sql_server_2005_数据同步文档
SQL Server2005数据库复制实现同步备份(技术文档)
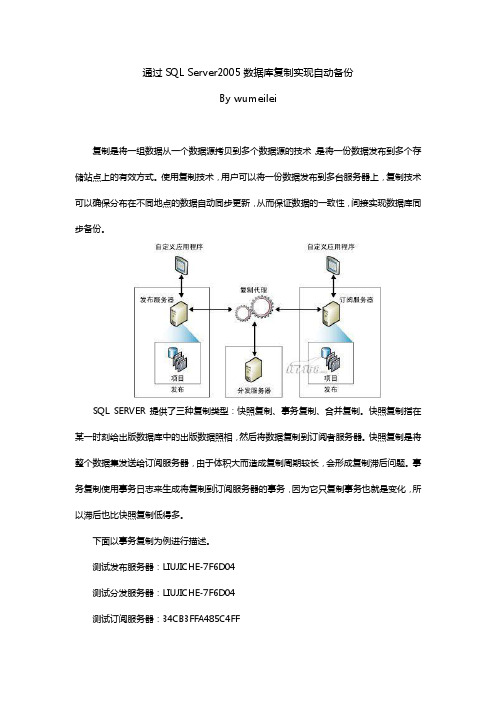
通过SQL Server2005数据库复制实现自动备份By wumeilei复制是将一组数据从一个数据源拷贝到多个数据源的技术,是将一份数据发布到多个存储站点上的有效方式。
使用复制技术,用户可以将一份数据发布到多台服务器上,复制技术可以确保分布在不同地点的数据自动同步更新,从而保证数据的一致性,间接实现数据库同步备份。
SQL SERVER提供了三种复制类型:快照复制、事务复制、合并复制。
快照复制指在某一时刻给出版数据库中的出版数据照相,然后将数据复制到订阅者服务器。
快照复制是将整个数据集发送给订阅服务器,由于体积大而造成复制周期较长,会形成复制滞后问题。
事务复制使用事务日志来生成将复制到订阅服务器的事务,因为它只复制事务也就是变化,所以滞后也比快照复制低得多。
下面以事务复制为例进行描述。
测试发布服务器:LIUJICHE-7F6D04测试分发服务器:LIUJICHE-7F6D04测试订阅服务器:34CB3FFA485C4FF一、建立发布(在LIUJICHE-7F6D04机器操作)在发布前请确保SQL SERVER代理已经启动、发布数据库的日志是完整模式。
以SA用户登录发布服务器SQL Server。
在左侧树结构中找到【复制】——>【本地发布】节点,点击右键,选择【新建发布】,如下图:弹出如下窗口:点击【下一步】,选择需要复制的数据库,如“acctrue_T_Code”:点击【下一步】,选择“事务性发布”:点击【下一步】,选择需要复制的数据库表,如“CodeContentItem”点击【下一步】,不需要筛选:点击【下一步】,选择“立即创建快照并使快照保持可用状态,以初始化订阅”和“计划在以下时间运行快照代理”。
然后点击【更改】按钮,调整复制时间计划,根据需要进行定义,此次以1分钟间隔为例。
更改后如下图:点击【下一步】:点击【安全设置】按钮,按照下图所示进行选择:设置完成后如下图:点击【下一步】:点击【下一步】,输入发布名称,如“abc”:点击【完成】按钮,系统将创建发布,提示成功后创建发布完成。
将SQLServer2005中的数据同步到Oracle中

将SQLServer2005中的数据同步到Oracle中有时由于项⽬开发的需要,必须将SQLServer2005中的某些表同步到Oracle数据库中,由其他其他系统来读取这些数据。
不同数据库类型之间的数据同步我们可以使⽤链接服务器和SQLAgent来实现。
假设我们这边(SQLServer2005)有⼀个合同管理系统,其中有表contract 和contract_project是需要同步到⼀个MIS系统中的(Oracle9i)那么,我们可以按照以下⼏步实现数据库的同步。
1.在Oracle中建⽴对应的contract 和 contract_project表,需要同步哪些字段我们就建那些字段到Oracle表中。
这⾥需要注意的是Oracle的数据类型和SQLServer的数据类型是不⼀样的,那么他们之间是什么样的关系拉?我们可以在SQLServer下运⾏:SELECT *FROM msdb.dbo.MSdatatype_mappingsSELECT *FROM msdb.dbo.sysdatatypemappings来查看SQLServer和其他数据库系统的数据类型对应关系。
第⼀个SQL语句是看SQL转Oracle的类型对应,⽽第⼆个表则更详细得显⽰了各个数据库系统的类型对应。
根据第⼀个表和我们的SQLServer中的字段类型我们就可以建⽴好Oracle表了。
ORACLE bigint NUMBER 19 3 1ORACLE binary BLOB NULL 0 1ORACLE binary RAW -1 4 1ORACLE bit NUMBER 1 3 1ORACLE char CHAR -1 4 1ORACLE char CLOB NULL 0 1ORACLE char VARCHAR2 -1 4 1ORACLE datetime DATE NULL 0 1ORACLE decimal NUMBER -1 3 1ORACLE double precision FLOAT NULL 0 1ORACLE float FLOAT NULL 0 1ORACLE image BLOB NULL 0 1ORACLE int NUMBER 10 3 1ORACLE money NUMBER 19 3 1ORACLE nchar NCHAR -1 4 1ORACLE nchar NCLOB NULL 0 1ORACLE ntext NCLOB NULL 0 1ORACLE numeric NUMBER -1 3 1ORACLE nvarchar NCLOB NULL 0 1ORACLE nvarchar NVARCHAR2 -1 4 1ORACLE nvarchar(max) NCLOB NULL 0 1ORACLE real REAL NULL 0 1ORACLE smalldatetime DATE NULL 0 1ORACLE smallint NUMBER 5 3 1ORACLE smallmoney NUMBER 10 3 1ORACLE sysname NVARCHAR2 128 4 1ORACLE text CLOB NULL 0 1ORACLE timestamp RAW 8 4 1ORACLE tinyint NUMBER 3 3 1ORACLE uniqueidentifier CHAR 38 4 1ORACLE varbinary BLOB NULL 0 1ORACLE varbinary RAW -1 4 1ORACLE varbinary(max) BLOB NULL 0 1ORACLE varchar CLOB NULL 0 1ORACLE varchar VARCHAR2 -1 4 1ORACLE varchar(max) CLOB NULL 0 1ORACLE xml NCLOB NULL 0 1ORACLE bigint NUMBER 19 3 1ORACLE binary BLOB NULL 0 1ORACLE binary RAW -1 4 1ORACLE bit NUMBER 1 3 1ORACLE char CHAR -1 4 1ORACLE char CLOB NULL 0 1ORACLE