基于Web日志的数据预处理研究
Web日志挖掘中数据预处理技术的研究

的图片、 声音 和脚本代码一起被下载到了客户端。
当挖掘 的 目的是 用户 访 问模 式时 , 片和声 音文 件 图 显然 用 处 不 大 。可 以 把 后 缀 为 JE MP , I , P G, 3 GF WMV等 的记 录删除 。但是 , 当挖掘的 目的是 为 了进 行 网络 流量分析 时 , 些信息又会 显得非 常 的重要 , 这
典 型 的 日志 记 录形 式如 下 :
次客户 连接请求 完所 要 的 网页后 , 服务 器会 自动与 客户断开 连接 , 同时被 申请 的网页文 件 连 同文件 上
22 129 .6 一 [2:35 8620 ] 一 0 .9 .46 1 2 :52/ /06
“G T d y lg h l . t l / .1” 一 1 0 — E / r / o / e p h ml Hr TP 1 0 1 0 1 一 “ t / w w. e p e u c ” 一 “ i d ws 12 ht / w h l . d . n p: W no
理, 包括删除无关紧要的数据 , 合并某些记录 , 对用 户请求 页 面时发 生 错 误 的记 录进 行 适 当 的处 理 等 等。只有当服务器 日志 中的数据能够准确地反映 用户 访 问 We 点 的情 况 时 , 过 挖掘 得 到 的关 b站 经
联规 则才 是真 正有 用 的。 由于 H r 议 是一 个 面 向非 连接 的协议 , T P协 每
表 1 E L 日志格 式 CF
雷 H H H H簦H
图 1 We b日志挖 掘 的预 处 理过 程
2 1 数据 清理 .
数 据 预处理 的第 一 步 是 数据 清 理 , , 据清 ’数 ] 理是 指 根 据 实 际 需 求 , WE 日志 文 件 进 行 处 对 B
改进的Web日志挖掘数据预处理方法研究

改进的Web日志挖掘数据预处理方法研究摘要Web日志挖掘中的数据预处理按处理流程,分为数据收集、数据清洗、用户识别、会话识别、路径补充、事务识别6步。
本文对会话的特点对预处理算法进行改进,直接由会话得到事务,不需要经过路径补充,从而简化处理过程,增强后期挖掘的正确性。
关键词Web日志挖掘;预处理;事务Web日志挖掘属于数据挖掘的一种,它是对用户访问Web时在服务器端留下的访问记录(即Web日志)进行分析处理,从中得到用户感兴趣的信息或模式。
并以此作为依据来改善网站结构,更好的满足不同用户的需求。
数据挖掘对数据的格式是要求严格的,而Web日志往往达不到该标准,直接处理会产生错误或无意义的工作,因此在挖掘前必须进行预处理,必须将Web日志转化为传统的数据挖掘方法能够处理的数据。
1 传统的方法Web日志挖掘的对象是Web日志,挖掘的主要目的是进行用户聚类,聚类的依据是页面访问序列,因此只考虑用户请求的页面,在请求方法当中只选取GET方法的。
日志中请求错误的、无用的信息记录在进行挖掘时都应该删除。
对数据整合,规范化,形成事务数据库,为挖掘做准备。
按处理的先后顺序,分6步来完成,它们分别是:数据收集、数据清洗、用户识别、会话识别、路径补充、事务识别。
2 改进的方法通过分析上述方法,同时结合实际情况:用户访问网站中的页面可以从网站根目录进来,也可能从历史纪录直接进入到某个页面,不难发现,能够反映用户真实兴趣的会话序列往往需要将路径补充完整,然后进行分割才能得到,过程较为复杂,而且补充路径的过程也比较费时。
若是简化过程,直接由会话序列得到事务则将大大提高算法的效率。
2.1 设计思想通过分析网站的结构,不难发现它是一棵有向树,为了处理方便可以看成一棵普通的树,而树中的一个结点就相当于一个页面。
当浏览到网站时就相当于从树根出发去遍历树中的结点,当到达分枝的叶子结点时,就认为已经浏览到了边界,这时要再访问别的页面就需要回退,即可认定新的会话开始了;或者当出现页面序列不连续,也可作同样的处理。
Web日志挖掘数据预处理研究

