SQL经典
基础sql语句

基础sql语句1. SELECT: 用于查询表中的数据,可以使用通配符(*)表示所有列或者指定列名。
例子:SELECT * FROM table_name;2. FROM: 用于指定查询的数据来源,即需要查询哪张表。
例子:SELECT * FROM table_name;3. WHERE: 用于筛选满足条件的数据行,可以使用比较运算符(>,<,=,!=,>=,<=)等。
例子:SELECT * FROM table_name WHEREcolumn_name >= 10;4. ORDER BY: 用于将查询结果按照某个列进行排序,可以指定升序或降序(ASC或DESC)。
例子:SELECT * FROM table_name ORDER BYcolumn_name ASC;5. GROUP BY: 用于将查询结果按照某个列进行分组,通常使用聚合函数(SUM,COUNT,AVG,MAX,MIN)进行数据计算。
例子:SELECT column_name, COUNT(*) FROM table_name GROUP BY column_name;6. LIMIT: 用于限制查询结果的数量,只返回前几条数据。
例子:SELECT * FROM table_name LIMIT 10;7. JOIN: 用于将多张表按照共同的字段进行连接,可以有多种连接方式(INNER JOIN,LEFT JOIN,RIGHT JOIN,FULL OUTER JOIN)。
例子:SELECT * FROM table1 LEFT JOIN table2 ONtable1.column_name = table2.column_name.。
sql经典语句(SQLclassicsentences)

sql经典语句(SQL classic sentences)I. Basic operation1) DESC, the describe role is to display the structure of the data table using the form: desc data table name2) distinct eliminates duplicate data usage: select, distinct, field name, from data table3) order by field 1 ASC, field 2 desc4) nested queries select, emp.empno, emp.ename, emp.job, emp.salFrom scott.empWhere sal>= (select, Sal, from, scott.emp, where, ename='WARD');5) nested queries select, emp.empno, emp.ename, emp.job, in, emp.salFrom scott.empWhere, Sal, in (select, Sal, from, scott.emp, where, ename ='WARD');6) nested queries select, emp.empno, emp.ename, emp.job, any, emp.salFrom scott.empWhere Sal > any (select, Sal, from, scott.emp, where, job='MANAGER');Equivalent to (1) select, Sal, from, scott.emp, where, job ='MANAGER'(2) select, emp.empno, emp.ename, emp.job, emp.salFrom scott.empData found in where Sal > (1) data a, or, Sal > (1), data found in B, or, Sal > (1), CEg:Select, Sal, from, scott.emp, where, job ='MANAGER'results; 12,10,13Equivalent to sal=12,10,13 or SAL> (12, OR, 10, OR, 13)7) the intersection operation is the intersection concept in the set. The sum of the elements that belong to the set A and belongs to the set B is the intersection. In the command edit area, execute the following statement.Eg:(select, djbh, from, ck_rwd_hz) intersect (select, djbh, from, ck_rwd_mx) documents numbered the sameSelect * from ck_rwd_mx a,((select, djbh, from, ck_rwd_hz) intersect (select, djbh, from, ck_rwd_mx)) BWhere a.djbh =b.djbhTwo function1) ceil takes the minimum integer ceil (N) greater than or equal to the value N; select, Mgr, mgr/100, ceil (mgr/100), from, scott.emp;2) floor takes the maximum integer floor (N) less than or equal to the value N; select, Mgr, mgr/100, floor (mgr/100), from, scott.emp;3) the remainder of mod m divisible by mod (m, n) n4) power, m, N, square, mod (m, n)5) round m four, five, keep the n bit mod (m, n)Select round (8.655,2) from dual; 8.66Select round (8.653,2) from dual; 8.656) sign n>0, take 1; n=0, take 0; n<0, take -1;7) AVG averages AVG (field name)8) count statistics total count (field name) select (*) from scott.emp; select count (distinct job) from scott.emp;9) min calculates numeric fields minimum, select, min (SAL), minimum salary from scott.emp;10) max calculates numeric field maximum, select, max (SAL), highest salary from scott.emp;11) sum calculates the sum of numeric fields, select, sum (SAL), the sum of salaries, from, scott.emp;Three input data1) single data entryInsert into data tables (fields 1, fields 2,...) valuse (field name 1 values, field name 2 values,...)Numeric fields can write values directly; character fields add single quotation marks; date fields add single quotes; at the same time pay attention to the order of days and months2) multi line data entryInsert into data table (field name 1, field name 2,...)(select (field name 1 or operation, field name 2 or operation,...) from data table where condition)3) data replication between tablesCreate table scott.testAs(Select, distinct, empno, ename, hiredate, from, scott.emp, where, empno>=7000);Create table spkpk_liu as select * from spkfk; creates tables and copies data, but creates incomplete table informationThis is all the way to full table backups.Usually after the table is built, you need to see if you want to build the index and primary key again.And "create, table, spkpk_liu, as, select * from, spkfk.""After this table is built, many of the parameter values of the table are the default minimum values, such as the initial value of the original table 10M, and the new table is probably only 256K.Formal environment used in the table, generally do not recommend such a table built.In this way, just a little