references employee)Note that alternative datatypes are possible.Other choices for not nullattributes may be acceptable.4.8As discussed in Section Section4.4.7Complex Check Conditions and Assertionssubsection.4.4we expect the constraint“an instructor cannot teach sections in two differ-ent classrooms in a semester in the same time slot”to hold.a.Write an SQL query that returns all(instructor,section)combinationsthat violate this constraint.b.Write an SQL assertion to enforce this constraint(as discussed in Sec-tion Section4.4.7Complex Check Conditions and Assertionssubsection.4.4.7,current generation database systems do not support such assertions,although they are part of the SQL standard).Answer:a.select ID,name,section id,semester,year,time slot id,count(distinct building,room number)from instructor natural join teaches natural join sectiongroup by(ID,name,section id,semester,year,time slot id)having count(building,room number)>1Note that the distinct keyword is required above.This is to allow twodifferent sections to run concurrently in the same time slot and are26Chapter4Intermediate SQLtaught by the same instructor,without being reported as a constraintviolation.b.create assertion check not exists(select ID,name,section id,semester,year,time slot id,count(distinct building,room number)from instructor natural join teaches natural join sectiongroup by(ID,name,section id,semester,year,time slot id)having count(building,room number)>1)4.9SQL allows a foreign-key dependency to refer to the same relation,as in thefollowing example:create table manager(employee name char(20),manager name char(20),primary key employee name,foreign key(manager name)references manageron delete cascade)Here,employee name is a key to the table manager,meaning that each em-ployee has at most one manager.The foreign-key clause requires that everymanager also be an employee.Explain exactly what happens when a tuplein the relation manager is deleted.Answer:The tuples of all employees of the manager,at all levels,getdeleted as well!This happens in a series of steps.The initial deletion willtrigger deletion of all the tuples corresponding to direct employees ofthe manager.These deletions will in turn cause deletions of second levelemployee tuples,and so on,till all direct and indirect employee tuples aredeleted.4.10SQL-92provides an n-ary operation called coalesce,which is defined asfollows:coalesce(A1,A2,...,A n)returns thefirst nonnull A i in the listA1,A2,...,A n,and returns null if all of A1,A2,...,A n are null.Let a and b be relations with the schemas A(name,address,title)and B(name,address,salary),respectively.Show how to express a natural full outer joinb using the full outer-join operation with an on condition and the coalesceoperation.Make sure that the result relation does not contain two copiesof the attributes name and address,and that the solution is correct even ifsome tuples in a and b have null values for attributes name or address.Answer:Exercises27 select coalesce(,)as name,coalesce(a.address,b.address)as address,a.title,b.salaryfrom a