char VARCHAR2 -1 4 1ORACLE datetime DATE NULL 0 1ORACLE decimal NUMBER -1 3 1ORACLE double precision FLOAT NULL 0 1ORACLE float FLOAT NULL 0 1ORACLE image BLOB NULL 0 1ORACLE int NUMBER 10 3 1ORACLE money NUMBER 19 3 1ORACLE nchar CHAR -1 4 1ORACLE nchar CLOB NULL 0 1ORACLE ntext CLOB NULL 0 1ORACLE numeric NUMBER -1 3 1ORACLE nvarchar CLOB NULL 0 1ORACLE nvarchar VARCHAR2 -1 4 1ORACLE nvarchar(max) CLOB NULL 0 1ORACLE real REAL NULL 0 1ORACLE smalldatetime DATE NULL 0 1ORACLE smallint NUMBER 5 3 1ORACLE smallmoney NUMBER 10 3 1ORACLE sysname VARCHAR2 128 4 1ORACLE text CLOB NULL 0 1ORACLE timestamp RAW 8 4 1ORACLE tinyint NUMBER 3 3 1ORACLE uniqueidentifier CHAR 38 4 1ORACLE varbinary BLOB NULL 0 1ORACLE varbinary RAW -1 4 1ORACLE varbinary(max) BLOB NULL 0 1ORACLE varchar CLOB NULL 0 1ORACLE varchar VARCHAR2 -1 4 1ORACLE varchar(max) CLOB NULL 0 1ORACLE xml CLOB NULL 0 1ORACLE bigint NUMBER 19 3 1ORACLE binary BLOB NULL 0 1ORACLE binary RAW -1 4 1ORACLE bit NUMBER 1 3 1ORACLE char CHAR -1 4 1ORACLE char CLOB NULL 0 1ORACLE char VARCHAR2 -1 4 1ORACLE datetime DATE NULL 0 1ORACLE decimal NUMBER -1 3 1ORACLE double precision FLOAT NULL 0 1ORACLE float FLOAT NULL 0 1ORACLE image BLOB NULL 0 1ORACLE int NUMBER 10 3 1ORACLE money NUMBER 19 3 1ORACLE nchar NCHAR -1 4 1ORACLE nchar NCLOB NULL 0 1ORACLE ntext NCLOB NULL 0 1ORACLE numeric NUMBER -1 3 1ORACLE nvarchar NCLOB NULL 0 1ORACLE nvarchar NVARCHAR2 -1 4 1ORACLE nvarchar(max) NCLOB NULL 0 1ORACLE real REAL NULL 0 1ORACLE smalldatetime DATE NULL 0 1ORACLE smallint NUMBER 5 3 1ORACLE smallmoney NUMBER 10 3 1ORACLE sysname NVARCHAR2 128 4 1ORACLE text CLOB NULL 0 1ORACLE timestamp RAW 8 4 1ORACLE tinyint NUMBER 3 3 1ORACLE uniqueidentifier CHAR 38 4 1ORACLE varbinary BLOB NULL 0 1ORACLE varbinary RAW -1 4 1ORACLE varbinary(max) BLOB NULL 0 1ORACLE varchar CLOB NULL 0 1ORACLE varchar VARCHAR2 -1 4 1ORACLE varchar(max) CLOB NULL 0 1ORACLE xml NCLOB NULL 0 12.建⽴链接服务器。
SQL server 2005备份异地数据库到本地计算机

SQL server 2005备份异地数据库到本地计算机目标:把服务器上的数据库备份到另一台计算机上,保证数据库服务器的硬盘空间。
具体操作:第一步:建立共享文件夹,赋予读/写权限:A、手动方式:选择文件夹→右键→共享(因为win7和XP、2003等区别较大,所以不截图演示了)。
B、DOS命令:Net share 共享名称=盘符路径注意:如果路径中有空格,必须使用双引号(””)包括路径。
第二步:在sql server2005中建立映射(服务器上,要备份的库中):1、检查服务器上sql server2005的xp_cmdshell是否启动:第一、开始→所有程序→Microsoft SQL Server 2005 →配置工具→SQL server外围应用配置器第二、选择功能的外围应用配置器第三、选择xp_cmdshell→应用→确定2、建立映射:master..xp_cmdshell'net use \\目标机器名称或IP\共享文件名目标机器登录密码 /user:目标机器登录名'第三步:执行备份A、执行sql语句:backup database 数据库名to disk=’\\目标机器名称或IP\共享文件名\…….bak’B、执行批处理自动备份:1、将如下语句复制到文本文件中:osql -S 连接字符串名称-U sa -P 密码-Q "BACKUP DATABASE 库名TO DISK= '\\目标机器名称或IP\共享文件名\db_%date:~0,10%.bak' WITH FORMAT"2、将文本文件保存成.bat的批处理文件。
3、添加windows任务计划,编辑执行频率。
基于SQL Server 2005煤矿考勤系统中的数据同步复制

童 斜技 茬
21年 期 01 第1
基 于 S LSre 2 0 Q evr 0 5煤 矿 考 勤 系统 中 的数 据 同步 复 制
李方迪