lazy, if you do so,A statement can achieve the purpose of building tables and inserting data.For example, you need to modify the data in table A, and you might want to back up the data from the A table before you modify it.This time you can use create table... As...This makes it easy to retrieve data from the A table in the futureYou can do this when you debug your own program, but you can't create processes, packages, functions like thisFour delete dataDelete deletes data; truncate deletes the entire table data, but retains the structure1) delete recordsDelete from scott.test where empno and empno <=8000 > = 7500;2) delete the entire dataTruncate table scott.test;Similarities and differences between truncate, delete and dropNote: the delete here refers to the delete statement without the where clauseThe same thing: truncate and the delete without the where clause, and drop will delete the data in the tableDifference:1. truncate and delete only delete data and do not delete the structure of the table (definition)The drop statement will delete the structure of the table, the dependent constraints (constrain), the trigger, and the index (index); the stored procedure / function that depends on the table will be retained, but the invalid state will be changedThe 2.delete statement is DML, which is put into the rollback segement before the transaction is committed, and if you have the corresponding trigger, the execution will be triggeredTruncate, drop is DDL, the operation takes effect immediately, and the original data is not put into the rollback segment and cannot be rolled back. The operation does not trigger trigger.. Obviously, the drop statement releases all the space occupied by the table3. speed, in general: drop>, truncate > deleteOn use, you want to delete part of the data rows, with delete,take care to bring the where clause. The rollback section is large enough to be rolled back through the ROBACK, and there is considerable room for recoveryTo delete tables, of course, use dropYou want to keep the table and delete all the data. If you have nothing to do with the transaction, you can use truncate. Truncate, table, XX, delete the entire table of data, there is no room for recovery, the benefits can be arranged in the table debris, release spaceSo it's better to back up the data firstIf you are tidying up the inner fragments of a table, you can use truncate to catch up with reuse stroage and then import / insert data againFive update dataUpdate data sheetSet field name, 1=, new assignment, field name, 2=, new assignment,...Where conditionUpdate scott.empSet, empno=8888, ename='TOM', hiredate='03-9, -2002'Where empno = 7566;Update scott.empSet sal=(select, sal+300, from, scott.emp, where, empno = 8099)Where empno=8099;Decode (condition, value 1, translation value 1, value 2, translation value 2, value n, translation value n, default value)Six data export1 export the database TEST completely, export the user name system password manager to D:\daochu.dmpExpsystem/manager@TESTfile=d:\daochu.dmp full=y2 export the system user in the database to the table of the sys userExpsystem/manager@TESTfile=d:\daochu.dmp only wner= (system, Sys)3 export tables table1 and table2 from the databaseExpsystem/manager@TESTfile=d:\daochu.dmp tables= (table1, table2)4 export the field filed1 in the table table1 in the database to data that starts with "00"Expsystem/manager@TESTfile=d:\daochu.dmp tables= (table1) query=\ "where filed1 like'00%'\""Explmis_wh/lmis@lmisbuffer=10000 only WNER=lmis_wh rows=nfile=d:\lmis_wh_nodata.dmp log=d:\lmis_wh_nodata.logImplmis/lmis@lmisbuffer=10000, fromuser=lmis_wh, touser=lmis, file=d:\lmis_wh_nodata.dmp, log=d:\lmis_wh_nodata.logC:\>implmis/lmis@lmisbuffer=50000000, full=n,file=e:\daochu.dmp, ignore=y, rows=yCommit=y compile=y fromuser=lmis_wh touser=lmisSeven data import1 import data from the D:\daochu.dmp into the TEST database.Impsystem/manager@TEST file=d:\daochu.dmpThere may be a problem with it because some tables already exist, and then it is reported wrong, and the table is not imported.It's OK to add ignore=y at the back.2 import table table1 from d:\daochu.dmpImpsystem/manager@TEST file=d:\daochu.dmp tables= (table1)SQL definition: SQL is a database oriented general data processing language specification, can complete the following functions: data extraction query, insert modify delete data generation, modify and delete database objects, database security, database integrity control and data protection.SQL