是 we b使用分析的一个基本先决条件 。
11 w b日志 文 件 . e
考虑 到普遍 性和代 表性 , 文那 仅 以 I 本 I 务 器 日志 文 S服 件 [为 例 , 论 W 3 2 ] 讨 C扩 展 日志 记 录 E F( xe d dL gF r L E t e o o— n
# Fil s e d :C— i t me C — me h d C - u i s e s - s a u p Da e Ti S to S r — t m c t t s
用 户 浏 览 的前 一 个 网址 ,
Uenme Sra meh d to ul tm r—se接 过 来 的 u e—a et Ye sr— gn s poo o rtc l sau tts b ts ye Ye s Ye s Ys e 客 户 所用 的浏 览 器 使 用 的 Itr e 协 议 , HT nent 如 TP, T FP 用 HT TP或者 F P术 语 所 描 述 的 动 作 状态 T 传 输 的 字节 数
微 型 电脑 应 用
20 07年 第 2 卷 第 1 期 3 0
We b日志挖 掘数 据预 处 理研 究
夏 成 文 , 韩 坚华 , 梁 乘 铭
摘 要 : 详 细 介 绍 E F 日志 文 件 格 式 的 基 础 上 定 义 了会 话 表 , 对 预 处 理 过 程 中 几 个 主要 步 骤 进 行 深 入 讨 论 , 结 已有 在 L 并 总
表 1 W 3 扩展 日志格 式部 分 域 C
域 标 识 符 是 否 需要 前 缀 描
述
d t ae t i me I p
-
N O NO Ye s Ye S Ye s Ye s
基于Web日志挖掘数据预处理技术的研究

/ \
亟 巨
土
.
・
= 苎 = 二 苎兰 = =
亟i
.
户 访 问序 列 。
x lU =J= :x Ux Ij: = ;x 【ilU = +Il ; f . ; n ¨) oa2 r k- : i {r . = ; ) f J l-. oO > '
用 1志 和站 点 拓 扑 结 构 . 3 构造 出他 的浏 览 路 径 。 果 当 前 请求 的 如 页 面 的 引用 页 不 在 已浏 览 的 页 面 系 列 中 ,则认 为存 在 另 外 具 有 1 We . b日志 挖 掘 的 过 程 We 日志 挖 掘 的过 程 一 般 分 为数 据 预 处 理 阶 段 、挖掘 算 法 相 同 I 址 与代 理 的用 户 。 b P地 下 面 给 出 的 是 i ae t 相 同 的访 问序 列 基 于 日志 参 引 D和 gn 均 实施 阶段 ( 式识 别 )模 式 分析 阶段 。 1 出了 日志 挖 掘 的过 模 、 图 给 页面 的 用 户 识 别 算 法 。 / n(< i= ) i 广 设 1 =< n为 p和 aet 相 同 且按 时 间 升 序 排 列 的 gn均 某 暂 定 用 户 访 问 序 列 ,i ul D 的 参 引 页 , x为 识 别 后 的用 L. r 为 p U
陈荣旺 1 2
郭
红
【 摘 要 】 数据预处理是 We : b日志挖掘 中的关键和 重要 一步, 文章分析 了We b日志挖 掘的数据预处理过程 , 并给 出基 于 日志参 引页的用户i  ̄ 、 径补全算法和基 于一种时 问窗 口模型的会话划分算 法。 e l路 , 【 关键词 】 We : b日志挖掘 数据预 处理 算法
网站Web日志数据预处理模型的建立

网站 W e 日志数 据 预 处 理模 型 的建 立 b
彭 薇
( 林 电 子 科技 大 学 计 算机 科 学 与 工程 学 院 ,广 西 桂 林 5 10 ) 桂 404
【 摘
翼】 文章对 W e b日志数据 的预处理进 行研 究 ,建立 了一个通用的基 于 We b日志数 据预处理的模型 。此模型