( 东煤 炭技 术 研 究所 , 东 济 南 山 山 2o 3 ) 5o 1
摘
要
文章介绍 了S evr QLS r 的同步复制技术 , e 利用这种技术可以满足许多部 门对数据的 同步共 享 的需求 , 同时方便 了数据 的安全备份并
一
数据库存储复制状 态数 据和 有关发 布 的元数 据 , 并且 在某些情况下为从发布服务器 向订阅服务器移动 的数 据起着排 队的作 用 。在很 多情况 下 , 一个 数据库 服务 器实 际充 当发布服务器和分发服务器两个角色 。这称 为“ 本地分发 服务 器 ” 。订 阅服务 器是 接收 复制数 据 的数据库。一个订 阅服务器可 以从多个 发布服务器和 发布接收数据。 13 复制类 型 . 复制有三种类 型 : 事务复制 、 照复制、 并复制。 快 合 事务复制是将复制启用后 的所有发布服务器上 发布的 内容在修改时传给 订 阅服 务器 , 数据 更改将 按照其 在 发布服务器上发生 的顺序和事务边界应用于订 阅服务 器, 在发布 内部 可 以保 证事 务 的一致 性 。快 照复制将 数据 以特定时刻 的 瞬时状态 分发 , 不监视对 数据 的 而 更新 。发生 同步 时 , 将生成 完整 的快 照并 将其发 送到 订阅服务器 。合并复制通常是从发布数据库对象和数 据的快 照开始 , 且用触 发器跟 踪在发 布服务 器和订 并 阅服务器上所做的后续数据更 改和架构修改 。订 阅服 务器在连接到 网络 时将 与发 布服务器 进行 同步 , 交 并 换 自上次 同步以来发布服务器和订阅服务器之间发生 更改 的所有行。
SQL2005数据库同步复制操作

1.1.1S QL SERVER2005一、同步前的准备:本文档适应于在SQL Server 2005下通过发布订阅,将LeagView主服务器的UniMonDB 数据库同步到LeagView备份服务器上的UniMonDB上。
图中主测试服务器IP地址为10.251.4.9,备份测试服务器IP地址为10.251.4.10。
在配置同步前需要注意:(1)确认备份服务器SQL Server Agent是否运行,如没运行,则先启动运行;(2)需要在计算机管理里面建立用于数据库发布订阅的账号,或者使用Administrator账号。
(3)该方案并不取代数据库备份方案,建议用户配置数据库备份方案,定期备份数据库。
(4)备份服务器上的LeagView系统只需运行“Jboss”服务,“LeagView安全运维服务”不需要启动(5)本文档只适应于SQL Server 2005,操作前请先仔细阅读此文档。
二、发布:(1)在主LeagView服务器上打开Microsoft SQL Server 2005 Management stadio,展开实例号,右键点击“复制—本地订阅”,选择“新建发布”,如图2.1。
出现如图2.2所示界面,点击“下一步”。
图2.1 新建发布图2.2新建发布向导选择数据库服务器作为分发服务器,在此,选择LeagView主服务器所在的数据库服务器作为分发服务器。
如图2.3所示。
图2.3 选择分发服务器(2)选择快照文件夹,一般选择默认文件夹就行,如图2.4所示。
图2.4 选择快照文件夹(3)选择发布的数据库为UniMonDB,如图2.5所示。
图2.5选择发布数据库(4)选择发布类型为“快照发布”,如图2.6所示。
图2.6 发布类型为快照发布(5)选择要发布的对象,在此选择“表和视图”。
如图2.7所示。
图2.7 选择发布的对象(6)点击下一步,直到出现如图2.8所示界面中,勾选“计划在以下时间运行快照代理”和点击“更改”,配置作业计划属性,一般情况下,设定作业在每周星期六00:00更新一次发布过程,如图2.9所示。
SQL SERVER数据同步方案

基于sql server的订阅和分布功能中的对等事务复制,实现数据实时双向同步。
当用户在数据库上修改数据时,相应的修改会实时显示在公司的数据库上;当开发人员在公司的的数据库中修改数据时,相应的修改在用户的数据库中也会实时显示。
分别以公司服务器上的SQL server2005作为A数据库,sql server 2012作为B数据库,作为测试数据库;通过配置对等事务复制,创建一个由A数据库和B数据库两个节点组成的拓扑,实现数据库的实时同步。
1、首先,在SQL server2005实例中创建TEST数据库,里面包含[dbo].[test_data]表,作为测试数据使用,如图所示:2、确保A、B数据库两个节点都在运行SQL SERVER代理,确保在配置拓扑后运行日志读取器代理和分发代理。
3、在A、B数据库上配置分发4、在第一个节点上创建发布(以A数据库作为第一个节点)4.1展开“复制”文件夹,右键单击“本地发布”文件夹4.2单击“新建发布”4.3在新建发布向导的“发布数据库”页上,选择要发布的数据库(选择TEST数据库)4.4在“发布类型”页上,选择“事务发布”4.5在“项目”页上,选择要发布的数据库对象(选择dbo.test_date)4.6 筛选表行不做配置,直接通过(不支持筛选对等发布)4.7在“快照代理”页上,清除“立即创建快照”(我的理解是快照代理不做配置)4.8在“代理安全性”页上,指定快照代理和日志读取器代理的凭据(点击安全设置按钮,在快照代理安全性中,选择在SQL SERVER代理服务账户下运行、使用以下SQL SERVER 登录名)配置完如下所示4.9在“向导操作”页上,根据需要,可以选择为发布编写脚本4.10在“完成该向导”页上,指定发布的名称(发布名称在整个拓扑上必须相同,原因是配置对等拓扑向导在每个节点上创建发布时使用此名称)指定好发布名称之后,点击确定,就生成了一个发布,相应的会出现在复制文件下的本地发布5 为对等复制启用发布5.1 展开本地发布文件夹5.2右键单击创建的发布,再单击“属性”5.3在“发布属性”对话框中的“订阅选项”页上,为“允许对等订阅”属性选择True 值6、初始化每个节点的架构和数据(备份A实例中TEST数据库,在B实例中还原)在配置拓扑之前,每个节点上必须存在初始数据。
郝斌老师 sql server 2005数据库大纲
