张继东社会科学与自然科学学术语篇中介入型式的对比研究共38页
社会科学为什么要找因果机制 - 《公共行政评论》

统计定律 ' T' ( ' ) & ' ) * ( + Y ( , & (
资料来源 ) 9 1 2 51 + ' #H@D ( / 转引自 T( + 2 4 ' #HHC ) ?"A ( "
然而 ! 不管何种形式 ! 覆盖律解释观的核心都是规律和论证 ! 其示意图如下 * 解释项) 普适 ' 或统计( 定律 ==被解释项) 待解释的现象 ' 或规律( 特定现象或事实 由此可见! 从解释项到被解释项的过程! 必须是一个演绎推理的过程# 现代科 学的许多解释 , 尤其是物理学- 都符合亨普尔所描述的形式* 在普适定律和一些附 加事实面前! 一种现象不得不发生# 例如! 苹果落地这一现象可以由牛顿的万有引 力定律和一些附加假定经过演绎推导出来# 不得不承认! 这种模型为经验科学中的 解释程序提供了一个系统的逻辑分析基础和统一的方法论基础! 也就是将解释还原 为形式化的逻辑论证#
表 #= 覆盖律解释模型的形式 解释项 特定事实 ' E ( . ' ) * 7+ ( . \ ( * ' & ( 定律 ===== 普适定律 '^ 4) 0 1 . & ( + Y ( , & ( OB W 演绎 #律则 'O 1 /7* ' ) 0 1 ` W 2 + 6 ) * ( + ( ; B T 归纳 #统计 '; 4/7* ' ) 0 1 ` T' ( ' ) & ' ) * ( + ( OB W 演绎 #律则 'O 1 /7* ' ) 0 1 ` W 2 + 6 ) * ( + ( OB T 演绎 #统计 'O 1 /7* ' ) 0 1 ` T' ( ' ) & ' ) * ( + ( 普遍规律 ' U 1 41 . ( + S 1 6 7+ ( . ) ' ) 1 & (
2012年度江苏省社科基金立项项目名单
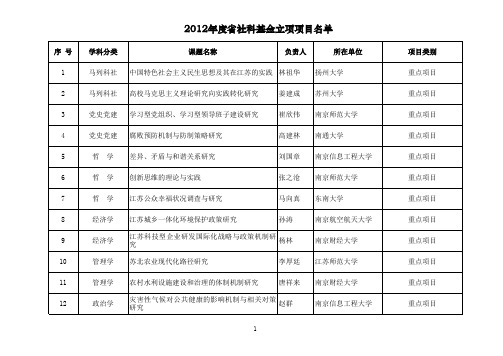
新闻传播、图 书情报、档案 江苏数字出版业发展研究 学 新闻传播、图 书情报、档案 数字环境下图书馆生态与服务变革研究 学 新闻传播、图 书情报、档案 社会情绪的网络扩散及其应对研究 学
8
2012年度省社科基金立项项目名单
105 106 107 108 109 110 111 112 113 114 115 116 117 新闻传播、图 袁庆东 书情报、档案 公共图书馆行政法人化可行性研究 学 新闻传播、图 书情报、档案 江苏政府职能部门电子政务能力提升路径研究 胡广伟 学 新闻传播、图 书情报、档案 微博裂变式传播对舆论引导作用研究 学 教育学 苏绣人才的专业能力及其发展研究 教育学 教育学 教育学 教育学 教育学 教育学 教育学 艺术学 艺术学 江苏文化产业人才培养体系研究 江苏高校拔尖创新人才培养问题研究 在苏藏族学生跨文化适应研究 民国时期学位与研究生教育发展研究 民国教育行政体制研究 骆冬松 杨翠蓉 赵国乾 崔海涛 冉苒 岳爱武 刘建 江苏师范大学 南京大学 南京理工大学 苏州科技学院 南京晓庄学院 南京理工大学 江苏技术师范学院 南京信息工程大学 南京师范大学 苏州大学 南京大学 苏州科技学院 南京师范大学 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目
7
2012年度省社科基金立项项目名单
92 93 94 95 96 97 98 99 100 101 102 103 104 外国文学 外国文学 语言学 语言学 语言学 语言学 语言学 语言学 语言学 语言学 基于理雅各《尚书》译注的翻译伦理研究 陆振慧 扬州大学 南京师范大学 江苏师范大学 南京农业大学 东南大学 苏州大学 南京师范大学 东南大学 南京财经大学 淮阴师范学院 南京师范大学 东南大学 江苏师范大学 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目 一般项目
2015年河南省教育厅人文社科成果奖-获奖名单

— 2 —
2015—c—t030
《十日谈》 和 ‚三言‛ ‚二拍‛ 之比较 研究
外国文学 外国文学
著作 论文 论文 论文 著作 论文 论文 论文 论文 论文 论文 著作 著作 论文 著作 著作 论文
付江涛 河南大学 侯林梅 河南师范大学 张霁月 河南大学 崔青峰 郑州大学 徐欢颜 河南理工大学 孟轲 杜静 河南师范大学 河南大学
王颢霖 河南师范大学 任宝玉 河南财经政法大学 陶玉霞 河南师范大学 曹玉涛 洛阳师范学院 韩启振 许昌学院 沙德春 河南农业大学 魏明侠 河南工业大学 熊伟 张燚 许昌学院 河南理工大学
2015—c—t017 生态文明建设的技术批判与重构 2015—c—t018 现代汉语让步条件句认知研究 2015—c—t019 科技园区转型升级研究 2015—c—t020 网上信用风险的演化: 一个探索性分析 框架
钱泳宏 郑州轻工业学院 展龙 河南大学
魏华莹 郑州大学 寇东亮 郑州大学 宋妍萍 郑州师范学院 肖伟韬 河南理工大学 崔志胜 河南大学
— 1 —
2015—c—t013
判断框架对时序知觉位置启动效应的 影响
心理学 体育学 政治学 管理学 哲学 语言学 管理学 管理学 历史学 艺术学 经济学 经济学 图书情报文献学
孔国庆 河南师范大学 张胜利 河南大学 高慧铭 郑州大学 刘文武 河南大学 惠萍 河南大学