h a c a y fr u e d nt c to a e i h s c lulto t e c ur c o s r ie iiai n b s d Olt i a c a in.Afe r —p o e sng he s m i tu t r d W e t s c n— f tr p e r c s i ,t e —sr c u e b daa i o
应用技术
A p e eh o g p l dT cn l y i o
企业 科 技 与发展
En e p ie S in e An c n l g & D e eo m e t tr rs ce c d Te h o o y v lp n
2 1 年第 1 期( 2 8 00 8 总第 8 期)
v t d i t tu t r d d t,w ih i h l flfrW e n n tn x tp r c ie h s p o e a e mo e sf a i l d e t n o sr cu e aa h c s ep u b mi i g a e tse .P a t a r v d t t t d li e b e a e o c h h s n
We b日志 数 据挖 掘 面 临 着 以下 难点 : () 原 始 的 We 日志 文 件 包 含 的数 据 ,数 据 量 往 往 很 大 , 1 b
Web日志挖掘中的数据预处理研究
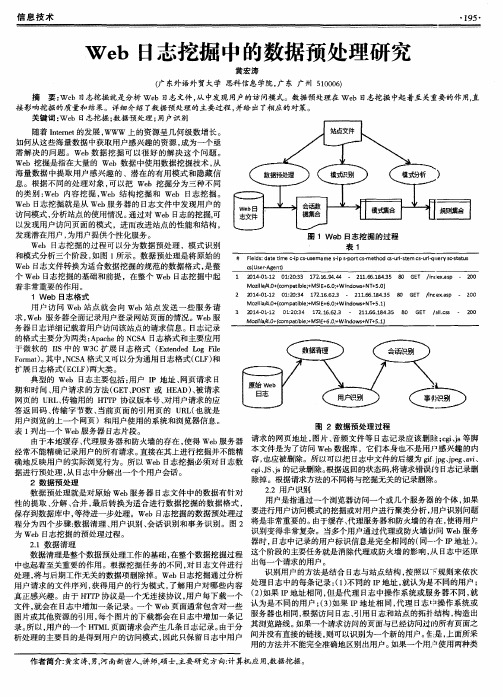
图1 We b日志 挖 掘 的 过 程
表 1
# F i e l d s : d a t et i me c  ̄ i p c s - u s e ma me s - i P s . p o r t c s * me t h o d - u l f - s t e m c s — u r l - q l l e r y s c - s t a t u s
Mo z i I l a 1 4 . 0 + ( c o np r a t i b l e ; + MS l E + 6 . 0 . + Wi n d o ws + N T + 5 . 0 )
ቤተ መጻሕፍቲ ባይዱ
2 扣1 4 — 0l - 1 2 0 1 : 2 0 : 3 4 1 7 2 . 1 6 . 6 2 - 3 - 2 1 i J 5 6 . 1 8 4 . 3 s 8 0 G E T / i n c e x . a s p - 2 0 0 Mo z i I l a 4. 1 O + ( c o mp a t i b l e MS l E + 6 . 0. + Wi n d o ws + N T + 5 . 1 )
c s ( U s e r - A g e n t )
1 加1 4 - 0 1 - 1 2 0 1 : 2 0 : 3 3 1 7 2 . 1 5 . g 4 . 4 4 — 2 l 1 . 6 6 . 1 8 4 . 3 5 8 0 G E T / i n d e x . a s p 一 2 0 0
信 息技 术
・ 1 9 5 ・
We b日志挖掘 中的数据预处理研究
黄宏涛 ( 广东外语 外贸大学 思科信 息学院, 广 东 广州 5 1 0 0 0 6 )
基于Web日志挖掘中的数据预处理

是 数 据 挖 掘 技 术 在 Wb e环 境 下 的 应 用 . 集 We 是 b技 术 、 据 挖 掘 技 环 节 的 任 务 、 在 的 主 要 问 题 和 实 现 技 术 展 开 分 析 。 数 存 术 、 息 科 学 等 多 个 领 域 的 一 项 技 术 。 We 信 b挖 掘 对 传 统 的 数 据 挖 掘