数据库学习大纲什么是数据库狭义:存储数据的仓库广义:可以对数据进行存储和管理的软件以及数据本身统称为数据库数据库是由表、关系、操作组成为什么需要数据库几乎所有的应用软件的后台都需要数据库数据库存储数据占用空间小容易持久保存存储比较安全容易维护和升级数据库移植比较容易简化对数据的操作为将来学习Oracle做准备B/S架构里面包含数据库数据库的安装和卸载sg12000解决挂起的问题sq12005参见视频预各知识学习数据库必须的学习数据库原理么我的视频中会讲一些数据库原理的知识学习SglServer 2005必须的先学一门编程语言么不需要,但是懂一门编程语言的话会有助于学SQLServer 2005的TL-SQL数据结构和数据库的区别数据库是在应用软件级别研究数据的存储和操作数据结构是在系统软件级别研究数据的存储和操作什么是连接【重点】有了编程语言为什么还需耍数据库对内存数据操作是编程语言的强项,但是对硬盘数据操作却是编程语言的弱项对硬盘数据操作是数据库的强项,是数据库研究的核心问题建议初学者从三个方面学习数据库1 数据库是如何存储数据的字段记录表约束(主键外键唯一键非空check default 触发器)2 数据库是如何操作数据的insert update delete T-SQL 存储过程函数触发器3 数据库是如何显示数据的Select (重点的重点)必备的一些操作如何建数据库如何删除数据库如何附加和分离数据库设置登录用户名和密码如何创建用户数据库是如何解决数据存储问题的【最基础内容,必须掌握】1.表的相关数据字段一个事物的某一个特征记录字段的组合表示的是一个具体的事物表记录的组合表示的是同一类型事物的集合表和字段、记录的关系字段是事物的属性记录是事物本身表是事物的集合列字段的另一种称谓属性字段的另一种称谓元组记录的另一种称谓2. create table命令通过图形化界面建表create table最后一个字段的后面建议不要写逗号说明:简单掌握后面我们会再详细的介绍3.什么是约束定义对一个表中属性操作的限制叫做约束分类主键约束不允许重复元素避免了数据的冗余外键约束通过外键约束从语法上保证了本事物所关联的其他事物一定是存在的事物和事物之间的关系是通过外键来体现的check约束保证事物属性的取值在合法的范围之内default约束保证事物的属性一定会有一个值唯一约束保证了事物属性的取值不允许重复,但允许其中有一列且只能有一列为空问题:unique键是否允许多列为空?答案:SqlServer2005只允许一个unique列为空Oracle11G允许多个unique列为空not null要求用户必须的为该属性斌一个值,否则语法出错!如果一个字段不写null 也不写not null则默认是null即默认允许用户可以不给该字段斌值如果用户没有为该字段赋值,则该字段的值默认是null要注意null和default的区别相同点:都允许用户不赋值不同点:null修饰的字段如果用户不赋值则默认是nulldefault修饰的字段如果用户不斌值则默认是default指定的那个值4.表和约束的异同数据库是通过表来解决事物的存储问题的数据库是通过约束来解决事物取值的有效性和合法性的问题建表的过程就是指定事物属性及其事物属性各种约束的过程5.什么是关系定义: 表和表之间的联系实现方式通过设置不同形式的外键来体现表和表的不同关系分类(假设是A表和B表)一对一既可以把表A的主键充当表B的外键也可以把表B的主键充当表A的外键一对多【重点】把表A的主键充当表B的外键或者讲:把A表的主键添加到B表来充当B表的外键外键添加原则:在多的一方添加外键多对多多对多必须的通过单独的一张表来表示例子班级和教师班级是一张表教师是一张表班级和教师的关系也是一张表6.主键定义:能够唯一标示一个事物的一个字段或者多个字段的组合主键的特点【重点】含有主键的表叫做主键表主键通常都是整数不建议使用字符串当主键(如果主键是用于集群式服务,才可以考虑用字符串当主键)主键的值通常都不允许修改,除非本记录被删除主键不要定义成id,而要定义成表名id或者表名_id要用代理主键,不要用业务主键任何一张表,强烈建议不要使用有业务含义的字段充当主键我们通常都是在表中单独添加一个整型的编号充当主键字段主键是否连续增长不是十分重要7.外键定义:如果一个表中的若干个字段是来自另外若千个表的主键或唯一键则这若干个字段就是外键注意:外键通常是来自另外表的主键而不是唯一键,因为唯一键可能为null 外键不一定是来自另外的表,也可能来自本表的主键含有外键的表叫外建表,外键字段来自的那一张表叫做主键表问题:先删主键表还是外建表? 答案:先删外建表如果先删主键表,会报错,因为这会导致外建表中的数据引用失败查询【最重要难度最大,强烈建议所有的学生都要熟练掌握查询的内容】1.计算列select * from emp; ---*表示所有的from表示从emp表查询select ename , sal from emp;select ename, sal, sal * 12 as "年薪" from emp;-------as可省略select 888 from emp;----ok,输出行数是emp行数,值是888select 5;----ok,一行,值是5注意:在oracle中字段的别名不允许被单引号括起来但是在sql2005中允许,因此为了兼容性最好字段别名用双引号括起来2.distinct【不允许重复的】select distinct deptno from emp;----会过滤重复的deptnoselect distinct comm from emp;---会过滤掉重复的null,或者所:有多个null,最终也只会输出一个select distinct deptno, comm from emp;---对deptno和comm组合进行过滤select deptno, distinct comm from emp;---error 逻辑上有冲突3.between 【在某个范围】----查找工资在1500到3000之间(包括和)的所有员工信息select * from empwhere sal >=1500 and sal <=3000等价于select * from empwhere sal between 1500 and 3000;>---查找工资小于1500或者大于3000之间的所有员工信息select * from empwhere sal not between 1500 and 3000;4. inselect * from emp where sal in (1500, 3000, 5000)等价于Select * from empwhere sal=1500 or sal=3000 or sal=5000select * from emp where sal not in (1500, 3000,5000)一把sal不是也不是也不是的记录输出等价于select*from empwhere sal<>1500 and sal<>3000 and sal<>5000一数据库中不等于有两种表示:!