full outer join b on = anda.address=b.address4.11Some researchers have proposed the concept of marked nulls.A markednull⊥i is equal to itself,but if i=j,then⊥i=⊥j.One application of marked nulls is to allow certain updates through views.Consider the view instructor info(Section Section4.2Viewssection.4.2).Show how you can use marked nulls to allow the insertion of the tuple(99999,“Johnson”,“Music”) through instructor info.Answer:To insert the tuple(99999,“(”Johnson),“Music”)into the view instructor info,we can do the following:instructor←(99999,“Johnson”,⊥k,⊥)∪instructordepartment←(⊥k,“Music′′,⊥)∪departmentsuch that⊥k is a new marked null not already existing in the database.Note:“Music”here is the name of a building and may or may not be related to Music department.。
相图分析chap4

• 任何情况下均三点共线;
包
• 液相组成和固相组成点路径异,首尾相接;
晶
• 最终存在相与原体系点符合重心规则。
型
相
图
一、高温稳定、低温分解的二元化合物
§ 1. 相图组成 读图(点、线、面的物理意义)
6
A
几
种
A
特
e4
殊
相 图
Bk
e3
p
BC
EC
B
e1 BC
e2
C
一、高温稳定、低温分解的二元化合物
§
6
类
tB
e1 E e3
tc
相
B
C
e2
图
B
C
e2’
tB tc
1. 相图组成
tA
tC
§ 4
tB
e’ 3
共
e’ 1
晶
类
相 图
A
e1
e’ 2
E’
e3
C
E e2
B
二元初晶线:
6条 2
1. 相图组成
tA
tC
§ 4
tB
e’ 3
共
e’ 1
晶
类
相 图
A
e1
e’ 2
E’
e3
C
E e2
B
初晶区:
三个 2
1. 相图组成
基
单相区与两相区邻接的界限延长线必进入两相区。
础
即:单相区两边界线夹角小于180℃。
三元系:
单相区与两相区邻接的界限延长线必进入两个两 相区,或同时进入三相区。
一、读图(点、线、面的物理意义)
§
Fe-O二元相图是分析铁的氧化、铁氧化物还原
GSM、GPRS网络术语大全

GSM网络术语●GSM——数据蜂窝移动通信系统●MSC——移动业务交换中心●BSS——基站系统●BSC——基站控制器●BTS——基站收发信台●MS——移动台●OSS——操作与维护子系统●PSTN——公众交换电话网●ARFCN——无线频率信道编号●RF——载频●ME——移动设备●ISDN——综合业务数字网●IWF——互通功能单元●SIM——智能卡、用户识别卡●TMSI——临时移动用户身份识别号●LAI——位置区识别号●MSISDN——移动台的电话号码●XCDR——压缩编码器●TRAU——压缩编码器速率适配单元移动业务交换中心●EIR——设备识别寄存器●AUC——鉴权中心●IWF——网络互通功能●EC——回声消除器●DTX——不连续发射●MSRN——移动用户漫游号●IWF——网络互通功能●NMC——网络管理中心●OMC——操作与维护中心●TUP——电话用户部分●TMA——塔顶放大器●BSSMAP——基站系统管理应用部分●DTAP——直接传输应用部分●AM——幅度调制●FM——频率调制●PSK——相移键控●TCH——业务通道●SCH——同步通道●PCH——寻呼通道●GMSK——高斯最小相移键控●BCCH——广播控制通道●CCCH——通用控制通道●DCCH——专用控制通道●FCCH——频率控制信道●RACH——随机接入通道●AGCH——接入允许通道●CBCH——小区广播通道●SDCCH——独立专用控制通道●SACCH——慢速随路控制通道●FACCH——快速随路控制通道●MBCCH——主要的广播控制通道GPRS网络术语●SGSN——服务GPRS支持节点,在本SGSN服务区为MS分配IP地址、数据的路由和转发、加密、会话管理、与其它实体设备之间的接口连接、话单记录针对无线资源使用。
●GGSN——关口GPRS支持节点,好似路由(网关)连接其它网络,完成MS与外网通信建立、将用户的数据发往正确的SGSN、话单记录针对连接外网。
chap4(37-38)

在分段系统中不可能存在一条指令或一 个数据存放在不同段中。
4、8 请求分段存储管理方式
• 缺段处理比缺页处理要复杂的多:段的长度 是不固定的,若调入的段较长,则需要淘汰 多个段来满足,系统需要将多个分散的区域 拼接在一起。
缺段中断处理过程:
请求分段系统中的中断处理过程:
否
阻塞请求进程
有合适空闲区? 是 从外存读入S段 修改段表、空闲分区表 唤醒请求进程
3 、在一个请求分页存储管理中,假如一个作业的 页面走向为1 、2 、3 、4 、 2、 1 、5 、6 、2 、1、 2 、 3 、7 、 6 、 3 、 2 、 1 、 2 、 3 、 6 。当系统分配给该 作 业 的 物 理 块 数 为 3 时 , 计 算 分 别 采 用 OPT、 FIFO、LRU页面置换算法时的缺页次数和缺页率。
实现请求分段存储管理软件支持:
内存的分配、回收程序; 缺段中断处理程序;
段置换算法。
内容总结
研究的主要内容:
(1)如何给进入内存的作业分配、回收内存空间。 (2)将原作业空间中的逻辑地址转换成物理地址。
主要知识点
一、什么是逻辑地址?什么是物理地址?
二、什么叫重定位?分为几种类型?
内容总结
地址转换机构:
基本过程:若段号、段内位移、操作均合法 访问的段已经在内存,则同基本分段系统的地址 变换过程; 访问的段不在内存,则先通过缺段中断处理过程 将缺段调入内存、修改段表,然后进行地址转换。 地址变换过程:
基本分段系统的地址变换过程
访问[s]|[w]
否
S<段表长度? 是 找到段S对应的段表项 是 W<S段段长?
4、8 请求分段存储管理方式
请求分段中的硬件支持
chap4 动量和冲量

mv 2
d( mv ) Fdt
动量定理 微分形式
. I
mv 2
t2 mv 2 mv1 Fdt t1
动量定理 积分形式
结论
质点所受合外力的冲量等于质点动量的增量 动量定理
动量定理
t2 mv 2 mv1 Fdt t1
动量定理的投影形式
F2 t 2
F1 t1
P mv
Fi t i
Fn t n
把作用时间分成 n 个很小的时段ti ,每个 时段的力可看作恒力
I
i 注意:冲量 I的方向和瞬时力F 的方向不同!