的 相 关 数 据 中 发 现 蕴 涵 的 、 知 的 、 潜 在 应 用 价 值 的 、 平 凡 的 模 日 志 文 件 : 未 有 非 式 . 访问 者 、 点经 营 者 以及基 于网 络 的商 务活 动提 供 决策 支 持 。 为 站 简单 的平 面 文本 文件 , 含 了一 些 不完 整 的 、 余 的 、 误 的数 据, 包 冗 错 需 的基 础 和实施 有 效挖 掘算 法 的 前提 。 We 志 挖 掘 首 先 要 对 挖 掘 数 据 进 行 预 处 理 。 始 1志 文 件 是 请 求 。 b1 3 原 3 2) 息 错 误 1 志 ( r rl , 取 请 求 失 败 的 数 据 , 如 : 失 信 3 E r o o g) 存 例 丢 3) 奇 1 志 ( okelg ) C ke是 由 We 曲 3 C oi os , o i b服 务 器 产 生 的 用 于 自 要 进 行 处 理 , 则 将 会 直 接 影 响 挖 掘 的 效 果 。 据 预 处 理 是 整 个 过 程 连 接 。 权 失 败 , 超 时 。 否 数 授 或 本 文 论 述 了 We 日志 挖 掘 基 本 概 念 、 骤 和 主 要 任 务 , 点 分 动 标 记 和 跟 踪 站 点 的 访 问 者 的 记 号 . oke由 客 户 端 持 有 , 务 器 方 b 步 重 Coi 服 析 了 We b 1 挖 掘 中 的 数 据 预 处 理 问 题 . 结 合 对 某 汽 修 网 站 We 可 采 用 C ke方 式 跟 踪 单 个 用 户 。 3志 b o i 日志 挖 掘 的 数 据 预 处 理 具 体 过 程 . 析 了 数 据 预 处 理 的 具 体 步 骤 和 剖
Web日志挖掘数据预处理技术的研究

科
We b日志挖 掘 数据 预 处理 技术 的研 究
任 海 龙
( 大庆油 田第一采油厂 第二 油矿 , 黑龙 江 大庆 130 ) 6 0 0
摘 要: We 在 b数据挖掘研 究领 域中, 数据预处理在 We b日志挖掘过程 中起 着至关重要 的作用 , 深入探讨 了数据预处理环节 的过程, 并介绍一 种由用户访 问序列直接 生成 用户访 问事务的算法。
关键 词 : 据挖 掘 ; b日志挖 掘 ; 据 预 处理 数 We 数
多个用 户 。 保存当前路径 P t; ah 1概述 We 数据挖掘是数据挖掘技术和 lt nt b ne e应 r 2 会话标识。 . 3 对于上一步标识出的用户所有 pp t) o(,: S P 用研究相结合的研究领域, We 在 b数据挖掘中, 最 的访问序列, 它们可能超越了很长的时间段, 因此 i P在 pt f( a h中) 重要的应用是 We 志挖掘。 b b1 3 We 日志挖掘与传 可能用户在这个时间段内不只一次访问了该网 从 pt ah中删去 P; 统数据挖掘的区别在于数据源不同, b日 We 志挖 站。会话标识的 目的就是将用户的所有访问序列 PP >ci ; =- rhl ) d 掘的对象通常是服务器的 日 志信 息,而传统数据 分成多个单独的用户一次访问序列。为了获得这 i( ak m tS ) 触Ⅱ fS eE p () t yI 果栈空但访 问序列并未 挖掘的 对象多为数据库。 b We 服务器的 日 志 e 个划分 , b 一个最简单的方法就是定义一个时间段 , 结束 , 则将 P 指向树根结点,a 赋为 0 l fg l 己 o 载了用户访问站点的信 息, 这些信息包括: 如果用户请求的相邻的任意两个页面之间的访问 访 ( f g ̄ } l - , a- 问者的地址 、 访问时间 、 访问的页面、 页面的大小 、 时间间隔超过了这个时间段 ,则认为用户又开始 1 3 . 验 。 算 法 实 现 的操 作 系 统 Wi— 2实 n 浏览器类型 、响应状态等等。每当站点被访 问一 了一个新的会话 , 这个时间段, 晴况下选择为 一股 次 , bl We o g就在 日志数据库 内追加相应的记录 。 3 0分钟。会话标识的 目的就是要创建每一个用户 dw 20 Sre, o s0 3 evr使用编程语言 C + 编译器 Mi +, — 站点的规模和复杂程度与 日俱增,利用普通 的概 的有意 义的 页面 聚类 。 coot i a C + - 图 3 表一个网站的拓扑 rsf Vs l + 6 。 ( u 0 弋 率方法来统计分析和安排站点结构已经不能满 2 4格式化。