刘志伟 郑州大学 刘旭旺 河南大学 冯文贺 河南科技学院 赵宁 河南师范大学
丁志伟 河南大学
— 3 —
2015—c—研究
管理学 教育学 管理学 管理学 教育学 管理学 教育学 法学 管理学
杨玉珍 河南师范大学 李新安 河南财经政法大学 温芳芳 河南科技大学 楚行军 华北水利水电大学 周强 肖帅 岳磊 信阳师范学院 河南大学 郑州大学
“七选五”解题教学:从语篇结构入手

&
学科教育"!"
Copyright©博看网. All Rights Reserved.
三%从语篇的微观结构入手"抓住解题 能共同出现&比如"OFMON 和OJSG"AJL 和
线索
VDKS"ADV和Q?FSS等常常同时出现&
引导学生从语篇的微观结构入手"把握 如果把语篇比作一串珍珠项链"衔接就
句与句之间的逻辑关系%句子内部的衔接"可 是用合适的方法把一颗颗珍珠串起来&教师
生从以下两个方面找出段落的关联机制一 $ OIKMFDP I[MIPM ARM TNIP FSSDQ FONDIUIG"
是引导学生找出设空的段落主旨再提炼前 "
JAMFDPIG"FPGAJRVNM"MNIKIOJ?IQFMD?I
一段%后一段的主旨"结合篇章主旨"判定各 XJKMNIMKRIQIPQIJXNFHHDPIQQ,
FKI,!/#!
导学生辨别语篇类型绘制结构图这有助
于学生依据语篇特定的结构判断语篇各部 "3FONXFOMSIFKPIGIFONQWDSSFOYRDKIG
分信息的基本功能先后顺序和分布方式 QNJRSG NFUI F HRKHJQI, ZI QNJRSG PJM
学生在掌握常见的语篇结构基础上能够在 MNIKIXJKITFQMIJRKMD?ISIFKPDPVXFOMQAL
清提出自己的主张最后阐述理由一 现语篇第"#两段提出了作者对信息记
般个别型又称为概括具体型其内 忆的看法第$%两段指出了因特网出现
部结构通常包括概括陈述具体陈述和总结 给信息记忆带来的新变化第&'两段指
学术会议论文摘要的介入资源研究——以ISFC40中国学者论文摘要为例

然而,迄今为止,大量研究 都锁定在文献综述 、结果 、 讨 论甚至结 束语等部 分 。对摘 要部 分的人际 资源虽有所 分 析 ,但深 度不够 。学术会议论文摘要 ,不同于在公开学术刊 物 上所发表 的学术论 文的摘 要,没有 刊物所规 定的格 式可 循 ,而是 由作者完全根据学术直觉撰 写而成 ,反应 了作者急 于得到学术界接纳和认可的强烈愿望 。因此 ,对学术会议论
以通过语言选择来进行评价 ,表明自己的态度 ,构建人际意 义,与读者结盟 ,体现作 者和读者之间的互动 。 学 术语 篇 的研 究 备 受重 视 。国 外 的相 关研 究肇 始 于
S wa l e s ( 1 9 9 0 d e w( 2 0 0 2 ) ,
的事实 ( H y l a n d , 2 0 0 0 , 2 0 0 5 , 2 0 1 0; T h o mp s o n ,2 0 0 1 )。作
能 语言学会 议 ( 简称 I S F C 4 0 )选取 由中国学者撰 写的十篇
会议论文英文摘要作为语料 ,通过 分析其介入资源的使用情 况 ,透析作 者一读者之间的人际互动和社会关系 。
文摘要进行 分析研 究 ,更加 有助于揭 示一 个学科领域 内的
收稿 日期:2 0 1 5 . 0 2 . 1 8 基金 项 目:本 文为教 育部 社科 基金 项 目 “ 英语 学术语 篇 的合 理 性 建构 手段 研 究”
(1 1 YJ A7 4 O 0 8 8)的 部 分 成 果 。
以I S F C 4 0中国学者论 文摘要 为例
王全智 刘 文姣
( 暨南 大 学 ・ 广州 ・ 5 1 0 6 3 2 )
内容 提要 :本 文通 过对 I s F C 4 0中 国学者 的英文摘 要 中介入 资源进 行分析 ,揭 示摘要 作 者在 构 建读者 联盟 的过 程 所做 的语 言选 择 。分析 显 示 ,在 利用 介入 资 源实现人 际互动 的过程 中,摘要作 者 更偏 重 于扩展
基于相关熵诱导度量的近端策略优化算法

第41卷 第3期吉林大学学报(信息科学版)Vol.41 No.32023年5月Journal of Jilin University (Information Science Edition)May 2023文章编号:1671⁃5896(2023)03⁃0437⁃07基于相关熵诱导度量的近端策略优化算法收稿日期:2022⁃05⁃14基金项目:黑龙江省自然科学基金资助项目(F2018004)作者简介:张会珍(1979 ),女,天津人,东北石油大学副教授,硕士生导师,主要从事复杂系统的鲁棒控制研究,(Tel)86⁃454⁃6504062(E⁃mail)zhuizhen2002@㊂张会珍,王 强(东北石油大学电气信息工程学院,黑龙江大庆163318)摘要:在深度强化学习算法中,近端策略优化算法PPO(Proximal Policy Optimization)在许多实验任务中表现优异,但具有自适应KL(Kullback⁃Leibler)散度的KL⁃PPO 由于其不对称性而影响了KL⁃PPO 策略更新效率,为此,提出了一种基于相关熵诱导度量的近端策略优化算法CIM⁃PPO (Correntropy Induced Metric⁃PPO)㊂该算法具有对称性更适合表征新旧策略的差异,能准确地进行策略更新,进而改善不对称性带来的影响㊂通过OpenAI