classification:DDL - Data Definition Language (CREATE, ALTER, DROP, DECLARE)DML - Data Manipulation Language (SELECT, DELETE, UPDATE, INSERT)DCL - data control language (GRANT, REVOKE, COMMIT, ROLLBACK) DDL - database definition language: direct submission. CREATE: used to create database objects.DECLARE: in addition to creating temporary tables that are used only during the process, the DECLARE statements are very similar to the CREATE statements. The only object that can be declared is the table. And must be added to the user temporary tablespace.DROP: you can delete any object created with CREATE (database object) and DECLARE (table).ALTER: allows you to modify information about certain databaseobjects. Cannot modify index.Eight, the following is mainly based on object presentation of basic grammar1, database:Create database: CREATE, DATABASE, database-name, [USING, CODESET, codeset, TERRITORY, territory]Note: the code page problem.Delete database: drop, database, dbname2, table:Create new table:Create, table, tabname (col1, Type1, [not, null], [primary, key], col2, type2, [not, null],...)Create a new table based on the existing table:A:create, table, tab_new, like, tab_oldB:create, table, tab_new, as, select, col1, col2... From tab_old definition onlyModify table:Add a column:Alter, table, tabname, add, column, col, typeNote: column added will not be deleted. The DB2 column after the data type does not change, the only change is to increase the size of the varchar. Add primary key:Alter, table, tabname, add, primary, key (Col)Delete Primary key:Alter, table, tabname, drop, primary, key (Col)Delete table: drop, table, tabnameAlter table BMDOC_LIUFDrop constraint PK1_BMDOC cascade;3, table space:Create table spaces: create, tablespace, tbsname, PageSize, 4K, managed, by, database, using (file, file, size)Adding containers to tablespace: alter, tablespace, tablespace_name, add (file,'filename', size)Note: the operation is irreversible and will not be removed after adding the container. Therefore, when it is added, pay attention to it.Delete tablespace: drop, tablespace, tbsname4, index:Create indexes: create, [unique], index, idxname, on, tabname (col... ).Delete index: drop, index, idxnameNote: the index is not modifiable. If you want to change it, you must delete it.5 views:Create views: create, view, VIEWNAME, as, select, statementDelete view: drop view VIEWNAMENote: the only change to the view is the reference type column, which changes the range of columns. None of the other definitions can be modified. The view becomes invalid when the view is based on the base table drop.DML - the database manipulation language, which does not implicitly submit the current transaction and is committed to the setting of the visual environment.SELECT: querying data from tablesNote: the connection in the condition avoids Cartesian productDELETE: delete data from existing tablesUPDATE: update data for existing tablesINSERT: insert data into existing tablesNote: whether DELETE, UPDATE, and INSERT are submitted directly depends on the environment in which the statement is executed.Pay attention to the full transaction log when executing.2, DELETE: delete records from the tableSyntax format:DELETE, FROM, tablename, WHERE (conditions)3, INSERT: insert a record into the tableSyntax format:INSERT INTO tablename (col1, col2),... ) VALUES (value1, Value2),... );INSERT INTO tablename (col1, col2),... ) VALUES (value1, Value2),... ) (value1, value2,... ),......Insert does not wait for any program and does not cause locking4, UPDATE:Syntax format:UPDATE tabname SET (col1=values1, col2=values2),... (WHERE) (conditions);Note: update is slower and requires indexing on the corresponding column.Nine permissionsDCL - Data Control LanguageGRANT - Grant user permissionsREVOKE - revoke user rightsCOMMIT - commit transactions can permanently modify the databaseROLLBACK - rollback transactions, eliminating all changes made after the last COMMIT command, so that the contents of the database are restored to the state after the last COMMIT execution.1, GRANT: all or administrators assign access rights to other usersSyntax format:Grant [all privileges|privileges,... On tabname VIEWNAME to [public|user |,... .2 and REVOKE: cancel one of the user's access rightsSyntax format:Revoke [all privileges|privileges,... On tabname VIEWNAME from [public|user |,... .Note: any permissions of users of instance level cannot be canceled. They are not authorized by grant, but are permissions