在数据集完成会{ 刮 目 之后 , 会 结构 , 是一棵普通的树结构 , 将其转换为-3 树结 - ̄ 足要求。 通过挖掘服务器的日志文件, 得出用户的 话数据必须被格式化成符合相应数据挖掘算法的 构如图 3) (所示。图 3 ) 每一结点的 I 1 (中 b 左结点为其 访 问模 式 ,从 而 可以进 一 步分 析 和研 究 日志 记 录 数据模型, 这一步工作称之为数据转化。例如, 进 在图 3 ) f中的孩子琉 , a 右缝 为其兄弟结点。 的规律 , 来改进网站的组织结构及典陛能 , 构造 白 行关联规则挖掘的数据格式和进行序列挖掘的数 适应网站; 还可以通过统计和关联分析 , 增加个 胜 据格式就可能不同。在数据转化完成之后 , 可以对 化服务, 发现潜在 的 用户群体 , 这在电子商务等领 格式化的数据进行{ 域是 很有 市场 的。 3算法及实验 2数据预处理的四个阶段 3 算法 。T 1 . 1 sI 算法是首先把网站的 树形拓扑 数据预处理是在将 1 3志文件转换成数据库 结构转换为二叉树 的结构 ,然后在二叉树结构上 文件以后进行的, 目的是把 We 志转化为适 根据用户的会话序列得到事务序列。P t 其 b1 3 ah中用来 合进行数据挖掘的可靠的精确的数据 。这个过程 存在当前向前的引用路径 ,也就是用户的访问事 主要包括 四个阶段: 数据清理 、 用户标识 、 会话标 务数据,e i 为用户访问序列, 指 向用户访问 Ss o sn s 【 一个网站的拓扑结构 a ) () b 转换为二叉树的结构 识和格式化。 序列中的当前结点,a 用来表示是否在树中找到 l fg 2 数据清理。 . 1 数据预处理的首要任务是数据 了浏览路径 的第一个结 。T为树的根结点, P为 图 1拓扑 结构 转换 为二 又列 清理 , 在任何形式的 We b日志分析过程中, 清除 指 向树根钴. 的指针 , 采用二叉链表存储结构。 假如在同—个会话产生的 1志如表 1 3 所示。 服务器 日志中不相关数据 的技术是非常重要 的。 获得最大 向前参引路径的算法描述如下 : 表1 用户会话 日志 序列 只有当服务器 日志中表示的数据能够准确地反映 初始化栈 S t 当前会话 页面 请求页面 用户访问 We b站点的情况时 , 经过挖掘得到的关 P指向二叉树的根结点 T A B f g 0 l -; a 联规则才是真正有用的。 B E E I 由于 H 丫P协议是一个面向不连接的协议 , 1r Wh e i 用户访问序列 S l 未结束 F K 每次客户连接请求完所要的网页后 ,服务器会 自 {i( g =9 fn =0 = A C 动与客户断开连接 ,同时被 申 的网页文件连同 请 I ({ 果根的当前结 fP 础口 1 与用户访问序列 中 文件上的图片和脚本代码一并被下载到了客户 的当前结点相同, 将其加入到 P t ab中 这次会话的浏览路径即用户访问序列为 A — 端。在大多数的情况下,只有 H M 代码是有用 TL I P >aa * ) f(-d t S - B F 1卜K A c, _ _一 — _ 通过路径补充技术 , 得到用户会 的, 并被保存在 1 3 志文件中以用于用户的识别。 因 f把 P加 入 到 P t ah中 ,S +; 话序列为 A E 『F B FK FB A C, + i f . 一_ - _ _ — _ — - 再利用最 此这就要清除日志 中的图片文件,通常清除不相 (a=O Fa= ; fg= 9 lgl) 1 : 大前向引用路径算法得 出用户的访问事务为 A — 关数据项可通过检查 U L的后缀来实现 ,例如: R p s(’ ; uh t) SP 把当前 绍点压入栈中 B E I B FK A c 利用文章中给出的算法, _ -、 — _ 、- 。 在 可以把所有后缀是 gf e i pg的文件名从 1志数据 , j 3 P P >ci ; = - lhl 】 / d / 指向 P的左孩子结点 不需要补充路径的情况便可由用户访问序列直接 中清除掉。 