二<> 推荐使用第二种一对或取反是并且对并且取反是或5. top【最前面的若干个记录专属于Sql的语法,不可移植】select top 5 * from emp;select top 15 percent * from emp;一输出的是3个,不是2个select top 5 from emp;-error分页查询后面会讲6. null 【没有值空值】零和null是不一样的,null表示空值,没有值,零表示一个确定的值null不能参与如下运算: < > != =null可以参与如下运算:is not isselect * from emp where comm is null;一输出奖金为空的员工的信息select * from emp where comet is not null:一输出奖金不为空的信息select * from emp where comm < > null;--输出为空errorselect * from emp where comm != null;-偏出为空errorselect * from emp where come = null:一输出为空error任何类型的数据都允许为nullcreate table tl (name nvarchar(20),cnt int, riqi datetime);insert into tl values (null, null, null);---OK任何数字与null参与数学运算的结果永远是null一输出每个员工的姓名年薪(包含了奖金) comm假设是一年的奖金Select empno, ename, sal*12 + comm "年薪" from emp;一本程序证明了:null不能参与任何数据运算否则结果永远为空一正确的写法是:select ename, sal*12+isnull(comm, 0)"年薪" from emp;---isnull (comm, 0)含意思:如果comm是null 就返回零否则返回comm的值7. order by【以某个字段排序】order by a, b --a和b都是升序order by a, b des -a升序b降序order by a desc, b -a降序b升序order by a desc, b desc 一a和b都是降序文字描述:如果不指定排序的标准,则默认是升序升序:asc 默认可以不写为一个字段指定的排序标准并不会对另一个字段产生影响强烈建议为每一个字段都指定排序的标准例子:---asc是升序的意思默认可以不写desc是降序select * from emp order by sal ;一默认是按照升序排序select * from emp order by deptno, sal;一先按照deptno升序排序,如果deptno相同,再按照sal升序排序Select * from emp order by deptno desc, sal;一先按deptno降序排序如果deptno相同,再按照sal升序排序(是升序不是降序)--order by a desc, b, c, d desc只对a产生影响不会对后面的b c d 产生影响select * from emp order by deptno, sal desc一问题:desc是否会对deptno产生影响?一答案:不会,先按deptno升序,如果deptno相同,再按sal降序8.模糊查询【搜索时经常使用】格式:select 字段的集合from 表名where 某个字段的名字like 匹配的条件匹配的条件通常含有通配符通配符:%表示任意0个或多个字符select * from emp where ename like '%A%' --ename只要含有字母A就输出select * from emp where ename like 'A%' --ename只要首字母是A的就输出select * from emp where ename like '%A' --ename只要尾字母是A的就输出_ [这是下划线不是减号]表示任意单个字符select *from emp where ename like '_A%' -ename只要第二个字母是A的就输出[a-f]a到f中的任意单个字符只能是a b c d e f中的任意一个字符select * from emp where ename like '_[A-F]%'一把ename中第二个字符是A或B或C或D或E或F的记录输出[a, f]a或f[^a-c]不是a也不是b也不是c的任意单个字符例子:select * from emp where ename like '_["A-F]%'一把ename中第二个字符不是A也不是B也不是C 也不是D也不是E也不是F的记录输出注意:匹配的条件必须的用单引号括起来不能省略也不能改用双引号通配符作为不同字符使用的问题预备操作create table student (name varchar(20) null,age int)insert into student values('张三',88);insert into student values('Tom',66);insert into student values('a_b',22);insert into student values('c%d',44);insert into student values('abces fe',56);insert into student values('c%',66);insert into student values('long''S',100)select * from student;select * from student where name like '%\%%' escape '\';---把name中含有%的输出select * from student where name like '%\_%' escape '\';----把name中含有_的输出;9.