implemented by groups.3, COMMIT: permanently records changes made in the transaction to the database.Syntax format:Commit [work]4, ROLLBACK: will undo all changes made since the last submission.Syntax format:Rollback [work]Ten advanced SQL brief introductionFirst, the query between the use of computing wordsA:UNION operatorThe UNION operator derives a result table by combining two other result tables (such as TABLE1 and TABLE2) and eliminating any duplicate rows in the table.When ALL is used with UNION (that is, UNION ALL), the duplicate rows are not eliminated. In the two case, each row of the derived table does not come from TABLE1, or from TABLE2.B:EXCEPT operatorThe EXCEPT operator derives a result table by including all rows in TABLE1, but not in TABLE2, and eliminating all duplicate rows. When ALL is used with EXCEPT (EXCEPT ALL), the duplicate rows are not eliminated.C:INTERSECT operatorThe INTERSECT operator derives a result table by including only rows in TABLE1 and TABLE2 and eliminating all duplicate rows. When ALL is used with INTERSECT (INTERSECT ALL), the duplicate rows are not eliminated.Note: several query results lines using arithmetic words must be consistent.Appendix: introduction to commonly used functions1, type conversion function:Converted to a numeric type:Decimal, double, Integer, smallint, realHex (ARG): 16 hexadecimal representation converted into parameters.Converted to string type:Char, varcharDigits (ARG): returns the string representation of Arg, and Arg must be decimal.Converted to date or time:Date, time, timestamp2, time and date:Year, quarter, month, week, day, hour, minute, secondDayofyear (ARG): returns the daily value of Arg in the yearDayofweek (ARG): returns the daily value of Arg in the weekDays (ARG): the integer representation of the return date, the number of days from the 0001-01-01.Midnight_seconds (ARG): the number of seconds between midnight and arg.Monthname (ARG): returns the month name of arg.Dayname (ARG): the week that returns arg.3 string function:Length, lcase, ucase, ltrim, rtrimCoalesce (arg1, arg2)... ) returns the first non null parameter in the argument set.Concat (arg1, arg2): connect two strings, arg1 and arg2.Insert (arg1, POS, size, arg2): returns a arg1 that removes size characters from POS and inserts arg2 into that location.Left (Arg, length): returns the leftmost length string of arg.Locate (arg1, arg2, <, pos>): find the location of the first occurrence of arg1 in arg2, specify POS, and start looking for the location of the arg1 from the POS of arg2.Posstr (arg1, arg2): returns the position where arg2 first appeared in arg1.Repeat (arg1, num_times): returns the string arg1 repeated num_times times.Replace (arg1, arg2, ARG3): replace all arg2 in arg1 to arg3.Right (Arg, length): returns a string consisting of lengthbytes on the left of the arg.Space (ARG): returns a string containing Arg spaces.Substr (arg1, POS, <, length>): returns the length character at the start of the POS position in arg1, and returns the remaining characters if no length is specified.4. Mathematical function:Abs, count, Max, min, sumCeil (ARG): returns the smallest integer greater than or equal to arg.Floor (ARG): returns the smallest integer less than or equal to the parameter.Mod (arg1,Arg2) returns arg1 by the remainder of the arg2, with the same symbol as arg1.Rand (): returns a random number between 1 and 1.Power (arg1, arg2): returns the arg2 power of arg1.Round (arg1, arg2): four, five into the truncated processing, arg2 is the number of bits, if arg2 is negative, then the number of decimal points before four to five processing.Sigh (ARG): symbolic designator to return arg. -1,0,1 representation.Truncate (arg1, arg2): truncate arg1, arg2 is the number of digits, and if arg2 is negative, keep the arg2 bits before the arg1 decimal point.5, others:Nullif (arg1, arg2): returns if the 2 arguments are equal, otherwise the argument 1 is returned。
sql面试必会6题经典

sql面试必会6题经典面试题
1. SQL有哪些数据类型?
SQL数据类型包括:数值类型(整数、实数、位类型)、字符串类型(字符串、固定长度字符串、可变长度字符串)、日期/时间类型、二进制类型以及用户自定义的特殊类型。
2. 什么是 SQL 联合查询?
SQL联合查询是一种在单个查询中使用多个表进行信息检索的技术,可以将多个相关表中的数据检索出来并进行合并显示。
常用的联合查询有内连接(Inner Join)、左外连接(Left Join)、右外连接(Right Join)、全外连接(Full Join)等。
3. 什么是 SQL 索引?
SQL索引是数据库表中用于快速检索数据的数据结构,它可以加快数据库表中某一列或多列上的查询速度。
常见的索引类型有B树索引、哈希索引、空间索引等。
4. 什么是SQL视图?
SQL视图是一种虚拟表,用于从一个或多个表中检索数据,并提供一种抽象的方法来访问表中的数据。
它可以让用户只能看到所需要看到的列和行,而不需要查看整个表。
5. SQL语句有哪些?
SQL语句有以下几种:CREATE(创建)、SELECT(查询)、INSERT(插入)、UPDATE(更新)、DELETE(删除)、ALTER(修改)、DROP(删除)等。
6. 什么是子查询?