es { 0 ( F l e p p L' s ; ∥ 栈顶元素出栈 获得用户的访问事务 A B F I B F K A C — . —、 - _ 、_ 。 2 . 2用户标识。接下来, 唯一的用户必须被标 并赋 给 P 因为在数据预处理的过程中省略 了路径补 识出来 , 也就是说要识别出来具体的用户。 采用的 PP >ci ; 1/ 向 P的右孩 充的步骤 , =- rhl d 脂 根据用户访问序列直接得到用户的访 方法是使用 I P地址 , gn 类型以及一些临时信 子结点 Aet 问事务,文章中提出的算法使得预处理的过程得 息综合起来标识一个用户。 具体方法是 : es i l e f f f( > aa 1 i P dt- S - 到简化, 从而节约了一定的时间, 提高了整个 日 志 第一步, 如果 I 地址相 同, A et 息中 P 但 gn 信 f把P 加入到 P t 中, 挖掘的效率。 a h 如浏览器软件或操作系统不同则可以假设为不同 S : H 结束语 的两个用 户 。 文章对 We 志挖掘中的预处理模块进行 b1 3 p s(t) uh ,; SP 第二步, I 地址和 A et 如果 P gn 信息都相同则 ‘ P- >ci ; =-l l } P hd 了研究 ,且提出了一种由用户访问序列直接生成 判断每一个请求访问的页面与访问过的页面之问 Es l e{ p s(t) uh , ; SP 用户访问事务的算法 , 这种算法不需要使用路径 是否有链接。如果一个请求访问的页面与上一个 补充技术来补充完整的路径后再进行事务识别, P P >c i ; - -rhl } d 已经访问过 的所有 的页面之间并没有直接 的链 Es f f P l 的前一个结点是左结 从而使得预处理的过程得到简化,提高了挖掘的 e i f 接, 则假设在访问 We 站点的机器上同时存在着 点) b 效 率。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
③ 用户请求 页面 的 日期和具体 时间 ;
④用户请求的方法 、 用户所请求的页面以及传输
使用 的协议版本 :
⑤ 服务器状 态码 , 0 2 表示请求成 功 ; 0 ⑥ 发送 给客户端 的总字节数 : ⑦ 用户代理 。
1 数 据 的 来 源
We 用 记 录 的数 据 除 了服 务 器 的 日志 记 录 外 . b使 还 包 括 代 理 服 务 器 1志 、 览 器 端 1志 、 册 信 息 、 3 浏 3 注 用
0 引 言
数 据 预 处 理 是 We b 1 挖 掘 的 关 键 技 术 .其 主 3志 要 任 务 是 从 We 志 文 件 中 有 效 地 识 别 用 户 访 问 会 b1 3 话 。 预 处 理 的 输 入 是 原 始 1志 文 件 , 出 的 是 用 户 会 3 输
① 访 问用户 的 I 址或用户使 用 的代理服务 器 P地
\
竺
基 于 We b日志 的数 据 预 处 理 研 究
金 述 强 . 蒋 外 文
( 南大学 信息科 学与工 程学 院 , 沙 4 08 ) 中 长 1 0 3
摘
要 :详 细 介 绍 W e 日 志 挖 掘 的数 据 预 处 理 过 程 。 通 过 对 预 处 理 的 结 果 用 户 会 话 文 件 进 行 处 b
理 , 造 出 扩 展 有 向 树 模 型 , 从 每 个 用 户 会 话 文件 中发 现 该 用 户 所 有 的 最 大 向 前 g 用 构 并 l 路 径 , 实施 w e 志挖 掘 算 法提 供 数 据 基 础 。 为 b1 3 关 键 词 :数 据 预 处 理 ;用 户 会 话 ;扩 展 有 向 树 ;最 大 向 前 引 用 路 径
目前 较 为 常 用 收 集 的 使 用 数 据 是 服 务 端 自动 记 录 的