I F1t1 F2 t2 Fn tn Fi ti
(下一页)
解法一:取挡板和球为研究对象,
由于作用时间很短,忽略重力影响。
y
v2 O 30o
45o x n
设挡板对球的冲力为 F
I Fdt mv2 mv1
0
,则有:
取坐标系,将上式投影,有:
v1
0
t 0 01s, v1 10m / s, v2 20m / s, m 2 5g I Ft I x 0 061Ns, I y 0 0073Ns
4、质点的动量定理的应用 (1)由动量的增量来求冲量;
mv2 x mv1x (2)进而求平均冲力, Fx t
1 当PX 一定时,FX 增大作用时间,缓冲 t
例 质量为 m 的匀质链条,全长为 L,
开始时,下端与地面的距离为 h。 求 当链条自由下落在地面上的长度为 l 时,地面所受链条的作用力? 解
Iy Ix
0 1200, 6052'
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Data Audit节点的设置
质量选项卡:用于反映数据质量的评价指标,以及数据离群点的诊断标准 等 缺失值 含有效值的记录的计数:选择此选项可为每个评估字段显示含有 效值的记录数。请注意,数值型空(未定义的)值、空值、空白 和空字符串总是被视为无效值。 含无效值的记录的分类计数:为每个字段显示含每类无效值的记 录数。 离群值和极值 与平均值的标准差。,根据与平均值的标准差的个数检测离群值 和极值。 四分位数间距,根据四分位数间距检测离群值和极值。
变量角色的说明
变量角色是指变量在模型建立时的角色 变量角色的说明也称为变量方向的说明 In:作为输入变量 Out:作为输出变量 Both:某些模型中,有的变量即可作为输入变量,又可作为输出变量 Partition:样本集分割角色 None:无角色
第四章 数据理解
4.1 4.2 4.3 4.4 4.5 数据理解的主要作用 变量说明 数据质量的评估和调整 数据的排序 数据的分类汇总
变量值的调整
Clementine的变量值调整,是在Data Audit节点执行结果的基础上,针对 数据中的离群点、极端值、缺失值,根据用户选择的方法进行调整和修正 主要包括: 离群点和极端值的调整 缺失值的调整
离群点和极端值的调整
选中某个变量行 下拉相应行的Action框选择调整方法 Coerce:离群点或极端值调整为距它们最近的正常值 Discard:剔除离群点和极端值 Nullify:用系统缺失值$null$替代离群点或极端值 Coerce outliers/discard extremes:按照Coerce方法修正离群点, 并剔除极端值 Coerce outliers/nullify extremes:按照Coerce方法修正离群点, 并将极端值调整为系统缺失值$null$ 选择窗口菜单的Generate下的Outlier&Extreme SuperNode Clementine将自动生成一个超节点,用于根据用户指定的调整方法, 调整离群点和极端值 将所自动生成的超节点连接到数据流的恰当位置上,即可查看变量值 调整的效果。
找出无效样本
有效样本是指那些在指定变量上未取无效值的样本,无效样本是指那些在指定变量 上取了有效值的样本 在质量审核窗口中,选择Generate下的Select Node项 Select when record is:Valid或Invalid表示选出有效样本或无效样本 Look for invalid value in:指定无效样本的界定变量,即样本在哪些变量 上取了无效值 All fields:在节点的所有变量 Fields selected in table:表示已选择的变量 Fields with quality percentage high than % :表示质量高于指定百分 比的变量 Consider a record invalid if an invalid value is found in:指定如何 确定无效样本 Any of the above fields:如果样本在上述三种界定依据中的任何一种 中取无效值 All of the above fields:如果样本在上述三种界定依据中都取无效值
对变量是否无偿献血的说明(续)
Define blanks: 选中该选项,表示视Missing Values表所列值,及某区间内的连续值 、$Null$、空格(White space)为空(Blanks) 指定为空的目的是将无须或无法调整的用户缺失值和系统缺失值,与 变量的正常值区分开,便于后续的数据分析 说明:用于输入变量名标签,是变量含义的简短说明文字
Data Audit节点的设置
设置选项卡:使用“设置”选项卡,可指定用于审核的基本参数 默认值。 如果没有“类型”节点设置,则报告中包括所有字段。 如果有“类型”设置,则显示中包括所有输入、目标和双向字段 。如果有一个目标字段,使用它作为“交叠”字段。如果指定了 多个目标字段,则不指定默认交叠。 使用自定义字段,选择此选项可手动选择字段 交叠字段。交叠字段用于绘制审核报告中显示的缩略图图形。如果是 连续字段,则还计算二元统计量(协方差和相关系数)。如果单个目 标字段根据“类型”节点设置显示,则使用它作为默认交叠字段,或 者,选择使用自定义字段以指定交叠。 显示。 图形。 显示每个选定字段的图形;根据数据的情况显示为分布 (条形)图、直方图或散点图。 基本/高级统计量。 指定默认显示在输出中的统计量的级别。 中位数和众数。 计算报告中所有字段的中位数和众数