聚合函数【多行记录返回至一个值通常用于统计分组的信息】函数的分类单行函数每一行返回一个值多行函数多行返回一个值聚合函数是多行函数例子:select lower(ename) from emp;一最终返回的是行lower()是单行函数select max(sal) from emp;一返回行max()是多行函数聚合函数的分类max0min()avg ()平均值count ()求个数1 count(*)返回表中所有的记录的个数select count(*) from emp;一返回emp表所有记录的个数2 count(字段名)返回字段值非空的记录的个数,重复的记录也会被当做有效的记录select count(deptno) from emp;一返回值是14 这说明deptno重复的记录也被当做有效的记录select count(comm) from emp;一返回值是这说明comm为null的记录不会被当做有效的记录3 count(distinct 字段名)返回字段不重复并且非空的记录的个数select count(distinct deptno) from emp;----返回值是3,说明统计的是deptno不重复的记录个数注意的问题判断如下sql语句是否正确select max(sal), min(sal), count(*) from emp; -okselect max (sal) "最高工资", min(sal)"最低工资",count (*)"员工人数" from emp; -okselect max(sal), lower(ename) from emp; -error单行函数和多行函数不能混用select max(sal) from emP; -ok默认把所有的信息当做一组10. group by【分组难点】格式:group by 字段的集合功能:把表中的记录按照字段分成不同的组例子查询不同部门的平均工资select deptno, avg(sal) as "部门平均工资,from emp group by deptno 注意理解: group by a, b,c的用法先按a分组,如果a相同,再按b分组,如果b相同,再按c分组,最终统计的是最小分组的信息一定要明白下列语句为什么是错误的select deptno, avg(sal) as"部门平均工资", enamefrom empgroup by deptnoselect deptno,enamefrom empgroup by deptnoselect deptno,job, salfrom empgroup by deptno, job记住:使用了group by 之后select中只能出现分组后的整体信息,不能出现组内的详细信息11. having【对分组之后的信息进行过滤难点】1.having子句是用来对分组之后的数据进行过滤因此使用having时通常都会先使用group by2.如果没使用group by但使用了having则意味着having把所有的记录当做一组来进行过滤极少用select count(*)from emphaving avg(sal)>10003.having子句出现的字段必须的是分组之后的组的整体信息having子句不允许出现组内的详细信息4.尽管select字段中可以出现别名但是having子句中不能出现字段的别名,只能使用字段最原始的名字5.having和where的异同相同的:都是对数据过滤,只保留有效的数据where和having一样,都不允许出现字段的别名,只允许出现最原始的字段的名字,此结论在SQL和Oracle都成立不同:where是对原始的记录过滤having是对分组之后的记录过滤where必须的写在having的前面,顺序不可顺倒否则运行出错例子:----统计输出部门平均工资大的部门的部门编号和部门的平均工资select deptno, avg(sal) "平均工资",count (*)"部门人数",max(sal) as "部门的最高工资"from empwhere sal>2000 --where是对原始的记录过滤group by deptnohaving avg(sal)>3000 --一对分组之后的记录过一判断入选语句是否正确select deptno, avg(sal)"平均工资",count (*)"部门人数",max(sal)"部门的最高工资"from empgroup by deptnohaving avg(sal)>300。
SQL Server数据同步
公司有一台很重要SQL数据库,如何实现数据库实时同步?一、客户需求客户现在有一个需求,公司有一台很重要SQL数据库,怕有一天服务器或者系统崩溃,导致所有SQL数据库数据丢失,客户想把数据库数据,通过某种方式将数库进行实时同步到另外一台服务器上,这样可以做个backup。
那客户这个需求如何实现呢?二、解决方案:通过分析与研究,使用的是SQL自带的发布与订阅功能,旧的SQL Server版本是2008,新安装一个SQL Server 2014版本,通过旧SQL Serer发布,再通过SQL Server2014订阅,来同步数据库数据。
三、实现过程3.1、发布发布前准备:首先两个服务器之间要能相互通讯,也就是能ping命令能通。
平时我们连接数据库时,经常都是用的ip登陆,但是发布的时候不能这样,必须用服务器名称。
如果在不同网段的两台数据库服务器,可以在两台服务器hosts文件中添加对应的IP地址和主机名。
在旧服务器上,打开SQL Server数据库软件,进行发布SQL数据库。
1、旧服务器上,找到复制--本地发布,右击新建发布。
2、选择需要发布的数据库名称。
3、选择事务发布。
4、在此数据库中,查看表,是否都可以正常的被发布,如下图所示,有些表无法正常发布,那该怎么办?5、发现是由于这些表中没有主键,需要给这三张表设置主键。
6、设置主键。
8、发现还有一个表无法发布。
9、查看原因。
10、需要将此表中的,阻止保存要求重新创建表的更改项勾选去掉。
11、去掉后,发现此表可以正常设置主键。
12、可以看到所有的表都可以正常发布了。
13、下一步。
14、选择添加。
15、选择立即创建快照并使快照保持可用状态,以初始化订阅。
16、选择安全设置。
17、输入数据库的sa用户名和密码。
18、选择下一步。
这时要注意,需要将数据库的代理服务开启,和SQL browser服务开启。
19、创建发布。
20、新建一个发布名称。
21、发布成功。
SQLServer数据同步
SQLServer数据同步
由于各信息系统的建设时期不同,架构也是千差万别,数据存储⽅案也各不相同,那么打破信息孤岛,实现数据同步互通是迫切的需求。
常见的有
SQL Server与Oracle之间的数据同步,SQL Server与MySQL之间的数据同步。
下⾯简单介绍使⽤TreeDMS实现SQL Server与MySQL之间的数据同步。
1、安装TreeDMS后,登录系统并配置数据库连接信息,测试连接成功!