gym 实验测试表明,相比于主流近端策略优化算法Clip⁃PPO 和KL⁃PPO 算法均能获得高于50%以上的奖励,收敛速度在不同环境均有500~1100回合左右的加快,同时也具有良好的鲁棒性㊂关键词:KL 散度;近端策略优化(PPO);相关熵诱导度量(CIM);替代目标;深度强化学习中图分类号:TP273文献标志码:A Proximal Policy Optimization Algorithm Based on Correntropy Induced MetricZHANG Huizhen,WANG Qiang(School of Electrical and Informatioin Engineering,Northeast Pertroleum University,Daqing 163318,China)Abstract :In the deep Reinforcement Learning,the PPO (Proximal Policy Optimization)performs very well in many experimental tasks.However,KL(Kullback⁃Leibler)⁃PPO with adaptive KL divergence affects the update efficiency of KL⁃PPO strategy because of its asymmetry.In order to solve the negative impact of this asymmetry,Proximal Policy Optimization algorithm based on CIM(Correntropy Induced Metric)is proposed characterize the difference between the old and new strategies,update the policies more accurately,and then the experimental test of OpenAI gym shows that compared with the mainstream near end strategy optimization algorithms clip PPO and KL PPO,the proposed algorithm can obtain more than 50%reward,and the convergence speed is accelerated by about 500~1100episodes in different environments.And it also has good robustness.Key words :kullback⁃leibler(KL)divergence;proximal policy optimization(PPO);correntropy induced metric (CIM);alternative target;deep reinforcement learning 0 引 言近端策略优化是一种无模型的深度强化学习[1]算法,由于其适应能力强,现已成为OpenAI [2]测试深度强化学习性能的默认基础算法,并因其在OpenAI gym 测试平台良好表现,成为近年来最流行的强化学习(RL:Reinforcement Learning)算法之一㊂同时吸引了众多学者对其进行研究[3]㊂PPO(Proximal Policy Optimization)算法有两种形式:一种是使用Clip 剪辑函数,即Clip⁃PPO 算法,该方法首次由Vanvuchelen 等[4]在近端策略优化(PPO 与剪辑)中使用;另一种是具有自适应惩罚系数的KL(Kullback⁃Leibler)散度的PPO,即KL⁃PPO [5]㊂具有自适应散度的KL⁃PPO 存在策略更新不稳定和收敛速度慢及随着输入状态维数增加而导致鲁棒性变差的问题㊂为加快收敛速率,别桐等[6]在KL⁃PPO 算法中加入了一种新设计的奖励函数,其对智能体的每步动作都给予一个立即的奖励,其目的是使智能体在这种立即的奖励下能迅速学习更可靠的动作,提升算法训练时的收敛速度㊂申怡等[7]在算法中添加了同步更新的经验池,保存采样的优秀样本经验,并利用该经验池[8]学习到的动作策略网络对动作进行快速选择,这不仅提高了样本利用率,还保证在训练网络模型时智能体能快速有效地学习㊂目前对KL⁃PPO 算法的研究在其收敛速率方面均有显著提高,但该算法还存在KL 散度不对称㊁不满足度量属性等问题,从而导致策略更新不稳定以及高维状态鲁棒性差的问题㊂关于描述两数据特征之间的相似性问题,Chen 等[9]提出了一种称为相关熵(Correntropy)的相似度量㊂李辉等[10]利用相关熵研究齿轮故障特征取得了一定进展,这表明相关熵和数据特征间研究是有意义的㊂为了将相关熵扩展到度量的指标,Liu 等[11]进一步提出了相关熵诱导度量,其优势在于CIM(Correntropy Induced Metric)可以满足度量的属性,并且更适合描述不同概率分布之间的相似性㊂笔者将相关熵诱导度量引入KL⁃PPO 算法中,解决散度不对称所带来的缺陷㊂其将原有的KL⁃PPO 中的KL 散度用相关熵诱导度量替代,用以表征新旧策略的差异,从根本上解决KL 