对变量是否无偿献血的说明
类型:显示当前变量的计量类型和存储类型 值:用来指定确定变量取值范围的方法 Read from data:取决于所读的外部数据 Pass:忽略所读的外部数据 Specify:指定变量取值和变量值标签 Check values:选择对变量不合理值的调整方法 None:不进行调整 Nullify:将用户缺失值调整为系统缺失值$null$ Coerce:调整为指定值,Clementine默认,Flag型变量调整为False 类对应的值,Set型变量调整为第一个变量值,数值型变量,大于上 限的调整为上限值,小于下限的调整为下限值,其余值调整为(最大 值+最小值)/2 Discard:剔除相应数据 Warn:遇到不合理取值时给出警告信息 Abort:遇到不合理取值时终止数据流的执行
第四章 数据理解
4.1 4.2 4.3 4.4 4.5 数据理解的主要作用 变量说明 数据质量的评估和调整 数据的排序 数据的分类汇总
4.4 数据排序
数据排序功能虽然简单,却有广泛的应用,是把握数据取值状态的最简洁 的途径 排序的作用 便于浏览数据,了解变量值的大致范围 有助于发现数据可能存在的问题,如离群点或极端值等 将Record Ops选项卡中的Sort节点连接到数据流中 单变量排序 多变量排序 将Table节点连接到数据流中,查看排序结果
第四章 数据理解
第四章 数据理解
4.1 4.2 4.3 4.4 4.5 数据理解的主要作用 变量说明 数据质量的评估和调整 数据的排序 数据的分类汇总
4.1 数据理解的主要作用
依据数据挖掘方法论,数据理解在数据挖掘过程中起着举足轻重的作用, 其目的是把握数据的总体质量,了解数据的大致范围。 数据理解主要包括数据质量评估和调整、数据的有序浏览和多维度汇总等
数据质量管理
数据质量管理是指,当数据质量评估后,可以将质量不高的变量或样本剔 除,仅保留高质量的变量和样本。
保留高质量的变量
高质量变量的标准:在该变量上取有效值的样本个数占总样本量的比例( 完整比例%Complete)高于某个指定值 在质量审核窗口中,选择窗口菜单Generate下的Filter Node项,设置相 应的参数,自动生成一个Filter节点 将生成的Filter节点连接到数据流中,可以看到变量保留或删除的情况
对变量家庭人均年收入的说明
家庭人均年收入的取值范围不能直接由外部数据决定,否则系统将视 999999(用户缺失值)为正常值,应在Lower和Upper框中手工输入合理的 取值区间为6617~503308 由于希望对家庭人均年收入中的999999和$null$值进行调整,不应选中 Define blanks项,系统将自动视999999和$null$为超出取值范围的不合 理取值,并按用户指定的Coerce方法进行调整 返回后,家庭人均年收入的Missing列上为空,表示该变量不存在用户缺 失值。
数据浏览
将Output选项卡中的Table节点连接到数据流中 浏览数据,发现存在的问题 利用Type节点解决数据存在的问题 将字段选项卡中的Type节点连接到数据流中
变量的重新实例化
数据读入时变量需要进行实例化,当数据源节点中的数据有更新,或数据 流派生出一些新的变量,或进行了数据集成操作,或原有变量的类型有了 新的调整时,变量需要实例化。 Clear Values或Clear All Values,强制所有变量变为非实例化状态,所 有变量Values项自动取值为Read Values列的取值 Read:读入数据进行重新实例化 Read+:读入数据且新数据自动追加到原有数据的后面 Pass:不读入变量值 Current:保持变量的当前值,不重新实例化 Read Values进行变量的重新实例化,Values列将显示各变量值的取值范 围
缺失值的调整
选中某个变量行 下拉相应行的Impute Missing框选择调整对象 Never:表示不做调整 Blank Values:对空做调整 Null Values:对系统缺失值$null$做调整 Null & Null Value:对空和系统缺失值做调整 Condition:对满足指定条件的变量值做调整 选择需要调整的变量行,选择窗口菜单Generate下的Missing Values SuperNode项
第四章 数据理解
4.1 4.2 4.3 4.4 4.5 数据理解的主要作用 变量说明 数据质量的评估和调整 数据的排序 数据的分类汇总
4.2 变量说明
变量说明是确保高质量数据的有效途径 变量说明主要包括两个方面 对数据流中变量取值的有效性进行限定、检查和调整 对各个变量在未来数据建模中的角色进行说明 可通过记录选项卡中的Type节点进行变量说明
数据的基本特征与数据质量报告
数据质量评估和调整,是对现有数据的取值异常程度以及缺失情况等进行 综合评价,并借助统计分析方法对其进行适当调整和填补 数据的基本特征与质量评价报告:对数据的缺失、离群点和极端值等情况 进行评估 完整变量比例的计算 完整样本比例的计算 其他评价指标的计算 利用Output选项卡中的Data Audit节点进行数据质量考察