子查询是一种在SQL语句中嵌套另一个完整的SQL语句的查询,它可以从其它表中检索数据,也可以从当前表中检索数据。
它可以让你更有效地检索数据,并且可以让你在不使用连接的情况下实现类似于连接的结果。
SQL经典50题练习
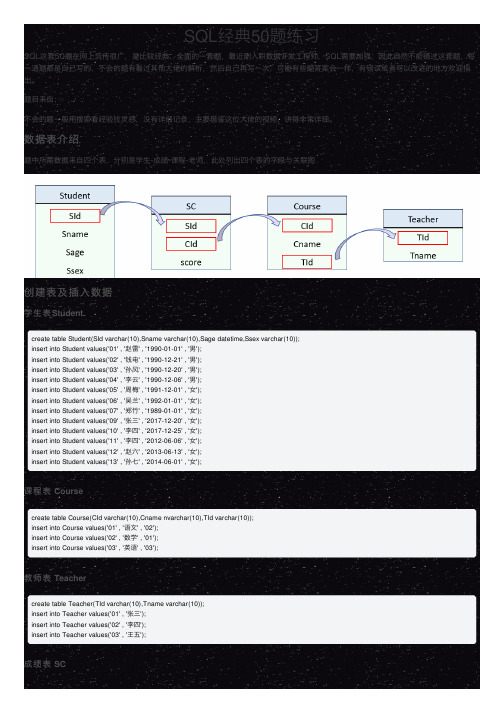
创建表及插⼊数据学⽣表Studentcreate table SC(SId varchar(10),CId varchar(10),score decimal(18,1));insert into SC values('01' , '01' , 80);insert into SC values('01' , '02' , 90);insert into SC values('01' , '03' , 99);insert into SC values('02' , '01' , 70);insert into SC values('02' , '02' , 60);insert into SC values('02' , '03' , 80);insert into SC values('03' , '01' , 80);insert into SC values('03' , '02' , 80);insert into SC values('03' , '03' , 80);insert into SC values('04' , '01' , 50);insert into SC values('04' , '02' , 30);insert into SC values('04' , '03' , 20);insert into SC values('05' , '01' , 76);insert into SC values('05' , '02' , 87);insert into SC values('06' , '01' , 31);insert into SC values('06' , '03' , 34);insert into SC values('07' , '02' , 89);insert into SC values('07' , '03' , 98);练习题⽬1. 查询" 01 "课程⽐" 02 "课程成绩⾼的学⽣的信息及课程分数1.1 查询同时存在" 01 "课程和" 02 "课程的情况1.2 查询存在" 01 "课程但可能不存在" 02 "课程的情况(不存在时显⽰为 null )1.3 查询不存在" 01 "课程但存在" 02 "课程的情况2. 查询平均成绩⼤于等于 60 分的同学的学⽣编号和学⽣姓名和平均成绩3. 查询在 SC 表存在成绩的学⽣信息4. 查询所有同学的学⽣编号、学⽣姓名、选课总数、所有课程的总成绩(没成绩的显⽰为 null )4.1 查有成绩的学⽣信息5. 查询「李」姓⽼师的数量6. 查询学过「张三」⽼师授课的同学的信息7. 查询没有学全所有课程的同学的信息8. 查询⾄少有⼀门课与学号为" 01 "的同学所学相同的同学的信息9. 查询和" 01 "号的同学学习的课程 完全相同的其他同学的信息10. 查询没学过"张三"⽼师讲授的任⼀门课程的学⽣姓名11. 查询两门及其以上不及格课程的同学的学号,姓名及其平均成绩12. 检索" 01 "课程分数⼩于 60,按分数降序排列的学⽣信息13. 按平均成绩从⾼到低显⽰所有学⽣的所有课程的成绩以及平均成绩14. 查询各科成绩最⾼分、最低分和平均分:以如下形式显⽰:课程 ID,课程 name,最⾼分,最低分,平均分,及格率,中等率,优良率,优秀率及格为>=60,中等为:70-80,优良为:80-90,优秀为:>=90要求输出课程号和选修⼈数,查询结果按⼈数降序排列,若⼈数相同,按课程号升序排列15. 按各科成绩进⾏排序,并显⽰排名, Score 重复时保留名次空缺15. 按各科成绩进⾏排序,并显⽰排名, Score 重复时保留名次空缺15.1 按各科成绩进⾏排序,并显⽰排名, Score 重复时合并名次16. 查询学⽣的总成绩,并进⾏排名,总分重复时保留名次空缺16.1 查询学⽣的总成绩,并进⾏排名,总分重复时不保留名次空缺17. 统计各科成绩各分数段⼈数:课程编号,课程名称,[100-85],[85-70],[70-60],[60-0] 及所占百分⽐18. 查询各科成绩前三名的记录19. 查询每门课程被选修的学⽣数20. 查询出只选修两门课程的学⽣学号和姓名21. 查询男⽣、⼥⽣⼈数22. 查询名字中含有「风」字的学⽣信息23. 查询同名同性学⽣名单,并统计同名⼈数24. 查询 1990 年出⽣的学⽣名单25. 查询每门课程的平均成绩,结果按平均成绩降序排列,平均成绩相同时,按课程编号升序排列26. 查询平均成绩⼤于等于 85 的所有学⽣的学号、姓名和平均成绩27. 查询课程名称为「数学」,且分数低于 60 的学⽣姓名和分数28. 查询所有学⽣的课程及分数情况(存在学⽣没成绩,没选课的情况)29. 查询任何⼀门课程成绩在 70 分以上的姓名、课程名称和分数30. 查询不及格的课程31. 查询课程编号为 01 且课程成绩在 80 分以上的学⽣的学号和姓名32. 求每门课程的学⽣⼈数33. 成绩不重复,查询选修「张三」⽼师所授课程的学⽣中,成绩最⾼的学⽣信息及其成绩34. 成绩有重复的情况下,查询选修「张三」⽼师所授课程的学⽣中,成绩最⾼的学⽣信息及其成 绩35. 查询不同课程成绩相同的学⽣的学⽣编号、课程编号、学⽣成绩36. 查询每门功成绩最好的前两名37. 统计每门课程的学⽣选修⼈数(超过 5 ⼈的课程才统计)。
经典SQL语句大全(超全)

一、基础1、说明:创建数据库CREATE DATABASE database-name2、说明:删除数据库drop database dbname3、说明:备份sql server--- 创建备份数据的 deviceUSE masterEXEC sp_addumpdevice 'disk', 'testBack', 'c:\mssql7backup\MyNwind_1. dat'--- 开始备份BACKUP DATABASE pubs TO testBack4、说明:创建新表create table tabname(col1 type1 [not null] [primary key],col2 type2 [not null],..)根据已有的表创建新表:A:create table tab_new like tab_old (使用旧表创建新表)B:create table tab_new as select col1,col2… from tab_old definition only5、说明:删除新表drop table tabname6、说明:增加一个列Alter table tabname add column col type注:列增加后将不能删除。