散度不对称性导致的收敛速度慢和鲁棒性差的问题;相关熵诱导度量设置相对容易计算的核函数,改善原算法存在大量散度复杂运算的问题㊂1 近端策略优化算法近端策略优化算法PPO 是一种基于演员⁃评论家(Actor⁃Critic)架构的强化学习算法[12],其不仅有良好的性能(尤其是对连续控制问题),同时相较于前置的强化学习方法更加易于实现㊂笔者针对Actor 网络的策略更新中,KL 散度限制更新步长会产生不稳定问题,对策略更新的优化目标函数进行一定的改进㊂1.1 近端策略优化算法框架如图1所示,近端策略优化算法在前置框架中加入了重要性采样[13]机制复用历史数据,提高了样本利用率,同时限制了Actor 网络中采样[14]和训练网络的分布差异,并采用自适应散度形式的KL⁃PPO,通过KL 散度限制了更新策略中的步长,以确保其更新稳定性㊂近端策略优化算法中的网络结构分为演员(Actor)和评论家(Critic)模块㊂演员模块Actor网络的更图1 近端策略优化算法Fig.1 Proximal policy optimization 新采用策略梯度(Policy Gradient)方式,同时Actor网络在每次进行策略更新时,需要将其参数拷贝到旧Actor 网络中进行存储㊂KL⁃PPO 的核心是在Actor 网络更新目标函数中,用KL 散度表征新旧策略的差异并且作为更新目标中的惩罚项㊂Actor 网络输出动作策略与环境交互,得到奖励R 和状态S ,并将这些信息存储于经验池中;评论家模块Critic 网络主要采用时序差分误差(TD⁃error:Temporal Differenceerror)的方式更新,其主要目的是评估Actor 网络中策略的价值㊂自适应散度KL⁃PPO 算法中Actor 网络策略更新的优化目标函数为L KL (θ)=maximize θ^E t πθ(a t s t )πθold (a t s t )^A -βK L [πθ(a t s t ),πθold (a t s t éëêêùûúú)],(1)其中πθ为随机策略,πθ(a t s t )πθold (a t s t )为重要性权重,^A 为优势价值函数,^E t 为t 时刻采样求均值,β为自适应系数,K L [πθ(a t s t ),πθold (a t s t )]为新旧策略之间的散度㊂散度大标志着新旧策略差距比较大,即更新的步长较大,式(1)中表示减去的这项作为较大的惩罚,最后的期望奖励会变小;反之,散度小新旧策略834吉林大学学报(信息科学版)第41卷差别小,更新步长较小,减去的这项作为较小的惩罚㊂为更加平稳地更新,加入自适应系数β,如果KL 散度变大,则系数β将在下一次迭代中减小;如果KL 散度变小,则系数β将在下一次迭代中加大㊂从而使惩罚在迭代中趋于平稳,每轮更新的步长将会得到很好的控制㊂1.2 KL⁃PPO 算法的缺陷近端策略优化是对代理目标的优化,目的是使代理目标L π(含有π策略的奖励函数)最大化,以确保折扣奖励最后可以趋于最大值㊂然而,该算法也存在一些问题,在自适应散度KL⁃PPO 中引入自适应惩罚因子β将导致更新效率较低㊂同时为避免每次策略更新时的波动,引入KL 散度作为约束,使其更新相对平稳㊂从统计学的角度看,KL 散度[15]是在新空间定义的两个数据之间相似性的函数㊂然而,KL 散度其本质上不是一个度量,因其是一个非对称函数,不满足度量的对称性㊂同时,KL 散度的不对称,也不服从度量的三角形不等式性,在正态分布的情况下,这种不对称性会随着均值μ和方差σ的不同而增加㊂综上分析,自适应KL 散度形式的KL⁃PPO 算法在近端策略优化中的具体缺陷总结如下㊂1)KL 散度具有不对称性,其容易将策略更新到其他策略而不是拥有较大奖励E [^Aπ]的最优策略,降低了更新效率,特别是在离散的作用空间,这种不良影响会更大㊂同时当维数增加时,不对称的影响也会愈发增大,即具有高维空间的不稳定性㊂2)KL⁃PPO 算法内部网络更新存在计算复杂度过高的问题㊂因为KL 散度计算形式本身较为复杂,这表明在更新的每步中,都必须重新计算KL 散度㊂求解过程中散度的复杂计算,严重影响算法的收敛速度㊂自适应KL 散度KL⁃PPO 中引入了新的惩罚因子β,实际训练时很难确定β值,这都会影响训练的稳定性㊂2 基于相关熵诱导度量的近端策略优化算法笔者对度量定理进行分析,并引入对概率分布计算的相关熵理论,同时引入相关熵诱导度量,然后将其应用于近端策略优化算法中进行改善,解决KL 散度由于不对称导致的策略更新不稳定以及鲁棒性差的问题㊂2.1 相关熵及相关熵诱导度量对两个随机变量x 和y 之间的相关熵(广义相关函数)定义为V σ(x ,y )=E [κσ(x -y )],(2)其中E 为期望,κ(㊃)为满足Mercer 条件的核函数,σ为核函数的核长㊂相关熵的性质随核函数的变化而变化,一个好的核函数会得到很好的结果㊂相关熵[16]本质也不是一个合理的度量指标,因为当x =y 时,V σ(x ,y )≠0,不满足正定性㊂为将相关熵扩展到度量指标,Liu 等[17]提出了相关熵诱导度量(CIM,d CIM ),如下:d CIM (x ,y )=(V σ(0)-V σ(x ,y ))1/2㊂(3) 显然,相关熵诱导度量具有如下特性:1)相关熵诱导度量是正定的,可以有界㊂而KL 散度是无界的㊂2)相关熵诱导度量满足对称性㊂对任何种类的核函数,相关熵诱导度量都满足三角不等式,即d CIM σ(x ,y )≤d CIM σ(x ,z )+d CIM σ(z ,y )㊂2.2 基于相关熵诱导度量的近端策略优化算法笔者将讨论如何通过引入广义相关熵改进KL⁃PPO 算法,以解决其KL 散度不对称带来的缺陷㊂相关熵诱导度量是一个度量,与无界的KL 散度相比,相关熵诱导度量总是有界的,而且比KL 散度更加平稳㊂相关熵诱导度量具有优异的鲁棒性,特别是在两个概率分布距离的评估中㊂其不仅可以处理高斯934第3期张会珍,等:基于相关熵诱导度量的近端策略优化算法噪声的分布,还可以处理非高斯噪声的分布㊂近端策略优化中的策略是一个概率分布,而KL 散度是对不同分布度量,相关熵诱导度量也是如此㊂然而,KL 散度的不对称性和重计算使策略优化方法的性能较差㊂因此,笔者在自适应散度KL⁃PPO 中使用相关熵机制代替自适应散度参数调整机制,将相关熵诱导度量代替自适应KL 散度,以此作为衡量新策略与旧策略之间距离的指标㊂为消除不对称惩罚的影响,避免KL⁃PPO 中对散度进行大量的复杂计算,在相关熵内部选择了相对容易计算的核函数三角核函数min 1-‖x -y ‖σ,{}0㊂对KL⁃PPO 中自适应参数β,因为相关熵诱导度量具有足够的鲁棒性,不用引入每次迭代都需要自我调整的自适应参数β,将其改为一个基于任务的常数α并默认设置为1㊂如果当前任务不希望在每次更新中新策略和旧策略之间的差异太大,则将α设置较大的数如2以上,加大惩罚项的影响㊂如果当前任务允许两个策略在一定范围内有差异,则将α设置较小的数如0.5以下,减少惩罚项的影响㊂然后利用随机梯度下降(SGD:Stochastic Gradient Descent)[18]优化策略㊂综上所述,笔者在描述新旧策略差异的KL 散度部分进行了改进,并提出了基于相关熵诱导度量的近端策略优化算法(CIM⁃PPO):L CIM (θ)=maximize θ^E t πθ(a t s t )πθold (a t s t )^A -αd CIM σ[πθ(a t s t ),πθold (a t s t éëêêùûúú)]㊂(4) 与自适应散度的KL⁃PPO 相比,CIM⁃PPO 在优化目标函数中使用相关熵诱导度量作为替代目标函数的惩罚㊂相关熵诱导度量的引入,解决了自适应KL 散度形式的KL⁃PPO 算法在近端策略优化中的的几个缺陷:1)相关熵诱导度量选择对称核函数后,可以是一个度量,从本质上解决了KL 散度不对称性在KL⁃PPO 中策略更新时容易波动及鲁棒性差的缺陷;2)相关熵诱导度量可以选择相对容易计算的核函数,避免了KL 形式计算复杂度过高的问题,从而大大地弥补了KL⁃PPO 训练速度过慢的问题㊂由于相关熵诱导度量具有对称性和足够的鲁棒性,不需要在CIM⁃PPO 中加入自适应调整机制,解决了KL⁃PPO 中在训练时难以找到自适应惩罚因子β的问题㊂CIM⁃PPO 算法伪代码如下:1)初始化π02)根据任务,选择惩罚控制参数α3)选择其是估计σ还是设置默认为14)for i =0,1,2, 直到收敛5) 通过小批量随机梯度下降SGD 优化后续的估计:6) 设置σ=1或通过Mercer 定律估计^σ7) 计算d CIM ^σ(πi ,π)=(V σ(0)-V σ(πi ,π))1/28) πi +1=arg max πE πiππi ^A -αd CIM ^σ(πi ,π[])9) π=πi +110)end for 3 仿 真通过设计实验比较笔者改进的算法CIM⁃PPO 与主流PPO 算法Clip⁃PPO 和KL⁃PPO 之间的效率㊂采用OpenAI 开发的gym 作为基本实验环境,并且从中选择4个基本的连续任务Pendulum⁃v0(倒立摆)(见图2)㊁LunarLanderContinuous⁃v2(月球着陆器连续版)(见图3)㊁BipedalWalker⁃v3(双足机器人)(见图4)和BipedalWalkerHardcore⁃v3(双足机器人硬核版)(见图5)㊂其中CIM⁃PPO㊁KL⁃PPO 和Clip⁃PPO 的相关参数设置如表2所示㊂044吉林大学学报(信息科学版)第41卷 图2 倒立摆环境图 图3 月球着陆器连续版环境图 Fig.2 Pendulum⁃v0 Fig.3 Lunar lander continuous⁃v2 图4 双足机器人环境图 图5 双足机器人硬核版环境图 Fig.4 Bipedal walker⁃v3 Fig.5 Bipedal walker hardcore⁃v3以上4个任务中,动作空间的维度从1增加到4,相应的状态空间从3增加到24,每个任务环境的具体动作和状态空间维度如表1所示㊂这些任务在构建策略过程中的正态分布方差在0.1~1之间,这使KL 散度的不对称性变得明显㊂从而证实了笔者上述分析得出的随着维数的增加,KL 散度的不对称性就会更加明显,自适应散度KL⁃PPO 算法的性能就会下降的结论㊂表1 实验任务相关信息Tab.1 Experimental task related information任务名称动作空间维度状态空间维度Pendulum⁃v0(倒立摆)13LunarLanderContinuous⁃v2(月球着陆器连续版)28BipedalWalker⁃v3(双足机器人)424BipedalWalkerHardcore⁃v3(双足机器人硬核版)424 为评估CIM⁃PPO 的性能,笔者分析了4个任务在训练过程中回合数与获得的回合奖励回报之间的关系,给出了CIM⁃PPO㊁Clip⁃PPO㊁KL⁃PPO 