2、输⼊查询SQL命令,查询需同步的数据,并确认来源表、⽬标表字段等信息。
这⼀步不是必须的,只是为了查询数据,并验证SQL语句。
3、配置【数据同步】任务,配置来源、⽬标信息,配置调度计划规则。
调度计划使⽤cron表达式,⽀持任务定时循环执⾏。
这是⼀种轻量级的⽅案,简单灵活,两边表名、字段名都可以不同。
可以在查询SQL语句中使⽤聚合函数,实现统计数据的同步。
4、数据同步中的【执⾏动作】规则说明
【新增】仅新增数据,速度快
【更新】仅更新数据,按约束条件更新
【覆盖】存在就更新,不存在就新增
5、执⾏⼀次,测试数据同步效果,查看同步⽇志。
6、选择正确的⽬标库,通过SQL查询命令,查看⽬标表数据,确认同步效果。
sqlserver数据同步
sqlserver数据同步SQLSERVER数据同步之数据复制复制是一组技术,它将数据和数据库对象从一个数据库复制和分发到另一个数据库,然后在数据库间进行同步,以维持一致性。
使用复制,可以在局域网和广域网、拨号连接、无线连接和Internet 上将数据分发到不同位置以及分发给远程或移动用户。
事务复制通常用于需要高吞吐量的服务器到服务器方案(包括:提高伸缩性和可用性、数据仓库和报告、集成多个站点的数据、集成异类数据以及减轻批处理的负荷)。
合并复制主要是为可能存在数据冲突的移动应用程序或分步式服务器应用程序设计的。
常见应用场景包括:与移动用户交换数据、POS(消费者销售点)应用程序以及集成来自多个站点的数据。
快照复制用于为事务复制和合并复制提供初始数据集;在适合数据完全刷新时也可以使用快照复制。
利用这三种复制,SQL Server 提供功能强大且灵活的系统,以便使企业范围的数据同步。
环境拓扑安装下配置步骤:一、在两台服务器上安装好SQL Server 2008 R2,主要安装的组件:Database Engine(含SQLServer Replication),Management Tools,并且启动Sql Server 代理(发布服务器和订阅服务器均设置)二、主数据库服务器(发布服务器)的配置1.设置存放快照的文件夹2.创建发布之前,先设置一下存放快照的文件夹,创建发布后会在该文件夹生成快照文件,订阅服务器需要在初始化时加载该快照文件。
3.选择Replication》Local Publications》属性,在出现的窗口中选择Publishers,如下图:点击红框处的按钮,出现设置窗口:在Default Snapshot Folder中设置快照文件存放路径。
4.在主数据库服务器创建发布:在Replication》Local Publications中选择New Publication,出现一个向导。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一. 加入域(发布方必须, 订阅方非必须).1.在DC中使用DCPROMO命令创建域:因为目前还没有AD(活动目录),现在是在AD中创建第一个域,所以此项应选择"新域的域控制器":选择"新林中的第一个域":输入域名(不能重名):设置NET BIOS名,为了像WIN98这样的操作系统能够访问此域:选择AD数据库和日志文件的存放位置:存放SYSVOL的存放位置(注意:一定要放在NTFS的分区中哦):注意:AD是离不开DNS服务的,因为客户机加入域和登录域都需要把域名解析为IP地址,这一过程都需要DNS服务器的支持,所以域是离不开DNS的,但反过来是不对的!因为此时DC没有DNS服务器,所以选择第二项让系统在创建DC的同时把DNS服务随之一起安装上.当然你也可以安装DC后自己手动再安装和配置DNS服务器(当时是您给会正确配置D NS服务器),不过我还是建议和DC一起让系统帮我们创建,因为省事并不会因为手动错误的配置DNS带来的麻烦.选择兼容的模式:设置AD的还原密码(为了以后对AD数据库做完备份,开机按F8进入AD还原模式需要的还原密码,如果在此设置了密码,一定切记):2.安装完重起系统后登录界面为: 使用域中的管理员和密码登录到域进入系统后查看计算机的状态:查看管理工具会增加DNS和有关AD的工具,以及安全策略:查看NTDS的文件:查看SYSVOL:3.在DC中创建域帐户:首先大家习惯还像在工作组时使用"本地用户和组"工具来创建用户帐户,但发现在DC中没有"本地用户和组",这是因为提升为DC后就没有本地用户和组了,原来的帐户和组都提升为域帐户和域中的组了.所以我们使用DC中的"AD用户和组"工具来创建域帐户,但首先我们先在域中创建一个管理单元(OU),OU可以使用部分来划分,所以我们先来创建一个名为"学术部"的OU,再在该OU中创建一个属于学术部的用户zhangsan,密码:abc123,(为什么要设置这样的密码呢?能否设置空密码呢?不好意思,因为默认的域安全策略的密码策略是这样设置的,长度7位以上,复杂度要开启,复杂度是大/小写字母,数字和特殊符号在密码设置中至少存在其中3种.那能否修改该策略呢,当时是可以的,不过在此我们不做太多的解释,以后有时间在做专门的专题讲解^-^)4.那么要把另一台计算机加入到域了,首先让客户机的IP如图所示: IP和DC的IP地址同一个网段,DNS地址指向DC的IP地址即可首先使用客户机看是否能够PING通DC:选择计算机-属性,修改计算机所属于的域的名字输入刚才创建的域名:出现对话框,输入在AD中创建的域帐号即可,但普通的域帐户只能允许10个客户端加入域,在此输入域管理员和密码:正确后会弹出以下对话框,代表已经加入域成功:需要重起生效:客户机重起后选择登录到域,再输入域帐户和密码就能登录到域了:进入系统和查看计算机的当前状态如下:实验完毕!以下实现复制步骤(以快照复制为例)运行平台SQL SERVER 2005一、准备工作:1.建立一个 WINDOWS 用户,设置为管理员权限,并设置密码,作为发布快照文件的有效访问用户。
2.在SQL SERVER下实现发布服务器和订阅服务器的通信正常(即可以互访)。
打开1433端口,在防火墙中设特例3.在发布服务器上建立一个共享目录,作为发布快照文件的存放目录。
例如:在D盘根目录下建文件夹名为SqlCopy (此用户的访问权限最好是系统用户administrator)4.设置SQL 代理(发布服务器和订阅服务器均设置)打开服务(控制面板---管理工具---服务)---右击SQLSERVER AGENT---属性---登录---选择“此帐户“---输入或选择第一步中创建的WINDOWS 用户(最好是administrator)---“密码“中输入该用户密码5.设置SQL SERVER 身份验证,解决连接时的权限问题(发布、订阅服务器均设置)步骤为:对象资源管理器----右击SQL实例-----属性----安全性----服务器身份验证------选“SQL Server和WINDOWS“,然后点确定6.开启SQL Server 2005的网络协议TCP/IP和管道命名协议并重启网络服务。