DB2中列加上后数据类型也不能改变,唯一能改变的是增加varchar类型的长度。
7、说明:添加主键:Alter table tabname add primary key(col)说明:删除主键: Alter table tabname drop primary key(col)8、说明:创建索引:create [unique] index idxname on tabname(col….) 删除索引:drop index idxname注:索引是不可更改的,想更改必须删除重新建。
9、说明:创建视图:create view viewname as select statement删除视图:drop view viewname10、说明:几个简单的基本的sql语句选择:select * from table1 where 范围插入:insert into table1(field1,field2) values(value1,value2)删除:delete from table1 where 范围更新:update table1 set field1=value1 where 范围查找:select * from table1 where field1 like ’%value1%’ ---like的语法很精妙,查资料!排序:select * from table1 order by field1,field2 [desc]总数:select count as totalcount from table1求和:select sum(field1) as sumvalue from table1平均:select avg(field1) as avgvalue from table1最大:select max(field1) as maxvalue from table1最小:select min(field1) as minvalue from table111、说明:几个高级查询运算词A:UNION 运算符UNION 运算符通过组合其他两个结果表(例如 TABLE1 和 TABLE2)并消去表中任何重复行而派生出一个结果表。
SQL中经典函数使用实例大全

SQL中经典函数使用实例大全SQL中有许多经典的函数,可以用来完成各种复杂的操作。
下面是一些常用的SQL函数以及它们的使用示例。
1.聚合函数:用于对数据进行汇总计算。
- AVG:计算列的平均值。
例如,计算一个表的成绩列的平均值:SELECT AVG(score) FROM table_name;- SUM:计算列的总和。
例如,计算一个表的销售额列的总和:SELECT SUM(sales) FROM table_name;- COUNT:计算列的行数。
例如,计算一个表的记录数:SELECT COUNT(*) FROM table_name;- MAX:找出列的最大值。
例如,找出一个表中的最大年龄:SELECT MAX(age) FROM table_name;- MIN:找出列的最小值。
例如,找出一个表中的最小工资:SELECT MIN(salary) FROM table_name;2.字符串函数:用于对字符串进行各种操作。
- CONCAT:将多个字符串连接在一起。
例如,将名字和姓氏连接起来:SELECT CONCAT(first_name, ' ', last_name) FROM table_name;- SUBSTRING:提取字符串的子串。
例如,提取一个表的地址列的前5个字符:SELECT SUBSTRING(address, 1, 5) FROM table_name;- UPPER:将字符串转换为大写。
例如,将一个表的名字列转换为大写:SELECT UPPER(name) FROM table_name;- LOWER:将字符串转换为小写。
例如,将一个表的地址列转换为小写:SELECT LOWER(address) FROM table_name;- LENGTH:返回字符串的长度。
例如,返回一个表的用户名列的长度:SELECT LENGTH(username) FROM table_name;3.数值函数:用于对数值进行各种操作。
常用的SQL语句

常用的SQL语句下面列举了一些我们在开发中常常会使用到的SQL语句,供大家参考学习。
1. 查询所有数据:SELECT * FROM table_name;2. 查询指定列数据:SELECT column1, column2 FROM table_name;3. 带条件查询:SELECT * FROM table_name WHERE condition;4. 带条件查询并排序:SELECT * FROM table_name WHERE condition ORDER BY column_name ASC/DESC;5. 带分组的查询:SELECT column1, COUNT(*) FROM table_name GROUP BY column1;6. 带分组和排序的查询:SELECT column1, COUNT(*) FROM table_name GROUP BY column1 ORDER BY COUNT(*) DESC;7. 带聚合函数的查询:SELECT AVG(column1), MAX(column2), MIN(column3) FROM table_name;8. 带子查询的查询:SELECT * FROM table_name WHERE column1 IN (SELECT column1 FROM other_table);9. 带连接条件的查询:SELECT * FROM table1 JOIN table2 ON table1.column1 = table2.column2;10. 带连接和排序条件的查询:SELECT * FROM table1 JOIN table2 ON table1.column1 = table2.column2 ORDER BY table1.column2 ASC;11. 带连接和分组条件的查询:SELECT * FROM table1 JOIN table2 ON table1.column1 = table2.column2 GROUP BY table1.column2;12. 