We 日志 文 件 可 见 We b b使 用 记 录 的 数 据 量 是 巨 大 的. 而且 数 据 类 型 也 相 当 丰 富 W e 志 挖 掘 的 对 象 b1 3 通 常 是 服 务 器 的 日志 信 息 We b服 务 器 的 1志 ( b 3 We
处 理 转 化 为 用 户 会 话 如 图 1 示 所
罂童 旦
==
— —
— — — —
提 后 站 结 升 的 点构
J …
一 / ’
现 种 : 用 1志 格 式 C FC mm0 o oma 和 扩 展 型 通 3 L (o nL gF r t ) 代 日志 格 式 (xed dL gF r t E tn e o oma 以一 条 通 用 日志格 式 ) 计
2 W e 日志 的 数 据 预 处理 b
虽 然 we b访 问 日 志 有 着 良 好 格 式 和 详 细 的 信 息 . 由于代理服务 器 、 火墙 和客户端缓存 的存在 , 但 防 服 务 器 端 访 问 日志 文 件 中 记 录 的 信 息 并 不 能 真 实 地
反 映 用 户 访 问信 息 。 因 此 .必 须 对 E志 进 行 预 处 理 。 l
I P地 址 :
② 用 于记 录用户 名及其 I , D 如果是 空 白, 则用 一
个 ” “ 位符代替 . 示 未注册用 户 : 一一 占 表
话文件 . 出结果直接影 响到挖 掘算法 产生 的规则 和 输
模 式 。 因 此 预 处 理 过 程 是 We 志 挖 掘 质 量 保 证 的 b1 3
九
三
期
、一
① MDR OPTR0 10 OENC E 28 MU o
.
研s发 究 开
21 数 据 净 化 .
数 据 净 化 是 指 删 除 We b服 务 器 日志 中 与挖 掘 算 法无 关 的 数 据 由 于 用 户 的 一 次 请 求 可 能会 让 浏 览 器 自动 下载 多 个 附 属 文 件 . 如 一 些 图 片 、 标 等 , 般 例 图 一 这些 请 求 对 于 日志 挖 掘 来 说 没 有 什 么 意 义 因此 , 要
户会话 信 息 、 易信 息 、 oke中的信 息 、 户查 询 、 交 C oi 用
鼠 标 点 击 流 等 一 切 用 户 与 站 点 之 间 可 能 的交 互 记 录 收 集 数 据 的 地 点 除 了 服 务 器 端 .还 可 以 在 客 户 端 、 H,r 理 端 、 b服 务 器 端 . 至 是 底 层 网 络 通 路 。 I P代 ] We 甚
g 记 载 了 用 户访 问 站 点 的 数 据 . 映 出 多 个 用 户 对 1 反 单 个 站 点 的 访 问 行 为 1志 记 录 的 格 式 主 要 分 为 两 3
We 日志 数 据 预 处 理 技 术 就 是 将 原 始 1志 文 件 结 合 b 3
站 点 的 结 构 和 We b页 面 的 内 容 .经 过 一 系 列 的数 据
一——源自、 —算 机
^
的记 录 为 例 :
L
一 一 r 1Ma / 0 6 1 : 8 1 - 2 / r2 o :4 0 :4 4 -
朗
@
用户 识别
咎
磐
’ — l
l 2 1 811 9 .6 ..
总
0 0 ] “ E t : w s j. / ann w / Hr P 80 ⑧ G T ht # w.m. c m i e s pw i xn / r/
收 稿 1 期 : 0 8 0 — 7 修 稿 日期 : 0 8 1 —1 3 20— 7 0 20 — 0 0 作 者 简 介 : 速 强 (9 2 ) 男 , 士 研 究 生 , 究 方 向 为 W e 日志挖 掘 全 18 一 , 硕 研 b
图1 we 日志 数 据 预 处 理 的 一 般 步骤 b
1 1 2 0 ̄2 5 .” 0 0 0@ “ o i a4 0 (o ail; I .; M zl / l c mp t eMSE 60 b
.
原 始访 问 日志 数据 简化
会话 F ae 路径 用 户会 话文 件 rm 识别 过 滤 补充
第
二
W id w NT 5 1S 1 n os .:Vl⑦