3种算法的学习曲线㊂3种算法的实验参数设置如表2所示,学习曲线如图6a ~图6d 所示㊂表2 实验参数设置回合数,纵坐标为累计奖励回报值㊂累计奖励回报值越高表示强化学习任务完成的效果越好,反之表示学习效果越差㊂学习曲线趋于平稳且不再有剧烈波动,表示智能体最终学习到了执行该任务的能力,到达平稳状态训练的回合数为收敛时间,回合数越少,则训练的越快,算法收敛越快,反之则收敛越慢㊂144第3期张会珍,等:基于相关熵诱导度量的近端策略优化算法图6 算法在不同任务实验中累计奖励回报与训练回合数的实验结果Fig.6 Experimental results of cumulative reward and training rounds of the algorithm in different task experiments图6a ~图6d 表明,在学习速率方面,CIM⁃PPO 至少可以达到与Clip⁃PPO 相同的效果,有时优于Clip⁃PPO,但总会优于KL⁃PPO㊂在倒立摆任务中,最初,所有3种算法都可以达到几乎相同的效果,但KL⁃PPO 在大约1200回合左右时崩溃,Clip⁃PPO 趋于稳定,尽管CIM⁃PPO 波动在一个范围内,但其最终奖励回报值仍然高于Clip⁃PPO㊂在连续任务中,Clip⁃PPO 和KL⁃PPO 都经历了奖励回报值迅速飙升然后又骤降到原始奖励回报值的过程,但CIM⁃PPO 的奖励回报值增加后仍能保持在一个较高的水平,这表明CIM⁃PPO 具有良好的鲁棒性㊂改进算法在后两个任务中表现相对更好㊂从图6c 和图6d 可看到,改进算法的奖励回报值随着训练次数的增加而稳步上升,最后达到其稳定极限㊂4 结 语笔者基于KL⁃PPO 算法,研究了KL⁃PPO 中KL 散度的不对称性及其对鲁棒性和学习效率的影响㊂随着策略维度的增加,KL 散度不对称性带来的影响会增大㊂笔者在KL⁃PPO 中引入了相关熵,并使用相关熵诱导度量CIM 替代衡量旧策略与新策略之间差异的KL 散度㊂实验结果表明,改进后的CIM⁃PPO 算法在训练过程中的学习速率以及训练后的奖励回报值和鲁棒性均有显著提高㊂参考文献:[1]秦智慧,李宁,刘晓彤,等.无模型强化学习研究综述[J].计算机科学,2021,48(3):180⁃187.QIN Z H,LI N,LIU X T,et al.A Review of Model Free Reinforcement Learning [J].Computer Science,2021,48(3):180⁃187.[2]FINNIE⁃ANSLEY J,DENNY P,BECKER B A,et al.The Robots Are Coming:Exploring the Implications of OpenAI Codex on Introductory Programming [C ]∥Australasian Computing Education Conference.New York,USA:Association for Computing Machinery,2022:10⁃19.[3]贝世之,严嘉钰,章乐.基于PPO 算法的旅行商问题求解模型[J].北京电子科技学院学报,2021,29(4):88⁃95.BEI S Z,YAN J Y,ZHANG L.Solving Model of Traveling Salesman Problem Based on PPO Algorithm [J].Journal of Beijing Institute of Electronic Science and Technology,2021,29(4):88⁃95.[4]VANVUCHELEN N,GIJSBRECHTS J,BOUTE e of Proximal Policy Optimization for the Joint Replenishment Problem244吉林大学学报(信息科学版)第41卷[J].Computers in Industry,2020,119:103239.[5]CHENG Y,HUANG L,WANG X.Authentic Boundary Proximal Policy Optimization [J].IEEE Transactions on Cybernetics,2021,52(9):9428⁃9438.[6]别桐,朱晓庆,付煜,等.基于Safe⁃PPO 算法的安全优先路径规划方法[J /OL].北京航空航天大学学报:1⁃15,2022[2022⁃06⁃07].https:∥ /10.13700/j.bh.1001⁃5965.2021.0580.BIE T,ZHU X Q,FU Y,et al.Safety First Path Planning Method Based on Safe PPO Algorithm [J /OL].Journal of BeijingUniversity of Aeronautics and Astronautics:1⁃15,2022[2022⁃06⁃07].https:∥ /10.13700/j.bh.1001⁃5965.2021.0580.[7]申怡,刘全.基于自指导动作选择的近端策略优化算法[J].计算机科学,2021,48(12):297⁃303.SHEN Y,LIU Q.Proximal Policy Optimization Algorithm Based on Self Guided Action Selection [J].Computer Science,2021,48(12):297⁃303.