带连接和聚合函数条件的查询:SELECT * FROM table1 JOIN table2 ON table1.column1 = table2.column2 GROUP BY table1.column2 HAVING AVG(table2.column3) > 0;13. 插入数据:INSERT INTO table_name (column1, column2) VALUES (value1, value2);14. 更新数据:UPDATE table_name SET column1 = value1 WHERE condition;15. 删除数据:DELETE FROM table_name WHERE condition;16. 清空表数据:TRUNCATE TABLE table_name;17. 创建表:CREATE TABLE table_name (column1 datatype, column2 datatype, ...);18. 修改表结构:ALTER TABLE table_name ADD column_name datatype;19. 删除表:DROP TABLE table_name;20. 查看表结构:DESCRIBE table_name;21. 查看表数据量:SELECT COUNT(*) FROM table_name;22. 查看表索引:SHOW INDEX FROM table_name;23. 创建索引:CREATE INDEX index_name ON table_name (column_name);24. 删除索引:DROP INDEX index_name ON table_name;25. 批量插入数据:INSERT INTO table_name (column1, column2) VALUES (value1, value2), (value3, value4), ...;26. 批量更新数据:UPDATE table_name SET column1 = value1 WHERE condition, column2 = value2 WHERE condition, ...;27. 批量删除数据:DELETE FROM table_name WHERE condition, ...;28. 分页查询:SELECT * FROM table_name LIMIT offset, limit;29. 子查询嵌套查询:(SELECT column1 FROM other_table WHERE condition) IN (SELECT column1 FROM another_table WHERE condition);30. UNION操作符查询:SELECT * FROM table1 UNION SELECT * FROM table2。
mysql-50道经典sql题

mysql-50道经典sql题English.Q1: Find all customers who have placed orders with a total value of over $1000.sql.SELECT customer_id, SUM(order_total) AS total_value.FROM orders.GROUP BY customer_id.HAVING total_value > 1000;Q2: Find all products that have been ordered more than 10 times.sql.SELECT product_id, COUNT() AS order_count.FROM order_items.GROUP BY product_id.HAVING order_count > 10;Q3: Find all employees who have worked on more than 5 projects.sql.SELECT employee_id, COUNT() AS project_count.FROM project_assignments.GROUP BY employee_id.HAVING project_count > 5;Q4: Find all orders that were shipped within 2 days of being placed.sql.SELECT order_id, DATEDIFF(ship_date, order_date) AS shipping_time.FROM orders.WHERE shipping_time <= 2;Q5: Find all customers who have placed at least one order in the last year.sql.SELECT customer_id.FROM orders.WHERE order_date >= DATE_SUB(CURDATE(), INTERVAL 1YEAR);Chinese.Q1: 找出所有总订单价值超过 1000 美元的客户。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用排序规则特点计算汉字笔划和取得拼音首字母
SQL SERVER的排序规则平时使用不是很多,也许不少初学者还比较陌生,但有一个错误大家应是经常碰到: SQL SERVER数据库,在跨库多表连接查询时,若两数据库默认字符集不同,系统就会返回这样的错误:
“无法解决 equal to 操作的排序规则冲突。
”
一.错误分析:
这个错误是因为排序规则不一致造成的,我们做个测试,比如:
create table #t1(
name varchar(20) collate Albanian_CI_AI_WS,
value int)
create table #t2(
name varchar(20) collate Chinese_PRC_CI_AI_WS,
value int )
表建好后,执行连接查询:
select * from #t1 A inner join #t2 B on =
这样,错误就出现了:
服务器: 消息 446,级别 16,状态 9,行 1
无法解决 equal to 操作的排序规则冲突。
要排除这个错误,最简单方法是,表连接时指定它的排序规则,这样错误就
不再出现了。
语句这样写:
select *
from #t1 A inner join #t2 B
on = collate Chinese_PRC_CI_AI_WS