7.在SQL Server中创建步骤1中对应的系统用户登陆名,作为发布数据库的拥有者(设置为dbo_owner 和public)。
8.以系统超级用户sa登陆SQL Server建立数据库和表。
9.发布服务器和订阅服务器互相注册步骤如下:视图----单击以注册服务器----右键数据库引擎----新建服务器注册-----填写要注册的远程服务器名称------身份验证选“SQL Server验证“-----用户名(sa) 密码------创建组(也可不建)-----完成。
10.对于只能用IP,不能用计算机名的,为其注册服务器别名设置别名是在SQL Server Configuration Manager 中sql native client 设置中点击别名右键新建,别名项输入对方的数据库服务器名称,端口为对方的数据库端口,服务器项输入对方的ip,协议项输入tcp/ip,确定之后重启服务。
如下图:二、开始:发布服务器配置(在发布服务器上配置发布和订阅)1.选择复制节点2.右键本地发布 ----下一步---------系统弹出对话框看提示----直到“指定快照文件夹“----在“快照文件夹“中输入准备工作中创建的目录(指向步骤3所建的共享文件夹)------选择发布数据库-------选择发布类型-------选择订阅服务器类型-------选择要发布的对象------设置快照代理-------填写发布名称。
本篇文章发表于(小新技术网)3.右键本地订阅--------选择发布服务器-------选择订阅方式(如果是在服务器方订阅的话选择推送订阅反之选择请求订阅)-------填加订阅服务器--------选择代理计划(一般选择连续运行)---------其余选择默认项。
MSDTC(分布式交易协调器),协调跨多个数据库、消息队列、文件系统等资源管理器的事务。
该服务的进程名为Msdtc.exe,该进程调用系统Microsoft Personal Web Server和Microsoft SQL Server。
该服务用于管理多个服务器 .位置:控制面板--管理工具--服务--Distributed Transaction Coordinator依存关系:Remote Procedure Call(RPC)和Security Accounts Manager建议:一般家用计算机涉及不到,除非你启用Message Queuing服务,可以停止。
解决办法: 1. 在windows控制面版-->管理工具-->服务-->Distributed Transaction Coordinator-->属性-->启动2.在CMD下运行"net start msdtc"开启服务后正常。
注:如果在第1步Distributed Transaction Coordinator 无法启动,则是因为丢失了日志文件,重新创建日志文件,再启动就行了。
重新创建 MSDTC 日志,并重新启动服务的步骤如下:(1) 单击"开始",单击"运行",输入 cmd 后按"确定"。
(2) 输入:msdtc -resetlog (注意运行此命令时,不要执行挂起的事务)(3) 最后输入:net start msdtc 回车,搞定!一、问题现象在执行分布式事务时,在sql server 2005下收到如下错误:消息7391,级别 16,状态 2,过程xxxxx,第16 行无法执行该操作,因为链接服务器"xxxxx" 的OLE DB 访问接口"SQLNCLI" 无法启动分布式事务。
在sql server 2000下收到如下错误:该操作未能执行,因为OLE DB 提供程序'SQLOLEDB' 无法启动分布式事务。
[OLE/DB provider returned message: 新事务不能登记到指定的事务处理器中。
]OLE DB 错误跟踪[OLE/DB Provider 'SQLOLEDB' ITransactionJ oin::JoinTransaction returned 0x8004d00a]。
二、解决方案1. 双方启动MSDTC服务MSDTC服务提供分布式事务服务,如果要在数据库中使用分布式事务,必须在参与的双方服务器启动MSDTC(Distributed Transaction Coordinator)服务。
2. 打开双方135端口MSDTC服务依赖于RPC(Remote Procedure Call (RPC))服务,RPC使用135端口,保证RPC服务启动,如果服务器有防火墙,保证135端口不被防火墙挡住。
使用“telnet IP 135 ”命令测试对方端口是否对外开放。
也可用端口扫描软件(比如Advanced Port Scanner)扫描端口以判断端口是否开放。
3. 保证链接服务器中语句没有访问发起事务服务器的操作在发起事务的服务器执行链接服务器上的查询、视图或存储过程中含有访问发起事务服务器的操作,这样的操作叫做环回(loopback),是不被支持的,所以要保证在链接服务器中不存在此类操作。
4. 在事务开始前加入set xact_abort ON语句对于大多数OLE DB 提供程序(包括SQL Server),必须将隐式或显示事务中的数据修改语句中的XACT_ABORT 设置为ON。
唯一不需要该选项的情况是在提供程序支持嵌套事务时。
5. MSDTC设置打开“管理工具――组件服务”,以此打开“组件服务――计算机”,在“我的电脑”上点击右键。
在MSDTC 选项卡中,点击“安全配置”按钮。
在安全配置窗口中做如下设置:l选中“网络DTC访问”l在客户端管理中选中“允许远程客户端”“允许远程管理”l在事务管理通讯中选“允许入站”“允许出站”“不要求进行验证”l保证DTC登陆账户为:NT Authority\NetworkService6. 链接服务器和名称解析问题建立链接sql server服务器,通常有两种情况:l第一种情况,产品选”sql server”EXEC sp_addlinkedserver@server='linkServerName',@srvproduct = N'SQL Server'这种情况,@server (linkServerName)就是要链接的sqlserver服务器名或者ip地址。