[8]张建行,刘全.基于情节经验回放的深度确定性策略梯度方法[J].计算机科学,2021,48(10):37⁃43.ZHANG J H,LIU Q.Deep Deterministic Policy Gradient Method Based on Plot Experience Playback [J].Computer Science,2021,48(10):37⁃43.[9]CHEN B,LIU X,ZHAO H,et al.Maximum Correntropy Kalman Filter [J].Automatica,2017,76:70⁃77.[10]李辉,郝如江.相关熵和双谱分析齿轮故障诊断研究[J].振动工程学报,2021,34(5):1076⁃1084.LI H,HAO R J.Research on Gear Fault Diagnosis Based on Correlation Entropy and Bispectrum Analysis [J].Journal of Vibration Engineering,2021,34(5):1076⁃1084.[11]LIU W,POKHAREL P P,PRINCIPE J C.Correntropy:Properties and Applications in Non⁃Gaussian Signal Processing [J].IEEE Transactions on Signal Processing,2007,55(11):5286⁃5298.[12]杜嘻嘻,程华,房一泉.基于优势演员⁃评论家算法的强化自动摘要模型[J].计算机应用,2021,41(3):699⁃705.DU X X,CHENG H,FNAG Y Q.Enhanced Automatic Summarization Model Based on Dominant Actor⁃Critic Algorithm [J].Computer Application,2021,41(3):699⁃705.[13]樊龙涛,张森,普杰信,等.基于异环境重要性采样的增强DDRQN 网络[J].火力与指挥控制,2020,45(1):47⁃52.FAN L T,ZHANG S,PU J X,et al.Enhanced DDRQN Network Based on Heterogeneous Environment Importance Sampling [J].Fire Control and Command,2020,45(1):47⁃52.[14]周江卫,关亚兵,白万民,等.一种二次采样的强化学习方法[J].西安工业大学学报,2021,41(3):345⁃351.ZHOU J W,GUAN Y B,BAI W M,et al.A Reinforcement Learning Method Based on Secondary Sampling [J].Journal of Xi’an University of Technology,2021,41(3):345⁃351.[15]孙凤霄,孙仁诚.基于KL 散度的波形对齐算法[J].信息技术与信息化,2021(5):103⁃105.SUN F X,SUN R C.Waveform Alignment Algorithm Based on KL Divergence [J ].Information Technology and Informatization,2021(5):103⁃105.[16]余沁茹,卢桂馥.一种基于最大相关熵和局部约束的协同表示分类器[J].智能科学与技术学报,2021,3(3):334⁃341.YU Q R,LU G F.A Cooperative Representation Classifier Based on Maximum Correlation Entropy and Local Constraints [J].Journal of Intelligent Science and Technology,2021,3(3):334⁃341.[17]LIU W,POKHAREL P P,PRINCIPE J C.Correntropy:Properties and Applications in Non⁃Gaussian Signal Processing [J].IEEE Transactions on Signal Processing,2007,55(11):5286⁃5298.[18]朱志广,王永.基于高斯噪声扰动的随机梯度法的设计与应用[J].电子技术,2021,50(8):4⁃7.ZHU Z G,WANG Y.Design and Application of Random Gradient Method Based on Gaussian Noise Disturbance [J].Electronic Technique,2021,50(8):4⁃7.(责任编辑:张洁)344第3期张会珍,等:基于相关熵诱导度量的近端策略优化算法。
国外图书馆嵌入式学科服务研究内容演变及启示

·域外采风·国外图书馆嵌入式学科服务研究内容演变及启示张世怡(天津师范大学图书馆 天津 300387)摘 要:随着嵌入式服务的不断拓展,学科馆员们所面临的问题也在发生着变化。