二.排序规则简介:
什么叫排序规则呢?MS是这样描述的:"在 Microsoft SQL Server 2000 中,
字符串的物理存储由排序规则控制。
排序规则指定表示每个字符的位模式以及存
储和比较字符所使用的规则。
"
在查询分析器内执行下面语句,可以得到SQL SERVER支持的所有排序规则。
select * from ::fn_helpcollations()
排序规则名称由两部份构成,前半部份是指本排序规则所支持的字符集。
如:
Chinese_PRC_CS_AI_WS
前半部份:指UNICODE字符集,Chinese_PRC_指针对大陆简体字UNICODE的排序规则。
排序规则的后半部份即后缀含义:
_BIN 二进制排序
_CI(CS) 是否区分大小写,CI不区分,CS区分
_AI(AS) 是否区分重音,AI不区分,AS区分
_KI(KS) 是否区分假名类型,KI不区分,KS区分
_WI(WS) 是否区分宽度WI不区分,WS区分
区分大小写:如果想让比较将大写字母和小写字母视为不等,请选择该选项。
区分重音:如果想让比较将重音和非重音字母视为不等,请选择该选项。
如果选择该选项,比较还将重音不同的字母视为不等。
区分假名:如果想让比较将片假名和平假名日语音节视为不等,请选择该选项。
区分宽度:如果想让比较将半角字符和全角字符视为不等,请选择该选项
三.排序规则的应用:
SQL SERVER提供了大量的WINDOWS和SQLSERVER专用的排序规则,但它的应用
往往
被开发人员所忽略。
其实它在实践中大有用处。
例1:让表NAME列的内容按拼音排序:
create table #t(id int,name varchar(20))
insert #t select 1,'中'
union all select 2,'国'
union all select 3,'人'
union all select 4,'阿'
select * from #t order by name collate Chinese_PRC_CS_AS_KS_WS
drop table #t
/*结果:
id name
----------- --------------------
4 阿
2 国
3 人
1 中
*/
例2:让表NAME列的内容按姓氏笔划排序:
create table #t(id int,name varchar(20))
insert #t select 1,'三'
union all select 2,'乙'
union all select 3,'二'
union all select 4,'一'
union all select 5,'十'
select * from #t order by name collate Chinese_PRC_Stroke_CS_AS_KS_WS drop table #t
/*结果:
id name
----------- --------------------
4 一
2 乙
3 二
5 十
1 三
*/
四.在实践中排序规则应用的扩展
SQL SERVER汉字排序规则可以按拼音、笔划等排序,那么我们如何利用这种功能
来处理汉字的一些难题呢?我现在举个例子:
用排序规则的特性计算汉字笔划
要计算汉字笔划,我们得先做准备工作,我们知道,WINDOWS多国汉字,UNICODE 目前
收录汉字共20902个。
简体GBK码汉字UNICODE值从19968开始。
首先,我们先用SQLSERVER方法得到所有汉字,不用字典,我们简单利用SQL语句就
可以得到:
select top 20902 code=identity(int,19968,1) into #t from syscolumns a,syscolumns b
再用以下语句,我们就得到所有汉字,它是按UNICODE值排序的:
select code,nchar(code) as CNWord from #t
然后,我们用SELECT语句,让它按笔划排序。
select code,nchar(code) as CNWord
from #t
order by nchar(code) collate Chinese_PRC_Stroke_CS_AS_KS_WS,code
结果:
code CNWord
----------- ------
19968 一
20008 丨
20022 丶
20031 丿
20032 乀
20033 乁
20057 乙
20058 乚
20059 乛
20101 亅
19969 丁
..........
从上面的结果,我们可以清楚的看到,一笔的汉字,code是从19968到20101,从小到大排,但到
了二笔汉字的第一个字“丁”,CODE为19969,就不按顺序而重新开始了。
有了这结果,我
们就可以轻
松的用SQL语句得到每种笔划汉字归类的第一个或最后一个汉字。
下面用语句得到最后一个汉字:
create table #t1(id int identity,code int,cnword nvarchar(2))
insert #t1(code,cnword)
select code,nchar(code) as CNWord from #t
order by nchar(code) collate Chinese_PRC_Stroke_CS_AS_KS_WS,code
select word
from #t1 A
left join #t1 B on A.id=B.id-1 and A.code<B.code
where B.code is null
order by A.id
得到36个汉字,每个汉字都是每种笔划数按Chinese_PRC_Stroke_CS_AS_KS_WS排序规则排序后的
最后一个汉字:
亅阝马风龙齐龟齿鸩龀龛龂龆龈龊龍龠龎龐龑龡龢龝齹龣龥齈龞麷鸞麣龖龗齾齉龘
上面可以看出:“亅”是所有一笔汉字排序后的最后一个字,“阝”是所有二笔汉字排序后的最后
一个字......等等。
但同时也发现,从第33个汉字“龗(33笔)”后面的笔划有些乱,不正确。
但没关系,比“龗”笔划
多的只有四个汉字,我们手工加上:齾35笔,齉36笔,靐39笔,龘64笔
建汉字笔划表(TAB_HZBH):
create table tab_hzbh(id int identity,cnword nchar(1))
--先插入前33个汉字
insert tab_hzbh
select top 33 word
from #t1 A
left join #t1 B on A.id=B.id-1 and。