如何为当下高层次用户继续提供满意的嵌入式学科服务,留住用户资源,是学科馆员们共同面对的问题之一。
文章从引文视角出发,引入因子分析,对国外图书馆嵌入式学科服务主题下的研究领域进行界定、研究热点进行辨析,结合文献梳理从嵌入式学科服务提供者、提供服务主体单位以及服务用户需求等方面阐述国外嵌入式学科服务的研究内容及演变方向。
在此基础上,结合国内实践案例抽象出“面向融合”的嵌入式学科服务工作思维导图。
关键词:国外图书馆;嵌入式学科服务;引文分析;因子分析;面向融合中图分类号:G252 文献标识码:AEvolution and Insights into Research on Embedded Subject Services in Foreign LibrariesAbstract With the continuous expansion of embedded services, subject librarians are facing evolving challenges. Providing satisfactory embedded subject services to high-level users and retaining valuable resources have become common concerns among subject librarians. This article utilizes a citation-based approach and incorporates factor analysis to define research areas and distinguish hot topics under the theme of embedded subject services in foreign libraries. It presents the research content and evolving directions of embedded subject services in foreign libraries, considering aspects such as service providers, institutional entities offering services, and user demands. Drawing from domestic practical cases, the article abstracts a conceptual framework for "integration-oriented" embedded subject service strategies.Key words foreign libraries; embedded subject service; citation analysis; factor analysis; integration-oriented1 引言嵌入式学科服务最早诞生于英美国家的大学图书馆中,自2004年提出至今,其相关理论和实践不断发展[1]。
学术语篇评价性that从句的评价理论介入视角研究

学术语篇评价性that从句的评价理论介入视角研究
陈晓曦;张继东
【期刊名称】《海外英语》
【年(卷),期】2015(000)024
【摘要】作为评价语篇重要的语法标记之一,从属连词that具有重要评价意义。
它可以在语料库中标记出具有极大评价潜势的名词性从句;可以在作者、读者甚至参
与第三方之间建立起对话。
评价性that的使用能反映出语篇清晰的评价结构和具
体的人际介入。
该文将选取上海交通大学科技英语语料库JDEST部分内容组建小
型语料库作为研究对象,利用评价理论的介入框架,将评价性that小句进行功能分类,并讨论分类标准和评价性that小句介入特点,同时为学术语篇写作的学习提出建议。
【总页数】4页(P216-218,220)
【作者】陈晓曦;张继东
【作者单位】东华大学
【正文语种】中文
【中图分类】H315
【相关文献】
1.介入视角下学术语篇的对话性分析 [J], 谢丽
2.突发事件新闻报道中的介入策略对比研究——评价理论视角 [J], 李君
3.生态翻译学视角下学习者与专家译者翻译策略对比研究——以学术语篇定语从句的翻译为例 [J], 马星宇
4.评价理论视角下学术语篇中模糊限制语的人际意义研究 [J], 薛美娜;崔林
5.从评价理论的介入观点看学术语篇中的互动特征 [J], 张跃伟
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1、战鼓一响,法律无声。——英国 2、任何法律的根本;不,不成文法本 身就是 讲道理 ……法 律,也 ----即 明示道 理。— —爱·科 克
3、法律是最保险的头盔。——爱·科 克 4、一个国家如果纲纪不正,其国风一 定颓败 。—— 塞内加 5、法律不ห้องสมุดไป่ตู้使人人平等,但是在法律 面前人 人是平 等的。 ——波 洛克
谢谢!
36、自己的鞋子,自己知道紧在哪里。——西班牙
37、我们唯一不会改正的缺点是软弱。——拉罗什福科
xiexie! 38、我这个人走得很慢,但是我从不后退。——亚伯拉罕·林肯
39、勿问成功的秘诀为何,且尽全力做你应该做的事吧。——美华纳
40、学而不思则罔,思而不学则殆。——孔子